※2018年06月23日追記
PyTorchを使用した最新版の内容を次の書籍にまとめました。
つくりながら学ぶ! 深層強化学習 ~PyTorchによる実践プログラミング~ 18年6月28日発売
2016年に発表された強化学習のアルゴリズム「A3C」を実装しながら、解説します。
(エイ・スリー・シー)と呼ぶそうです。
A3Cは、アルファ碁ゼロをはじめ、最新の強化学習を学ぶうえで、避けては通れない重要なアルゴリズムです。
世界一分かりやすいA3C、猫でもわかるA3Cの紹介を目指して、記事を書きます。
※ 171115
tarutoさまにお気づきいただき、AgentクラスのAct関数を修正しました。
概要
OpenAI GymのCartPoleを題材に、「A3C」の実装・解説をします。
プログラムが1ファイルで完結し、学習・理解しやすいようにしています。
本記事では、
- A3Cとは(概要)
- A3Cのアルゴリズム解説
- A3Cを少しずつ実装しながら、実装方法の解説
- 最終的なコード
の順番で紹介します。
【対象者】
・強化学習DQNの発展版に興味がある方
・速習 強化学習: 基礎理論とアルゴリズム(書籍)を読んで、A3Cを知ったが、実装方法がよく分からない方
【得られるもの】
ミニマム・シンプルなプログラムの実装例から、A3Cを理解・実装できるようになります。
【注意】
本記事に入る前に、OpenAI gymのCartPoleの使い方、Q学習、DQN、Dueliing DQNをなんとなく知っておくと良いと思います。
●CartPoleでQ学習(Q-learning)を実装・解説【Phythonで強化学習:第1回】
●CartPoleでDQN(deep Q-learning)、DDQNを実装・解説【Phythonで強化学習:第2回】
●実装例から学ぶDueling Network DQN
A3Cとは(概要)
A3Cとは「Asynchronous Advantage Actor-Critic」の略称です。
強化学習におけるA3Cの立ち位置を紹介します。
強化学習の分野は、ディープラーニングを取り入れた強化学習である「DQN」が2013年に発表され、大きく進展しました。
その後、DQNを少し発展させたDDQNやDueling Network、prioritized experience replayなどの手法が発表されました。
また、これらの流れとは別に、Gorila(General Reinforcement Learning Architecture)のような、並列計算で性能を上げる手法なども発表されました。
A3CはこれらのDQNの発展と、並列化の流れが合体したような手法です。強化学習の世界では、DQNの次の世代の手法として注目を浴びた革新的なアルゴリズムになります。
しかしながらA3Cは、DQNの次の世代的存在であるため、DQNからの変化幅が大きく、理解するのがなかなか難しいです。
アルゴリズムそのものが難しいです。
その実装方法も難しいです。
ですがアルファ碁ゼロをはじめ、最新の強化学習の世界を理解するには、A3Cは避けて通れない重要なアルゴリズムです。
A3Cのアルゴリズム解説
A3Cのアルゴリズムを解説します。3つのAをひとつずつ紹介します。
「Asynchronous Advantage Actor-Critic」ですが、
- Advantage
- Actor-Critic
- Asynchronous
の順番で説明します。
Advantage
通常のQ学習、DQNではQ関数の更新を、Q(s,a) が、 r(t) + γ・max[Q(s_,a)] に近づくように、Q関数を学習していきました。
ここで、r(t)は時刻tで得た報酬、s_は状態sでaの行動をした結果の状態です。
つまり、s_=s(t+1)。
γは時間割引率です。
Q(s,a) → r(t) + γ・max[Q(s_,a)]
で再帰的にQ関数を学んでいきます。
はじめはイメージがつきにくいですが、CartPoleの場合は、t=200もしくは倒れたときが終端(終了)となるので、終端のsの場合、次の状態s_がないため、
