ディープラーニングは特定分野で非常に高い精度が出せることもあり、その応用範囲はどんどん広がっています。
しかし、そんなディープラーニングにも弱点はあります。その中でも大きい問題点が、「何を根拠に判断しているかよくわからない」ということです。
ディープラーニングは、学習の過程でデータ内の特徴それ自体を学習するのが得意という特性があります。これにより「人が特徴を抽出する必要がない」と言われたりもしますが、逆に言えばどんな特徴を抽出するかはネットワーク任せということです。抽出された特徴はその名の通りディープなネットワークの中の重みに潜在しており、そこから学習された「何か」を人間が理解可能な形で取り出すというのは至難の業です。

例題:このネットワークが何を根拠に猫を猫として判断しているか、ネットワークの重みを可視化した上図から答えよ(制限時間:3分) image from CS231n Visualizations
「何かを学んでいるはずだが、何を学んでいるかはよくわからない」
これがディープラーニングにおける、解釈性の問題になります。
ただ、この点については近年研究が進んでおり、その判断根拠を明らかにする手法がいくつか提案されています。本文書では、それらの手法について紹介をしていきたいと思います。
1.判断根拠を理解することの意義
「精度が高いならそれでいいじゃん?」という説もあるので、まず説明力を持たせることのメリットについていくつか事例を交えて紹介します。
以下は、画像の分類において予測をするのに重要な手がかりとなったピクセルを可視化する研究になります。

SMOOTHGRAD // SmoothGrad: removing noise by adding noise
左が入力画像で、右の白黒画像が判断に重要な個所を可視化したものです(上が既存手法、下が提案手法)。病理診断のモデルに適用すれば、レントゲン写真などの画像のどこに着目して診断をしたのかを明らかにすることができるでしょう。「あなたは病気です。なぜかはわからんけど、高い確率で」と言われても納得しがたいように、下された判断に納得するにはその過程の共有というのが重要なプロセスになります。ディープラーニングは画像の分野で大きな成果を収めていますが、こうした手法はその判断過程を理解するための有効な手法になります。
次に紹介するのは、SNS上の発言から危機的状況(自殺しちゃいそうなど)かどうかを検知するだけでなく、検知の根拠を提示するという研究です。
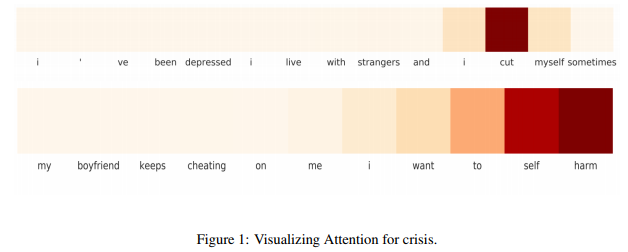
Detecting and Explaining Crisis
この研究では自然言語処理でよく利用されるAttentionという技法を用いて、発言内の各単語に対して判断に対する重要度を算出し、それを可視化しています。SNS上での発言はとても多いので、その中から危険度の高いものを優先順位付け(トリアージ)することで対応に役立てようとしています(ちなみにこの研究を共同で行っているKokoはMIT Media Lab発のベンチャーで、メッセンジャーアプリを通じての悩み相談機能など提供しています。研究機関出身ということもあり、最新の研究成果をサービスに活かすとしている点も特徴です)。
このAttentionの技法を画像キャプショニングに応用し、キャプションを生成する際に画像のどこに注目しているのかを明らかにする研究などもあります。

Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
何れの研究も、機械学習モデルの判断をもとに人が行動する(業務を行う)ことを想定しているといえると思います。今後さまざまな領域で機械学習が活用されていくと思いますが、人と機械学習モデルとが協調して動くには、こうした仕組みが必要不可欠ではないかと思います。欧州ではこの点についての検討が行われており、いわゆるAIが搭載された機器についてユーザーが求めた場合その判断過程を提示できるようにすべきではないか、ということも検討されています。
また、機械学習モデルの振る舞いを検証するという面でも意義があります。というのも近年では、学習モデルを「ハッキング」する手法があることが報告されているためです。これはAdversarial Attackとも言われていて、入力画像に一目ではわからない微細なノイズを乗せることで認識結果を誤認させることができるというものです。以下の図では、入力画像にノイズを加えることでパンダがテナガザルに誤認されています。
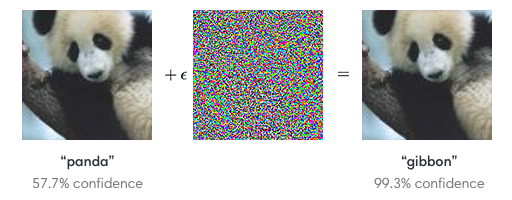
Intriguing properties of neural networks
