本投稿の内容
Qiitaの記事は、投稿してから2週間ほどしか見られる機会が無い。
そのため「見逃した良記事」「埋もれた良記事」が多数存在する。
⇒見逃しても大丈夫。良記事をまとめて殿堂入りさせたサイトを作ろう!
先に結果を書くと、以下のようなサイトを作った。
作ったモノ ⇒ Qiitaの殿堂
そして、作るなら 「無料」で「超省力」で作る!
GCP(GoogleCloudPlatform)を活用して、
「無料」で簡単にサービスを作る方法、としても本記事を公開する。
重要なノウハウやハマりポイントを全て公開!(保存版)
Qiitaの殿堂 とは?
**Qiitaの殿堂**は、
上位1~2%の超人気記事を月ごとのランキング形式で紹介するサイト
(他にもいろいろ検討中・・・)
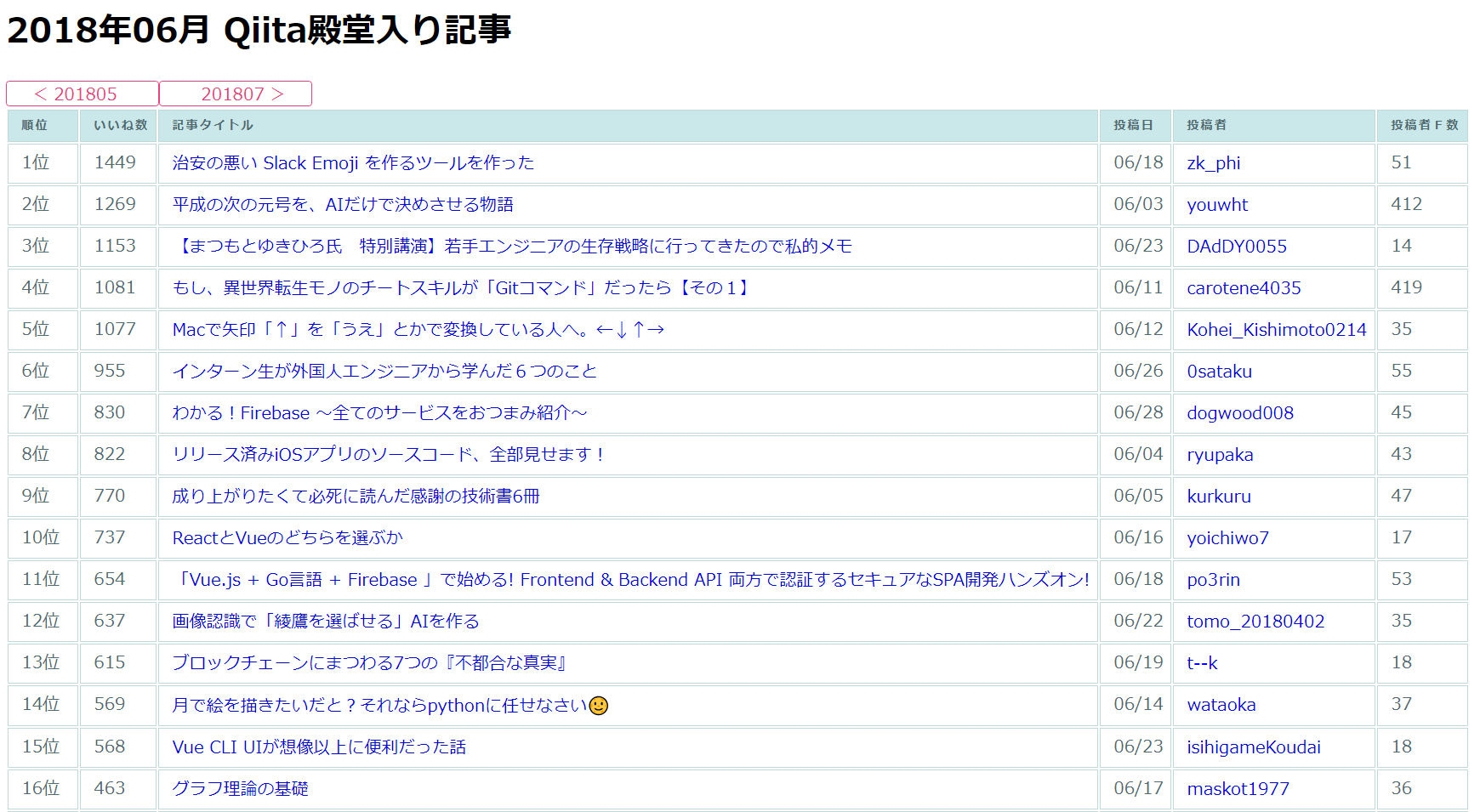
後述のように無料枠での簡易運用なので、サーバが落ちているかも!?
