TL;DR;
- Amazon AuroraはIn-Memory DBでもなくDisk-Oriented DBでもなく、In-KVS DBとでも呼ぶべき新地平に立っている。
- その斬新さたるやマスターのメインメモリはキャッシュでありながらWrite-BackでもなくWrite-Throughでもないという驚天動地。
- ついでに従来のチェックポイント処理も不要になったのでスループットも向上した。
- 詳細が気になる人はこの記事をチェキ!
Amazon Aurora
Amazon AuroraはAWSの中で利用可能なマネージド(=運用をAWSが面倒見てくれる)なデータベースサービス。
ユーザーからはただのMySQL、もしくはPostgreSQLとして扱う事ができるのでそれらに依存する既存のアプリケーション資産をそのまま利用する事ができて、落ちたら再起動したりセキュリティパッチをダウンタイムなしで(!?)適用したりなどなどセールストークを挙げだすとキリがないけど、僕はAWSからお金を貰っているわけではないのでそこは控えめにしてAuroraでのトランザクションの永続性について論文から分かる範囲と想像で補った内容を説明していく。
Auroraのアーキテクチャ
AWSの公式資料を取ってこればいくらでもそれっぽい図はあるが、説明に合わせて必要な部分だけ切りだした。
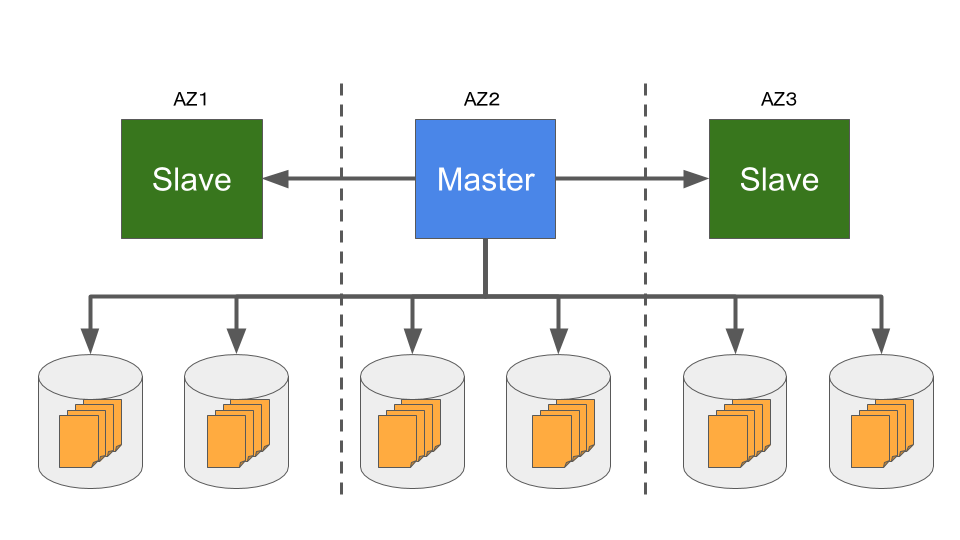
AZとはAvailability Zoneの事で、AWSのデータセンターで障害が発生した場合に別の故障単位になるよう設計されているユニットの事である。物理的には部屋が分かれているのか建物が分かれているのかわからないが、電源やスイッチは確実に系統が分かれておりミドルウェアのバージョンアップなども分かれているという。それをまたがる形でMasterが一つとSlaveが複数(最大15台)立ち上がる。MasterはDBに対する読み書き両方ができるが、Slaveは読み出ししかできない。典型的なWebサービスは読み出しが負荷の多くを占めるので読み出し可能な複製が複数用意できるのは理に適っている。
このそれぞれのコンポーネントを繋ぐ矢印はRedo-Logを表している。Redo-Logとは「特定のページを書き換える操作とその内容」が記述されたDBログの最小単位である。一般にDBを複製すると言うと読み書きされるあらゆるデータが複製されるものであるがAuroraではこのRedo-Logしか複製しない点が面白い。論文中に THE LOG IS THE DATABASE とでっかく書いてあるのは恐らくこの辺に由来する。
