※2018年06月23日追記
PyTorchを使用した最新版の内容を次の書籍にまとめました。
つくりながら学ぶ! 深層強化学習 ~PyTorchによる実践プログラミング~ 18年6月28日発売
これから強化学習を勉強したい人に向けて、「どんなアルゴリズムがあるのか」、「どの順番で勉強すれば良いのか」を示した強化学習アルゴリズムの「学習マップ」を作成しました。
さらに、各手法を実際にどう実装すれば良いのかを、簡単な例題を対象に実装しました。
本記事では、ひとつずつ解説します。
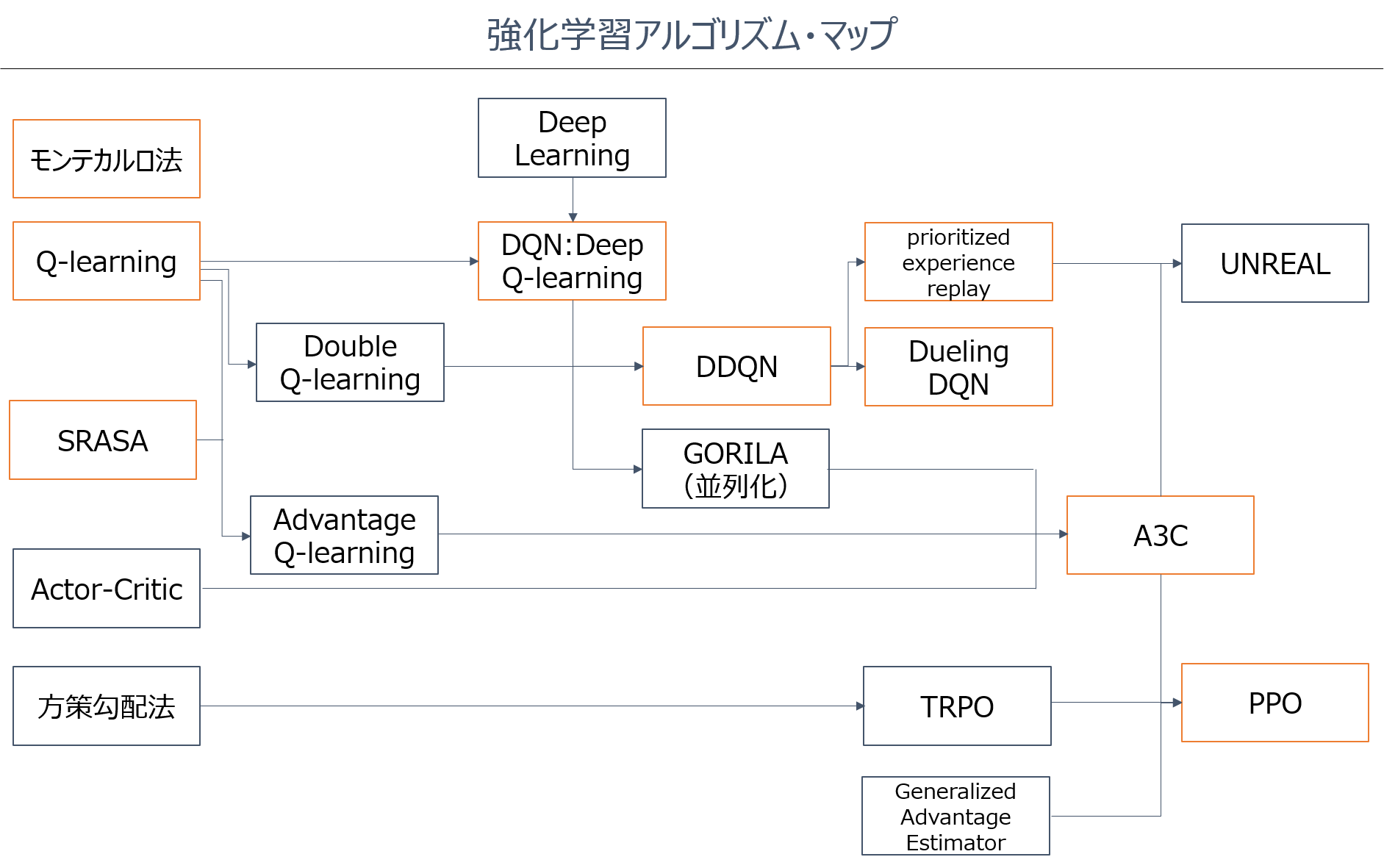
オレンジ枠の手法は、実装例を紹介します。
※今回マップを作るにあたっては、以下の文献を参考にしました。
●速習 強化学習: 基礎理論とアルゴリズム(書籍)
●Deep Learning for Video Game Playing
強化学習とは
強化学習は、画像識別のような教師あり学習や、クラスタリングのような教師なし学習とは少し異なる、機械学習の分野です。
最終的に達成したいゴールはあるけれど、そこにいたる詳細な制御手法は分からないときに、ゴールできたかどうかをベースに、制御手法を構築する学習手法です。
例えばぶつからない車の自動運転技術の開発では、「センサーで車間距離が○ mになったら、ブレーキをさせる」というのは、ルールベースの制御です。
一方で、実際に車を何度もシミュレーションや実車で走らせて、ぶつかった場合は改善し、ぶつからなかった場合はその制御手法を採用し、何度も試行錯誤しながら、ぶつからないというゴールを達成させる学習手法が、強化学習です。
強化学習は主に「何かの制御」や「対戦型ゲームのアルゴリズム」に使用されることが多い手法です。
「何かの制御」であれば、先ほどのぶつからない自動運転技術の開発や、サーバールームの空調代金を安く抑える空調の制御手法の開発、共有サーバーの資源の最適配分、ロボットの運動制御などがあります。
