TL;DR;
Eventual Consistencyとか言いながらどうせもっとまともな一貫性実装してることはよくあるんだからみんな適切な名前を使おうぜ。
なぜこの記事を書くのか
NoSQLの文脈においてスケーラビリティとのトレードオフでEventual Consistencyという用語は結構な頻度で出てくる。
ACIDに対抗してBASE(Basicaly Avalilable, Soft state, Eventual consistency)なんて言葉が出てきたり、CAP定理の中のAとPだと言ってみたり、分散システムのスケーラビリティを高めるために人類は一貫性を諦めることに余念がない。
その一方で、諦められた一貫性に関しては雑な分類論で語られる事が多く実はもっと適切な言葉があるのに「Eventual Consistencyです」なんて言われる事が良くある。そこで、この記事では過去に並行・分散システムの分野で提唱された一貫性について僕が知りうる限りの中身をダンプして共有する。
ここで扱う一貫性とは
システムと人間が向き合う際、意識的・無意識的に人間はシステムで起きる挙動についてある程度の想像と期待をしながら扱うことになる(書き込んだ値は読めるだろう、とか)。これは複雑で高速なシステムを組む際にはどうしてもその挙動と意識の境界線付近を弄くり倒すことになる。境界付近を安全に踏み抜く行為には明瞭な責任分界点が必要となりこれは一種の契約である。その契約の事を一貫性モデルと呼び、プログラマ達はそれを仕様としてインタフェースのこちら側と向こう側で協調することになる。
気をつけて欲しいのはインタフェースのこちら側ではその契約の実装についてある程度の想定を置くことはできるがその向こう側でどんな実装が為されているかは全く定義していない。どんな恐ろしい事が裏側で起こっていようがこちらからそれが観測されない限りは契約の範囲内でありそれが一貫性モデルの面白い所である。「観測できる」という言葉をまだるっこしい言い方をわざわざしているのはそうやって裏側で利用者の予想を裏切る最適化が押し込まれているかもしれないということを隠喩している。
説明の前提
複数のクライアント(ユーザと呼んでも良い)から同時に一つのオブジェクトにアクセスしにくる、という文脈がまず最初にある。
アクセスの内容は直感的にわかりやすいRead()やWrite()かも知れないし、もっと複雑な Snapshot() などかも知れない、もっと言うと Deposit() や Withdraw() など特定のアプリケーションの文脈での操作かも知れない。アクセスされるオブジェクトは所謂オブジェクト指向のオブジェクトかも知れないしサーバプロセスそのものかも知れない。オブジェクト一つの中に複数の値を保存しているかも知れないし値と1対1対応しているケースもあるかも知れない。それらの詳細は一貫性モデルの定義に対して意味を持たないので無視される。
アクセスは必ず開始(Invoke)と完了(Return)があり、操作は必ずその間に行われることになる。
図の左右は時間軸を示しており、右に行くほど未来を指し示す。
図の上下は意味を持たない。見やすいように適宜並べ替える事もある。
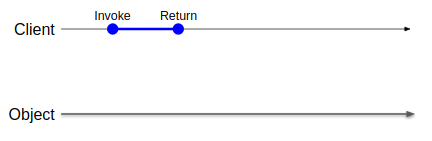
ここに図の文法を例示する。下に見える線がオブジェクト、上にあるやや細い線がクライアントの時系列を示す。青い線が何らかの操作を示している。操作の内容に関しては文脈上意味を持たない限りは明示しない。青線の左端が操作の開始タイミング、右端が完了タイミングを指す。当然ながらシステムの実行は非リアルタイムなので(突然OSにCPU時間を吸い取られて進行できないなんてよくあるよね)線の長さは必ずしも一定とは限らない。
一貫性の分類
強いものから徐々に弱くしていく順序で説明するが、一部必ずしも弱いとは言い切れない(順序を定義できない)物もあるので適宜それは説明する。
Linearizability
現実的かつ最強の一貫性モデルがLinearizability(線形化可能性)である。
実時間性があり、挙動が直感的に理解できる。これを満たすためには以下の条件を満たす必要がある。
- 操作があたかも一瞬で完了したかのように観測でき、実時間の中のどこかにプロットできる
