Webアプリケーション開発についての知見を、自分の経験と知識をベースに整理してみようという試みです。
いわゆるサーバサイドにスコープを絞り、フロントエンドは対象外です。筆者は普段、オブジェクト指向言語で書いているので、本記事でもその前提(Ruby、PHP、Python、Java、Scalaあたりを想定)になっています。
では、本編をどうぞ。
ソフトウェア開発は複雑さとの戦い
『人月の神話』では、ソフトウェアの本質的な困難性について4つの性質をあげている。その中で最初に出てくるのが**「複雑性」**である。『新人プログラマに知っておいてもらいたい人類がオブジェクト指向を手に入れるまでの軌跡』なんか読んでもらえると、ソフトウェアの複雑性と戦うために、人類が生み出してきた発明の数々が説明されている。
では、複雑さとは何か?もう少し掘り下げて考えてみよう。
複雑さの正体
Webアプリケーションが複雑になる要因は、大きくは3つだと、筆者は考えている。
- ビジネスの複雑性
- 技術的な複雑性
- インピーダンスミスマッチ
これらが複合的に絡まり合うとスパゲッティなコードが出来上がり、それを変更しようとすると死にそうになったり死んだりする。
なお、個々人のスキルとかマネジメントとか政治的なアレコレとか、そういうのも影響するが、アーキテクチャ設計では一旦忘れる。
ビジネスの複雑性
コードの複雑性を生み出す、ビジネスの複雑性の主要因をあげてみよう。
現実世界
**そもそも現実世界は複雑怪奇である。**その現実世界の問題を解決するために実装されたコードは、どうやっても複雑になる。
変化
**ビジネスは変化し続ける。**最初はシンプルだったものが、徐々に複雑なモノへと変貌していく。エントロピー増大の法則はビジネスも例外ではない。もちろんコードも例外ではない。
矛盾
**現実世界は矛盾に満ちている。**矛盾したままだと実装できないので、色々な辻褄合わせをしなければならないのだが、これがまた複雑さを増大させる。ニンゲンと違って、コンピュータは空気を読んでくれないのだ。
技術的な複雑性
我々がコードを書くうえで、必要な知識は言語やフレームワークだけにとどまらない。
プログラミング
- オブジェクト指向
- トランザクション管理
- 例外処理
- リファクタリング
- テスティング
ミドルウェア/マネージドサービス
- データベース : MySQL、Oracle、PostgreSQL、SQL Server
- キャッシュ : Memcached、Redis
- 検索 : Elasticsearch
- メッセージング : SQS、Kinesis、Cloud Pub/Sub
- データウェアハウス : Redshift、BigQuery
その他いっぱい
適当に思いつくままに書き連ねてみた。もちろん、コードを書くだけではユーザに届かないので、デプロイ、インフラ、運用、監視、CIなんて話も出てくる。ここでは、あくまで一部を切り出したに過ぎない。
掘り下げていくと、これら一つ一つが複雑性を内包しているうえ、これらをどう組み合わせるかという問題も出てきたりする。
インピーダンスミスマッチ
ビジネスはビジネスで複雑だし、技術は技術で複雑だというわけで、それ単体でも大変なのに、**我々はさらにその複雑なもの同士を繋げあわせなきゃならない。**ここでもう一つの複雑さであるインピーダンスミスマッチが登場する。
『コンセプトの異なる2つの分野を繋ごうとする際に起こる困難』などと説明されたりもするアレだ。
異なる技術要素のインピーダンスミスマッチ
メジャーなところだと、オブジェクト指向とリレーショナルデータベースがあり、根本的に異なるデータ構造であるコイツラをどうマッピングすんねんっていうのが、実装する上で課題になる。