Q(s,a) → r(t)
とQ関数が再帰的でなく確定します。
このように、終端の状態sからQ関数がどんどん確からしくなっていきます。
Advantageは、このQ関数の更新を「1ステップ先でなく、2ステップ以上先まで動かして、更新しよう」という考え方です。
例えば、2ステップ先を考慮したAdvantageは以下のようになります。
Q(s,a) → r(t) + γ・r(t+1) + (γ^2)・max[Q(s_,a)]
となります。
ここで、時刻tで状態はsです。時刻tで行動a(t)を行い、状態sが変わります。
また報酬r(t)を得ます。
次になんらか行動a(t+1)を行い、状態がs_となり、報酬r(t+1)を得ます。
つまり、s_=s(t+2)となっています。
これがAdvantageの考え方です。
これだけ聞くと、「めっちゃ先までAdvantageした方がいいやん♪」って思いますが、単純にそうでもありません。
というのも、途中の行動a(t+1)を決めるときに、完成途中のQ関数を使用するので、そこが間違っていたら、その先もどんどん間違うことになります。
そのため、どんどん先のAdvantageを使えば良いというわけでもなく、少し先くらいまでのAdvantageを使うのがバランスが良いです。
以上がAdvantageの考え方です。
Actor-Critic
これまでQ学習の枠組みで話をしました。
Q学習、DQNなどは、状態sにおいて、行動aを行った場合に、「その先得られるであろう報酬の合計を時間割引した総報酬R」(割引総報酬)を出力する
R = Q(s,a)
のQ関数を使用して強化学習を実施していました。
このようなQ関数を用いた強化学習は、Value-Basedと呼ばれます。
一方で、「Actor-Critic」はPolicy-Basedと呼ばれる別の枠組みと、value-Basedの組み合わせとなります。
Policy-BasedはQ関数を求めず、状態sから直接行動aを決める手法です。
アルファ碁ゼロも、一つのネットワークにPolicy-Basedと、value-Basedを組み合わせたActor-Criticになっています。
Actor-Criticの場合には、ネットワークが行動を出力するActor部分と、状態sの割引総報酬Rを出力するCritic部分に分かれています。
よく以下の絵で紹介されます。
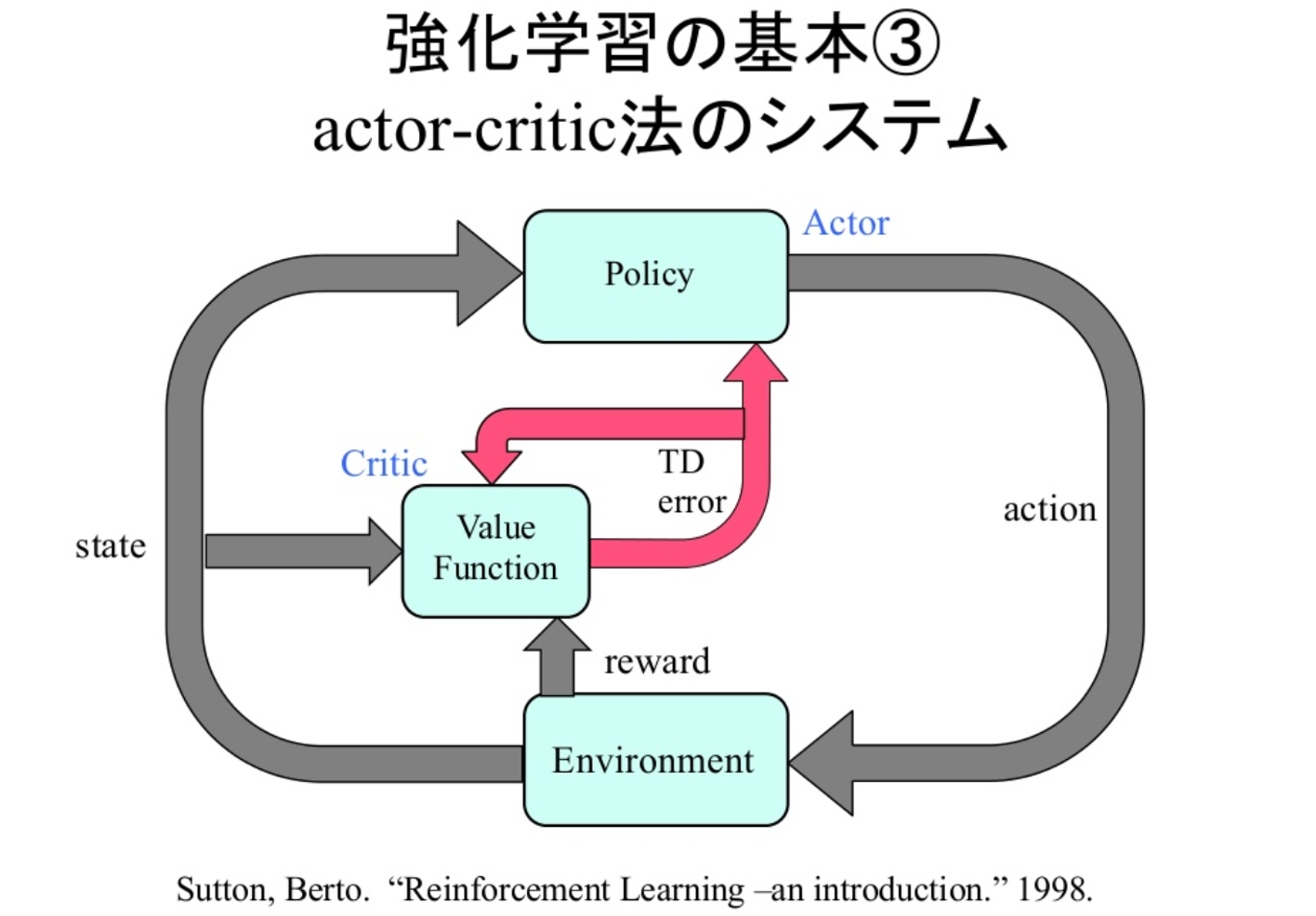
※Sutton, Berto. 1998
※ディープラーニングの最新動向強化学習とのコラボ編6 A3C
ですが、この絵を見ても私にはさっぱり分からないです。
そこでCartPoleのネットワークでActor-Crticを書くと次の通りです。
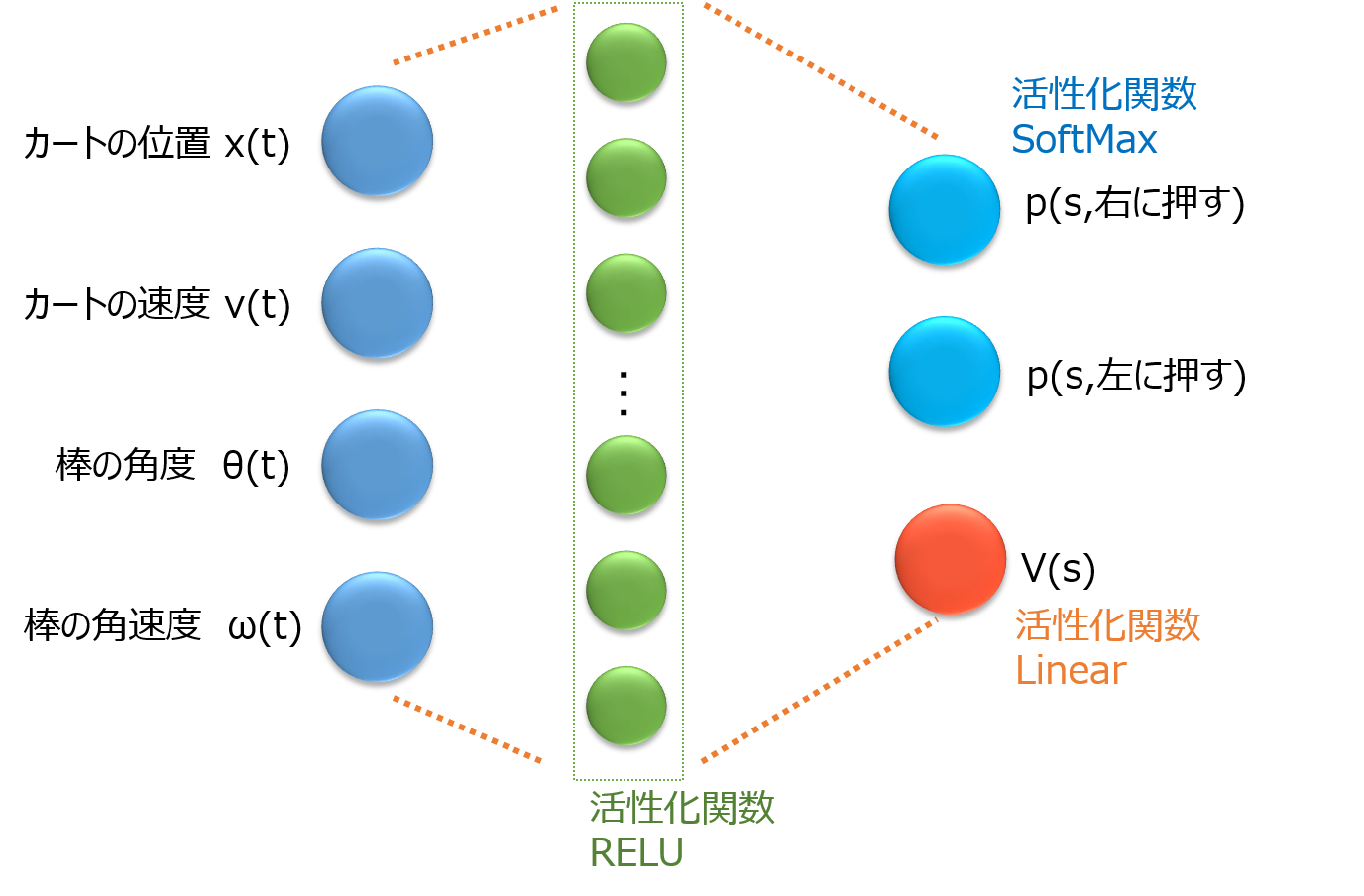
Fig. 1 CartPoleにおけるActor-Criticなニューラルネットワーク
入力素子は4つです。
状態s(t)の各要素を入力します。
なお、状態s(t)=[x(t), v(t), θ(t), ω(t)]であり、それぞれカートの位置、速度、棒の角度、角速度を表します。
出力素子は、行動a=[右にカートを押す、左にカードを押す]の2つ(Actor)と、状態sでの割引総報酬R=V(s)を出力(Critic)の3つです。
Actorの2つの素子は、状態sの場合に、右に押すのが良い確率p(右)と、左に押すのが良い確率p(左)を示します。
p(右)+p(左)=1となります。
そして、時刻tで状態sの場合に、行動aはこの確率pに従って、右か左に決まります。
また最後の出力層までの途中はActorとCriticが共有しているのが一般的です。
これでActor-Critic・ネットワークで、入力sから行動aを決める流れが説明できました。
(フォワード側の流れ)
ではバックワード側の流れ、つまりどうやってネットワークの素子と素子をつなぐ重み係数を学習するのでしょうか?
