1.すぐに利用したい方へ(as soon as)
「ゼロから作るDeep Learning2自然言語処理編」斎藤 康毅 著

https://www.oreilly.co.jp/books/9784873118369/
<この項は書きかけです。順次追記します。>
docker
dockerを導入し、Windows, Macではdockerを起動しておいてください。
Windowsでは、BiosでIntel Virtualizationをenableにしないとdockerが起動しない場合があります。
また、セキュリティの警告などが出ることがあります。
docker pull and run
$ docker pull kaizenjapan/anaconda-deep
$ docker run -it kaizenjapan/anaconda-deep /bin/bash
ファイルを共有したい場合(Macintosh)
$ docker run -v /Users/{user name}/Documents/workspace:/home/data -it kaizenjapan/anaconda-deep /bin/bash
ファイルを共有したい場合(Windows)
$ docker run -v /c/Users/{user name}/Documents/workspace:/home/data -it kaizenjapan/anaconda-deep /bin/bash
以下のshell sessionでは
(base) root@f19e2f06eabb:/#は入力促進記号(comman prompt)です。実際には数字の部分が違うかもしれません。この行の#の右側を入力してください。
それ以外の行は出力です。出力にエラー、違いがあれば、コメント欄などでご連絡くださると幸いです。
それぞれの章のフォルダに移動します。
dockerの中と、dockerを起動したOSのシェルとが表示が似ている場合には、どちらで捜査しているか間違えることがあります。dockerの入力促進記号(comman prompt)に気をつけてください。
ファイル共有または複写
dockerとdockerを起動したOSでは、ファイル共有をするか、ファイル複写するかして、生成したファイルをブラウザ等表示させてください。参考文献欄にやり方のURLを記載しています。
複写の場合は、dockerを起動したOS側で次のようにしました。f19e2f06eabbはお使いのdockerの番号で置き換えてください。複写したファイルをブラウザで表示し内容確認しました。
$ docker cp f19e2f06eabb:/deep-learning-from-scratch-2/ch01/train_c1.png .
$ docker cp f19e2f06eabb:/deep-learning-from-scratch-2/ch01/train_c2.png .
$ docker cp f19e2f06eabb:/deep-learning-from-scratch-2/ch01/spiral.png .
$ docker cp f19e2f06eabb:/deep-learning-from-scratch-2/ch02/small.png .
$ docker cp f19e2f06eabb:/deep-learning-from-scratch-2/ch03/trainer.png .
第1章
(base) root@f19e2f06eabb:/# ls
bin boot deep-learning-from-scratch-2 dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
(base) root@f19e2f06eabb:/# cd deep-learning-from-scratch-2/
(base) root@f19e2f06eabb:/deep-learning-from-scratch-2# ls
LICENSE.md README.md ch01 ch02 ch03 ch04 ch05 ch06 ch07 ch08 common dataset
(base) root@f19e2f06eabb:/deep-learning-from-scratch-2# cd ch01
(base) root@f19e2f06eabb:/deep-learning-from-scratch-2/ch01# ls
forward_net.py show_spiral_dataset.py train.py train_custom_loop.py two_layer_net.py
forward_net.py
(base) root@f19e2f06eabb:/deep-learning-from-scratch-2/ch01# python forward_net.py
[[-3.75987607 2.88184767 0.70790565]
[-4.00541319 2.45471769 1.69667098]
[-3.86374037 2.09590372 2.05944503]
[-3.2456851 2.20352841 0.84411808]
[-3.54065719 2.17029004 1.46937473]
[-4.00934517 2.25979763 1.99581236]
[-3.9925953 2.64020227 1.42864389]
[-3.64107153 2.73896715 0.71204338]
[-3.96827961 2.6421512 1.40249969]
[-3.77412466 3.0798037 0.35972095]]
two_layer_net.py
(base) root@f19e2f06eabb:/deep-learning-from-scratch-2/ch01# python two_layer_net.py
show_spiral_dataset.py
# python show_spiral_dataset.py
x (300, 2)
t (300, 3)
編集したpythonファイル
- PNGファイル出力のおまじない:2行追記
import matplotlib as mpl
mpl.use('Agg')
- ファイル出力操作:2行追記、1行注釈化
fig = plt.figure()
#plt.show()
fig.savefig('spiral.png')
結果はspiral.pngファイルとして出力
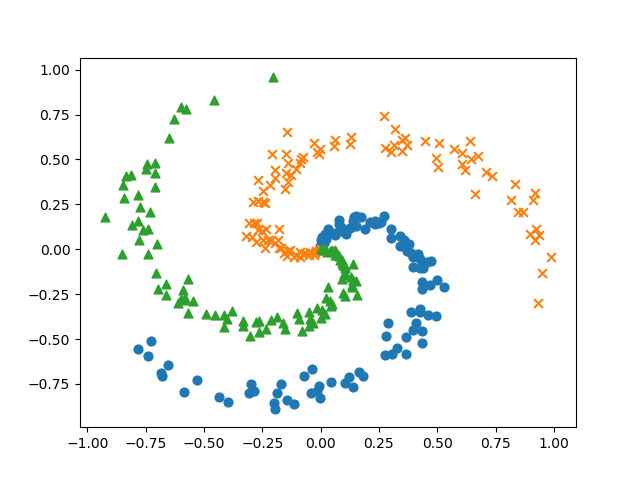
# coding: utf-8
import sys
sys.path.append('..') # 親ディレクトリのファイルをインポートするための設定
from dataset import spiral
import matplotlib as mpl
mpl.use('Agg')
import matplotlib.pyplot as plt
fig = plt.figure()
x, t = spiral.load_data()
print('x', x.shape) # (300, 2)
print('t', t.shape) # (300, 3)
# データ点のプロット
N = 100
CLS_NUM = 3
markers = ['o', 'x', '^']
