さまざまなニュースアプリ、ブログ、SNSと近年テキストの情報はますます増えています。日々たくさんの情報が配信されるため、Twitterやまとめサイトを見ていたら数時間たっていた・・・なんてこともよくあると思います。世はまさに大自然言語時代。
 *from [THE HISTORICAL GROWTH OF DATA: WHY WE NEED A FASTER TRANSFER SOLUTION FOR LARGE DATA SETS](https://www.signiant.com/articles/file-transfer/the-historical-growth-of-data-why-we-need-a-faster-transfer-solution-for-large-data-sets/)
テキスト、音声、画像、動画といった非構造データの増加を示したグラフ*
*from [THE HISTORICAL GROWTH OF DATA: WHY WE NEED A FASTER TRANSFER SOLUTION FOR LARGE DATA SETS](https://www.signiant.com/articles/file-transfer/the-historical-growth-of-data-why-we-need-a-faster-transfer-solution-for-large-data-sets/)
テキスト、音声、画像、動画といった非構造データの増加を示したグラフ*
そこで注目される技術が、「要約」です。膨大な情報を要点をまとめた短い文章にすることができれば、単純に時間の節約になるだけでなく、多様な視点から書かれた情報を並べて吟味することもできます。
本文書は、この文書要約(Text Summarization)についてその概観を示すことを目的として書かれています。具体的には、以下の順に沿って解説をしていきます。
- 要約というタスクの種類
- 要約を作成する手法
- 良い要約の評価
- 要約の作成に使えるツール
- 要約を試すためのデータセット
1. 要約というタスクの種類
単純に「要約」といっても、いろいろな種類があるためまずはそれらを整理します。今後要約に取り組みたいと思ったときに、どんな「要約」に挑戦しようとしているのかをはっきりさせる足掛かりにしていただければと思います。
要約というタスクを整理する観点としては、3つの観点があります。
- 要約のインプットとなる文書
- 要約作成に対する意思入れ
- 作成される要約の内容
第一に、要約するのは単一の文書なのか、複数の文書なのかといった観点があります。単一の場合はSingle document summarization、複数の場合はMulti-document summarizationと呼ばれます。
第二に、要約に際して何らかの指示を与えるかという観点があります。何も指示をせず単純に要約を作成する処理をGeneric summarizationと呼びます。これに対して、何らかのトピックやキーワードを指定してそれを中心とした要約を作成させることをQuery focused summarizationと呼びます。この特殊なケースとして、文章の更新前後の差分に着目するUpdate summarizationがあります。これは例えば、メールの要約を行う際に前回のメールとの差分に特に注目して要約を行うといったようなタスクになります。
実用的な側面としては、指示を与えない単純な要約(Generic summarization)は意味がないという議論もあります(Automatic summarizing: factors and directions)。これは個人的にはかなり共感する意見です(実際作成してみた要約を見ると特にそう感じます)。
