今回はScalaMatsuriセッション当選御礼の第2弾ということで、ScalaのDependency Injection(DI、依存性の注入 1)の方法について色々考察し、ドワンゴアカウントシステムで採用されているDIの方法の解説をしたいと思います。
まえおき
ドワンゴアカウントシステムはScalaのコードだけで22万行を越え、ドワンゴ社内で最大のScalaリポジトリとして知られています。
比較として、Scalaで最もメジャーなWebフレームワークであるPlay Frameworkが9万行、DBライブラリのSlickが3万行というと規模感がご理解いただけるのではないでしょうか。
なぜこれほど大きなコードになっているのかと言いますと、ドワンゴアカウントシステムはニコニコの様々なユーザー登録方法、認証方法、TwitterやFacebookなどの外部システム連携などの非常に多様で複雑な仕様を実現しているためです。
そして、現在もセキュリティ向上のための新しい認証方法の実装など、ユーザーがより便利にニコニコやドワンゴのサービスを使うことができるような機能の実装を急ピッチで進めています。
そんなドワンゴアカウントシステムですが、ドワンゴ社内で2015年前半のMost Valuable Team(MVT)に選ばれました(つい先日2015年後半のMVTが選出され、そこでは残念ながら連続受賞とはなりませんでしたが)。
これは伝え聞くところによりますと、ドワンゴアカウントシステムが社内の他のチームからの多くの開発依頼などに対して、迅速に対応することができたことが要因だったようです。
つまり、ちょっと大袈裟に言えば、ドワンゴアカウントシステムは22万行を越える社内最大のScalaシステムでありながら、その高い生産性が評価されて、2015年前半のドワンゴ全ての開発チームの中で最高のチームとして表彰されたわけです。
そのドワンゴアカウントシステムの生産性をプログラミング技術の面から一番支えていると個人的に考えているのが、今回解説するドワンゴアカウントシステムで採用されたDI方法です。
ドワンゴアカウントシステムはシステム全体に渡って大規模にDIが採用されています。
そして、我々の開発ではプルリクエストのレビューにはGoogleが開発したレビューシステムの Gerrit が採用され、プルリクエストにはDIにより抽象化されたAPIに対するドキュメントと、すべての例外ケースに対するユニットテストが必須とされ、レビューによってチェックされます。
このDI方法を考案し、レビューシステムを整備し、APIドキュメントコンベンションを定めた人物が田山氏という方で、その田山氏の名前にちなんでこのDI方法は社内ではTayamamixinと呼ばれたりもします。
結論から言えば、このTayamamixinはScala界隈で静的なDIとして知られているCakeパターンの一種と言えるものですが、僕はこの手法をCakeパターンの中でも純粋にDIだけの機能しか持っていない「最小のCakeパターン(Minimal Cake Pattern)」と呼びたいと考えています。
この記事は色々なScalaのDI方法と比較して、この「最小のCakeパターン」がなぜ優れているのか、ということを解説するためのものです。
また、この記事は、Scalaに限らない一般的なDIの定義や利点についての解説になっていたり、Scalaの色々なDI方法の解説にもなっていますので、
Dependency Injection?依存性の注入?って何?何のためにあるの?という方や、JavaのDIコンテナは知っているけどScalaのDI方法について学びたいという方も、最初のほうだけでも読むのをおすすめしたいです。
では、以下のような順番で説明していきますと思います。
- (Scalaに限らない)一般的なDIの定義、利点
- ScalaのDIによく使われる様々な技法
- ドワンゴアカウントシステムで採用されている手法
- なぜ他の手法に比べてこのDI手法が優れているのか
まずはDependency Injectionの復習
まずは今回の議論の土台として、一般的なDependency Injectionについて復習しましょう。
しかし、2015年にあってDependency Injectionについて考えるのはなかなかしんどい作業です。
なぜならDependency InjectionおよびInversion of Control(制御の反転)はJava界隈では10年以上前から使われている概念であり、
Martin FowlerがInversion of ControlからDependency Injectionという概念を抽出したのは2004年2、
さらにInversion of Controlについては1980年代からあるもの3であり、
それからDIについては現在に至るまで散々語り尽された感もあり、今更語るべき内容はあまり見当たりません。
とは言え、最近ではPHPやJavaScriptでもDependency Injectionを使ったフレームワークが登場するなど、Dependency Injectionという技術自体はいまだに学ぶべき重要な技術です。
ここではこれからの議論のためにDependency Injectionとはどういうものなのか、またDependency Injectionの利点は何なのかについてあらためて振り返りたいと思います。
Dependency Injectionとは?
