最近Bitcoinの方が流行っている印象を受けますが,ディープラーニングの勢いは依然強く,Google Trendを見ても未だに検索数は上昇傾向にあるように見えます.
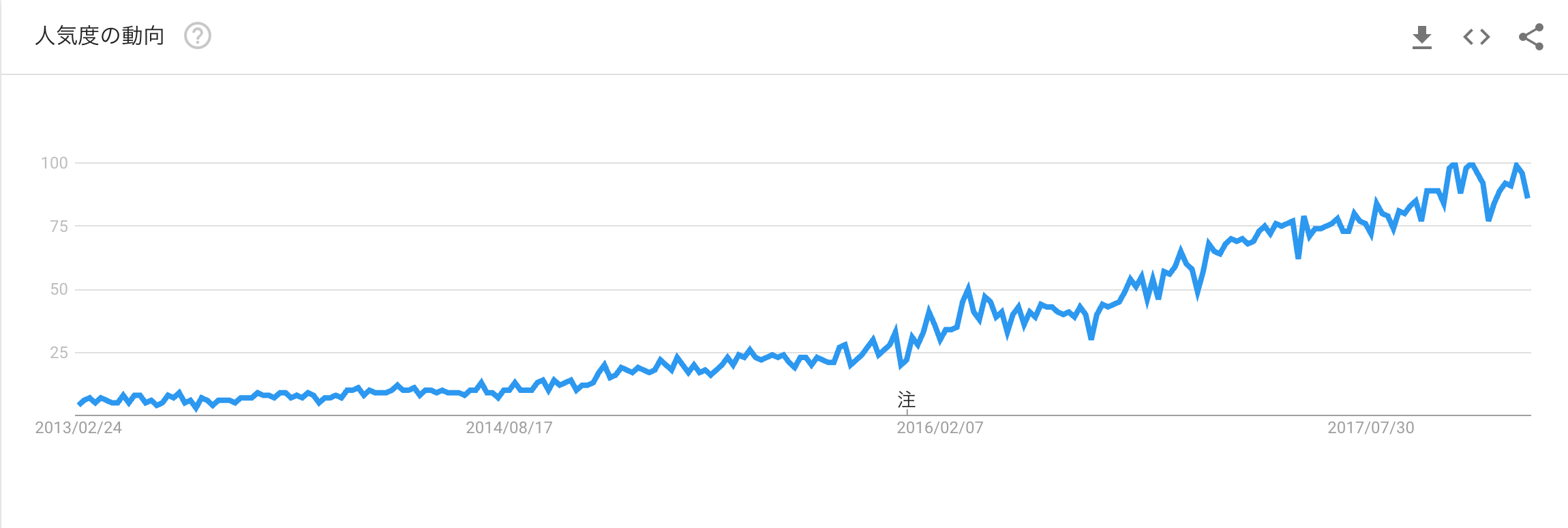
実際体験してみるとわかりますが,ディープラーニングはとんでもなく強力な機械学習の手法で,うまく使いこなせれば強力な武器になります.しかし,「ディープラーニングにはPhDが必要だ」「ディープラーニングは素人には学べない」といった幻想もちらほらあり,興味はあってもなかなかこの世界に飛び込めない人も多いのではないでしょうか?
この記事の目的
この記事では筆者がディープラーニングを学ぶ上で筆者が特に有効だと感じたリソースと,有効な学習法について紹介します.参考までに,筆者はディープラーニングを学び始めてまだ9ヶ月程度ですが,今となっては職場でディープラーニングを教える立場になっています.まだ筆者はディープラーニングに関しては初心者ですし,発見できていない素晴らしいリソースもたくさんあることは重々承知ですが,少しでもこの分野に取り組めるエンジニアの数を増やせればと思い,この記事を投稿します.
前提知識
ディープラーニングを学ぶにはPhDは不要ですが,最低限以下の知識は必要です.
高校レベルの微積分と行列の知識
積分は不要ですが,logの微分と行列の掛け算の仕方くらいは知っといた方が良いです.これより高いレベルの数学ももちろんわかっていた方が良いですが,必要だと感じた時に学ぶくらいの心持ちでいいのではないかと思います(これについては学習法の部分でもう少し詳しく述べます).
プログラミング(Python)
プログラミング未経験でディープラーニングをやるのは厳しいところがあります.別に得意である必要はありませんが,Pythonはある程度書けないとかなり苦労します.Python初心者の方はDotinstallのPython3講座あたりを見て予習しておくと良いのでは,と思います.オブジェクト指向,遅延評価,リスト内包表記などを理解し,Pythonを自由自在にかければかけるほど良いのですが,これも必要に応じて勉強する姿勢で取り組めばいいのではないかと思います.
ちなみにディープラーニングをやるならPythonは3系一択です.2系を使うメリットが何一つないのと,2系はnumpyに見捨てられている以上長期的に見たら使うことができなくなるので.
英語
数学とプログラミング以上に重要かもしれないのが英語です.ディープラーニングに関する優良なリソースのほとんどは英語です.フレームワークのドキュメントも(基本的には)英語です.論文も(当然)英語です.別にTOEFL100点レベルの英語は必要ではありませんが,日本語のリソースだけに頼っていてはかなり限度があることを認識した方が良いと思います.
優良リソース集
ディープラーニングに入門する際に筆者の役に立ったリソースをここで紹介します.
ディープラーニング入門
オンラインコース
fast.ai