for i in range(CLS_NUM):
plt.scatter(x[i*N:(i+1)*N, 0], x[i*N:(i+1)*N, 1], s=40, marker=markers[i])
#plt.show()
fig.savefig('spiral.png')
##train_custom_loop.py
(base) root@f19e2f06eabb:/deep-learning-from-scratch-2/ch01# python train_custom_loop.py
| epoch 1 | iter 10 / 10 | loss 1.13
| epoch 2 | iter 10 / 10 | loss 1.13
| epoch 3 | iter 10 / 10 | loss 1.12
| epoch 4 | iter 10 / 10 | loss 1.12
| epoch 5 | iter 10 / 10 | loss 1.11
| epoch 6 | iter 10 / 10 | loss 1.14
| epoch 7 | iter 10 / 10 | loss 1.16
| epoch 8 | iter 10 / 10 | loss 1.11
| epoch 9 | iter 10 / 10 | loss 1.12
(中略)
| epoch 299 | iter 10 / 10 | loss 0.11
| epoch 300 | iter 10 / 10 | loss 0.11
(base) root@f19e2f06eabb:/deep-learning-from-scratch-2/ch01# ls
__pycache__ forward_net.py show_spiral_dataset.py train.py train_c1.png train_c2.png train_custom_loop.py two_layer_net.py
編集したpythonファイル
- PNGファイル出力のおまじない
import matplotlib as mpl
mpl.use('Agg') - ファイル出力操作(1)
fig = plt.figure()
#plt.show()
fig.savefig('train_c1.png')
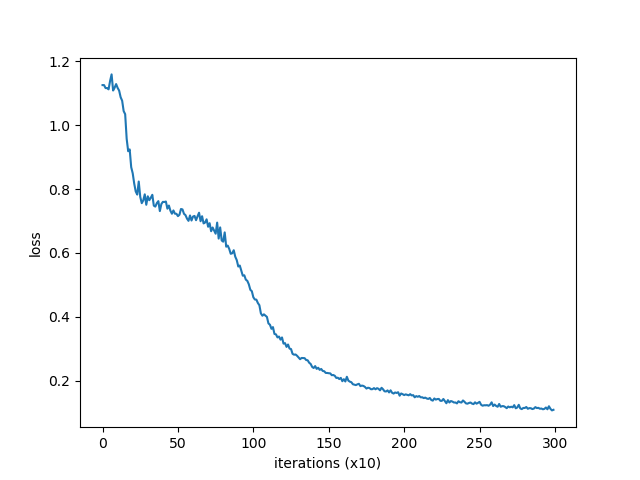
結果をtrain_c1.pngとして出力
- ファイル出力操作(2)
fig2 = plt.figure()
#plt.show()
fig2.savefig('train_c2.png')
結果をtrain_c2.pngとして出力

# coding: utf-8
import sys
sys.path.append('..') # 親ディレクトリのファイルをインポートするための設定
import numpy as np
from common.optimizer import SGD
from dataset import spiral
import matplotlib as mpl
mpl.use('Agg')
import matplotlib.pyplot as plt
from two_layer_net import TwoLayerNet
# ハイパーパラメータの設定
max_epoch = 300
batch_size = 30
hidden_size = 10
learning_rate = 1.0
x, t = spiral.load_data()
model = TwoLayerNet(input_size=2, hidden_size=hidden_size, output_size=3)
optimizer = SGD(lr=learning_rate)
# 学習で使用する変数
data_size = len(x)
max_iters = data_size // batch_size
total_loss = 0
loss_count = 0
loss_list = []
for epoch in range(max_epoch):
# データのシャッフル
idx = np.random.permutation(data_size)
x = x[idx]
t = t[idx]
for iters in range(max_iters):
batch_x = x[iters*batch_size:(iters+1)*batch_size]
batch_t = t[iters*batch_size:(iters+1)*batch_size]
# 勾配を求め、パラメータを更新
loss = model.forward(batch_x, batch_t)
model.backward()
optimizer.update(model.params, model.grads)
total_loss += loss
loss_count += 1
# 定期的に学習経過を出力
if (iters+1) % 10 == 0:
avg_loss = total_loss / loss_count
print('| epoch %d | iter %d / %d | loss %.2f'
% (epoch + 1, iters + 1, max_iters, avg_loss))
loss_list.append(avg_loss)
total_loss, loss_count = 0, 0
# 学習結果のプロット
fig = plt.figure()
plt.plot(np.arange(len(loss_list)), loss_list, label='train')
plt.xlabel('iterations (x10)')
plt.ylabel('loss')
#plt.show()
fig.savefig('train_c1.png')
# 境界領域のプロット
fig2 = plt.figure()
h = 0.001
x_min, x_max = x[:, 0].min() - .1, x[:, 0].max() + .1
y_min, y_max = x[:, 1].min() - .1, x[:, 1].max() + .1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
X = np.c_[xx.ravel(), yy.ravel()]
score = model.predict(X)
predict_cls = np.argmax(score, axis=1)
Z = predict_cls.reshape(xx.shape)
plt.contourf(xx, yy, Z)
plt.axis('off')
# データ点のプロット
x, t = spiral.load_data()
N = 100
CLS_NUM = 3
markers = ['o', 'x', '^']
for i in range(CLS_NUM):
plt.scatter(x[i*N:(i+1)*N, 0], x[i*N:(i+1)*N, 1], s=40, marker=markers[i])
#plt.show()
fig2.savefig('train_c2.png')
ch03/train.py
(base) root@f19e2f06eabb:/deep-learning-from-scratch-2/ch03# python train.py