さらに、道路標識を誤認させるようなことも可能という研究もあります。自動運転を行っている際に停止の標識が誤認されたら・・・と考えるとちょっとぞっとする事例です。この手法については、機械学習のトップカンファレンスであるNIPSでもその手法と防衛方法がコンペティション形式で活発に検討されています。
機械学習モデルの判断根拠を理解することで、こうした攻撃を受けた際に「普段とは違う根拠」であることに気づける可能性があります。それに、別に攻撃を受けなくても純粋にデータの傾向(ユーザーの行動など)が変わることで精度が落ちることもあります。この場合でもモデルが依拠していた特徴量がわかれば対応がとりやすいです。つまり自分たちの利用しているモデルをメンテナンスしていくという面でも、判断根拠の解釈が重要になってくるということです。
2.判断根拠の「理解」の定義
ここからは、実際にディープラーニングの判断根拠を「理解」する方法について見ていきます。しかし、何をもって「理解」とするのかは曖昧であるため、ここでいくつか定義をしておきます。
まず、モデルの理解という面では以下2つの観点があります。
- 仕組みの理解:モデルの中でどのような作用が働いて出力に至っているのか、というプロセスを理解する。ホワイトボックス的な理解。
- 挙動の理解:どんな入力をしたらどんな出力がでるかだけ理解する。ブラックボックス的な理解(中で何がどうなっているのかは気にしない)。
実際に利用されるモデルはいろいろな種類があるため、逐一中身の仕組みを理解していくのは大変です。そのため、ここでは「挙動の理解」に焦点を当てます。具体的には学習済みのモデルが与えられている状態からスタートし、どんな入力をしたらどんな出力が得られるのかを「説明」できれば「理解」ができたこととします。自動販売機でいえばどんなボタンを押したらどんなドリンクが出てくるか理解できればokで、ボタンを押したら内部の機械のアレにコレな信号が走って・・・という内部の仕組みは置いておく、ということです。
さて、「説明」は人間に対して行うので、当然人間が理解可能な「表現」で行われる必要があります。ただ、「表現」できれば説明できたことになるかというとそうではありません。先ほど示したネットワークの重みを可視化した画像のように、人間が認識可能な表現であってもそれが説明力を持っているかというとまた別の話になります。
この表現と説明の差異を、以下のように定義します。
- 表現:人間が理解可能な表現、具体的には画像(可視化)やテキストに変換する。※数値や単語の単なる羅列は表現には該当しない
- 説明:ネットワークの出力に貢献を行っている特徴量(入力画像内のピクセルや、入力テキスト中の単語etc)を、「表現」すること
つまり、「説明」とは単に可視化や文章化といった「表現」を行うことではなく、「ネットワークの出力に貢献を行っている特徴量」を「表現」して初めて「説明」になる、ということです。つまり、説明を行うためには出力に対する各入力の影響度を算出すること、それを人が理解可能な形で表現すること、の2つの工程が含まれます。以後紹介する手法においても、この2点について工夫がとられています。
3.学習されたネットワークの「説明」に挑戦する
ここからは、実際にネットワークの出力を説明する手法を紹介していきます。手法は、大きく以下のように分けられます。
- ネットワークの出力を最大化する入力を作成する
- 入力に対する感度を分析する
- 出力から入力までの経路を逆にたどる
- 様々な入力から出力の傾向を推定する
- 変更量から判断基準を類推する
- 学習結果が予測可能になるよう矯正する
- 入力に対する着眼点をモデルに組み込む
最後の着眼点をモデルに組み込む(Attention)についてはネットワーク自体に手を入れる必要があるためブラックボックスという観点から外れてしまいますが、非常に有効な手法であるためここで紹介をします。
3.1 ネットワークの出力を最大化する入力を作成する(Activation Maximization)
分類問題を扱うネットワークの場合、その出力は各カテゴリに対する分類確率になります。ここで、あるカテゴリの分類確率が非常に高い入力を見つけることができれば、それはネットワークがそのカテゴリの「代表例」ととらえていることと同義であり、それを特定できれば判断根拠の推定に役立ちそうです。
以下はGoogleが2012年に発表した、教師なし学習(Auto encoder)で画像の特徴を学ばせたネットワークに識別を行わせる研究で、最も人らしいと判定されたデータ(上)と、最も人と判定されるデータを合成したもの(下)です。

Building high-level features using large scale unsupervised learning
