10年以上金融機関で働いているインフラエンジニアの落ちないサーバにするための考察です。
ハードウェアの専門家ではないので、正確ではないかもしれません。
今までの経験からの個人的考え方になります。
私たちオンプレ重視のインフラエンジニアは、
クラウドサービスではできない高可用性サーバを導入したり、
複数台構成で1台故障しても問題ない構成のサーバはコスト重視するなど、
システムに最適なサーバを導入しようとしています。
高可用性サーバを追求する目的
■アプリに影響を与えないように
Active/Standby構成にしていて、インフラ的にはダウンタイムが数秒だとしても、
アプリによっては復旧に時間がかかったり、問題ないことの確認にも時間がかかってしまいます。
また、正しくサーバが落ちればアプリが問題ないとしても、
サーバが中途半端な状態のままになってしまい、なんだかおかしいということもあります。
私たちインフラエンジニアは、できる限り落ちないサーバにすることによって、
アプリが問題なく動くようにしたいと考えています。
■仮想化で1ホストで複数ゲストを動かすため
最近は1サーバ(1筐体)ではCPUやメモリーやディスクを使えきれないほど高性能化しており、
コストを抑えるためにも仮想化していく必要がありますが、
サーバ(ホストOS)が停止すると、多くのゲストOSも停止してしまいますので、
できる限り高可用性サーバを使いサーバが落ちることがないようにしたいと考えています。
ハードウェア故障箇所ランキング
ハードウェアの故障箇所のランキングを作成してみました。
このランキングは、某自営保守を行っている販売代理店の人の情報を参考にしています。
| Ranking | 故障個所 | 影響 | 備考 |
|---|---|---|---|
| No.1 | HDD | なし | RAIDで、故障時も影響なし |
| No.2 | FAN | なし | 複数FANが搭載されているため、影響なし |
| No.3 | 電源 | なし | 冗長構成できるため問題なし |
| No.4 | メモリー | なし・大 | エラーチェックによる故障検知だけだと問題なし。 メモリー故障によりOS停止の経験あり。 |
| No.5 | バッテリーキャッシュ | 小 | キャッシュ故障だけなら、OS停止しない。 書き込みが遅くなる。 |
| No.6 | アレイコントローラ | 大 | ファームの不具合の経験あり。 OSが停止してしまう。read onlyになってしまいログインできないが動き続けていることもあります。 |
| No.7 | システムボード | 大 | BIOSの画面も見れなくなってしまう障害です。 何度か経験はあります。 |
| No.8 | CPU | 大 | OSが停止してしまう。 めったに故障しない |
| ランク外 | NIC | 大 | NICドライバーがおかしいことによる疎通不可の経験あり。 OSは停止しないが、OS再起動の必要あり。 |
このランキングを作って思ったことは、
よくあるような多くのハードウェア故障は影響がないということです。
もっとも多いHDD故障でもほとんどないということです。
まして、OSが停止してしまうような大きなハードウェア故障は、発生頻度が少ないということです。
ハードウェア故障原因、サーバ停止原因
今までの経験からハードウェア故障とサーバ停止原因を整理してみたいと思います。
ハードの物理的故障
物理的故障は時々あります。
OSが停止してしまうような大きなハードウェア故障は、発生頻度が少ないです。
私の経験では、OSが停止してしまう物理的ハードウェア故障は、500物理サーバあって、年1台あるかないかくらいです。
ファームウェアのバグ
ファームウェアは以下のハードの中にあるプログラムです。
- アレイコントローラ
- バグの例:アレイコントローラXXXで、まれなケースで 0x13 コードを出力し、システムがハングすることがある
- バグの例:アレイコントローラXXXで、メモリのエラーによって POST コード 0x13 を出力してコントローラがロックアップする可能性がある
- ファイバーチャネル
- NIC
- システムROM(BIOS、UEFI)