詳しくは後述するが、**オブジェクトと各種要素技術をどのように繋ぎ合わせるか、というのはあらゆる場面で問題となる。**ここを適当に実装すると一気にコードの見通しが悪くなるため、アーキテクチャ設計上は極めて重要なポイントとなる。
ビジネスと技術のインピーダンスミスマッチ
現実世界の複雑性をそのまま実装に持ち込むと、コードの複雑性が無限大に膨れ上がるため、抽象化やモデリングを行い、実装可能なレベルに落とし込んでいく必要がある。
当たり前の話であるが、ビジネスをオブジェクト指向で考えてる人なんて誰もおらず、ビジネス上の概念をプログラミング言語で表現するのは我々エンジニアの仕事となる。
アプリケーションアーキテクチャ設計のポイント
分割統治
**大きくて複雑な問題は、そのままでは制御が困難なので小さく分割する。**複雑な問題が複合的に絡み合うと、指数関数的に解決が困難になるため、一度に相手にしてはいけない。
関心事の分離
複雑さの要因である**「ビジネスの関心事」と「技術的関心事」をいかに分離するか**は、Webアプリケーションの設計でキモになってくる。この二つがフュージョンすると、魔人ブウですら勝てない化物になりかねないので、個別撃破できるように隔離する。
いかに「ビジネスの関心事」を分離するか
多くのWebアプリケーションフレームワークでは、MVCが設計の根幹として位置づけられているが、ある程度複雑なシステムになってくると、MVCだけでは複雑さが制御できなくなってくる。「ビジネスの関心事」を表現したビジネスロジックと、データベースへの永続化などの「技術的関心事」が混在しはじめると、Fat ControllerやFat Modelが誕生しやすい。
そこで、ある程度大きなアプリケーションでは、『レイヤードアーキテクチャ』や『ヘキサゴナルアーキテクチャ』、『クリーンアーキテクチャ』などによって、「ビジネスの関心事」を「技術的関心事」から分離する。
いずれをベースにするにしても、**重要なことは「ビジネスの関心事」と「技術的関心事」に明確な境界を定義していることである。**それぞれの関心事が互いに漏れ出さないようにすることが鍵なのだ。
ドメイン駆動設計
「ビジネスの関心事」を設計する方法論として、台頭しているのがドメイン駆動設計(DDD)である。
レイヤ構造
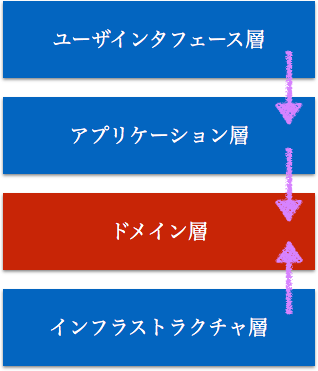
ドメイン駆動設計では、「ビジネスの関心事」を「技術的関心事」から分離することが徹底される。
「ビジネスの関心事」を表現する際には、**ドメインモデルをドメイン層に隔離し、アプリケーション層でドメインモデルを用いてユースケースを記述していく。**また、「技術的関心事」は基本的に、インフラストラクチャ層に押し込められる。
Dependency Injection
インタフェースが定義可能な言語では、『Dependency Injection(DI)』をフレームワークレベルでサポートしているものもある。JavaのSpringやPHPのLaravelがそれに該当する。
DIがフレームワークレベルで提供されると、例えばなにを永続化するかというインタフェース定義(ビジネスの関心事)と永続化の実装(技術的関心事)、を完全に分離することが可能になる。これによって、アプリケーションレイヤはインタフェースだけ知っていればよく、実装技術に依存せず、永続化処理を表現することが可能になる。
先ほど挙げた、レイヤ構造の部分で貼り付けた図では、シレッとインフラストラクチャ層がドメイン層に依存しているが、これはDIを前提にした依存関係を表現してる。
