この記事について
本記事はPythonを使ったWebスクレイピングのテクニックを紹介します。
※お酒飲みながら暇つぶしで書いたので割と適当です。
今回紹介するテクニックを使えれば経験上大体どんな値でも取得でき、これらはRubyだろうがGolangだろうが同じ様に動作します。
Webスクレイピングが出来ないサイトがあればコメントにて教えてください。全身全霊を持ってやってみます。
また、Webスクレイピングをしたことが無い方は下記の記事を読むことをお勧めします。
Python Webスクレイピング 実践入門 - Qiita
追記更新
6/12 コメントに対応しました。
はじめに
注意事項です。よく読みましょう。
岡崎市立中央図書館事件(Librahack事件) - Wikipedia
Webスクレイピングの注意事項一覧
テクニック集
・CSSセレクターを使用してサクっと取得しよう
CSSセレクターはご存知ですか?
CSSを書いたことがある方はわかりますが、例えばこんなやつです。
# foo{
color: #red;
}
# foo > .hoge{
color: #blue;
}
どの部分がCSSセレクターかというと#fooという部分と#foo > .hogeの部分です。
このコードの意味はidがfooという要素に対してcolor: #redを適用し
idがfooという要素の子要素の中でclassがhogeという要素に対してcolor: #blueを適用するcssです。
具体的にどう変化するかと言いますと
<html>
<body>
<div id="foo">
<p>赤だよ!</p>
<div class="hoge">
<p>青だよ!</p>
</div>
<div class="hogehoge">
<p>赤だよ!</p>
</div>
</div>
</div>
</body>
</html>
って感じです。
この#fooと#foo > .hogeという部分がどこに適用するのかを指定しています。
これらの記述方法を使って、どこの値をクローラーが取得するかを指定します。
CSSセレクターについて、詳しくは下記のサイトを参照してください。
CSS セレクター - MDN Web Docs
動作するコード
PythonとBeautifulSoupを使って取得します。
お題は日本経済新聞の日経平均株価を取得します。
# coding: UTF-8
import urllib2
from bs4 import BeautifulSoup
# アクセスするURL
url = "https://www.nikkei.com/markets/kabu/"
# URLにアクセスする 戻り値にはアクセスした結果やHTMLなどが入ったinstanceが帰ってきます
instance = urllib2.urlopen(url)