一番最初に紹介するのはfast.aiというコースです.これはあまり日本だと有名じゃないのかもしれませんが,筆者の中では世界最高のディープラーニングのリソースです.fast.aiはJeremy Howardという元Kaggle Champion(Kaggleは機械学習のプロコンみたいなもので,世界中の猛者が賞金を求めて競い合います)が教えているオンラインコースで,機械学習や数学についての前提知識をほとんど必要とせず,ある程度コードがかける人向けにディープラーニングを教えるものになっています.なんと,2時間近いレッスンを7つ完全に無料で見れます.英語も聞き取りやすく,説明もとてもわかりやすいので非常に勉強が捗ります.
このコースの良いところは,実際にディープラーニングを使うために必要な知識を教えてくれるところで,フレームワークの使い方や実践的に必要な知識(ハイパーパラメーター調整など)について,実際の例(Kaggleの過去のCompetition)を元に学べます.
また,このコースは最初に実践的な課題を解く方法を示し,そのあと裏にある仕組みを説明するトップダウンの教え方をしてくれます.「野球を教えるときは普通事細かにルールやバッティングについてあれこれ最初から教えるのではなく,とりあえずプレイさせてその中で必要な知識を教える.学校教育だってそうあるべきだ」という思想をベースにしているそうです.これには筆者も同意しますが,時間の都合上やや裏の仕組みについての説明が薄い部分もあったりします.ちゃんと仕組みを知らないと気持ち悪いという人は次に紹介するコースを同時に受講することをおすすめします.
CourseraのDeep Learningコース

言わずとしれたAndrew Ng(機械学習界隈の超有名な研究者)が教えるディープラーニング講座.こちらは基礎的な知識から始めて徐々により高度な内容を紹介する,ボトムアップの教え方をとる講義です.Andrew Ngは機械学習のコースもCourseraで持っていますが,それと同様のいつものわかりやすい説明で初心者にも理解できるようにディープラーニングの重要な概念について解説してくれます.正直どんなディープラーニングについての入門書よりもこのコースの方が簡潔にまとまっていてわかりやすいと思います.特に過学習に関する説明がかなり丁寧なのが筆者的に好感を持てます.
ちなみにビデオだけなら,下のAudit the courseオプションを選択することで無料で見れます.