- バグの例:BIOSXXXで、iLO4 FW vx.xx を使用している場合、SmartStorageBattery が誤検知され、サーバーがハングすることがある
- バグの例:BIOSの電源設定により、ESXiホストが再起動するバグがありました。
- パフォーマンスを重視するような設定に変えられます
- ハードを制御できるということは、設定によりハードが問題になることも考えられます。
多くの人が使っているデフォルト設定のままの方がいいのかもしれません。
- 管理ツール(例 HPE ilo)
- バグの例:iLO FWvX.XXで、NVDIMM 非搭載構成で SmartStorageBattery 故障時に SMI が過剰に発生し、サーバーがハングすることがある
OSを入れ替えても、ファームウェアはかわりません。
故障で、ハードウェアを交換するとファームウェアのバージョンも変わります。
ベンダーは、問題があり問い合わせると、ファームウェアが古いことが原因かもしれませんので、ファームウェアを最新にしてくださいと言ってきます。
ハード故障といってもファームウェアが引き金になっていることもあります。
ドライバーのバグ
ドライバーは、OSにあるハードを制御しているプログラムです。
故障で、ハードウェアを交換しても、ドライバーのバージョンはかわりません。
ドライバーは、ハードベンダーとOSベンダーが出しているドライバーがあります。
- アレイコントローラ
- ファイバーチャネル
- NIC
- 運用を開始してしばらくすると、NICドライバーの問題で疎通できなくなることがありました。
OS、ハイパーバイザーのバグ
勝手にOS再起動したり、カーネルパニックになったり、ハングしたりもあります。
どのログにも原因が書かれていなく原因不明となることもあります。
もしかしたらOS起動してから日数が経過したことが原因で、
1年毎に定期再起動が必要なのではないかという声もありますが、
実際は本当かどうかわかりません。
サーバ停止原因のまとめ
物理的な故障なら、冗長化できているミッションクリティカルサーバにすることによって対応できますが、
ファームウェアやドライバーやOSのバグに関しては、
ミッションクリティカルサーバにしても発生する可能性があり、問題によってはサーバが停止してしまいます。
# ハードウェアを購入する時に確認したいこと ハードウェアの故障個所と、その原因を整理したことにより、 問題となるファームウェア、ドライバーに対してどのように対応できるかが、 高可用性サーバの選定基準にするのがいいのではないかと考えます。 また、それ以外にもサーバを選定するうえでの判断材料がありますので、まとめたいと思います。
■高可用性サーバにとって、ファームウェアで重要なこと
- サイトで調べる際に、ファームウェアのバグや最新バージョンがわかりやすいか
- サーバで使っているファームウェアのバージョン確認方法が楽であること
- ファームウェアのバージョンアップ方法
- Linux OSからファームのバージョンアップできるか?
- リモートから一斉にBIOSや色々なファームのバージョンアップできるか?
- OSがない状態でのファームのバージョンアップ方法
- 色々な箇所のバージョンアップが含まれるパッケージがあるか?
- ファームウェアの切り戻しがしやすいか。
■高可用性サーバにとって、重要なこと
- ハードウェアの故障の確認方法
- 概要などでエラーがわかるようになっているか。
- ハードウェア故障時にはメールを飛ばせるか。
- 一元管理できるか。
- メールが飛ばなかったり、その時にメールを見過ごしても、後からもハード故障が把握できるか
- 物理的にもLEDによりどこが故障しているかわかるか。
- 故障しているか確認するためのHW診断ができること
- 診断ツールがあることによって、この診断で問題なかったらそのままいきましょうと言える。
- ホットプラグで何を交換可能か(ディスク、FAN、電源など)
■その他考慮すること
- BIOSの設定方法
- 現在どのようなBIOS設定になっているかが、OS起動後でもわかるか?
- 100Vか200Vか。高可用性サーバは200Vが多いです。
- リモートからのコンソール操作のしやすさ。
- ISOイメージのマウント方法
- 密度。(何Uに何台入るか?)
