この記事は、俺コン Vol.1 / Day. 2 - connpassでの発表を、文章としてリライトしたものです。
スライド版:
https://speakerdeck.com/takasek/20171003-number-orecon-ios-number-akibaswift
前置き

このアスキーアートは、「矛盾塊」と呼ばれるそうです。矛盾する情報が同時に与えられたとき、人は混乱してしまいます。ここはQiitaなのでコードで書きますと、
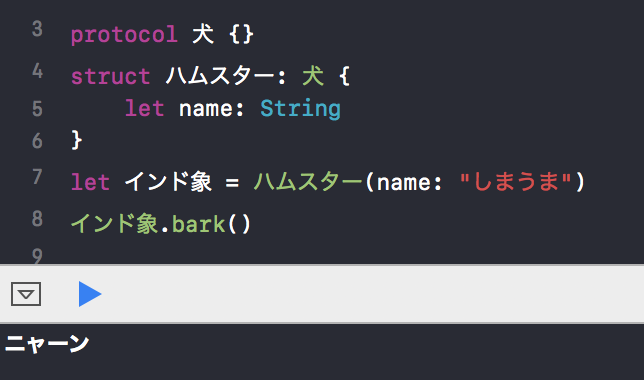
コードになっても混乱しますね。
こんな矛盾に溢れたコードを、業務では見たくないですよね。しかし矛盾塊コードは、程度の差はあれ、普段の業務コードの中にも潜んでいるものです。たとえば、
-
update()で特定の条件ではupdateせずに戻る -
fetch()といいつつUIの更新もしてる - 名前に困って
func didReceive(hoge: Hoge)
このような矛盾塊コードをそのままにしてしまう理由は、様々あるかと思います。めんどくさいとか、動いているコードに触りたくないとか、適切な名前が思いつかないとか、まあ全体を読めば理解できるし…とか。でもまあ、要は、バグってわけじゃないし、そこまで実害を感じないからこそ、見逃してしまうのでしょう。
しかし、そこには明確な実害があります。
矛盾塊コードの実害1: コードリーティングを遅くする
矛盾塊を見るときに受ける混乱を、心理学用語で「ストループ効果」というそうです。Wikipediaからの孫引きですが、
例えば、色名を答える質問を行った場合、赤インクで書かれた「あか」の色名を答える場合より、青インクで書かれた「あか」の色名(『あお』)を答える方が時間がかかる事をいう。
そう。矛盾塊コードは、コードリーディングを遅くする。これが心理学に裏付けされた真実なのです。
矛盾塊コードの実害2: 関係ない処理が入り込む隙ができる
矛盾塊コードには、もっと危険な実害があります。
名前に混乱を来したまま開発を進めると、本来関係のない処理が入り込む隙に繋がります。つまり、型やメソッドの責務の範囲が定まらなかったり、型やメソッドが肥大化する・処理が各所に分散する。そして最悪、バグが仕込まれます。
そうしてみると、さっき「まあいいかな」と思えたコードも、実は隙だらけだとわかってきます。
-
update()で特定の条件ではupdateせずに戻った結果、データ更新後も画面は更新されない。…と思ったら処理が途中でguardされていた -
fetch()といいつつUIの更新もした」結果、思わぬ時にAlertが表示される - 名前に困って
func didReceive(hoge: Hoge)と名付けた結果、isFetching: Boolの管理箇所が分散してしまった
全体を注意深く読めば防げると思われるかもしれませんが、そんなのは無理です。それよりは、注意深くなくても大丈夫な仕組みをつくるほうが大事です。
それが「しっかりしたネーミング」を徹底する理由です。
良い名前をつけることの重要性、おわかりいただけたでしょうか。適切なネーミングは、コードを読みやすくするばかりでなく、設計を正しく保ち、バグの混入を防ぐのです。良い名前をつけましょう。
では、どうすれば?