Dependency InjectionについてWikipediaのDependency injectionの項目を見てみますと、
- Dependencyとは実際にサービスなどで使われるオブジェクトである
- InjectionとはDependencyオブジェクトを使うオブジェクトに渡すことである
とあります。さらにDIには以下の4つの役割が登場するとあります。
- 使われる対象の「サービス」
- サービスを使う(依存する)「クライアント」
- クライアントがどうサービスを使うかを定めた「インターフェース」
- サービスを構築し、クライアントに渡す「インジェクタ」
これらの役割について、前回のFujitaskの記事と同じ例(UserRepository、UserRepositoryImpl、UserService)で考えてみます。
ちょっとDDDとDIの用語が混同されるので、注意してください。
まずはDIを使っていない状態のクラス図を見てみましょう。
ソースコードは こちら です。
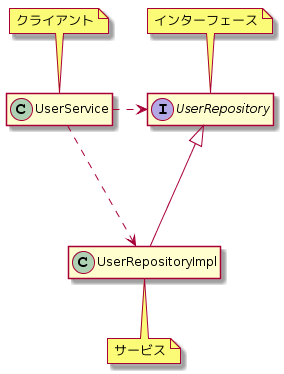
このクラス図の役割を表にしてみます。
DDD的なServiceが今回のDIの用語のサービスと衝突してしまってややこしいですが、以下の対応になります。
| DIの役割 | コード上の名前 | 説明 |
|---|---|---|
| インターフェース | UserRepository | 抽象的なインターフェース |
| サービス | UserRepositoryImpl | 具体的な実装 |
| クライアント | UserService | UserRepositoryの利用者 |
DIを使わない状態ではUserRepositoryというインターフェースが定義されているのにもかかわらず、UserServiceはUserRepositoryImplの参照も持っていました。
これではせっかくインターフェースを分離した意味がありません。
UserServiceがUserRepositoryインターフェースだけを参照(依存)するようにすれば、具体的な実装であるUserRepositoryImplの変更に影響されることはありません。
この問題を解決するのがDIの目的です。
それではDIのインジェクタを加えて、上記のクラス図を修正しましょう。
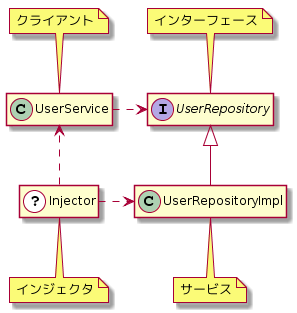
謎のインジェクタの登場によりUserServiceからUserRepositoryImplへの参照がなくなりました。
おそらくインジェクタは何らかの手段でサービスであるUserRepositoryImpl(Dependency)をクライアントであるUserServiceに渡しています(Injection)。
このインジェクタの動作を指して「Dependency Injection」と呼ぶわけです。
そして、このインジェクタをどうやって実現するか、それがDI技術の核心に当たります。
Dependency Injectionの利点
では、このDIを使うとどのような利点があるのでしょうか。
一つは前節でも触れた点ですが、クライアントがインターフェースだけを参照することにより、具体的な実装への参照が少なくなり コンポーネント同士が疎結合になる という点が挙げられます。
たとえばUserRepositoryImplのクラス名やパッケージ名が変更されてもUserServiceには何の影響もなくなります。
次に挙げられる点は具体的な実装を差し替えることにより クライアントの動作がカスタマイズ可能 になるという点です。
たとえば前回の例ではUserRepositoryImplはScalikeJDBCの実装でしたが、MongoDBに保存するMongoUserRepositoryImplを新しく作ってUserServiceに渡せばクライアントをMongoDBに保存するように変更することができます。
またDIは設計レベルでも意味があります。DDDではしばしばヘキサゴナル・アーキテクチャ4やクリーンアーキテクチャ5のようなドメインを中心とするアーキテクチャが推奨されますが、
このようなアーキテクチャを実現するには 依存関係逆転の原則を実現 しなければなりません。
たとえばUserRepositoryとUserServiceはDDDで言うところのドメイン層のものですが、ScalikeJDBCの実装であるUserRepositoryImplはインフラストラクチャ層のものです。
通常のレイヤ化アーキテクチャではドメイン層のUserRepositoryがインフラストラクチャ層のUserRepositoryImplのメソッドを呼び出すわけですが、依存関係逆転の原則を適用したアーキテクチャではこれは許されません。
DIを使えばこの依存関係逆転の原則を実現することができます。
そして、見落されがちな点ですが、DIでは クライアントに特別な実装を要求しない という点も重要です。
これはJava界隈でDIが登場した背景に関連するのですが、Spring FrameworkなどのDIを実現するDIコンテナは複雑なEnterprise JavaBeans(EJB)に対するアンチテーゼとして誕生しました。
複雑なEJBに対し、何も特別でないただのJavaオブジェクトであるPlain Old Java Object(POJO)という概念が提唱され、わかりやすさや、言語そのものの機能による自由な記述が重視されました。
DIの登場にはそのような背景があり、クライアントに対して純粋な言語機能以外求められないことが一般的です。
最後に、おそらくDIで一番重要な点と考えられているのが 依存オブジェクトのモック化によるユニットテストが可能になる という点です。
たとえばWebアプリケーションについて考えると、Webアプリケーションは様々な外部システムを使います。
WebアプリケーションはMySQLやRedisなどのストレージを使い、TwitterやFacebookなどの外部サービスにアクセスすることもあるでしょう。
また刻一刻と変化する時間や天候などの情報を使うかもしれません。
このような外部システムが関係するモジュールはユニットテストすることが困難です。
DIを使えば外部システムの実装を分離できるので、モックに置き換えて、楽にテストできるようになります。