- ラッキングしやすいか。(ドライバー不要か)
各ベンダーが出しているミッションクリティカルサーバ
高可用性サーバを目指す選定基準を整理しましたが、
各ベンダーから一般的なx86サーバよりも、より高可用性を目指しているサーバがありますので、
どのようなものがあるのか、どのように高可用性を実現しているのかをまとめてみました。
IBM Power
- 高速なPOWERプロセッサー搭載。GoogleもPower プロセッサーを採用
- 2Uサーバの小さなサーバがある
- AIX, Red Hat、SUSE、Ubuntu
- 商用OSではない、Ubuntuサポートを打ち出している。
- CPUやメモリーが故障してもOS停止しない工夫。
- 1コアあたり8スレッドまで設定可能
- 1ソケット12コアのマシンであれば、最大で96コアにできる。
- スレッド数は、1 or 2 or 4 or 8 で、アプリケーションにあった最適なスレッド数を変更可能
■気になること
- Power CPUのため、Power CPU用のOS、アプリを入れる必要がある。
- Power CPUのため、商用ミドルウェアが動かないこと、保証対象外になることがある。

HPE Superdome X
- シングルシステムで99.999%の高可用性が得られます
- 他のx86プラットフォームと比較して、20倍優れた信頼性を備え、ダウンタイムを60%低減
- クリティカルなLinuxおよびWindowsのワークロードに最適なプラットフォーム
- Linux、Windows、およびVMware
- OS と連携したメモリや CPU コアの復旧や I/O エラーの封じ込めを実現。復旧が困難と判断した場合には故障したコンポーネント( CPU /メモリ/ブレード)を自動で切り離すこともできます
■気になること
- エンクロージャー型で導入コストが大きい。
- リプレースの時にもエンクロージャーを購入する必要がある。

Fujitsu PRIMEQUEST
インテル Xeonプロセッサーをはじめ、 Windows Server、Linux といった業界標準のオープン・アーキテクチャーをベースに、 富士通がメインフレームで培ったノウハウ、テクノロジーを結集したオープン・ミッションクリティカルサーバ
- Linux/Windows対応
- 内部コンポーネントを徹底的に冗長化
- ソフトウェア側の配慮を必要としないハードウェアによる高可用テクノロジー
- 最長10年の長期保守が可能です。
Strutas FT Server
ストラタステクノロジーが30年以上にわたり培ってきた独自のアーキテクチャによる連続可用性技術が、ダウンタイムによる高額な損失コストの発生を回避し、お客様に「無停止の安心」をお届けします。
- ストラタスのftServerのコンポーネント(CPU、メモリ、チップセット、ディスク、PCI、電源、ファン等)は全てハードウェアレベルで冗長化
- 各種デバイスドライバを一から検証し、強化
- Windows/Red Hat/VMware 搭載の無停止型IAサーバ

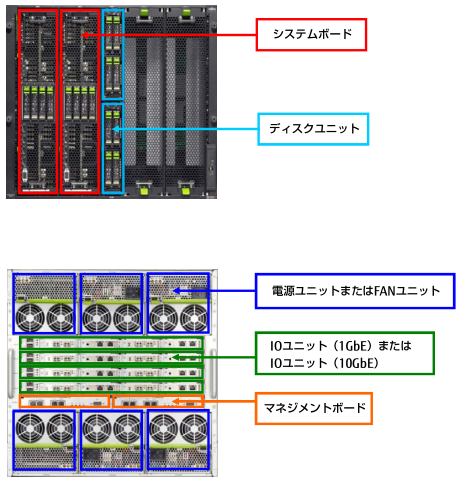
NEC ftサーバ Express5800
-
- Linux、Windows、VMware
- システム停止につながる障害の原因となりやすいサーバのハードウェアを二重化して格納
- 二重化したモジュール全体でホットスワップを実現しているため、障害の発生した部品を交換する際もシステムの停止や再起動は不要。

ミッションクリティカルサーバの特徴まとめ
- ハードウェアの二重化
- 長年の同じ仕組みを使うことによるファームウェア、ドライバーの信頼性
- 長年無停止で使われてきたメインフレームなどの技術を採用
- ハードウェアに問題がある場合、ダンプ機能がしっかりしており、原因の特定が可能
ダウンタイム
ダウンタイムと表現する時、一般的には、「計画外ダウンタイム」になります。
メンテナンスを除いたサーバが動いている時間に対して、
計画外ダウンタイムをどのくらいにするかということです。
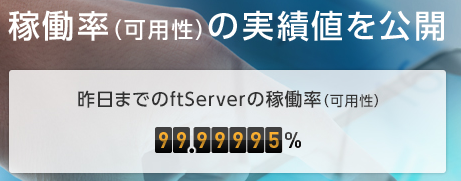
99.999%なら、計画外ダウンタイムが5.25分に抑えられることになります。
私の考え方ですが、高額な高可用性サーバなら、故障なしで、ダウンタイム0秒を期待してしまいます。
ダウンしたサーバを早く復旧させるのは、高可用性サーバの特徴ではなく、クラスターソフトなどの役割です。
一度ダウンしてしまったサーバをOS再起動して、復旧すればそれでいいのかといったら、そんなことは期待していないです。
この数値が大きければサーバが壊れにくいという目安ぐらいにとらえたいと思います。
| Availability | 読み方 | 年間のダウンタイム | 実現方法 |
|---|---|---|---|
| 99.9999% | six nine | 31秒 | |
