「ゼロから作るDeep Learning」(斎藤 康毅 著 オライリー・ジャパン刊)を読んでいる時に、参照したサイト等をメモしていきます。
新しい分野で、新しい単語、用語が出てくるのは当然ですが、それがアルファベットの頭をとった略語だったりすると、非英語民族にはどう読めばいいのかわかりません。
その昔、専門学校でCOBOLを教えたとき、学生が最初につまづいたのが、COBOLで使われている命令の発音と意味でした。発音できないものは覚えられないし、使えない。
と言う事で、
この本の中に出てきた単語で、読み方とか語源とか、私が調べたものをまとめてみました。
読んでいる最中なので、本に出てきた順になっています。
1巻目
1章
Python
パイソン もともと「にしきへび」の意味の英単語なので、その発音で読みます。
なんで、蛇? かというと、モンティ・パイソンというTV番組があって・・・(有名な話なので省略)
NumPy
ナンパイ これは、もとが数値演算(numerical operation)用のpythonライブラリーということだから、number(ナンバー) のナンとパイソンのパイで、ナンパイでいいかと。
SciPy
サイパイ 科学技術計算(science サイエンス)用ということで、サイパイ。その昔、SF小説(science fiction)のことを、エスエフと呼ぶか、SciFi(サイファイ)と呼ぶかなんて話もありましたが、まったく別の話。
TensorFlow
テンサーフロー 日本では「テンソルフロー」と読む人もいるらしいが、google の人はテンサーフローと読んでいる。 tensor (多次元配列)という単語は、英語読みではテンサー、ドイツ語ではテンソル。日本の科学技術関連の文献では「テンソル」が主流。戦前に定着した語なのかもしれません。
Matplotlib
マットプロットリブ MATLABという数値解析ソフトと同様のことをpythonで使えるようにしたライブラリ。Mat は Matrix(行列)がもともとの語のようです。plotは「グラフを描く」という英単語。行列(配列)をグラフにするライブラリ。
Anaconda
アナコンダ もとは南米のヘビの名前。pythonが蛇だから、ディストリビューションのほうも蛇の名前ということでしょう。
2章
AND NAND OR XOR
アンド ナンド オア エクスオア 論理演算の基本です。
3章
activation function
アクティベーション 活性化関数
あとになって、アクティベーション(活性化関数の後の出力データ) なんて語が出てきたりします。
sigmoid function
シグモイド関数
sigmoid はS字形のこと
exp() exponential function
e(ネピア数)を底とする指数関数。
exp(x)は eのx乗。きちんとエクスポネンシャルエックスと読む人もいるようだが、イーのエックス乗で意味は通じる。
ReLU(Rectified Linear Unit)
レル
rectify(調整)された linear(線形関数)を使ったユニット。元の語の読み方をつなげば、 レルになる。ランプ関数という別名があるらしいが、わざわざ別名になおして読むのは不自然だろう。
softmax
ソフトマックス
引数(argument)の中でどれが最大(Max)かを示す関数を滑らか(soft)にしたもの。 後でargmaxという関数も出てくる
MNIST
エムニスト
Modified National Institute of Standards and Technology database
NISTとは、米国の技術や産業、工業などに関する規格標準化を行っている政府機関であるアメリカ国立標準技術研究所
NISTが作ったデータベースを修正(modify)したもの?