「リーダブルコード」より:「名前に情報を詰め込む」
ネーミングの指針として定評あるのが、「リーダブルコード ―より良いコードを書くためのシンプルで実践的なテクニック」という本です。
この本では「名前に情報を詰め込む」ための6つのテクニックを紹介しています。
- 明確な単語を選ぶ
- 汎用的な名前を避ける(あるいは、使う状況を選ぶ)
- 抽象的な名前よりも具体的な名前を使う
- 接尾辞や接頭辞を使って情報を追加する
- 名前の長さを決める
- 名前のフォーマットで情報を伝える
「名前に情報を詰め込む」①明確な単語を選ぶ
まず最初のテクニックが「明確な単語を選ぶ」こと。
// ❌
HogeStorage.set(fuga)
// ⭕️
HogeStorage.store(fuga)
たとえばストレージに対してなら、setという無味乾燥な単語よりは、storeという単語のほうがイメージしやすくなります。
// ❌
RxSwift.Observable
// ⭕️
RxSwift.Single` // as you can!
また、RxSwiftではObservable型が広く使われていますが、もし一度しかイベントの発生しないストリームであれば、ObservableよりもSingle型を使った方が、その意図が明確になります。
また、Swiftには引数ラベルがあります。これを活用しましょう。
// ❌️
employees.remove(x)
view.dismiss(false)
let text = words.split(12)
// ⭕️
employees.remove(at: x)
view.dismiss(animated: false)
let text = words.split(maxSplits: 12)
// ※出典: https://swift.org/documentation/api-design-guidelines/
remove(x) と言われると、xという要素を削除するのかと思ってしまいます。しかし、atというラベルを入れ、remove(at: x) とするることで、x番目の要素を削除するという意図が明確になります。
「名前に情報を詰め込む」②汎用的な名前を避ける(あるいは、使う状況を選ぶ)
続いてのテクニックが「汎用的な名前を避ける」ことです。ViewControllerのプロパティに、marginと、defaultSizeがあったとします。
// ❌
final class HogeViewController {
private let margin: CGFloat = 2.0
private let defaultSize = CGSize(width: 100, height: 50)
...
}
なんのマージンとサイズやねん、って感じですよね。このような名前は、避けましょう。
ただし、汎用的な名前が常にNGというわけではありません。
// ⭕️
func calculateComponentWidth
(paralleling contentSizes: [CGSize]) -> CGFloat {
return contentSizes.reduce(margin) { result, size in
let margin: CGFloat = 2
result + size.width + margin
}
}
var userID: Int? {
switch self.userState {
case .id(id): return id
case .entity(e): return e.id
case .unavailable: return nil
}
}
メソッドの中など、スコープが狭く限定的な場合には、汎用的な名前はむしろ良いものです。
また、Enum の associated value を取り出すときなどに、変数が一時的なものだと示すために、あえて雑な名前をつけるのもアリだと思います。
「名前に情報を詰め込む」③抽象的な名前よりも具体的な名前を使う
テクニック3番目。「抽象的な名前よりも具体的な名前を使う」。まずは悪い例のメソッドの、インタフェースだけごらんください。HogeListViewControllerに生えているメソッドです。
// ❌
class HogeListViewController : UIViewController {
...
func fetch()
func fetchBackground()
func fetchReally(_ id: String, show: Bool)
...
}
fetch 、 fetchBackground , fetchReally 。
どれがどういう役割を持ったものだか、ぱっと理解できるでしょうか。 fetchReally があるということは、普通の fetch はリアリーじゃないんでしょうか。 bakcground ってどういうことでしょうか。謎は深まるばかりです。
実装の中身を見てみます。
class HogeListViewController : UIViewController {
/// 通信して、失敗したらアラートを表示する
func fetch() {
fetchReally(textField.text!, show: true)
}
/// 通信して、失敗してもアラートは表示しない
func fetchBackground() {
fetchReally(textField.text!, show: false)
// 👆どうやら「アラートを表示しない」からbackgroundというらしい。嘘だろ!?