| epoch 1 | iter 1 / 2 | time 0[s] | loss 1.95
| epoch 2 | iter 1 / 2 | time 0[s] | loss 1.95
| epoch 3 | iter 1 / 2 | time 0[s] | loss 1.95
| epoch 4 | iter 1 / 2 | time 0[s] | loss 1.95
| epoch 5 | iter 1 / 2 | time 0[s] | loss 1.95
| epoch 6 | iter 1 / 2 | time 0[s] | loss 1.95
| epoch 7 | iter 1 / 2 | time 0[s] | loss 1.95
| epoch 8 | iter 1 / 2 | time 0[s] | loss 1.94
| epoch 9 | iter 1 / 2 | time 0[s] | loss 1.94
| epoch 10 | iter 1 / 2 | time 0[s] | loss 1.94
(中略)
| epoch 991 | iter 1 / 2 | time 0[s] | loss 0.94
| epoch 992 | iter 1 / 2 | time 0[s] | loss 0.33
| epoch 993 | iter 1 / 2 | time 0[s] | loss 0.96
| epoch 994 | iter 1 / 2 | time 0[s] | loss 0.61
| epoch 995 | iter 1 / 2 | time 0[s] | loss 0.49
| epoch 996 | iter 1 / 2 | time 0[s] | loss 0.48
| epoch 997 | iter 1 / 2 | time 0[s] | loss 0.92
| epoch 998 | iter 1 / 2 | time 0[s] | loss 0.65
| epoch 999 | iter 1 / 2 | time 0[s] | loss 0.63
| epoch 1000 | iter 1 / 2 | time 0[s] | loss 0.63
you [-0.85186464 0.8873791 0.9535413 1.759501 -0.86705554]
say [ 1.1053841 -1.0883542 -1.052522 1.2985277 1.1104386]
goodbye [-1.0607617 1.0740693 1.0050163 -0.34769127 -1.0925001 ]
and [ 1.0371324 -0.8034061 -1.2292709 1.336546 0.9448045]
i [-1.0493721 1.0505022 1.0150882 -0.34115607 -1.1023822 ]
hello [-0.86085826 0.88232267 0.95443195 1.7587373 -0.84508234]
. [ 0.80664647 -1.1676135 -0.24818163 0.68286717 0.9483339 ]
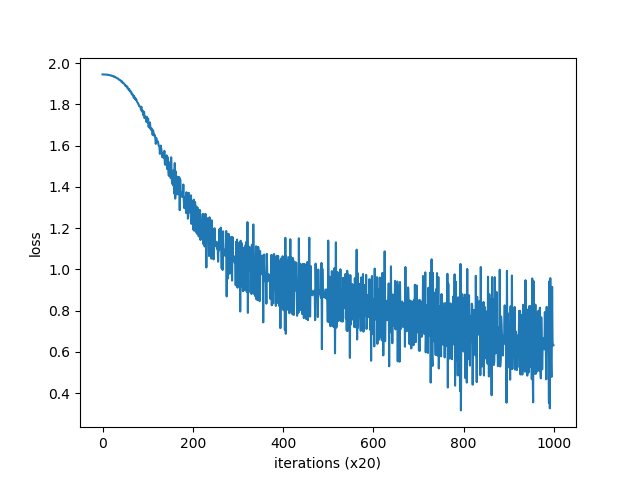
編集するのはこのファイルではなく、common/trainer.py
common/trainer.py
ここまでと同様の処理。
2箇所def plotがあるのでそれぞれに処理を追記。
train.pyは一方しか呼んでいないみたい。
第二章
count_method_big.py
(base) root@f19e2f06eabb:/deep-learning-from-scratch-2/ch02# python count_method_big.py
counting co-occurrence ...
calculating PPMI ...
1.0% done
2.0% done
3.0% done
4.0% done
5.0% done
6.0% done
7.0% done
8.0% done
9.0% done
10.0% done
(中略)
91.0% done
92.0% done
93.0% done
94.0% done
95.0% done
96.0% done
97.0% done
98.0% done
99.0% done
100.0% done
calculating SVD ...
[query] you
i: 0.6666895151138306
anybody: 0.5807172060012817
we: 0.5673905611038208
else: 0.5443344116210938
do: 0.5044347047805786
[query] year
quarter: 0.6834844350814819
month: 0.6641101241111755
earlier: 0.6461527347564697
last: 0.625231146812439
next: 0.6001166105270386
[query] car
luxury: 0.6281501054763794
auto: 0.5573192834854126
vehicle: 0.5489078760147095
truck: 0.5140106081962585
corsica: 0.5129688382148743
[query] toyota
motor: 0.702085018157959
motors: 0.6883779764175415
nissan: 0.6658307909965515
honda: 0.625495433807373
lexus: 0.5883824825286865
most_similar.py
(base) root@f19e2f06eabb:/deep-learning-from-scratch-2/ch02# python most_similar.py
[query] you
goodbye: 0.7071067691154799
i: 0.7071067691154799
hello: 0.7071067691154799
say: 0.0
and: 0.0
ppmi.py
(base) root@f19e2f06eabb:/deep-learning-from-scratch-2/ch02# python ppmi.py
covariance matrix
[[0 1 0 0 0 0 0]
[1 0 1 0 1 1 0]
[0 1 0 1 0 0 0]
[0 0 1 0 1 0 0]
[0 1 0 1 0 0 0]
[0 1 0 0 0 0 1]
[0 0 0 0 0 1 0]]
--------------------------------------------------
PPMI
[[0. 1.807 0. 0. 0. 0. 0. ]
[1.807 0. 0.807 0. 0.807 0.807 0. ]
[0. 0.807 0. 1.807 0. 0. 0. ]
[0. 0. 1.807 0. 1.807 0. 0. ]
[0. 0.807 0. 1.807 0. 0. 0. ]
[0. 0.807 0. 0. 0. 0. 2.807]
[0. 0. 0. 0. 0. 2.807 0. ]]
similarity.py
