グループコミットによってトランザクションのスループットを大幅に引き上げる技法について昨日の記事で書いたが、この技法ではロック期間は結局ディスクのヘッドシークの長さになる。
むしろロガーとのコミュニケーションコストやログ待ちの時間を考えると個々のロック保持期間は微妙に長くなってさえいる。
また、各スレッドはロガーによって永続化されるまでトランザクションの完了を待たなくてはならないので、1回のログ操作に詰め込めるトランザクション数はスレッドの数が上限になる。
つまりスループットを上げる為にはより多くのスレッドを並列して動かす必要がある。
更には、ロガーのバッファにトランザクションログを送付する際にも、ロックが衝突する可能性もある。複数のワーカーが同時にロガーにログを送付しようとするとそこもボトルネックになりうる。
そこで提案されているのがAetherである。読みはおそらく「エーテル」で、ファイナル・ファンタジーでMPが回復するアイテムと語源は同じ。以下に貼り付ける図などはこの論文の抜粋である。
Aetherの中で提案されている改善は
- Early Lock Release
- Flush Pipelining
- Buffer Consolidation
の3つである。それぞれに付いて説明する。
Early Lock Release
ロガーにログを送付した後ならロックを解放して良いというアルゴリズムである。
ただし、ロガーがログを永続化し終えた後でしかユーザにトランザクションの完了を報告してはならない所がポイントである。面白い事に、これは一切グループコミット、つまりS2PLのセマンティクスを破壊せず、ACID特性を守り続ける事ができている。それでいて、遅いディスクIOの間ロックを保持し続けなくて良くなるので同じデータにアクセスする後続のトランザクションが処理を続行できるという利点がある。
実は、このEarly Lock Release(以下ELR)はこの論文が最初の登場ではないが、提案として適切にベンチマークを取ったのはこの提案が初であるとの事である。
論文に載っている評価は以下である。
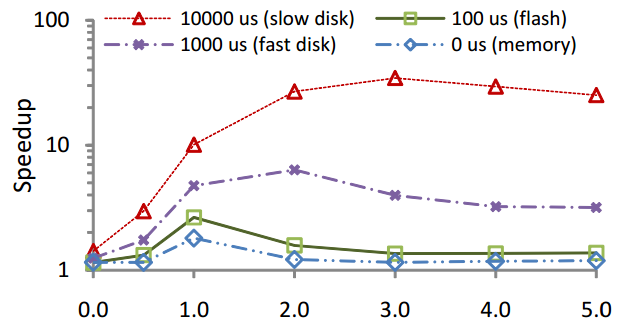
TPC-Bという更新系ベンチマークにおいてSkewつまり操作対象の偏り(横軸)を増やす程にロックの衝突率が増えるが、Early Lock Releaseを適用した場合には大きな高速化が得られる(縦軸)。特に遅いディスクにおいての性能差が顕著だが、高速なSSD(遅延100us)を使っている場合であっても2倍程度の高速化を実現している。
Flush Pipelining
各トランザクションスレッドはロガーがログを永続化するまで待機し、その後でユーザにトランザクションの完了を報告する。
さて、ロガーがどのように永続化を待機するかというと、まさかSpinで待つわけにも行かないのでcondition_variableなどを使って待機する事になる。(Spin、つまりforループで待っていたらそのCPUコアは食いつぶされるのでCPUコア数以上のスレッドを走らせても性能が出せない。かと言ってyield()で待ってもコンテキストスイッチのコストが重い)そのcondition_variableはロガーからnotify_allで呼び出されるまでトランザクションスレッドを寝かせる物でスレッド数が増えるとそれだけコンテキストスイッチのコストが掛かる。
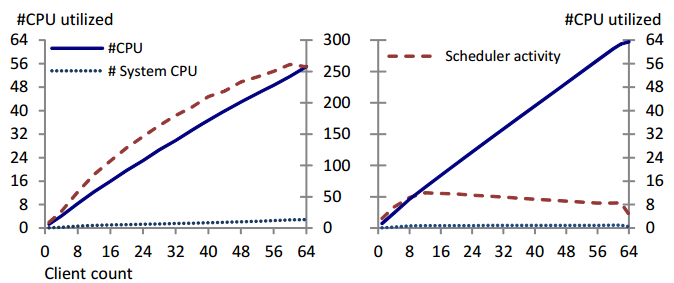
この図の左のように、クライアントが増える程にCPU使用率(左縦軸)が上がるが、コンテキストスイッチの数(右縦軸)も増大している。これがトランザクションの性能の阻害となる。
実はロガーにログを転送してロックを手放して即クライアントに完了を報告してしまえば、そのスレッドは二度とそのトランザクションに触らなくて良いのでcondition_variableのnotifyが不要になって性能が向上する(Asynchronous Commit)。しかし「クライアントに完了を報告したがログを永続化する前にシステムがクラッシュ」というシナリオでDurability違反が発生してしまう。
それではダメなのでロガーにログを転送した段階ではクライアントに完了を報告せず、ロガーにトランザクションを永続化させた後で「クライアントに完了を報告する」という動作をデーモンスレッドがアタッチして一気に行う。そうすることでコンテキストスイッチの回数を大幅に削減することができる。
テクニックとしては割と実装レベルの工夫のように見えるが割と性能に影響が大きい。
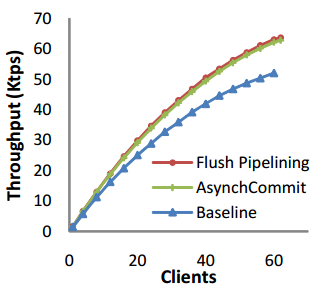