以上、DIの利点を見てきました。
実装オブジェクト(Dependency)を取得し、サービスに渡す(Injection)だけの役割のインジェクタの登場により様々なメリットが生まれることが理解できたと思います。
DIは特に大規模システムの構築に欠かせない技術であると言っても過言ではないと思います。
Scalaにおける色々なDI手法の紹介
一般的なDIについて振り返ったところで、次にScalaにおけるDIの手法を紹介していきましょう。
まず大きくわけるとScalaのDI手法は三つの区分があると言えます。
- GuiceなどのDIを支援するフレームワークである「DIコンテナ」を使う方法
- 「Cakeパターン」を使う方法
- 「Readerモナド」などの関数型の技術を使う方法
それぞれ手法について代表的な資料を紹介しつつ考察していきます。
GuiceなどのDIを支援するフレームワークである「DIコンテナ」を使う方法
Scalaの代表的なWebフレームワークであるPlay Frameworkが今年リリースされたバージョン2.4でGoogle Guiceを使ったDIを採用したことには驚かされました。
Guiceを使ったDIがScalaでも使えることは昔から知られていましたが、Scalaではトレイトのミックスインを使ったCakeパターンによるDI手法がメジャーなものと考えられていたからです。
Play Frameworkはステートレスなフレームワークを目標とする一方で、グローバルなステートオブジェクトの存在に悩まされてきました。
一部モジュールはグローバルステートオブジェクトと分離しがたく、テストもグローバルステートオブジェクトのスタブ実装を用いなければならず、不便なものでした。
Play Frameworkはこのような問題をGuiceを使うことで解決しようとしているわけです。
そのあたりの事情については以下のtototoshiさんのブログにまとめられています。
Play 2.4 と Dependency Injection - tototoshi の日記
またInfoQにPlayフレームワークの開発者であるJames Roperさんへのインタビュー記事があり、こちらもPlayがどういう方針なのか参考になります。
GuiceとScalaを組み合わせるとどのようになるかは以下の記事を読むと雰囲気が掴めるでしょう。
ScalaとGoogle Guiceの組み合わせについて軽く調べた - Qiita
Scala - Google Guiceについて、もうちょっと調べた - Qiita
DIコンテナを使う利点と欠点
では、DIを実現するのにDIコンテナを使う利点は何でしょうか?
まず挙げられるのが依存オブジェクトの注入がDIコンテナに任されるため完全にコードから依存の情報がなくなるという点です。
これによりクライアントからサービスへのソースコードの参照がなくなるのでクライアントとサービスを 完全に別々にコンパイルすることが可能 になり コンパイル時間の短縮や別々のデプロイも可能 になります。
またクライアントはコンストラクタやフィールドにサービスを格納する変数を用意するだけで、コード上の特別な記述は必要ないので クライアントをよりプレーンなものにすることができる という点もあります。
そして、Javaでも広く使われているDIコンテナを使うことで DIのやり方を標準化された方法に統一できる という点もあります。Scalaの言語機能を使ったDIは色々な記述方法が可能で決定版と言える方法がない状態です。おそらくPlayがGuiceを採用したのはこの理由も大きいでしょう。
逆にDIコンテナを使う欠点もあります。
DIコンテナは動的にクライアントとサービスを結びつけ、アプリケーションを組み立てます。
よって エラーの判明が実行時まで遅延されてしまう こともしばしばあります。
またDIコンテナを使うことにより通常のプログラミングではできないような 複雑すぎる依存関係も作れてしまう ことがあります。
このような問題を解決するには DIコンテナの動作の知識が要求される こともあるでしょう。
最後に、DIの提唱者であるMartin FowlerのInversion of Control コンテナと Dependency Injection パターンを読んでみると、
意外にも当時の彼はDIコンテナの利用を完全に支持していたわけではないことがわかります。
DIコンテナはInversion of Control(制御の反転)という技術が使われています。大袈裟な名前ですが、要するにDIコンテナはオブジェクトを注入するための制御を持つフレームワークであるということです。
これに対し、Martin Fowlerは興味深いことを述べています。
制御の反転はフレームワークに共通する機能であるが、その機能にはそれなりの代償も伴う。 制御の反転は理解しづらくなりがちである。デバッグしようとしたときに問題となることもある。 よって、総合的な見地から、私は制御の反転については、どうしても必要となるまで利用を避けたい。 これは Dependency Injection が使えない、と言っているわけではない。 単に、より素直な代替案があるのなら、それを利用するのはもっともだと言いたいだけである。
これはかなり一般的な話です。
たとえば通常のライブラリであれば、テストはメソッドもしくは関数を呼び出して、結果が期待されたものと一致したか確認するだけで事足ります。
しかしライブラリではなくフレームワークを利用した場合、メソッド呼び出しの制御はフレームワーク側に委ねられるので、そのような単純なテストが不可能になります。
そのフレームワークに合わせたテスト機能が必要になるでしょう。
このように フレームワークの利用はテストのしやすさや制御のわかりやすさを犠牲にする ような諸刃の剣になりうるわけです。
そして最後に、コード中にサービスを提供する役割を持たせたオブジェクトを作る「Service Locator」という手法と比較して、
アプリケーションクラスを構築するにあたっては、両者ともだいたい同じようなものだが、私は Service Locator のほうが少し優勢だと思う。こちらのほうが振る舞いが素直だからだ。しかしながら、構築したクラスが複数のアプリケーションで利用されるのであれば、Dependency Injection のほうがより良い選択肢となる。