あと、投稿数&いいね数の推移グラフも追加しました。そちらも必見。
実現したいこと(動機) = 殿堂入り記事の収集
「殿堂入り記事の収集」とは、どんなことで、なぜやりたいと思ったのか?
を以下に記す。長くなるため、
「無料」で「超省力」に、の工夫を見たい人は、読み飛ばしてほしい。
方針:過去の良記事のまとめ
「投稿してから2週間ほどしか見られる機会が無い」
は、多少誇張があるが、現在流行りの記事のランキングはあっても、
過去の良記事へたどり着く方法が少ない、という意味だ。
端的に言えば、Qiita公式のトレンド=投稿一週間以内、であり、
Qiita公式のメール=前週のトレンド相当。
非公式のランキングサイト等もそんなに長期間扱わないため、
かなり「いいね」を集めた良記事であったとしても、
2週間後の公式メール以降は、アクセス数は激減する傾向にある。
かといって、全記事で「いいね」ランキングを作れば良いわけでもない。
「いいね」数は随時変動していくし、
もっと重要なのは、以下に投稿した分析でも明らかになったように、
直近1年のQiita記事分析で分かった7つの「驚愕」
投稿時期によって「いいね」数は3倍以上の差があるためだ。
(直近の方が多いならまだ良いが、過去の方が多いから、
ランキングが過去記事ばかりになってしまう)
そこで、投稿された月単位で「殿堂入り記事」を集めることで、
過去の良記事へ容易にアクセスすることができる仕組みを思いついた。
実際に直近の記事で作ってみた結果を以下に投稿した。
Qiita殿堂入り記事ランキングを作った物語
つまり、これをWeb化/自動化していきたいという話。
Qiita公式や既存他サービスとの違い
他の「ランキング系」や「トレンド」と一番違う点は、
何度も同じ記事を見ることが無いという点だ。
他のほとんどのランキングシステム、Qiita公式の仕組みでは、
日ごとのランキング、週ごとのランキング、などで
同じ記事が何度も出てくる上、アクセスするたびに
順位が大きく変わるため、何を読んでいないのか分からなくなる。
記事の書き手側が楽しむためのランキング、な気がしてしまう。
また、「直近一週間」などの時間軸も良くないと思う。
直近一週間で何いいねだったか、よりも、
累計でいくつだったのか、の方が興味がある。
新着情報/話題/流行を追う意味では、既存サイトや公式の仕組みは有意義だが、
過去への振り返りや、そんなに毎日のように見ない人、を対象とした
良記事の推薦/まとめシステムがあっても良いのではないか?
作り手として:手間の割に効果大
サービスを作る側としても、楽である。
「殿堂入り」は機械的に作成することができ、更新頻度も少なくて済むのに、
厳選された良記事を多数集めることが出来るため、とても**「効率がいい」。
(例えば2018年5月だと、上位30投稿(上位0.4%**以下)で、
**43%**以上のいいねを独占。「いいね」換算で集める意味で超高効率)
数値の最新化のために更新は必要だとしても、
過去記事の月ごと順位は大きく変動することは無いため、
更新頻度が低くても誰も気にしないだろう。
その他のニーズ:過去の振り返り/再読
別なニーズとして、自分がいいねした記事が、
その後どれくらい「いいね」が伸びたのか、どんな更新やコメントがあったのか、
一週間たってトレンド外になるとあまり目にしなくなる。
この点も少し気になっていた。あの時こんな記事見たな~、
と過去を振り返る意味でも「殿堂入り」は有意義である。
今後の発展/検討要素
最初は「いいね」数準拠でサービスを作るが、
もちろん「いいね」の少ない埋もれた良記事も沢山ある。
以下の記事でその発掘を挑戦している。
AIが見つけた、埋もれたQiita良記事100選
この取り組みもWeb化したいものの、これは難易度が高い。後で検討する。
(むやみに「いいね」のみを信じるものではない、と明記しておく)
まとめ:「殿堂入り」の定義と理由
「記事を最初に投稿した月ごと」の「いいね数」で、
ランキング上位一定数 ⇒ 「殿堂入り」
理由①: 現状「いいね」以外に(全員が平等に納得するような)指標が無い。