Flush PipeliningはこのようにAsynchronous Commitに逼迫する性能をたたき出している。しかもAsynchronous CommitのようなDurability違反もしていない。
Consolidation ArrayとDecoupling Buffer Fill
ロガーにログを永続化させる場合、大雑把には以下のステップを踏むことになる
- ロガーのバッファのロックを獲得する
- バッファに自分のログを書き込む
- ロックを開放する
このステップはトランザクションスレッドが増える程にロックの衝突度合いが高まり全体のパフォーマンスを大きく損なう事が予見される。
なので2つの技法を使う事でログバッファにログを書き込む操作に並列性を注入する。
Consolidation Array
ロガーのロックを獲得できなかった際にカーネルにCPUを返却すると巨大なオーバーヘッドがかかるので基本的にロックはスピンで待ちたい。だがスピンで待つとそれ自体がキャッシュコヒーレントのトラフィックを発生させ大きな遅延を発生させる。なので適当なバックオフ時間を設けて1マイクロ秒後にリトライ→失敗したら2マイクロ秒後→それでも失敗したら4マイクロ秒…という感じにわざと空ループでアクセスせずに待つ方が全体のスループットを高める事が多い(これを指数時間バックオフと言う)。
だが、どうせカーネルにCPUを返さずに空ループを回すのだからもう少し有効な事に使いたい。それがConsolidation Arrayの基本的な考え方である。
すごく平たく言うと「ログバッファを獲得できなかったスレッド同士がくっついて代表者を決め、その代表者が獲得したロックでみんなが一斉に書き込む」という手順である。
そのためにロガーのバッファとは別に小さな配列を用意する、便宜上ConsolidationArrayと呼ぶ。そして以下のステップで利用する。
- ログバッファの獲得を試みる(
try_lock) - 失敗したら乱数を出してConsolidationArrayの中のどれか1つを選ぶ。選んだ場所を便宜上Slotと呼ぶ
- そのSlotの中で最初の自分が到着者であれば、自分が書きたいログの長さだけバッファオフセットの数値をずらして、そのSlotの状態をOPENにしてログバッファの獲得を待つ。
- 自分より先に到着しているスレッドが居て、なおかつそのSlotがOPENであれば自分の書きたいログの長さだけオフセットの数値をずらしてNotifyされるまで寝る。これをJOINと呼ぶ。
- 自分より先に到着しているスレッドが居て、なおかつそのSlotがCLOSEDであれば2からやり直し
- ログバッファのロックが獲得できたらSlotの状態をCLOSEDに書き換え、合計で変動したバッファオフセット分だけログバッファを獲得、同SlotにJOINしたスレッドを起こす。
- 起きたスレッドはそれぞれ自分の指定したオフセットの位置に自分のログを書き込む
- 書き終えたら完了
Decoupling Buffer Fill
こちらは割と素直である。
ログを転送する、端的に言うとmemcpyを行っている間にもロックを握りしめている必要は無いので、ロックを獲得してバッファ内の自分が書き込みたい場所を獲得したらmemcpy前にロックを手放すのである。それでロックの保持期間を減らして並列度を高める事ができる。これは特に個々のログが大きい場合に大きな効果が期待できる。
しかし、それでは自分より若いトランザクションのログが書き終わるよりも先に自分がログを終えてしまう可能性がある。なので、自分より若いトランザクションがすべてを書き終えるまで待機を行う。
なので上で書かれている4.のステップでロックを手放し、6.のステップで自分より若いトランザクションの完了を待つというロジックを足すだけである。なのでConsolidation Arrayと容易に両立できる。
さて、ELRとFlush PipeliningとConsolidation Array&Decoupling Buffer Fillのアルゴリズムを組み合わせた高速ロギング手法がAetherであるがそのパフォーマンスは以下の様に改善をしている。(ベースラインはShore-MTというDB研究者向けの実験DBである)
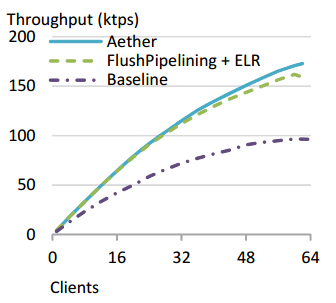
見て分かるように、FlushPipeliningとELRが導入された時点で約68%程高速化しており、最後のログ周りはさほど大きな改善をしていない。論文中ではまだシステムが小さいからでこれからコア数を増大させていけば更にログ周りの改善が効いてくるはずと書かれているが、追試に期待したいところである。
今日の記事はびっくりするほど長くなった。
長くなったが言いたいことは簡潔である。
S2PLのセマンティクスに違反しない範囲でも人類はここまでアルゴリズムを改良できた。