Masterは普通のMySQL(もしくはPostgreSQL)サーバのように見えユーザから読み書きがリクエストできる。
InnoDBの代わりのバックエンドのデータストアとして分散KVSが稼働しており、その分散KVSはAZを跨った6多重に冗長化されている。論文中ではKVSだなんて一言も書いていないがストレージバックエンドの説明として理解しやすいのであえてKVSに喩えて説明していく。
6多重のうち4つにまで保存できた段階で永続化完了と見なしユーザに返答する事でレイテンシの短縮を図っている。システムはいろんなノイズで遅れるが、全体の足を引っ張って律速するは決まってstrugglerであり、90パーセンタイルぐらいであれば圧倒的に機敏に返事を返してくるのは巨大システムの常である。
全部の複製が全く同じ情報を持っていないといけないので、仮にログを取りこぼした複製がいたとしてもMasterに聞き直さず複製同士でGossip通信を行って全部のログを全員が受け取るように取り計らう。
この辺の話はAWSの人の公式スライドにも腐るほど出てくるので僕は詳しく説明しない。
トランザクションの挙動の違い
どれかのDBにとって極端に都合が良いワークロードで比較しても単なるセールストークにしかならない。
複数の方式のDBが明白に異なる挙動をする典型例のワークロードとして「巨大テーブルの全部の行の特定のフラグを立てる」というトランザクションを例に挙げて伝統的なDisk-Oriented DB・In-Memory DB・Auroraの動作を順に説明する。
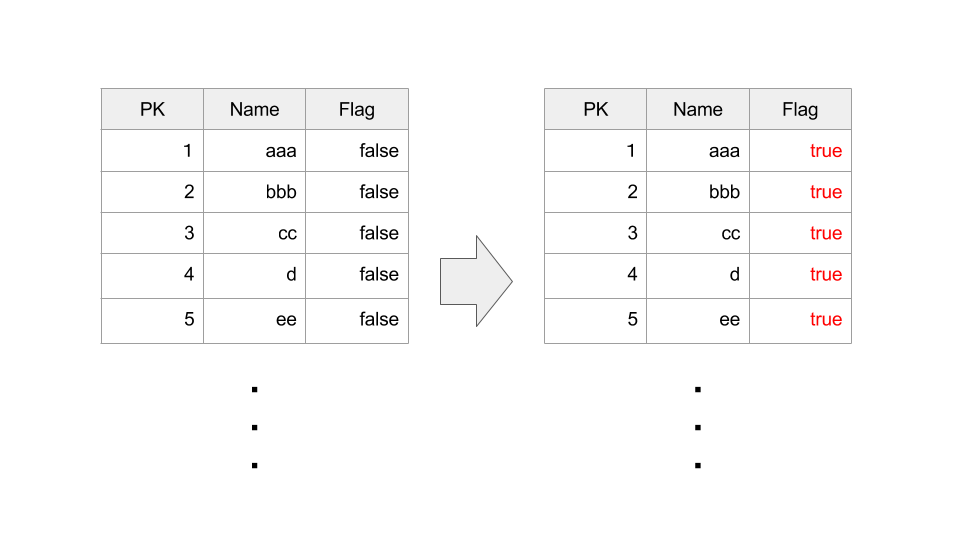
SQL文としてはこんな感じである。
UPDATE table1 SET flag = true;
なおこのtable1はものすごく行数が多い(=縦に長い)とする。
Disk-Oriented DBの挙動
まず巨大テーブル全体を一気にメモリに置くアーキテクチャにはなっておらず、メモリ上に用意したデータベースページ領域にDisk上のDBの一部を複製してくる所から始まる。ここまではMySQLでもPostgreSQLでも同じはず。この文脈でのページとはDBの中身の一部が(MySQLならデフォルトで)16KBの大きさ毎に詰め込まれた連続したメモリ領域であり、OSが提供するメモリぺージとは少し違う。(ちなみにPostgreSQLのデフォルトページサイズは8KB)
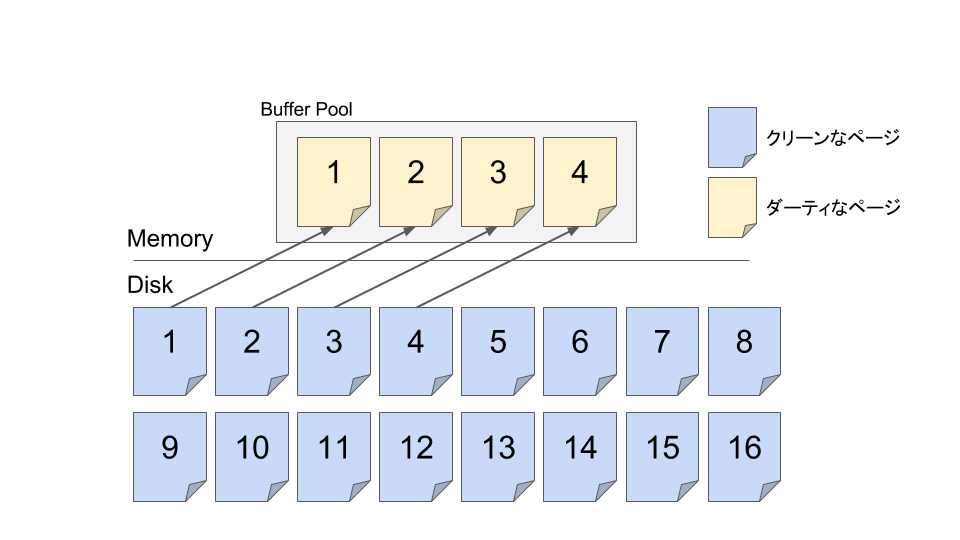
