背景
Qiitaの過去良記事を発掘したい
自分にとって役立つ記事、面白い記事を読みたい、というのは多くの人が思う欲求である。
Qiitaの記事を読む時は、大きく3パターンあると考える。
- 【最新トレンド】
- ニュースの閲覧的に、最新の話題記事をチェックして読む時
- 【課題検索収集】
- 技術的な課題の解決や、関連情報収集のため、Googleなどで検索して読む時
- 【偶発リンク】
- 1or2で読んでいる途中で、リンクやユーザ情報などから、気になった記事を辿る時
【最新トレンド】 と、【課題検索収集】については既に様々な仕組みがある。
Qiitaトップページのトレンド、多数のランキングサイト/ページや、メール配信等での、
日次、週次、月次の、「いいね」ランキング。
「タグ」によるジャンル別の情報配信や、Google検索、関連記事のリコメンドなど。
「いいね」の個数をそのまま良記事判定と考えて良いのか?については、
ものすごくいろいろな意見があると思うが、
特定のジャンルの記事を【課題検索収集】しているのでなければ、
一旦、「いいね」を指標として考えておく。
(「いいね」が少ない良記事を取得する話題は、まず「いいね」が多い記事を得てから考える)
しかし、Qiita歴が浅い私としては、
過去に話題になった記事(殿堂入り記事的な)を見つけるための仕組みが非常に弱いと感じている。
トレンドなどに乗った記事か、検索時にたまたま見つけた良記事しか読めていないが、
実はもっと、読んだ方が役立つ記事や面白い良記事が、過去記事内にも多いのではないか?
トレンドやランキングなど、毎日チェックしてねーよ、って人も同じように思うのではないか?
(話題になった記事も、1~2週間でトレンドやランキングからは外れる)
また、じわじわと「いいね」が上がるような、トレンドに浮上しにくい良記事もあるのでは?
【最新トレンド】の「最新」を消したような、
「殿堂入り記事集」が欲しくなってきている。
月次ランキングや年次ランキングではない。それは、日々変わってしまうと、
どこまで読んだのか分からなくなってしまうし、読んだ記事と未読記事の判別も面倒。
XXランキングとか、XXボットとか作るほどの方は、熱心なQiita愛好者であり技術も高いため、
毎日チェックすることが前提的な状態に見える。
「いやーたまにしか見ないんだよね」的な人が喜ぶまとめがあってもいいんじゃない?。
本投稿の内容
- QiitaのAPIを使って過去投稿のデータを取得する。(取得プログラムを作成する)
- 取得したデータを分析して、Qiita全体の傾向について考察結果を記載する。
- 時系列で「殿堂入り記事集」を作る。(分析/まとめプログラムを作成する)
- 実際に(私が欲しかった)直近2年分くらいの殿堂入り記事のまとめを記載する。
- リンク集としても役立つ記事に!
- 最終的には、自然言語解析で良記事の分析や自動判定なども検討したいが、それは別記事予定。
- コードの実行環境は全て、Windows10 + Python3 を前提。
- Qiitaの利用状況をデータを元に考察するには、必読の記事になると思われる
まず「いいね」について簡単な考察(指標決め)
「いいね」の個数が、自分にとっての良記事とイコールか?
多くの人はNoと言うだろう。
「いいね」は、良い記事かどうかという以前に、
そもそも記事がViewされないと絶対に付かない。
そのため、以下のようなパターンの記事は埋もれてしまいがちである。
- 良い記事なのだが、viewsの数が少ない記事
- 特定のジャンルに興味がある人だけにとって良い記事
viewsは、自分が書いた記事についてしか見ることの出来ない仕様になっている。
仕方ないので、私の書いた過去記事を使って比較してみる。
- (146いいね / 3910views = 3.7% 2018/06/25)
- (1220いいね / 39253views = 3.1% 2018/06/03 )
- (1461いいね / 35020views = 4.2% 2018/05/07)
- (9いいね / 602views = 1.5% 2018/03/10)
- (23いいね / 2106views = 1.1% 2018/03/10)
(数字はいずれも2018年6月28日22:30ごろのデータ。他にも記事はあるが面倒なので記載省略)
モビルスーツの性能の違いが、戦力の決定的差ではないということを・・・教えてやる!