こちらは、基本的にミニマムな入力であるクラス$c$に分類される確率$p$を最大化する$x^*$を見つけるという問題になります。
$$
x^* = max_x \log p(w_c|x) - \lambda ||x||^2
$$
($||x||^2 = 1$として単位球面上にする制約をかける手法もある)
ただ、こうすると確かに出力は最大だけれども人間が理解できないような謎の画像が生まれる可能性もあるので(過学習のような状態)、さらに実際の入力に近いもの、という制約をかけるパターンもあります。
$$
x^* = max_x \log p(w_c|x) + \log p(x)
$$
$p(x)$、つまり実際にデータが登場するであろう確率を加えるということです。これと同等の制約を用いて画像特徴の可視化を行った研究があります。

Understanding Deep Image Representations by Inverting Them
ただ、入力データが高次元だったりするとこの$p(x)$を精度高く推定することがとても難しくなったりします。なので、VAEやGANのような生成モデルと組み合わせて行うという手法もあります。ここでは、$x^*$は適当なベクトル$z$からGeneratorを通じて生成されることになります。
$$
max_{z \in Z} \log p(w_c|g(z)) - \lambda ||z||^2
$$
クラス$w_c$に分類されるような画像を$z$から生成させる、という形です。画像の生成といえばGANですが、GANの方面でもこの制約と同等、つまり生成した画像が本物のクラスと同じクラスに分類されるようにする制約を加えた研究があります(Conditional Image Synthesis With Auxiliary Classifier GANs)。

なお、GANが目指しているところと判断根拠の理解において目指しているところはちょっと異なります(端的に言えば、本物っぽいものよりある程度抽象化されていた方が良い)。そのため、上式では$\lambda||z||^2$の制約を効かせて表現の幅を抑えています。
ちなみに、一時話題になったDeep Dreamはこの手法を用いたものです。入力した画像(やランダムなノイズ)を、ネットワークの出力が最大になるよう最適化していくとああした画像になるということです。
こちらの記事では、このActivation Maximizationによる画像特徴の可視化について、詳しい解説が行われています(以下の画像も、その記事から引用しています)。

なお、この記事の続編としてページ上でインタラクティブに判断根拠が見られるデモを含んだ記事が公開されています。この記事ではさらに一歩踏み込んで、ネットワークの「どこが」各クラスの判断を最大化するのに寄与するのか特定しようと試みています。
The Building Blocks of Interpretability
3.2. 入力に対する感度を分析する(Sensitivity Analysis)
入力された特徴量の中で、それを変化させることで出力に大きな影響が出るものがある場合、それは重要な特徴量と考えることができます。つまり、ネットワークがどの入力に対して敏感なのか、という変化量を調べることでその重要がわかりそうです。
変化量と言えば微分の出番なので、これは勾配(Gradient)を調べることで達成できます。ニューラルネットはそもそも勾配により学習するので、これは既にある最適化の仕組みとも相性が良いです。以下のように、簡単に入力$x$に対する感度を計算することができます。
$$
S(x) = (\frac{\partial f}{\partial x})^2
$$
※絶対値の場合もある
冒頭で紹介したSMOOTHGRADは、これをよりきれいに見えるよう工夫を加えたものになります(勾配がノイズに敏感すぎるので、意図的にノイズを加えた複数のサンプルを作成し、それらの結果を平均してならす)。
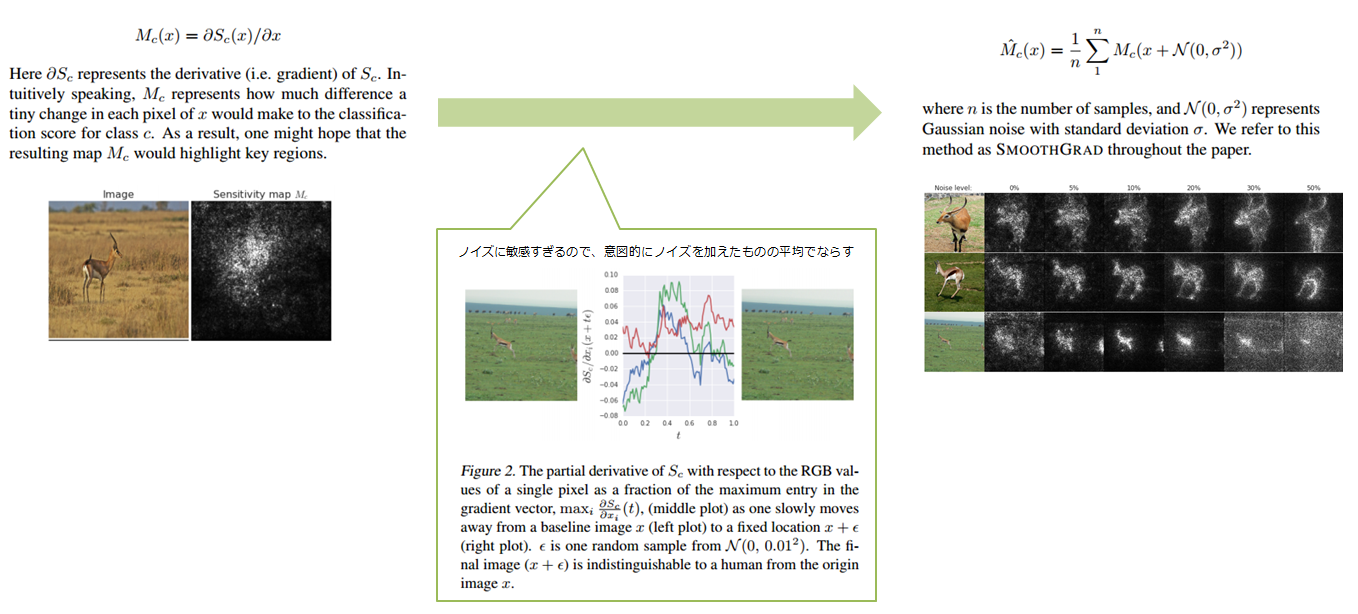
ただ、これで得られるのは誤差を大きく/小さくするのはどの部分の変化か、ということです。例えばどこを変化させればより車っぽくなるか、などはわかりますがそもそもなぜ車と判断されているのか、といったことはわかりません。この点については、利用する際に意識しておく必要があります。
3.3. 出力から入力までの経路を逆にたどる(Deconvolution/LRP)
次に紹介するアイデアは、出力から入力を逆にたどれば何か意味がある結果が得られるのではないか、というものです。
