ざっくり言うと
リスト構造のデータに対してランダムアクセスはしちゃだめだぞ。お兄さんとの約束だ!
発端
数年前に他部署の支援で作ったJavaのシステムに、ちょっとデカめのデータを突っ込んだらありえないほど遅いので助けてくれ、と連絡が入った。
まぁクエリとかインデックスをちょっと見れば直るっしょ・・・と鼻をほじりながら支援に向かった。
処理内容
遅い部分の処理は以下のようなものであった。
- 処理対象のデータをListで受け取る。
- それをforループで1件ずつ前処理する。
- 処理結果をオブジェクトに格納し、ORマッパーでDBにINSERTする。
これだけ?
そう、これだけだ。並列処理なんて高級なことはもちろんやってない。
インフラ調査
処理中のサーバのようすを調査する。今回のインフラは典型的な3層3サーバ構成。
WEBサーバはなにもかもが余裕。
APサーバではCPUを1つ使い切っている。
14コアのサーバ(EC2のc4.4xlarge)なので、1つのCPUがどれだけ頑張っても使用率7%なのが悲しい。
DBサーバでは多少のディスク負荷はあるが性能的には余裕。
ネットワーク、メモリ等も調査したがすべてのリソースが有り余っている。
各種設定値も正常だ。
DBまわりを調査
ご覧の通りほぼINSERTしかやってないような処理である。
そのため、APのCPU負荷は気になるものの、その場の全員がDBまわりを疑いいろいろといじりまわしていた。
しまいにはORマッパーのバグを踏んだのでは?という声まで出てきて、JDBCを直接使うという懐かしい体験もした。
しかし成果はなく、ランボー怒りの休日出勤が決定する・・・。
発見
基本に立ち返り、ロジックの処理時間の分析をやりなおす。
「ループ回数が進むごとに処理が重くなってる気がする」という証言のもと、
ループ回数と1ループの処理時間の関係を出してみることにした。
以下は分析結果のイメージである。入力データ量を変え、N万件と2N万件で比較した。
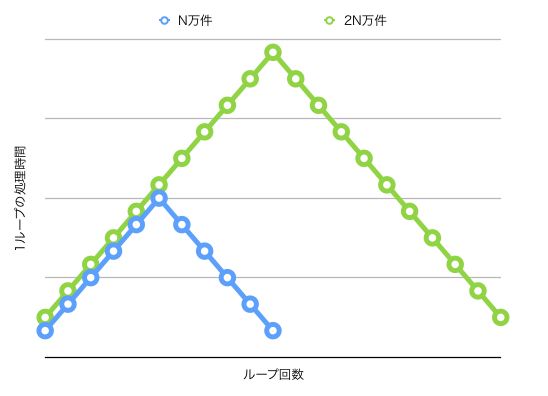
「後半減っとる・・・!!」
小さい方のデータは大きい方のデータの前半を切り出したものなので、データの内容による変動ではなさそうだ。
さらに細かく分析すると、グラフの頂上の部分で最も時間を食っていたのは以下の一行だった。
変数dataの型はList<MyClass>である。
MyClass record = data.get(i);
これには度肝を抜かれた。Listから要素を取得するだけがめちゃくちゃ遅いのである。
誰かが口を開いた。
「これ、LinkedListなんじゃね?」
2N万件もあるLinkedListのN万番目を取り出そうとして、とてつもない時間がかっていたのだ。
おそらくリストのサイズの半分を基準にして、後半の方のデータにはお尻からアクセスするようになっているのだろう。
我々を休出に誘ったトラブルは、for文を拡張for文に変えるというリファクタリングレベルの変更で幕を閉じた。
for (int i = 0; i < data.size(); i++) {
MyClass record = data.get(i);
...
}
↓
int i = 0;
for (MyClass record: data) {
...
i++;
}
一見これ何の違いがあるの?という変更ではあるが、Listにとっては変更前はランダムアクセス、
変更後は(Iteratorによる)シーケンシャルアクセスということになり、データ件数が多いときにはパフォーマンスに雲泥の差が出るのだった。
大変勉強になりました。
はじめ拡張for文を使っていなかった理由は、処理の中でiの値も使いたかったというもの。
JavaにもPythonのenumerateがあればなあ・・・(恨み言)