}
func fetchReally(_ id: String, show: Bool) {
api.fetch(id) { [weak self] models in
self?.didReceive(models: models, showsAlertIfFailed: show)
}
// 👆「具体的な通信処理が書いてある」からreallyというらしい
}
}
蓋を開けてみると、 fetch と fetchBackground は、どちらも fetchReally を呼ぶ処理が1行書いてあるだけでした。違いは、 fetch では通信失敗時のアラートを出すけれど、 fetchBackground では出さないらしいです。アラートを出さないから「バックグラウンド」というメソッド名…嘘だろって感じです。
あと Really については…おそらく、開発初期にあったのは fetch メソッドだけで、 fetchBackground の誕生時に通信処理を切り出したものの、元メソッドをリネームしなかった結果こんな名前になっちゃったんでしょう。
が、経緯はともかく、今目の前にあるのは、わけのわからない矛盾塊です。
fetch と fetchBackground の違いが、アラートの出し分けの有無なのであれば、それを具体的な名前で表すべきです。また、
Really という副詞は何も言っていないのと変わりません。
こうしましょう。
// ❌
func fetch()
func fetchBackground()
func fetchReally(_ id: String, show: Bool)
// ⭕️
func startFetchingHogesWithFailureAlert()
func startFetchingHogesWithoutFailureAlert()
func fetchHoges(withID id: String, showsAlertIfFailed: Bool)
これなら、初めて読む人でも理解できる、具体的な名前になります。
「名前に情報を詰め込む」④接尾辞や接頭辞を使って情報を追加する
4番目のテクニック。「接尾辞や接頭辞を使って情報を追加する」についてです。
以下に示すのは、URLエンコードされた文字列をデコードする一連の処理です。
// ❌️
let text1 = "100%25%E5%8B%87%E6%B0%97"
let text2 = text1.removingPercentEncoding! // "100%勇気"
let text3 = text2.removingPercentEncoding! // CRASH😣
// ⭕️
let encodedText = "100%25%E5%8B%87%E6%B0%97"
let decodedText = encodedText.removingPercentEncoding! // "100%勇気"
// もう👆はdecode済みだとわかる
悪い例では、text1,2,3という変数名のため、どれがデコードされたものかわかりません。
良い例では、変数名にencoded, decodedという接頭辞をつけることで、その意味が明確になりました。
「名前に情報を詰め込む」⑤名前の長さを決める
5番目のテクニック、「名前の長さを決める」です。
