本記事の前に下記の記事をどうぞ。
府大生が趣味で世界一の認識精度を持つニューラルネットワークを開発してしまった論文を読んだ
(2017/10/24追記)ご本人よりShakeDropの論文では、2つを比較した上でCutoutではなく、Random Erasingを利用しているとコメントを頂きましたので修正しました。
はじめに
府大生がニューラルネットワークの「認識精度世界一」を奪還してしまったようです。
一般物体認識分野「認識精度 世界一」を奪還! 府大生が開発したニューラルネットワーク https://t.co/9HSt7iGl55
— ニーシェス (@lachesis1120) 2017年10月19日
前回は趣味だったのが、今回は晴れて本業になったようです。
具体的な内容は、10月に開催された電子情報通信学会のパターン認識・メディア理解 (PRMU) 研究会の技術報告1にありますので、解説していきたいと思います。
こういう面白い発表がありますので、是非PRMU研究会に一度参加してみましょう!12月は東京開催で、コンピュータビジョン勉強会@関東と合同開催となっております。
【サマリ】本稿で解説するShakeDropは、強力な特徴レベルのdata augmentationを行うモデルであるShake-Shakeを改良することで非常に深いモデルであるPyramidNetをベースネットワークとして利用することを可能とし、更に強力な画像レベルのdata augmentationを行うCutoutRandom Erasingを利用しつつ、1800エポックという長時間学習させることで、既存手法に対しかなりの精度向上を実現しています。
Residual Networks
Residual Networks (ResNet) 2は、大規模画像認識のコンペティションであるILSVRC'15で優勝した、現状のデファクトスタンダードといえる畳み込みニューラルネットワークのアーキテクチャです。
ResNet以前まではネットワークを深くすることで表現能力を向上させ、認識精度を改善することが行われてきましたが、あまりにも深いネットワークは、batch normalization等を利用しても最適化が困難でした。
ResNetでは、通常のネットワークのように、何かしらの処理ブロックによる変換$F(x)$を単純に次の層に渡していくのではなく、その処理ブロックへの入力$x$をショートカットし、$F(x)+x$を次の処理ブロックに渡すことが行われます。この処理単位はresidual unit (or building block) と呼ばれます。
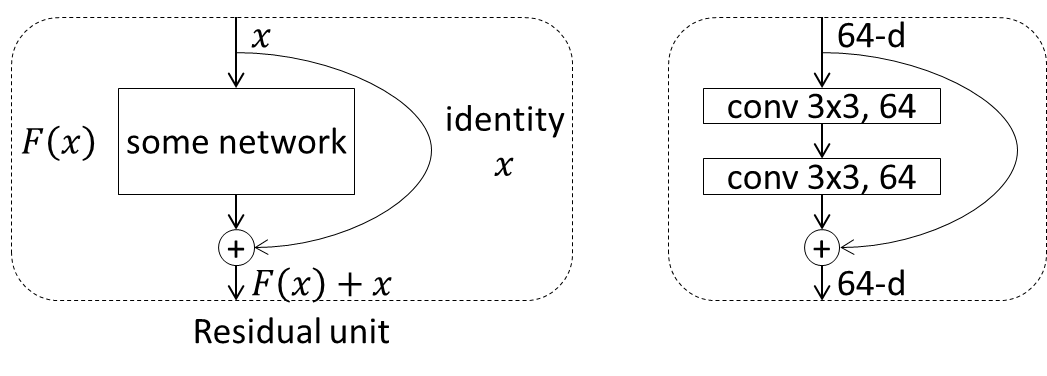