- そのプロットされる時間が操作の開始から完了の実時間中のどこかである
小難しく書いてあるが、早い話が普通のプログラマが普通に直感的に期待する操作である。
一貫性としては使い勝手がこの上なく良いが、高性能を目指す並行システムではこれを実現するのは大変な労力が掛かる場合があり、よく諦められてしまう。
ユーザ側の想像の上では適当なタイミングでグローバルなロックを取っていい感じに実行されたと考えれば問題ない。
操作が並行する(開始と終了の時間に被りがある)場合にはどちらが先に実行されるかは定義されない。操作開始時刻の実時間順に実行されることを期待する人もいるかも知れないが、並行分散システムの世界において実時間順というのは非現実的な解法である。
図に書くと以下のような挙動を示す。
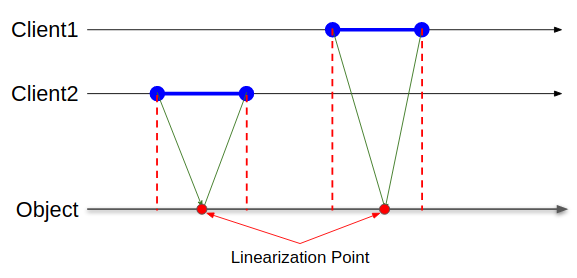
操作の結果はオブジェクトの時系列上のどこかにプロットされる。プロットされる時刻のことはLinearizabilityの時に限り「Linearization Point(線形化ポイント)」と呼ばれる。このLinearization Pointがその関数のInvokeからReturnの間に必ず収まる、という保証がある時Linearizabilityと呼ばれる。絵的にはクライアントから見て自分から伸びる赤い点線と緑の矢印が交差しなければ良い。
External Consistency
Linearizabilityと似ているが定義がやや違う。外部一貫性とも呼ばれるこれはその差分が実用上どこで出てくるかはよくわからない。
条件は以下である
- 並行しない2つの操作は論理的にも実時間と同じ順序で実行される
この文章が直感的でなかった人向けに言い換えると「ある操作が完了した後で始まった別の操作は前の操作を絶対追い越さない」と言い換えても良い。
操作はどのクライアントから発行されたものであっても構わない。実時間にプロットするという観点で考えるとLinearizabilityよりも少しプロット可能領域が広がるがこれがシステム設計上どんな意味を持ってくるか自分にはよくわからない。
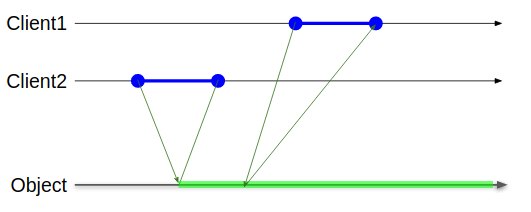
この図で説明すると、Client1の操作は時系列的に前に実行されたClient2より時系列的に後にプロットされさえすれば緑色の領域のどこにプロットされてもよいことになる。
GoogleのSpannerはこの一貫性モデルを採用していると論文中に書いているが、アカデミックな文脈でのこの用語の出現頻度は結構低く、よくこんなものを引っ張り出してきたなぁというのが率直な感想なのだけどこれがLinearizabilityと混同されて困る場面は僕にはピンときていない。
Quiescent Consistency
静止一貫性と訳されるこの一貫性モデルは現実のプログラムではめったに見かけることはない。それを満たす条件はこんな感じ。
- 操作があたかも一瞬で完了したかのように観測でき、実時間の中のどこかにプロットできる
- 操作が一切行われていない実時間上の空白を静止状態と呼び、それを跨るリオーダーは行われない
何を言っているのかわからないと思うが、これは回折ツリーというおもしろデータ構造を組んだ時にちょうどここのスポットに落ちる。回折ツリーの詳細はTAoMP本に譲る。
Linearizabilityは条件上確実にこれを満たすので完全な上位互換にあたるが、External Consistencyは静止状態について何も述べていないように見えるのでその観点ではこちらのほうが強いという言い方はできなくはない。
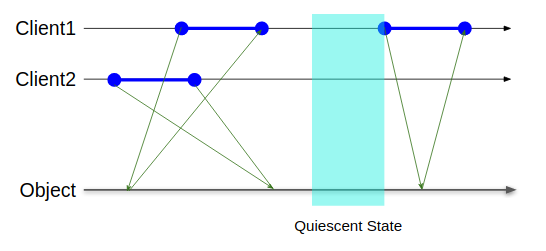
図で言うとQuiescent Stateと書いてある水色の矩形の領域はどのクライアントも操作をしていない区間なのだが、これをまたがる操作が存在しないことを保証するのがQuiescent Consistencyである。
この一貫性の何がありがたいかというと、すべての操作を実行し終わった状態では必ず状態がそれ以上変わらない事が保障されるのである(逆にいうとこれより下の一貫性では一般にそれが保障されない)
何が危険かというと、静止状態を挟まず並行して行われている操作の間ではいかなるリオーダーも発生しうるという事である。これはかなり直感に反するので、現実でもあまり好まれていない。