Criticに対しては、Q関数が価値関数V(s)に変わっているので、その出力V(s)の更新は
V(s) → r(t) + γ・V(s_)
となるように、ネットワークを更新すれば良いことが分かります。
Advantageを考慮した場合には、例えば
V(s) → r(t) + γ・r(t) + (γ^2)・V(s_)
となります。
そして、Actor側も更新してあげる必要があります。
Actor側の更新は、
log[pi_θ(a|s)]*A(t)
を大きくするように更新すれば良いことが知られており、Policy Gradient Theorem(方策勾配定理)と呼ばれています。
ここでA(t)=(R(t)-V(s))であり、パラメータ更新の際にA(t)は定数として扱う必要があります。
例えば、時刻tで状態sの場合に、行動a(t)=右に押す、を行った場合、
log(p(右))*{R(t)−V(s)}
となります。
ここでR(t)はV(t)であり、2step-Advantageの場合は、
R(t) = r(t) + γ・r(t) + (γ^2)・V(s_)
です。
なぜこれで良いのかは、きちんと方策勾配定理を理解するしかないので、ここでは割愛します。
気になる方はこちらのスライドをおすすめします。
●強化学習その3
この最大化したい対象の式には、p()の項が含まれているので、Actor側のネットワークの重みが更新できることになります。
※なお、TensorFlowでは最大化はできないので、マイナスをかけたものを最小化させる方向に、ネットワークの重みを更新します。
また実装時にはp()が一気に更新されてlocalminimunに落ちないように、エントロピー項をつけて、収束しづらくしています。
Asynchronous
最後にAsynchronous、日本語で非同期という概念について説明します。
Asynchronousは、非同期的でマルチエージェントな分散学習になります。
これはマルチスレッドで複数の学習環境を用意し、各環境のAgentがそれぞれ勝手に経験を積み重ねます。
各スレッドは各自自分の、Advantage-Actor-Criticのネットワークを持っています。
さらに、全スレッドで共有したAdvantage-Actor-Criticのネットワーク(Parameter Server)が存在します。
各Agentは勝手に動いて溜めた経験から、よりたくさん報酬が得られるように、Advantage-Actor-Criticで、ネットワークの重みを更新させる方向(gradient)を求めます。
gradientを求めるタイミングは、一定ステップTmaxが経過するか、終端に達したときです。
ここでそのAgentは自分のネットワークの重みを更新するのではなく、全スレッドで共有したParameterServerにネットワークの重みを更新させる方向(gradient)を渡します。
そして、共有ネットワーク(Prameter Server)でネットワークの重みをgradientの方向に更新します。
gradientを渡したスレッドは、更新されたPrameterServerの重みをコピーしてきて、シミュレーションを継続します。
これらを各スレッドが非同期的に勝手なタイミングで実施します。
つまり、以下の流れとなります。
- スレッドはParameter Serverからネットワークの重みをコピーする
- スレッドのAgentは自分のネットワークにsを入力して、aを得る
- aを実行し、r(t)とs_を得る
- (s,a, r, s_)をスレッドのメモリに格納する
- 2〜4を繰り返す(各スレッドでTmaxステップ経過もしくは、終端に達するまで)
- 経験が十分に溜まったら、自分スレッドのメモリの内容を利用して、ネットワークの重みを更新させる方向gradを求める
- gradをParameter Serverに渡す
- Parameter Serverはgradの方向にParameter Serverのネットワークを更新する
- 1.へ戻る
これが非同期的な分散学習です。
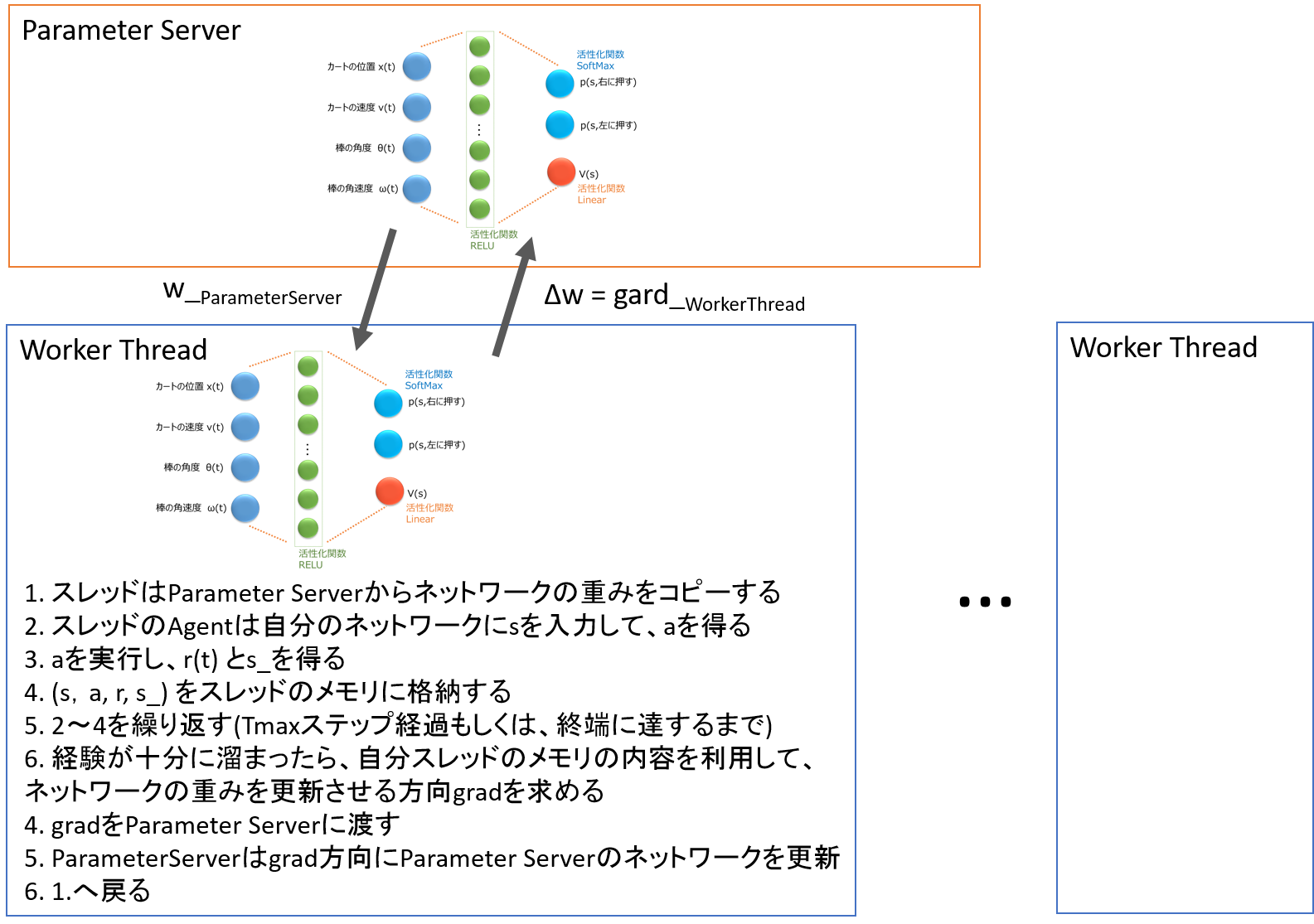
Fig. 2 Asyncrhousな学習
イメージとしては、漫画NARUTOで主人公が分身して修行する感じです。
NARUTOは影分身してたくさんの人数で修行し、一人に戻ると、分身して体験した修行内容を一気に習得できます。
NARUTOもA3Cなどの分散学習アルゴリズムを実装していたのだと思われます。

http://www.mangajunky.net/img/1423053905407.jpg/
影分身はどうでも良いのですが、非同期的な学習には、分散して早い以上に大きな利点があります。
それはDQNと異なり、experimental replayを使用しないことです。
経験を溜め、それをシャッフルして学習するexperimental replayは、時系列がぐちゃぐちゃになるため、ニューラルネットワークにLSTM(Long short-term memory)を使用できません。
一方でA3CではLSTMも使用できるため、過去の時系列を考慮したニューラルネットワークが実現できます。
※今回の実装例ではLSTMは使用していません
以上が、A3Cのアルゴリズムの解説となります。
これら3つの手法
- Advantage
- Actor-Critic
- Asynchronous
を実装したものを、A3C「Asynchronous Advantage Actor-Critic」と呼びます。
本記事以外に、以下のSlideShareでもA3Cの解説があるので、合わせて参考にしてください。
●ディープラーニングの最新動向強化学習とのコラボ編6 A3C
A3Cを少しずつ実装しながら、実装方法の解説
それではA3Cを実装してみます。
ですが、これはなかなかの大変さです。
というのもA3Cを実装するには、
- TensorFlowをマルチスレッドで走らせる
- 複数のニューラルネットワークを用意して、ネットワーク間で重みをコピーする
- gradをActor-Criticのloss関数を利用して求める
- localスレッドで求めたgradでParameter Serverのネットワークを更新する
を実装できる必要があります。
とても大変ですが、ひとつずつ解説します。
なお実装には以下の2つのサイトを参考にしました
●Let’s make an A3C: Implementation
●GitHub A3C.py by MorvanZhou
実装コードのクラス構成
実装コードのクラス構成を紹介します。
クラス名とメソッド名、各内容の概要です。
メインメソッドと5つのクラスからなります。
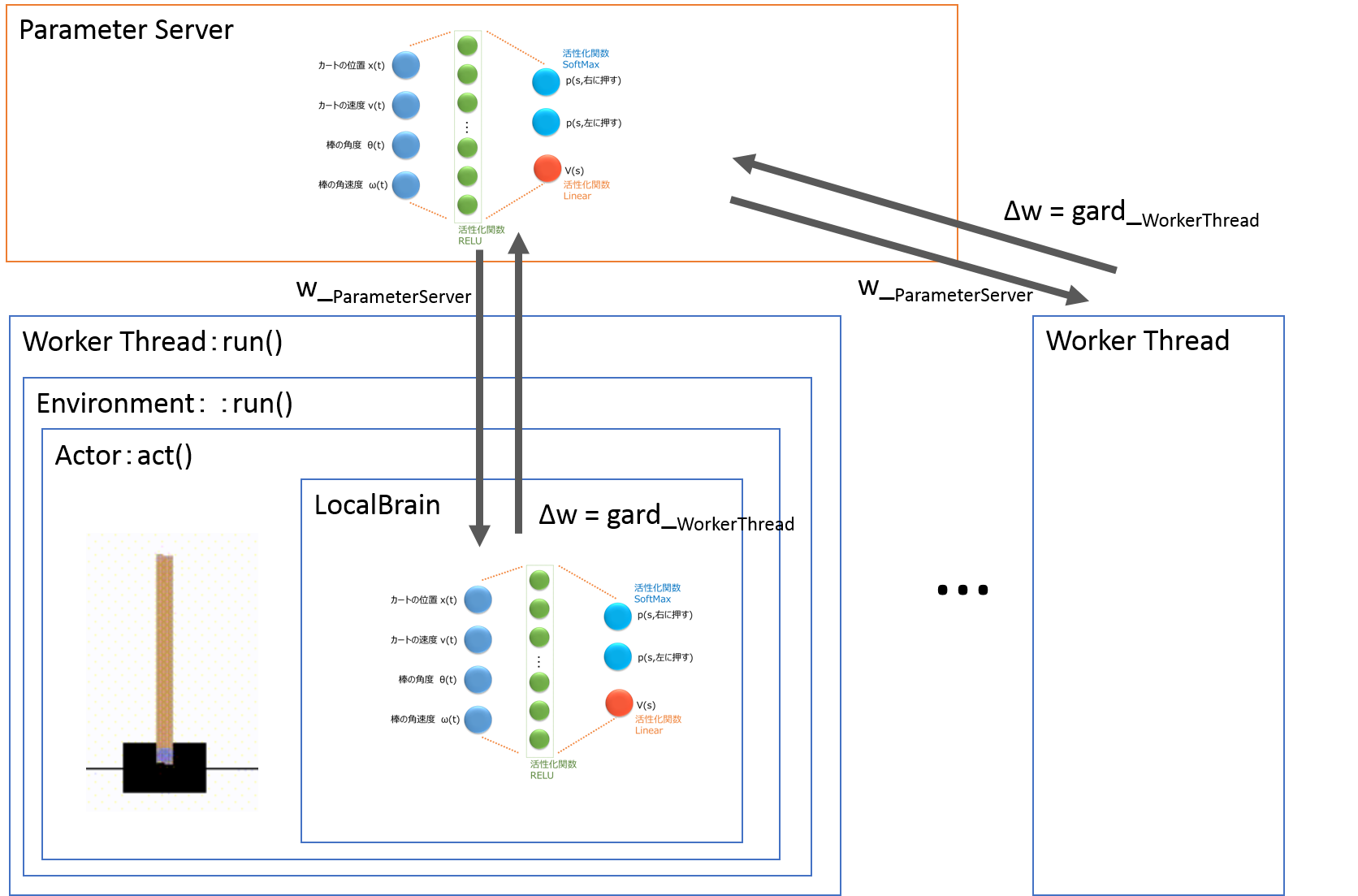
Fig.3 クラス構成
・メインメソッド(マルチスレッドを実行します)
・ParameterServer(全スレッドで共有するネットワークのクラス)
build_model(ネットワークの形を定義するメソッド、ここでは4入力、、中間層1層、(2出力と1出力)の、以下のネットワークを定義します)
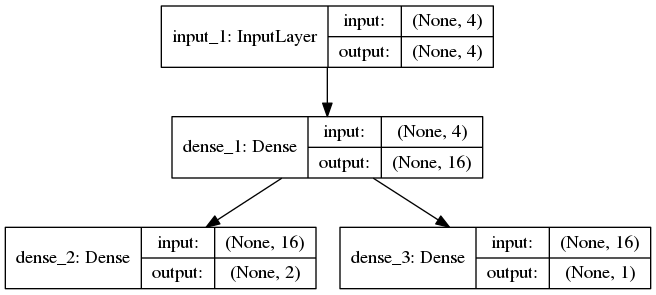
・LocalBrain(各スレッドが持つネットワークのクラスです。メンバ変数にParameterServerと、記憶キューを持ちます)
build_model(ParamerServerクラスと同じく、ネットワークを定義するメソッドです)
build_graph(ネットワークのloss関数などを定義するメソッドです)
pull_parameter_server(localスレッドがParameterServerの重みをコピーします)
push_parameter_server(localスレッドの重みをParameterServerにコピーします)
update_parameter_server(localスレッドでgradを求め、ParameterServerの重みをgradで学習・更新します)
predict_p(状態sから各actionの確率pベクトルを返します)
train_push(s, a, r, s_を、自分のキューに格納します)
・Agent(open AI gymの環境で活動します。メンバ変数にLocalBrainと記憶メモリを持ちます)
act(ε-greedy法のもと、自分のLocalBrainのネットワークから行動aを取得します)
advantage_push_local_brain(s, a, Advantageを考慮したnステップの割引総報酬R, nステップ後の状態s_、をLocalBrainのキューに追加します)
・Environment(openAI gymを走らせる環境です、メンバ変数にAgentを持ちます)
run(シミュレーションを1試行実行します)
・Worker_Thread(分散して非同期的に実行されるスレッドです。メンバ変数にEnvironmentを持ちます。学習するlearningスレッドと学習後にテストを行うtestスレッドがあります)
run(Environmentのrunを実行します、学習中は学習を行い、学習後はテスト行程で描画しながら実行します)
以上のクラス構成とメソッドです。
もう少しクラスを減らすこともできますが、これくらいの分割の方が分かりやすいので、この分け方にしました。
メイン関数
メイン関数を紹介します。
ここでは、TensorFlowをマルチスレッドで実行します。
メイン関数はほとんどTensorFlowでマルチスレッドを走らせるときのお手本コード通りです。
Worker_threadクラスを生成し、同時に走らせています。
工夫点は次の2つです。