以下は、ネットワークをある層まで伝搬させて、その後調べたい個所以外を0にして逆伝搬すれば、その箇所に貢献している入力が逆算できる、という手法を提案しています。
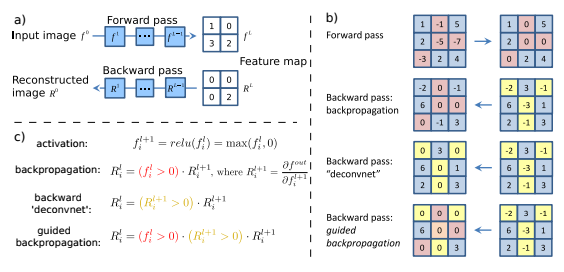
Striving for Simplicity: The All Convolutional Net
この逆伝搬においてActivationを減衰させるようなマイナスの値を取り除くために、伝搬/逆伝搬時に値がマイナスになるような箇所を0にして伝搬しています(結果的に、ReLUと同等な非線形の処理を行っている)。先の研究ではこれを"guided backpropagation"と名付けておりその結果以下のような入力において重要な点の可視化に成功しています。

クラスの分類に寄与したところだけ知りたい、ということで望まれるラベルから勾配を逆にたどるという手法も提案されています。
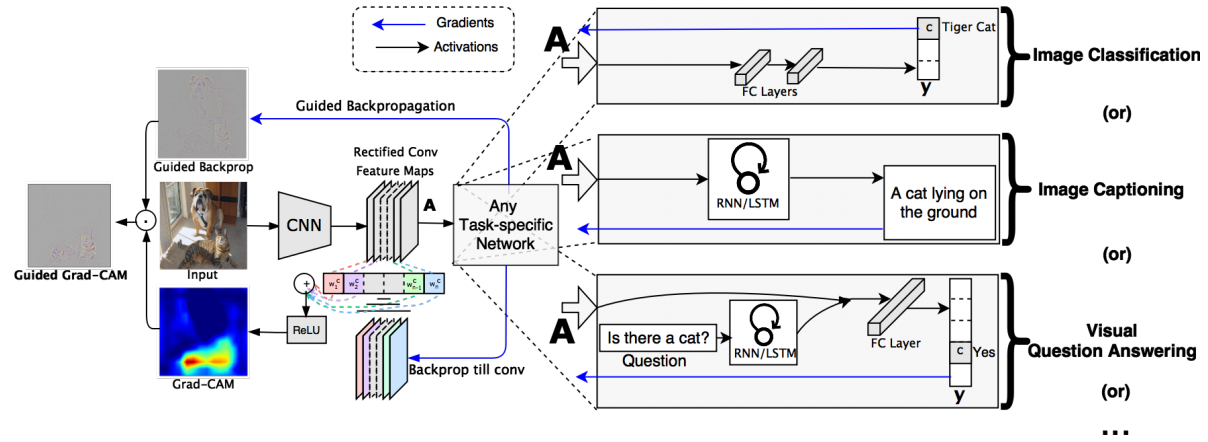
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
これはクラス分類に至るまでの各特徴マップの貢献を算出し、その重みをもって逆伝搬していくという手法です。これによりヒートマップライクな出力(上図の左から二番目の列の最下部にあるGrad-CAMの図)を得ることができます。ただ、貢献度の算出がマップ単位のため上述のGuided backpropagationのようにピクセル単位の貢献を得ることはできません。そのため、合わせて使うといいとも上記の論文では言われています( Guided Grad-CAM)。Grad-CAMの詳細な解説と実際に適用したみた結果は、以下のブログで紹介されています。
深層学習は画像のどこを見ている!? CNNで「お好み焼き」と「ピザ」の違いを検証
Layer-wise relevance propagation(LRP)は、レイヤー間の関係性を逆に伝搬していき、入力にたどり着くという手法です。アイデアとしては、出力に対する各入力の貢献の総和は各レイヤ間で等しく、伝搬を通じてその配分が変わっているに過ぎない、というのがベースにあります。
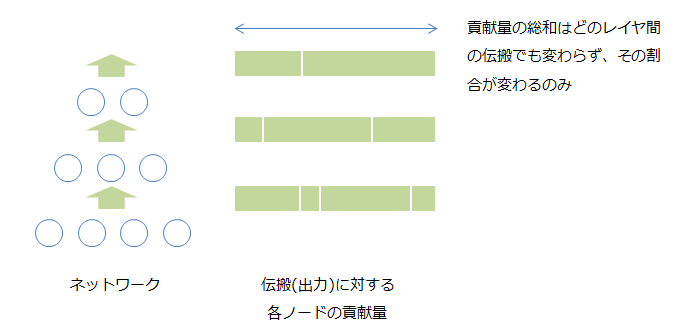
ではこの貢献量(Relevance)をどう算出するのかですが、以下のような設定になります(導出はExplaining nonlinear classification decisions with deep Taylor decompositionを参照)。

通常の伝搬はReLUでのactivation(表一番上)で、画像を受け取る入力層のように値の範囲が限定されている場合(0~255)はテーブル中央のルール(Pixel intensities=closed interval)が適用されます。これを実際に実装するチュートリアルも公開されており、試してみることができます。
Tutorial: Implementing Layer-Wise Relevance Propagation
こちらのサイトではデモも公開されており、自分の書いた画像に対するLRPの結果を参照できます。
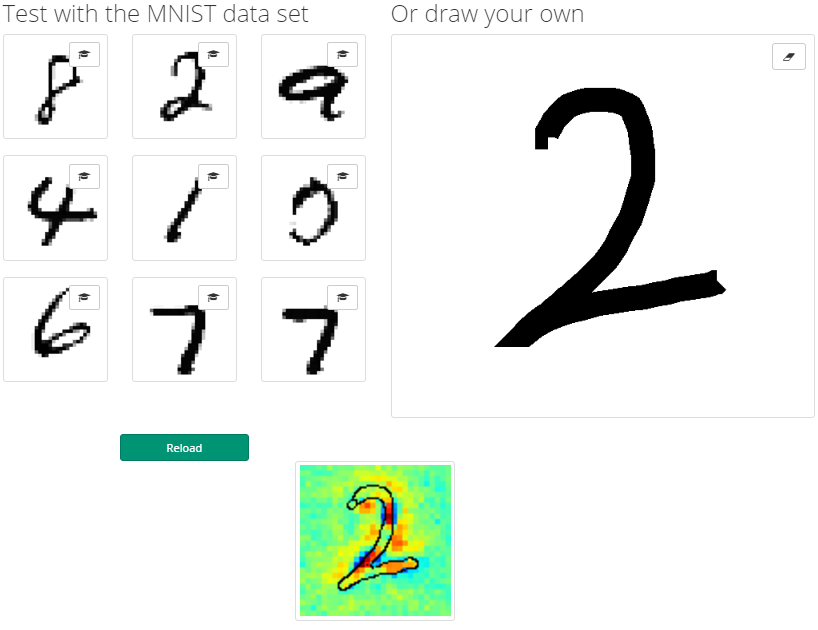
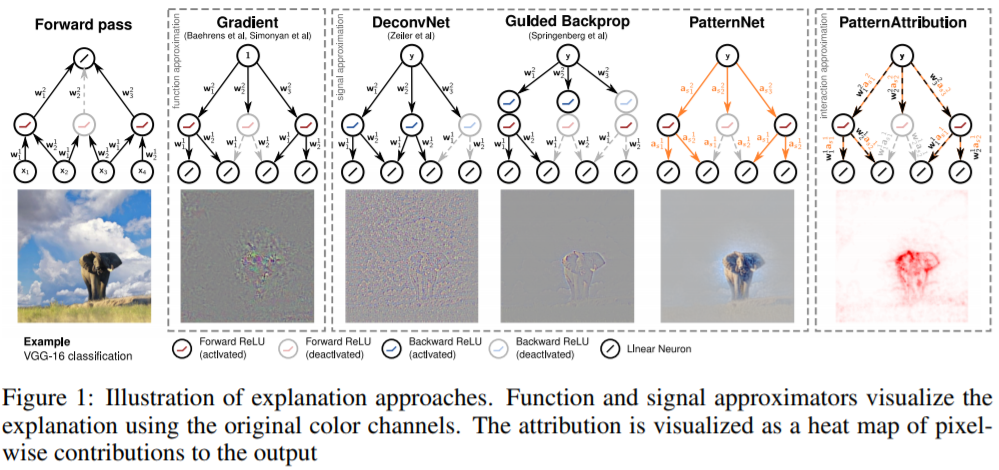
なお、これらの手法の改良版としてPatternNet/PatternAttributionという手法が提案されています。
Learning how to explain neural networks: PatternNet and PatternAttribution
この論文は、まずネットワーク中の「重み」を分析するだけでは判断根拠を理解することはできないとしています。
その理由ですが、まず入力$x$を最終的な出力$y$に寄与する$s$とそれ以外(つまりノイズ)の$d$に分け、$x=s+d$と表現してみます。
この時、シンプルなネットワークの出力が$w^T x = y$になることを考えると、重み$w$は$x$から$d$をフィルタし、$y$に貢献する$s$を抽出する役割を持っていると考えることができます。
とすると、重み$w$の役割はノイズ$d$をキャンセルすることであり、そのため$w$のベクトル方向は$d$に依存することになります。これでは、いくら調べても$s$を見つけることはできません。以下の図は黒い矢印が$w$で、黄色い矢印が$d$となっており、互いにキャンセルする方向を向いていることがわかります。$w$の方向は$d$に依存し、求めたい$s$とは全く関係がありません。