左は抽象的なresidual unitの構成です。右は具体的によく使われるresidual unitの例で、カーネルサイズ3x3、チャネル数64の畳み込み層が2つ配置されています。本来はこの中にbatch normalizationとReLUが配置されますが、その並べ方は様々なため省略しています。
このショートカットを通して、backpropagation時に勾配が直接下層に伝わっていくことになり、非常に深いネットワークでも学習を行うことができるようになりました。
ResNetは、このresidual unitを大量に重ねることにより構成されます。
Stochastic Depth
Stochastic Depth3は、ResNetにおいて、訓練時にresidual unitをランダムにdropするという手法です(ショートカットは残します)。$l$番目のresidual unitがdropされずに生き残る確率(生存確率)$p_l$はネットワークの出力に近いほど低くなる(dropされやすくなる)ように線形に減少させます。
これにより、訓練時の「期待値で見たときの深さ」が浅くなり、ResNetは非常にdeepであるゆえに学習に時間がかかるという問題を改善し、また、residual unitが確率的にdropされることにより正則化の効果が期待できます。
具体的には、$l$番目のresidual unitを下記のような構成にします。ここで$b_l$はベルヌーイ変数で、確率$p_l$で1を、確率$1 - p_l$で0を取ります。
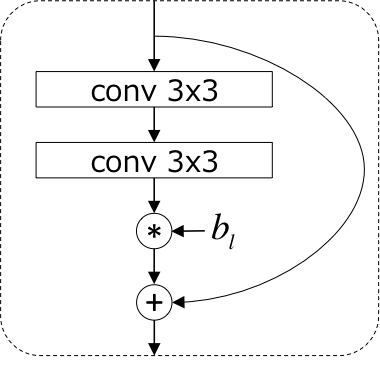
テスト時には、それぞれのresidual unitについて生存確率の期待値$p_l$を出力にかけることでキャリブレーションを行います。
Shake-Shake
Shake-Shake4 5はResNetをベースとし、テンソルに対するdata augmentationを行うことで、正則化を実現する手法です。通常data augmentationは画像に対して行われますが、中間層の出力テンソル(特徴ベクトル)に対してもdata augmentationを行うことが有効であろうというのが基本的なアイディアになります。
下記にShake-Shakeで利用される$l$番目のresidual unitの構成を示します。
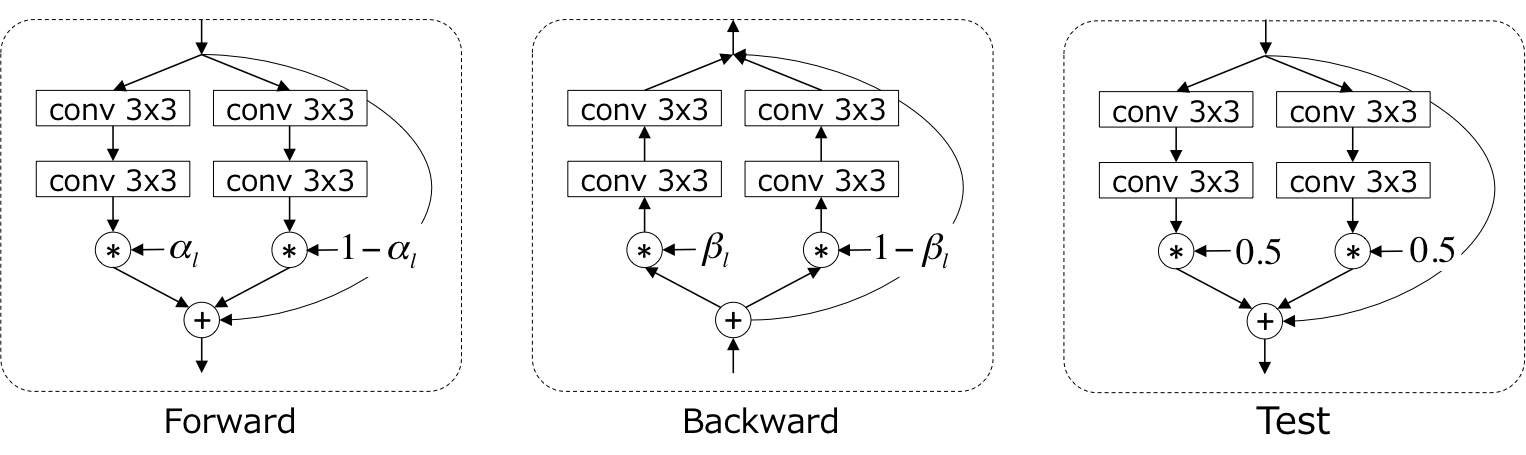
上記のようにShake-Shakeでは、residual unit内の畳み込みを2つに分岐させ、それらを一様乱数$\alpha_l \in [0, 1]$によって混ぜ合わせるということを行います。直感的には、画像ドメインに対するdata augmentationにおいてランダムクロッピングを行うことで、その画像内に含まれている物体の割合が変動してもロバストな認識ができるように学習ができるように、特徴レベルにおいても各特徴の割合が変動してもロバストな認識ができるようにしていると解釈することができます。