Disk上の全域データを直接一瞬で書き換えることは当然できないので、狭いメモリ空間でLRU等を用いて取り回しながら書き込みの終わった未コミットなダーティページをディスクに書き戻しながら進行する他ない1。だがそんなことをすると、その瞬間にDBのプロセスが強制終了してリスタートした時に未コミットなダーティページがディスク上から読み出し可能な状態で観測される恐れがある。それではACIDのうちAに違反してしまう。そこで各DBは僕の知る限り以下の挙動をとる。
ARIES
進行しながらRedo-Undo logをディスクに永続化し、もし途中でシステムがリスタートした時はリカバリとしてUndo処理を行う。
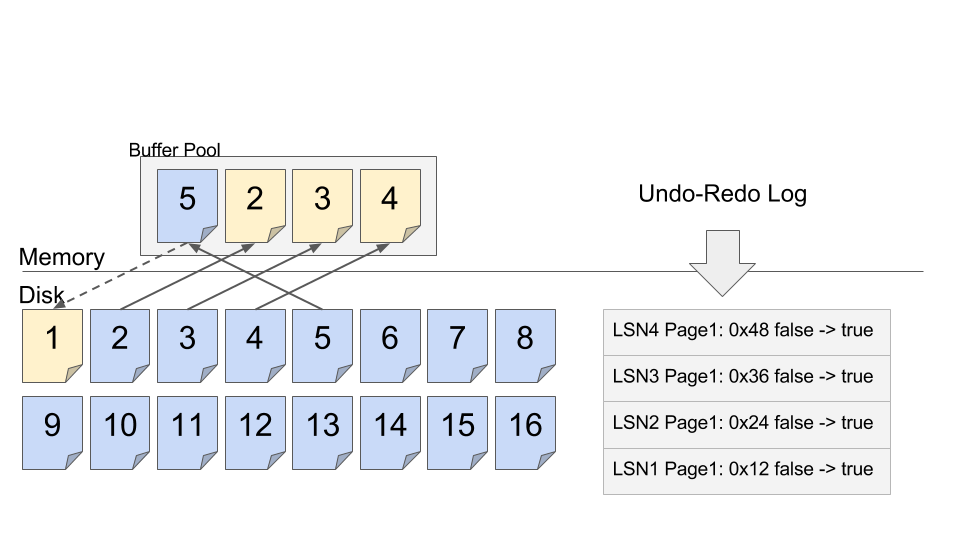
この図で言うとページ1は未コミットなトランザクションによって既に書き換えられているが、Undo-Redo Logの形で既にWALを永続化しているのでリカバリ可能でありダーティなページはそのままディスクに永続化して構わない。なので永続化して空けたBuffer Poolのスペースに次に更新したいページ5をフェッチしてくる事ができる。
PostgreSQL
上書きは常に新たなバージョンでの追記操作であり、clogというデータで保存されているトランザクションステータスが commited でない限り読み出しできない。したがって痕跡は物理的にページに残るがデータベースのユーザからは不可視であり問題にならず、いずれバキュームされて物理的にも消失する。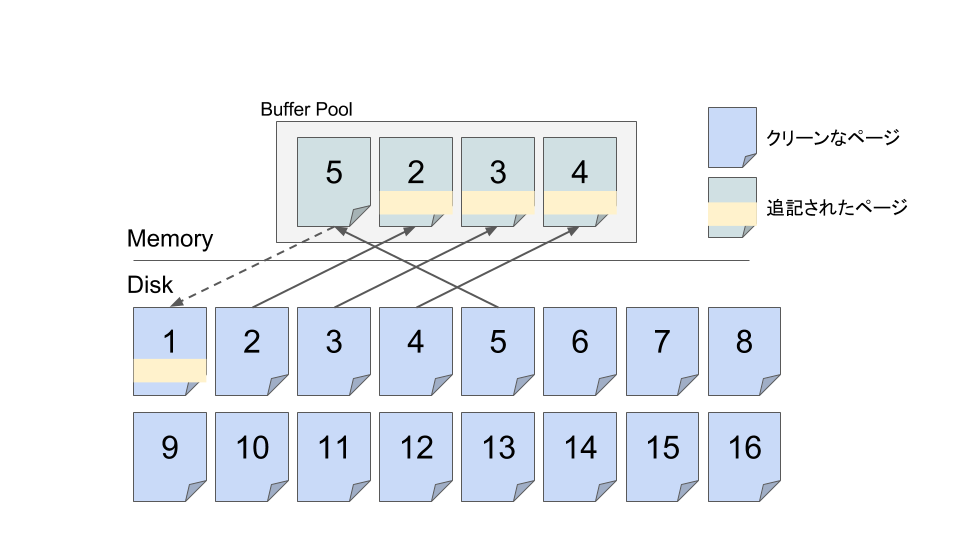
この図でいうと、ページ1は物理的にはダーティだが追記がされているだけでありclogのお陰で論理的に他のトランザクションから見えない。なのでそのままディスクに永続化されても問題が発生しないのでこうしてバッファプールからそのままページ1を追い出して、空いた領域にページ5をフェッチしてくる事ができる。
MySQL
ibdataの中に更新前の値が保存されており、ディスクに書き戻される際にはそちらも永続化されるので、リスタート時のリカバリ処理でibdataとテーブルデータを突き合わせて可視なデータがユーザから見えるように整合性を保つ(詳しくないが多分)。
いずれにせよ、トランザクションが走りながらログを記述していく事は共通している。
In-Memory DBの挙動
全部のデータがメモリに収まる前提を置いて良いのでこちらはだいぶシンプルに収まる。