「いいね」の絶対値の違いが、良記事かどうかの決定的差ではなく、
「割合」や「どんなテーマで書いたか」「投稿後どれくらいの時間が経過したか」などの
データも元にした方がよいと考えて、上記の数字も見てみたのだが・・・。
- 「views」は投稿者自身にしか見れない、APIでも取得できなかった。
- 投稿後の経過日数の影響は、全く同じタグ/同じレベルの内容でないと比較考察しにくい。
- 同じ投稿者、投稿日でも内容(タグ)によって、数倍の違いがあると分かる。
- そもそも良記事の指標を決定しきれない(人によるだろう)
- ユーザへのフォロー数を考慮? いや、既に自身でもバラツキが多すぎる。
上記考察より、しかたないので、一旦「いいね」を指標とすることにする。
方針としては、まず「いいね」を指標として記事を取得/分析する。(本投稿)
その後、どういった記事が「いいね」なのか傾向が分かれば
「いいね」が無いけれども、本来はviewされれば「いいね」が付く記事、
が見えてくるかもしれない。そうすればそれを自動判定させたい。。。(後日検討)
なお、後述するが、2016年11月に「いいね」の大きな仕様変更が入っており、
「いいね」をする文化/傾向にも大きな変化があったように見える。
その仕様変更の数か月分前くらいの記事から影響を受けており、
最近の記事の方が、2016年4月以前の記事よりも、数倍「いいね」を得にくい状態である。
そのため、各ユーザの「Contribution」についても、
昔の投稿分については、本来は若干間引いた方がよいと思われる。
また、「全記事でのいいねランキング」もたまに見かけるが、
それだと過去記事が有利であるため、新記事が埋もれやすい。
補足:何がviewsに影響?何がユーザフォローに影響?
なお、上記の自身の投稿をしていて初めて理解できたことだが、
以下2点の影響はかなり大きい。
- 「Qiitaトップページのトレンド」に記載されるかどうか?
- 「週次のQiita公式のメール」に記載されるかどうか?
逆に言うと、その期間が過ぎると「いいね」も「views」も日々の増加数は激減する。
全く無くなるわけではなく、「リンク」などによって少しずつ流入するようになる。
また、「いいね」と「ユーザへのフォロー」は関係があるような無いような、分からない。
「いいね」をしていなくても、フォローだけする人も一定の割合いらっしゃる模様。
忘れていたのなら今から「いいね」してもいいですよ(違。
QiitaAPIv2を使った過去投稿データの取得
既にこの時点で、物凄く長くなりそうな予感がするので、興味のある人がいるならば、後で書く。
またはもう別記事にする。
pythonでQiitaAPIv2を叩く。取得したjsonをパースする。
qiita2というpython用のラッパーを使用させていただく。(感謝
ポイントは、一度に取得できるデータ量は1万件までというAPIの制限があること。
その制限をクリアするために、ライブラリ側にも手を入れつつ、頑張る
月次で取得すればある程度良いのだが、一部に月次で1万件を超えてしまう箇所有(泣。
ユーザのcontributionは取得出来ない、などのいくつかのAPI仕様も理解する必要あり。
データの分析結果:時系列傾向
分析方針
- YYYY年MM月に投稿された記事について、「いいね」の数をカウントする。
- 月ごとに集計を行うことで、〇月ごろの殿堂入り記事、として読んでいきたい。
- 直近の2年間を対象とする。
時系列での分析結果サマリ
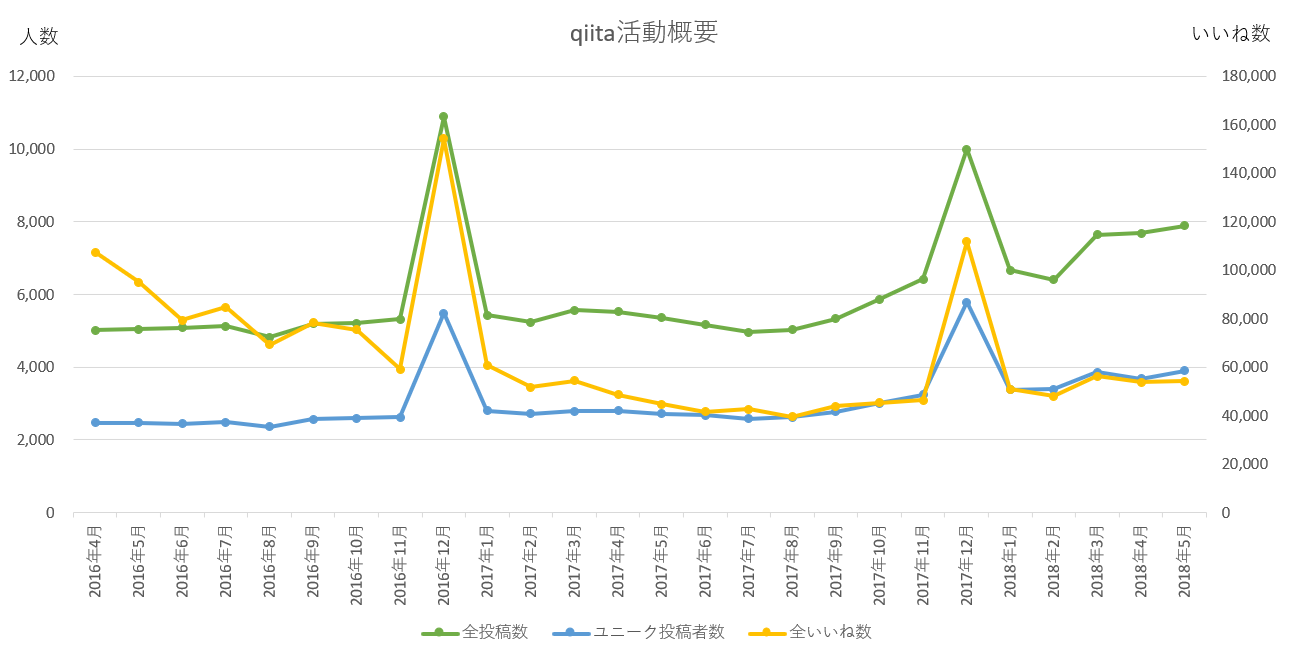
- 全投稿数と、ユニーク投稿者数は、グラフの左側の数値を参照