このとき、$y = w^T x = w^T (s + d)$であり、$d$は$w$でキャンセルされるはずなので$w^T d = 0$で$w^T s = y$となります。また$y$と$d$は相関が全くないはずなので、$cov[y, d] = 0$であり、$cov[x, y]$は$cov[s, y]$と等価になります。$x$から$s$を抽出する関数を$S(x)$とすると、$cov[s, y] = cov[S(x), y]$となります。これを利用し、$S(x)$を求めることができます。
まず、線形変換の場合は線形の$y$しか出力できない=$s$も線形となるはずなので、その相関は線形の関係になるはずです。つまり、以下の式が成り立ちます。
$$
s = ay => S_a(x) = a w^T x
$$
これを先ほどの$cov$の関係に代入すると、
$$
cov[x, y] = cov[S(x), y] => cov[a w^T x, y] = a cov[w^T x, y] = a cov[y, y]
$$
ここから、
$$
a = \frac{cov[x, y]}{cov[y, y]} = \frac{cov[x, y]}{\sigma_y^2}
$$
となります。ただ、これはあくまで線形の場合で、画像で良く使用されるReLUではマイナス方向は伝搬しない非線形の関数になります。この場合は、$s$, $d$についてもプラス方向の$s_+, d_+$、マイナス方向の$s_-, d_-$に分けて考える必要があります。この導出式は省略しますが、こうして逆伝搬する値を$s_+, s_-$に置き換えたものが強化版DeConvNet/Guided Backpropagation、LRPで、それぞれPatternNetとPatternAttributionと名付けられています。
また、$S(x)$の抽出能力を以下の評価指標$\rho$で計測することができます。
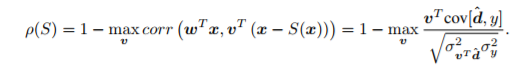
$x - S(x)$は、$S(x)$が完全に$s$を抜ければ残骸である$d$しか残らないので、$w^T x = y$との相関性は非常に低くなり結果として値が高くなります。
これで、より精度の高い判断根拠の推定と、その推定能力の計測ができるようになります。
3.4. 様々な入力から出力の傾向を推定する(LIME)
単体の入力からでなく、様々に変形させた入力からモデルの挙動を探ろう、というのが次に紹介するアイデアです。これは“Why Should I Trust You?” Explaining the Predictions of Any Classifierで提案されたLIME(Local Interpretable Model-Agnostic Explanations)になります。
手法としては、まずオリジナルの画像をいくつかのパーツに分けたような入力を生成します。それを学習済みのモデルに食わせて、判断結果を得ます。そうすると入力とモデルの判断結果のペアが得られます。これを、本体のモデルとは別に用意したより単純かつ説明力の高いモデルに学習させます。
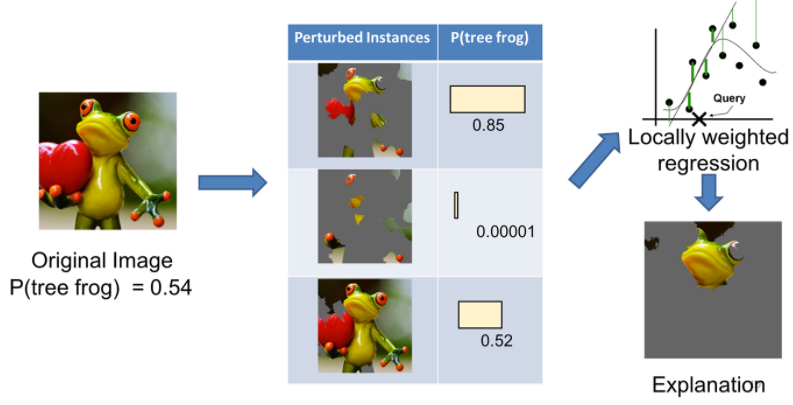
Introduction to Local Interpretable Model-Agnostic Explanations (LIME)
そうすると、学習させた単純なモデルから重要視されている特徴量が得られる、という寸法です。手法がシンプルである分、これはどんなモデルに対しても適用可能が可能です。以下の記事で、より詳しい解説と実際に使ってみた結果が紹介されています。
この入力データの変動に対する、出力への影響を定式化した研究として、Understanding Black-box Predictions via Influence Functionsがあります。各学習データの影響と、学習データに対する変更の影響双方について定式化しており、これによりモデルの判断に貢献する/判断精度を下げるようなサンプルの特定や、モデルの判断に影響を与える変更などを導くことができます。
また、画像にマスクをかけることでどこが重要かを洗い出す、というLIMEの仕組みを機械学習モデル化した研究があります(画像認識モデルに対する、マスクのかけ方を学習する)。これにより、マスクをかけた部分=重要な個所、として可視化することができます。

Interpretable Explanations of Black Boxes by Meaningful Perturbation
3.5. 変更量から判断基準を類推する