predict
プリディクト
(…を)予言する、予報する
4章
損失関数(loss function)
ロス・ファンクション
損失関数はニューラルネットワークの性能の“悪さ”を示す指標です。現在のニューラルネットワークが教師データに対してどれだけ適合していないか、教師データに対してどれだけ一致していないかということを表します。
交差エントロピー誤差(cross entropy error)
勾配(gradient)
グラジエント
学習係数(learning rate)
ラーニング・レイト
$\eta$ イータ →ギリシャ文字の読み方
微分
\frac{dy}{dx} ディーワイディーエックス
偏微分
\frac{\delta f}{ \delta x} デルエフデルエックス
iter_per_epoch
イテレーション iteration 反復
この本では 訓練データ件数 ÷ バッチデータ件数
1エポックの中で、イテレーション回数、バッチを繰り返せば、すべてのデータを見たことになります。
5章
backward propagation 逆伝播
バック・プロパゲーション という語で説明する本も多い
レイヤ(Layer)
層
Lay(平らに積む)
コスチューム・プレイヤーの省略形ではないらしい
Affine
アフィン アフィン変換とかアフィン空間とかいう用語があるらしい
たぶん、アフィン結合のことではないかと
wikipedia
与えられた体 K 上のベクトル空間 V において、その元 x1, …, xn の α1, …, αn を係数とするアフィン結合とは、係数和が 1, つまり $ ∑^n_{i=1}αi = 1 $ を満たすような線型結合
$ ∑^n_{i=1} αi xi = α1x1 + α2x2 + ・・・ + α_nx_n$
を言う。
keras では Dense という名前のようです。
6章
SGD
エスジーディー こういう、他に読みようがないものは分かりやすい
stochastic gradient descent
ストカスティック グラジエント ディセント
確率的勾配降下法 最適なパラメータを見つけるための手法のひとつ
確率というよりも、ストックであてずっぽうに突いて、勾配が下がっている方向を探して進んでいく感じ
Momentum
モーメンタム
運動量 最適なパラメータを見つけるための手法のひとつ
AdaGrad
アダグラド ? 元の語の読みをつなげると、こうなります。
Adaptive Subgradient Methods
アダプティブ サブグラジエント メソッド 劣勾配を適応させる手法?
最適なパラメータを見つけるための手法のひとつ
Adam
アダム
AdaGrad と Momentum を融合?
最適なパラメータを見つけるための手法のひとつ
標準偏差が0.01 のガウス分布
ガウス分布は正規分布ともいう。
正規分布の中でもμ(ミュー 平均値)=0、$σ^2$(シグマ二乗 分散)=1の分布を標準正規分布と呼び、Numpyライブラリのrondomモジュール内のrandnメソッドで生成できる。
np.random.randn(node_num, node_num)
また、normalメソッドを使えば、randnと違い、 μ(平均値)と σ(シグマ 標準偏差)を任意で指定した正規分布に従う乱数配列を生成することができる。
np.random.normal(loc=0, scale=0.01, size=(node_num, node_num))
しかし、P178ではnormalメソッドではなく、randnメソッドを使っています。
P178
これまで、重みの初期値は、
0.01 * np.random.randn(10, 100) のように、ガウス分布から生成される値を0.01 倍した小さな値――標準偏差が0.01 のガウス分布――を用いました。
この辺、私は詳しくないのですが、正規分布するXを標準化して標準正規分布Zに変換したとき
$Z = \frac{X - μ}{σ} $ となるらしいので、平均μ=0、標準偏差σ=0.01なら、
$Z = \frac{X}{0.01} $ なので
$X = 0.01 ×Z$
ということでしょうか?
μ ミュー
σ シグマ
Kerasレイヤーの重み初期化では、
keras.initializers.RandomNormal(mean=0.0, stddev=0.01, seed=None)
表現力の制限
P182
各層のアクティベーションの分布は、適度な広がりを持つことが求められます。
なぜなら、適度に多様性のあるデータが各層を流れることで、ニューラルネット
ワークの学習が効率的に行えるからです。逆に、偏ったデータが流れると、勾
配消失や「表現力の制限」が問題になって、学習がうまくいかない場合があり
ます。
representation ? 唐突に現れた「表現力」という語の意味がよくわからなかったので、いくつか参考になりそうな文献を探してみた。
表現力とは機械学習モデルが近似できる関数集合の広さを表す概念
→残差スキップ接続をもつ深層ニューラルネットの表現力に基づく数理解析と設計
ニューラルネットワークに関して最も衝撃的な事実の1つは任意の関数を表現できることです。 例えば誰かから複雑で波打った関数f(x)を与えられたとします:それがどんな関数であっても、考えられるすべての入力xに対して、 出力値がf(x)(もしくはその近似)であるニューラルネットワークが存在します。
→ニューラルネットワークが任意の関数を表現できることの視覚的証明
三層パーセプトロンでも中間層のユニット数を無限に増やせば任意の関数を任意の精度で近似できる.ではなぜ深い方が良いのか? 深さに対して指数的に表現力が増大するから
→機械学習技術とその数理基盤
Xavier の初期値
研究者の名前 Xavier Glorot から
ザビエル ?
宣教師?