進行途中でログを書き出す必要は無いし、バッファの中でLRU等を用いてどのページをディスクに書き戻すかなども心配しなくてよい。
トランザクションログを書き出すタイミングは典型的な実装としてはコミット時に一気に書き出す事が多いようだ。
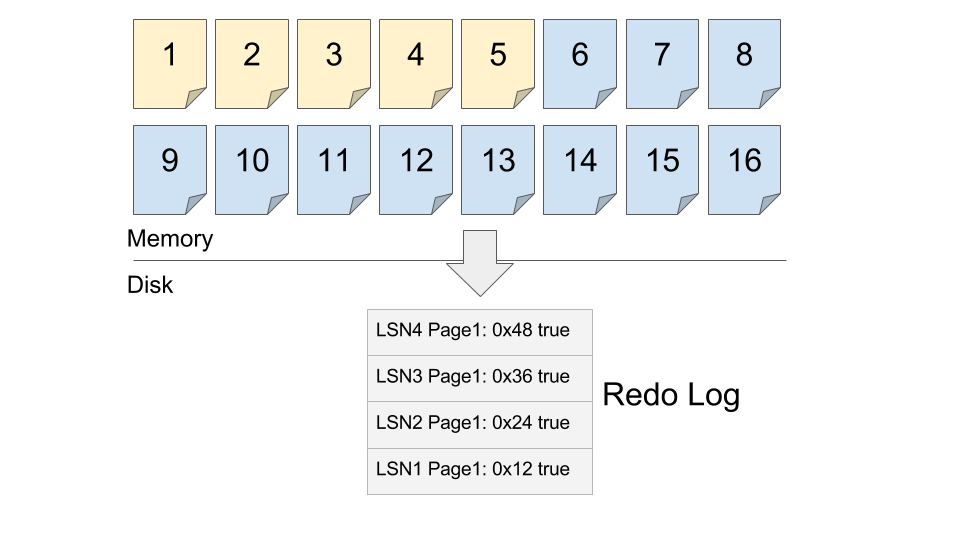
リスタート時はログデータをスキャンしてデータベースを再構築するので、ユーザから commit が命じられていないトランザクションはログにすら残っておらず、ダーティページはそもそも概念が存在しない。
Auroraの挙動
メモリにもローカルのディスクにもテーブル全体が入りきらない前提で設計されている。
トランザクションの都合上必要なページがMasterのメモリで運良くキャッシュできていない場合、KVSに問い合わせを行いページを持ってくる。
なお、KVSは物理的には6多重で保存しているが論理的には一つのデータが6重に保存されているだけなので論理的には1つのストレージ領域と考えて良い(RAID1を論理的には単一のHDD扱いするのと同様)のでそう書く。
走りながら当然ログも永続化していく。6多重で保存されるのはログも同じだ。前述したように驚くべき事にRedo-logしか保存していかない。
当然Masterのメモリには全データ乗らないので、どうにかして処理用にメモリを取り回す必要がある。
そこでMasterは一番使わないと判断したページをKVSに書き戻…さずに捨てる。 もう一度言う、捨てるのだ、キャッシュなのに。
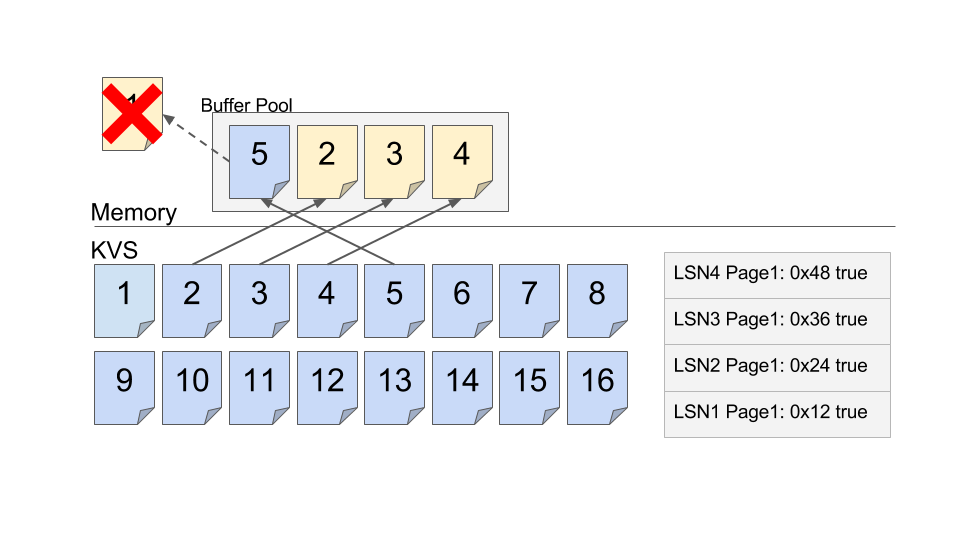
そんなことをしたらKVSに載ったページは古いままじゃないかと心配になるが、Auroraの分散KVSは単なるストレージではなくてAurora用の専用のロジックが駆動するインテリジェントな分散KVSである。
こいつらはMasterから受け取ったRedo-Logを必要に応じて手元のページに適用(Apply)していく事ができる2。
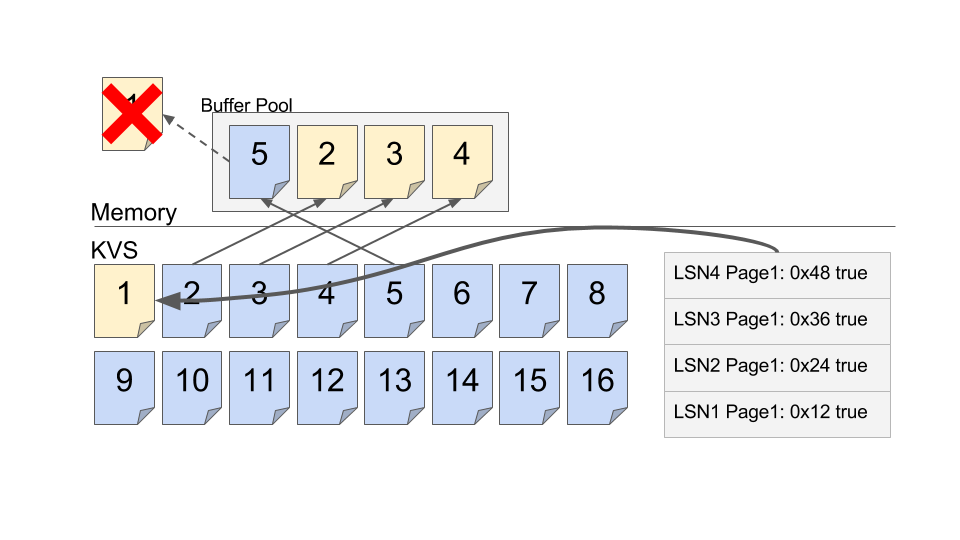
なんでせっかく作った更新済みPage1を捨ててまで新たにKVS側でログを適用し直すかというと、基本的にAWSにおいてMasterのCPUやネットワーク資源は限られたリソースである一方、KVS側のCPUは相対的に持て余したリソースであり安いこと。さらには後に述べるチェックポイントの簡潔さのために完全に分散KVS側に倒した設計を行っているように見える。