(base) root@f19e2f06eabb:/deep-learning-from-scratch-2/ch02# python similarity.py
0.7071067691154799
show_ptb.py
(base) root@f19e2f06eabb:/deep-learning-from-scratch-2/ch02# python show_ptb.py
corpus size: 929589
corpus[:30]: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
24 25 26 27 28 29]
id_to_word[0]: aer
id_to_word[1]: banknote
id_to_word[2]: berlitz
word_to_id['car']: 3856
word_to_id['happy']: 4428
word_to_id['lexus']: 7426
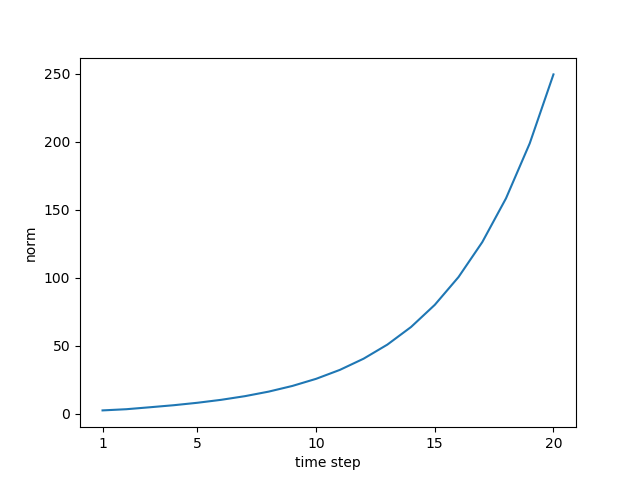
chap06
# coding: utf-8
import numpy as np
#import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.use('Agg')
import matplotlib.pyplot as plt
N = 2 # ミニバッチサイズ
H = 3 # 隠れ状態ベクトルの次元数
T = 20 # 時系列データの長さ
dh = np.ones((N, H))
np.random.seed(3)
Wh = np.random.randn(H, H)
#Wh = np.random.randn(H, H) * 0.5
fig=plt.figure()
norm_list = []
for t in range(T):
dh = np.dot(dh, Wh.T)
norm = np.sqrt(np.sum(dh**2)) / N
norm_list.append(norm)
print(norm_list)
# グラフの描画
#fig=plt.figure()
plt.plot(np.arange(len(norm_list)), norm_list)
plt.xticks([0, 4, 9, 14, 19], [1, 5, 10, 15, 20])
plt.xlabel('time step')
plt.ylabel('norm')
#fig=plt.figure()
#plt.show()
fig.savefig('rnn_gra.png')
#Wh = np.random.randn(H, H)
Wh = np.random.randn(H, H) * 0.5
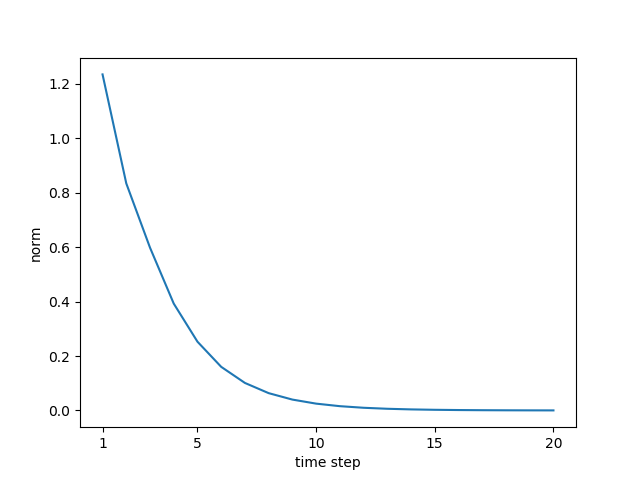
# python clip_grads.py
before: [7.28449187 5.75706778 9.10440563 6.08134942 8.62414161 0.99632405
3.07822728 7.58228078 9.15052157]
after: [1.43684997 1.13556894 1.79582395 1.19953278 1.70109293 0.19652272
0.60717355 1.49558818 1.80492022]
2. dockerを自力で構築する方へ
ここから下は、上記のpullしていただいたdockerをどういう方針で、どういう手順で作ったかを記録します。
上記のdockerを利用する上での参考資料です。本の続きを実行する上では必要ありません。
自力でdocker/anacondaを構築する場合の手順になります。
dockerfileを作る方法ではありません。ごめんなさい。
docker
ubuntu, debianなどのLinuxを、linux, windows, mac osから共通に利用できる仕組み。
利用するOSの設定を変更せずに利用できるのがよい。
同じ仕様で、大量の人が利用することができる。
ソフトウェアの開発元が公式に対応しているものと、利用者が便利に仕立てたものの両方が利用可能である。今回は、公式に配布しているものを、自分で仕立てて、他の人にも利用できるようにする。
python
DeepLearningの実習をPhthonで行って来た。
pythonを使う理由は、多くの機械学習の仕組みがpythonで利用できることと、Rなどの統計解析の仕組みもpythonから容易に利用できることがある。
###anaconda
pythonには、2と3という版の違いと、配布方法の違いなどがある。
Anacondaでpython3をこの1年半利用してきた。
Anacondaを利用した理由は、統計解析のライブラリと、JupyterNotebookが初めから入っているからである。
docker公式配布
ubuntu, debianなどのOSの公式配布,gcc, anacondaなどの言語の公式配布などがある。
これらを利用し、docker-hubに登録することにより、公式配布の質の確認と、変更権を含む幅広い情報の共有ができる。dockerが公式配布するものではなく、それぞれのソフト提供者の公式配布という意味。
docker pull
docker公式配布の利用は、URLからpullすることで実現する。
docker Anaconda
anacondaが公式配布しているものを利用。
$ docker pull continuumio/anaconda3
Using default tag: latest
latest: Pulling from continuumio/anaconda3
Digest: sha256:e07b9ca98ac1eeb1179dbf0e0bbcebd87701f8654878d6d8ce164d71746964d1
Status: Image is up to date for continuumio/anaconda3:latest
OgawaKiyoshi-no-MacBook-Pro:docker-toppers ogawakiyoshi$ docker run -it continuumio/anaconda3 /bin/bash
apt
(base) root@f19e2f06eabb:/# apt update
(base) root@f19e2f06eabb:/# apt install -y procps vim apt-utils
Deep Learning2
(base) root@f19e2f06eabb:/# git clone https://github.com/oreilly-japan/deep-learning-from-scratch-2.git
Cloning into 'deep-learning-from-scratch-2'...
remote: Enumerating objects: 17, done.
remote: Counting objects: 100% (17/17), done.
remote: Compressing objects: 100% (14/14), done.
remote: Total 320 (delta 4), reused 3 (delta 3), pack-reused 303
Receiving objects: 100% (320/320), 7.51 MiB | 1.93 MiB/s, done.