NSLayoutManager には、 func drawStrikethrough(forGlyphRange glyphRange: NSRange, strikethroughType strikethroughVal: NSUnderlineStyle, baselineOffset: CGFloat, lineFragmentRect lineRect: CGRect, lineFragmentGlyphRange lineGlyphRange: NSRange, containerOrigin: CGPoint) というメソッドがあります。目眩を覚える長さです。少しでも短くなるように努力すべきでしょうか。たとえば Gryph という単語が頻出するので、それを Gp などと略せば文字数を減らせそうです。
しかし、リーダブルコードによれば、それは否です。長い名前の入力自体は問題ではありません。IDEのコード補完に任せれば一文字のミスもなく入力できるからです。名前に読みづらいだけの省略形を使う意味はありません。避けましょう。
かといって、名前を冗長にしろということではありません。リーダブルコードは「不要な単語を投げ捨てろ」と断じています。
Swift の 2 から 3 にかけてのAPIの変化は、まさに、不要な単語を投げ捨てるものでした。
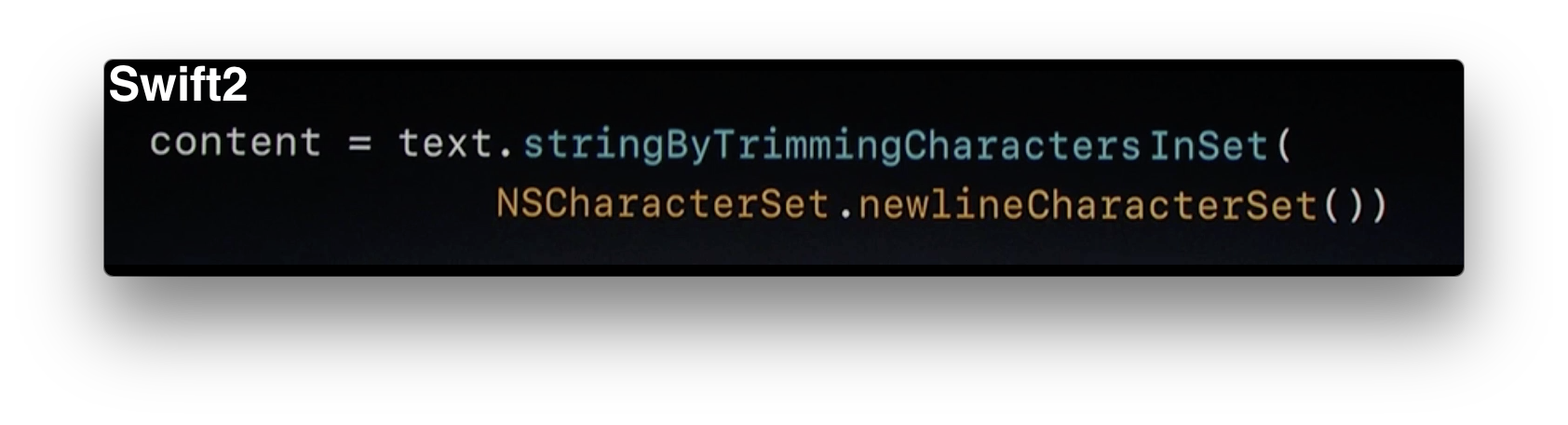

Swift2での長ったらしいメソッド名は、Swift3では、こんなふうに変わりました。劇的ですね。ラベルでの意味の補強も合わせて、とても書きやすいものになりました。見倣いましょう。
「名前に情報を詰め込む」⑥名前のフォーマットで情報を伝える
最後のテクニックは名前のフォーマットについてのものですが、Swiftではあまり使われないものですね。
「大文字始まりは型名、それ以外は小文字始まり」というざっくりしたルールがある程度です。ただ、「アンダースコア始まりのAPIはpublicなものではない」ということは覚えておくと良いことが時々ありそうです。
たとえば、 _kvcKeyPathString というAPIがあります。privateなものなので、publicにしてくれというバグレポが出ているのですが、これがpublicではないと気付けるのは名前のフォーマットのおかげですね。
「名前に情報を詰め込む」まとめ
以上が「名前に情報を詰め込む」でした。
- 明確な単語を選ぶ
- 汎用的な名前を避ける(あるいは、使う状況を選ぶ)
- 抽象的な名前よりも具体的な名前を使う
- 接尾辞や接頭辞を使って情報を追加する
- 名前の長さを決める
- 名前のフォーマットで情報を伝える
以上6つのテクニックで、適切なネーミングには大きく近づけました。
「リファクタリング」より
「リファクタリング」もいいこと言ってましたので、引用します。1
メソッド名には、内部でどのように処理をしているかでなく、そのコードが何をするのかという意図を示します。
置き換えによって、以前よりコードが長くなったとしても、意図が明確になっていれば良しとします。ここで重要なことは、メソッドの長さを切り詰めるのではなく、メソッド名と、その実装との距離を埋めることだからです。
たとえば、 User が格納されている配列から最初の3要素を取得する処理を、 firstThreeUsers とするのではなく usersForFirstView とする…というような感じでしょうか。
Swift の API design guideline に従う
また、Swiftを書くなら重要なのは、SwiftのAPI design guidelineに従うことです。
抜粋すると、
- 流暢な英文に見えるように
- 変数・引数・付属型のネーミングは、その制約よりも役割に応じて行う
- メソッド名の品詞を、副作用あるなしで変化させる
- 副作用なし: 名詞、動詞の過去分詞、現在分詞を使う
- e.g.
array.sorted
- e.g.