というかちょうどここの一貫性レベルに落ちるように実用的なコードを書かねばならない一般的なケースが果たしてどれほどあるのやら。なぜならみんながインクリメントしにくる文脈でx==0な値を観測してxに1を代入して、xの値を読みに来たらまた0になっている可能性すらあるのである。
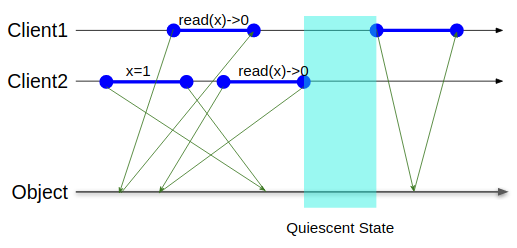
Client2の立場になって考えてみると、xに1を代入して、読みに来たらxに0が入っているのだから期待した動作ではない可能性がある。
ここまでに紹介した3つの一貫性モデルはいずれもcomposability(構成可能性)を持っている点が有用である。composabilityというのは「その特性を持ったものを組み合わせた時に完成品も同じ特性を持つ」という意味であり、例えばQuiescent Consistencyを持った部品を2つ組み合わせて何らかのデータ構造を作った場合、そのデータ構造もQuiescent Consistencyを持っている。(もちろん意図的に壊す事は可能だが)
Sequential Consistency
日本語では逐次一貫性とも言う。たまにLinearizablityと混同している人を見かけるが異なる概念である。
これを満たすための条件は以下である
- 操作があたかも一瞬で完了したかのように観測でき、実時間の中のどこかにプロットできる
- 同一のクライアントから発行される操作の間ではリオーダーは行われない
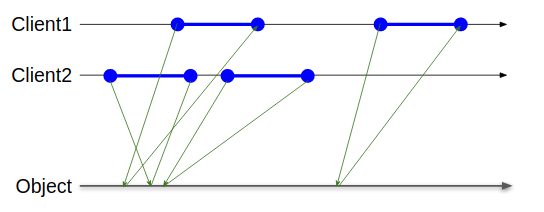
図で説明すると同一のクライアントから伸びる緑色の線が交差しない事が保証できる場合にSequential Consistencyの定義を満たす。
この挙動は大雑把に言うと「すべての操作が一本のキューによって投入順に行われているかのように実行される」という理解をすると正しい。
ぱっと見ではどこが困るのかわからないと思う(僕もわからなかった)。しかしこれは複数のオブジェクトを同時に扱うようになった時に困るようになる。
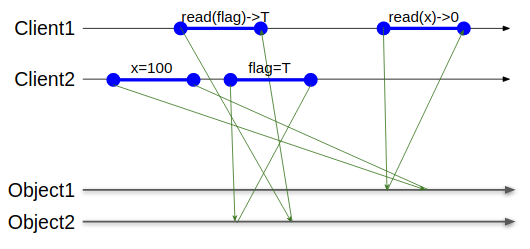
この図は同一のクライアントから同一のオブジェクトに向かって伸びる矢印は一切交差していないので正当なSequential Consistencyの実行を表現する。この中でClient2はxに100を代入した後に完了フラグをTへ書き換えた。Client1は完了フラグがTになっているのを確認してxの値を読みに行ったのにxが更新されていないという状況を観測する結果になる。
composabilityが欠如しているので、複数のオブジェクトがそれぞれSequential Consistencyをサポートしてもそれらを同時に利用するオブジェクトはSequential Consistencyを満たさない。
また、この一貫性モデルは実行される実時間に関しては何も言っていないのでまさに「10年20年後と言うことも可能だろう・・・ということ・・・!」の世界である。
とあるCPUのキャッシュ実装は単一のキャッシュラインについてはこのSequential Consistencyをサポートしているが、複数のキャッシュラインに跨ってしまうとSequential Consistencyを満たせなくなる。一般にCPUのキャッシュはSequential Consistencyすら満たしていない。
ここより上の一貫性モデルが一般に「Strong Consistency」と呼ばれているもので、すべてのクライアントから見たすべての操作が何らかの順序で(タイミングはともかく)一貫している、という共通点がある。逆に言うとここより下の一貫性は条件次第ではクライアントから見て操作を観測する順序が反転する事がある。
Release Consistency
一般にCPUのキャッシュ機構が満たしていると言われるConsistencyがこれである。
条件を書き下すと
- Releaseという指定の付いた特定の操作は発行された後に同一クライアントからの他の操作によって追い越されない
- Acquireという指定の付いた特定の操作は発行する際に同一クライアントからの他の操作を追い越さない