AはOKです、BはNGです、という結果があった際に、ではどうすればBをOKにできる/近づけることができるのか?ということがわかれば、何がOKとNGの間にあるのか=判断基準がわかりそうです。この点に着目した研究として、以下の論文があります。
Interpretable Predictions of Tree-based Ensembles via Actionable Feature Tweaking
これは決定木を用いたアンサンブル学習をベースとした手法で、各決定木においてNGなxをOKに持って行くための変更量を算出し、その中から最小の変更量を求めることで最小コストでOKにする変更量を求める、という手法です。この論文ではこれを広告配信に応用し、「売れない」広告を「売れる」広告にすることを試みています(これは変更料に応じた適切な広告料の設定に活かされます)。
3.6. 学習結果が予測可能になるよう矯正する(Constrain)
これは逆転の発想で、そもそも理解できないような判断をしないようにするというアイデアです。
下記はコーヒーショップの推薦を学習させようとしたタスクで、通常は近くにあるコーヒーショップの方が良いですが、実際に学習させるとデータの不足から遠くにあるのに推薦するといった誤った予測をするようになっています(左図)。これを防止するため、傾向が「単調」になるような制約をかけています(右図)。
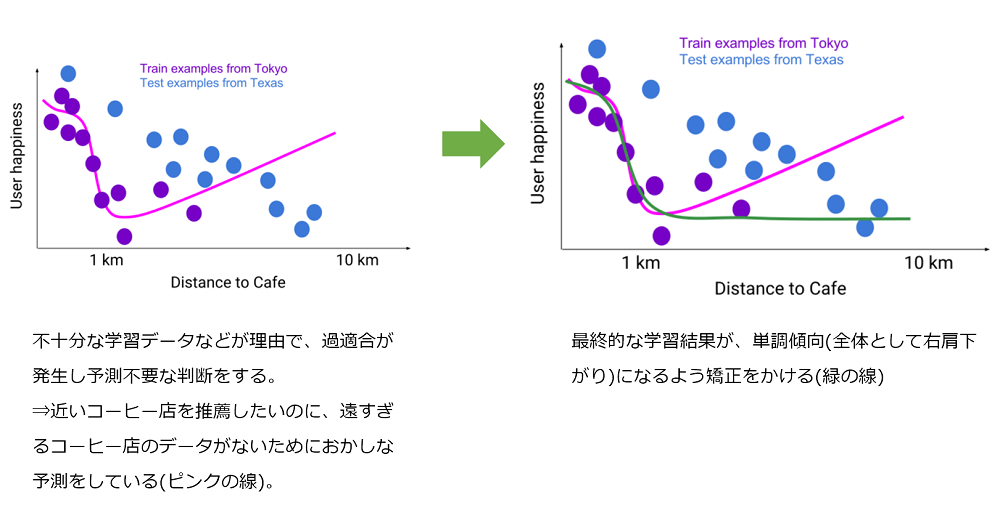
TensorFlow Lattice: Flexibility Empowered by Prior Knowledge
実装:tensorflow/lattice
コンセプトとしては、モデルの表現力を活かしつつ全体の傾向を制御するというものです。これにより、線形のモデルなどをばしっと当てるより細かな傾向を反映できます。そもそもデータを増やせば、ということもありますが、手に入らない場合も往々にしてあります。
制約をかけることで本来対応すべき状況に対応できなくなるリスクもありますが、その分予測不可能な挙動を取るリスクを避けることができます。この点はトレードオフになるでしょう。
3.7. 入力に対する着眼点をモデルに組み込む(Attention)
最後に、モデルに対して入力データに対する着目点を示すような機構を導入する手法について紹介します。これはAttentionと呼ばれる手法です。おそらく初出は翻訳モデルへの適用で、翻訳先の単語を出力する際に元文のどの単語に注目するかを学習させる仕組みとして登場しました。下図はx軸が元文でy軸が翻訳先文となっており、翻訳先文の単語が出力される際に元文のどの単語を参照しているのかが図示されています。
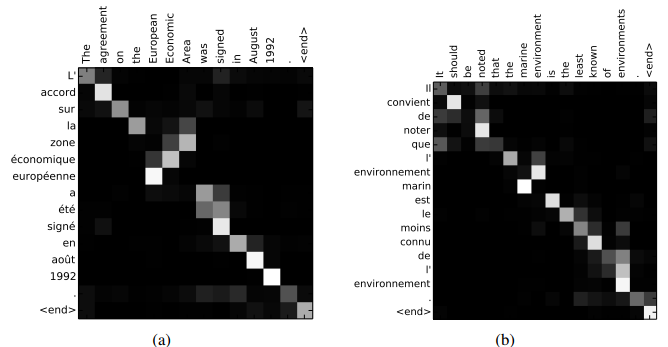
Neural Machine Translation by Jointly Learning to Align and Translate
Attentionの基本的な考え方は、出力を行う際に直前の隠れ層だけでなく過去の隠れ層も利用しようということで、その際に重要な個所により重みを配分するというものです。
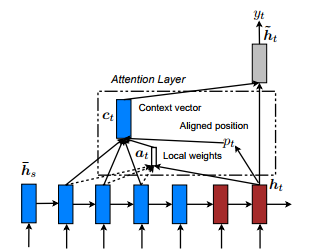
Effective Approaches to Attention-based Neural Machine Translation
時刻$t$における隠れ層が$h_t$、過去の隠れ層が$\overline{h_s}$で与えられるとき、それらに対するAttention(重み)は以下のように定義できます。
$$
a_t(s) = \frac{exp(score(h_t, \overline{h_s}))}{\sum_{s'}exp(score(h_t, \overline{h_s}))}
$$
scoreは、単純に内積をとったりAttention用の重み用意するなどいろいろバリエーションがあります。
そして、このAttention(重み)をかけて時刻$t$の出力ためのベクトル(コンテキスト)$c$を作成します。なんだか難しいことをやっているように感じるかもしれませんが、ざっくりいえば加重平均をとっているのと同等です。
$$
c_t = \sum_s a_t(s) \overline{h_s}
$$
これがAttentionの基本的な仕組みになります。これにより、現在に連なる系列データのうちどこを重要視しているのかを、$a_t$より得ることができます。
4.説明力の評価
上記では様々な「説明」を行う手法を紹介してきましたが、ではその「説明力」を検証する方法はあるでしょうか。その観点としては、以下の2点があります。
- 説明の一貫性
- ある入力に対する説明は、その入力に近いデータに対する説明と近しいはず=似ているデータは似ている説明がなされるはず