- 副作用あり: 動詞の命令形を使う。あるいは
formを頭につける- e.g.
array.sort/y.formUnion()
- e.g.
- 副作用なし: 名詞、動詞の過去分詞、現在分詞を使う
- 前例を採用しましょう
- etc...
他にも重要な記述ばかりですので、まずは全員原文を読みましょう。日本語じゃないと嫌!という人は、最近Qiitaに日本語訳も上がっていました。
Swift Foundation / Cocoaの流儀に従う
APIガイドラインに「前例を採用しましょう」とあったとおり、SwiftのFoundationやCocoaのAPI名になるべく近づけることも大事です。
プログラマの間では、Boolの命名についてよく議論になったりします。be動詞ではない場合にどうするか、たとえば exists にするか、文法的におかしくても isExist にするか、 is も省略するか、などの論争が起こりがちです。しかし他の言語ではともかく、Swiftであれば**「be動詞ならisつけましょう、一般動詞なら三人称単数現在にしましょう、あるいは can〜 、needs〜 などで始めましょう」**という一択です。
あるいは、delegateメソッドの名付けでは、よく委譲元の型名が省略されているコードを見かけます。しかし、Cocoaの流儀に則れば、委譲元が明示される命名規則に辿り着くことができます。
// ❌️
func willBlog(_ blog: Blog)
// ⭕️
func atendeeWillBlog(_ blog: Blog)
どういった名付けがスタンダードなんだっけ? と迷ったときのためには、Appleのリファレンスを簡単に検索できるようにしておくと便利です。自分はDashというドキュメント検索アプリを活用したり、ランチャーアプリのAlfredで https://developer.apple.com/search/?q={query}&type=Reference というクエリを即座に呼び出せるようにしています。
そもそも適切なネーミングができない例もある
以上、紹介したような手段でネーミングは完璧!と言いたいところですが、小手先のネーミングテクニックだけではしっくりこないことも多いです。
そんな例を2つほどご紹介します。
適切なネーミングができない例①非同期処理
まずは、先程リーダブルコードの説明のときに例に出したコードを見てみましょう。
class HogeListViewController : UIViewController {
...
func startFetchingHogesWithFailureAlert() {
fetchHoges(withID: textField.text!,
showsAlertIfFailed: true)
}
func startFetchingHogesWithoutFailureAlert() {
fetchHoges(withID: textField.text!,
showsAlertIfFailed: false)
}
func fetchHoges(withID id: String, showsAlertIfFailed: Bool) {
api.fetchHoges(withID: id) { [weak self] hoges in
self?.didReceive(
hoges: hoges,
showsAlertIfFailed: showsAlertIfFailed
)
}
}
...
