本記事では、 チームによる持続的に変更可能なWebアプリケーションの開発を目標に、フレームワーク導入時に考慮すべき22の観点を紹介する。
フレームワークによって特徴は異なるが、本番導入にあたって、考慮すべきポイントはあまり変わらないので、極力フレームワーク1に依存しすぎないよう配慮する。また、話をシンプルにするため、REST APIを提供するアプリケーションを題材とする。
前提
ソフトウェアのエントロピー
ソフトウェアがエントロピー増大の法則を避けられないことを、体感している開発者は多いだろう2。普通にアプリケーション開発を続けると、開発スピードは鈍化し、品質は低下してバグが増え、開発者からは技術的負債への怨嗟の声が聞かれるようになる。エントロピー増大というフォースは極めて強力で、意思を持って立ち向かわなければ、容易にダークサイドに堕ちてしまう。
関心事の分離
大規模Webアプリケーションにおける複雑性とアーキテクチャ設計に関する一考察でも述べているとおり、ソフトウェア開発は複雑さとの戦いになる。特に、「ビジネスの関心事」と「技術的関心事」をいかに分離するかは、持続的に変更可能なアプリケーション開発を実現するためのキモとなる。
ドメイン駆動設計
「ビジネスの関心事」と「技術的関心事」を分離して設計するアプローチで最も優れた手法は、ドメイン駆動設計(DDD)である。関心事を分離し、「ビジネスの関心事」をユビキタス言語を駆使しながらモデリングを行い、継続的にリファクタリングすると本当に変化に強くなる。3 本記事では、ドメイン駆動設計そのものについては深く触れないが ドメイン駆動設計を実践するうえで、土台となるアーキテクチャを設計すること4は明確に意識している。
考慮すべき22の観点
それぞれの観点は独立しているが、ここでは概ね、筆者が設計する際の順序で並べている。
全体設計
中核技術
横断的関心事
軽視されがちな重要要素
テストコード
スケールする組織
全体設計
言語/フレームワーク選定
言語/フレームワークの選定はそれ自体が大きな設計判断になる。失敗は許されないため、慎重さと決断力の両方が求められる。
さわってみる
Webに転がってるドキュメントを読んだだけで、決断してはいけない。小さいなアプリケーションでいいので、自分で実際になにか作ってみよう。
個人的には、RSSリーダーを作ることが多い。Webアプリケーションで必要な要素が網羅されており、仕様も複雑ではないので、手早く実装できる。副次的な効果として、同じお題で毎回作ると、フレームワークの違いも素早く学べる。Webアプリケーションフレームワークの「Hello, World!」としてオススメの題材だ。
選択する
自分でさわってみて、筋が良さそうだとわかったら、実際に選択するフェーズである。選択する際には、下記の観点でチェックする。
- 複雑なビジネスロジックをリーダブルに表現できるか
- コンパイラやエディタ(IDEを含む)の支援があり、リファクタリングを容易に行えるか
- 後方互換性を重視しているか
- コミュニティが存在し、メンテナンスされ続けているか
- 十分な量の情報が流通しているか
- エンジニアのモチベーションが向上するか
なお、上記リストの元ネタははてなでの10年戦える新技術採用戦略の話で、もっと詳細に技術採用戦略について記述されている。必読である。
覚悟を決める
言語/フレームワークを本番導入後の変更することは、作り直しとほぼ同義である。しくじると、プロジェクトの失敗に直結するため責任重大だ。腹をくくって決断しよう。
また、決断した後はあらゆる人に、「○○にはしないんですか?」と何度も言われる。本当に何度も言われる。相手も悪気があって言ってるわけではないので、あまり気にせず、自分の決断を信じよう。
アプリケーション・アーキテクチャ
伝説のMVC5
多くのWebアプリケーションフレームワークは、MVCを前提としている。
シンプルなCRUDサービスであればMVCでも良いが、中長期で運用されるWebアプリケーションの場合、MVCでは複雑さが制御できなくなるケースが多い。
アプリケーション・アーキテクチャの候補
MVCじゃなけりゃどうするんだ、という話になるが、ドメイン駆動設計で実装を始めるのに一番とっつきやすいアーキテクチャは何かで説明されているアーキテクチャが参考になる。
- レイヤードアーキテクチャ
- ヘキサゴナルアーキテクチャ
- オニオンアーキテクチャ
- クリーンアーキテクチャ
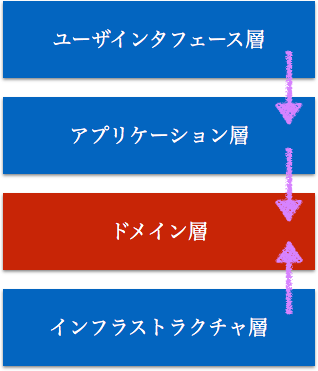
実は考え方は似通っており、ドメインモデルを中核に据えて設計しよう、と言ってるだけである。「ビジネスの関心事」であるドメインモデルと、データベースアクセスなどの「技術的関心事」を分離できると、それだけでも相当変化に強いコードになる。
筆者の場合は、レイヤードアーキテクチャをベースにすることが多い。ただし、後述のDIを使って、ドメイン層が他に依存しないようにしている6。
中核技術
DI(Dependency Injection)とDIコンテナ
変化に強いWebアプリケーションの開発には、DIは事実上必須なので、どのように実現するか、最初に検討しておく。
DI(Dependency Injection)
「ビジネスの関心事」と「技術的関心事」を分離するための核となる考え方が、DI(Dependency Injection)である。DIを導入すると、依存オブジェクトを外部から注入することができるようになり、結合度を大幅に下げることができる。そして、そのDIの実現をサポートしてくれるのがDIコンテナである。