# instanceからHTMLを取り出して、BeautifulSoupで扱えるようにパースします
soup = BeautifulSoup(instance, "html.parser")
# CSSセレクターを使って指定した場所のtextを表示します
print soup.select_one("#CONTENTS_MARROW > div.mk-top_stock_average.cmn-clearfix > div.cmn-clearfix > div.mkc-guidepost > div.mkc-prices > span.mkc-stock_prices").text
ね?簡単でしょ?
といく人はまずいないでしょう。
このコードで値を取得する場所を指定するためのCSSセレクターは
# CONTENTS_MARROW > div.mk-top_stock_average.cmn-clearfix > div.cmn-clearfix > div.mkc-guidepost > div.mkc-prices > span.mkc-stock_prices
とバカでかいです。
これをいちいち書いていたらサクッとどころの話ではありません。
でも大丈夫!......そう、「Google Chrome」ならね
Google Chromeには簡単にCSSセレクターを自動的に生成する方法があります。
※追記
Google Chrome以外でも大体のブラウザで出来ます。
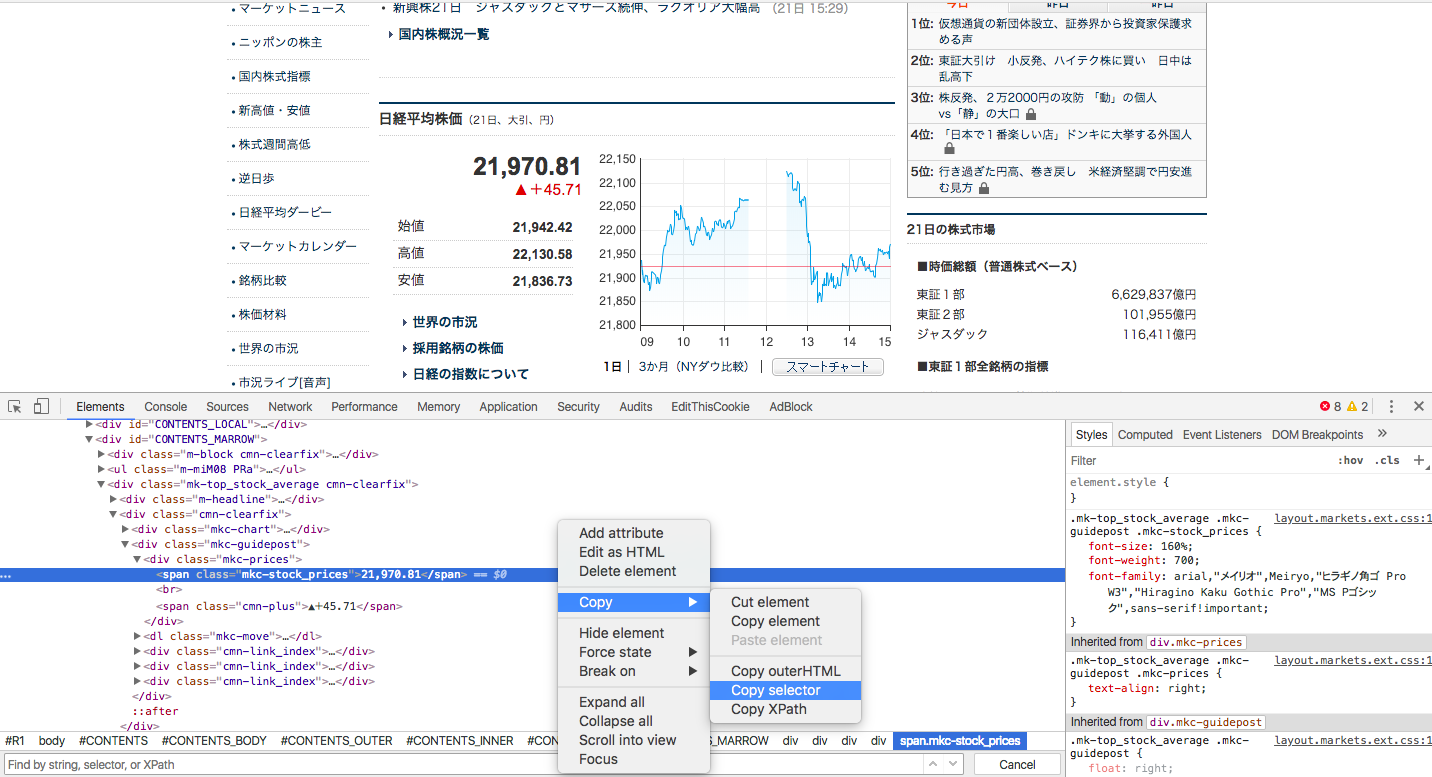
画面を右クリックして検証をクリックすると開発者ツール?が出てきますので、クローラーに取得させたい値が存在する要素を「右クリック→Copy→Copy selector」とするとクリップボードにGoogle Chromeが自動的に生成したCSSセレクターがコピーされています。
後はselect_one関数の引数にぶち込むだけでおけおけおっけー!
ね?簡単でしょ?
このCSSセレクターをマスターすれば大体どんな場所に取得したい値が存在しようとも取得できます。
Google Chromeの生成するCSSセレクターで出来ない場合(動的に変化する場合)
Google Chromeが自動生成するCSSセレクターでは正しく指定が出来ない場合があるんです。
例えば下記のHTMLだと最初はクロール出来ても、次回からはクロール出来ない可能性が高いです。
<html>
<body>
<div id="20171224">
<p>今日の日経平均株価は</p>
<div class="114514">
<p>114514</p>
</div>
<div class="hoge">
<p>円です!</p>
</div>
</div>
</div>
</body>
</html>
見たらわかると思いますが、idとclassの値が動的な雰囲気なのがわかりますよね?