Resolving deltas: 100% (178/178), done.
pip
(base) root@f19e2f06eabb:/deep-learning-from-scratch-2/ch01# pip install --upgrade pip
Collecting pip
Downloading https://files.pythonhosted.org/packages/5f/25/e52d3f31441505a5f3af41213346e5b6c221c9e086a166f3703d2ddaf940/pip-18.0-py2.py3-none-any.whl (1.3MB)
100% |████████████████████████████████| 1.3MB 2.0MB/s
distributed 1.21.8 requires msgpack, which is not installed.
Installing collected packages: pip
Found existing installation: pip 10.0.1
Uninstalling pip-10.0.1:
Successfully uninstalled pip-10.0.1
Successfully installed pip-18.0
pyqt5
(base) root@f19e2f06eabb:/deep-learning-from-scratch-2/ch01# pip install pyqt5
Collecting pyqt5
Downloading https://files.pythonhosted.org/packages/3a/c7/4a9bec78c864051051b41b4cc76672ecc232e6dc7dbb91a5f8ff6f20ff64/PyQt5-5.11.2-5.11.1-cp35.cp36.cp37.cp38-abi3-manylinux1_x86_64.whl (117.9MB)
100% |████████████████████████████████| 117.9MB 311kB/s
Collecting PyQt5_sip<4.20,>=4.19.11 (from pyqt5)
Downloading https://files.pythonhosted.org/packages/d7/db/06ad1f62a1f80a5df639c322066f03db381c1a6322c02087e75092427838/PyQt5_sip-4.19.12-cp36-cp36m-manylinux1_x86_64.whl (66kB)
100% |████████████████████████████████| 71kB 30kB/s
distributed 1.21.8 requires msgpack, which is not installed.
Installing collected packages: PyQt5-sip, pyqt5
Successfully installed PyQt5-sip-4.19.12 pyqt5-5.11.2
apt install libgl1-mesa-dev
(base) root@f19e2f06eabb:/deep-learning-from-scratch-2/ch01# apt install -y libgl1-mesa-dev
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
libdrm-amdgpu1 libdrm-dev libdrm-intel1 libdrm-nouveau2 libdrm-radeon1 libdrm2 libgl1-mesa-dri libgl1-mesa-glx libglapi-mesa
libllvm3.9 libpciaccess0 libpthread-stubs0-dev libsensors4 libtxc-dxtn-s2tc libx11-dev libx11-doc libx11-xcb-dev libx11-xcb1
libxau-dev libxcb-dri2-0 libxcb-dri2-0-dev libxcb-dri3-0 libxcb-dri3-dev libxcb-glx0 libxcb-glx0-dev libxcb-present-dev
libxcb-present0 libxcb-randr0 libxcb-randr0-dev libxcb-render0 libxcb-render0-dev libxcb-shape0 libxcb-shape0-dev libxcb-sync-dev
libxcb-sync1 libxcb-xfixes0 libxcb-xfixes0-dev libxcb1-dev libxdamage-dev libxdamage1 libxdmcp-dev libxext-dev libxfixes-dev
libxfixes3 libxshmfence-dev libxshmfence1 libxxf86vm-dev libxxf86vm1 mesa-common-dev x11proto-core-dev x11proto-damage-dev
x11proto-dri2-dev x11proto-fixes-dev x11proto-gl-dev x11proto-input-dev x11proto-kb-dev x11proto-xext-dev x11proto-xf86vidmode-dev
xorg-sgml-doctools xtrans-dev
Suggested packages:
pciutils lm-sensors libxcb-doc libxext-doc
The following NEW packages will be installed:
libdrm-amdgpu1 libdrm-dev libdrm-intel1 libdrm-nouveau2 libdrm-radeon1 libdrm2 libgl1-mesa-dev libgl1-mesa-dri libgl1-mesa-glx
libglapi-mesa libllvm3.9 libpciaccess0 libpthread-stubs0-dev libsensors4 libtxc-dxtn-s2tc libx11-dev libx11-doc libx11-xcb-dev
libx11-xcb1 libxau-dev libxcb-dri2-0 libxcb-dri2-0-dev libxcb-dri3-0 libxcb-dri3-dev libxcb-glx0 libxcb-glx0-dev libxcb-present-dev
libxcb-present0 libxcb-randr0 libxcb-randr0-dev libxcb-render0 libxcb-render0-dev libxcb-shape0 libxcb-shape0-dev libxcb-sync-dev
libxcb-sync1 libxcb-xfixes0 libxcb-xfixes0-dev libxcb1-dev libxdamage-dev libxdamage1 libxdmcp-dev libxext-dev libxfixes-dev
libxfixes3 libxshmfence-dev libxshmfence1 libxxf86vm-dev libxxf86vm1 mesa-common-dev x11proto-core-dev x11proto-damage-dev
x11proto-dri2-dev x11proto-fixes-dev x11proto-gl-dev x11proto-input-dev x11proto-kb-dev x11proto-xext-dev x11proto-xf86vidmode-dev
xorg-sgml-doctools xtrans-dev
0 upgraded, 61 newly installed, 0 to remove and 25 not upgraded.
Need to get 24.4 MB of archives.
After this operation, 193 MB of additional disk space will be used.