ちなみに、DIコンテナがなくても、DIは実現可能である。例えばScalaにおける最適なDependency Injectionの方法を考察するでは、DIコンテナを使わず、Scalaの機能だけでDIを実現した事例が紹介されている。
DIコンテナ
DIコンテナを採用する場合、基本的にフレームワークが提供or推奨しているモノを使うことになる。例えば、Scala+Playの場合は、Google Guiceがデファクトとなる。DIコンテナによって、オブジェクトを注入するために必要な準備が異なる。
JavaのSpringでは、アノテーションを使って宣言的に定義するだけで、DIを実現できる。一方、Google GuiceやPHPのLaravelなどは、バインディング定義は自前で書かねばならず、Springと比較すると少しメンドクサイ。
O/Rマッパー
インピーダンスミスマッチの解決
おおまかに二つの方向性がある。
- アクティブレコードパターン : オブジェクトにデータベースアクセスをカプセル化して、ドメインロジックを追加する。テーブルのデータ構造と、オブジェクトのデータ構造が一致するシンプルなアプリケーションで便利。最初楽で、後で段々大変になってくる。
- データマッパーパターン : ドメインモデルとテーブルをマッピングするクラスを定義し、テーブルのデータ構造と、オブジェクトのデータ構造を完全に分離する。マッピングがメンドウなので、最初はかなり大変だが、変更には強いので、後で楽になってくる。
アクティブレコードパターンで、変化に強いコードを維持するのは相当大変なので、中長期で保守する可能性が高いアプリケーションの場合は、素直にデータマッパーパターンで設計されたO/Rマッパーを選択したほうがよい。
マッピング
O/Rマッパーがどの程度、自動的に値をマッピングしてくれるかも確認しておこう。
- 文字列や数値などのプリミティブな値
- 時刻型(LocalDateTime型など)
- nullかもしれない値(Optional型など)
- 列挙型(enumなど)
- 独自定義したクラスの値(ValueObjectなど)
1〜3番くらいまでは、ある程度自動でマッピングしてくれる。4〜5番については、一度O/Rマッパーに文字列などへマッピングさせてから、手動でマッピングしなおすか、独自のマッピングルールをO/Rマッパーに組み込むかの二択になる。
例えば、MyBatisの場合、TypeHandlerを使うと、独自のマッピングルールを定義でき、随分楽になるので、O/Rマッパーにマッピングルールを追加できる機構が備わっている場合、積極的に使っていこう。
タイプセーフ
当たり前の話であるが、静的型付け言語を採用しても、SQLについてはコンパイラは何もしてくれない。しかし、O/Rマッパーの中には、独自のDSLで、型チェック可能なクエリビルダを提供している場合がある。例えば、ScalaのScalikeJDBCの場合だと、普通のSQLとタイプセーフなSQLを両方書くことができる。
- 普通のSQL
def find(id: Long)(implicit session: DBSession): Option[Member] = {
sql"select id, name, birthday from members where id = ${id}"
.map { rs =>
new Member(
id = rs.long("id"),
name = rs.string("name"),
birthday = rs.jodaLocalDateOpt("birthday")
)
}
.single.apply()
}
- タイプセーフなSQL
def find(id: Long)(implicit session: DBSession): Option[Member] = {
val m = Member.syntax("m")
withSQL { select.from(Member as m).where.eq(m.id, id) }
.map { rs =>
new Member(
id = rs.get(m.resultName.id),
name = rs.get(m.resultName.name),
birthday = rs.get(m.resultName.birthday)
)
}.single.apply()
}
タイプセーフなSQLを書くと、コンパイラによるチェックが走るので、安定感が増す。反面、複雑なJOINなどをする場合に、独自DSLの書き方を学ばなければならず、やや学習コストが高い。トレードオフはあるものの、検討する価値はある。7
横断的関心事
トランザクション
トランザクション定義
基本的に、フレームワークもしくはO/Rマッパーが標準で提供する方法で実現することになる。アプリケーションコード内で、トランザクション制御のコードを記述するモノが多く、PHPのLaravelの場合だと下記のようになる。
public function update() {
DB::transaction(function () {
DB::table('users')->update(['votes' => 1]);
DB::table('posts')->delete();
});
}
一方、Springの@Transactionalアノテーションのように宣言的に定義できるものも存在する。技術的関心事をキレイに追い出せる優れモノだ。
@Transactional
public void updateFoo(Foo foo) {
...