つまりユーザが「この操作はReleaseだよ」とか指定しなくてはいけなくて面倒である。付けないとすべての操作が追い越し・追い越される可能性が発生することになる。逆に、すべての操作にAcquireかつReleaseの指定をつけるとそれはSequential Consistencyと同じ挙動になる。Composeされた複数のオブジェクトに跨ってRelease/Acquireのルールを適用できる時、Release Acquireを適切に実行することはシステム全体がSequential Consistencyで動いてるかのようにみなすことができる。
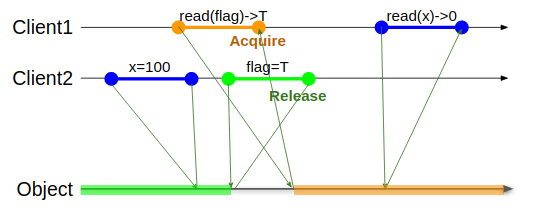
この図で言うと、flag変数の操作にそれぞれRelease/Acquireを付けたのでClient2がフラグを設定する操作より後にClient2のx=100の代入操作がリオーダされることはなく、緑色の領域にしかプロットされなくなる。Release指定された操作は同一クライアントから見て左から右にクロスすることができない。同様にClient1のread(x)の操作はflagの読み出しより先行して行われることがなくオレンジ色の領域にしかプロットされなくなる。言い換えるとAcquire指定された操作は同様に同一クライアントからみて右から左にクロスすることができない。これによって無事にflag変数を媒介してxという値を2つのクライアント間でやりとりすることができるようになった。これは複雑になってくるとBrain Damagingなデバッグを要求するのであまり積極的に飛び込もうとしてはいけない。
コンパイラはユーザが記述したプログラムがそのプログラミング言語仕様に合わせた挙動をする機械語に落としこむのが仕事なので、CPUが仮に何らかのリオーダーを行う前提のアーキテクチャ(Alphaとか)であれば必要な位置に適切にメモリバリア命令を挟み込む必要があり、そのメモリバリア命令に相当するのがRelease/Acquireである。もっと言うとプログラミング言語仕様に合った挙動さえすれば問題無いので仕様内であれば最適化の目的でイカれた並び替えを行うことも許される。その有名な実装がJMM(Java Memory Model)である。synchronizedとかlockとかunlockとかの境界部分を除きJMMは実は結構アグレッシブなリオーダーをするとされており、これはメモリモデルが緩い(=より厳格なRelease/Acquireを要求する)CPUの性能を引き出す際に高いポテンシャルを発揮する…というが本当だろうか。Azul Systemsという会社ではJavaを実行するための専用のプロセッサを開発し、JVMとCPUの密結合アーキテクチャによってガベージコレクションや並列化の性能を向上させていた。その工夫の中の一つがメモリモデルでありソースはこの辺にある。
普段使われているx86ではTotal Store Orderingという、このRelease Consistencyの仲間のような一貫性モデルを採用している。これは「別のアドレスに向けたLoad命令はその前に発行されるStore命令を追い抜く事だけができるが、それ以外の追い抜きは許されない」というかなり強固なメモリモデルであり、丁度いい具合にピーターソンロックがメモリバリアなしでは実装できないという面白い挙動をする。
Causal Consistency
ここから下の一貫性モデルではユーザの操作セマンティクスに踏み入った順序整理を行う事がある。一般に僕はその手のアイデアは事故のもとになるのであまり好いてはいない。
まず因果一貫性とも呼ばれるこの一貫性モデルでは、クライアントはアクセスを行う際にこれまでにどのデータを読み書きしたかという情報をセットで提供する。それによって「この操作はあの操作よりも後」という順序付けをすることがサーバ側で順序付けできるようになるので因果関係が崩壊するような事態を避ける事ができる。