Get:1 http://deb.debian.org/debian stretch/main amd64 libdrm2 amd64 2.4.74-1 [36.2 kB]
3.docker hub 登録
ここからは、新たにソフトを導入したdockerを自分のhubに登録する方法です。
ご自身で何かソフトウェアを導入されたら、ぜひhubに登録することをお勧めします。
続きの作業を誰かに依頼したり、エラーがでてわからなくなったときに、対処方法を問い合わせるのにも役立ちます。
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f19e2f06eabb continuumio/anaconda3 "/usr/bin/tini -- /b…" 3 hours ago Up 3 hours
$ docker commit f19e2f06eabb kaizenjapan/anaconda-deep
$ docker push kaizenjapan/anaconda-deep:latest
参考資料(reference)
dockerで機械学習(python:anaconda)「直感Deep Learning」Antonio Gulli、Sujit Pal 第1章,第2章
https://qiita.com/kaizen_nagoya/items/483ae708c71c88419c32
OpenCVをPythonで動かそうとしてlibGL.soが無いって言われたけど解決した。
https://qiita.com/toshitanian/items/5da24c0c0bd473d514c8
サーバサイドにおけるmatplotlibによる作図Tips
https://qiita.com/TomokIshii/items/3a26ee4453f535a69e9e
Dockerでホストとコンテナ間でのファイルコピー
https://qiita.com/gologo13/items/7e4e404af80377b48fd5
Docker for Mac でファイル共有を利用する
https://qiita.com/seijimomoto/items/1992d68de8baa7e29bb5
「名古屋のIoTは名古屋のOSで」Dockerをどっかーらどうやって使えばいいんでしょう。TOPPERS/FMP on RaspberryPi with Macintosh編 5つの関門
https://qiita.com/kaizen_nagoya/items/9c46c6da8ceb64d2d7af
64bitCPUへの道 and/or 64歳の決意
https://qiita.com/kaizen_nagoya/items/cfb5ffa24ded23ab3f60
ゼロから作るDeepLearning2自然言語処理編 読書会の進め方(例)
https://qiita.com/kaizen_nagoya/items/025eb3f701b36209302e
<この項は書きかけです。順次追記します。>
This article is not completed. I will add some words and/or centences in order.
Este artículo no está completo. Agregaré algunas palabras en orden.
知人資料
' @kazuo_reve 私が効果を確認した「小川メソッド」
https://qiita.com/kazuo_reve/items/a3ea1d9171deeccc04da
' @kazuo_reve 新人の方によく展開している有益な情報
https://qiita.com/kazuo_reve/items/d1a3f0ee48e24bba38f1
' @kazuo_reve Vモデルについて勘違いしていたと思ったこと
https://qiita.com/kazuo_reve/items/46fddb094563bd9b2e1e
自己記事一覧
Qiitaで逆リンクを表示しなくなったような気がする。時々、スマフォで表示するとあらわっることがあり、完全に削除したのではなさそう。
4月以降、せっせとリンクリストを作り、統計を取って確率を説明しようとしている。
2025年2月末を目標にしている。
一覧の一覧( The directory of directories of mine.) Qiita(100)
https://qiita.com/kaizen_nagoya/items/7eb0e006543886138f39
仮説(0)一覧(目標100現在40)
https://qiita.com/kaizen_nagoya/items/f000506fe1837b3590df
Qiita(0)Qiita関連記事一覧(自分)
https://qiita.com/kaizen_nagoya/items/58db5fbf036b28e9dfa6
Error一覧 error(0)
https://qiita.com/kaizen_nagoya/items/48b6cbc8d68eae2c42b8
C++ Support(0)
https://qiita.com/kaizen_nagoya/items/8720d26f762369a80514
Coding(0) Rules, C, Secure, MISRA and so on
https://qiita.com/kaizen_nagoya/items/400725644a8a0e90fbb0
Ethernet 記事一覧 Ethernet(0)
https://qiita.com/kaizen_nagoya/items/88d35e99f74aefc98794
Wireshark 一覧 wireshark(0)、Ethernet(48)
https://qiita.com/kaizen_nagoya/items/fbed841f61875c4731d0
線網(Wi-Fi)空中線(antenna)(0) 記事一覧(118/300目標)
https://qiita.com/kaizen_nagoya/items/5e5464ac2b24bd4cd001
なぜdockerで機械学習するか 書籍・ソース一覧作成中 (目標100)
https://qiita.com/kaizen_nagoya/items/ddd12477544bf5ba85e2
プログラムちょい替え(0)一覧:4件
https://qiita.com/kaizen_nagoya/items/296d87ef4bfd516bc394
言語処理100本ノックをdockerで。python覚えるのに最適。:10+12
https://qiita.com/kaizen_nagoya/items/7e7eb7c543e0c18438c4
Python(0)記事をまとめたい。
https://qiita.com/kaizen_nagoya/items/088c57d70ab6904ebb53
安全(0)安全工学シンポジウムに向けて: 21
https://qiita.com/kaizen_nagoya/items/c5d78f3def8195cb2409
プログラマによる、プログラマのための、統計(0)と確率のプログラミングとその後
https://qiita.com/kaizen_nagoya/items/6e9897eb641268766909
転職(0)一覧
https://qiita.com/kaizen_nagoya/items/f77520d378d33451d6fe
技術士(0)一覧
https://qiita.com/kaizen_nagoya/items/ce4ccf4eb9c5600b89ea
Reserchmap(0) 一覧
https://qiita.com/kaizen_nagoya/items/506c79e562f406c4257e
物理記事 上位100
https://qiita.com/kaizen_nagoya/items/66e90fe31fbe3facc6ff
量子(0) 計算機, 量子力学
https://qiita.com/kaizen_nagoya/items/1cd954cb0eed92879fd4
数学関連記事100
https://qiita.com/kaizen_nagoya/items/d8dadb49a6397e854c6d
coq(0) 一覧