・各スレッドには名前をつけています。この名前はlocalBrainのTensorFlowのネットワークの名前にまで、引き継がれます
・スレッドは、training用のスレッド複数個と、学習後に実行されるtestスレッド1つがあります
学習とテストはファイルを分割し、学習後のパラメータを保存し、別ファイルで読み込んで走らせる方が実用的ですが、今回はスレッドを2種類用意し、学習とテストをひとつのファイルで実行します。
# -- main ここからメイン関数です------------------------------
# M0.global変数の定義と、セッションの開始です
frames = 0 # 全スレッドで共有して使用する総ステップ数
isLearned = False # 学習が終了したことを示すフラグ
SESS = tf.Session() # TensorFlowのセッション開始
# M1.スレッドを作成します
with tf.device("/cpu:0"):
parameter_server = ParameterServer() # 全スレッドで共有するパラメータを持つエンティティです
threads = [] # 並列して走るスレッド
# 学習するスレッドを用意
for i in range(N_WORKERS):
thread_name = "local_thread"+str(i+1)
threads.append(Worker_thread(thread_name=thread_name, thread_type="learning", parameter_server=parameter_server))
# 学習後にテストで走るスレッドを用意
threads.append(Worker_thread(thread_name="test_thread", thread_type="test", parameter_server=parameter_server))
# M2.TensorFlowでマルチスレッドを実行します
COORD = tf.train.Coordinator() # TensorFlowでマルチスレッドにするための準備です
SESS.run(tf.global_variables_initializer()) # TensorFlowを使う場合、最初に変数初期化をして、実行します
running_threads = []
for worker in threads:
job = lambda: worker.run() # この辺は、マルチスレッドを走らせる作法だと思って良い
t = threading.Thread(target=job)
t.start()
#running_threads.append(t)
# M3.スレッドの終了を合わせます
# COORD.join(running_threads)
Worker_Thread
ローカルスレッドです。
メンバ変数として、Environmentを持ちます。
またthread_typeはlearnigかtestで、学習用スレッドか学習後に使用するテストスレッドかを指定します。
run関数の内容が分かりにくいですが、学習が終わるまではlearningスレッドを走らせ、テストスレッドはスリープさせておきます。
学習後は、learningスレッドはスリープさせ、testスレッドを走らせています。
# --スレッドになるクラスです -------
class Worker_thread:
# スレッドは学習環境environmentを持ちます
def __init__(self, thread_name, thread_type, parameter_server):
self.environment = Environment(thread_name, thread_type, parameter_server)
self.thread_type = thread_type
def run(self):
while True:
if not(isLearned) and self.thread_type is 'learning': # learning threadが走る
self.environment.run()
if not(isLearned) and self.thread_type is 'test': # test threadを止めておく
time.sleep(1.0)
if isLearned and self.thread_type is 'learning': # learning threadを止めておく
time.sleep(3.0)
if isLearned and self.thread_type is 'test': # test threadが走る
time.sleep(3.0)
self.environment.run()
Environment
次に、Envrionmentクラスを紹介します。
Environmentは、メンバ変数にAgentクラスを持ちます。
メソッドはrun()だけです。
CartPoleを1試行実行します。
行っていることはAsynchronousで説明した、以下の実行です。
- スレッドはParameter Serverからネットワークの重みをコピーする
- スレッドのAgentはネットワークにsを入力して、aを得る
- aを実行し、r(t)とs_を得る
- (s,a,r,s_)をスレッドのメモリに格納する
- 2〜4を繰り返す(各スレッドでTmaxステップ経過もしくは、終端に達するまで)
- 経験が十分に溜まったら、メモリの内容を利用して、ネットワークの重みを更新させる方向gradを求める
- gradをParameter Serverに渡す
- Parameter Serverはgradの方向にParameter Serverのネットワークを更新する
- 1.へ戻る
注意点は次のとおりです。
・各スレッドで共有して使うグローバル変数を変更する場合は、globalで変数宣言する必要があります
・最後の部分がややこしいですが、自分のスレッドで10試行平均の性能が199ステップを越えたら、そのときのパラメータをPrameterServerにコピーしています
# --CartPoleを実行する環境です、TensorFlowのスレッドになります -------
class Environment:
total_reward_vec = np.zeros(10) # 総報酬を10試行分格納して、平均総報酬をもとめる
count_trial_each_thread = 0 # 各環境の試行数
def __init__(self, name, thread_type, parameter_server):
self.name = name
self.thread_type = thread_type
self.env = gym.make(ENV)
self.agent = Agent(name, parameter_server) # 環境内で行動するagentを生成
def run(self):
self.agent.brain.pull_parameter_server() # ParameterSeverの重みを自身のLocalBrainにコピー
global frames # セッション全体での試行数、global変数を書き換える場合は、関数内でglobal宣言が必要です
global isLearned
if (self.thread_type is 'test') and (self.count_trial_each_thread == 0):
self.env.reset()
self.env = gym.wrappers.Monitor(self.env, './movie/A3C') # 動画保存する場合
s = self.env.reset()
R = 0
step = 0
while True:
if self.thread_type is 'test':
self.env.render() # 学習後のテストでは描画する
time.sleep(0.1)
a = self.agent.act(s) # 行動を決定
s_, r, done, info = self.env.step(a) # 行動を実施
step += 1
frames += 1 # セッショントータルの行動回数をひとつ増やします
r = 0
if done: # terminal state
s_ = None
if step < 199:
r = -1
else:
r = 1
# Advantageを考慮した報酬と経験を、localBrainにプッシュ
self.agent.advantage_push_local_brain(s, a, r, s_)
s = s_
R += r
if done or (step % Tmax == 0): # 終了時がTmaxごとに、parameterServerの重みを更新し、それをコピーする
if not(isLearned) and self.thread_type is 'learning':
self.agent.brain.update_parameter_server()
self.agent.brain.pull_parameter_server()
if done:
self.total_reward_vec = np.hstack((self.total_reward_vec[1:], step)) # トータル報酬の古いのを破棄して最新10個を保持
self.count_trial_each_thread += 1 # このスレッドの総試行回数を増やす
break