そのため「いいね」を指標として採用する。
理由②: 時期によって「いいね」の大小は3倍以上違うため、
集計期間を長くしたり、「いいね」の絶対値で決めるのは良くない。
そのため、月ごとに集計する。唯一、12月だけは投稿数が多く不利かも。
理由③: 例えば2018年5月だと、上位30投稿(上位0.4%以下)で、
43%以上のいいねを独占しており、「いいね」を指標とする場合、
圧倒的な効率の良さがある。
理由④: 既存の別サイトや、Qiita公式自身のトレンド/メールのように、
ランキング形式で随時順番が入れ替わるような仕組みでは、
毎日見るような人以外の読み手に対して、優しくないと思う。
理由⑤: 投稿月ごとのランキングならば、データ更新の頻度が少なくて良い。
メンテナンスが楽。マシンパワーも低くて済む。
実現する方法/手段 (無料&超省力で構築)
Qiitaの殿堂の作成時に使った技術や方法の、選定理由を以下に記す。
GCP(GoogleCloudPlatform)の永久無料枠
GCPには、最初の1年間に与えられる3万円相当のチケット以外にも、
この範囲で使うならばずっと無料だよ、という利用枠がある。
各サービスごとに、無料部分の定義が異なるため、詳細は公式参照。
GCPの公式「いつまでも無料のプロダクト」
GCE(GoogleComputeEngine)(IaaS)の最小インスタンスが永久無料。
データ収集は個人PCではやってられない
今回はQiitaのAPIでデータの収集を行う。
これに限らず、一般的にWebスクレイピングなどの、データの収集系は、
(サーバ側への負荷を抑えるためにも)時間がかかる。
また、将来実施しようと思っている解析系についても同様である。
定期的にデータを更新したい、などの場合は特に個人PCではやりたくない。
⇒データの取得/解析作業をGCPの無料枠を使って実施し、
どこまで無料で出来るのか試してみよう、と思った。
ドメイン取得も無料で出来る
1年間限定だが、ドメイン取得を無料(カード登録も不要)で出来るサービスがある。
freenomというサービス
詳細は以下のQiita記事をご参照。(.tkは悪評があったので、今回は.mlを取得⇒後日.gaに変更)
無料のドメインを取得する
(※一年たったら閉鎖orURLを変更するかもしれません。状況次第)
☆追記:1年後に再度延長を手続きすれば、また1年継続して無料な模様。
★追記:その後、更新手続きを忘れると、有料になっていたので.gaに変更。
GCEなら固定IPも無料で使える
GCPのIaaSサービスのGCE(GoogleComputeEngine)では
静的IPアドレスの発行は無料。(※インスタンスが起動していないと維持費発生)
詳細は、GCEインスタンスの無料での立て方と合わせて以下のQiita記事をご参照。
GCE の無料枠のサーバを立るときに、初見でハマりそうなところ
⇒どうせGCP上でデータ収集するならば、サーバ構築練習も兼ねて、
収集結果を何かサービスとして公開しちゃえば?と思った。
超省力化方針:MVP(Minimum Viable Product)
極力、余計なレイヤーを増やさず、pipだけのフルpython構成とした。
(ローカルWindowsで開発したものをUPしてすぐ動くようにという構成)
MVPの概念自体は、「省力」とは異なるのだが、
下記の考え方によって、本筋と思っていること以外はやらない!
MVPを構築しようと考えているときには、
調査したいことに直接結びつかない機能やプロセス、
労力を取り除く、という原則に従いましょう。
by MVP(Minimum Viable Product)とは?実践するメリットと検証方法
具体的には、最小の手間でサービス化出来るように、下記の構成とする。
「Flask」(Pythonの軽量なウェブアプリケーションフレームワーク)
「sqlite3」(Python標準ライブラリに含まれている軽量データーベース)
「GCE」(GCPの中で最も基本的なIaaSサービスしか使わない)
これだけで、十分「見れる」サービスが出来るのではないか!?
