『現場で役立つシステム設計の原則』という本を付箋を付けながら一通り読んだ?ので
個人的に面白かったところを自分用にメモしておきます。
本当にメモです。
本質とはだいぶ違うところだと思うので買って読んで下さい。。
(付箋はつけていたけどうまく説明できなさそうなところは消しました。)
目的ごとに変数を用意する
段落わけと、目的ごとの変数で分かりやすい。
一度作った変数を変更するのを破壊的代入といい、それをなくすことでコードが安定するそうです。
int basePrice = quantity * unitPrice
int shippingCost = 0
if (basePrice < 3000) {
shippingCost = 500
}
int itemPrice = ...
コレクション型を扱うロジックを専用クラスに閉じ込める
これをコレクションオブジェクトやファーストクラスコレクションというらしい。
リストを使う側が簡単になるようにロジックを提供する。
外にリストを渡すときはCollections.unmodifiableList(customers)などをして、変更を不可にして返す。
「顧客の一覧」などは業務の関心事そのものであったりするので、変更するときに場所が分かりやすくなったりするようです。
class Customers {
List<Customer> customers;
Customers importantCustomers() { ... }
}
状態の遷移ルールをわかりやすく記述する
状態の遷移を関心事として管理する方法のようです。
Stateはenumで宣言しておいて、以下のようなクラスを用意して、状態の遷移が出来るかどうかを判定することで、ifやswitch文などがいらずに状態を管理できるようです。
class StateTransitions {
Map<State, Set<State>> allowed;
{
// Mapの初期化
}
boolean canTransit(State from, State to) { ...}
}
データとロジックを分けることがわかりにくさを生む
プレゼンテーション層/アプリケーション層/データ層という3層アーキテクチャを採用していても
データとロジックが別れていると、
同じ業務ロジックがあちこちに書いてある状態になり、
それにより変更が手間になったり、大量のテストが必要になる。
このデータというのはデータだけが入っているEntityクラスなどがそう。
またそれに対して、UtilクラスやCommonクラスで対処を行う方法があります。
それでも、コードの共通化は実現できません。
- 汎用ロジックを書く: ニーズが微妙に異なったりして、関係ない引数への理解が必要になったりして、適切な使い方を理解するのが大変になる。そうすると誰も使わなくなって、同じようなロジックがあちこちに書かれる
- 用途ごとに細分化した共通関数: メソッドがたくさんになって、微妙な違いを理解して使い分けるのが大変で、結局使われず、同じロジックが使われだしてしまう。
そこでデータとロジックを一つにして整理するのが良いと書いてありました。
メソッドは必ずインスタンス変数を使う
以下のようなメソッドはどこに何が書いてあるのかがわかりにくくなるため、データの近くにメソッドを書くことを徹底する方が良いそうです。つまりデータを持つクラスへ移動することになります。
悪い例
bigDecimal total(BigDecimal unitPrice, BigDecimal quantity) {
...
return ...
}
三層 + ドメインモデルで関心事を分かりやすく分離する
できるだけ業務的な判断、加工、計算のロジックはドメインモデルで行い、それぞれの層は簡潔で分かりやすく記述する。
なぜならそれぞれの層に書いてしまうとロジックが重複して、変更が難しくなるため。
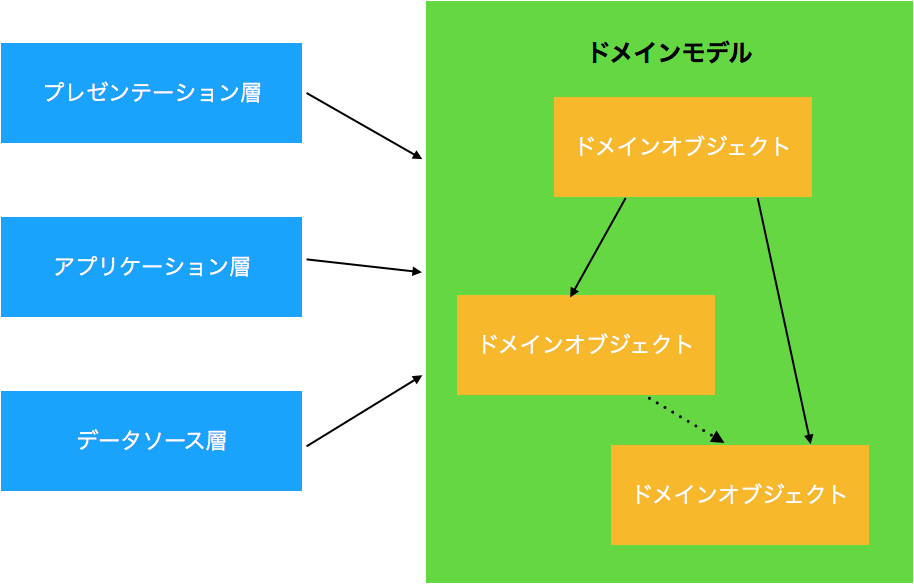
利用する側と提供する側の合意を明確にする
利用する側と約束を取り決め設計をシンプルにする設計を契約による設計と呼ぶそうです。
以下では異常な事態を例外で通知するようになっています。
if(!canWithDraw()){
throw new IllegalStateException("残高不足")
}
draw()
対象的に防御的プログラミングがあり、利用する側は何をするかわからないという前提でさまざまな防御ロジックを書きます。これは無意味にコードを複雑にして読みにくくします。また結局想定外の使われ方がされてしまう場合があり、また利用する側によって例外のときに行いたい処理が異なったりするので、よくないです。
カラムの追加はテーブルを追加する
今まで保存していたデータにnullか仮のデータを入れる必要があるため、カラムを追加するときはテーブルを追加して、外部キーを使う感じにするようです。普通に既存のテーブルに追加するとデータの整合性と信頼性を劣化させ、プログラムを不要に複雑にするから、だそうです。
(これほんと?って感じでした。デフォルトの設定値があるものとかであればいいのかな、、?)
オブジェクトはオブジェクトらしく、テーブルはテーブルらしく
お互いの設計変更の影響をマッピング定義に局所化出来るため、テーブルとオブジェクトは明示的に定義できるものを利用する。
マッピングの情報をアノテーションで埋め込んだりするのは設計を歪め、コードの見通しを悪くするそうです。
著者がおすすめしているMyBatis SQL Mapperというマッピングするフレームワークであれば独立性を保ちながら、マッピングできるそうです。
(そうはいってもたいへん、、)
画面でのドメインオブジェクトの利用方法(画面もドメインオブジェクトも利用者の関心事のかたまり)
どのように画面にデータを表示するのか、という話でした。
ドメインオブジェクトをそのまま利用するか、画面用のオブジェクトを用意する。という感じでした。
Web APIとの計算ロジックの置き場所
Web APIでの日付などは基本的には表示する導出結果にしたほうが間違いが少なく、変更にも強い設計になるそうです。
感想?
レイヤードアーキテクチャで確かにロジックの重複に悩まされたことがあるので、そこらへんはとてもよかったです。
良くあるデータだけのentityパッケージをdomainって名前にして、データだけがあるentityにメソッド生やしてロジックをそちらに寄せれば、多少は簡単にロジックの重複が減らせそうでした。もちろん作り直せたほうが良いですが(この内容をツイートしたら著者の方にリツイートしてもらえました。)
あとかなり分かりやすく読みやすかったです。
あとはなんのフレームワークでもいいのでサンプルリポジトリが欲しかったです。