- 説明の正当性
- 説明において重要とされている特徴量は、モデルの判断にとっても重要な特徴量のはず=もし説明において重要とされている特徴量を抜いたら、モデルの判断に大きな影響を与えるはず
- 実装普遍性
- ネットワークの構成は違っても出力は全く同じ場合、説明の手法は2つのネットワーク間で一致するはず
4.1 説明の一貫性の評価
説明の一貫性については、例えば入力が画像の場合徐々にスライドしていくなどした場合にその説明がどう変化するのかを見ることで確認ができます。下図では数字の2の画像を右にずらしていったときに、その説明($R(x)$)がどう変化するかを手法ごとに比較しています(一番右のLRPがずらした時の影響度が少ないことがわかる)。
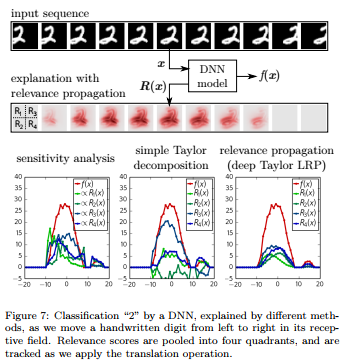
Methods for Interpreting and Understanding Deep Neural Networks
4.2 説明の正当性の評価
説明の正当性については、pixel flippingと呼ばれる手法があります。これは、説明において重要とされたピクセル(データが自然言語の場合は単語)を徐々に抜いていき、その精度の変化度合いを測るものです。下図では、重要なピクセルから抜いていった場合にその分類精度がどう下がっていくのかが図示されています(これもLRPが最も急激に落ちており、説明力が高いことがわかります)。
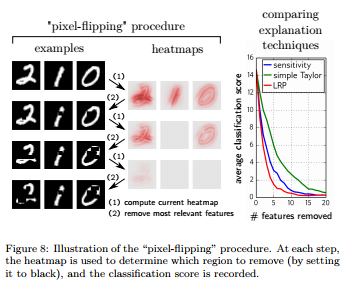
Methods for Interpreting and Understanding Deep Neural Networks
これらの手法を利用することで、説明に利用した手法の「説明力」を検証することができます。
4.3 実装普遍性
ブラックボックスで行う判断根拠の推定は、基本的に入力と出力しか見ません。これは中で何をしているかは脇に置くということであり、そのため中がどんなネットワークでも入力と出力が一致している以上、その判断根拠の推定は同じになっていなくてはならない・・・ということです。
5.応用事例
これまで紹介してきたような、DNNの判断を説明する手法を用いてどのようなことが可能になるでしょうか。DNNは表現学習(特徴抽出)がとても得意なので、人がそもそも特徴をよく認識できない対象に対してその表現を学習させ、さらにその説明を行わせることで新しい気付きを得ることが可能かもしれません。
以下は分子構造を学習させたモデルを用いて、分子構造を成すのに貢献している原子間の関係性を可視化したものです(この発表をした論文を読むのに化学知識がだいぶ要求されるので、この記述はちょっと不正確かもしれませんが)。
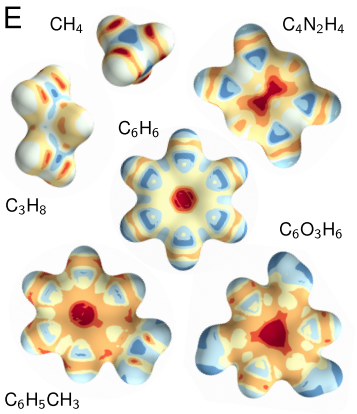
Quantum-Chemical Insights from Deep Tensor Neural Networks
AlphaGoは囲碁において人を上回る成果を収めましたが、AlphaGoがもし高い説明力を持っていれば、囲碁について人はより多くの知見を得ることができたはずです。まだ人が解明しきれていない研究分野はたくさんあります。その解明に挑戦していく際に、ディープラーニングの力は大きな一助となると思います。
科学の分野だけでなく、社会科学の分野においても解明されていない課題は多くあります。なぜ人は争い続けるのか・・・、というのは大げさですが、近年ではテロ事件のデータなどもまとめられてきています。
こうしたデータから何か有効な施策の手がかりが得られる可能性もあります。余談ですが、冒頭で紹介したSNS上の発言から危機的状況を検知する研究を行っているコロンビア大学では、ギャングの抗争が起きる予兆をSNSから検知する研究も行っています。これは、ソーシャルワーカーと連携しデータのアノテーション作業などを行ったそうです。
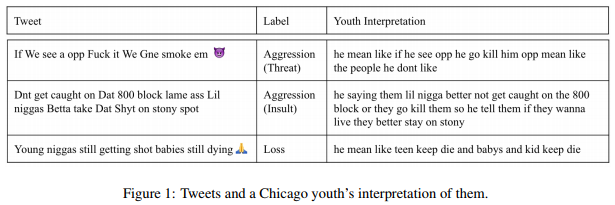
Automatically Processing Tweets from Gang-Involved Youth: Towards Detecting Loss and Aggression
地震が多い日本では、災害対策に活かすというのも有望な活用方法です。東日本大震災前後の衛星画像で、津波の被害を受けて無事だったものとそうでないものをアノテーションしたABCDdatasetというものがあります。

建物が被害を受けてから保険金や補償金を受け取るためには被害状況の査定が入りますが、大規模災害だと手が回らず結果として被害に遭われた方にお金が届くのに時間がかかるという問題があります。この際に、損壊の有無はもちろん、その度合いや根拠を示せれば大きな助けになります。