また最近では、文章生成などにも使われたりしています。
基本的に作りたいもののゴールは設定できるけど、そのゴールを達成するための手法・ルール・制御をうまく設計できない場合に、強化学習が使われています。
「対戦型ゲームのアルゴリズム」では、アルファ碁やアルファ碁ゼロに強化学習が使われています。
本記事では「対戦型ゲーム」は取り扱っておらず、どちらかというと、「何かの制御」に使われる強化学習アルゴリズムを紹介します。
強化学習の例題
強化学習の例題としては、単純な迷路課題や3目並べなども使われますが、OpenAIのCartPoleが最もおすすめです。
CartPoleは以下のような、倒立振子の制御問題です。
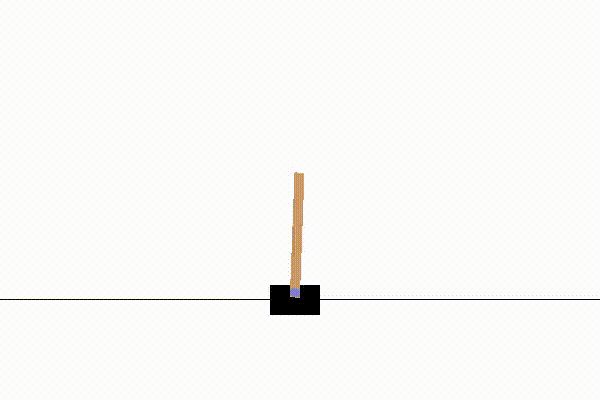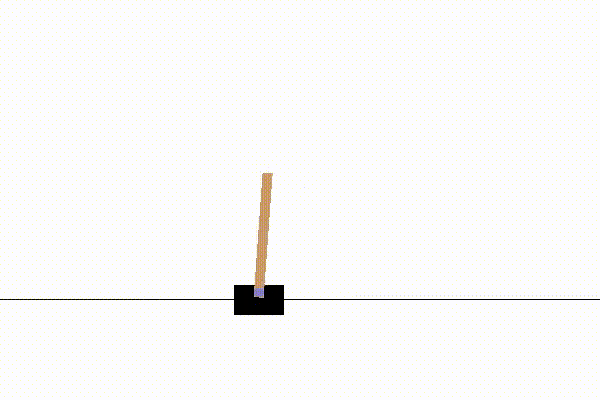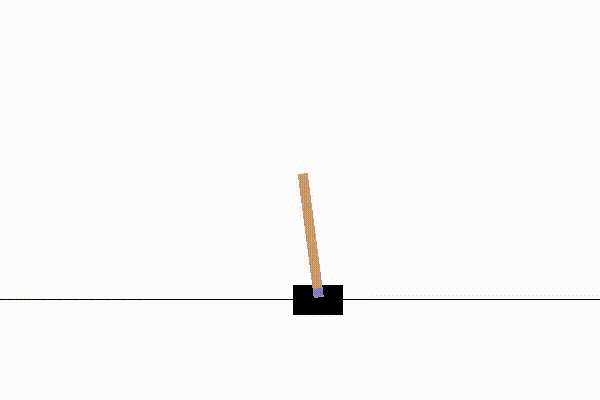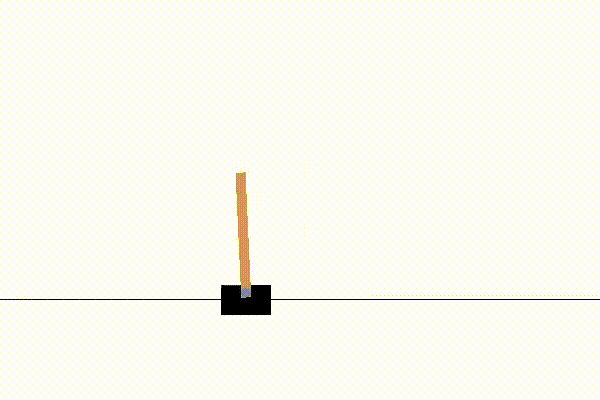
CartPoleをおすすめする理由は、動画で動きが見れて楽しいのと、適度な複雑さがあるからです。
一方で使用するのは非常に簡単です。
このCartPoleは、小学生が掃除の時間にほうきを手のひらで立てて遊ぶのと同じ事をしています。
各時刻step=tで選択できる行動a(t)は、土台の車を(右に押す, 左に押す)の2択です。
そして、状態s(t)は土台の車の位置x(t)、速度v(t)と、棒の角度θ(t)と角速度ω(t)の4変数です。
やりたいことは、状態s(t)に応じて適切な行動a(t)を実行し、棒を立て続けることです。
本記事ではこのCartPoleを対象に各アルゴリズムの実装を行いました。
それでは次に、各アルゴリズムを紹介します。
Deep Learningが生まれる前までの強化学習
強化学習において、Deep Learningが提案される前までのアルゴリズムには、代表的な手法が3つあります。