}
ちなみに、手動でコミットしたりロールバックしたりという、心温まるアプローチもあるが、バグの温床にしかならないので絶対にやめよう。
public void updateFoo(Foo foo) {
connection.begin();
...
connection.commit();
}
トランザクションの責務
定義方法以上に大事なのが、どのクラスにトランザクションの責務を担わせるかである。チーム内で一貫性のある設計にしておかないと、気付いたらトランザクションがネストしまくって、コントロール不能になったりする。
筆者の場合は、いわゆるアプリケーションサービスのクラスに、トランザクションを定義するよう、チームで徹底するようにしている。
例外ハンドリング
エラーの扱い
エラーの扱いについては、エラーハンドリング・クロニクルが非常に参考になる。Webアプリケーションの場合、多くの言語8では、エラーは例外で表現する。そこで、本記事でも例外にフォーカスする。
例外設計
例外設計については PHP7で堅牢なコードを書く - 例外処理、表明プログラミング、契約による設計が網羅性が高く、実践的なのでまずはこれを読もう。
さて、例外の扱い方であるが、例外はアプリケーションコード内では原則キャッチしないとしておくのがよい9。try-catch文などを使って、個別にログ出力やエラー通知を書くのは、コードの不吉な匂いである。見通しが一気に悪くなるうえ、漏れも発生するため、例外処理は例外ハンドラにおまかせしよう。
大抵のフレームワークでは、例外ハンドラを定義するための機構が提供されており、例外ハンドリングをカスタマイズできる。
例外ハンドラ
例外ハンドラでやるべきことは大きくは3つ。
- エラーレスポンスの定義
- エラー通知
- エラーログ出力
エラーレスポンスの定義
例外ハンドラにエラーレスポンスの定義を集約できると、エラー時のHTTPステータスコードとペイロードが、アプリケーション全体で一貫性を保ちやすい。特にペイロードは重要である。例えばFacebookの場合は、下記のような構造で、エラーが表現される。
{
"error": {
"message": "Message describing the error",
"type": "OAuthException",
"code": 190,
"error_subcode": 460,
"error_user_title": "A title",
"error_user_msg": "A message",
"fbtrace_id": "EJplcsCHuLu"
}
}
エラーレスポンスを標準化しておくと、APIクライアントの実装が非常に楽になる。逆にバラバラだと、APIクライアントの実装者が泣くハメ10になる。なお、Proposed Standardではあるが、RFC7807にて、エラー時のJSONペイロードの仕様が策定されていたりするので、参考にしてもよいだろう。
エラー通知
アプリケーションから直接メールやSlackへ通知するのではなく、Rollbarなどの、エラーモニタリングシステム経由で通知したほうがよい。一時的に通知をオフにしたり、同種のエラーをグルーピングしたうえで通知したりと、柔軟な通知制御が、アプリケーションを弄らなくても実現できる。
また、オオカミアラームにも注意を払おう。サービスイン直後などは心配なので、何でもかんでも通知してしまいがちだが、ある程度安定してきたら、エラー通知の断捨離をする。最悪なのは、エラー通知が常態化して、本当に深刻なエラーに気づけないことだ。
エラーログ出力
障害調査の要となるため、例外発生時は確実にエラーログを出力させる。ログが残ってない時の絶望感たるやエゲツないものがあるので、本番でエラーログが出力されることは必ず確認しよう。
また、独自で例外をスローする場合は必ずエラーメッセージを含める。間違っても throw new RuntimeException(); とか横着してはいけない。エラーメッセージのない例外を投げてもいいのは小学生までである。
多くの場合、エラーメッセージには、なぜエラーが発生したのかを書くことになるだろう。しかし、もう一歩踏み込んで、このエラーが発生したら、何をすればいいかを書いておくと親切である。対応手順がどこかにまとまっているのであれば、そのURLを記述しておくのも良い。少し手間だが、運用を考えると十分ペイする。
ロギング
ログフォーマット
アプリケーションログの設計のポイントは、ログ設計指針が詳しい。ロガーによって多少の差はあるが、できることはあまり変わらないはずだ。
また、出力フォーマットをJSONにしておくと、あとで加工がしやすい。ログ収集のシステムなどとも連携しやすくなるのでオススメである。ログの検索をgrepでやるようなレトロな環境でも、jqコマンド等と組み合わせれば視認性が大幅にアップする。
出力タイミング
必ず出力すべきなのは、次の3つである。これらは、アプリケーション開発者に意識させず、自動で出力するようにしておく。
- リクエスト開始時 : リクエストパラメータや、実行しようとしたクラス名/メソッド名など。何を実行しようとしたか分かる情報を可能な限り出力する。
- リクエスト正常終了時 : HTTPステータスコードや実行時間などを出力する。ログが肥大化するので、ペイロードは出力しない。
- リクエスト異常終了時(例外発生時) : 例外クラス名やエラーメッセージを出力する。必須ではないが、リクエストパラメータなど、リクエスト開始時に出力する内容も一緒に出力しておくと、障害調査が楽になる。
他の出力タイミングとしてよくあるのは、次の2つだ。
- 外部システム連携時 : 外部システムと通信する前に、リクエストパラメータを出力しておく。合わせて異常時には、エラーレスポンスを出力しておこう。正常終了時は、正常終了したことだけ分かればOKだ。