}
小手先のネーミングで、最初よりはだいぶマシになりました。しかし、これ、正直言うと、違和感が残ります。どこかというと、これです。
func fetchHoges(withID id: String, showsAlertIfFailed: Bool) {
api.fetchHoges(withID: id) { [weak self] hoges in
self?.didReceive(
hoges: hoges,
showsAlertIfFailed: showsAlertIfFailed
)
}
}
fetchしてから、受け取ったデータを didReceive というメソッドに渡す。でも、この「受け取ったものをどうする」という情報が、fetchHoges というメソッド名だけではまったく伝わらないのです。引数に何かフラグはあるけど、失敗時に他にやってることは何なのか、成功時にはどうしてるのか、何も分からない。
どうネーミングを頑張っても、この違和感は解決できません。何故こんなしっくりしない現象が起きてしまうのか。それは、構造化プログラミングの大原則に起因します。
構造化プログラミングでは、原則として、メソッドは 入口(引数) と 出口(戻り値) を持ちます。しかし非同期処理を愚直に書くと、戻り値には反映されない処理が、メソッドに混ざってしまう。そうすると必然的に、メソッド名と処理内容は乖離してしまいます。
非同期処理は、根本的にそういう問題を孕んでいるのです。
ではどうするか。
非同期処理の結果を、なんらかの手段を使って引数か戻り値で受けるようにしてしまえばいいのです。そのために使えるのが、 コールバックやPromiseパターンといったデザインパターンです。
// 🤔
func fetchHoges(withID id: String, showsAlertIfFailed: Bool)
// 👍callback
func fetchHoges(withID id: String, completion: ([Hoge] -> Void))
// 💯promise
func fetchHoges(withID id: String) -> RxSwift.Single<[Hoge]>
fetchHoges メソッドではHogesをfetchする以外のことは行わない。fetchの結果は、メソッドの外でハンドリングするようにしましょう。コールバックなら completion というクロージャを引数に含める。Promiseパターンなら、結果の取得を監視するための型を、戻り値で受け取る。
これで、ネーミングと処理内容が一致しました。
ちなみに引数を使ったコールバックよりも、戻り値を使ったPromiseパターンのほうが優れています。なぜなら、コールバック関数は呼び忘れるリスクがありますが、戻り値は絶対に返ってくることがコンパイラレベルで保証されるからです。
適切なネーミングができない例②引数の表現力が弱い
以下のメソッドを見てください。
func postProfileWith(name: String?,
address: String?,
tel: String?,
profileImage: UIImage?,
profileImageURL: URL?)
-> RxSwift.Single<Bool>
おそらくプロフィール情報をAPIにPOSTするメソッドなのでしょう。
短くて意図が明確、シンプルで分かりやすい…と思われたでしょうか。
本当に、そうでしょうか?
メソッド基部だけ見れば、シンプルです。しかし、引数まで注目してみると…よくわからないことだらけです。
- Optionalばかりだけど、必須パラメータは何なのか
- tel ☎️ はどういうフォーマットで文字列化すればいいのか
- 何故
profileImageとprofileImageURLが両方あるのか。どちらも渡したら、あるいはどちらも渡さなかったらどうなるのか。
そう、このメソッドは、引数の表現力が弱すぎるのです。
お分かりでしょうか。引数もネーミングの内です(もちろん戻り値も)。メソッドをよりよく名付けるためには、基部だけではなく、引数の表現力を高める必要があります。
以下のようにすると、どうでしょうか。
func postProfileWith(textData: ProfileTextData?,
imageData: ProfileImageData)
-> RxSwift.Single<Bool>
大量にあった引数を、ふたつの独自型、 ProfileTextData , ProfileImageData という型を作って整理しました。
ProfileImageData のほうはOptionalすらなくなっていますね。
型の定義を見てみると、
struct ProfileTextData {
let name: String
let address: String
let tel: Tel?
}
enum ProfileImageData {
case image(UIImage)
case url(URL)
}
ProfileTextData はテキストで表されるプロフィールのデータの組のようです。structで包むことで、必要なデータが揃っていること、つまり要素のAND条件を型として表現できました。
また、 ProfileImageData のほうはenumで包まれています。UIImageか、URLか。いずれかの要素があればいいということ、つまり要素のOR条件を、型として表現できました。
型の定義を理解すると、メソッドの意図が明確に伝わるようになりました。 postProfile メソッドに渡す引数は2つ。
ProfileTextData はname,address,telを揃えて渡すか、完全にスルーする。 ProfileImageData は、UIImageかURLの、いずれかを引数にする。なるほど、明確ですね!