最後に、作成する要約の内容、スタイルについての観点があります。内容については、例えば書籍や映画を紹介するために要約する場合、ネタバレしてしまうと困るでしょう。その場合内容全体まではわからないように要約を作成することになりますが、こうした要約をIndicative summaryと呼びます。これとは逆に、すべての内容をもとに作成する要約をInformative summaryと呼びます。
要約のスタイルは、長さや形式といった観点です。特に一行でまとめるような要約をHeadline summaryと呼びます。また文ではなく、単語だけを抽出するようなスタイルをKeyword summaryと呼びます。
要約に取り組む際は、これら3つの観点を元にどういったタスクかを定義することで、先行研究の調査が行いやすくなります。
2. 要約を作成する手法
要約を作成するには、主に抽出型(Extractive)と抽象型(Abstractive)の2つのアプローチがあります。本節では、各アプローチの概要とその代表的なアルゴリズムについて解説を行います。
2.1 抽出型(Extractive)
抽出型は、要約対象の文章の中から重要と思われる文を抽出して要約を作成するというアプローチです。そのメリットとデメリットは、以下のようになります。
- メリット: 元の文章中にある文を選択して要約を作成するため、まったく内容がつかめない要約になる可能性が低く、文法的におかしな要約になることもない
- デメリット: 文中にない単語を利用することはできないため、抽象化や言い換え、読みやすくするための接続詞の使用などができない。このため、作成された要約は粗雑な印象になる。
続いて、抽出型の代表的な手法をいくつか紹介します。
2.1.1 Graph Base Methods
グラフベースの手法は、文章をグラフ構造で表現し各ノード(=文や単語)の関係性を元に要約を作成するという手法です。代表的なアルゴリズムとしては、TextRankがあります。TextRankは、Google検索の基礎となっているPageRankという手法を文章に応用した手法です。PageRankの基本的な考えは、リンクされているページは良いページで、さらに多くリンクされているページ(=人気のページ)からのリンクは高く評価されるというものです。この評価は、ページに対するユーザーの流入量と等価になります(多くのページからリンクが張られていれば流入しやすく、人気のページからの流入は通常のページからの流入より大きい)。ページ間のリンクは行列で表現することができ、各ページにおけるリンクの総数で割ることでこの行列はユーザーがそのページからリンクが張られた別のページに遷移する確率の行列になります(下図$M$)。これを利用し、ユーザーが各ページに滞在する確率(下図$P$)=ページの評価を求めることがPageRankの目的です。
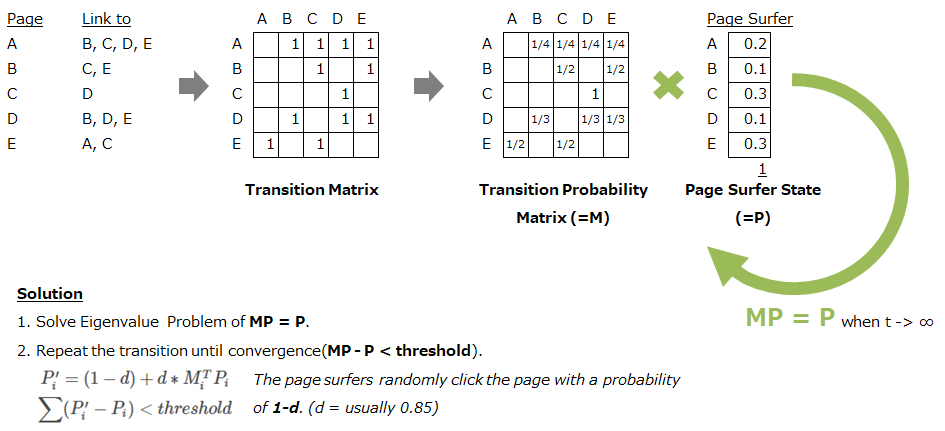
$P$を求めるには、固有値問題を解く方法とページ遷移の試行を繰り返す方法の2つのアプローチがあります。何れも、多くの回数ページ遷移を繰り返していけば、最終的にページの滞在確率は安定する($MP=P$が成立する)という前提に基づいています。固有値問題を解く方法はこれを実現する$P$を直接求めることができますが、行列のサイズが大きくなると解くのにすごく時間がかかります。試行ベースの方は、一発では解けませんがページ数が多い場合でも$P$を求めることができます。
PageRankの説明が長くなりましたが、TextRankはこれを文章に応用した手法になります。TextRankのポイントは以下の2点です。
- 何をNodeとするか:単語、文etc..