つまり、IaaS(OS) + Pythonプログラム(しかも全てpipで入るライブラリ)
しか存在しないという、超何もない構成。初心者でも簡単に出来る。
- nginxやapacheなども入れない。環境構築作業がpipだけ。
- BigQueryやBigtable、などのGCPの誇る強力なDBも無し。mysqlすら無し。
- GAEやGKEなど、IaaS以外は、面倒なので使わない。
- ローカル環境との一致度が下がったり、
- Googleのサービスとしての仕様調査が生じる、という意味。
- HTTPS化やバックアップ/運用自動化などはやらない。
よくエンジニアが言う「簡単にできる」は「学習すれば、数行で簡単に」
という意味合いが大きい気がするが、私の言う「簡単」は
学習コストが「簡単」の意味。IaaSとPythonしかないので、
「簡単」+汎用性が高い部分だけの学習で済む。
構築作業/無料&簡単ノウハウ
前置きが長くなったが、ここから実際に構築作業について記載する。
もし同じようなサービスを作りたいという人がいれば、
予備知識が無くても、(ググりながら)同様に作っていけるハズ。
全体構成/設計
構築の見通しを良くするため、
これから作ろうとする構成の概要を記載する。以下の4つが完成図。
- IaaS:無料取得ドメインを付けた、永久無料のGCEの最小インスタンス
- 30GBもディスクがあるので、データはその上に置く
- アプリ① Qiitaから情報を取得して、DB(sqlite3)に格納するアプリ
- 「DB」と言っても実態は「~.db」というファイルがあるだけ
- アプリ② DBの情報を参照して、「殿堂入り記事」のCSVを作るアプリ
- アプリ③ Flaskによって、HTMLを表示するアプリ
- HTML表示時に、指定したCSVを表示するように少しJavaScript有
なお、どのアプリも実態は「~.py」という
ただのPythonファイルである。
IaaS構築_1:GCEインスタンス構築
GCEインスタンスの作成方法については、前述の以下のQiita記事をご参照。
GCE の無料枠のサーバを立るときに、初見でハマりそうなところ
ポートの変更やLet's Encrypt などは、面倒なので必須ではないため、実施しない。
GCEインスタンスの生成時には、「CentOS」を選択した。
あと、静的IPアドレスも無料で取れるので設定しておく。
GCPの左のメニュー 「ネットワーキング」⇒「VPCネットワーク」
⇒「外部IPアドレス」から対象のGCEインスタンスのIPアドレス選び、
「エフェメラル」となっているタイプを「静的」に変更する。
表示されたIPアドレスはあとで使うのでメモっておこう。
以降の作業は、立てたサーバに、SSH接続で中に入って実施する。
TeraTerm?Putty?キーの生成?設定どうする?とか、一切不要!
GCEでは、「ComputeEngine」⇒「VMインスタンス」
⇒「作ったインスタンスの名前」⇒「リモート アクセス」のところの、
「SSH」というボタンを押すだけで、
ブラウザ上でターミナルを扱える。
ちょっと反応がもたつくが、このサーバ上ではまともに作業はしないので問題ない。
ブラウザだけで動くため、初心者にとても優しい。
IaaS構築_2:Python3とpipのインストール
この状態では、Pythonのバージョンが2.7.5であるため、
下記の手順で、Python3をインストールする。
同時に、pipも使えるようにしておく。
pythonのバージョン違いについては、気づかないとハマりポイント。
意外とこのやり方について記載された情報は少ない。
# 現状のバージョンを確認
python -V
# 2.7.5
# Python3系のインストール
sudo yum install -y python36
# Python3系には、「python3」でアクセスできるようにする
sudo ln -s /usr/bin/python3.6 /usr/bin/python3
sudo ln -s /usr/bin/pip3.6 /usr/bin/pip3
python3 -V
# pipのインストール
sudo python3 -m ensurepip --upgrade
pip3 --version
sudo pip3 install --upgrade pip
pip3 --version
# pipで、これから使うライブラリをインストールしておく
# 作るアプリによってこのあたりは読み替え。
sudo pip3 install parse
sudo pip3 install urllib3
sudo pip3 install requests
sudo pip3 install flask
アプリ①:Qiitaから情報を取得して、DB(sqlite3)に格納
QiitaAPIから、得た結果をsqlite3に書き込むPythonプログラムを作る。
以前に以下の記事で作ったものを使いまわして、sqlite3に書き込むようにした。
Qiita殿堂入り記事ランキングを作った物語
特に変わったことは実施していないし、
sqlite3の使い方はググれば出てくるため、コードは省略。