| 99.999% | five nine | 5分 | HPE Superdome X FT Server |
| 99.99% | four nine | 53分 | HA クラスターソフトウェア Amazon S3 |
| 99.9% | three nine | 8時間45分 | 一般的なパブリック・クラウド |
| 99% | two nine | 3日15.6時間 |
参考
2011年、Google AppsのSLAから、計画外ダウンタイムを外し、
全てのダウンタイムをカウントすることになったそうです。
わかりやすいですね。
ただ、その目安も99.99%で、年間で53分以内に抑えるということで、利用者としては
使えなくなることもあるということを考えておく必要があります。
# UNIXという選択肢 UNIX OSとしては、IBMのAIX, HPEのHP-UX, OracleのSolarisなどがあります。
- OSサポート期間が長い。
- サーバリプレースしないで長いこと使える。
- UNIXサーバはミッションクリティカルサーバで使われるので、ハードの保守も長い。
- ハード保守が高い。ベンダーによっては、標準保守が切れた5年後に保守費用が高騰する。
- ハードウェアとOSが同じベンダーであり、ファームウェアの信頼性が高い。
# 落ちにくい高可用性サーバはどのように選ぶか
-
ハードウェアは販売開始してから、少し経過した機種の方が、ファームが改善されていてよい。
- 新しいハードウェアはどんどんファームが改善される。(またそうならないといけない。)
- 高可用性のためには、新しめのハードウェアは選択しない。ファームが心配。
- 販売されてから様子をみて、1,2年後くらいが目途。(斬新な仕組みのハードは、もっと遅らせてもよい)
- 最新のハードの技術を利用したいのでなければ、少し古いサーバで十分
- OSが停止してしまうようなハードウェア故障(CPU故障、アレイコントローラ)の確率は少ないが、停止する確率を下げたいサーバは、ミッションクリティカルサーバを採用する。
高可用性サーバにするためにどのように運用するか
-
ファームウェアは構築時に最新にしておく。
- 一世代前ではなく、最新のファームウェアを使う。
- バグ対応が基本のファームウェアに関しては、出てきたばかりのファームウェアでもよい。
(あまりに新しすぎるのは問題だが。) - 利用開始前に最新のファームウェアにしたら、運用開始後は、問題がなければバージョンアップはしない。
今まで問題がなかったのに、問題がでるようになっては困る。
- サーバリプレースなどホストを停止させることができるのであれば、ファームとOSは新しいものにしておきましょう。
- OSもマイナーバージョンの最新を使う。(CentOS7.2ではなく、CentOS7.3を使う)
-
構築時に、全ソフト(ドライバー含む)を最新まであげておく。
yum update - 利用開始前に最新のパッケージにしたら、運用開始後は、問題がなければパッケージアップグレードはしない。
アップグレードすることによって、今まで問題がなかったのに、問題がでるようになっては困る。
-
構築時に、全ソフト(ドライバー含む)を最新まであげておく。
- OSのメジャーバージョンが変わる際には、すぐ使うのではなく、様子を見てから使う。
-
サーバを構築してから、すぐに本番利用をしない。
- 例えば、1カ月などOSを起動している期間を設けてから本番利用する。
- インフラはできる限り早く構築して、起動期間を設けて、引き渡すのがよいです。
- 開発への引き渡し期限ぎりぎりで作らないこと。
# まとめ
- 物理的故障によりサーバが落ちることは少ない。(500台物理サーバがあって、年1台あるかないかくらい)
- 何度も同じ箇所が故障するのは、ハードベンダーが出しているファームウェアの不具合
- 特に新しいハードウェアの技術を使いたいということがないのであれば、少し古いサーバでも問題ない。
- ファームウェアの問題を少なくするために、ハードが販売開始されて少し間をおいてから購入し、ファームも最新を使う。
- できる限り早くOSを入れて構築し、ある程度期間を置いてから本番利用することで、少しでもバグを避ける
- ハードが冗長化されているミッションクリティカルサーバでも、ファームやドライバーやOSのバグがあったら停止する。
- ミッションクリティカルサーバを導入したからといって、サーバが落ちないとは言い切れない。
どのようなハードウェアでも停止しないサーバはないので、故障時の影響を少なくするために、
ゲストOSを入れすぎないということも重要だと思います。
同じ信頼性のサーバなら、高性能なサーバ1台よりも、高密度サーバを2台購入するという工夫をしましょう。
高密度サーバの今の目安としては、1U2ホストです。5Uなら、10ホスト。10Uなら20ホストくらいです。