興味深いのは、backward時には、forward時の乱数$\alpha$とは異なる一様乱数$\beta_l \in [0, 1]$を利用するということです。テスト時には、乱数の期待値である0.5を固定で利用してforwardを行います。
論文中では、上記の$\alpha_l$と$\beta_l$を、0.5固定にしたり、それぞれ同じ値を利用したりする組み合わせを網羅的に検証しており、どちらも独立してランダムに (shake) する形が良いと結論付けています。
BackwardでのShakeは、residual unit毎に、learning rateをランダムにスケーリングしているような効果があり、SGDにおいて最適解に辿り着く確率を上げているのではないでしょうか(※個人の感想です)。
$\alpha_l$と$\beta_l$は、バッチ単位で同一にするか、画像単位で独立に決定するかの2通りが考えられますが、こちらは画像単位で独立に決定するほうが良いと実験的に示されています。
これらの外乱効果は、ニューラルネットからすると迷惑限りないことですが、結果として強い正則化の効果をもたらし、既存手法に対しかなりの高精度化を実現できています。
なお、Shake-Shakeの学習で特徴的な点として、学習率の減衰をcosine関数で制御6し、通常300エポックかけて学習を行うところを、1800エポックかけてじっくりと学習することが挙げられます。これはShake-Shakeの効果により、擬似的に学習データが非常に大量にあるような状態となっているため、長時間の学習が有効であるためと考えられます。
Cutout / Random Erasing
Cutout7は2017年8月15日に、Random Erasing8は2017年8月16日と、ほぼ同時期にarXivに論文が公開されたほぼ同一の手法(!)で、モデルの正則化を目的とした新しいdata augmentationを提案しています。
同じく正則化を目的としたDropoutは全結合層には効果がありますが、CNNに対しては元々パラメータが少ないため効果が限定的でした。より重要な観点として、CNNの入力である画像は隣接画素に相関があるので、ランダムにdropしたとしてもその周りのピクセルで補間できてしまうため、正則化の効果が限定的でした。
これに対し、Cutout/Random Erasingでは入力画像をランダムなマスクで欠落させることで、より強い正則化の効果を作り出すことを狙いとしています。