Q-Learning、SARSA、モンテカルロ法です。
Q-Learning
Q-Learning(Q学習)は、最も代表的な手法になります。
まずはこの手法から勉強するのが良いです。
Q-LearningではQ関数と呼ばれる行動価値関数を学習し、制御を実現します。
行動価値関数Q(a|s)とは、状態s(t)のときに行動aを行ったときに、その先どれくらいの報酬がもらえそうかを出力する関数です。
このQ関数に行動右に押すと、左に押すを入力したときの出力を比べ、報酬が多いほうを選べば、自然とCartPoleが立ち続けることになります。
以下の記事で、openAIのCartPoleの使用方法からQ-Learningのアルゴリズム詳細と実装例までを紹介しているので、まずはこちちらをご覧ください。
●CartPoleでQ学習(Q-learning)を実装・解説【Phythonで強化学習:第1回】
SARSA、モンテカルロ法
SARSAはQ-Learningと同様にQ関数を学習するのですが、少し学習の仕方が異なる手法です。
Q-LearningやSARSAは1stepごとにQ関数を学習していく手法です。
それらとは異なり、CartPoleが倒れるまで行動し、その行動履歴からQ関数を学習する手法がモンテカルロ法です。
今回のマップではモンテカルロ法から進展しているアルゴリズムはありませんが、重要なアルゴリズムです。
SARSAとモンテカルロ法のアルゴリズム詳細と、CartPoleで実装した例を、次の記事にまとめましたので、詳細はこちらをご覧ください。
●シンプルな実装例で学ぶSARSA法およびモンテカルロ法【CartPoleで棒立て:1ファイルで完結】
Deep Learningが生まれる前までの強化学習手法としては、この3つが実装できれば良いのではと思います。
Deep Learningが生まれてからの強化学習
Deep Learningの出現にともない、強化学習にもDeep Learningが使われるようになり、ブレイクスルーが生まれました。