典型的にはベクタークロックを用いてデータにバージョンをつけていく事でこの一貫性レベルに落ちる事が多い。人間の直感に反しないように設計されているっぽく見えるがベクタークロックがそもそもスケールしにくい(参加台数に合わせてベクターが肥大化する)とか、複数のクライアント間で協調した際に思った通りに動いてくれなかったりとかあまり良い事ばかりには見えない。仮にExternal Consistencyの対義語としてInternal Consistencyを定義するならばこのCausal Consistencyあたりが妥当ではないかなと思っている。なぜならサービスの文脈内部の事情においての一貫性レベル保証を行っているからである。
PRAM consistency
PRAM(pipelined random access memory)一貫性、もしくはFIFO Consistencyと呼ばれるのがこの一貫性。Causal Consistencyより有意に弱い。
これはどういう一貫性かというと
- 同一のクライアントから同じ場所に書き込まれた値だけは他のすべてのクライアントからもその順序で観測できる
- 別のクライアントから同じ場所に書き込まれた値はクライアントによって別の順序で観測される場合もある
という物である。FIFOというのでSequential Consistencyの場合と混同しがちであるがSequential Consistencyと違うのはRandom Access Memoryが間に入っているかのような挙動をするので、読み出し操作が特定のクライアントローカルでは自分たちのストアバッファにヒットして最新の値が読めてしまうが、すべてのクライアントが同じストアバッファを共有しているわけではないので他のスレッドからは違う順序で値を観測しうる。複数本の途中読み出し可能キューが間に挟まっている状態のSequential Consistencyを想像すると恐らく近い状況になる。正直ちょっと手を出したくない一貫性レベルである。
Read Your Write Consistency
ここから下の一貫性はClient-Centric Consistencyと呼ばれる。
Read Your Write Consistencyは書いて字のごとく、自分が最近書いた値が自分で読める一貫性レベルである。RYW Consistencyと略すこともある。
自分で書いた値以外への順序は保証されない。
典型的には、相互にデータを非同期バックアップしあうサーバが複数居て、クライアントごとに別のHash関数を経由してどのサーバに保存するかをHash(データ名, クライアント名)で決定する、みたいな負荷分散を行った場合に起きる。
例えばクライアント1はHash関数の結果サーバBにXの読み書きを行うとすると、サーバBに書かれた内容は即座にサーバA,Cに伝搬するとは限らない一方で、サーバBには確実に保存されているのでBに対して読み書きを繰り返す限りにおいては自分からの読み書きは常に順序反転なく行われると期待してよい。しかしクライアント2はHash関数の結果サーバAに読み書きを行うことになっていたとして、サーバBによってXに書かれた内容がサーバAに届くのは非同期的なので、たとえクライアント1から「Xに書き込み完了したよ!」とこのシステム外の何らかの手段で通知を受けてクライアント2がサーバAにXを読みに行ったとしても最新の値が読めるとは限らない。
この近辺に「一度読んだ値が少なくとも自分から見て更に古い値で上書きされない」というMonotonic Read Consistency(MR Consistency)とかその別種のMonotonic Write Consistency(MW Consistency)とかこの近辺にはいろいろあるが現実で出くわしたことはない。
Eventual Consistency
ここまでに説明した一貫性が全部適用されない場合、つまり
- どこのタイミングで操作が完了したか保証がない
- ある値を読めたからと言って次に同じ値を読みに来た時に古い値に巻き戻る可能性も捨てきれない
- 自分が読めた順序で他のクライアントも読めているかもわからない
- いずれ何らかの書き込んだ値になることだけは分かる
という状況の時にやっと誰から見ても文句のない「Eventual Consistency」と呼べる状況になる。これはもはや何を保証しているのかすらわからない(個人の感想です)。Eventual Consistencyの文脈で出てくるLast Write WinってそれつまりDB屋に言わせればLost Updateを含むってことだからな!