日付と日経平均の値がそのままidやclassになっています。
おそらく明日になるとこう変化するでしょう
<html>
<body>
<div id="20171225">
<p>今日の日経平均株価は</p>
<div class="114194">
<p>114194</p>
</div>
<div class="hoge">
<p>円です!</p>
</div>
</div>
</div>
</body>
</html>
そして、Google Chromeが今日のindex.htmlを読み取って自動生成するCSSセレクターはこうなります。
# 20171224 > div.114514 > p
これでは今日は良くても明日からは確実に値を取得することができないことがわかると思います。
手動でちゃんとbodyからなる相対的なCSSセレクターを書けばそんなことにはならないんですが、いちからCSSセレクターを書くのも面倒ですよね。。。
でも大丈夫!......そう、「Google Chrome」ならね
こういう場合は先ほどもお話した開発者ツールで、現在表示されているHTMLを編集してidやclassを消してしまいばいいんです。
開発者ツールでは読み込んだHTMLを自由に編集することができるので下記のようにidとclassを消します
<html>
<body>
<div>
<p>今日の日経平均株価は</p>
<div>
<p>114194</p>
</div>
<div class="hoge">
<p>円です!</p>
</div>
</div>
</body>
</html>
そして、Google Chromeでもう一度自動生成をすると・・・
body > div:nth-child(1) > div:nth-child(1) > p
というふうに動的に変化する物を除いてCSSセレクターを再生成します。
これなら明日以降でも大丈夫そうですね!
RSS Feedを活用しよう!
例えば、1日で記事が消されてしまう様な不便なWebサイトの記事をWebスクレイピングしてタイトルと内容を記録したい!という時に使える技です。
RSS Feedはサイト自体の情報や発信している記事の見出しや概要を記した物です。
サイト運営者はこのRSS Feedを使って画RSSなどで相互リンクもしますし、Google Search Console(旧Google Web Master Tool)にサイトの情報を送信してインデックスしてもらいます(検索エンジンに自分のサイトを出るようにする作業みたいなものです)。
基本的にインターネット上に公開するのであれば絶対に必要な物です。
RSS Feedのリンクを探す方法は幾つかありますが、下記のサイトを使用すればRSS Feedのリンクがサクッとわかります。
RSSフィード取得・検出ツール - BeRSS.com
今回は例としてYahooの日経トレンディネットのRSS Feedを使います
動作するコード
今回はfeedparserというRSS Feedをパースするライプラリを使います。pip install feedparserでインストール可能です。
ドキュメントはこちら。
https://pythonhosted.org/feedparser/
# coding: UTF-8
import feedparser
import urllib2
from bs4 import BeautifulSoup
# 取得するRSSのURL
RSS_URL = "https://headlines.yahoo.co.jp/rss/trendy-all.xml"
# RSSから取得する
feed = feedparser.parse(RSS_URL)
# 記事の情報をひとつずつ取り出す
for entry in feed.entries:
# タイトルを出力
print entry.title
# URLにアクセスする 戻り値にはアクセスした結果やHTMLなどが入ったinstanceが帰ってきます
instance = urllib2.urlopen(url)
# instanceからHTMLを取り出して、BeautifulSoupで扱えるようにパースします
soup = BeautifulSoup(instance, "html.parser")
# 例としてタイトル要素のみを出力する
print soup.title
あとはBeautifulSoupを使って記録したい物を記録すればOKです。
今回は例としてBeautifulSoupからはタイトル要素を摘出しています。
結果としては下記になります
高級コンパクトデジタルカメラはキヤノンとソニーの二強対決!?(日経トレンディネット)
<title>高級コンパクトデジタルカメラはキヤノンとソニーの二強対決!? (日経トレンディネット) - Yahoo!ニュース</title>
カプコン 辻本Pに聞く 新作『モンハンワールド』は何がすごい?(日経トレンディネット)
<title>カプコン 辻本Pに聞く 新作『モンハンワールド』は何がすごい? (日経トレンディネット) - Yahoo!ニュース</title>
iPad用キーボード探しの旅:Bluetooth接続の「KEYS-TO-GO」を試す!(日経トレンディネット)
<title>iPad用キーボード探しの旅:Bluetooth接続の「KEYS-TO-GO」を試す! (日経トレンディネット) - Yahoo!ニュース</title>
以下略...