- SQL実行時 : フツーのO/Rマッパーは、実行したSQLをログ出力できる。デバッグ時に非常に役に立つので、少なくとも開発環境ではログ出力する。もし、本番環境でも出力する場合、大量のログが出力されるので、ディスクフルで死んだりしないように配慮しよう。
秘匿情報のマスキング
ログ出力するものの中には、秘匿情報(個人情報など)が含まれる場合がある。その場合は、ログ出力時に適切にマスク処理を施せるようにしておく。こんなことをやらなくても、アプリケーションは動くため、忘れてしまいがちだ。
例えばRailsであれば、標準でリクエストパラメータの秘匿情報をマスクする仕組みが提供されている。
Rails.application.config.filter_parameters += ['password', 'card_number']
こんな感じで書けば、ログ出力時には [FILTERED] という文字列に置き換えてくれる。
相関IDと分散トレーシング
Webサーバとアプリケーションサーバが分かれている場合や、マイクロサービスでは、一つの処理を実行するのに、複数のサーバを経由することになる。
処理中にエラーが発生した場合に備え、どこでエラーが起きたかトレースできる仕組みが必要となる。ZipkinやAWS X-Rayなどの分散トレーシングシステムに乗っかれるのが理想だが、そうでない場合でも、相関IDは必ずログに含めておく。相関IDについては、マイクロサービスアーキテクチャの8.8節にも解説がある。
認証・認可
チェック処理
プロジェクト内で設計方針を統一しておかないと、あらゆるトコロにチェックを行うためのif文が登場し、手がつけられなくなる。あとで変更しようとしても、バグったときの影響範囲が大きく心理的ハードルを超えられない場合が多い。
極力フレームワークやライブラリのサポートを得られるように、開発初期に設計しておこう。とりあえずif文を追加する、という誘惑に断固として打ち勝つこと。
共通化
if文を撒き散らすのを回避するため、共通化がよく行われる。コントローラの実行前後に、処理を挟み込む場合が多い。例えば、Playの場合はFilter機能を使えばよい。フレームワークによって呼称が違うので、ドキュメントを探してみよう。
もし、このような機構が提供されていない場合、コントローラの基底クラスに組み込むしかないが、基底クラスを太らせるのは典型的なアンチパターンなので、できれば避けたい。もし実装する場合は、基底クラスに直接実装するのではなく、別クラスで定義して委譲し、基底クラスの肥大化を低減しよう。
軽視されがちな重要要素
ディレクトリ構造
プロジェクト全体
プロジェクト全体のディレクトリ構造は、フレームワーク標準をベースとしよう。ただし、標準構成では置き場に困るモノが必ず出てくるので、そこは設計する必要がある。
例えば、バッチ実行が必要になるWebアプリケーションも多いが、フレームワーク標準では、バッチ用スクリプトの置き場が規定されてない場合が多いので、そこは独自にディレクトリを切ったりする。
アプリケーションコード
ほとんどのWebアプリケーションフレームワークは、MVCがベースとなっている。そのため、MVC以外のアーキテクチャをベースにすると、ディレクトリ構造を独自に定義することになる。
ディレクトリを作ること自体は簡単であるが、そのディレクトリがどんな責務を持つのかは、チームで共通理解を深めておく必要がある。いくら美しく構造化しても、携わるエンジニアが理解できないのであれば無意味だ。
アンチパターン
絶対にやってはいけないのは、適当にディレクトリを作成することである。置き場に困って、とりあえず動かすために適当に作ったディレクトリは、後世まで残り続ける。時間のない、開発初期にやってしまう場合が多い。
ディレクトリ構造の理想は、ドキュメントを読まなくても、自分が見たいファイルがどこにあるのか直感的に分かること。なんでココにあるの?と思われたら負けである。
タイムゾーン
UTC or JST
日本でサービス提供する場合は、UTCかJSTの二択になる。どちらが正しいということはなく、グローバル展開への考慮、連携システムのタイムゾーンなどの外部要因によってもどちらを選択するかは変わってくる。
また、アプリケーションコードでタイムゾーンを意識するかどうかも決めておいたほうが良い。例えばJavaであれば、日時オブジェクトを扱う場合に、タイムゾーンを含まない LocalDateTime を使うのか、タイムゾーンを含む ZonedDateTime を使うのか、統一すべきである。
環境差異
特にタイムゾーンを指定していないと、OSのタイムゾーンが使われたりする。
あるあるなのが、開発者のマシンはJST、本番サーバはUTCで爆死するパターンである。CIで拾えればまだマシだが、本番リリースされてしまうと目も当てられない。暗黙的な定義は事故の元なので、タイムゾーンは明示的に定義しよう。
データベースサーバの設定
データベースサーバとアプリケーションのタイムゾーンは可能な限り一致させたほうが良い。 例えば、AWSのRDSで何も考えずに、データベースサーバを構築すると、タイムゾーンはUTCになる。これを知らずに、アプリケーションをJSTにすると、混乱を招く。
歴史的経緯などにより、どうしても別のタイムゾーンになってしまう場合は、アプリケーションコードで、タイムゾーンを意識させる。JVM系の言語であれば、LocalDateTime ではなく ZonedDateTime を使い、日時オブジェクトにタイムゾーンの情報を保持させる。
現在日時
プロダクションコード
現在日時は、カンタンに取得可能であるが、コード内で「現時刻」を気軽に取得してはいけないことを肝に銘じよう。
テストコード
テストコードでは現在日時というのは実に厄介である。テストするたびに毎回違う値が入るため、テストが不安定になりやすいのだ。そこで、よくやるのは テスト時に、現在日時を固定するということだ。
例えばRubyでは、Timecopというgemがあり、簡単に現在日時を固定することができる。