# 総試行数、スレッド名、今回の報酬を出力
print("スレッド:"+self.name + "、試行数:"+str(self.count_trial_each_thread) + "、今回のステップ:" + str(step)+"、平均ステップ:"+str(self.total_reward_vec.mean()))
# スレッドで平均報酬が一定を越えたら終了
if self.total_reward_vec.mean() > 199:
isLearned = True
time.sleep(2.0) # この間に他のlearningスレッドが止まります
self.agent.brain.push_parameter_server() # この成功したスレッドのパラメータをparameter-serverに渡します
Agent
Agentクラスはメンバ変数にLocalBrainと、メモリを持ちます。
メモリはAdvantageを考慮した、(s, a, r, s_)を格納します。
act()メソッドはε-greedy法でランダム行動と、最適行動を選択します。
最適行動は自身のLocalBrainのネットワークから求めます。
advantage_push_local_brain()メソッドは、メモリをLocalBrainのキューに格納します。
このときにAdvantageを考慮した計算を行います。
工夫点は、
・行動aはone-hotcoding(もし選択肢が3つあって、2つ目なら、[0,1,0]の形)にしています
・nステップ分の割引総報酬self.Rを計算する際に、前ステップの結果を利用して計算しています(ヤロミルさんのサイト参照)
# --行動を決定するクラスです、CartPoleであれば、棒付き台車そのものになります -------
class Agent:
def __init__(self, name, parameter_server):
self.brain = LocalBrain(name, parameter_server) # 行動を決定するための脳(ニューラルネットワーク)
self.memory = [] # s,a,r,s_の保存メモリ、 used for n_step return
self.R = 0. # 時間割引した、「いまからNステップ分あとまで」の総報酬R
def act(self, s):
if frames >= EPS_STEPS: # ε-greedy法で行動を決定します 171115修正
eps = EPS_END
else:
eps = EPS_START + frames * (EPS_END - EPS_START) / EPS_STEPS # linearly interpolate
if random.random() < eps:
return random.randint(0, NUM_ACTIONS - 1) # ランダムに行動
else:
s = np.array([s])
p = self.brain.predict_p(s)
# a = np.argmax(p) # これだと確率最大の行動を、毎回選択
a = np.random.choice(NUM_ACTIONS, p=p[0])
# probability = p のこのコードだと、確率p[0]にしたがって、行動を選択
# pにはいろいろな情報が入っていますが確率のベクトルは要素0番目
return a
def advantage_push_local_brain(self, s, a, r, s_): # advantageを考慮したs,a,r,s_をbrainに与える
def get_sample(memory, n): # advantageを考慮し、メモリからnステップ後の状態とnステップ後までのRを取得する関数
s, a, _, _ = memory[0]
_, _, _, s_ = memory[n - 1]
return s, a, self.R, s_
# one-hotコーディングにしたa_catsをつくり、、s,a_cats,r,s_を自分のメモリに追加
a_cats = np.zeros(NUM_ACTIONS) # turn action into one-hot representation
a_cats[a] = 1
self.memory.append((s, a_cats, r, s_))
# 前ステップの「時間割引Nステップ分の総報酬R」を使用して、現ステップのRを計算
self.R = (self.R + r * GAMMA_N) / GAMMA # r0はあとで引き算している、この式はヤロミルさんのサイトを参照
# advantageを考慮しながら、LocalBrainに経験を入力する
if s_ is None:
while len(self.memory) > 0:
n = len(self.memory)
s, a, r, s_ = get_sample(self.memory, n)
self.brain.train_push(s, a, r, s_)
self.R = (self.R - self.memory[0][2]) / GAMMA
self.memory.pop(0)
self.R = 0 # 次の試行に向けて0にしておく
if len(self.memory) >= N_STEP_RETURN:
s, a, r, s_ = get_sample(self.memory, N_STEP_RETURN)
self.brain.train_push(s, a, r, s_)
self.R = self.R - self.memory[0][2] # # r0を引き算
self.memory.pop(0)
ParameterServer
次に全スレッドで共有して持つParameterServerクラスを紹介します。
ここではネットワークの形を定義しており、Kerasを使用しています。
注意点としては、学習にRMSPropOptimizerを使用しています。
RMSPropとは、それまでのパラメータ変化の仕方を考慮した、パラメータ更新方法で、ディープラーニングでよく用いられる手法です。
重要な点は、
with tf.variable_scope("parameter_server"): # スレッド名で重み変数に名前を与え、識別します(Name Space)
で、このネットワークのすべてのパラメータの名前の前に、"parameter_server"を付加していることです。
こうすることで、このネットワークの重みパラメータを
self.weights_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="parameter_server")
で定義できます。
今回複数のネットワークが出てくるので、各ネットワークのパラメータを識別するために、scopeを利用することが重要です。
# --グローバルなTensorFlowのDeep Neural Networkのクラスです -------
class ParameterServer:
def __init__(self):
with tf.variable_scope("parameter_server"): # スレッド名で重み変数に名前を与え、識別します(Name Space)
self.model = self._build_model() # ニューラルネットワークの形を決定
# serverのパラメータを宣言
self.weights_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="parameter_server")
self.optimizer = tf.train.RMSPropOptimizer(LEARNING_RATE, RMSPropDecaly) # loss関数を最小化していくoptimizerの定義です
# 関数名がアンダースコア2つから始まるものは「外部から参照されない関数」、「1つは基本的に参照しない関数」という意味
def _build_model(self): # Kerasでネットワークの形を定義します
l_input = Input(batch_shape=(None, NUM_STATES))
l_dense = Dense(16, activation='relu')(l_input)
out_actions = Dense(NUM_ACTIONS, activation='softmax')(l_dense)
out_value = Dense(1, activation='linear')(l_dense)
model = Model(inputs=[l_input], outputs=[out_actions, out_value])
plot_model(model, to_file='A3C.png', show_shapes=True) # Qネットワークの可視化
return model
LocalBrain
最後にLocalBrainクラスについて説明します。
ボリュームが多くて大変ですが、A3Cの中心となるクラスです。
build_model()は基本的にはParameterServerと同じです。
ですが、実行前にinitでKeras.set_sessionを実行しています。
model._make_predict_function() # have to initialize before threading
で、その後のメソッドが定義できる状態にします。
_build_graph()はこのネットワークに対して実行する様々なメソッドを定義している部分です。
まず、loss関数を定義しています。
loss_policy = - log_prob * tf.stop_gradient(advantage) # stop_gradientでadvantageは定数として扱います