JavaScriptによる描画に対応する
例えば、React.jsを使ったウェブサイトだとページにアクセスしてから必要な情報が描画される場合があります。
よくわからない人は1度下記のhtmlを保存してブラウザで表示してみてください。
今日の日経平均株価は114514円ですと表示されます。
<html>
<head>
<script src="http://cdnjs.cloudflare.com/ajax/libs/react/0.11.2/react.js"></script>
<script src="http://cdnjs.cloudflare.com/ajax/libs/react/0.11.2/JSXTransformer.js"></script>
</head>
<body>
<div>
<p>今日の日経平均株価は</p>
<div id="heikin"></div>
<script type="text/jsx">
/** @jsx React.DOM */
React.renderComponent(
<p>114514</p>,
document.getElementById('heikin')
);
</script>
<p>円です!</p>
</div>
</body>
</html>
<html>
<head>
<script src="http://cdnjs.cloudflare.com/ajax/libs/react/0.11.2/react.js"></script>
<script src="http://cdnjs.cloudflare.com/ajax/libs/react/0.11.2/JSXTransformer.js"></script>
</head>
<body>
<div>
<p>今日の日経平均株価は</p>
<div id="heikin"><p data-reactid=".0">114514</p></div>
<script type="text/jsx">
/** @jsx React.DOM */
React.renderComponent(
<p>114514</p>,
document.getElementById('heikin')
);
</script>
<p>円です!</p>
</div>
</body></html>
JavaScriptが実行されて<div id="heikin"><p data-reactid=".0">114514</p></div>と変化し、114514円と日経平均株価が表示されてますね。
では、Webスクレイピングしてみましょう
# coding: UTF-8
import urllib2
from bs4 import BeautifulSoup
# htmlオブジェクトが帰って来る
html = urllib2.urlopen("file:///Users/admin/Desktop/index.html")
# htmlオブジェクトをBeautifulSoupで扱う
soup = BeautifulSoup(html, "html.parser")
# 平均の値を取得する
print soup.select_one("#heikin")
<div id="heikin"></div>
あれれ・・・
JavaScriptはブラウザ側で動作するため、直接HTMLファイルをダウンロードするPythonではJavaScriptが実行されずに日経平均株価が表示されません。
でも大丈夫!
......
そう、「Google Chrome」ならね
ブラウザで正しく描画できるならブラウザを使ってWebスクレイピングすればいいんです。
具体的に何をするのかと言うと、WebブラウザをPythonを使って操作してWebブラウザでJavaScriptを実行させた後にその実行されたHTMLを取得します。
今回ブラウザをPythonで操作するためにSeleniumというライブラリを使います。
もともとSeleniumとは、Webブラウザを使ってWebアプリケーションをテストするツールですが、こういうことにも使えます。
操作対象のブラウザは一番メジャーなPhantomJSを使おうかと思いましたが、SeleniumがPhantomJSのサポートを終了するみたいなのでGoogle ChromeのHeadlessモードでやってみたいと思います。
Headlessモードとはバックグラウドで動くモードで、実際には普通のブラウザとして動いていますがデスクトップには表示されません。
Seleniumのドキュメントはこちら
http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.chrome.webdriver
インストールはpip install seleniumで可能です
動作するコード
# coding: UTF-8
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# ブラウザのオプションを格納する変数をもらってきます。
options = Options()
# Headlessモードを有効にする(コメントアウトするとブラウザが実際に立ち上がります)
options.set_headless(True)
# ブラウザを起動する
driver = webdriver.Chrome(chrome_options=options)
# ブラウザでアクセスする
driver.get("file:///Users/admin/Desktop/index.html")
# HTMLを文字コードをUTF-8に変換してから取得します。
html = driver.page_source.encode('utf-8')
# BeautifulSoupで扱えるようにパースします
soup = BeautifulSoup(html, "html.parser")
# idがheikinの要素を表示
print soup.select_one("#heikin")
<div id="heikin"><p data-reactid=".0">114514</p></div>
正しく動きましたね。これでJavaScriptにも対応しました。
これでも対応出来ない場合はJavaScriptが最後まで実行される前にHTMLを取得している可能性があるので、取り敢えずSleepを入れたりドキュメントにあるオプションを使えば大体どうにかなります。
結論
Google Chrome最強
とはいえ、コメントにあるようにSafariでもOperaでもブラウザだったら基本的にCSSセレクターのコピーは可能です。
わかりにくいところや、解説不足、誤字脱字は編集リクエスト、コメントにてお願いします。
このサイトのWebスクレイピングってどうすんの!ってのも募集します。
※明らかに私的利益を確保するためのコメントは今後無視します。どうしても教えてほしいのであれば私のメールに予算と詳細を書いて送ってください。
ありがとうございました。
こちらもどうぞ
Python Webスクレイピング 実践入門
【毎秒1万リクエスト!?】Go言語で始める爆速Webスクレイピング【Golang】
【初心者向け】Re:ゼロから始める遺伝的アルゴリズム【人工知能】
追記コーナー
CAPTCHAについて
ハテブのコメントにCAPTCHAは無理だろ?論破!と書かれていました。
そもそも論としてCAPTCHAを導入しているサイトをWebスクレイピングすること自体おかしな話です。
Webスクレイピング等BOTに色々して欲しくないからCAPTCHAを入れているのでそれを突破しようなんて倫理的どうなんですかね?