Timecop.freeze(Time.new(2017, 12, 15, 12, 34, 56))
Time.now #=> 2017-12-15 12:34:56 +0900
Timecop.return
一方、JavaなどのJVM系の言語の場合、現在日時を固定できるように、テスト時にClockオブジェクトを差し替える仕組みが必要で、DIを使って実現したり、独自のラッパークラスを定義したりしないといけない。
フレームワークというよりは言語の問題ではあるが、現在日時の固定方法は早めに確立しておいたほうがよい。
プレゼンテーション
ルーティング定義とエンドポイント設計
ルーティング定義は、カオス化しやすく、一度リリースしてしまうと、後でリファクタリングがしづらいので、構造化を意識したい。
また、エンドポイントの設計に一貫性がないと、理解不能になる恐れがあるので、チーム内でしっかり方針を決める。翻訳: WebAPI 設計のベストプラクティスやWeb API: The Good Partsなどを参考にするのがよいだろう。
リクエストパラメータ
リクエストパラメータの扱いは基本的にフレームワーク依存になる。任意のFormオブジェクトへマッピングしてくれる機構があれば、ぜひ使いたい。単なるハッシュにマッピングするだけのフレームワークも多いので、その場合は手動でオブジェクトへのマッピングが必要である。
なお、間違ってもハッシュをそのまま引き回さないこと。 なんでも入るため、最初に作る人は楽だが、後から変更する人は、何が入っているか分からず、あちこちコードを行き来するハメになる。
バリデーション
Railsのようにデータベースへの永続化時にバリデーションを実行するフレームワークもあるが、最近のフレームワークはコントローラでバリデーションを実行するものが多い。フレームワークによって、バリデーションという言葉が示す範囲が違うので、バリデーションの責務はチームで認識を合わせよう。バリデーションの責務の論点は、アプリケーションアーキテクチャ設計パターンの9.1節「検証」が参考になる。
また、バリデーション定義をどこに書くかについても明確にする。個人的にはバリデーションはプレゼンテーションレイヤにFormオブジェクトを定義して、ソイツの責務にすることが多いが、ドメインモデルに定義するのを好む人もいる。
バリデーションエラー時の挙動については、例外を投げて例外ハンドラに丸投げすると実装は楽である。ただ、少々乱暴なので、都度ハンドリングするという方針でもよいだろう。
レスポンス
JSONを返すだけで良ければ、オブジェクトをJSON文字列に変換するモジュールを導入するのが手っ取り早い。ただし、ドメインモデルをそのまま変換しないこと。Viewとドメインモデルが密結合になって、ドメインモデルが変更しづらくなる。はっきり言ってメンドウだが、Viewモデルを挟んでおきたい。
HTMLを返す場合は、テンプレートエンジンを導入する。テンプレートエンジンはモノによってクセが結構違うので、導入前によく検証する。また、テンプレートエンジンにロジックが散らばると死ぬので、チームでよく認識を合わせておこう。
アプリケーションの設定と初期化処理
秘伝のタレ
アプリケーションの設定ファイルや初期化コードというのは、最もリファクタリングが行われにくいヤツラである。なんせ、下手に変えると動かなくなるし、エラーメッセージは意味不明だし、なんの意図で入ってるのか分からないなんてザラで、アンタッチャブルになりやすい。
そこで我々が目指すべきはズバリ、ノーモア、秘伝のタレ化である。
モジュール化
アプリケーションの設定ファイルや初期化コードは、デフォルトでは単一ファイルであることが多い。しかし、大抵は別ファイルを読み込む仕組みが提供されているので、役割ごとにファイルを分けてしまおう。 なぜかモジュール化が軽視されがちだが、ファイルレベルで分離しておくとあとで変更がしやすい。
コメント
「コメントを読まなくても理解できるコードを書こう」そんな助言は無視しよう。
後で読む人のために、たくさんのコメントを書いて、可能な限り手がかりを残しておくのだ。通常のアプリケーションコードと比較すると、変更頻度が低い(でも影響は甚大)ので、コメントと実態が乖離することも少ない。
何をしているかを書いてくれるだけでもありがたいが、なぜそうしたのかを書いておくと、変更時の判断に非常に役に立つ。参考にしたStack OverflowやQiita、個人ブログのリンクなども残しておこう。どの情報を参考にしたか、という情報自体が貴重な手がかりになる。
ビルド定義
JavaScriptは相変わらず群雄割拠という感じだが、だいたいの言語ではデファクトスタンダードが存在するので、それを使おう。JavaならGradleを使えばいいし、Scalaならsbtを使っておくのが無難だ。
依存ライブラリの定義
言語/フレームワークを問わず必ず出てくるのは、依存ライブラリの定義だ。定義方法自体はググれば理解できると思うが、重要なのは依存ライブラリの管理ポリシーとバージョンアップ戦略である。
管理ポリシー
どこで使ってるか不明なライブラリが増えるとムダな維持コストがかかるので、依存ライブラリは最小限に留める。また、適当に突っ込んでしまうと、依存関係が複雑化して、バージョンアップできなくなるリスクも出てくる。ライブラリの導入にあたっては、カジュアルに試し、慎重に決断することが求められる。
バージョンアップ戦略
バージョンアップ戦略はたった一つ。バージョンアップはこまめに行えだ。依存ライブラリのバージョンアップが特別なイベントになってしまうと、心理的ハードルが上がってしまい、どんどんやらなくなってしまう。
日常的な活動としてバージョンアップを行おう。そうすれば、地雷を踏んだとしても、対象ライブラリのChangeLogやコミットログを読めば、原因究明できる可能性が高い。
モジュール化とコメント
設定ファイルなどと同様、ビルド定義もモジュール化して、たくさんコメントを書いておこう。コメントのないビルド定義が数百行など、有名なOSSでもザラだが、真似する必要はない。