前層のノードの数がn 個の場合、$\frac{1}{\sqrt n}$ を標準偏差とするガウス分布
Kerasレイヤーの重み初期化では、 glorot_normal
He の初期値
研究者の名前 何恺明(Kaiming He) から。
何?
フー?
前層のノードの数がn 個の場合、$\sqrt\frac{2}{n}$ を標準偏差とするガウス分布
Kerasレイヤーの重み初期化では、 he_normal
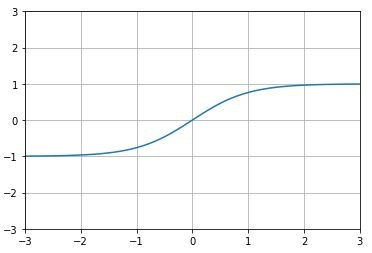
tanh関数
ハイパボリックタンジェント 双曲線関数
$\tanh x=\frac{\sinh x}{\cosh x}$
Batch Normalization
バッチ ノーマリゼーション バッチノーマライゼイション
米国英語だと、ノーマリゼーションという発音もありのようですが、元の語 normalize がノーマライズとしか読めないので、ノーマライゼーションが正しいようです。
Batch Norm は、その名前が示すとおり、学習を行う際のミニバッチを単位として、ミニバッチごとに正規化を行います。具体的には、データの分布が平均が0 で分散が1 になるように正規化を行います。
標準化したいデータ集合をX、その平均がμ、標準偏差σ(だから分散は$σ^{2}$)
標準化したデータをZとすると、
$Z = \frac{X - μ}{σ} = \frac{X - μ}{\sqrt{σ^{2}}}$ となるらしい
これについてのコードは、
Batch Norm に対応しているニューラルネットのクラスが commonフォルダの中の multi_layer_net_extend.py 、そこから参照している layers.py で定義しているクラス BatchNormalization にあります。
if train_flg:
mu = x.mean(axis=0)
xc = x - mu
var = np.mean(xc**2, axis=0)
std = np.sqrt(var + 10e-7)
xn = xc / std
初期値にロバスト
robust 〈人・体格など〉強健な,たくましい,がっしりした
P259
ここで言うロバスト性とは、たとえば、ニューラルネットワークは、入力画像に
小さなノイズがのってしまっても、出力結果が変わらないような頑健な性質がある
ということです。そのようなロバスト性のおかげで、ネットワークを流れるデータを
“劣化”させても、出力結果に与える影響は少ないと考えることができます。
過学習 overfitting
オーバーフィッティング
訓練データにだけ、ぴったり合うように学習し過ぎてしまった。
Weight decay
ウェイト ディケイ 荷重減衰
過学習しないように、重みを衰えさせる
L2 ノルム(norm)
いろいろなものの「大きさ」を表す量
M 次元のベクトル x の p 次ノルムとは以下で定義される量です。
∥x∥_p =(∑^M_i|x_i|^p)^{1/p}= \sqrt[p]{|x_1|^p + · · · + |x_M|^p}
L2ノルムは、M次元のベクトルxの2次ノルム
∥x∥_2 =(∑^M_i|x_i|^2)^{1/2}= \sqrt{|x_1|^2 + · · · + |x_M|^2}
これが2次元のとき、こうなります。
∥x∥_2 = \sqrt{x_1^2 + x_2^2}
これって、ピタゴラスの定理と見れば、直角三角形の斜辺の長さのことになる。
2乗してルートをはずすと
r^2 = x^2 + y^2
となって、原点を中心とする半径rの円の方程式になります。
で
重みをWとすれば、L2 ノルムのWeight decay は、$ \frac{1}{2}\lambda\ W^2 $ になり、この$ \frac{1}{2}\lambda\ W^2 $ を損失関数に加算します。
ということなので、 $ 0.5 × λ ×(w_1^2 + · · · + w_M^2) $ を損失関数に加算します。
イメージとしては損失関数0の場所(オーバーフィッティングになってしまう場所)を原点とした円を描いて、そこに向かって学習するけれど、円周の中には入れない、という感じ? 訓練データに例外データが混ざっていて例外に合わせようとして重みwが大きくなると、円も大きくなって学習するのをジャマをし、例外データを無視して重みwが小さくなると円も小さくなって学習のジャマをしない、ということか?