Auditは無料で動画を見れる代わりに,課題には取り組めません.正直課題だけのために数万払うのは勿体無いと思うので,個人的にはこのコースはビデオ視聴で基礎知識を深める感覚で取り組むといいと思います.ただ筆者は課題をやらずにこれを言っているので,検討している人は実際にやった人の声もレビューなどで確認した方が良いかもしれません.
書籍
上のコースが素晴らしいので,筆者はあまり入門書の必要性を感じたことがありません.ここでは上のコースの内容を補完または深めるような書籍について紹介します.
Deep Learning本

著名なディープラーニング研究者が書いている本で,これもまた無料で読めます.ディープラーニングの裏にある数学や理論の基本について学ぶのに最適な本です.3つの部に分かれていて,第1部ではディープラーニングをやる上で必要な数学や機械学習の知識をカバーし,第2部ではディープラーニングの基礎的な理論について書いています.上のコースを受講し終えた人や機械学習についての知識たある程度ある人にはおすすめです.
第3部はディープラーニングの最先端について書く,と書いてあるのですがかなり内容に偏りがある(ほとんどが生成モデルについての話で,かなり数学的です)ので,正直あまり読まなくて良いと思います.
ゼロから作るディープラーニング

日本限定で考えると,上の本よりもこの本の方が有名かもしれません.この本はディープラーニングそのものを学ぶ題材というよりは,ディープラーニングのフレームワーク(これについてはのちに説明します)が裏でどういうことをしているのかを理解するための題材と考えてもらった方がいいと思います.ただ,これはAndrew Kaparthyという偉い人も言っていることですが,フレームワークが裏でどう動き,ニューラルネットがどうやって学習しているかのイメージをもつことはデバッグをする上で重要になってくるので,時間と興味があればこの本もいい資料になると思います.ただ最速でディープラーニングを使えるようになりたい人はパスした方がいいかもしれません.
周辺知識
機械学習
ディープラーニングは機械学習の手法の一つで,ディープラーニングを有効に使うためには機械学習の知識もある程度必要です.機械学習は広い分野なので,この記事でリソースをカバー仕切るのは不可能ですが,いくつか機械学習の入門的なリソースでおすすめのものを紹介します.
Courseraの機械学習コース

これもまたAndrew Ngが教える超有名な機械学習のオンラインコース.筆者はこれを見て機械学習について学び始めました.説明が直感的でわかりやすく,前提知識を要求しないので初めて機械学習を学ぶ人にも,基礎をもう一度復習したい人にもおすすめです.ディープラーニングを学ぶために受講する場合は,Week 6までの内容をカバーすればいいと思います.このコースでは筆者は課題に取り組みましたが,numpyを使った経験があまりない人には行列計算をベースとした言語・ライブラリの考え方を身につけるいい題材だと思いました.ちなみに課題を全部numpyとscipyで書き直した人もいるので,numpyで課題を全部やって見るといい練習になるかもしれません(このnumpyのリソースについては筆者は取り組んでいないので,質については保証できません.取り組んで見た人がいたらぜひコメント等で筆者に感想を教えてください).
An Introduction to Statistical Learning
 スタンフォード大学が公開しているオンラインコースでも使われている世界的に有名な機械学習の入門書です.包括的でわかりやすい説明に加えてR言語のコードがあるので実際に手を動かして理解を深めることができます.実は筆者はこの本を読み切ってはいないのですが,周囲での評判はかなり良いです.無料でpdfが公開されているので,興味がある人は手にとってみることをオススメします.
スタンフォード大学が公開しているオンラインコースでも使われている世界的に有名な機械学習の入門書です.包括的でわかりやすい説明に加えてR言語のコードがあるので実際に手を動かして理解を深めることができます.実は筆者はこの本を読み切ってはいないのですが,周囲での評判はかなり良いです.無料でpdfが公開されているので,興味がある人は手にとってみることをオススメします.
Hands-On Machine Learning with Scikit-Learn and TensorFlow
 こちらはPythonの有名な機械学習ライブラリであるscikit-learnとtensorflowを使いながら機械学習について学んでいく本です.他の本に比べて理論面の説明がやや薄いものの,その代わりコードがたくさん掲載されているため,実践的に学ぶことができます.Scikit-learnはおそらく一度は触ることになると思うので,さっと目を通すだけでも何かと役に立つと思います.
こちらはPythonの有名な機械学習ライブラリであるscikit-learnとtensorflowを使いながら機械学習について学んでいく本です.他の本に比べて理論面の説明がやや薄いものの,その代わりコードがたくさん掲載されているため,実践的に学ぶことができます.Scikit-learnはおそらく一度は触ることになると思うので,さっと目を通すだけでも何かと役に立つと思います.
はじめてのパターン認識
 有名な日本語の機械学習の入門書です.数学的に様々なアルゴリズムの裏の理論をちゃんと説明してくれます.パターン認識と機械学習などの機械学習本に比べてわかりやすく読みやすいので初心者におすすめです.
有名な日本語の機械学習の入門書です.数学的に様々なアルゴリズムの裏の理論をちゃんと説明してくれます.パターン認識と機械学習などの機械学習本に比べてわかりやすく読みやすいので初心者におすすめです.
パターン認識と機械学習