とも述べています。
DIコンテナがこれだけ普及した現在ならおそらく違う意見だと思われますが、EJBのアンチテーゼとして生まれたDIコンテナがフレームワークであることに対する若干のためらいのようなものを感じます。
Cakeパターンを使う方法
次にCakeパターンを使ったDI手法について解説します。
(ここからは理解するのにScalaの言語機能の知識が必要になります)
JavaのDIが10年前からある技術であるように、ScalaのCakeパターンの登場も5年以上前に遡ります。
おそらくCakeパターンを使ったDI手法の最も代表的な資料はAkkaのオリジナルの作者でTypesafe社CTOとして知られるJonas Bonérさんによる2008年に書かれた以下の資料でしょう。
実戦での Scala: Cake パターンを用いた Dependency Injection (DI) | eed3si9n
この資料はちょっとわかりづらいところがあるので、再びUserServiceとUserRepositoryの例に戻って軽く補足したいと思います。
前回のコードの問題点はクライアントのUserServiceから具体的な実装であるUserRepositoryImplを直接参照していることでした。
trait UserRepository {
// 略
}
object UserRepositoryImpl extends UserRepository {
// 略
}
object UserService {
val userRepository: UserRepository = UserRepositoryImpl // ← ここでImplを参照しているのが問題
// 略
}
これをBonérさんの資料の方針に従って修正すると以下のようになります。
trait UserRepositoryComponent {
val userRepository: UserRepository
trait UserRepository {
// 略
}
}
trait UserRepositoryComponentImpl extends UserRepositoryComponent {
val userRepository = UserRepositoryImpl
object UserRepositoryImpl extends UserRepository {
// 略
}
}
trait UserService {
this: UserRepositoryComponent =>
// 略
}
object UserService extends UserService with UserRepositoryComponentImpl
UserServiceはトレイトになり、UserRepositoryImplへの直接の参照がなくなりました。
Bonérさん方法では、UserRepositoryの外側にUserRepositoryComponentというものを用意し、UserServiceはUserRepositoryComponentを自分型アノテーション(self type annotations)として指定し、そのフィールドを経由してUserRepositoryを参照するようになります。
そうすることで最後にトレイトのミックスイン機能を使って具体的な実装を注入することができるわけです。
余談:自分型アノテーション or 継承
余談になりますが、ここで自分型アノテーションを使うのは必須ではありません。
たとえばUserServiceはUserRepositoryComponentを直接継承してしまってもかまいません。
// これでもだいたい同じ
trait UserService extends UserRepositoryComponent {
// 略
}
自分型アノテーションを使うか、継承を使うかは、実装者の好みによると思います。
自分型アノテーションは実質的にDI専用の機能です。なので、自分型アノテーションを使うことでコード上でDIをおこなっているのがわかりやすくなるという利点があります。
自分型アノテーションは外から見たときに継承関係が隠蔽されるという利点もあります。
またトレイトのミックスインと違って、自分型アノテーションは循環参照を許していますが、これは好みがわかれるところでしょう。
これらの利点に大きな価値を見出せない場合は継承を使ってもよいと思います。
Cakeパターンは毀誉褒貶が激しい
このCakeパターンですが、Scalaの開発者界隈では毀誉褒貶が激しいです。
まずは褒める意見ですが、以下のDaniel Spiewakさんによるものが代表的でしょう。
翻訳: "Cake Pattern: The Bakery from the Black Lagoon" - Okapies' Archive
この資料には、DIの利用を越えて、モジュールを構成するためにCakeパターンを使う様々な可能性が示されています。
またこの資料はCakeパターンの賛否とは別にScalaのトレイトの実践としてたいへん素晴らしい資料になっています。
Scalaのトレイトで何が可能なのか、これを読めばよくわかります。Scalaプログラマ必読と言える資料です。
(とは言え、この資料の手法を実際に採用すべきかは別問題ですが…)
対するCakeパターンを貶す意見ですが、なんとScalaコンパイラ開発者から出されています。
Scalaのコミッターの人が「Cake Patternはアンチパターンだ」と言って話題に! - Togetterまとめ
そのScalaコンパイラ開発者であるKossakowskiさんの意見を簡単に要約するとこうです。
- Cakeパターンは複雑なpath-dependentな型を生み出し、デバッグが困難になる
- Cakeパターンの合成とワイルドカードimportの組み合わせは、依存のコントロールが困難になる
- Cakeパターンによる重度にネストされたクラスは、パフォーマンスに悪い影響を与える
そして、GuiceなどのDIコンテナを使うほうがよいという結論に至っています。
Scalaコンパイラ開発者からこういう意見が出されるというのはどういうことなのでしょうか?