https://qiita.com/kaizen_nagoya/items/d22f9995cf2173bc3b13
統計(0)一覧
https://qiita.com/kaizen_nagoya/items/80d3b221807e53e88aba
図(0) state, sequence and timing. UML and お絵描き
https://qiita.com/kaizen_nagoya/items/60440a882146aeee9e8f
色(0) 記事100書く切り口
https://qiita.com/kaizen_nagoya/items/22331c0335ed34326b9b
品質一覧
https://qiita.com/kaizen_nagoya/items/2b99b8e9db6d94b2e971
言語・文学記事 100
https://qiita.com/kaizen_nagoya/items/42d58d5ef7fb53c407d6
医工連携関連記事一覧
https://qiita.com/kaizen_nagoya/items/6ab51c12ba51bc260a82
水の資料集(0) 方針と成果
https://qiita.com/kaizen_nagoya/items/f5dbb30087ea732b52aa
自動車 記事 100
https://qiita.com/kaizen_nagoya/items/f7f0b9ab36569ad409c5
通信記事100
https://qiita.com/kaizen_nagoya/items/1d67de5e1cd207b05ef7
日本語(0)一欄
https://qiita.com/kaizen_nagoya/items/7498dcfa3a9ba7fd1e68
英語(0) 一覧
https://qiita.com/kaizen_nagoya/items/680e3f5cbf9430486c7d
音楽 一覧(0)
https://qiita.com/kaizen_nagoya/items/b6e5f42bbfe3bbe40f5d
「@kazuo_reve 新人の方によく展開している有益な情報」確認一覧
https://qiita.com/kaizen_nagoya/items/b9380888d1e5a042646b
鉄道(0)鉄道のシステム考察はてっちゃんがてつだってくれる
https://qiita.com/kaizen_nagoya/items/faa4ea03d91d901a618a
OSEK OS設計の基礎 OSEK(100)
https://qiita.com/kaizen_nagoya/items/7528a22a14242d2d58a3
coding (101) 一覧を作成し始めた。omake:最近のQiitaで表示しない5つの事象
https://qiita.com/kaizen_nagoya/items/20667f09f19598aedb68
官公庁・学校・公的団体(NPOを含む)システムの課題、官(0)
https://qiita.com/kaizen_nagoya/items/04ee6eaf7ec13d3af4c3
「はじめての」シリーズ ベクタージャパン
https://qiita.com/kaizen_nagoya/items/2e41634f6e21a3cf74eb
AUTOSAR(0)Qiita記事一覧, OSEK(75)
https://qiita.com/kaizen_nagoya/items/89c07961b59a8754c869
プログラマが知っていると良い「公序良俗」
https://qiita.com/kaizen_nagoya/items/9fe7c0dfac2fbd77a945
LaTeX(0) 一覧
https://qiita.com/kaizen_nagoya/items/e3f7dafacab58c499792
自動制御、制御工学一覧(0)
https://qiita.com/kaizen_nagoya/items/7767a4e19a6ae1479e6b
Rust(0) 一覧
https://qiita.com/kaizen_nagoya/items/5e8bb080ba6ca0281927
programの本質は計画だ。programは設計だ。
https://qiita.com/kaizen_nagoya/items/c8545a769c246a458c27
登壇直後版 色使い(JIS安全色) Qiita Engineer Festa 2023〜私しか得しないニッチな技術でLT〜 スライド編 0.15
https://qiita.com/kaizen_nagoya/items/f0d3070d839f4f735b2b
プログラマが知っていると良い「公序良俗」
https://qiita.com/kaizen_nagoya/items/9fe7c0dfac2fbd77a945
逆も真:社会人が最初に確かめるとよいこと。OSEK(69)、Ethernet(59)
https://qiita.com/kaizen_nagoya/items/39afe4a728a31b903ddc
統計の嘘。仮説(127)
https://qiita.com/kaizen_nagoya/items/63b48ecf258a3471c51b
自分の言葉だけで論理展開できるのが天才なら、文章の引用だけで論理展開できるのが秀才だ。仮説(136)
https://qiita.com/kaizen_nagoya/items/97cf07b9e24f860624dd
参考文献駆動執筆(references driven writing)・デンソークリエイト編
https://qiita.com/kaizen_nagoya/items/b27b3f58b8bf265a5cd1
「何を」よりも「誰を」。10年後のために今見習いたい人たち
https://qiita.com/kaizen_nagoya/items/8045978b16eb49d572b2
Qiitaの記事に3段階または5段階で到達するための方法
https://qiita.com/kaizen_nagoya/items/6e9298296852325adc5e
出力(output)と呼ばないで。これは状態(state)です。
https://qiita.com/kaizen_nagoya/items/80b8b5913b2748867840
祝休日・謹賀新年 2025年の目標
https://qiita.com/kaizen_nagoya/items/dfa34827932f99c59bbc
Qiita 1年間をまとめた「振り返りページ」@2024
https://qiita.com/kaizen_nagoya/items/ed6be239119c99b15828
2024 参加・主催Calendarと投稿記事一覧 Qiita(248)
https://qiita.com/kaizen_nagoya/items/d80b8fbac2496df7827f
主催Calendar2024分析 Qiita(254)
https://qiita.com/kaizen_nagoya/items/15807336d583076f70bc
Calendar 統計
https://qiita.com/kaizen_nagoya/items/e315558dcea8ee3fe43e
LLM 関連 Calendar 2024
https://qiita.com/kaizen_nagoya/items/c36033cf66862d5496fa
Large Language Model Related Calendar
https://qiita.com/kaizen_nagoya/items/3beb0bc3fb71e3ae6d66
博士論文 Calendar 2024 を開催します。
https://qiita.com/kaizen_nagoya/items/51601357efbcaf1057d0
博士論文(0)関連記事一覧
https://qiita.com/kaizen_nagoya/items/8f223a760e607b705e78
coding (101) 一覧を作成し始めた。omake:最近のQiitaで表示しない5つの事象
https://qiita.com/kaizen_nagoya/items/20667f09f19598aedb68
あなたは「勘違いまとめ」から、勘違いだと言っていることが勘違いだといくつ見つけられますか。人間の間違い(human error(125))の種類と対策