リファクタリング
適切な名前を考える ⊃ 設計の見直し
非同期通信の例、postProfileの例。
ふたつの例をご紹介しましたとおり、適切な名前を考えるためには、ときには設計を見直すことも必要です。つまり、ネーミングの改善に必要なのは、リファクタリングです。
しっかりした名前をつけようとすると長くなるとか、うまく名付けられないとかで、不正確に要約してしまいたくなることが時々あります。しかし、それは現実から目を背け、設計の問題を隠蔽しているだけです。
やってることが複雑すぎて一言で言い表せないメソッドがあった場合、それは設計の黄信号。リファクタリングが必要だというサインなのです。
ではここからは、本「新装版 リファクタリング―既存のコードを安全に改善する―」を引用しつつ、よりよいネーミングに向かうためのテクニックをご紹介します。
「引数を型にまとめる」
種明かしすると、実は先程話した、引数をまとめた型を作るテクニックも、「リファクタリング」に紹介されているテクニックのひとつです。
「メソッドオブジェクト」
また、メソッドオブジェクトというアプローチもあります。端的に言うと、以下のようなテクニックです。
- メソッド自身 → 名詞化して型(オブジェクト) に
- 全てのローカル変数 → 型のプロパティ に
- メソッド → 型内のメソッド群 に
先程の事例だった postProfile というメソッドを、メソッドオブジェクト化してみましょう。
class ProfilePoster {
let textData: ProfileTextData?
let imageData: ProfileImageData
func run() -> RxSwift.Single<Bool>
private func ...
}
「リファクタリング」ではメソッド名を compute としろと言っていましたが、そこは別に好きにすりゃいいんじゃないかと思います。
「特性の横恋慕」
「リファクタリング」P80に、次のような記述があります。
オブジェクト指向には、処理および処理に必要なデータを1つにまとめてしまうという重要な考え方があります。あるメソッドが、自分のクラスよりも他のクラスに興味を持つような場合には、古典的な誤りを犯しています。特に属性については注意しなければなりません。
以下のコードを見てください。
// ❌️
class ProfilePoster {
...
private func isTelValid(tel: String) -> Bool {
return (try! NSRegularExpression(pattern: "^[0-9]+-[0-9]+-[0-9]+$"))
.firstMatch(in: tel,
range: NSRange(location: 0, length: (tel as NSString).length)) != nil
}
}
メソッドオブジェクト ProfilePoster を実行する間、いくつか処理が呼ばれているとします。そのうちのひとつが、電話番号のバリデーションを行うプライベートメソッド、 isTelValid(tel:) です。しかし、このメソッドは、ProfileをPostすること自体には興味がありません。興味があるのは、電話番号それ自身。
これが横恋慕状態です。
解決するためには、新しい型、電話番号に興味を持つ型を用意する必要があります。
// ⭕️
extension NSRange {
static func wholeRange(for string: String) -> NSRange {
return NSRange(location: 0, length: (string as NSString).length)
}
}
extension String {
func matches(pattern: String) throws -> Bool {
return try NSRegularExpression(pattern: pattern)
.firstMatch(in: self, range: .wholeRange(for: self)) != nil
}
}
struct Tel {
let value: String
var isValid: Bool {
return try! value.matches(pattern: "^[0-9]+-[0-9]+-[0-9]+$")
}
}
横恋慕が収まりました。それだけでなく、ネーミングの点でも良いことをもたらすのがおわかりでしょうか。
// 🤔before🤔
ProfilePoster.isTelValid(tel: String) -> Bool
// 🎉after🎉
Tel.isValid: Bool
元々のメソッド名が長ったらしかったのに対し、移動した後のcomputed varはシンプルで明瞭です。
主語となる型に処理を託すことで、処理対象を型自身が説明してくれる上に、対象がselfとなるぶん、渡さなければいけなかった引数も消えます。良いことづくめですね。
少し脱線: Tel.isValid: Bool よりも良い設計
話の流れ上、 isValid: Bool というcomputed varを生やしましたが、そもそも不正なTel型を作れないようにするほうがよいです。型をinitするタイミングで同時にバリデートするのです。つまりこういうことです。
struct Tel {
enum Error: Swift.Error {
case invalidFormat
}
let value: String
init(value: String) throws {
guard try value.matches(pattern: "^[0-9]+-[0-9]+-[0-9]+$") else {
throw Error.invalidFormat
}
self.value = value
}
}
余談でした。
まとめ
お気づきでしょうか。
引数を型にまとめるテクニックも、メソッドオブジェクトも、特性の横恋慕の解決も、要は**「適切な型を作る」という話でした。
型を用意することで、豊かに、かつ端的に意図を表現できるようになるのです。型ってすごい!