以下は自分が2012年ごろにScala 2.10当時のリフレクションとマクロについて調査した資料ですが、
Scala 2.10 Reflection and Macros
この中にこんな図が出てきます。
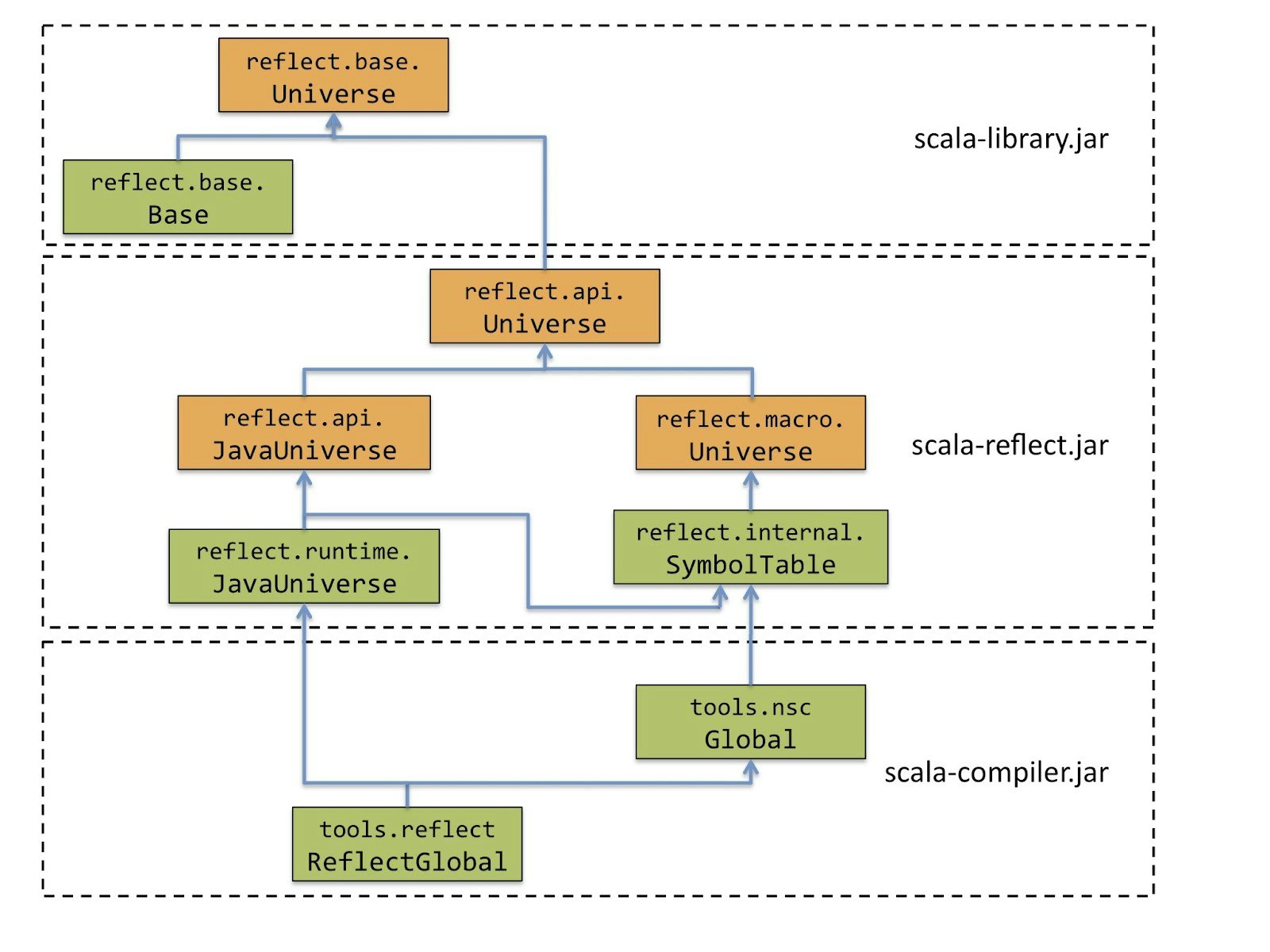
これはScalaコンパイラの構成図です。
一つ一つUniverseは数十個のトレイトからなるCakeパターンで作られたクラスです。
その個々のトレイトの中にはこれまた無数のクラスが存在しています。
そんなUniverseがこの図のように複雑な継承関係になっているわけです。
このようなScalaコンパイラのとてつもない複雑さを考えるとKossakowskiさんのような意見が出るのは当然と言えるでしょう。
以上、Cakeパターンの賛否について見てきましたが、しかし、これらは今我々が話題にしているDIと本当に関連していると言えるのでしょうか。
CakeパターンはそもそもBonérさんの記事にあるとおり、Scalaの言語設計者であるOderskyさんによる2005年の論文「Scalable Component Abstractions」で紹介された抽象型、自分型アノテーション、トレイトのミックスインを使ったコンポーネント作成方法でした。
それがBonérさんの記事によりDI手法として注目され、今ではCakeパターンはScalaの代表的なDI方法として広く認識されています。
と考えると、Cakeパターンに対するSpiewakさんによる称賛も、Kossakowskiさんによる非難も、Cakeパターンをコンポーネント作成方法として見做したものであり、Cakeパターンを純粋にDIとして適用した場合にあてはまるものなのでしょうか。
この疑問については、後で説明する我々が採用した「最小のCakeパターン(Minimal Cake Pattern)」によるDI方法の説明により答えたいと思います。
「Readerモナド」などの関数型の技術を使う方法
そして、Scalaの代表的なDI手法として最後に紹介するのが、Readerモナドを使ったDI手法です。
(この話題を理解するのは関数型プログラミングに興味がある人だけでよいです)
Readerモナドを使った手法は、関数型プログラミングのアプローチを好む開発者によって提案されました。
代表的な資料はJason Arhartさんによる以下の記事や
『Scala関数型デザイン&プログラミング』の著者の一人として知られているRúnar Bjarnasonさんによる以下の発表資料です。
Dead-Simple Dependency Injection in Scala // Speaker Deck
「Dead-Simple Dependency Injection in Scala」のほうは資料だけを読んでもわかりづらいので、合わせて以下の資料を読むこともおすすめします。
Scala - Dependency InjectionとDSL - Qiita
このようにScalaの関数型界隈ではCakeパターンに代わりReaderモナドをDIに使うのがよいという意見がありますが、
結論から述べると、このReaderモナドを使った手法はまだまだ実用するには越えなければならない壁が多いと個人的に感じています。
ReaderモナドをDIで使う問題点
以下、ReaderモナドをDIに使うのが難しい理由を述べていきます。
- メソッド単位で細かいDI情報を意識するのは煩雑になりすぎる
- たとえば、一つ一つのメソッドがログをファイルに書くか、fluentdに送るかなどの細かいDIまで意識しなければならないのだろうか?