- 全いいね数は、右側の数値を参照
- 2016年12月は単月で、API上限値の1万件を超えてしまう。
ここのユニーク投稿者数だけ、予測値- 2018/06/30 個別に計算しました。
6000⇒5489 で、グラフも合わせて修正。
- 2018/06/30 個別に計算しました。
- (追記)2017年12月も単月で超過、上の図は誤っていた。実態は上記の1.2倍ほど。
時系列で分析結果考察
分かったこと:
- まず目に付くのは、「12月」の投稿量が、異常に増えるということ。
- 年末だからまとめて書こうとか振り返りとかやっているの?
- ⇒Advent Calendarのためと、howdy39さんからご指摘いただく。
- このイベントの影響は結構大きい模様。
- 投稿の分量やユーザ数は、微増を続けており、特に2017年9月以降の上昇幅は大きい。
-
「1投稿当たり平均いいね数」は、2016年11月以前の方がかなり高い
- いいね数は基本的には減らないため、昔の投稿の方が有利だが、それ以上に影響が大きい。
- なお、2018年5月vs2016年4月では、平均6.9 vs 21.5 で3倍以上の開きがある。
- グラフ外だが、2016年4月だけ高いのではなく、それ以前も同様の数値。
- これは、2016年11月のQiitaの仕様変更による影響が大きいため。
- 右記事参照: 投稿記事やコメントに「いいね」できるようになりました
- 旧仕様で公開された期間が十分に長いほどいいねが多くなるので、
- 2016年4月~2016年11月間で減少し続けているように見える。
- つまり、投稿時期の違う記事を「いいね数」だけで比較することは誤差が大きい
- ある程度投稿時期を揃えて、時期ごとに殿堂入り記事を見つけることが望ましい。
- 1投稿者あたり、ひと月に、平均2記事投稿程度、という値はおよそ一定。
- ひと月あたりのユニーク投稿者数は、2018年5月でおよそ4000人。
殿堂入り記事集
殿堂入りの定義
- 「記事を最初に投稿した月ごと」にランキングを作る(いいね数のTOP30まで)
- 例えば、2018年05月の例だと、TOP 0.38% の厳選投稿ということ。
- TOP 0.38% の記事で、5月の投稿に対するいいね数の、43.7% を占めている。
- このTOP30個の記事を**「殿堂入り」**ということにしておく。
- (7800記事の中から30個読むだけで、その月の40%分のいいねを読める高効率性)
- 下記のデータは全て、2018年6月末ごろ、の時点のデータとする。
- 更新が発生すると、どこまで見たか忘れるので、原則更新しない。
- 一年や半年に一回くらい作り直して別記事にすればいいのではないか。
- 28位~30位あたりは更新するたびに入選落選が入れ替わるかもしれないが、
- 過去記事のいいね増加は緩やかであるため、数値以外に大きな変動は無いだろう。
殿堂入り記事集の作り方
やっぱり長くなりすぎているので、興味のある人がいるならば、後で書く。
またはもう別記事にする。
データ取得してきたときに、月ごとにlist化しておき、
いいね数でソートして上位30取り出して、エクセルに張り付ける感じ。
いや、pythonで全部やれよって話もあるけど、どう書くか決まっていない段階では、
素データ状態でエクセルで見たほうが楽だよね、ということにしておく。
以下、殿堂入り記事一覧(結果)の記載
2年分記載しようと思ったが、やはり超絶長くなるため、
まず直近の半年分くらの結果を記載する。
後で書く、か別記事化か・・・。
⇒6/30に、直近「1年分」に追加変更。これ以上は別途記載かな。
2018年05月の殿堂
