「ゼロから作るDeep Learning」(斎藤 康毅 著 オライリー・ジャパン刊)を読んでいる時に、参照したサイト等をメモしていきます。 その17 ← → その19
Google Colaboratory 上で、本のスクリプトを Keras に置き換えて実行できることが確認できました。
で、
今度はKaggleの猫と犬のデータセットの判別をやらせてみることにしました。
自習メモその6の2でやったときは、正解率が60%で、あてずっぽうより少しマシ程度の結果。
このときは、データ作成時にメモリエラーが頻発したため、訓練データの数を減らしましたし、ニューラルネットはこの時点で理解できていた2層の全結合ネットだったので、1次元に変換したりしました。
自習メモその12では、畳み込みニューラルネットで処理してみましたが、メモリエラーでまともな学習ができず、正解率が50%と、あてずっぽうと同じレベル。
今回はGoogle Colaboratory でメモリエラーを気にしないで、畳み込みニューラルネットに再挑戦して見ようかと思います。
Google Drive に写真をアップ
猫と犬のデータはそれぞれ400MBくらい、マイドライブの空き容量は数ギガあるので、容量の問題はありません。ただ、これをフォルダごとアップしようとすると、時間がかかりすぎて、タイムアウトになったりしました。1フォルダ12500個のファイルなので、ファイル数の問題なのかもしれませんが、犬フォルダは途中で止まったのに、猫フォルダは全部アップできたりして、原因がよくわかりません。時間がかかったから、という理由だと、回線が混んでいた、サーバーの負荷が高かったとか、その時々の事情によるでしょうから、ま、しょうがない。
colab画面を長い時間ほっておくとタイムアウトになる?
長時間スクリプトを実行させたままにして画面の操作をしないでいるとタイムアウトになるという話があったので、画像の形を整える処理は、犬と猫で分けて別々に退避してから、ひとつにまとめました。
自習メモその12でやったのと同じように画像を加工しましたが、自習メモその12は本のDeepConvNet用のデータだったので、channels_first (batch, channels, height, width) の形式になるようにtransposeで加工していました。Kerasは channels_last (batch, height, width, channels) 形式なので、transpose せずに保存しています。
前回作成したKeras版のDeepConvNetで学習させてみた
# 入力データの準備
from google.colab import drive
drive.mount('/content/drive')
import os
import pickle
mnist_file = '/content/drive/My Drive/Colab Notebooks/deep_learning/dataset/catdog.pkl'
with open(mnist_file, 'rb') as f:
dataset = pickle.load(f)
x_train = dataset['train_img'] / 255.0 #正規化している。
t_train = dataset['train_label']
x_test = dataset['test_img'] / 255.0
t_test = dataset['test_label']
print(x_train.shape)
(23411, 80, 80, 3)
画像データは 0 ~ 255 の整数値ですが、これを255.0で除算して0.0~1.0 の範囲に収まるように変換しています。これをやると、学習の速度があがりました。
正規化していないと、エポックを5回やっても正解率60%になりませんでしたが、正規化してから学習させると4回目で60%を超えました。
# TensorFlow と tf.keras のインポート
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from keras.layers import Dense, Activation, Flatten, Conv2D, MaxPooling2D, Dropout
# ヘルパーライブラリのインポート
import numpy as np
import matplotlib.pyplot as plt
def create_model(input_shape, output_size, hidden_size):
import numpy as np
import matplotlib.pyplot as plt
filter_num = 16
filter_size = 3
filter_stride = 1
filter_num2 = 32
filter_num3 = 64
pool_size_h=2
pool_size_w=2
pool_stride=2
model = keras.Sequential(name="DeepConvNet")
model.add(keras.Input(shape=input_shape))
model.add(Conv2D(filter_num, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal'))
model.add(Conv2D(filter_num, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal'))
model.add(MaxPooling2D(pool_size=(pool_size_h, pool_size_w),strides=pool_stride))