2点だけポイントとなる箇所を挙げる。
GCE上でも実行しやすくするコツ
私の場合、自分の開発環境がWindowsであるため、
例えばsqlite3のdbファイルのパスを示すコードを書く際に、
以下のようにしておくこと。コードを一切変更せずに、
Windows ⇒ GCE上のCentOS の双方で動かすことが出来る。
import os
rootdir = os.path.abspath(os.path.dirname(__file__))
DBFilePath = rootdir + os.path.sep + "DATA.db"
冪等性によって、メンテ効率を上げるコツ
データ書き込み時に、その時のデータベースの状態によらずに、
何度実行しても同様の結果が得られるようにしておく。
(冪等性とは、ある操作を1回行っても複数回行っても
結果が同じであることをいう概念)
これにより、結果の確認時や、データの最新化の時に、
一度テーブルをドロップしたりせずに、何度でも試せる。
具体的には、以下のようにDBにデータを登録する関数のSQLを、
「INSERT INTO」ではなくて、
「REPLACE INTO」にすることで、
PRIMARY KEY が同一であった場合に上書きするようにする。
実行するたびに同じレコードが増えていく、ようにしないということ。
import sqlite3
conn = sqlite3.connect(DBFilePath)
cur = conn.cursor()
# DBへ格納する情報は、insert_listsに入れておく。
# tableを作る際に、IDに、PRIMARY KEY 設定にしておく。
def insert_to_db(insert_lists):
replace_sql = "REPLACE INTO table_name(ID, ColumnA, ColumnB) values (?,?,?)"
cur.executemany(replace_sql, insert_lists)
conn.commit()
return 0
ノウハウ:ローカルとのファイル共有
ローカル環境で作ったアプリやファイルを、
どうやってクラウド上のインスタンスに置くのか?
コマンドでカッコよく置く方法もあるが、
設定がいろいろ手間なので、最も理解しやすい方法を記載する。
Cloud Storage を経由したファイルの転送
GCPのメニューから「Storage」⇒「ブラウザ」を選択する。
Regional Storage(米国リージョンのみ)が5Gまで永久無料だ。
Storage上に上記を満たすように任意の名前でバケットを作る。
あとは「ファイルをアップロード」「フォルダをアップロード」などの
ボタンが出るので、あまり迷わないだろう。
これで、ローカルのWindowsからCloudStorageまで、
任意のファイルやフォルダを送受信することが出来る。
一方、GCEのインスタンスからこのファイルを取得するためには、
以下のように実施する。
# これでバケットの中が見れる
gsutil ls gs://{バケット名}
# これでCloud Storageのモノを取得できる。
gsutil cp -r gs://{バケット名}/ ./{GCEのフォルダ名など}
GCEのインスタンスからファイルをアップロードする場合だけは、
ちょっとだけ面倒で、パスワード認証含め以下のような作業になる。
# 以下のコマンドを実行してYESを選んでいく
gcloud auth login
# 認証用のURLが表示されるのでブラウザでアクセス
# Googleのアカウントで認証すると、パスワードが表示される。
# そのパスワードを入力すると、以下のような、
# GCEからCloudStorage側への書き込みが出来る。
gsutil cp {ローカルファイル名} gs://{バケット名}/
# これは、認証したユーザで書いていることになるため、
# セキュリティ的には、終わったら以下のようにログアウトすると望ましい。
gcloud auth revoke アカウント名
GCEのデータのバックアップ先としても、
Cloud Storageは用意しておいた方がよい。
これで、テスト環境で作ったアプリを、
GCEに持ってくることができた。あとは実行だ。
ノウハウ【最重要】:ずっとクラウドに作業させる方法
今回のように無料インスタンス上で構築するにあたって、
最も重要なのは「pythonアプリの起動方法」。
普通に、「python3 XXX.py」などで実行すると、
SSH接続が切れた場合に強制終了してしまう。
これは、sshログインしている状態でコマンドを実行すると、
sshdのログインシェル(bash)の子プロセスとして実行されるため。
sshのログアウトを行うと、ハングアップシグナル(HUP)を送信し、
子プロセスを終了させてしまい、コマンドが終了される。
それを防ぐためには、nohupコマンドで
HUPシグナルを無視するようにすれば良い。
具体的には以下のように実行すれば、
SSHが切れても、GCEが頑張ってスクリプトを実行し続けてくれる!