上図の左がCutout、右がRandom Erasingにおけるdata augmentation結果例です(画像はそれぞれの論文から引用)。
Cutout
Cutoutでは、マスクの形よりもサイズが重要であるとの主張から、マスクの形状は単純なサイズ固定の正方形を利用し、そのマスクを画像のランダムな位置にかけて、その値を(データセットの?)平均値にしてしまいます。
より詳細には、マスクの中心位置を画像中のランダムな位置に設定し、その周りをマスクします。これにより、マスクの一部が画像からはみ出すケースが発生し、このようなあまりマスクをしすぎないケースが存在することも重要だと主張しています。
より明示的には、一定の確率でマスクを掛けないケースを許容することも考えられると記載されています(後述のRandom Erasingではそうなっています)。
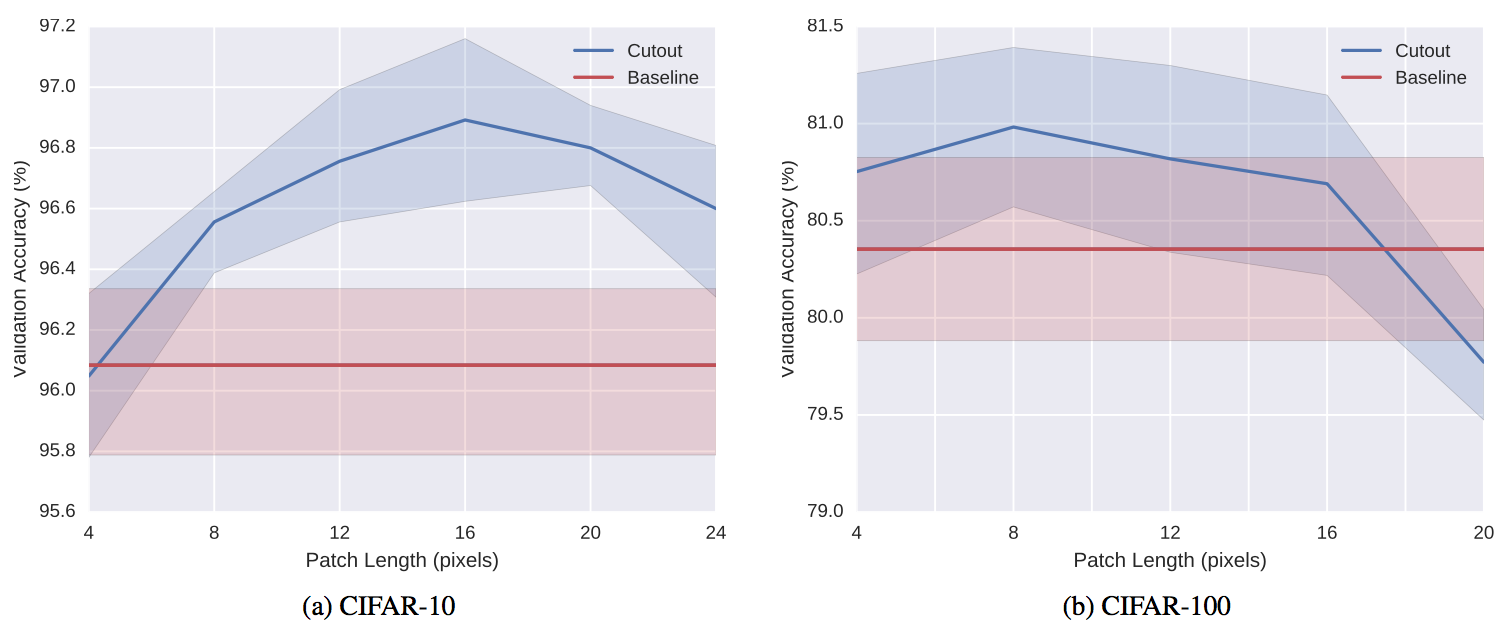
Cutoutの効果は上図(縦軸精度、横軸マスクのサイズ)のようにマスクのサイズに依存し、データセットとタスクによって最適なサイズが違うことが予想されます。
Random Erasing
Random Erasingでは、まず各画像に対しマスクを行うか行わないかをランダムに決定します。
マスクを行う場合には、まず画像中の何%をマスクするかを予め決められた範囲内からランダムに決定します。次に、同じく予め決められた範囲内でマスクのアスペクト比を決定します。最後にマスクの場所をランダムに決定し、マスク内の画素を0から255のランダムな値に変更します。
上記をベースとし、物体検出のように認識対象のBounding Boxが与えられるケースでは、それぞれの物体に対し、個別にRandom Erasingを行うことも提案しています。
具体的なパラメータとしては、実験的に、マスクをする確率を0.5、マスクの割合を2%〜40%、アスペクト比を0.3〜1/0.3とすることが推奨されています。
また、マスクでどのように画素を変更するかについて、ランダム、平均(Cutoutと同じ)、0、255の4種類のアプローチを比較しており、ランダムが一番良かったと報告されています(平均もほぼ同じ)。
Cutoutでは画像分類タスクのみでしか評価されていませんでしたが、Random Erasingの論文では、画像分類に加えて物体検出と人物照合タスクについても有効性が確認されています。
ShakeDrop
やっと本題の手法です。他の論文との整合性のため、notationを変えてあります。
ShakeDrop1は、一言で言えば、Stochastic Depthにおいて、層をdropさせる代わりに、forward/backward時にShake-Shakeのような外乱を加える(shakeすると表現します)手法です。