胸に手を当て少し考えてみましょう
とはいえ回避する方法は無いわけでも無いです。
QiitaのCAPTCHAに関しては回避して無限にアカウントを生成することが可能だったり(´▽`)
方法はQiitaの人が修正したら教えます(゚▽^*)
追記・セキュキャンΔでQiitaの中の人と出会ったので教えちゃいました(゚▽^*)
追記・ちゃんと修正されました
値スクレイピングはできるんだが、その先の画像がダウンロードできないサイトがあるんですよー!なーにー!やっちまったなぁ!…というのはホントでエキスパートに相談したいんだけど。について
おそらくそれは、画像URLに直リンクで接続しているからダウンロードできないのだと思います。
htaccessとかnginxとかの設定で自分のドメインからの接続以外は全て拒否する設定にしてあるんだと思います。
ここらへんにそれっぽいことが書いてあります。
直リンクを防ぐには?…禁止と言っても無駄(2ページ目) - AllAbout デジタル
メモ/nginxで直リン禁止設定。valid_refererでリファラを検証。 - えんぞーどっとねっと
保存する方法としてはSeleniumを使って表示された画像を直接保存(ブラウザに表示された画像は既にブラウザにダウンロード済み)すればいいと思います。
とはいえ、PythonのSeleniumには見落としているかもしれませんが、それっぽい奴は見つけられなかったです(スクリーンショットでごり押しはできるかもしれませんが)。
手っ取り早く実装するならUWSCと言うマクロ言語を使えば簡単に保存できます。
※追記
こういう場合もあるみたいです。
閲覧に s3 cookie が必要な画像でも、selenium で http client に cookie コピーしてやって、画像 downlaod できるよ
画像に入った値に関して
例えば画像にメールアドレスが記入されている場合でもこんなAPIを使えば案外読めたりします。
まあ、スクレイピングされたくないから画像にしていると思うので辞めたほうがいいです。それこそ、CAPTCHAの話にも繋がります。
光学式文字認識(OCR) - Google Cloud Vision API
取得だけなら簡単だけどidがとことん無かったりnth-childだと壊れやすいんだよなあ。Chromeなら今ならpuppeteer が楽チンでオススメ。
確かにそういう場合もあります。
私はそういう場合では別のコメントにもありますが、サイトの特性を掴んでスクレイピングします。
例えばですが、広告とかの画像は除いて記事の中にある画像だけを抜き取りたい時などはURLを着目して
記事中の画像のURLだと/post-image1.jpgになるけど広告の画像は/ad-image1.jpgになるから、全てのimg要素を取得し、正規表現で/post-image*.jpgのようにすれば取得できるなみたいな感じです。
壊れやすいサイトの場合はCSSセレクターでサクッとまではいきませんがこういう風にすれば出来ますね。
スクレイピングの記事見るたびに思う。スクレイピングそのものはあまり問題じゃなくて、大変なのは、クローラの自動化とその周辺、各種エラー処理と、それらが継続運用可能なシステムの構築だと・・・
実務でWebスクレイピングしたことないんでよく知りませんが(そもそも働いたこと自体そんな無い())、AWS Lambdaとか使えば楽に管理出来ますよ。小規模であれば無料期間内で収まりますし、実行するペースもWeb上で簡単に指定できます。
実際に使っているので割とおすすめです。あと、PythonだけでなくGolangも使えるので神ですね。