これで、超時間がかかるスクレイピング系の処理などを
無料クラウドにやらせ続けることができる、ってわけ。
nohup python -u script_file_name.py > out.log &
ログはout.logに出す。落ちていると悲しいので最初は適宜見ると良い。
これで、24時間以上ずっとクラウドに作業させることが可能。
無料インスタンスに、数ギガのデータ収集の仕事をしてもらうと、
なぜか、とても得した気持ちになってくるのでオススメ。
標準出力に表示されなくなるため、別途途中状況の
ログファイルを生成するように作っておいた方がよい。
おっと、あぶない、終了させるやり方を書くのを忘れる所だった。
後述のFlaskなどはバックグラウンドで永遠に実行され続けてしまうため、
止めたい場合は、以下のようにする。
# 以下のコマンドで、実行中のPythonプロセスを確認
ps -aux | grep python
# 対象プロセスのプロセスIDを見て、以下のようにkillコマンドで止める
kill -KILL 99999
IaaS構築_3:無料ドメインの取得
これは、前述の以下のQiita記事をご参照。
無料のドメインを取得する
まず1年間は無料で使える。もちろん、安いドメインを買っても良い。
「ネームサーバを指定する」手順も実施して、
「ping ドメイン名」で、GCEに設定した静的IPアドレスから、
応答が返ってくるか確認すること。
アプリ②:DBの情報を参照して、「殿堂入り記事」のCSVを作る
これは、作るアプリによっていろいろ違うと思うので、
コードや解説は省略する。
一つポイントを挙げるならば、役割分担。
- アプリ①=データ取得(QiitaAPI実行)
- アプリ②=データの加工/整形(CSV出力)
- アプリ③=サイトの公開(Flask)
という役割だとすれば、①と②の部分は分けておかないと、
②の加工のバグが原因で、データの再取得になるのは避けたい。
加工後のフォーマットを変更したい場合にも対応しにくい。
また、②と③の部分も分けておかないと、
サイトにアクセスが生じるたびに、
何かの加工処理をしていては、表示が遅くなるだけでなく、
貧弱な無料インスタンスが落ちてしまう。
無駄な負荷がかからないように
サーバをいたわった設計も、無料運用のコツである。
アプリ③:Flaskによって、HTMLを表示する
Flaskの基本的な内容については、ググれば出てくるために割愛する。
templatesフォルダ、staticフォルダを用意して、
その中にhtmlやcssなどを格納しておく。
htmlからのパス参照のさせ方にクセがあるのでご注意。
(詳細はFlaskについて書かれた情報をググってください)
シンプルな例を挙げると、以下のコードでサーバを作れる。
デフォルトでは、「ttp://localhost:5000/ 」でサーバが起動し、
templatesフォルダ内のindex.htmlが表示される。
だが「app.run()」だけでは、起動した自分のマシンからしかアクセス出来ない。
特に、GCE上では、デフォルトでは5000番ポートは塞がっているため、
本番時はapp.run()の設定を以下のように変更して、
元から空いている80番ポートを使うようにする。
コード中の最後の「本番用」が外部アクセス&ポート変更を設定済みの版。
(もちろんGCEのネットワーク設定を変更して、任意のポートで動かしても良い)
# coding: utf-8
from flask import Flask, request, render_template
app = Flask(__name__) #インスタンス生成
@app.route('/')
def index():
return render_template('index.html')
# <>内の値は、引数的に渡される。201807⇒2018と07などに分けてテンプレートに渡す例
# 今回の実装範囲では、静的サイトだけでも実装は不可能ではないが、
# これらの機能は分析機能などを作る際にも役立つかもしれない。
@app.route('/dendou/<yearmonth>')
def show_dendou(yearmonth):
return render_template('show_dendou.html', year=yearmonth[0:4], month=yearmonth[4:6])
if __name__ == "__main__":
# webサーバー立ち上げ
#デバッグ用
app.run()
#本番用
#app.run(debug=False, host='0.0.0.0', port=80)
アプリ①②は全く作っていない状態でも、