ドメイン駆動設計の深淵
ドメイン駆動設計についての詳しい情報は、『エヴァンス本』か、『ドメイン駆動設計 基本を理解する』あたりを参考にしてほしい。ここでは説明しないが、ユビキタス言語や境界づけられたコンテキストなど、極めて強力な概念が提示されている。
技術的なインピーダンスミスマッチ
オブジェクトで表現できないものは、インピーダンスミスマッチが発生する。
- リレーショナルデータベース
- リレーショナルデータベース以外のデータストア
- リクエストパラメータ
- View
- システム連携
- 通知
- メッセージング
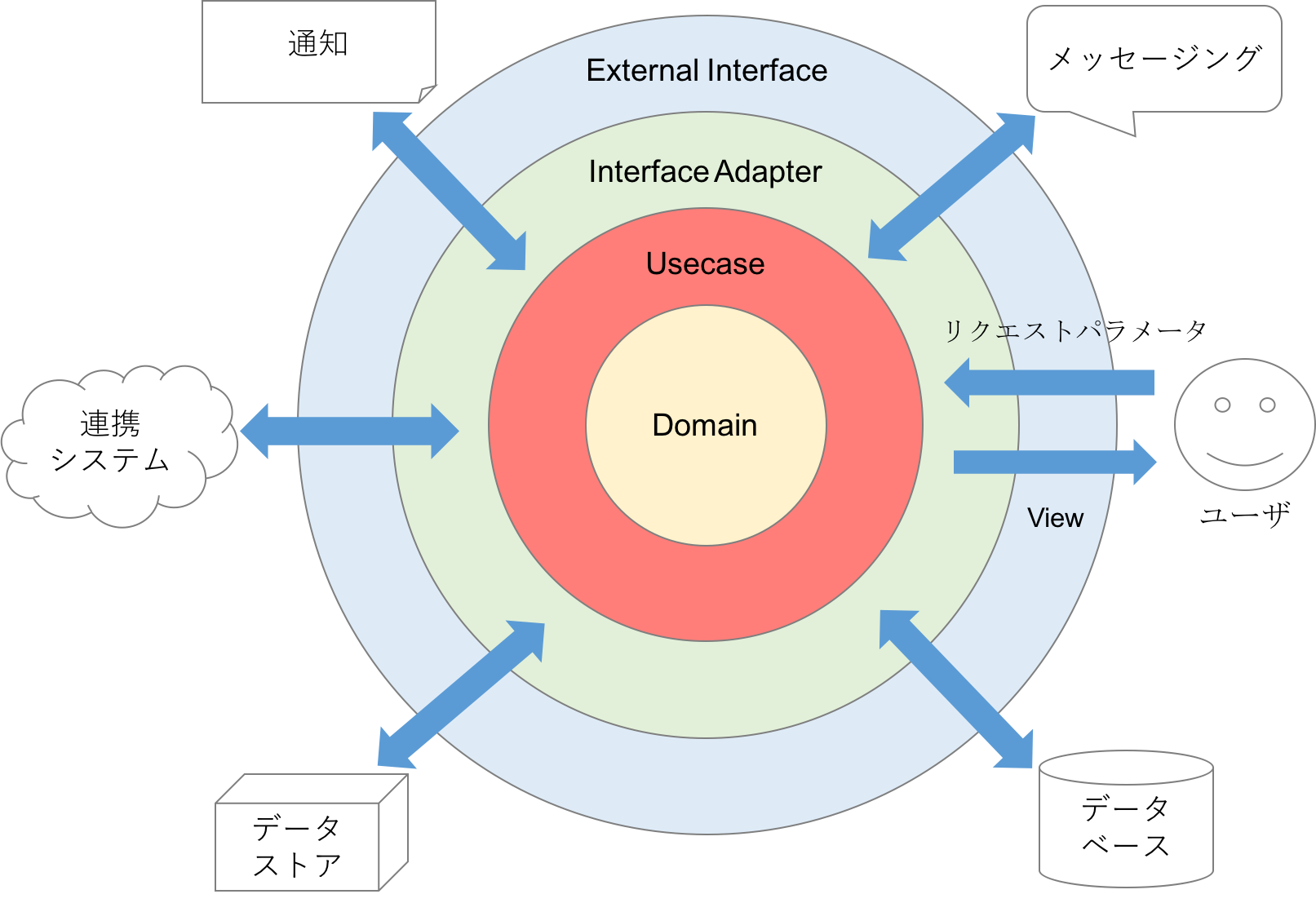
すごく乱暴に言えば、ネットワーク境界を行き来するデータは、そのままオブジェクトで表現できないので、必ずマッピング処理が必要となる。フレームワークやライブラリがよしなにしてくれるものもあれば、明示的に自分で書かなければいけないものもある。
また、不正データや通信エラーなどの外部要因により失敗する可能性も考慮する必要があり、運用する上では、エラーハンドリングについても重要な設計テーマになる。
リレーショナルデータベース
リレーショナルデータベースへの永続化パターンは、大きくは2つ存在する。
アクティブレコードパターン
オブジェクトにデータベースアクセスをカプセル化して、ドメインロジックを追加するパターン。**テーブルのデータ構造と、オブジェクトのデータ構造が一致するシンプルなアプリケーションで威力を発揮する。**マッピング処理を自分で書かなくて良いため、非常に便利である。
ただし、データベースとオブジェクトが密結合になるため、ビジネスロジックが複雑になってくると一気にカオス化する。また、経験則上、アクティブレコードパターンはカプセル化を破りやすい。オブジェクト指向設計への理解が浅いと、トランザクションスクリプトを量産して、ビジネスロジックがアプリケーション全体に拡散するハメになる。
データマッパーパターン
テーブルとドメインモデルをマッピングするクラスを定義し、テーブルのデータ構造と、オブジェクトのデータ構造を完全に分離する。テーブル設計とドメインモデリングを個別に行うことができるため、複雑なビジネスロジックが実装しやすく、保守性も極めて高くなる。
ただし、率直に言って、書くのは非常にメンドウである。アクティブレコードだと一瞬で実装できるコードも、愚直に実装しなければならない。また、アプリケーションが小さいうちは、データベースとオブジェクトが一対一で対応付けられるケースも多く、メリットが享受しづらい。最初にコードを書く人より、あとでコードを読む人が幸せになれるパターンであり、ホスピタリティが要求されるパターンとも言える。
リレーショナルデータベース以外のデータストア
リレーショナルデータベース以外のデータストアとしては、Memcached、Redis、Elasticsearch、DynamoDB、BigQueryなどがある。大抵のメジャーな言語向けにはライブラリが提供されており、ローレベルなプロトコルについては知る必要がないように実装されている。
これらのデータストアは、それぞれ独自のデータ構造を持っており、ライブラリで定義された専用のオブジェクトや汎用のハッシュ(連想配列/ディクショナリ)形式で、データをやり取りすることになる。このデータストア固有のデータ構造が、アプリケーション全体に拡散すると複雑度が上がるため、原則として、自分で定義したオブジェクトにマッピングする処理を書いたほうがよい。
リクエストパラメータ