ベースネットワークとして、ResNetではなく、より精度が高いPyramidNet9を利用しています(が、本手法の本質ではないはずです)。
下記にShakeDropで利用される$l$番目のresidual unitの構成を示します。

上図において、$b_l$は、確率$p_l$で1を、$1 - p_l$で0を取るベルヌーイ変数です。Stochastic Depthと同様に$p_l$はネットワークの出力層に近いほど小さな値を取るように設計され、$p_l = 1 - \frac{l}{2L}$と定義されます($L$はresidual unit数)。
$\alpha_l$と$\beta_l$はShake-Shakeと同様に、forward/backward時に出力をスケーリングする乱数です。テスト時には、forward時のスケーリング$b_l + (1 - b_l)\alpha_l$の期待値をかけてあげます。
上図において、$p_l = 1$(全くdropされない)とすれば通常のresidual unitと同様になり、$p_l = 0$(常にdropする)とすれば、Shake-Shakeと同様に全ての入力に対しshakeするようなreisual unitになります。
逆に、$\alpha_l = 0$と$\beta_l = 0$とすれば、Stochastic Depthと同一になります。
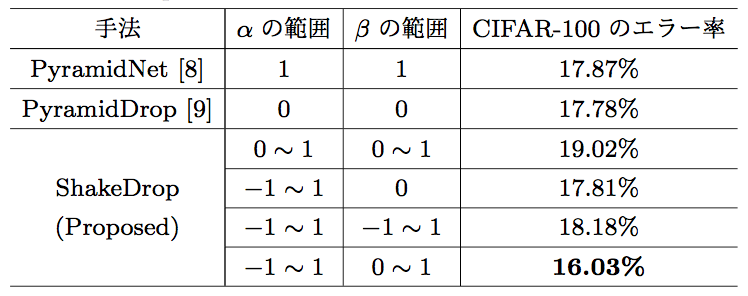 $\alpha_l$と$\beta_l$が取りうる範囲は、幾つかの候補から最も精度が良くなった$\alpha_l \in [-1, 1]$と$\beta_l \in [0, 1]$が採用されています。
解釈が難しいのが、$\alpha_l$と$\beta_l$の正負が異なるケースが存在することです。そのようなケースでは、実際にupdateすべき勾配と逆の方向にパラメータがアップデートされることになります(正負が同じであれば、スケールが違うだけで方向は同じなのでそこまで変ではない)。
1つの解釈としては、逆の勾配でアップデートされるということは、前のステップのパラメータに戻るような効果があり、パラメータをannelingするような影響があるのかもしれません。
なお、$p_l > 0.5$であれば(本論文の設定では満たされる)、期待値上は正しい方向にパラメータは進んでいくはずです(そもそもSGDでmomentumを利用する場合には、実際には正しい方向にアップデートされそうですが)。
$\alpha_l$と$\beta_l$が取りうる範囲は、幾つかの候補から最も精度が良くなった$\alpha_l \in [-1, 1]$と$\beta_l \in [0, 1]$が採用されています。