- 何をEdgeとするか:単語/文の類似度、参照関係etc
この定義が決まれば、あとはPageRankと同じ手法で解くことができます。なお、LexRankはNodeに文、Edge/Weightに類似度を使用した手法になります。
2.1.2 Feature Base Methods
文の特徴を定義して、その特徴による重みづけ(スコアリング)を行うことで文選択を行うのがFeature Baseの手法です。例えば、以下の論文がFeature Baseの手法として挙げられます。
Sentence Extraction Based Single Document Summarization
この論文では、文のスコアリングをした後に、文の選択を行っています。文のスコアリングには、以下の特徴が使用されています。
- 文章における、文の位置
- 文に動詞が含まれるか否か
- 文の長さ
- 単語の出現頻度
- 単語の固有表現
- 単語に適用されているフォントスタイル
・・・などです。これらの特徴は、以下の計算式で一つのスコアにまとめられます。
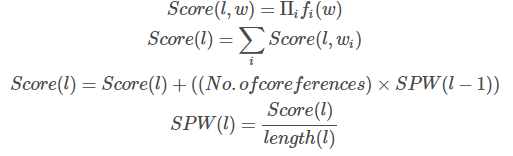
単語ベースの特徴を掛け合わせて$Score(l, w)$を算出し、文中に含まれる各単語のスコアを合計しています。なお、前の文章への参照を考慮するために、No.of coreferencesを使用しています。これは単純に文の前半に含まれる代名詞の数で、代名詞の数分だけ一つ前の文章の平均スコア($Score$を$length$で割った$SPW$)をかけています。
特徴ベースの歴史は古く、古典的なLuhn’s Algorithmでは、単語の出現頻度から「重要度」を算出し、それが文を区切ったバケットにどれだけ含まれるかでスコアリングを行っています。
続いて、文の選択には算出したスコアだけでなく「選択済み」の文に含まれる単語との一致率が考慮されています。これは、既に選択した文との情報の重複を避けるための工夫です。さらに、そのあと文のつながりを自然にするために疑問形の削除や特定接続詞の削除などを行っています(Refinement)。
なお、文選択のプロセスはFeature Baseだけでなく抽出型全体において重要なプロセスです。というのも、単純にスコアの高い順から文を選択していくと情報の重複などが起こってしまうためです。文選択後のブラッシュアップであるRefinementについても同様のことが言えます。
2.1.3 Topic Base Methods
Topic Baseの手法は、文章のトピックを算出し、そのトピックに沿った文を選択するという手法です。重要なトピックに近い文を選択する、各トピックの代表文を選ぶ、などです。Topic Baseの手法については、以下の論文によくまとめられています。
Text summarization using Latent Semantic Analysis
Topic Baseの手法ではLSA(Latent Semantic Analysis)という手法が良く用いられます。これは、縦に文、横に単語をとった文章行列を特異値分解(Singular Value Decomposition=SVD)にかけて、その固有ベクトル(=トピック)を算出するという手法です。以下の図は、SVDを実行して得られた2つのトピック成分上に各文をプロットした図(左)と、各トピックごとに最も高い値を持つ文を選択している図になります(右)。

特異値分解の結果得られた固有ベクトルや固有値をどのように使って文のスコアを算出するのか、またどのように文を選択していくのか、という点で様々なバリエーションがあります。
2.2 抽象型(Abstractive)
抽象型は、人が要約を作成するときのように、文章の意味を汲み取ったうえで(=抽象化した上で)適切な要約を作成する手法です。そのメリットとデメリットは、以下のようになります。
- メリット: 元の文中にはない単語を自由に使って要約を作成できるため、より自然な要約を作成できる。また、要約の長さに対する自由度が大きい。
- デメリット: 文法的に違和感がなく、また前後の文脈で不整合が生じないような自然な文を生成することが難しい。
抽象型の代表的な手法としては、Encoder-Decoderモデルがあります。
2.2.1 Encoder-Decoder Model
Encoder-Decoderモデルは、Encoderで文を潜在表現に圧縮し、Decoderは圧縮された表現から文を生成する、というモデルです。翻訳のタスクでよく使用されるモデルで、翻訳元の文をEncoderで圧縮し、翻訳先の文にDecodeするといった形で利用されています。
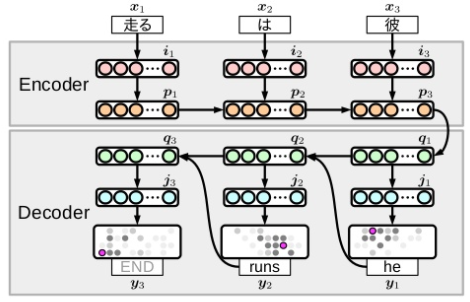
Encoder-decoder 翻訳 (TISハンズオン資料)