このように、科学分野だけでなく、社会においても解決されていない問題はとても多く、そして解決のための「特徴量」を発見するのは人間だけでは難しいのが現状です。こうした中で、機械学習はもとより、特に表現学習に強いディープラーニングに対して「説明力」を付与することで、解決のきっかけを得られるかもしれません。
今後より多くの課題を解決していくために、これらの「説明」を行う手法はより重要になってくると思います。
6.参考文献
Articles
- Methods for Interpreting and Understanding Deep Neural Networks
- SmoothGrad: removing noise by adding noise
- Detecting and Explaining Crisis
- Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
- European Union regulations on algorithmic decision-making and a "right to explanation"
- Intriguing properties of neural networks
- Robust Physical-World Attacks on Machine Learning Models
- Building High-level Features Using Large Scale Unsupervised Learning
- Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
- Visualizing Higher-Layer Features of a Deep Network
- Understanding Deep Image Representations by Inverting Them
- Conditional Image Synthesis With Auxiliary Classifier GANs
- Striving for Simplicity: The All Convolutional Net
- Explaining nonlinear classification decisions with deep Taylor decomposition
- Evaluating the visualization of what a Deep Neural Network has learned
- Learning how to explain neural networks: PatternNet and PatternAttribution
- “Why Should I Trust You?” Explaining the Predictions of Any Classifier
- Interpretable Explanations of Black Boxes by Meaningful Perturbation
- Understanding Black-box Predictions via Influence Functions
- Interpretable Predictions of Tree-based Ensembles via Actionable Feature Tweaking
- Monotonic Calibrated Interpolated Look-Up Tables
- Neural Machine Translation by Jointly Learning to Align and Translate
- Effective Approaches to Attention-based Neural Machine Translation
- Explainable Artificial Intelligence: Understanding, Visualizing and Interpreting Deep Learning Models
- Quantum-Chemical Insights from Deep Tensor Neural Networks
- Automatically Processing Tweets from Gang-Involved Youth: Towards Detecting Loss and Aggression
- Axiomatic Attribution for Deep Networks