解釈が難しいのが、$\alpha_l$と$\beta_l$の正負が異なるケースが存在することです。そのようなケースでは、実際にupdateすべき勾配と逆の方向にパラメータがアップデートされることになります(正負が同じであれば、スケールが違うだけで方向は同じなのでそこまで変ではない)。
1つの解釈としては、逆の勾配でアップデートされるということは、前のステップのパラメータに戻るような効果があり、パラメータをannelingするような影響があるのかもしれません。
なお、$p_l > 0.5$であれば(本論文の設定では満たされる)、期待値上は正しい方向にパラメータは進んでいくはずです(そもそもSGDでmomentumを利用する場合には、実際には正しい方向にアップデートされそうですが)。
なお、予備実験において、$p_l = 0$とする(常にshakeする)場合では、全く学習できなかったことが報告されており、全てshakeすることは外乱としては強すぎることが伺えます。Shake-Shakeのケースでは、2つに分岐した畳み込みが似たような特徴を学習することで、この影響を軽減しているのではないかと思います。
$\alpha_l$と$\beta_l$をどの単位で変化させるかですが、Shake-Shakeの論文ではバッチ単位と画像単位のみしか検証されていませんでしたが、本論文ではチャネル単位と画素単位でも検証が行われています。
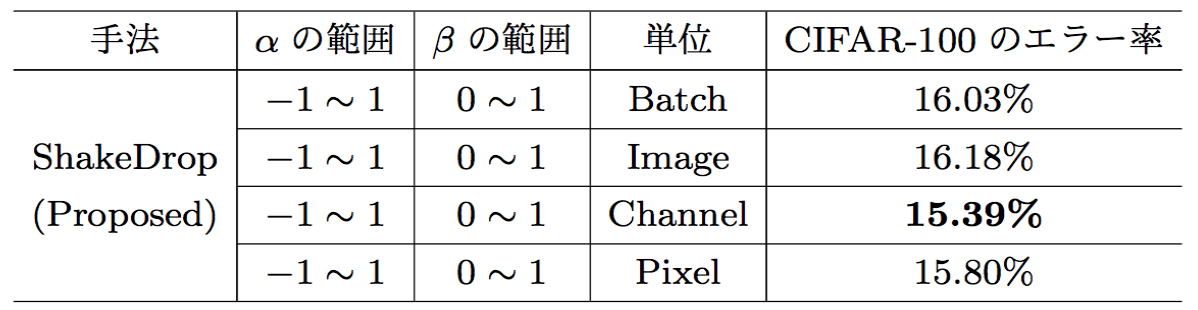
上記のように、チャネル単位での精度が良いことが示されています。
ShakeDropは、Shake-Shakeと比較すると、2つに分岐させていた畳み込みが1つになっており、パラメータを半分にできている一方、ベースネットワークとしてPyramidNetを利用することで、同等のパラメータで総数を大幅に増加させており、その辺りが高精度化に効いていると思われます。
また、ShakeDropでは、Shake-Shakeと同様に1800エポックの学習を行っていますが、cosine関数で学習率で制御するのではなく、エポックが全体の1/2および3/4となるタイミングで学習率を1/10とするスケジューリングを行っています。
下記が、既存のstate-of-the-artの手法との比較結果です。
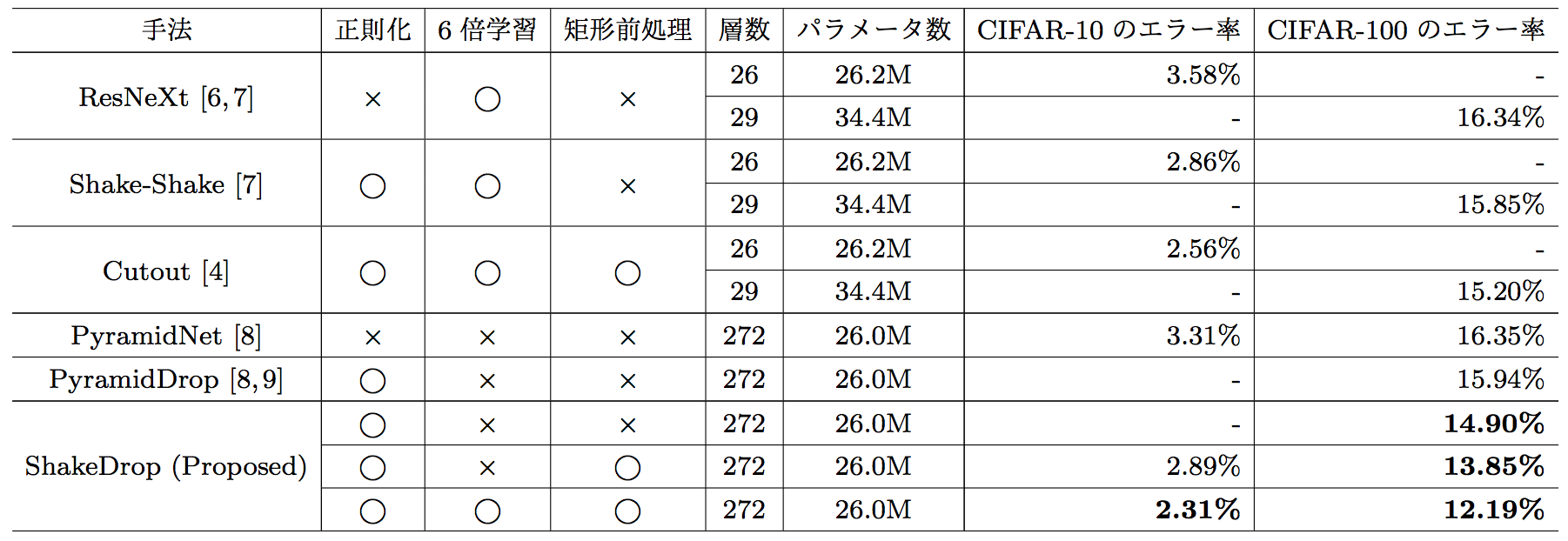
6倍学習と書かれている箇所は、1800エポックで学習したか、矩形前処理はCutoutを行っているかです。