HTTPリクエストされたパラメータはフレームワークによって、ハッシュや疑似ハッシュオブジェクトに変換されることが多い。ハッシュは汎用的で非常に便利であるが、データ構造が明示的に表現できないという欠点がある。コードを全部読まないと、どんなキーになんの値が入っているのか分からないのだ。
よって、**パラメータの数が多い場合は、Formオブジェクトなどへの変換を検討しよう。**リクエストパラメータのデータ構造をクラスとして明示的に表現すると、コード内での扱いが簡単になる。また、フレームワークによっては、Formオブジェクトへの変換をサポートしているものもあるので、使えるなら積極的に使おう。
View
HTML
HTMLを返す場合は、テンプレートエンジンに、オブジェクトを渡してレンダリングすることになる。テンプレートエンジンではif文などの制御構造がサポートされていることが多く、ロジックが散らばりやすい。
可能な限りテンプレートエンジンにはロジックを書かず、オブジェクトに対するメソッド呼び出しで対処すること。アーキテクチャ的に制約がかけづらいため、啓蒙活動も必要になるだろう。(テンプレートエンジンにロジック書いたら往復ビンタ!とか)
JSON
JSONを返す場合は、オブジェクトとJSONへのマッピングをどう実現するかが課題になる。例えばJavaだと、JAX-RSを実装したライブラリを使えば、オブジェクトから自動的にJSONにマッピングする機能を提供してくれる。しかしこの場合は、JSONの構造がオブジェクトのデータ構造にそのまま引っ張られてしまう。
そのため、面倒でも手動でマッピングするか、JSON変換用の専用のViewモデルを導入するほうが、中長期的には複雑になりにくい。
システム連携
Twitterなどの一般公開されているREST APIや、提携企業とのシステム連携、社内に構築されているマイクロサービスなど、他のシステムと連携する機会は多い。
これらは、それぞれが固有のインタフェースを定義しており、連携時には、API仕様に合わせて、泥臭く実装することになる。JSONだったり、XMLだったり、謎のテキストフォーマットだったりと、連携先のシステムによってデータフォーマットもデータ構造もバラバラだからだ。
連携システムのインタフェースが、アプリケーション全体に漏れ出すと制御不能な状態に陥るので、Adapterなどで腐敗防止層を実装し、外部システムの影響を局所化すること。
また、同時アクセス数や単位時間あたりのアクセス件数に上限が設けられていることが多いので、その制約に引っかからないよう実装しなければならない。
通知
まだまだメールが多いが、チャットサービスやモバイルアプリへのpush通知も行われるようになってきた。View同様、通知文面を定義するテンプレートにロジックが散らばりやすいため注意が必要である。
なお、インピーダンスミスマッチとはあまり関係がないが、通知はしくじったときの影響範囲が甚大なため、通知の責務を担うクラスをきちんと定義することが望ましい。「いつ」「だれに」「どんな」通知が飛ぶか、すぐに全体像が見えなくなるため、適切に管理する必要がある。
メッセージング
メッセージングでは、まずどんなメッセージを送るかが設計のポイントになる。メッセージには『コマンドメッセージ、ドキュメントメッセージ、イベントメッセージ』の三種類があるとされ、メッセージの設計にしたがって、オブジェクトをマッピングすることになる。
この3つのなかでも特にイベントメッセージングは、Pub/Subモデルが採用できるため、**アプリケーション自体の分割も可能である。**インピーダンスミスマッチという観点では正直大したことはないが、アーキテクチャ設計という観点からすると、かなり大きな可能性を秘めている。詳しくは『マイクロサービスアーキテクチャにおけるオーケストレーションとコレオグラフィ』あたりを参照してほしい。