λ ラムダ Weight Decay(L2ノルム)の強さ
Dropout
ドロップアウト 過学習を抑制するため、ニューロンをランダムに消去しながら学習する手法
ハイパーパラメータ(hyper-parameter)
各層のニューロンの数やバッチサイズ、パラメータの更新の際の学習係数やWeight decay など
スタンフォード大学の授業「CS231n」
CS231n: Convolutional Neural Networks for Visual Recognition
7章
CNN convolutional neural network
シーエヌエヌ こういう、他に読みようがないものは分かりやすい
畳み込みニューラルネットワーク
convolutional コンボリューショナル 渦を巻いている
Convolution レイヤ
コンボリューション 渦巻き
フィルタが入力データの上をぐるぐる回っていく感じ?
日本語では「畳み込み」になっているけれど、これは折り紙のように畳んでいくというイメージからなんでしょうか?
パディング(padding)
pad 形を整えるための詰め物、平たく形を整えた物
インド映画「パッドマン」では、パッドというのは女性生理用品のことだった。
入力データの周辺に0を詰めて形を整える
ストライド(stride)
~をまたぐ
大きな歩幅でまたいでいく感じ。
指輪物語のアラゴルンの俗称がストライダーだが、大きな歩幅で歩く人という意味。瀬田貞二訳では「馳夫」。日本語訳の名前にすることはいいと思うのだが、速いという面が強調されすぎてて、足が長い=背が高い、という面が欠けてしまっている。後になって実は王様だったとか、映画になったときの役者のイメージと、ずいぶん違うように思うのだが。
Poolingレイヤ
プーリング
共同利用する
im2col
image to column の略記だから、 イムトゥカル ?
画像から行列へ
phpでも形式を変換する関数で、toを2に変えた名前のものがけっこうある。
エッジ(edge)やブロブ(blob)などのプリミティブ(primitive)な情報
LeNet
ルネット ? フランス語読みなら Le はルと読む。
フランス人のYann LeCun(ヤン・ルカン)がつくった畳み込みニューラルネットワーク
AlexNet
アレックスネット
Alex Krizhevsky がつくった畳み込みニューラルネットワーク
8章
Data Augmentation
データ・オーグメンテーション(増加)
NVIDIA
エヌビディアコーポレーション
コンピュータのグラフィックス処理や演算処理の高速化を主な目的とするGPUを開発し販売する半導体メーカー
FCN(Fully Convolutional Network)
エフシーエヌ フリー・コンボリューショナル・ネットワーク
「すべてが畳み込み層から構成されるネットワーク」
バイリニア補間による拡大
Bilinear
Bi(二つの方向から)リニア(直線的)に補間する
デコンボリューション(逆畳み込み演算)
deconvolution
de- 否定、逆転
NIC (Neural Image Caption)
エヌアイシー? ニック?
ニューラル・イメージ・キャプション
マルチモーダル処理
Multimodal
DCGAN(Deep Convolutional Generative Adversarial Network)
ディーシー・ギャン? ガン? 英語読みだと ギャン になると思うが。
畳み込みニューラルねとワークを使ったGAN(画像生成モデル)
ジェネレイティブ(生成)アドバーサリアル(敵対的)ネットワーク
P268
Generator(生成する人)とDiscriminator(識別する人)と呼ばれる2 つのニューラルネットワークを利用して、・・・
両者を競わせるように学習させていくことで、Generator は、より精巧な騙し画像の技術を学習し、Discriminator は、より高精度に見破ることができる鑑定師のように成長していく
Deep Q-Network(通称、DQN)
ディーキューエヌ?
さすがに、ドキュンとは読まないと思うが・・・
2巻目 自然言語処理編
1章
GPU(Graphics Processing Unit)
ジーピーユー グラフィックス プロセッシング ユニット
もともとは画像処理用演算装置なのだが、並列処理に強いため、AIに使うようになったらしい。
CuPy
クーパイ?
CuPy is an implementation of NumPy-compatible multi-dimensional array on CUDA.
CUDA(クーダ)上で、NumPy互換の多次元配列を使えるようにするPythonライブラリ。
Google Colaboratory では、インストールしなくても使えるようです。
ノートブックを開き、[編集]>[ノートブックの設定]>ハードウェアアクセラレータ>GPU を選択
2章
スタンフォード大学の授業「CS224d」
CS224d: Deep Learning for Natural Language Processing
You say goodbye and I say hello.