こちらも言わずと知れた機械学習についての本.これは入門書ではありませんし,割と癖が強いです.この本を読むメリットとしては,他のリソースだとあまりしっかり教えてくれない確率的な視点から機械学習を捉え直すことができる点です.
真面目に取り組んでると初心者は挫折する可能性が高いと思うので,ディープラーニングをマスターすることを目的として読むなら上巻だけ取り組んで,エビデンス近似などのベイジアインハイパーパラメーター最適化あたりの話は(現状ディープラーニング界隈ではまだあまり使われていないので)読み飛ばすのが良いと思います.
数学
ディープラーニングを実践的に使うためにはそこまで数学は必要ありませんが,論文を読もうとしたり,理論をより深く理解しようとするとある程度の数学力は必要になってきます.基本的に数学はその都度学んでいけば良いのではないかと思っていますが,より体系的に学びたい人のために筆者が知っているいくつかの良いリソースを紹介します.
ちなみに機械学習の数学面について学びたい人は上で述べたリソースが良いと思うので,ここでは線形代数と確率統計についてのリソースのみを紹介します.
Introduction to Linear Algebra

MITの線形代数の授業で使われている教科書.今まで出会ってきた線形代数についての全てのリソースの中で圧倒的にわかりやすく,体系的で深いです.ネット上で線形代数のオススメの(英語の)資料を探しても大抵みんなこの本を一番にあげています.筆者的にもオススメです.
プログラミングのための線形代数