考えてみれば当たり前で、オブジェクト指向で書く限り、メソッドもプロパティも何らかの型のメンバです。
つまりネーミングの際には、メソッドであれば「何をする」、プロパティであれば「何である」という情報に意識が向きがちです。しかし、それだけでなく「誰がそれをする」「誰のものである」**という部分に目を向けることで、よりよいネーミングに近づけるのではないでしょうか。
一言で言えば、**「よりよいネーミングのためには、ちゃんとオブジェクト指向しようね」**という話でした。
Happy Naming!😃 皆さんのコードが、よきネーミングとともにありますように。
おまけ: より豊かなネーミングのために
ここからは、15分の発表枠では入らなかったよしなしごとをいくつか。
returns Optional vs throws
先程の余談では、throwsなinitが登場しました。
struct Tel {
enum Error: Swift.Error {
case invalidFormat
}
let value: String 👇
init(value: String) throws {
guard try value.matches(pattern: "^[0-9]+-[0-9]+-[0-9]+$") else {
throw Error.invalidFormat
}
self.value = value
}
}
しかし、Failable Initializerを使う( init?(value: String) )という手もあります。
これらの利点・弱点を比較してみます。
- returns Optional
- 👍 お手軽簡単に扱える
- 👿 付加情報が乏しい
- 例外処理(throws)
- 👍「失敗しうる」ことを明確に表せる
- 👍
try?構文でOptionalに変換可能 - 👍
Errorを定義して細やかに失敗原因を伝えられる - 👿
Errorを定義する必要がある
どちらも一長一短ではあります。
しかし、ネーミングとは意図を表現するものであり、より豊かに意図を表現できるのはどちらかと考えると、自分はthrowsを積極的に使っていきたいです。
もちろんそこまでの表現力を求めていない場合もあるでしょうから、そこではOptionalも充分な選択肢に入ります。この判断基準をもっと掘り下げたい方は、Swiftのエラー4分類が素晴らしすぎるのでみんなに知ってほしい - Qiitaの「simple domain error」「recoverble error」について読むとヒントが得られるのではと思います。
言語機能を駆使しよう
自然言語も同じですが、細かい意図を表現するには、語彙を増やすことが欠かせません。プログラミング言語では、言語機能をどれだけ駆使できるかが、豊かな語彙に繋がります。前項の throws / optional の話もそうですね。他には、ネーミングに活用できるSwiftの言語機能には以下のようなものがあります。
- 自分自身の型を返すstatic func
- operator
- 記号による処理を定義する
- 前置・中置・後置
- subscript
- e.g.
reversiBoard[x: 10, y: 8] - 複数の引数、ラベル付与も可能
- e.g.
コマンド・クエリ分離原則(CQS)
非同期処理の話では、引数や戻り値に結果を含めるデザインパターンを紹介しました。しかし、すべての処理結果を入力と出力で明示できるわけではありません。つまり、処理は副作用があるよね? ということです。
その現実と戦うためのテクニックで、「コマンド・クエリ分離原則(CQS)」というものがあります。
- コマンド(戻り値なし、副作用を起こす)
- クエリ(戻り値を期待、何度呼んでも同じ結果(冪等))
を分けると設計とネーミングがすっきりします。
var canFetch: Bool // クエリ
func startFetching(id: Int) -> Void // コマンド
let hoges: Rx.Observable<[Hoge]> // 結果は通知される
以上です。
-
「新装版 リファクタリング 既存のコードを安全に改善する」2014年 P77 ↩