DQN、DDQN
これまでQ関数を表すのに、実際には表を使用していました。
表のサイズが、「状態sを離散化した数」×「行動の種類」となります。
ですが、表ではサイズに限りがあるため、ニューラルネットワークを使用したかったのですが、うまくいっていませんでした。
そこでQ関数の表現にDeep Learningを使用したのがDQN(Deep Q-Network もしくは Deep Q-Learning Network)です。
DQNの出現により、より複雑なゲームや制御問題の解決が可能になり、強化学習が注目を集めました。
なおDeep Learning(深層学習)を用いた強化学習は、深層強化学習とも呼ばれます。
またDQNの学習で、2つのQ-networkを使用する手法をDouble DQN(DDQN)と呼びます。
DQN、DDQNのアルゴリズム詳細とCartPoleを実装した例を、以下にまとめましたのでご覧ください。
●CartPoleでDQN(deep Q-learning)、DDQNを実装・解説【Phythonで強化学習:第2回】
prioritized experience replay、Dueling DQN
DDQNをより良くするために、prioritized experience replayやDueling DQNが提案されました。
prioritized experience replayは、Q学習がまだ進んでいない状態s(t)の経験に対して、優先的に学習を実行させる手法です。
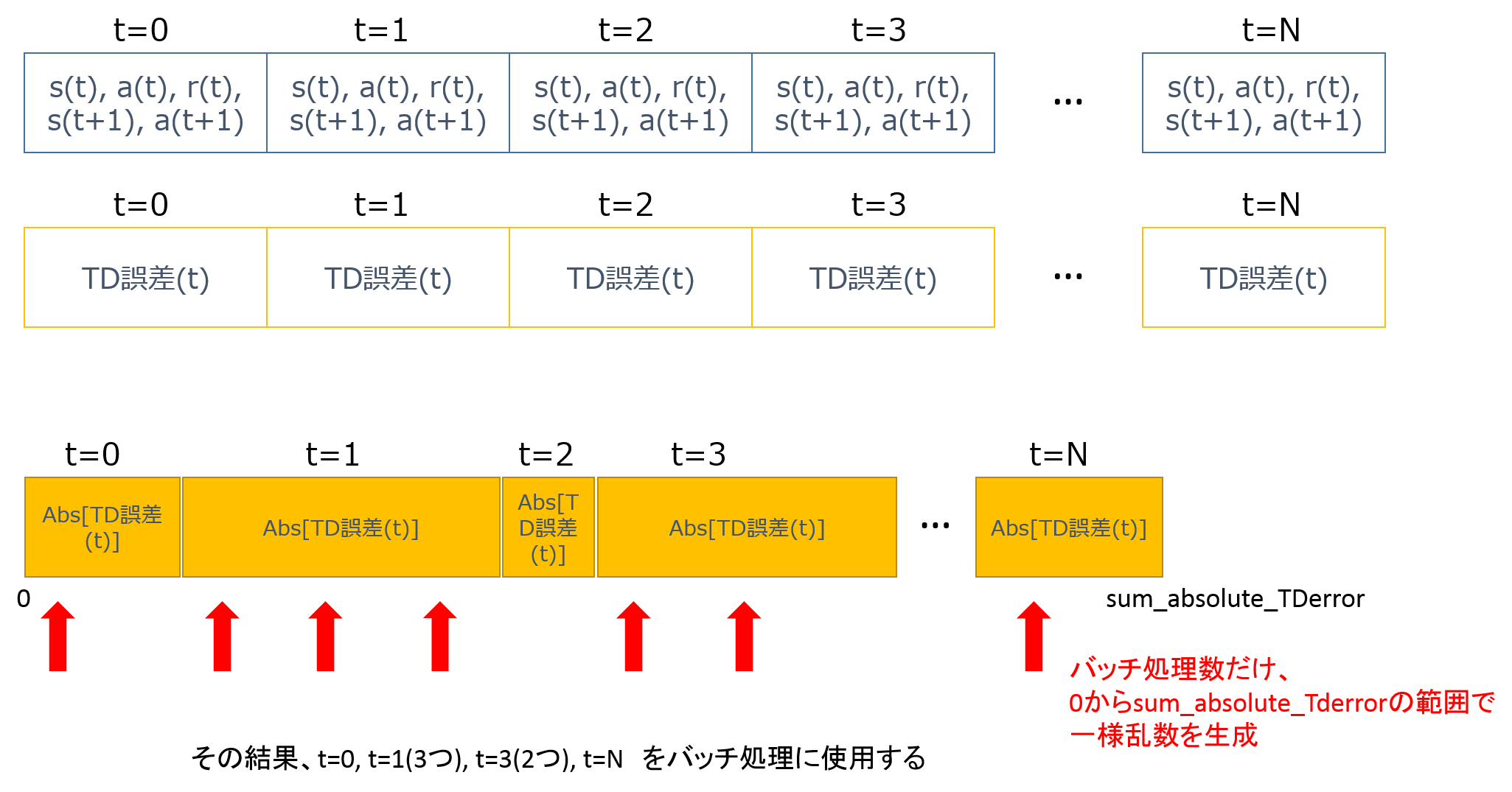
こちらでアルゴリズム詳細と実装例を紹介しています。
●実装例から学ぶ優先順位付き経験再生 prioritized experience replay DQN
Dueling DQNは、Q関数を状態価値関数V(s)とAdvantage関数A(a|s)に分割して学習するネットワークを使用する手法です。