要約に適用する場合、文章をEncoder入れていきDecoderから要約を生成させる形になります。文章から直接要約を生成するという形になるため、End-to-Endのモデルともいわれます。TensorFlowには、この形式で要約を作成するモデルが組み込まれています。
Text summarization with TensorFlow
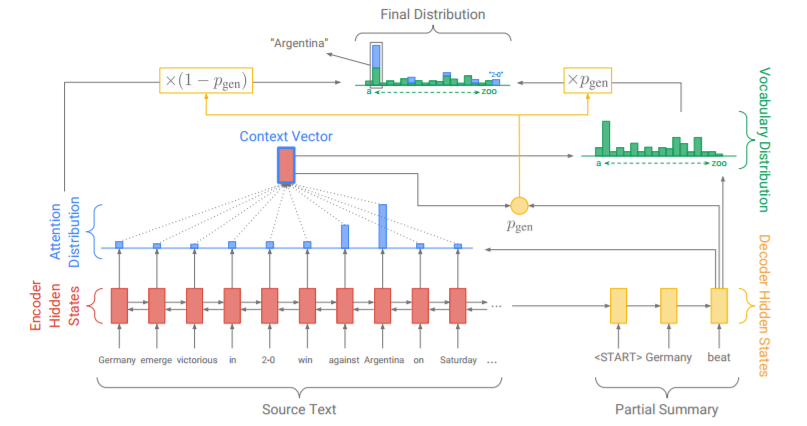
なお、抽出型と抽象型のいい所どりをする研究も近年は進められています。以下の研究は、抽出と生成をスイッチする確率p_genを算出しながら要約を作成するとうアイデアです。
Get To The Point: Summarization with Pointer-Generator Networks
3. 良い要約の評価
要約を評価する観点としては、通常の機械学習と同様適合率(Precision)と再現率(Recall)の観点があります。
3.1 ROUGE-N カバー率の評価
ROUGE-NのNはN-gramのNで、生成した要約と人間が作成した要約がN-gram単位でどれだけ一致しているかを計測した指標です。ROUGE-1なら単語単位、ROUGE-2ならbi-gram単位の一致になります。例えば、"いちご ばなな"と"ばなな いちご"は、ROUGE-1単位(単語単位)では一致しますが、ROUGE-2、つまりbi-gramなら"いちご ばなな"が一単位になるため一致はしなくなります。これは即ち正解の要約文中にあるN-gramの組み合わせがどれだけ生成した要約に出てくるかを表しており、乱暴に言えば要約文をすごく長くすればそれだけROUGEスコアは高くなる傾向があります。そうした意味で、ROUGEによる評価はRecall的といえます。もちろん、これだけでは「実際の要約にはない」単語=ミスが評価されません。そこで出てくるのが、次のBLEUスコアです。
3.2 BLEU 一致率の評価
BLEUは、生成した要約のN-gram中のどれだけが実際の要約に登場するかで評価されます(なお、この場合長い文は短い文に比べてN-gram数が大きくなり不利になるため、調整が行われています)。BLEUは分母に生成した要約のN-gram数が来るため、乱発すればそれだけ一致する率は下がることになります。このため、Precision的な評価が可能になります。なお、BLEUは翻訳のタスクでよく使用されています。
実際には、評価ではROUGEが使われることが多いです。というのも、たいていの場合要約の長さには制限があり、「長々生成してスコアを稼ぐ」という戦略自体が利用できないためです。
4.要約の作成に使えるツール・データセット
要約を作成してみたいという熱が高まったに違いないと思うので、最後に実際に要約を作成できるツールとデータセットを紹介します。
4.1 ツール
これまで紹介した、抽出型/抽象型の要約の手法ごとに紹介します。
抽出型(Extractive)
- Graph Base
- gensim
- pytextrank
- Feature Base
- TextTeaser
- PyTeaser
- Topic Base
- gensim models.lsimodel
sumyは、抽出型の手法を広くカバーするソフトウェアになっています。
抽象型(Abstractive)
4.2 データセット
要約を行うためのデータセットとしては、以下のデータセットがあります。
-
DUC 2004
- 最もメジャーですが、ダウンロードをするのに署名してメール送信しないといけないなどハードルが高いです
-
Annotated English Gigaword
- こちらは有料のデータセットになります
- Opinosis Dataset - Topic related review sentences
- 17 Timelines
- Legal Case Reports Data Set
X.参考文献
Papers
- Automatic summarization
- Automatic summarizing: factors and directions
- TextRank: Bringing Order into Texts
- LexRank: Graph-based Lexical Centrality as Salience in Text Summarization
- Sentence Extraction Based Single Document Summarization
- Luhn’s Algorithm
- Text summarization using Latent Semantic Analysis
- Get To The Point: Summarization with Pointer-Generator Networks
Blog/Wikis