データベースマイグレーション
データベースマイグレーションは、フレームワークが標準で提供しているモノを採用してもいいし、単体で動作するライブラリを導入してもよい。選択にあたっての観点を2つほど紹介するので、チームにフィットしたマイグレーションツールを選ぼう。
DSL
複数のデータベースを透過的にサポートするためのDSLを提供しているマイグレーションツールは多い。例えば、RailsのActive Recordマイグレーションでは、Rubyのコードとして、マイグレーション定義が可能である。
class CreateProducts < ActiveRecord::Migration
def change
create_table :products do |t|
t.string :name
t.text :description
t.timestamps
end
end
end
一方、JavaのFlywayなんかは生のSQLを書く。
CREATE TABLE person(
id INT(11) NOT NULL,
name VARCHAR(100) NOT NULL,
PRIMARY KEY (id)
);
良くも悪くも凝ったことはできないので、誰でも理解可能でき、SQLさえ書ければ学習コストはゼロである。個人的にはFlywayの設計思想は大好きだが、生SQL書くとかありえないっしょ、と考える人もいるだろう。
ロールバック
多くのマイグレーションツールは、ロールバックの機構が備わっているが、Flyway11のように、ロールバックを備えていないツールも存在する。本番で事故るのがイヤなので、個人的にはロールバック機能はいらない子だが、開発時にはあれば多少便利である。
CI
設定のコード化
Jenkinsの1系では、CIの設定は画面でポチポチしていくものだったが、2系からはJenkinsfileにコードで設定が表現可能になった。問答無用でコード化しよう。 ちなみに、CircleCIのようなSaaSの場合は、最初から設定ファイルで書く。素晴らしい。
くどいようだが、CIの設定ファイルにもコメントを残しておこう。高速化などの理由でテクニカルなことをする場合は、特に重要だ。
健全なコードを維持する
CIでテストをパスさせるのは当然として、それ以外にCIにやらせたいコトを列挙する。
- テストカバレッジの計測
- 静的コード解析
- コピペチェック
- コードフォーマットチェック
- セキュリティチェック
- 依存ライブラリのバージョンチェック
- アーティファクトの生成
- デプロイ
この中でも、最低限、テストカバレッジの計測と静的コード解析だけは、プロジェクト開始時点で組み込みたい。 最初は小うるさいのだが、コードの品質が保て、中長期的には幸せになれる。
データベースサーバ
ミドルウェアの話なので本記事のスコープからやや外れるのだが、データベースがMySQL12の場合、アプリケーションの実装に影響を与えるハマりポイントがいくつかあるので、紹介しておく。
文字コード
新規にMySQLサーバを構築するなら、文字コードは utf8mb4 一択である。歴史的経緯などにより、utf8になっている場合は、絵文字をバリデーションで弾くなどの配慮が必要となる。
照合順序
MySQLには、ハハパパ問題や寿司ビール問題といった、非常にアレな問題が存在する。どうしてこうなった!という感じだが、検索時の挙動に直接影響を与えるため、最初に決めておこう。特に理由がなければ utf8mb4_bin が無難である。
なお、マイグレーションツールによっては、MySQLのデフォルト設定を無視する場合がある。Rails4なんかはそうで、何も設定しないと*_unicode_ciでテーブルが作成されてしまう。Rails5では解消されたそうだが、知らないと後の祭りなので、意図した挙動になることを確認しよう。
トランザクション分離レベル
トランザクション分離レベルそのものについては、トランザクション分離レベルについて極力分かりやすく解説あたりを参照してほしいのだが、注目すべきはMySQLのデフォルト設定が REPEATABLE READ である点だ。OracleやPostgreSQLは READ COMMITTED なので、普段Oracleを使ってるけど、今回だけMySQLみたいな場合には注意が必要だ。
トランザクション分離レベルをリリース後に変更する心理的ハードルはメチャクチャ高いので、変えるのであれば開発初期に変えてしまおう。
テストコード
データベーステスト
データベースと結合したらユニットテストじゃねーだろって声も聞こえてきそうだが、大抵のプロジェクトではテストしたくなる。というわけで、データベーステストをスムーズに行うための枠組みを整えておく。世の中に転がってるライブラリなどを活用し、作り込みすぎないようにする。
テスト用データベースの分離
言うまでもないが、テストで使用するデータベースは、開発時に使用するデータベースとは分けておこう。設定ファイルで、テスト時のデータベースの向き先を変えて、いくら壊しても大丈夫な状態にしておくのだ。
テスト用データベースのマイグレーション
テスト実行時に一度だけテストデータベースをまっさらにして、マイグレーションが自動で実行されるようにしておく。テストデータベースのマイグレーションが自動化されてないと、いちいち開発者が手動でマイグレーションを実行するハメになり非効率である。
テストケース単位のクリーンアップ
データベースのテストを行う場合は、テストケースごとに自動でクリーンアップする仕組みを作っておく。データベーステスト用の基底クラスを提供し、勝手にロールバックする仕組みにするのが一番簡単だ。
テスト後に、テーブルをキレイにする処理を手動で書いてもいいが、だいたいどこかで書き漏らす。テストが不安定になりやすいので、あまりオススメしない。
データベースフィクスチャ