ShakeDropは、PyramidNetをベースネットワークすることで、非常に深いネットワークを利用しつつ、その総数でも利用できるようなShake-Shakeの代替アーキテクチャを利用し、更にCutoutRandom Erasingを組み合わせて長時間学習させることで、既存手法に対しかなりの精度向上を実現できていることがわかります。
以上が、ShakeDropの全体像になります。
結果としてのモデルアーキテクチャとしては比較的シンプルであるにも関わらず、非常に高精度な認識を実現しているということで、一度試してみてはいかがでしょうか。
-
山田良博, 岩村雅一, 黄瀬浩一, "PyramidNetに対する新たな確率的正則化手法ShakeDropの提案," 信学技報, 2017. ↩ ↩2
-
K. He, X. Zhang, S. Ren, and J. Sun, "Deep Residual Learning for Image Recognition," in Proc. of CVPR, 2016. ↩
-
G. Huang, Y. Sun, Z. Liu, D. Sedra, and K. Weinberger, "Deep Networks with Stochastic Depth," in Proc. of ECCV, 2016. ↩
-
X. Gastaldi, "Shake-shake Regularization," in arXiv:1705.07485v2, 2017. ↩
-
X. Gastaldi, "Shake-Shake Regularization of 3-branch Residual Networks, in Proc. of ICLR 2017 Workshop, 2017. ↩
-
I. Loshchilov and Frank Hutter, "SGDR: Stochastic Gradient Descent with Warm Restarts," in Proc. of ICLR, 2017. ↩
-
T. DeVries and G. W. Taylor, "Improved Regularization of Convolutional Neural Networks with Cutout," in arXiv:1708.04552, 2017. ↩
-
Z. Zhong, L. Zheng, G. Kang, S. Li, and Y. Yang, "Random Erasing Data Augmentation," arXiv:1708.04896, 2017. ↩
-
D. Han, J. Kim, and J. Kim, "Deep Pyramidal Residual Networks," arXiv:1610.02915, 2016. ↩