- 反対に個々のメソッドが細かいDI情報を扱いたくない場合、おそらくReaderモナドを使ったDIのインジェクタは全てのサービスの情報を含んだものになってしまう
- この場合、メソッドの挙動を追わないとクライアントがいったいどのサービスに依存してしまうかわからなくなってしまう
- DI情報がコールスタックにしたがって伝搬されるため、HaskellのIOモナドのようなモナドの伝搬地獄が発生する
- たとえばコールスタックの奥深くでDIしなければならなくなったとき、コールスタックのすべてのメソッドをReaderモナドに修正しなければならなくなる
- 大規模にDIを適用した場合、ほとんどすべてのメソッドがReaderモナドになるという事態を引き起こしかねない
- Martin FowlerがInversion of Control コンテナと Dependency Injection パターンで指摘したサービス・ロケータと同じような問題、つまりクライアントはサービスへの依存をやめるかわりに、新たにReaderモナドに依存しているという問題が起きているのではないだろうか
- 容易にモナドのネストが発生してしまう
- メソッドの返り値がOptionやFutureである場合
Option[Reader[E, Future[A]]]のような型ができてしまいそうだが、これをどう解決するか頭を悩ませることになる - モナドトランスフォーマーを導入することになったら…DIを解決するのに本末転倒の新しい問題を引き起こしているのではないだろうか?
少なくともReaderモナドを素朴にDIに使うのは難しいというのが個人的な見解です。
Readerモナドは前回紹介したFujitaskのトランザクションオブジェクトのように限られた状況で暗黙的に伝達しなければならない情報を入れるのには向いていると思いますが、
このDIの問題のようにアプリケーション全域にばらまく用途には向いてないと思います。
余談:implicit parameterを利用したDI手法
ちなみにScalaではimplicit parameterを利用したDI手法もありますが、ReaderモナドをDIで使う問題点で説明した1から3までの問題点はまったく同じです。
大規模システムに採用するには厳しいと思います。
なのでimplicit parameterを使った手法は大きく取り上げることはしませんでした。
ドワンゴアカウントシステムで採用されている手法
では、いよいよドワンゴアカウントシステムで採用されているDI方法について解説しましょう。
Cakeパターン再考
冒頭で我々が採用しているDIはCakeパターンの一種であると述べました。
そして、ScalaのDI方法の解説のところで、Cakeパターンには批判的な声もあるということを紹介し、それはコンポーネント手法としてのCakeパターンに対してであるとも述べました。
ここでは先ほど棚上げした疑問である、DIのみに特化したCakeパターンは批判されるべきものなのか、という点について考えたいと思います。
では、先ほどScalaコンパイラ開発者から批判されたCakeパターンの機能についてもう一度見ていきましょう。
- Cakeパターンは複雑なpath-dependentな型を生み出し、デバッグが困難になる
これはCakeパターンの中で抽象型を使っているのが問題であると思います。
抽象型は表現力の高い機能ではありますが、一方でここで指摘されたようなわかりづらさを生み出してしまう問題があるのも事実だと思います。
乱用には注意が必要です。
- Cakeパターンの合成とワイルドカードimportの組み合わせは、依存のコントロールが困難になる
自分も個人的にCakeパターンをコンポーネント技術として使った場合の最大の問題点と考えているのが、合成されるCake同士の結合度合いの高さです。
Cake間で自由に型やクラスを参照しすぎると、コンポーネントが本来持つべき独立性が損われてしまいます。
- Cakeパターンによる重度にネストされたクラスは、パフォーマンスに悪い影響を与える
Cakeパターンをモジュールとして考えた場合に、パッケージのかわりにネストされたクラスを使うという用途が考えられますが、個人的にそれほど大きな利点があるとは思えないので、やめてしまってよい気がします。
これで、Cakeパターンの問題点を振り返ることができました。
最小のCakeパターン(Minimal Cake Pattern)
では、これら問題点を解決するためには、どうすればいいでしょうか?