大抵の言語には、データベースフィクスチャの定義をサポートしてくれるライブラリが存在するので、導入しておく。例えばrubyだとfactory_bot(旧factory_girl)が有名だ。
データベースフィクスチャは、共通化を頑張りすぎると、テストコードを見ても何をテストしているのか分からなくなるので、ほどほどにしておく。テストに関してはDRYであることが価値につながらない場合が多い。
インメモリデータベース
テスト高速化のため、H2 Databaseなどのインメモリデータベースを導入する場合がある。H2 Databaseの場合、MODEオプションを切り替えると、MySQL風、Oracle風などと挙動を切り替えられて一見便利なのだが、当然まったく同じ挙動にはならない。
以前複数チームに導入してみたが、結局挙動の違いでテストが落ちたりしてムダにデバッグ時間がかかっていた。確かにテストの実行は早いのだが、テストを通すまでのコストが高い印象である13。
スローテスト問題を見据えたカテゴリ化
データベーステストや、コントローラのテストは、スローテスト問題の主要因になるため、カテゴリ14を設定しておいて、テスト実行時に除外可能な状態にしておくと、あとで役に立つ。最初からやるべきかは判断が難しいが、検討する価値はある。
スローテスト問題が発生してしまうと、CI実行の並列化ぐらいしか手が打てなくなる。スローテスト問題はテストケースの数が膨大になってから発生するので、問題が発生した頃にはテストコードをリファクタリングして、高速化するという手段は現実味がない。
テストダブルとHTTP通信
テストダブル
大抵の言語には、テストダブルを実現するライブラリが存在するので、導入しておく。例えばJavaだと、mockitoあたりを入れる。スタブやモックはどうせ必要になるので、プロジェクト開始時に入れておこう。
HTTP通信
外部システムのREST APIを叩く部分など、HTTP通信が発生する箇所はスタブにする。標準的なテストダブルのライブラリでスタブを作ってもよいし、HTTP通信テスト用のライブラリを導入するのも手だ。
例えばrubyであれば、webmockとVCRを使うと、非常に簡単に通信部分をスタブに差し替えられる。
テスト用モジュール
構造化
テストコードが育っていくと、テストでしか使わないコードが色々出てくる。それぞれ、どこに置くか、配置場所を決めておこう。
- テスト用基底クラス
- テスト用ユーティリティクラス
- データベースフィクスチャ
- 外部サービスの通信部分のスタブ定義
統一しておかないと、各自が好き勝手に配置してしまい、見通しが悪くなる。
手本
テスト用のモジュールをいくら用意したところで、使い方が分からなければ意味がない。
チームに浸透させる一番楽な方法は、お手本のコードを実装し、それをコピペしながら学んでもらう方法である。テストコードは、本当にカジュアルにコピペされる。それを逆手にとってコピペラブルなテストコードを提供してしまうのだ。
スケールする組織
ドキュメンテーション
README
チームに新しいメンバを迎えたとき、おそらく最初に読むのはREADMEである。
アプリケーションの概要、環境構築手順、実行方法、デプロイ手順など、プロジェクトに必要な情報はすべて書いておくべきである。もちろん、最新情報を別の場所(QiitaやConfluenceなど)で管理しているのであれば、そこへのリンクを貼っておくだけでも良い。後回しにされがちだが、読みやすいREADMEを書くなどを参考に、カッコいいREADMEを書こう。
図
コードを読むだけでは理解が難しい、システムアーキテクチャ図なども描いておこう。インフラ構成や、外部システムとの関係を、全員が理解しておくと、システム連携で死ぬみたいな事故が減る。
また、RDRAやICONIXの手法を取り入れて、コンテキストモデルやユースケースモデル、ロバストネス図などを作っているなら残しておこう。メンテナンスし続けるのは難しいので、スナップショットと割り切り、ホワイトボードに描いたものを、写真にとってREADMEなどから辿れるようにしておく。必ずしもキレイな絵にしておく必要はない。
サービステンプレート
複数チーム複数システム
複数チーム複数システムで開発する予定があるなら、カスタムのサービステンプレート15を作成しよう。毎回まっさらな状態で始めるのも悪くはないが、効率的とは言い難い。本記事で言及したような、どのシステムでも必要になるモノを一式実装したテンプレートを提供してしまうのだ。特にマイクロサービスが主流になっている組織では、威力を発揮する。
ライブラリ
サービステンプレートは、コピペされて使われる。そこで、サービステンプレートに組み込まれるモジュールを、機能別にライブラリとして別リポジトリに切り出そう。そして、単純に依存ライブラリの一つとして、サービステンプレートに組み込むのだ。
複数システムで利用されるため、依存関係を小さく保ち、密結合を避け、単機能なものを注意深く設計する必要がある。ライブラリの設計については、APIデザインの極意やC++のためのAPIデザインに有用な助言が多数ある。
正直、簡単な仕事ではないが、うまくやると組織がスケールしても、高品質なシステムが最高スピードで実装できるようになる。
モチベーション
色々ショートカットできるサービステンプレートだが、強制されるとチームのやる気が損なわれる。そのため、あくまでも、サービステンプレートを使うかどうかはチームに委ねるべきだ。
また、サービステンプレートで提供したソリューションに不満を感じ、知らないうちに違うことをやりだすチームも出てくる。目くじらをたてず、むしろ推奨してしまおう。目的は標準化ではないし、今より良い方法は常に存在するのだ。
ただし、単なる独自進化にとどまると勿体無いので、フィードバックサイクルは回るようにしたい。サービステンプレートを社内オープンソースとして扱い、よりよいソリューションを取り込めるようにしよう。
One more thing...