The Beatles の歌「Hello,Goodbye」の一節
単語の分散表現
Qiitaの記事より
なぜ自然言語処理にとって単語の分散表現は重要なのか?
自然言語処理における単語分散表現(単語ベクトル)と文書分散表現(文書ベクトル)
コサイン類似度(cosine similarity)
数式は理解できませんが、2つのベクトルの間の角度のことだと考えれば、なんとなくわかります。

相互情報量(Pointwise Mutual Information)
SVD 特異値分解(Singular Value Decomposition)
特異値分解の内容はまったく理解できていないが、行列Xを次のような3つの行列の積に分解できるということなので、これを利用すると次元削減できるというのは、わからないでもない。
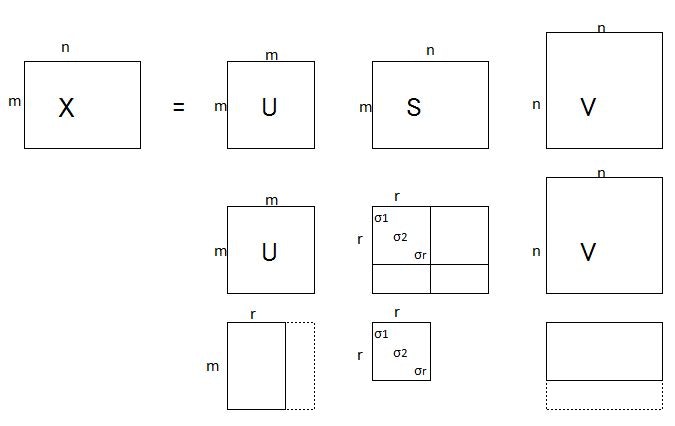
行列S(たぶんシグマのこと)の要素は、σ1≧σ2≧・・・≧σr>0 で、これら以外は全部0。
と言う事なので、このσで掛け算される以外の要素は0になってしまう。
だから、行列Uはm×rだけでよいことになる。
さらに、σは値が大きい(重要度)順に並んでいるから、要素の最初のほうだけを残して、あとは削っても大きな問題は無い、と考えていい。
PTB データセット
3章
word2vec
ワード・トゥ・ベク
単語をベクトルに変換する
Googleコード word2vec
CBOW(continuous bag-of-words)モデル
シーバウ
continuous 切れ目のない、とぎれない
bag-of-words 語の袋
文書検索システムで従来使われている手法で、文書中の語から索引語の集合を作り、与えられた検索語の集合あるいは質問文から作られた検索語の集合と比較照合するもの。
P177
CBOWモデルの学習の本来の目的は、コンテキストからターゲットを
正しく推測できるようになることです。この目的を達成するために学習を進めると、
(その副産物として)単語の意味がエンコードされた「単語の分散表現」が得られま
した。
skip-gram モデル
スキップ・グラム
gram=文字 をスキップする
4章
Embedding レイヤ
embed エンベッド 埋め込む
Tensor Flow サイトより 単語の埋め込み
Negative sampling
transfer learning 転移学習
SVM Support Vector Machine
1995年頃にAT&TのV.Vapnikが発表したパターン識別用の教師あり機械学習方法
5章
RNN Recurrent Neural Network リカレントニューラルネットワーク
Recurrent 繰り返し起こる
h は hidden state の h
言語モデル(Language Model)
BPTT Backpropagation Through Time
バックプロパゲーション
時間方向に展開したニューラルネットワークの誤差逆伝播法
Truncated BPTT
私の自習メモ
その1 ディレクトリー、フォルダの配置とか
その2 パーセプトロン、半加算器、全加算器
その3 MNISTデータセット
その4 推論処理
その5 学習処理
その6 Fashion MNIST
その6 Kaggleの猫と犬
その6 9未満か9以上か
その7 なんで2分の1?
その8 MatPlotLib
その9 MultiLayerNet クラス
その10 MultiLayerNet クラス
その11 CNN
その12 ディープラーニング
その13 Google Colaboratory
その14 Colaboratoryで4章のプログラムを動かす
その15 TensorFlowの初心者向けチュートリアル
その16 SimpleConvNet を Keras で構築
その17 DeepConvNet を Keras で構築
その18 Grad-Cam
その19 Data Augment
その19の2 続き
その20 自然言語処理編
その21 3、4章