まず、DIには直接関係ないので 抽象型などの高度な機能は使わない ようにします。
また、コンポーネント間の結合を制限したいので 一つのCakeの合成により受け渡されるのは一つのフィールド変数だけ とします。
DIの用語で言うと一つのフィールドインジェクションに限るということです。
そして、Bonérさんの記事にあるようなオリジナルのCakeパターンとは変えて クラスをネストさせない ようにします。
これらの条件を満たすようなDIに特化したCakeパターンを「最小のCakeパターン(Minimal Cake Pattern)」と定義します。
この最小のCakeパターンはScalaコンパイラ開発者から批判されたような特徴は持ちません。しかし、DIの機能はあります。
これがドワンゴアカウントシステムで採用されているDI方法というわけです。
最小のCakeパターンの具体例
では、この最小のCakeパターンの具体例を見てみましょう。
前の例と同じようにUserRepositoryとUserServiceを使って考えてみます。
インターフェース部分は以下のようになります。
trait UsesUserRepository {
val userRepository: UserRepository
}
trait UserRepository {
// 略
}
UserRepositoryは先ほどと同じインターフェースです。
そして、そのインターフェースと対になるUsesUserRepositoryを作りました。
このUsesUserRepositoryは、UserRepositoryへの依存を示すただ一つのフィールドを持つモジュールです。
実装部分は以下のようになります。
trait MixInUserRepository extends UsesUserRepository {
val userRepository = UserRepositoryImpl
}
object UserRepositoryImpl extends UserRepository {
// 略
}
UserRepositoryImplは先ほどと同じ(DI用語の)サービスです。
そして、そのサービスと対になるMixInUserRepositoryを作りました。
このMixInUserRepositoryは、UserRepositoryの実装を提供するただ一つのフィールドを持つモジュールです。
利用する部分は以下のようになります。
trait UserService extends UsesUserRepository {
// 略
}
object UserService extends UserService with MixInUserRepository
UserServiceトレイトは(DI用語の)クライアントです。そしてUsesUserRepositoryを継承し、インターフェースのUserRepositoryを使っていることを表明しています。
ここでは自分型アノテーションを用いずに継承により依存関係を表現しています。
そして、UserServiceオブジェクトはUserServiceトレイトとMixInUserRepositoryを継承し、サービスをクライアントにインジェクトしています。
以上、例を紹介しましたが、よく見るとUsesやMixInなどに名前が変更されていますが、Bonérさんの例からネスト外しただけということがわかります。
なんだ、結局それだけかよ、と思われるかもしれませんが このルールを徹底し、大規模に適用された場合 に、この最小のCakeパターンの意味がわかってくると思います。
実際にドワンゴアカウントシステムではどのようにコード作成していくのか
というわけで、実際に最近自分が開発したドワンゴアカウントシステムのとある新機能を例に、ドワンゴアカウントシステムではどのようにコードを作成していくか見ていくことにしましょう。
(新機能なので一部名前が伏せてあります)
1. インターフェースを定義する
ここではXXXUserという特殊なユーザーを作成する機能のコードを作っていきます。
まず最初に作るのはインターフェースの定義です。
trait XXXUserCreateService {
/**
* XXXUser を作成する
*
* @param userType XXXUserType
* @param deviceId XXXDeviceId
* @return Future.successful(XXXUser, XXXSessionId) 成功した (作成したXXXUserと発行したセッションIDを返す)
* Future.failed(IllegalArgumentException) Permanent の XXXしか作成できないように設定された環境で、Permanent 以外の種別を指定した
* Future.failed(TooFrequentAccessesException) IPアドレスが連続登録制限を超えている場合
* Future.failed(ResourceConflictException) XXXUserIdもしくはXXXDeviceIdが重複した
* Future.failed(DatabaseConnectionException) DB接続中にエラーが発生した
*/
def create(userType: XXXUserType, deviceId: XXXDeviceId, handprint: Handprint): Future[(XXXUser, XXXSessionId)]
}
ここで重要なのはエラーケースまでしっかりドキュメントを書くことです。
テストを書く際にはこのドキュメントが参照されることになります。
2. インターフェースの依存を提供するモジュールを作る
trait UsesXXXUserCreateService {
val xxxUserCreateService: XXXUserCreateService
}
ここは上記の具体例で説明したのと同じです。
3. 実装する
今回は複数の実装を持たないので、インタフェースのトレイトに直接実装してしまいましょう。
trait XXXUserCreateService
extends UsesXXXSessionCreateService
with UsesXXXUserRepository
with UsesXXXStorageAccess
with UsesXXXExpireUpdateService
with UsesXXXDummyUserRepository
with UsesStorageAccess
with UsesClock
with UsesApplicationLogger
with UsesAccountAttackDetectService
with UsesXXXConfig
with UsesRandomNextLong
with UsesXXXSessionRepository
with UsesDefaultExecutor {
/**
* XXXUser を作成する
*
* @param userType XXXUserType
* @param deviceId XXXDeviceId
* @return Future.successful(XXXUser, XXXSessionId) 成功した (作成したXXXUserと発行したセッションIDを返す)
* Future.failed(IllegalArgumentException) Permanent の XXXしか作成できないように設定された環境で、Permanent 以外の種別を指定した
* Future.failed(TooFrequentAccessesException) IPアドレスが連続登録制限を超えている場合
* Future.failed(ResourceConflictException) XXXUserIdもしくはXXXDeviceIdが重複した
* Future.failed(DatabaseConnectionException) DB接続中にエラーが発生した
*/
def create(userType: XXXUserType, deviceId: XXXDeviceId, handprint: Handprint): Future[(XXXUser, XXXSessionId)] =
// 略
}
詳細は省略しますが、13個のインターフェースに依存する実装になりました。
4. 実装を提供するモジュールを作る
trait MixInXxxUserCreateService extends UsesXxxUserCreateService {
val xxxUserCreateService =
new XxxUserCreateService
with MixInXxxSessionCreateService
with MixInXxxUserRepository
with MixInXxxStorageAccess
with MixInXxxExpireUpdateService
with MixInXxxDummyUserRepository
with MixInStorageAccess
with MixInSystemClock
with MixInApplicationLogger
with MixInXxxAttackDetectService
with MixInXxxConfig
with MixInRandomNextLong
with MixInXxxSessionRepository
with MixInDefaultExecutor
}
実装を作ったら、今度はこの実装を外部に提供するモジュールを作成します。
Usesトレイトが定義されているものは、必ず一つはMixInトレイトも提供されるので、それを使います。
ここで実装を差し替えることも可能です。
5. テストを書く
最後に作成したメソッドのテストを書きます。
class XXXUserCreateServiceSpec extends Specification {
"create" should {
"return created XXXUser" in // 略
"create permanent XXXUser if mockXXXConfig.createPermanentOnly is TRUE" // 略
"not create last_3_months XXXUser and throw IllegalArgumentException if mockXXXConfig.createPermanentOnly is TRUE" // 略
"not create DummyUserId and not update expire if XXXUserRepository throws Exception" // 略
//以下略
}
テストでは最初にインターフェースで書いたコメントのエラーケースが網羅されていることは必須とされます。
また依存オブジェクトの例外もチェックし、基本的にすべてのケースでテストを書く必要があります(しかし、こちらはたとえば全ての例外で同じ動作をするなど、あまりに自明である場合は省略することもできます)。
6. レビューに出す
テストまで書くとレビューに出すことができるようになったので、プルリクエストとしてレビューに出すことにします。
これが我々が開発するコードの単位になります。
先ほど紹介した最小のCakeパターンが開発スタイルに大きな影響を与えていることがよくわかると思います。
なぜ、この「最小のCakeパターン」が他のDI方法より優れていると言えるのか?