MasterからKVSへはRedo-logしか流れないし、KVSからMasterへはページしか流れない。圧倒的にシステムが簡単になった。
Masterがページを問い合わせる場合、バージョン番号もセットで問い合わせるのでそこまでに投げつけたRedo-logをKVS側で適用した最新ホカホカのページが返ってくるのでMasterは手元のメモリに乗っているダーティなページを気兼ねなく任意のタイミングで捨てて構わない。問い合わせの際はトランザクションの識別子を入れて引いてくるので、読んではいけないDirtyなページを獲得することはない。Slaveがページを問い合わせる場合は必ず永続化されたバージョンのものだけを読むようにしている。
ついでに言うとSlaveのページはMasterが6多重な分散KVSの他にSlaveにもRedo-logを投げつける。それを受け取るたびに(恐らくKVSと同じようなロジックで)ログ適用を行い、最新のコミット済みデータが読めるようになっている。ここで気づいた人もいると思うが、MasterはSlaveにログを共有するがその完了を待つとは一言も書いていない。4/6のKVS永続化が完了した時点でユーザにコミットを報告してしまう。なのでMaster側で更新を確認したデータがSlave側で読めるようになるには若干のタイムラグが発生する可能性がある。いわゆるSequential Consistencyである。ミリ秒オーダーなのでHTTPなWebサービスの文脈で大問題になるケースは稀だが覚えておいた方がいいかも知れない。
チェックポイントの挙動の違い
Auroraはシステム全体で見ると、Masterがせっかく更新したページをそのまま複製せずにKVSがログリプレイして再構築する分CPUクロックは無駄になっている。しかし、Masterはページを書き戻す必要が無くなり、更に言うとMasterがチェックポイント処理をする必要もなくなった。なぜならチェックポイント処理は分散KVS側で継続的にページ単位で実施されているからだ。なんだこれは。In-MemoryDBでもDisk-Oriented DBとも違うチェックポイントアーキテクチャだ。それぞれのチェックポイント戦略をここに列挙する。
- ARIES:
Checkpoint-BeginをWALに書いてからその瞬間のDirty Page TableとTransaction Tableを保存して、リスタート時のRedo-Log適用開始ポイントを算出可能にする。 - MySQL: ダーティなページをディスクに書き出す。ページの境界とブロックストレージのページ境界が一致しない事のほうが普通なのでチェックポイント中に電源が落ちたらページの一部が中途半端に永続化されてしまう。そこで二度書く事によってアトミック性を達成する(