横断的関心事
「ビジネスの関心事」と「技術的関心事」をどう表現するのかが、アプリケーションを書く上では重要だが、アーキテクチャ設計をする際には、「横断的関心事」についても考慮が必要である。
**「横断的関心事」は適切にアーキテクチャ設計をしておくと、普段の開発では、ほとんど意識しなくて済む。**一方、アーキテクチャ設計がイマイチだと、色々なトコロに顔を出して、コードを汚くしてくれる厄介者でもある。代表例を挙げておこう。
- 認証
- 認可
- ロギング
- 例外ハンドリング
- トランザクション管理
コイツラが至る所に顔を出すのは、アーキテクチャ設計における不吉な匂いである。多くのフレームワークでは、「横断的関心事」を制御するための機構がある程度備わっているが、フレームワークの知識が浅いと、これらの関心事が拡散しやすい。
「本質的な複雑性」と「偶有的な複雑性」
複雑性の別の視点
ブルックスによれば、ソフトウェア開発の複雑性には、「本質的な複雑性」と「偶有的な複雑性」の二種類がある。
「本質的な複雑性」は、問題領域から生じる複雑性で、取り除くことはできない。一方、「偶有的な複雑性」はエンジニア自身が生み出した複雑性で、取り除くことが可能である。
そこで、複雑性と対峙する際には、まず「偶有的な複雑性」を可能な限り削ぎ落とした上で、「本質的な複雑性」をコントロールすることがセオリーとなる。
「偶有的な複雑性」との戦い方
まずは余分な複雑性を生み出さないこと。例えば、インピーダンスミスマッチ解消のためのコードとビジネスロジックを混在させてはいけない。関係ないものを混ぜない、ということを徹底するだけで、「偶有的な複雑性」は生まれる前に消し去ることができる。
また、オブジェクト指向の知識や設計原則、プログラミングプラクティスも重要である。
- リーダブルコード
- カプセル化と情報隠蔽
- 防御的プログラミング
- 契約による設計
- SOLID原則
- デザインパターン
他にもあるだろうが、こういった設計の基本を丁寧に実践すると、「偶有的な複雑性」は大幅に低減できる。ウンコードを作らないことが最も簡単な「偶有的な複雑性」への対峙法である。
「本質的な複雑性」との戦い方
「ビジネスの複雑性」なんかは取り除くことができない典型的な複雑性だろう。これについては、取り除くのではなく、コントロールしにいく。
例えば、ドメイン駆動設計の知見を活用して、モデリングをしながらコードを書く。あるいは、単一責務のクラスを作って、その責務特有の複雑さをクラス内に押し込める。
重要なのは、境界を定義し、どこに複雑さを持たせるか明確にすることである。それができれば、あとは境界内で複雑さを制御するべく頑張るのみだ!
まとめ
アーキテクチャ設計をするにあたって、前提としなければならない事実の一つは**「コードは変更される」**ということである。変更されることからは逃れられないため、我々としては変更に強いコードを作る技術が求められる。アーキテクチャはその一助にならなければならない。
優れたアーキテクチャの特徴はいくつかあるが、特に重要なのは**「変更による影響範囲を局所化すること」「理解しやすいこと」「テストしやすいこと」**である。これらを実現することは容易ではないが、優れたアーキテクチャを構築できた時は本当に痛快な気持ちになれる。道のりは長いが、楽しんでいこう。
続編記事
Webアプリケーションフレームワーク導入時に考慮すべき22の観点
おまけ:巨人の肩の上に乗る
本記事の執筆にあたって参考にした書籍を紹介しておこう。膨大な知見をまとめあげた、偉大な先達に感謝である。