では、今まで見てきた様々なScalaのDI方法に比べて、この最小のCakeパターンがなぜ優れていると言えるのかを説明したいと思います。
まず、述べておきたいのはドワンゴアカウントシステムはこのDI方法により 400以上ものモジュールで構成されている という点です。
これだけ大規模にDIを適用するためにはDI技術に 本当に必要最小限のシンプルさが求められる ということです。
つまり余計な抽象型やネストされたクラスを取り除き 通常のCakeパターンの欠点にもなりうる部分を捨てる ことが重要なのです。
次に、DIコンテナに対する利点を考えてみますと、これはCakeパターン全般に言えることですが、Scalaのトレイトという言語機能により DIの「インジェクタ」という存在がそもそも不要になる ということです。
Martin Fowlerの「単に、より素直な代替案があるのなら、それを利用するのはもっともだと言いたいだけである。」という言葉を思い出してください。
言語機能の進歩によりフレームワークやデザインパターンのようなものが不要になることがありますが、ScalaのトレイトとDIコンテナの関係も同じようなものではないでしょうか。
また、繰り返しですがドワンゴアカウントシステムがScalaコード22万行、400以上ものモジュールで構成されているということを考えると、やはり 大規模システムではコンパイラよる静的なチェックのほうが好ましい と言えるのではないでしょうか。
これだけ大きなシステムを起動させなければエラーがわからないというよりは、コンパイル時にエラーがわかったほうが嬉しいと思います。
またDIコンテナのエラーよりもScalaコンパイラのエラーのほうがよりわかりやすいと思われます。
さらにUsesトレイトで依存を記述し、MixInトレイトでDIを表現するという記述方法はとてもシンプルで アノテーションやXMLに比べてもほとんど冗長さがない とも言えるでしょう。
これもこのDI方法が極めてシンプルであることの利点です。
そして、DIを全面的に採用できるようになった結果、上記のアカウントシステムの実装例で挙げたように、コードは以下のものをひとまとめにしたものになり、
- インターフェース
- インターフェースの依存を提供するモジュール
- 実装
- 実装を提供するモジュール
- インターフェースと利用モジュールに基づいたテスト
DIにより開発単位を規定できるようになった と言えるでしょう。
と、ここまで説明すれば、なぜこのDI方法が我々ドワンゴアカウントシステムの生産性に大きく寄与しているのかという理由がご理解いただけたと思います。
まとめ
以上、ドワンゴアカウントシステムで使われているDI方法について解説をおこないました。
このDI方法を考えた田山氏本人は、このやり方について、こんなの自明じゃないの?解説する価値があるの?と言っていましたが、Scalaに詳しい人ほど、このDIによるモジュール構成法が自明でないことがわかるのではないでしょうか。
最近のScala界隈は、Cakeパターンは古いものとして貶され、PlayがGuiceを採用したけど本当にDIコンテナで大丈夫なの?と訝しみ、関数型界隈からはReaderモナドによるDIが提唱されるが実戦で本当に使えるものなのかわからない、そんな状況だと思います。
熟練したScalaプログラマでもDIについての結論を出すのは難しいと思います。
僕も同じようにScalaのDIについて結論が出せなかった人間であり、だからこそドワンゴに入社し、アカウントシステムに配属され、この最小のCakeパターンと言うべき方法が全面的に採用されたソースコードを見たときには深い感銘を受けました。
そして、大規模システムで採用すべきDI方法はこの方式しかないと確信したわけですが、僕が受けたこの感銘を他の人に伝えるためには、この記事のようにあらためてDIの利点を問い直し、Scalaの様々なDI方法について考察し、そして、実際に我々のコードの一部を見ていただくしかないと考えました。
今回、ScalaMatsuriのセッション当選と、ドワンゴアドベントカレンダーという機会を得て、こういう記事を書けたことをたいへん嬉しく思います。
-
Dependency Injectionの訳語としては「依存性の注入」という言葉が一般的ですが、この記事では「Dependency Injection」もしくは「DI」という言葉を使いたいと思います。「依存性の注入」という訳語はあまりよくなく、正確には「依存オブジェクトの注入」と呼ぶべきだという意見がありますが、こちらの言葉はあまり一般的とは言えず、「DI」で十分意味が伝わるため、英語で十分だと判断しました。 ↩
-
Inversion of Control Containers and the Dependency Injection pattern が2004年に書かれたことを指しています。 ↩