Double Writeと呼ぶ)。 - PostgreSQL: ダーティなページをディスクに書き出す。ページの境界とブロックストレージのページ境界が一致しない事のほうが普通なのでチェックポイント中に電源が落ちたらページの一部が中途半端に永続化されてしまう。そこでそのチェックポイント後に最初にそのページに触るWALの中にページ(デフォルトで8KB)を丸っと埋め込んで完全性を保障する(
Full Page Writeと呼ぶ)。 - In-Memory DB: どこかのタイミングでメモリの内容をモリッとディスクに書き出してリスタート時に整合性を直すSiloRとか、ログを並列スキャンして完全なイメージを生成するFOEDUSとか戦略はまだ多岐に渡っている。
- Aurora: バックエンドのAuroraストレージが自動でログを適用していく。ページごとにログバッファが付いてて、バッファの長さがしきい値を超えるたびにページへのログ適用が実施される。ログは未コミットのトランザクションの進行中のログも含むがMasterがリスタートしている時点でそのトランザクションはそれ以上進むはずがないのでログを切り詰める(Truncate)。その際には最新の永続化済みのコミット完了のLSNまで復旧する。なおこの復旧処理はMasterが元気に進行している最中であってもバックグラウンドで良しなに実行される。ここのバックグラウンド処理とチェックポイントに差がないのがAuroraの学術的新規性の一つだと思う。Redo-logリプレイ機能付き分散ストレージがいればチェックポイントに係る複雑さが一気に解決できる。
ベンチマーク結果
論文から抜粋すると
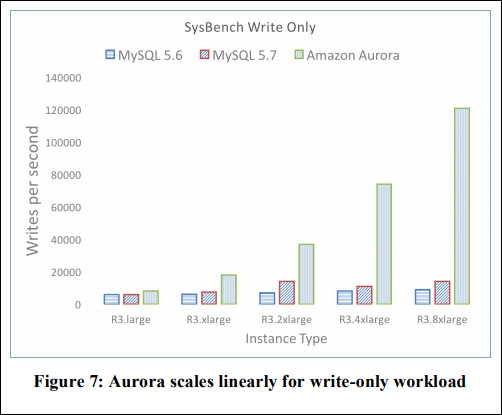
大きめのインスタンスの場合に性能向上の伸びしろが大きいようだ。
その他
なんか他に工夫ないの
ログ処理周りは大胆に手が加えられており、中でも感心したのはFlush Pipeliningが実装されている。
通常、ログが永続化されるのを待つにはロガーにログ内容を渡して、完了が報告されるまでセマフォなどで寝るのが典型的な実装パターンである。しかしAuroraではロガーにログ内容を渡した後に「終わったらクライアントに完了を報告せよ」とキューに依頼を投げ込むだけで、そのスレッドは即座に次のリクエストを捌く処理に移行する。キューの中身を確認する専用のスレッドが居て、新たに永続化されたログのLSNとキューに登録された依頼を見比べて、永続化されたコミットの完了をクライアントに代理で報告する。