全記事数= 7891 全いいね数= 54257 投稿者ユニーク数= 3904
2018年04月の殿堂
全記事数= 7687 全いいね数= 53855 投稿者ユニーク数= 3684
2018年03月の殿堂
全記事数= 7642 全いいね数= 56293 投稿者ユニーク数= 3862
2018年02月の殿堂
全記事数= 6412 全いいね数= 48022 投稿者ユニーク数= 3391
2018年01月の殿堂
全記事数= 6664 全いいね数= 50839 投稿者ユニーク数= 3385
2017年12月の殿堂
全記事数= 9997 全いいね数= 111762 投稿者ユニーク数= 5794
2017年11月の殿堂
全記事数= 6414 全いいね数= 46335 投稿者ユニーク数= 3249
2017年10月の殿堂
全記事数= 5875 全いいね数= 45311 投稿者ユニーク数= 3008
2017年09月の殿堂
全記事数= 5340 全いいね数= 43936 投稿者ユニーク数= 2776
2017年08月の殿堂
全記事数= 5028 全いいね数= 39641 投稿者ユニーク数= 2629
2017年07月の殿堂
全記事数= 4958 全いいね数= 42579 投稿者ユニーク数= 2589
2017年06月の殿堂
全記事数= 5164 全いいね数= 41663 投稿者ユニーク数= 2677
【おまけ】2018年06月の殿堂【途中版(6/28時点)】
全記事数= 7646 全いいね数= 36440 投稿者ユニーク数= 3744
※特に6月後半の投稿は、まだトレンドやメールでの拡散が不十分であるため、
7月1日になれば確定、というわけでもない。
前述の通り、トレンドやメールの影響が大きいため、
その影響が安定したら再集計すればよいと思われる。
あとがき
いくつかやり残した。
「いいね」の反応が多いなど、ニーズ/ご支援が多そうなら、
以下のやり残したことをやってみようと思う。
(私の他にも同様の、殿堂入り記事ニーズを感じている人や、
同の分析結果が知りたいという人がいるかも、と思って投稿/公開してみたが、
記事にするのは多少手間がかかる。「いいね」するよりはずっと大変。)
- 記事を書くだけ系
- データ取得のプログラムの解説/分析のプログラムの解説
- ランキングをもっと過去分を張る
- 1記事が重くなって編集にも差しつかえるので、分割した方がいいかもしれない。
- 既に、プレビュー状態で編集していると重すぎて困ってきた。
- これからやってみたいこと
- まず、取得できた良記事を読んで楽しむ(もともとの私の目的)
- 投稿の内容(タグ、文字数、投稿者等)といいね数の傾向分析
- その分析プログラムの作成や、データの視覚化
- 自然言語解析による、投稿内容の分析 (第二の目的)
- 自分自身の投稿は、分析してはいけないカオスになりそうな予感で少し気が引ける
- メロンとメロンパンを、キカイが探す物語
- 平成の次の元号を、AIだけで決めさせる物語
- 「赤の他人」の対義語は「白い恋人」 これを自動生成したい物語
「対空邪神ジェイソン貯水池」とかノイズが多すぎる。どうするんだ?
- 2018年7月3日 追記:
- 投稿の内容といいね数の傾向分析結果を、以下の記事として追加
- 直近1年のQiita記事分析で分かった7つの「驚愕」
以上。
2018年6月29日時点初版投稿
2018年6月30日、2017年06-11月分を追加。
2018年7月3日 続編へのリンクを追加。
直近1年のQiita記事分析で分かった7つの「驚愕」
2018年8月5日 本内容をWebサービス化
【無料】Qiitaの殿堂を作った物語【簡単】