のtf.stop_gradientで「advantage」をバックプロパゲーションの計算時に定数として扱っています。
loss関数の定義はActor-Criticで説明したとおりですが、エントロピー項が追加されています。
エントロピー項は、p(右)、p(左)の更新が、一気に間違った方向に進まないようにする項です。
エントロピー項のさらなる詳細は、ヤロミルさんのサイトが分かりやすいです。
●Let's make an A3C
その後、
・パラメータを自分の名前scopeで求める
・自分のネットワークのgradを求める手法
を定義しています。
後半のメソッドたちは、ParameterServerと自分のネットワークでのやりとりを定義しています。
具体的には、自分のgradientを適用してParameterServerを更新したり、ネットワークの重みをコピーしたりするメソッドの定義です。
ここでzip()はひとつの変数ずつ取り出すコマンドです。
ベクトル変数になっているものから、要素をひとつずつ取り出して、実行しています。
self.update_global_weight_params =
parameter_server.optimizer.apply_gradients(zip(self.grads, parameter_server.weights_params))
あとは定義した操作を、実行するメソッドを定義しています。
# --各スレッドで走るTensorFlowのDeep Neural Networkのクラスです -------
class LocalBrain:
def __init__(self, name, parameter_server): # globalなparameter_serverをメンバ変数として持つ
with tf.name_scope(name):
self.train_queue = [[], [], [], [], []] # s, a, r, s', s' terminal mask
K.set_session(SESS)
self.model = self._build_model() # ニューラルネットワークの形を決定
self._build_graph(name, parameter_server) # ネットワークの学習やメソッドを定義
def _build_model(self): # Kerasでネットワークの形を定義します
l_input = Input(batch_shape=(None, NUM_STATES))
l_dense = Dense(16, activation='relu')(l_input)
out_actions = Dense(NUM_ACTIONS, activation='softmax')(l_dense)
out_value = Dense(1, activation='linear')(l_dense)
model = Model(inputs=[l_input], outputs=[out_actions, out_value])
model._make_predict_function() # have to initialize before threading
return model
def _build_graph(self, name, parameter_server): # TensorFlowでネットワークの重みをどう学習させるのかを定義します
self.s_t = tf.placeholder(tf.float32, shape=(None, NUM_STATES)) # placeholderは変数が格納される予定地となります
self.a_t = tf.placeholder(tf.float32, shape=(None, NUM_ACTIONS))
self.r_t = tf.placeholder(tf.float32, shape=(None, 1)) # not immediate, but discounted n step reward
p, v = self.model(self.s_t)
# loss関数を定義します
log_prob = tf.log(tf.reduce_sum(p * self.a_t, axis=1, keep_dims=True) + 1e-10)
advantage = self.r_t - v
loss_policy = - log_prob * tf.stop_gradient(advantage) # stop_gradientでadvantageは定数として扱います
loss_value = LOSS_V * tf.square(advantage) # minimize value error
entropy = LOSS_ENTROPY * tf.reduce_sum(p * tf.log(p + 1e-10), axis=1, keep_dims=True) # maximize entropy (regularization)
self.loss_total = tf.reduce_mean(loss_policy + loss_value + entropy)
# 重みの変数を定義
self.weights_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=name) # パラメータを宣言
# 勾配を取得する定義
self.grads = tf.gradients(self.loss_total, self.weights_params)
# ParameterServerの重み変数を更新する定義(zipで各変数ごとに計算)
self.update_global_weight_params = \
parameter_server.optimizer.apply_gradients(zip(self.grads, parameter_server.weights_params))
# PrameterServerの重み変数の値を、localBrainにコピーする定義
self.pull_global_weight_params = [l_p.assign(g_p)
for l_p, g_p in zip(self.weights_params, parameter_server.weights_params)]
# localBrainの重み変数の値を、PrameterServerにコピーする定義
self.push_local_weight_params = [g_p.assign(l_p)
for g_p, l_p in zip(parameter_server.weights_params, self.weights_params)]
def pull_parameter_server(self): # localスレッドがglobalの重みを取得する
SESS.run(self.pull_global_weight_params)
def push_parameter_server(self): # localスレッドの重みをglobalにコピーする
SESS.run(self.push_local_weight_params)
def update_parameter_server(self): # localbrainの勾配でParameterServerの重みを学習・更新します
if len(self.train_queue[0]) < MIN_BATCH: # データがたまっていない場合は更新しない
return
s, a, r, s_, s_mask = self.train_queue
self.train_queue = [[], [], [], [], []]
s = np.vstack(s) # vstackはvertical-stackで縦方向に行列を連結、いまはただのベクトル転置操作
a = np.vstack(a)
r = np.vstack(r)
s_ = np.vstack(s_)
s_mask = np.vstack(s_mask)
# Nステップあとの状態s_から、その先得られるであろう時間割引総報酬vを求めます
_, v = self.model.predict(s_)
# N-1ステップあとまでの時間割引総報酬rに、Nから先に得られるであろう総報酬vに割引N乗したものを足します
r = r + GAMMA_N * v * s_mask # set v to 0 where s_ is terminal state
feed_dict = {self.s_t: s, self.a_t: a, self.r_t: r} # 重みの更新に使用するデータ
SESS.run(self.update_global_weight_params, feed_dict) # ParameterServerの重みを更新
def predict_p(self, s): # 状態sから各actionの確率pベクトルを返します
p, v = self.model.predict(s)
return p
def train_push(self, s, a, r, s_):
self.train_queue[0].append(s)
self.train_queue[1].append(a)
self.train_queue[2].append(r)
if s_ is None:
self.train_queue[3].append(NONE_STATE)
self.train_queue[4].append(0.)
else:
self.train_queue[3].append(s_)
self.train_queue[4].append(1.)