https://qiita.com/kaizen_nagoya/items/ae391b77fffb098b8fb4
プログラマの「プログラムが書ける」思い込みは強みだ。3つの理由。仮説(168)統計と確率(17) , OSEK(79)
https://qiita.com/kaizen_nagoya/items/bc5dd86e414de402ec29
出力(output)と呼ばないで。これは状態(state)です。
https://qiita.com/kaizen_nagoya/items/80b8b5913b2748867840
これからの情報伝達手段の在り方について考えてみよう。炎上と便乗。
https://qiita.com/kaizen_nagoya/items/71a09077ac195214f0db
ISO/IEC JTC1 SC7 Software and System Engineering
https://qiita.com/kaizen_nagoya/items/48b43f0f6976a078d907
アクセシビリティの知見を発信しよう!(再び)
https://qiita.com/kaizen_nagoya/items/03457eb9ee74105ee618
統計論及確率論輪講(再び)
https://qiita.com/kaizen_nagoya/items/590874ccfca988e85ea3
読者の心をグッと惹き寄せる7つの魔法
https://qiita.com/kaizen_nagoya/items/b1b5e89bd5c0a211d862
「@kazuo_reve 新人の方によく展開している有益な情報」確認一覧
https://qiita.com/kaizen_nagoya/items/b9380888d1e5a042646b
ソースコードで議論しよう。日本語で議論するの止めましょう(あるプログラミング技術の議論報告)
https://qiita.com/kaizen_nagoya/items/8b9811c80f3338c6c0b0
脳内コンパイラの3つの危険
https://qiita.com/kaizen_nagoya/items/7025cf2d7bd9f276e382
心理学の本を読むよりはコンパイラ書いた方がよくね。仮説(34)
https://qiita.com/kaizen_nagoya/items/fa715732cc148e48880e
NASAを超えるつもりがあれば読んでください。
https://qiita.com/kaizen_nagoya/items/e81669f9cb53109157f6
データサイエンティストの気づき!「勉強して仕事に役立てない人。大嫌い!!」『それ自分かも?』ってなった!!!
https://qiita.com/kaizen_nagoya/items/d85830d58d8dd7f71d07
「ぼくの好きな先生」「人がやらないことをやれ」プログラマになるまで。仮説(37)
https://qiita.com/kaizen_nagoya/items/53e4bded9fe5f724b3c4
なぜ経済学徒を辞め、計算機屋になったか(経済学部入学前・入学後・卒業後対応) 転職(1)
https://qiita.com/kaizen_nagoya/items/06335a1d24c099733f64
プログラミング言語教育のXYZ。 仮説(52)
https://qiita.com/kaizen_nagoya/items/1950c5810fb5c0b07be4
【24卒向け】9ヶ月後に年収1000万円を目指す。二つの関門と三つの道。
https://qiita.com/kaizen_nagoya/items/fb5bff147193f726ad25
「【25卒向け】Qiita Career Meetup for STUDENT」予習の勧め
https://qiita.com/kaizen_nagoya/items/00eadb8a6e738cb6336f
大学入試不合格でも筆記試験のない大学に入って卒業できる。卒業しなくても博士になれる。
https://qiita.com/kaizen_nagoya/items/74adec99f396d64b5fd5
全世界の不登校の子供たち「博士論文」を書こう。世界子供博士論文遠隔実践中心 安全(99)
https://qiita.com/kaizen_nagoya/items/912d69032c012bcc84f2
日本のプログラマが世界で戦える16分野。仮説(53),統計と確率(25) 転職(32)、Ethernet(58)
https://qiita.com/kaizen_nagoya/items/a7e634a996cdd02bc53b
小川メソッド 覚え(書きかけ)
https://qiita.com/kaizen_nagoya/items/3593d72eca551742df68
DoCAP(ドゥーキャップ)って何ですか?
https://qiita.com/kaizen_nagoya/items/47e0e6509ab792c43327
views 20,000越え自己記事一覧
https://qiita.com/kaizen_nagoya/items/58e8bd6450957cdecd81
Views1万越え、もうすぐ1万記事一覧 最近いいねをいただいた213記事
https://qiita.com/kaizen_nagoya/items/d2b805717a92459ce853
amazon 殿堂入りNo1レビュアになるまで。仮説(102)
https://qiita.com/kaizen_nagoya/items/83259d18921ce75a91f4
100以上いいねをいただいた記事16選
https://qiita.com/kaizen_nagoya/items/f8d958d9084ffbd15d2a
水道局10年(1976,4-1986,3)を振り返る
https://qiita.com/kaizen_nagoya/items/707fcf6fae230dd349bf
小川清最終講義、最終講義(再)計画, Ethernet(100) 英語(100) 安全(100)
https://qiita.com/kaizen_nagoya/items/e2df642e3951e35e6a53
<この記事は個人の過去の経験に基づく個人の感想です。現在所属する組織、業務とは関係がありません。>
This article is an individual impression based on my individual experience. It has nothing to do with the organization or business to which I currently belong.
Este artículo es una impresión personal basada en mi experiencia personal. No tiene nada que ver con la organización o empresa a la que pertenezco actualmente.
文書履歴(document history)
ver. 0.10 初稿 20180925 昼
ver. 0.11 hub登録訂正 20180925 夕方
ver. 0.12 ファイル複写追記 20180925 深夜
ver. 0.13 出力細分化 20180926 零時
ver. 0.14 誤記訂正 20180926 朝
ver. 0.15 表題変更 20180927 朝
ver. 0.16 ch06 add 20190117
ver. 0.17 補足 20200317
最後までおよみいただきありがとうございました。
いいね 💚、フォローをお願いします。
Thank you very much for reading to the last sentence.
Please press the like icon 💚 and follow me for your happy life.
Muchas gracias por leer hasta la última oración.
Por favor, haz clic en el ícono Me gusta 💚 y sígueme para tener una vida feliz.