model.add(Conv2D(filter_num2, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal'))
model.add(Conv2D(filter_num2, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal'))
model.add(MaxPooling2D(pool_size=(pool_size_h, pool_size_w),strides=pool_stride))
model.add(Conv2D(filter_num3, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal'))
model.add(Conv2D(filter_num3, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal'))
model.add(MaxPooling2D(pool_size=(pool_size_h, pool_size_w),strides=pool_stride))
model.add(keras.layers.Flatten())
model.add(Dense(hidden_size, activation="relu", kernel_initializer='he_normal'))
model.add(Dropout(0.5))
model.add(Dense(output_size))
model.add(Dropout(0.5))
model.add(Activation("softmax"))
#モデルのコンパイル
model.compile(loss="sparse_categorical_crossentropy",
optimizer="adam",
metrics=["accuracy"])
return model
input_shape=(80,80,3)
output_size=2
hidden_size=100
model = create_model(input_shape, output_size, hidden_size)
model.summary()
Model: "DeepConvNet"
Layer (type) Output Shape Param #
conv2d (Conv2D) (None, 80, 80, 16) 448
conv2d_1 (Conv2D) (None, 80, 80, 16) 2320
max_pooling2d (MaxPooling2D) (None, 40, 40, 16) 0
conv2d_2 (Conv2D) (None, 40, 40, 32) 4640
conv2d_3 (Conv2D) (None, 40, 40, 32) 9248
max_pooling2d_1 (MaxPooling2 (None, 20, 20, 32) 0
conv2d_4 (Conv2D) (None, 20, 20, 64) 18496
conv2d_5 (Conv2D) (None, 20, 20, 64) 36928
max_pooling2d_2 (MaxPooling2 (None, 10, 10, 64) 0
flatten (Flatten) (None, 6400) 0
dense (Dense) (None, 100) 640100
dropout (Dropout) (None, 100) 0
dense_1 (Dense) (None, 2) 202
dropout_1 (Dropout) (None, 2) 0
activation (Activation) (None, 2) 0
Total params: 712,382
Trainable params: 712,382
Non-trainable params: 0
input_shape と output_size 以外は、その17で作ったスクリプトと同じです。
model.fit(x_train, t_train, epochs=10, batch_size=128)
test_loss, test_acc = model.evaluate(x_test, t_test, verbose=2)
Epoch 1/10
195/195 [==============================] - 385s 2s/step - loss: 0.7018 - accuracy: 0.5456
Epoch 2/10
195/195 [==============================] - 385s 2s/step - loss: 0.6602 - accuracy: 0.5902
Epoch 3/10
195/195 [==============================] - 383s 2s/step - loss: 0.6178 - accuracy: 0.6464
Epoch 4/10
195/195 [==============================] - 383s 2s/step - loss: 0.5844 - accuracy: 0.6759
Epoch 5/10
195/195 [==============================] - 383s 2s/step - loss: 0.5399 - accuracy: 0.7090
Epoch 6/10
195/195 [==============================] - 383s 2s/step - loss: 0.5001 - accuracy: 0.7278
Epoch 7/10