実行
以上で、コードは完成です(ただし定数宣言部分を除く)。
全コードは記事の最後に掲載しています。
このA3Cを実行すると、8つのlearningスレッドが実行され、およそ各スレッドが130試行から200試行弱で、つまり、合計すると1000試行ほどで学習が終わります。
試行数としてはDQNより多いのですが、実行時間は圧倒的にA3Cの方が早いです。
こんな感じの挙動をします。
以上、A3C実装の解説でした。
次回記事ではUNREALを行う予定です。
最終的なコード
最後に全コードを掲載します。
# coding:utf-8
# -----------------------------------
# OpenGym CartPole-v0 with A3C on CPU
# -----------------------------------
#
# A3C implementation with TensorFlow multi threads.
#
# Made as part of Qiita article, available at
# https://??/
#
# author: Sugulu, 2017
import tensorflow as tf
import gym, time, random, threading
from gym import wrappers # gymの画像保存
from keras.models import *
from keras.layers import *
from keras.utils import plot_model
from keras import backend as K
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # TensorFlow高速化用のワーニングを表示させない
# -- constants of Game
ENV = 'CartPole-v0'
env = gym.make(ENV)
NUM_STATES = env.observation_space.shape[0] # CartPoleは4状態
NUM_ACTIONS = env.action_space.n # CartPoleは、右に左に押す2アクション
NONE_STATE = np.zeros(NUM_STATES)
# -- constants of LocalBrain
MIN_BATCH = 5
LOSS_V = .5 # v loss coefficient
LOSS_ENTROPY = .01 # entropy coefficient
LEARNING_RATE = 5e-3
RMSPropDecaly = 0.99
# -- params of Advantage-ベルマン方程式
GAMMA = 0.99
N_STEP_RETURN = 5
GAMMA_N = GAMMA ** N_STEP_RETURN
N_WORKERS = 8 # スレッドの数
Tmax = 10 # 各スレッドの更新ステップ間隔
# ε-greedyのパラメータ
EPS_START = 0.5
EPS_END = 0.0
EPS_STEPS = 200*N_WORKERS
# --グローバルなTensorFlowのDeep Neural Networkのクラスです -------
class ParameterServer:
def __init__(self):
with tf.variable_scope("parameter_server"): # スレッド名で重み変数に名前を与え、識別します(Name Space)
self.model = self._build_model() # ニューラルネットワークの形を決定
# serverのパラメータを宣言
self.weights_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="parameter_server")
self.optimizer = tf.train.RMSPropOptimizer(LEARNING_RATE, RMSPropDecaly) # loss関数を最小化していくoptimizerの定義です
# 関数名がアンダースコア2つから始まるものは「外部から参照されない関数」、「1つは基本的に参照しない関数」という意味
def _build_model(self): # Kerasでネットワークの形を定義します
l_input = Input(batch_shape=(None, NUM_STATES))
l_dense = Dense(16, activation='relu')(l_input)
out_actions = Dense(NUM_ACTIONS, activation='softmax')(l_dense)
out_value = Dense(1, activation='linear')(l_dense)
model = Model(inputs=[l_input], outputs=[out_actions, out_value])
plot_model(model, to_file='A3C.png', show_shapes=True) # Qネットワークの可視化
return model
# --各スレッドで走るTensorFlowのDeep Neural Networkのクラスです -------
class LocalBrain:
def __init__(self, name, parameter_server): # globalなparameter_serverをメンバ変数として持つ
with tf.name_scope(name):
self.train_queue = [[], [], [], [], []] # s, a, r, s', s' terminal mask
K.set_session(SESS)
self.model = self._build_model() # ニューラルネットワークの形を決定
self._build_graph(name, parameter_server) # ネットワークの学習やメソッドを定義
def _build_model(self): # Kerasでネットワークの形を定義します
l_input = Input(batch_shape=(None, NUM_STATES))
l_dense = Dense(16, activation='relu')(l_input)
out_actions = Dense(NUM_ACTIONS, activation='softmax')(l_dense)
out_value = Dense(1, activation='linear')(l_dense)
model = Model(inputs=[l_input], outputs=[out_actions, out_value])
model._make_predict_function() # have to initialize before threading
return model
def _build_graph(self, name, parameter_server): # TensorFlowでネットワークの重みをどう学習させるのかを定義します
self.s_t = tf.placeholder(tf.float32, shape=(None, NUM_STATES)) # placeholderは変数が格納される予定地となります
self.a_t = tf.placeholder(tf.float32, shape=(None, NUM_ACTIONS))
self.r_t = tf.placeholder(tf.float32, shape=(None, 1)) # not immediate, but discounted n step reward
p, v = self.model(self.s_t)
# loss関数を定義します
log_prob = tf.log(tf.reduce_sum(p * self.a_t, axis=1, keep_dims=True) + 1e-10)
advantage = self.r_t - v
loss_policy = - log_prob * tf.stop_gradient(advantage) # stop_gradientでadvantageは定数として扱います
loss_value = LOSS_V * tf.square(advantage) # minimize value error
entropy = LOSS_ENTROPY * tf.reduce_sum(p * tf.log(p + 1e-10), axis=1, keep_dims=True) # maximize entropy (regularization)
self.loss_total = tf.reduce_mean(loss_policy + loss_value + entropy)
# 重みの変数を定義
self.weights_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=name) # パラメータを宣言
# 勾配を取得する定義
self.grads = tf.gradients(self.loss_total, self.weights_params)
# ParameterServerの重み変数を更新する定義(zipで各変数ごとに計算)
self.update_global_weight_params = \
parameter_server.optimizer.apply_gradients(zip(self.grads, parameter_server.weights_params))
# PrameterServerの重み変数の値を、localBrainにコピーする定義
self.pull_global_weight_params = [l_p.assign(g_p)
for l_p, g_p in zip(self.weights_params, parameter_server.weights_params)]
# localBrainの重み変数の値を、PrameterServerにコピーする定義
self.push_local_weight_params = [g_p.assign(l_p)
for g_p, l_p in zip(parameter_server.weights_params, self.weights_params)]
def pull_parameter_server(self): # localスレッドがglobalの重みを取得する
SESS.run(self.pull_global_weight_params)
def push_parameter_server(self): # localスレッドの重みをglobalにコピーする
SESS.run(self.push_local_weight_params)
def update_parameter_server(self): # localbrainの勾配でParameterServerの重みを学習・更新します
if len(self.train_queue[0]) < MIN_BATCH: # データがたまっていない場合は更新しない
return
s, a, r, s_, s_mask = self.train_queue
self.train_queue = [[], [], [], [], []]
s = np.vstack(s) # vstackはvertical-stackで縦方向に行列を連結、いまはただのベクトル転置操作
a = np.vstack(a)
r = np.vstack(r)
s_ = np.vstack(s_)
s_mask = np.vstack(s_mask)
# Nステップあとの状態s_から、その先得られるであろう時間割引総報酬vを求めます
_, v = self.model.predict(s_)
# N-1ステップあとまでの時間割引総報酬rに、Nから先に得られるであろう総報酬vに割引N乗したものを足します
r = r + GAMMA_N * v * s_mask # set v to 0 where s_ is terminal state
feed_dict = {self.s_t: s, self.a_t: a, self.r_t: r} # 重みの更新に使用するデータ
SESS.run(self.update_global_weight_params, feed_dict) # ParameterServerの重みを更新
def predict_p(self, s): # 状態sから各actionの確率pベクトルを返します
p, v = self.model.predict(s)
return p
def train_push(self, s, a, r, s_):
self.train_queue[0].append(s)
self.train_queue[1].append(a)
self.train_queue[2].append(r)
if s_ is None:
self.train_queue[3].append(NONE_STATE)
self.train_queue[4].append(0.)
else:
self.train_queue[3].append(s_)
self.train_queue[4].append(1.)