Q(a|s) = V(s) + A(a|s)
となります。
ネットワークで表すと以下の図の通りです。
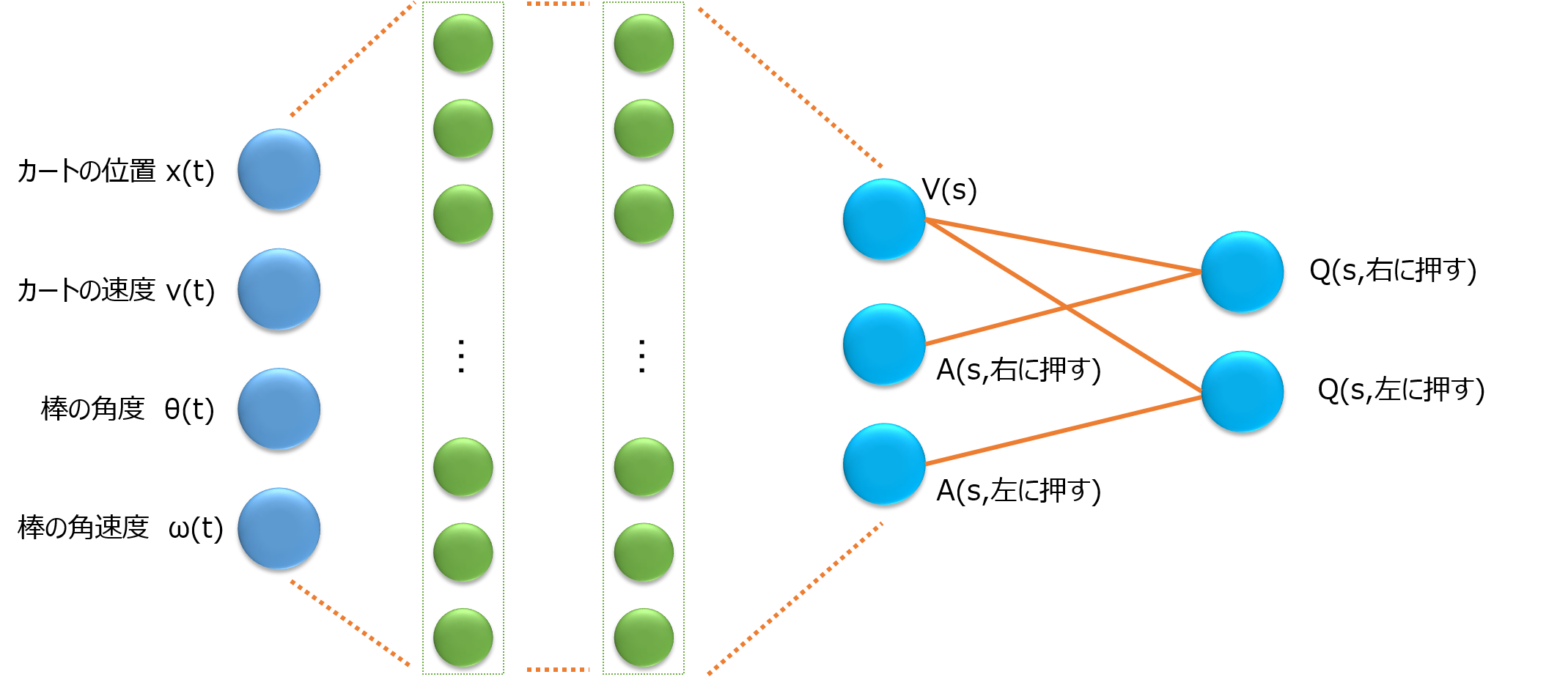
こうすることで、どんな行動のときもV(s)を学習するため、Q関数の学習が早く良くなります。
こちらでアルゴリズム詳細と実装例を紹介しています。
A3Cの登場
DQNの登場後、さらに深層強化学習の性能を上げることになった重要な手法がA3Cです。
A3C
A3Cとは「Asynchronous Advantage Actor-Critic」の略称です。
A3Cの前に、並列化してDQNを行う手法として、GORILA(General Reinforcement Learning Architecture)が提案されていました。
ゴリラ(GORILLA)ではないので、注意してください。
なお"GORILA Python"で画像検索すると、いままで脳で想像したことのない面白い画像があります。
●"GORILA Python"で画像検索した結果
話が脱線しました。
A3Cは並列計算に加え、さらにAdvantageと呼ばれる報酬の計算方法を使用しています。
Advantageは報酬の計算を1step後ではなく、数ステップ後まで行動を実施して行う計算手法です。
さらにA3Cには、Actor-Criticと呼ばれるネットワークが使用されています。
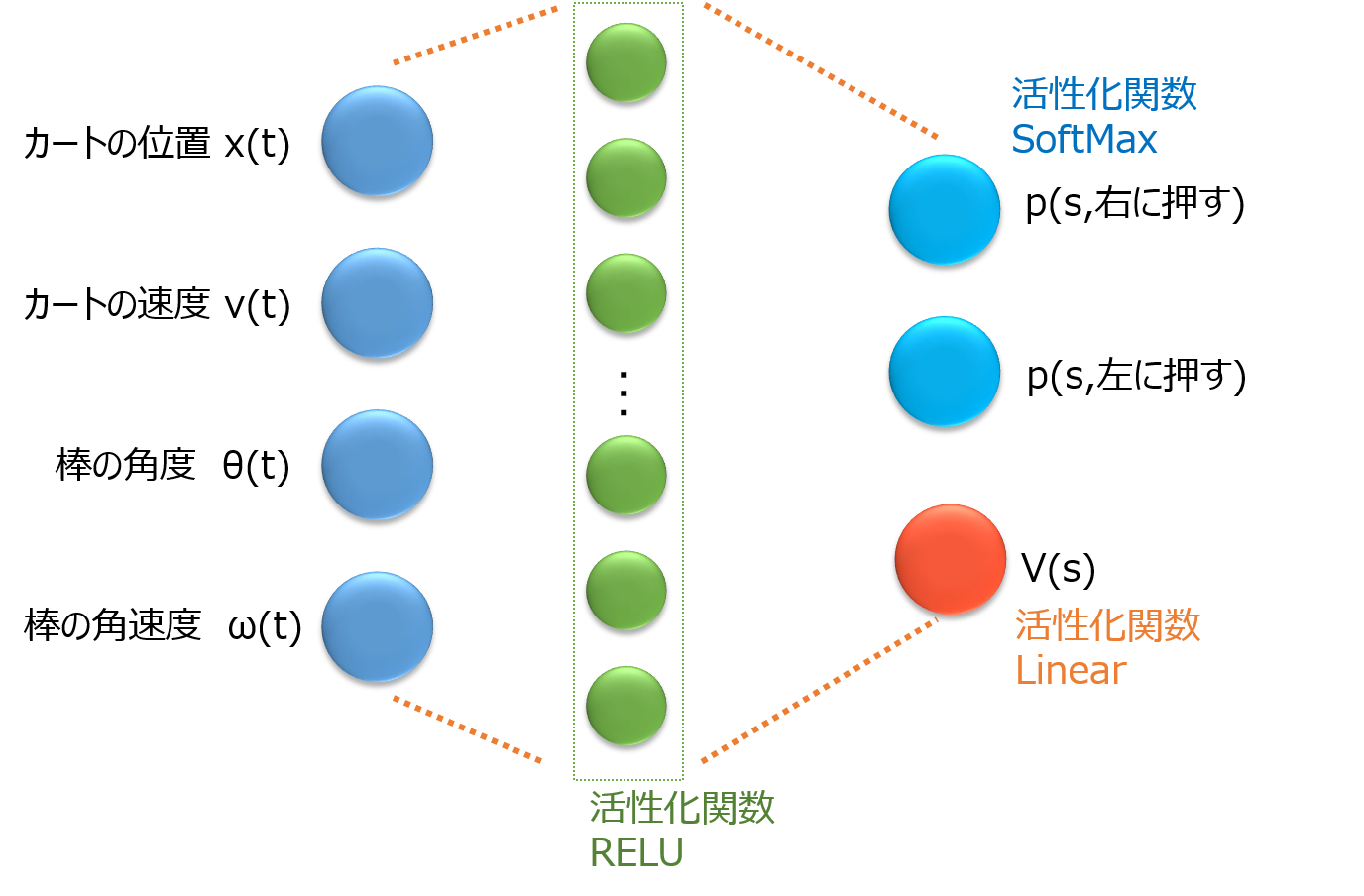
これは、Q関数ではなく、方策関数π(s)=[p(右), p(左)]で直接、状態sに応じた行動を出力します。
p(右)は状態sで右に押すほうが良い確率を示します。
この部分をActorと呼びます。
さらに同時に、状態価値V(s)も学習させます。
この部分をCriticと呼びます。
DQNから比べると大きく変わっているので、理解が難しいのですが、実際にゆっくり実装してみると理解が深まります。