PostgreSQLでもpgbenchでベンチマークを取ってイジメてみるとすぐにセマフォ処理近辺がボトルネックになるのでAuroraを真似てこの辺弄っても良さそうな気がするが大改造になるのでコミュニティには歓迎されない気がする。
Aurora Multi-Masterってどうなの
この論文で解説されてる仕組みだとLSNの発行からして複数台のマシンからやってダメなのでログのフォーマットのレベルで改造が加えられてそうな気がする。詳しくは動画で
https://www.youtube.com/watch?time_continue=2620&v=rPmKo2g9znA
どうやらパーティション単位で「テーブルのこの範囲はサーバAがリーダーね!」的に分割統治してMasterを複数用意するようだ。そして自分がMasterじゃないテーブルには一応書き込めるが最終的には調停者が決定するとの事である。更新が競合している場合はWrite性能は上がらないが競合していない場合は性能はよく伸びるらしい。
どんな更新がこれから来るかな
分散KVS側のCPUが安くて空いていて、そいつが保存しているページ内容に対してredo-logを適用できる程度に中身を解釈して動いているので、そいつらに集計系クエリを実行させるのはコストメリットが良さそう。貧者のOLAPとしてJOINが苦手なDB実装がクローズドな世界に君臨する可能性はあると思っている。もしくはredo-logをRedshiftにそのまま投げつけていってSlaveの一つとして稼働するようになるとか。
まとめ
- Auroraは投げつけられたRedoログをストレージ側でバックグラウンドで適用できるからMasterの負担が減った。なので性能が伸びるようになった。
- インテリジェントな分散ストレージすげーな!
- これを設計したAmazonの中の人は確実に「分散システムの肌感覚(Struggler対策とかシングルマスター構成とか)」「Disk-Oriented DBのACID保障の裏側(新しいDBページ一貫性保障プロトコル設計)」「Webアプリプログラマの需要(Webの文脈ではSlaveの厳密な一貫性までは必要としない事)」「クラウドのリソース感覚(分散KVSのCPUは遊んでいるリソースだから活用すべき)」の4つ全てについて確実に僕より深い造詣と生きた知識を持っている。恐るべし。