# --行動を決定するクラスです、CartPoleであれば、棒付き台車そのものになります -------
class Agent:
def __init__(self, name, parameter_server):
self.brain = LocalBrain(name, parameter_server) # 行動を決定するための脳(ニューラルネットワーク)
self.memory = [] # s,a,r,s_の保存メモリ、 used for n_step return
self.R = 0. # 時間割引した、「いまからNステップ分あとまで」の総報酬R
def act(self, s):
if frames >= EPS_STEPS: # ε-greedy法で行動を決定します 171115修正
eps = EPS_END
else:
eps = EPS_START + frames * (EPS_END - EPS_START) / EPS_STEPS # linearly interpolate
if random.random() < eps:
return random.randint(0, NUM_ACTIONS - 1) # ランダムに行動
else:
s = np.array([s])
p = self.brain.predict_p(s)
# a = np.argmax(p) # これだと確率最大の行動を、毎回選択
a = np.random.choice(NUM_ACTIONS, p=p[0])
# probability = p のこのコードだと、確率p[0]にしたがって、行動を選択
# pにはいろいろな情報が入っていますが確率のベクトルは要素0番目
return a
def advantage_push_local_brain(self, s, a, r, s_): # advantageを考慮したs,a,r,s_をbrainに与える
def get_sample(memory, n): # advantageを考慮し、メモリからnステップ後の状態とnステップ後までのRを取得する関数
s, a, _, _ = memory[0]
_, _, _, s_ = memory[n - 1]
return s, a, self.R, s_
# one-hotコーディングにしたa_catsをつくり、、s,a_cats,r,s_を自分のメモリに追加
a_cats = np.zeros(NUM_ACTIONS) # turn action into one-hot representation
a_cats[a] = 1
self.memory.append((s, a_cats, r, s_))
# 前ステップの「時間割引Nステップ分の総報酬R」を使用して、現ステップのRを計算
self.R = (self.R + r * GAMMA_N) / GAMMA # r0はあとで引き算している、この式はヤロミルさんのサイトを参照
# advantageを考慮しながら、LocalBrainに経験を入力する
if s_ is None:
while len(self.memory) > 0:
n = len(self.memory)
s, a, r, s_ = get_sample(self.memory, n)
self.brain.train_push(s, a, r, s_)
self.R = (self.R - self.memory[0][2]) / GAMMA
self.memory.pop(0)
self.R = 0 # 次の試行に向けて0にしておく
if len(self.memory) >= N_STEP_RETURN:
s, a, r, s_ = get_sample(self.memory, N_STEP_RETURN)
self.brain.train_push(s, a, r, s_)
self.R = self.R - self.memory[0][2] # # r0を引き算
self.memory.pop(0)
# --CartPoleを実行する環境です、TensorFlowのスレッドになります -------
class Environment:
total_reward_vec = np.zeros(10) # 総報酬を10試行分格納して、平均総報酬をもとめる
count_trial_each_thread = 0 # 各環境の試行数
def __init__(self, name, thread_type, parameter_server):
self.name = name
self.thread_type = thread_type
self.env = gym.make(ENV)
self.agent = Agent(name, parameter_server) # 環境内で行動するagentを生成
def run(self):
self.agent.brain.pull_parameter_server() # ParameterSeverの重みを自身のLocalBrainにコピー
global frames # セッション全体での試行数、global変数を書き換える場合は、関数内でglobal宣言が必要です
global isLearned
if (self.thread_type is 'test') and (self.count_trial_each_thread == 0):
self.env.reset()
self.env = gym.wrappers.Monitor(self.env, './movie/A3C') # 動画保存する場合
s = self.env.reset()
R = 0
step = 0
while True:
if self.thread_type is 'test':
self.env.render() # 学習後のテストでは描画する
time.sleep(0.1)
a = self.agent.act(s) # 行動を決定
s_, r, done, info = self.env.step(a) # 行動を実施
step += 1
frames += 1 # セッショントータルの行動回数をひとつ増やします
r = 0
if done: # terminal state
s_ = None
if step < 199:
r = -1
else:
r = 1
# Advantageを考慮した報酬と経験を、localBrainにプッシュ
self.agent.advantage_push_local_brain(s, a, r, s_)
s = s_
R += r
if done or (step % Tmax == 0): # 終了時がTmaxごとに、parameterServerの重みを更新し、それをコピーする
if not(isLearned) and self.thread_type is 'learning':
self.agent.brain.update_parameter_server()
self.agent.brain.pull_parameter_server()
if done:
self.total_reward_vec = np.hstack((self.total_reward_vec[1:], step)) # トータル報酬の古いのを破棄して最新10個を保持
self.count_trial_each_thread += 1 # このスレッドの総試行回数を増やす
break
# 総試行数、スレッド名、今回の報酬を出力
print("スレッド:"+self.name + "、試行数:"+str(self.count_trial_each_thread) + "、今回のステップ:" + str(step)+"、平均ステップ:"+str(self.total_reward_vec.mean()))
# スレッドで平均報酬が一定を越えたら終了
if self.total_reward_vec.mean() > 199:
isLearned = True
time.sleep(2.0) # この間に他のlearningスレッドが止まります
self.agent.brain.push_parameter_server() # この成功したスレッドのパラメータをparameter-serverに渡します
# --スレッドになるクラスです -------
class Worker_thread:
# スレッドは学習環境environmentを持ちます
def __init__(self, thread_name, thread_type, parameter_server):
self.environment = Environment(thread_name, thread_type, parameter_server)
self.thread_type = thread_type
def run(self):
while True:
if not(isLearned) and self.thread_type is 'learning': # learning threadが走る
self.environment.run()
if not(isLearned) and self.thread_type is 'test': # test threadを止めておく
time.sleep(1.0)
if isLearned and self.thread_type is 'learning': # learning threadを止めておく
time.sleep(3.0)
if isLearned and self.thread_type is 'test': # test threadが走る
time.sleep(3.0)
self.environment.run()
# -- main ここからメイン関数です------------------------------
# M0.global変数の定義と、セッションの開始です
frames = 0 # 全スレッドで共有して使用する総ステップ数
isLearned = False # 学習が終了したことを示すフラグ
SESS = tf.Session() # TensorFlowのセッション開始
# M1.スレッドを作成します
with tf.device("/cpu:0"):
parameter_server = ParameterServer() # 全スレッドで共有するパラメータを持つエンティティです
threads = [] # 並列して走るスレッド
# 学習するスレッドを用意
for i in range(N_WORKERS):
thread_name = "local_thread"+str(i+1)
threads.append(Worker_thread(thread_name=thread_name, thread_type="learning", parameter_server=parameter_server))
# 学習後にテストで走るスレッドを用意
threads.append(Worker_thread(thread_name="test_thread", thread_type="test", parameter_server=parameter_server))
# M2.TensorFlowでマルチスレッドを実行します
COORD = tf.train.Coordinator() # TensorFlowでマルチスレッドにするための準備です
SESS.run(tf.global_variables_initializer()) # TensorFlowを使う場合、最初に変数初期化をして、実行します
running_threads = []
for worker in threads:
job = lambda: worker.run() # この辺は、マルチスレッドを走らせる作法だと思って良い
t = threading.Thread(target=job)
t.start()
#running_threads.append(t)
# M3.スレッドの終了を合わせます
# COORD.join(running_threads)
A3C実装の解説でした。
次はUNREALを行う予定です。
以上、ご一読いただき、ありがとうございました。