A3Cのアルゴリズム詳細とCartPoleを実装した例を、以下にまとめましたのでご覧ください。
●実装しながら学ぶA3C【CartPoleで棒立て:1ファイルで完結】
TRPO、Generalized Advantage Estimator
その他、強化学習のアルゴリズムとしてはA3Cとほぼ同時期に、TRPOやGAEなども提案されています。
TRPO(Trust Region Policy Optimization)は、方策関数π(s)が一度に大きく更新されすぎないように制限をかけて、方策関数π(s)を更新する手法です。
また、GAE(Generalized Advantage Estimator)という手法は、Advantageを考慮して報酬を計算する際に、どの程度先のステップまで考慮するのかを、1つの式で一般的に表せるようにした枠組みです。
2017年最新の強化学習、UNREAL、PPO
速習 強化学習: 基礎理論とアルゴリズム(書籍)では、以上のアルゴリズムが紹介されていましたが、2016年末から2017年に発表されたアルゴリズムのうち、UNREALとPPOはとくに重要な手法なので、紹介します。
UNREAL
UNREALは、「UNsupervised REinforcement and Auxiliary Learning」(UNREAL:教師なしの強化および補助学習)の略称です。
Auxiliaryを日本語にすると、「補助の」という意味です。
A3Cのネットワークに、直接の制御目的とは少し異なる補助タスクを組み込んで、補助タスクがうまくできるようになることで、本来のゴールへの制御もうまくなるという作戦です。
例えば、URENALの論文では「3次元空間の迷路タスク」の攻略に、3つの補助タスクを組み込んでいます。
1つ目は、ピクセルコントロールと呼ばれ、画像ピクセルが大きく変化する動きを補助タスクとして学習させることで、迷路を進みやすくし、動き方を学ばせています。