線形代数の基本をエンジニア向けに平易に教えてくれる本です.個人的にはディープラーニングをやる上ではやや物足りない部分も感じるものの,線形代数の最小限の要点をなるべく効率的に学びたいという人にはオススメです.
統計学入門
 有名な統計学の基礎についての教科書.様々な確率分布,最尤推定,検定などの概念についてわかりやすく説明されているため,統計学の入門書として最適だと思います.ちなみに練習問題は結構誤植が多いので,解く際は気をつけましょう.
有名な統計学の基礎についての教科書.様々な確率分布,最尤推定,検定などの概念についてわかりやすく説明されているため,統計学の入門書として最適だと思います.ちなみに練習問題は結構誤植が多いので,解く際は気をつけましょう.
データ処理
ディープラーニング(に限らずあらゆる機械学習アルゴリズム)を使う上でデータの前処理は欠かせない技術です.データ処理は広く,深い分野なのでここで全ての優良リソースをカバー仕切ることはできませんが,筆者が特に役立つと感じたリソースをいくつか紹介します.
Pythonによるデータ分析入門
 Pythonでデータ処理を行う際に欠かせないライブラリであるPandasの作者が書き,日本語に翻訳されたデータ分析についての入門書.Pandasだけでなく,numpyやmatplotlibといったディープラーニングをやる上で欠かせない周辺ライブラリについてもかなり丁寧に書かれています.未だに時々見返すと新たに学ぶことがあり,筆者は非常に重宝しています.
Pythonでデータ処理を行う際に欠かせないライブラリであるPandasの作者が書き,日本語に翻訳されたデータ分析についての入門書.Pandasだけでなく,numpyやmatplotlibといったディープラーニングをやる上で欠かせない周辺ライブラリについてもかなり丁寧に書かれています.未だに時々見返すと新たに学ぶことがあり,筆者は非常に重宝しています.
Pandas Cheat Sheet
Pandasの重要な処理が簡潔かつ視覚的にまとめられている.上から読むというより,Pandasで困ったら真っ先にこれを見る癖をつけるとpandasを使いこなせるようになっていくと思います.
学習法
上で紹介したのはあくまでの入門的なリソースで,ディープラーニングについてのリソースは他にもたくさんあります.より深いことを学ぼうとするとかなりの量のブログ記事と論文を読むことが必要になります.全部片っ端から取り組もうしてもキリがないので,ここではおすすめの学習法について紹介します.
1. プロジェクトを決める
「とりあえずディープラーニング学ぶぞ」と言って簡単に学べるほどディープラーニングは甘い分野ではありません.ディープラーニングを使って何をしたいかを視野に入れながら勉強を進めないと情報過多で挫折します.
プロジェクトと言ってもそんな大層なものである必要はありません.例えばKaggle(データ分析のプログラミングコンテスト)でディープラーニングを使っていい結果を出すとか,ちょっとした顔認識のアプリケーションを作るとか,とにかく簡単なものでも大丈夫です(やってみると当初の想定より遥かに難しいことに気づくと思います).ディープラーニングは大量のデータが必要という言説がありますが,おそらく思っているよりも少量のデータでもディープラーニングは使えるので,興味を持ったテーマでぜひ何かプロジェクトに取り組んでみましょう.
2. ディープラーニングについてのコースを進めながら,プロジェクトを実行するために必要な情報をメモする
プロジェクトを決めた上で,上で紹介した入門コース(fast.aiとCourseraのディープラーニングコース)を受講しましょう.その際,内容が定着するようにプロジェクトを意識した上でメモを取ると効果的です.
3. プロジェクトで新たな情報が必要になる都度他のリソースにあたり,理解を深める.
受講し終えた段階で,プロジェクトに本格的に取り組み始めましょう.おそらくわからないことがたくさん出てくると思うので,その都度講義を見返したり,新しい資料を参照したりしましょう.筆者は新しいことを学習する際に「3の法則」というのを適用しています.これは,「xxxついてちゃんと学んだ方がいいな」(例えば線形代数やpandasなど)と3度思ったら本格的に1冊の本やコースに取り組むという簡単な法則です.個人個人学び方は違うと思いますが,何れにせよ情報過多に陥らないためにも本を片っ端から読むのではなく,目的意識を持って学ぶようにすることが大切だと思います.
フレームワークの選定について
ディープラーニングを学び始める際に(おそらく)誰もが悩むのはどのフレームワークを使うかです.自分が取り組みたいプロジェクトのexample codeが特定のフレームワークでしかないといった場合は,素直にそのフレームワークを選べばいいと思います.ディープラーニングのフレームワークはどれも急速に発展し,新たなフレームワークもどんどん登場するので,今どんなフレームワークを選ぼうと数年後には別のフレームワークを使っている可能性が高いので,今どれを選ぼうと最終的に大差ないと思います.とは言え,どれかを選ばないといけないので,主要なフレームワークの特徴をまとめていきます.
Tensorflow