③だけで全世界に任意のサイトを公開することが出来るため、
別途Flaskの情報を調べながら、ここだけ実施してみるのもオススメ。
アプリ③もただのpythonコードなので、
アクセスされるたびに任意のpythonスクリプトを実行することもできる。
このFlaskのアプリ③も、本番運用時は①で記載したように、
nohupコマンドで実行すること。
また、権限の関係で、「sudo」を付けて実行すること。
sudo nohup python3 -u server_app.py > server_app_out.log &
あと、Flaskデバッグ時に地味に便利なノウハウを追記。
ブラウザから参照するときに、**「ctrl + F5」**で
キャッシュ コンテンツを無視して現在のページを再読み込みする。
(スーパーリロード)
CSSなどを変更した場合に、キャッシュが残っていて
反映されていないように見える、などのトラブルが減る。
おまけ:HTMLの作成/CSVの表示
HTMLは好みの方法で作れば良いと思う。
ただ、テーマ的にsqlite3のDBの中身を見せる話なので、
一度見せる用のcsvを(アプリ②で)作成して、
それをHTMLから参照する形になる。
そのため、CSVをHTMLで表示する方法だけご紹介する。
「jquery.csvToTable.js」というjavascriptのライブラリを使った。
ちょっと面倒だった点は2点。
1点目は、「Qiitaの記事」なので、タイトル中に
HTMLのscriptタグ(≺script≻)が含まれる記事があり、
その場合ライブラリが上手く動作しなかった。
(ついでに「Kobito」などのMDエディタでも同様に悪さをする)
CSVのセパレータ(カンマなど)と合わせて、
上手くpython側でトリム/置換する。
分かれば大したことは無いのだが、
原因切り分けにはある程度のカンが必要だ。
2点目は、CSVを表示している殿堂入りページ中の、
最上部と最下部の、**「前後の月に移動するボタン」**の作成。
「201801」⇒「201712」「201802」と動的に値を返すように、
JavaScriptを実装するのがちょっと面倒であった。
デザイン(配置)などもCSSを調べて実施した。
ただこのボタンのおかげで、殿堂入り記事のタイトルだけでも、
連続して見ていくのは大変楽しい。
JavaScriptは、サイト上でソースを見れば出てくるので、
ここではコードは割愛する。
(てきとーに作ったものなので、見ないで良い)
おつかれさまでした!
このような工夫/作業の積み重ねによって、
Qiitaの殿堂
はついに完成した。
**「無料」**でありスペックが低いことや、
適宜更新をかけたり、データ取得中は重かったりして、
サーバが落ちているかもしれないが、
優しい気持ちでみていただきたい。
また、構築までの流れや、工夫した点、ハマりやすい箇所を
出来るだけ詳細に書いたつもりだ。
もしこれを見て、
「無料だし簡単そうだし、なにか作ってみよう」
という人がいたら大変嬉しい。
構想時から随所に見られる**「簡単さ/手抜きの工夫」**がアピールポイント。
私自身、自分でドメインを取得して公開用サーバを作ったのは、
実はこれが初めてだ。
諸先輩方の情報や記事に感謝すると共に、
Qiitaの殿堂 を作る前にこんな情報があったらな~、
と思った点を全て、足跡として残すことで感謝の形としたい。
今後の発展
もし、この投稿への「いいね」や、賛同者が多い場合は、
Qiitaの殿堂は、現状のままではなく、
直近1年のQiita記事分析で分かった7つの「驚愕」
で視覚化したような情報の半リアルタイム可視化や、
AIが見つけた、埋もれたQiita良記事100選
で発掘したような、埋もれた(低いいね)良記事の推薦、
または、「タグ」軸でのランキング化など、
別な取り組みや、ブラッシュアップを考えていきたい。
(2018/10/21追記)
「タグ」軸での表示や、分析が追加!ブラッシュアップ中!
- Qiitaの可視化から見えた、人気技術ランキングの推移
- [あなたの時間を無限に奪うQiita記事集できました]
(https://qiita.com/youwht/items/3ba161572b2fc233e100)
蛇足:
「まず隗よりはじめよ」 (戦国策)
昔、燕の昭王が「どうすれば賢者を招くことができるか」
と、郭隗という人に聞いた。郭隗は答えた。
「まず私のような凡人を優遇することから始めて下さい。
そうすれば、あの人が優遇されるのならば、と、
自然と優秀な人材が集まってくるでしょう」
①大事を始める時には、まず手近なことから始めると良い(MVP的思想)
②このような凡記事に「いいね」をすると、もっと良い記事が投稿される。
以上、長文へのおつきあいありがとうございました。