何をすればこんな状況に陥るかというと典型的にはGossip Protocolと称してレプリケーションの順番を非同期かつ予測不能にしてやることで発生する。Gossip Protocolはねずみ算式に到達ノード数が増えるのでランダム性を差し引いてもかなり迅速に最新データが伝搬する優秀なプロトコルであるが、一貫性という観点で考えるとかなり劣悪な前提をおくはめになる。仮にこの一貫性を誤解した状態で一貫性に起因するバグを埋め込んでしまうと、なまじ迅速にデータが伝搬する故に発現しにくいタチの悪いバグが長期にわたってプロジェクトを悩ますことになる。
ツッコミ
Q. まだまだ一貫性いっぱいあるよね!?!?!
A. ギャーーーもう勘弁してください…これぐらい知ってたら大抵の会話ついて行けますから…
Q. 後半の緩い一貫性に図解が無いよ?
A. わかりやすい図を用意する根気が湧いてこなかったので勘弁してつかーさい…。
その他
Serializabilityは何なの?
トランザクションの文脈において「個々のトランザクションを直列に混ぜずに順番(Serial)に実行した場合と同じ結果を生み出す」という実行順序の事をSerialにしうるという意味を込めてSerializableと呼ぶ。単一の操作の実時間性について議論していたLinearizabilityとはまた別基準の話をしている。Serializabilityの議論の上では実時間中のプロットやLinearization Pointのような概念は存在せず、ただ「複数の操作の間のその並び替えは合法か否か?」を読み書きの依存関係に絞って議論する。これらSerializabilityとLinearizabilityは用語としてはよく似ているが技術用語としては別の出自の別次元の話である。
もっと知りたい人はどこに行けば
- 厳格な定義でいうとこのサーベイ論文はトランザクショナルメモリの文脈に沿ってかなり網羅的だけど僕には読む根気がなかった…。
- Peter Bailis氏のこの論文は興味深い図がある。
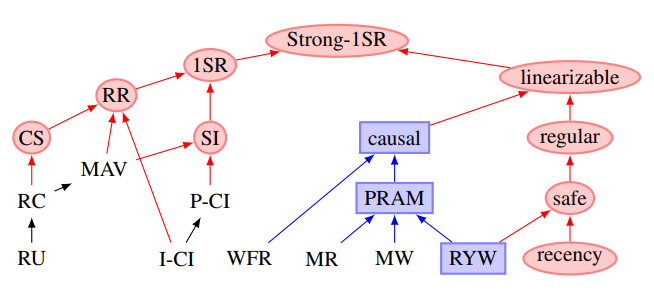
1SRは「1-copy Serializability」の事で「まるで複製がされていないかのようにユーザからは観測できるSerializability」つまり普通のSerializabilityを指している。つまりLinearizableとSerializableはどちらもStrong-1SRの下位レベルとして定義できる、と言っているように見える。これは個人的に両手放しに賛同できるとまでは思っていないが、大統一理論のように素敵な発想だと思う。更に、この色分けがCAP定理で言うところのConsistencyやAvaialabilityの下界を示しているそうだ。この詳細の議論は追いかける気力が湧いてこないのでもっと意欲のある人に任せたいと思う。 - Replication: Theory and Practiceという本の1章でこれらの一貫性レベルの厳密な定義や解説が載っている。僕は我流に噛み砕いて説明したけれど数学に強い人が読んだらまた違う知見が得られると思う。
- The Art of Multiprocessor Programmingの3章に強い一貫性に関する正しい分類と説明が載っている。ただ和訳が一部残念で、静止一貫性と逐次一貫性が排他であるという誤訳が含まれる。ここまで真面目に読んだ人にはLinearizability(線形化可能性)が静止一貫性と逐次一貫性の特性を併せ持つことは自明に理解できていると思う。気になる人は原著の方を読む事をおすすめする。ただし学術的にかなり正しさに気を使って書かれているので和訳がむしろ綺麗に訳せてるから読みにくいんだなぁという事をしみじみ感じる結果になるかも知れない(僕はそうなった)。
まとめ
Eventual Consistencyを採用する前にもう少し使いやすい妥協点を考えてみよう。もしくはあなたのシステムはEventual Consistencyと言いながら実はもう少し強い一貫性を採用できているかも知れないので真面目に見返してみよう。