aws lambdaてchrome動かすのは大変だよ。ec2の無料枠(t2.microとAmazon Linux2)で動くので、こっちがオススメ
それはそうです。当たり前くらいのレベルです。
Seleniumに関してはec2などのVPSがなければ言葉をお借りして大変です。(やろうとも思わない)
しかし、Seleniumを使わないWebスクレイピングに関しては凄い良いよって話です。
運用・保守について
他のシステムに依存するシステムは相手の変更に対応し続けないといけなくなる。そして一時的な利用なら手作業の方が良かったりもするので悩ましい
確かにそうですね。自分はmakeコマンド1つでlambdaにデプロイできる環境を作ってます。
また、エラーが発生して正常にWebスクレイピング出来ない場合は通知する様にもしてます。
ここらへんはAWSさんの力を借りれば出来ますね。
スクレイピングに対策する記事が読みたい
ここら辺はいたちごっこな感じがします。
しかし、今回紹介したテクニックを対策すれば一定のWebスレイピングは弾けるかもしれませんね。
あと、Flashとか使えば難易度は一気に上がったりすると思います。
flash使ってるサイトってどうやるんすかね
その昔、画像解析してゴリ押しでやってました。
大衆が見てもわかる様に説明するとグググーっと長くなるのでUWSCを使ってやっていたで勘弁してください。
UWSCを使ったことがある人であればたぶんこうやるんだなってわかるはずです。
やはりUWSCですか。某HITAC○Iの勤怠とかIE以外弾くんでスクレイピング出来ない。毎日入力面倒いんでUWSC系で自動化しているが、UWSC系だと動作中にPC弄れなくてそれが新たなストレスになるという・・。
UWSCには実際にカーソルを動かすのではなく情報だけ送信するモードもありますが、やはり実際にカーソルを動かすのと比べると精度が違いますね。もちろんうまくいく例もあると思いますが、flash系だと使えない場合が多いですね。
IE以外弾くんはUserAgentを変えたりしたらいけそうな気がしますけどね。
とはいえ、某ブラウザスマホゲームではPCからの接続を拒否するようにUserAgentだけでなくそれ以外の要素も見ているみたいです。
このようなアプリがあるのでWiresharkとかで覗いてみたりしたらいかがでしょうか?
ソーシャルゲームビューア - Chrome ウェブストア
このような、日にちを指定してから表示させるタイプはどのようにスクレイピングすればいいのでしょうか?
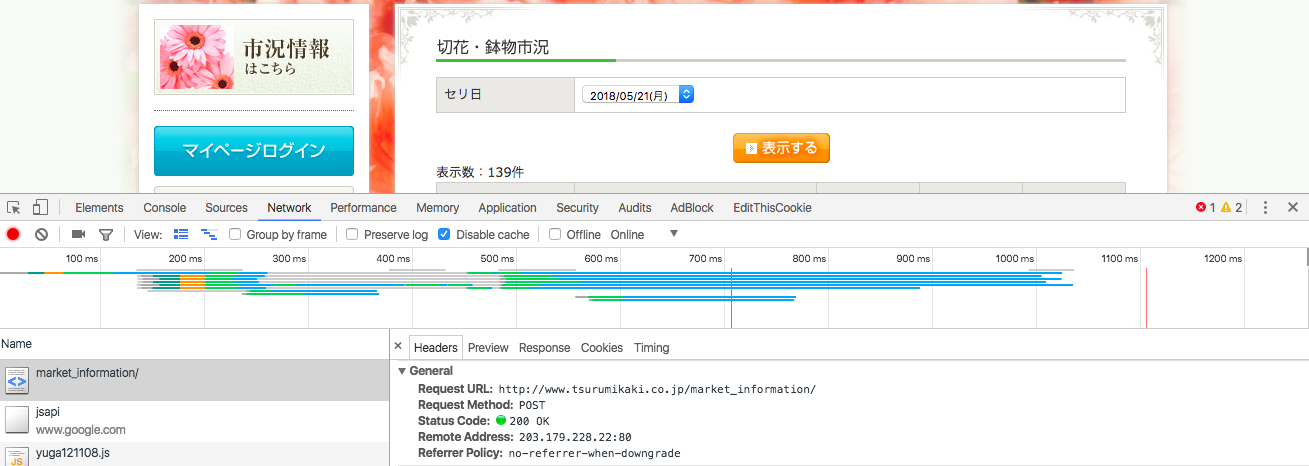
こちらのサイトでは日にちをPOSTリクエストしてますので、同様にPOSTリクエストを送れば良いです。
ChromeのデベロッパーツールのNetworkタブから確認することができます。
↓POST通信を確認
↓POSTで送る値
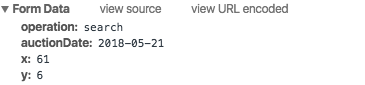
golangであればhttp.FormPost()で取れます。
このサイトの数値をスクレイピングすることができません。コードの見本を見せてください。お願いします。
https://www.basketball-reference.com/players/j/jamesle01.html
数値が多すぎて具体的に何の値を取得すれば良いのかわかりません。。。。
このサイトのスワップポイントをスクレイピングしたいのですが、iframeで書かれていて、どうにも上手いやり方が思いつかないです。ご教授お願いしたいです。
iframeのコツは直接参照すればいいです。
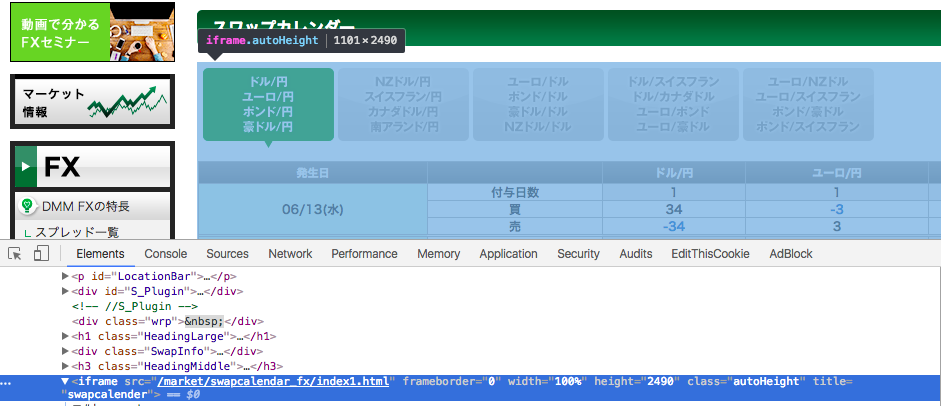