全部事前にやるの?
いいえ。
サービステンプレートがない場合、通常は、実際のプロジェクトの中で、アプリケーション開発をしながら、並行して行う。というか、並行して行わないと使えるものにならない。
これで勝つる?
いいえ。
本番リリースをするためには、インフラを構築して、デプロイの仕組みを作って、監視できるようにしないといけない。このあたりは、ウェブアプリケーション開発に新言語を採用したときにインフラで考えたことがよくまとまっているので参考にしてほしい。
そして、もちろん肝心要のアプリケーションの実装をしないといけない。終わったのは土台作りだけだ!
ぐだぐだ言ってないでコード書けよ
せやな。
実際、本記事はその精神には反している気もする。一方で、エンジニアも木工職人たちのように「一手間」を大事にというのは、耳を傾ける価値のある助言である。
本記事の内容は、「一手間」というにはちょっと手数が多すぎるのだが、これが筆者なりの「一手間」なのだ。
おわりに
最後まで読んでくれた人、本当にありがとう。そしておつかれさま。少しでもこれを読んだアナタの参考になれば幸いだ。
巨人の肩の上に乗る
- マイクロサービスアーキテクチャ
- .NETのエンタープライズアプリケーションアーキテクチャ
- 現場で役立つシステム設計の原則
- エリック・エヴァンスのドメイン駆動設計
- 実践ドメイン駆動設計
- エンタープライズ アプリケーションアーキテクチャパターン
- ソフトウェアアーキテクチャ
- アプリケーションアーキテクチャ設計パターン
- UNIXという考え方
- APIデザインの極意
- C++のためのAPIデザイン
- The Twelve-Factor App (日本語訳)
- .NET におけるアプリケーション アーキテクチャ ガイド
- TERASOLUNA Server Framework for Java (5.x) Development Guideline
-
ついでに、言語にも依存しすぎないよう配慮している。一応、Java、Scala、Kotlin、Ruby、PHP、Pythonあたりを念頭に置いている。 ↩
-
これは経験則です。DDDで変化に強いコードにできない人はボクを雇ってください。ちなみに、弊社では副業OKです! ↩
-
とはいえ、ほとんどの観点はドメイン駆動設計とは無関係に、役に立つと思う。 ↩
-
.NETのエンタープライズアプリケーションアーキテクチャの第7章「伝説のビジネス層」のパロディだ。 ↩
-
ちなみにこれは、現場で役立つシステム設計の原則の第3章でも説明されてる、三層+ドメインモデルのアーキテクチャと同じである。 ↩
-
紹介しておいて何だが、個人的な好みだけで言えば、クエリビルダは使わず、極力、生のSQLを書きたい派である。 ↩
-
Webアプリケーションの実装で使われるメジャーな言語で、例外がないのはgolangぐらいな気がする。 ↩
-
バッチ処理や非同期処理をゴリゴリ書く場合は、この助言はマズイ。バッチの場合は、リトライなども考慮せねばならず、単純に例外を投げて中断すればいいわけではない。また、非同期処理の場合は、単純に例外を投げてもキャッチする人がいない。 ↩
-
Twitterのエラーレスポンスの適当さはあまりにも有名である。 ↩
-
記事書いてる途中で5.0.0がリリースされサポートされてしまった。裏切り者!`Д´)ノ ↩
-
MySQL以外については知見がないので割愛。誰か書いてくりゃれ。 ↩
-
筆者自身は、インメモリデータベースでテストを高速化するより、データベース接続してテストする部分を最小化するようにしている。 ↩
-
この記事を書くまで知らなかったのだが、JUnit5ではtagと言うらしい。 ↩
-
マイクロサービスアーキテクチャの2.6.2節を参照のこと。 ↩