ディープラーニングのフレームワークと言えばTensorflowですが,できることならtensorflowは避けたほうがいいと思います.かなりboilerplate(テンプレ的な)コードを自分で書かないといけない点,APIがあまり直感的でない点(Session,Graph,Namespaceなど,普通のPythonプログラマからすると馴染みがない概念が多数登場し,それらを理解しなければいけない),デバッグのしにくさで他のframeworkにかなり見劣りするというのが筆者の意見です.Tensorflowと他のフレームワークの間には,感覚としてCでコードを書くのとPythonでコードを書くこと並みに生産性の差があると思ってもらってもいいかもしれません.
Keras

KerasはTensorflowのwrapperで,面倒なboilerplateコードやSessionなどといった概念を隠し,より直感的にニューラルネットを記述できるようにしています.KerasのAPIは非常にわかりやすく,普通のニューラルネットを学習するだけであれば他のどんなフレームワークよりも効率的に行うことができます.
Kerasのデメリットは柔軟性の低さです.様々な処理を覆い隠しているからちょっと凝った処理を行おうとするとかなり苦労します.そんな凝った処理書かないよ,と思うかもしれませんが,ディープラーニングの技術の発展のスピードは早く,一番良い手法を使おうとすると自分でちょっと高度な処理を書かないといけなくなることが多々あります.したがって,Kerasはディープラーニングを始める上では一番楽なフレームワークかもしれませんが,続ける上では微妙な部分があります.
また,KerasはTensorflowと同様に,あらかじめネットワークを定義し,コンパイルしてから学習を行います.Kerasにはデバッガーがないので,デバッグが大変です.KerasでデバッグすることはgdbなしでCのコードをデバッグするのに近い感覚があります.
PyTorch

もし一つだけフレームワークを学ぶのであれば,PyTorchがおすすめです.まだかなり新しいため色々と荒削りな部分はあるものの,使いやすさと柔軟性のバランスが非常に良いからです.PyTorchの特徴は,KerasやTensorflowと違ってニューラルネットワークをコンパイルせず,ダイナミックな実行方法をとる点です.そのためデバッグがしやすく,処理の柔軟性も高いです.また,Pythonのコードや概念との親和性が高く,tensorflowと違って新たにSessionなどの概念を学び直す必要はなく,基本的にPythonをしっかり理解していればPytorchも理解できます.
Pytorchを使う際のデメリットとしては,学習のループなどの基本的な処理を自分で書かないといけないという点があります.しかし,それも最近torchsampleなどの個人が開発しているライブラリの発展でマシになって来ています.筆者は最初Kerasを使っていましたが,最終的にPytorchへ移行しました.Kerasの方が楽だった部分もあるものの,Pytorchに慣れればなれるほどPytorchに移行してよかったと思います.
Chainer

実はPytorchはもともとChainerのForkです.したがってPyTorchとChainerはかなり似ています.APIや速度などの違いはあるものの,おそらく最大の違いはドキュメントや使用例の充実度です.Pytorchは世界的に使われているためコードの例や英語でのドキュメント,情報が充実しているのに対してChainerはほぼ日本でしか使われていないため日本語での情報は充実しているものの,情報の総量ではPytorchに大きく見劣りします.また,最新の論文もPytorchで実装されていることが多いため,Chainerだと自分で改めて実装する羽目になるなど,何かと苦労すると思います.どうしても英語が嫌な人はChainerでもいいかもしれませんが,将来性を考えるとPytorchの方がいい選択だと思います.
まとめ
この記事では筆者が役に立つと感じたリソースと有効だと感じた学習法について紹介しました.かなり筆者の主観が入っている上に筆者は全てのディープラーニング関連の本を読んでいるわけではないので,偏りや抜け漏れがあるかもしれません.それでもできるだけ多くの人に役立つと思っているリソースを紹介して来たつもりなので,少しでもディープラーニングに興味を持っている人の参考になれば嬉しいです.
また,「この本・コースがとてもよかった」「このリソースも紹介した方がいい」といった意見がある人はぜひコメント欄で教えていただけると筆者としても勉強になるので,大変ありがたいです.
一人でも多くの読者がディープラーニングを有効活用できるようになってくれることを願っています.