srcは/market/swapcalendar_fx/index1.htmlとなってるので、https://fx.dmm.com/market/swapcalendar_fx/index1.html がiframeのURLです。
普通にブラウザで表示されました。あとは簡単ですね。
このサイトのオッズをスクレイピングで取得したいのですがうまくいきません。コードとともに教えてください。
具体的にどこの部分でしょうか・・・スクリーンショット等で教えていただけると助かります。
マウスオーバーした時に表示される時刻情報を取得することは可能でしょうか??
不可能ではないですが、APIが公開されているみたいなのでこっちを使った法が楽だと思います
https://jp.tradingview.com/HTML5-stock-forex-bitcoin-charting-library/
すみません、下記サイトのkairiの数値をスクレイピングする方法なんですが、このサイトに記載されているやり方で稼働させようとしてもうまくいきませんでした。
どのようにしたら良いでしょうか(´・ω・`)
これはJavaScriptが動いてますね。
bitflyerにwebsocketで繋がって数ミリ秒毎に更新しているので記事に書かれているjavascript対応コードを使えば取得できます。
もし正常に取得できない場合はブラウザやwebdriverあたりに問題があります。
# coding: UTF-8
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# ブラウザのオプションを格納する変数をもらってきます。
options = Options()
# Headlessモードを有効にする(コメントアウトするとブラウザが実際に立ち上がります)
options.set_headless(True)
# ブラウザを起動する
driver = webdriver.Chrome(chrome_options=options)
# ブラウザでアクセスする
driver.get("https://techrepo.net/contents/sfd.html")
# HTMLを文字コードをUTF-8に変換してから取得します。
html = driver.page_source.encode('utf-8')
# BeautifulSoupで扱えるようにパースします
soup = BeautifulSoup(html, "html.parser")
# idがheikinの要素を表示
print soup.select_one("#kairi").text
seleniumを用いてとあるサイトの、seleniumを用いてとあるサイトの、<input type="hidden" value="xx" id="yy" name="zz">これのvalueを取得しようとしたのですが、出力が <input id="yy" name="zz" type="hidden" value=""/> となってしまい値が出てきませんでした。取得する方法があれば教えていただけると嬉しいです。
最初のコメントにURLがあったので、そのサイトを覗きましたがこれはおそらくログイン状態でないと取得できない値です。
一度同じサイトを別のブラウザで確認してみてください。
自分が確認したところログインも登録もしていないので<input id="yy" name="zz" type="hidden" value=""/>と記入されてました。
またはログイン状態以外の特定の条件下でのみ目的に値が表示される思うので、それをcode上に再現してください。