2つ目は、 prioritized experience replayを強化し、報酬がもらえたときの状態s(t)を多く学習させ、現在の状態s(t)から、将来の報酬を予測させる補助タスクを行っています。
3つ目は、A3Cでは状態価値V(s)を学ぶ際に、過去の経験をシャッフルしないのですが、シャッフルしたバージョンで状態価値V(s)を学ぶ補助タスクを行っています。
これらの補助タスクがうまくできるようになることで、本来のタスクと一部共有しているネットワークの重みが学習され、本来のタスクもうまくなる仕組みです。
PPO
PPOは、openAIから2017年に発表された手法で、UNREALよりも実装が簡単です。
方策関数π(s)の更新手法として、TRPOが提案されていましたが、TRPOは実装がややこしく、またA3CのActor-Criticなど、出力が複数種類あるネットワークに適用できないという課題がありました。
この点を解決したのがPPOです。
PPOではClippingと呼ばれ、π(s) / π(s_old)が大きく変化した場合には、一定の値にしてしまう操作(Clip)を行います。
例えば、π(s_old)が0.1なのにπ(s)が0.9となった場合には、π(s) / π(s_old) = 9ではなく、1.2などにしてしまい、π(s) / π(s_old)が1.2以上は全部1.2としてしまう操作をします。
こうすることで、TRPOとは異なる手法で、方策関数π(s)の更新が大きく変化しすぎるのを防ぎます。
PPOのアルゴリズム詳細とCartPoleを実装した例を、以下にまとめましたのでご覧ください。
●実装しながら学ぶPPO【CartPoleで棒立て:1ファイルで完結】
まとめ
以上、これから強化学習を勉強したい人に向けて、「どんなアルゴリズムがあるのか」、「どの順番で勉強すれば良いのか」を示した強化学習アルゴリズムの「学習マップ」を作成しました。
これから強化学習を勉強する方の参考になれば幸いです。
ご一読いただきまして、ありがとうございます。