やりたいこと
- はてなブックマークで、Python記事を検索しトレンドを分析
- はてなブックマークにSeleniumでログイン
- ブックマーク数をスクレイピング
- 時系列比較を行う
- バズるタイトルを分析
実装方法
- 詳しくは下記記事を参考にしてください。Pandasを利用したデータ分析まで載せています。
【Python】スクレイピング→データ収集→整形→分析までの流れを初心者向けにまとめておく ~Pythonに関するはてな記事を10年分スクレイピングし、Pythonトレンド分析を実際にやってみた~
実装
trendAnalytics.py
from selenium import webdriver
from pandas import *
import time
# Access to page
browser = webdriver.PhantomJS() # DO NOT FORGET to set path
url = "http://b.hatena.ne.jp/search/text?safe=on&q=Python&users=50"
browser.get(url)
df = pandas.read_csv('trend.csv', index_col=0)
# Insert title,date,bookmarks into CSV file
page = 1 #This number shows the number of current page later
while True: #continue until getting the last page
if len(browser.find_elements_by_css_selector(".pager-next")) > 0:
print("######################page: {} ########################".format(page))
print("Starting to get posts...")
#get all posts in a page
posts = browser.find_elements_by_css_selector(".search-result")
for post in posts:
title = post.find_element_by_css_selector("h3").text
date = post.find_element_by_css_selector(".created").text
bookmarks = post.find_element_by_css_selector(".users span").text
se = pandas.Series([title, date, bookmarks],['title','date','bookmarks'])
df = df.append(se, ignore_index=True)
print(df)
#after getting all posts in a page, click pager next and then get next all posts again
btn = browser.find_element_by_css_selector("a.pager-next").get_attribute("href")
print("next url:{}".format(btn))
browser.get(btn)
page+=1
browser.implicitly_wait(10)
print("Moving to next page......")
time.sleep(10)
else: #if no pager exist, stop.
print("no pager exist anymore")
break
df.to_csv("trend1.csv")
print("DONE")
結果
- こんな感じでスクレイピングした結果が表示されます。
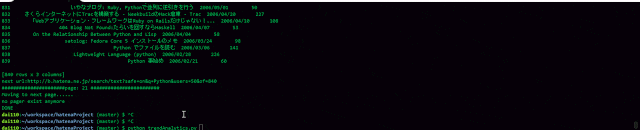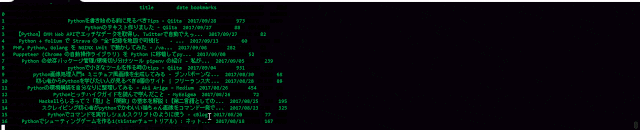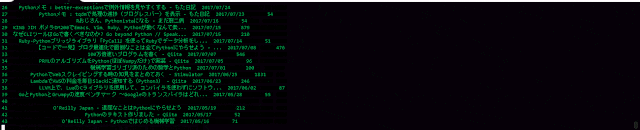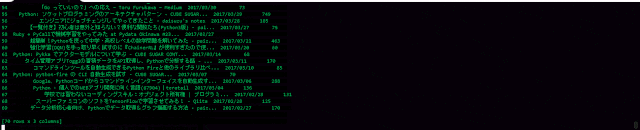
- Jupiter Notebookを利用して、こんな感じで分析しました.2017年度の結果
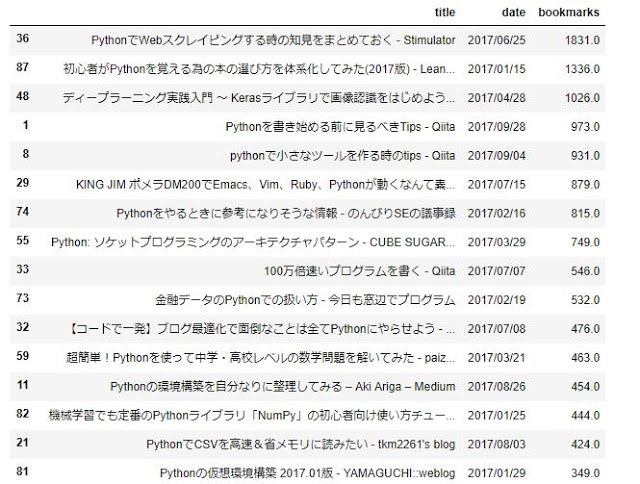
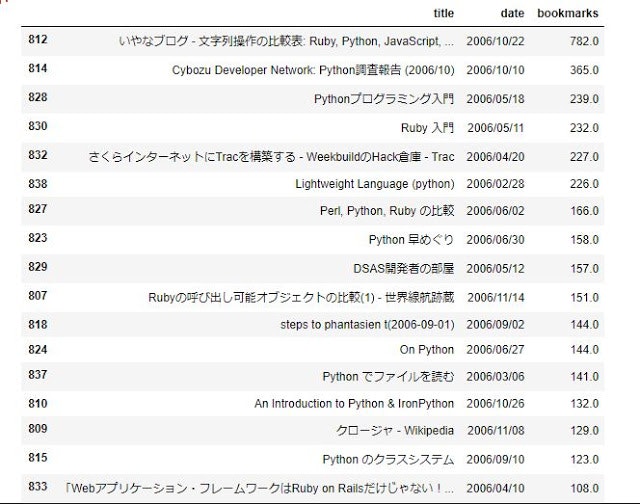
- こちらが2006年度の結果。明らかに使われ方が違いますね
参考
【Python】スクレイピング→データ収集→整形→分析までの流れを初心者向けにまとめておく ~Pythonに関するはてな記事を10年分スクレイピングし、Pythonトレンド分析を実際にやってみた~