195/195 [==============================] - 382s 2s/step - loss: 0.4676 - accuracy: 0.7513
Epoch 8/10
195/195 [==============================] - 382s 2s/step - loss: 0.4485 - accuracy: 0.7611
Epoch 9/10
195/195 [==============================] - 380s 2s/step - loss: 0.4295 - accuracy: 0.7713
Epoch 10/10
195/195 [==============================] - 382s 2s/step - loss: 0.4099 - accuracy: 0.7788
4/4 - 0s - loss: 0.3249 - accuracy: 0.8500
正解率は85%。
判定結果を表示してみました。
# 予測する
predictions = model.predict(x_test)
def plot_image(i, predictions_array, t_label, img):
class_names = ['cat', 'dog']
predictions_array = predictions_array[i]
img = img[i].reshape((80, 80, 3))
true_label = t_label[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
# X個のテスト画像、予測されたラベル、正解ラベルを表示します。
# 正しい予測は青で、間違った予測は赤で表示しています。
num_rows = 10
num_cols = 10
num_images = num_rows*num_cols
plt.figure(figsize=(2*num_cols, 2.5*num_rows))
for i in range(num_images):
plt.subplot(num_rows, num_cols, i+1)
plot_image(i, predictions, t_test, x_test)
plt.show()
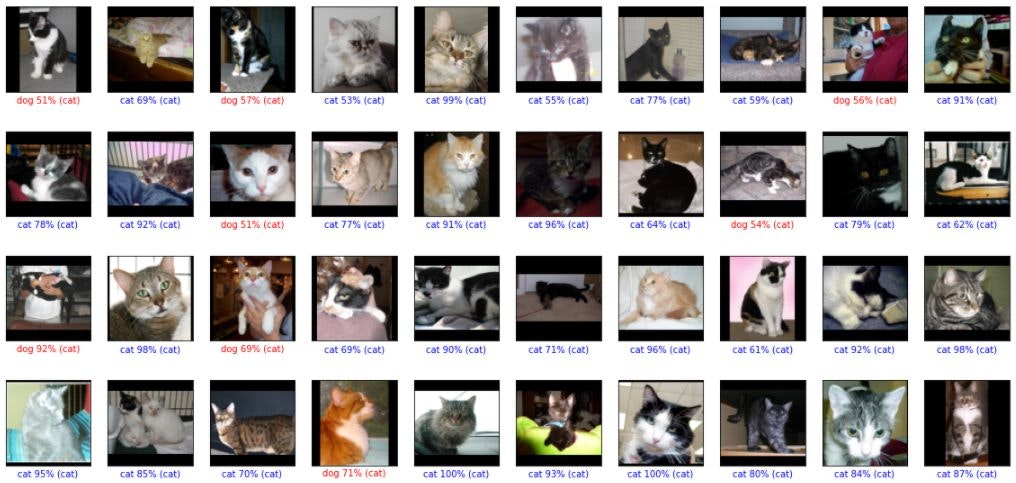
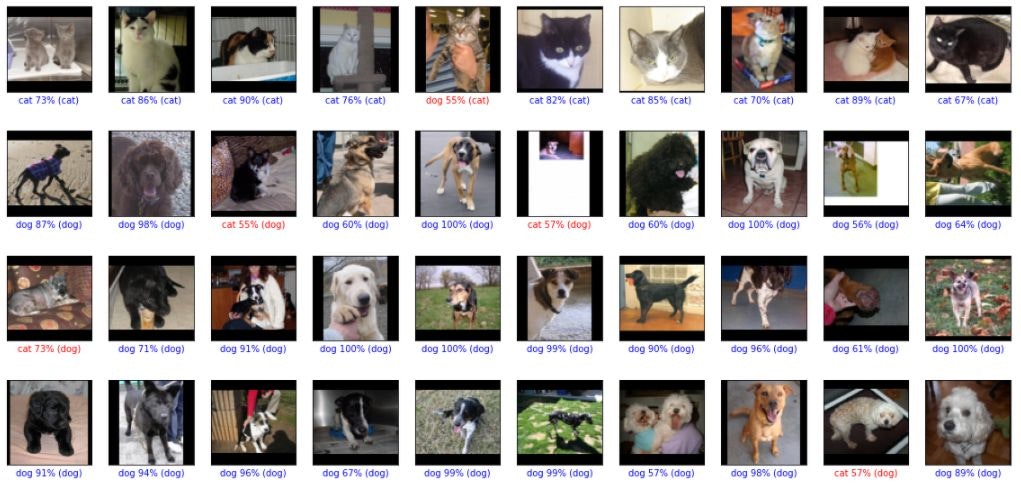
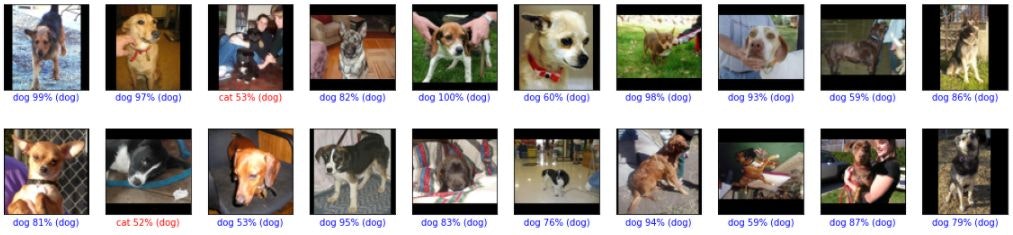
猫を犬と間違えたのが9件、犬を猫と間違えたのが6件です。
顔が大きく真正面を向いている場合は間違いがないように見えます。横向きだったり、顔が小さいと間違えているのかもしれません。猫はみんな三角耳、多くの犬がたれ耳というのもポイントか?
と言う事で
画像の何に注目して判定しているのかが知りたくなって、GRAD-CAMを使って見ることにしました。
Grad-CAM
Gradient-weighted Class Activation Mapping (Grad-CAM) 勾配加重クラス活性化マッピング手法と言うらしい。グラドキャムでいいのかな?
Grad 勾配と言うと、損失関数のところで出てきましたが、どうやら、勾配が大きくなるところが分類に最も影響する、ということのようです。
それ以上の追求はあきらめて、プログラムを動かして、結果だけ見てみようかと思います。
Grad-CAM計算用のプログラムは、こちらを参考にしました。
→kerasとtensorflowでGrad-CAMを実装してみた
import numpy as np
import cv2
# Grad−CAM計算用
from tensorflow.keras import models
import tensorflow as tf
def grad_cam(input_model, x, layer_name):
"""
Args:
input_model(object): モデルオブジェクト
x(ndarray): 画像
layer_name(string): 畳み込み層の名前
Returns:
output_image(ndarray): 元の画像に色付けした画像
"""
# 画像の前処理
# 読み込む画像が1枚なため、次元を増やしておかないとmode.predictが出来ない
h, w, c = x.shape
IMAGE_SIZE = (h, w)
X = np.expand_dims(x, axis=0)
preprocessed_input = X.astype('float32') / 255.0
grad_model = models.Model([input_model.inputs], [input_model.get_layer(layer_name).output, input_model.output])
with tf.GradientTape() as tape:
conv_outputs, predictions = grad_model(preprocessed_input)
class_idx = np.argmax(predictions[0])
loss = predictions[:, class_idx]
# 勾配を計算
output = conv_outputs[0]
grads = tape.gradient(loss, conv_outputs)[0]
gate_f = tf.cast(output > 0, 'float32')
gate_r = tf.cast(grads > 0, 'float32')
guided_grads = gate_f * gate_r * grads
# 重みを平均化して、レイヤーの出力に乗じる
weights = np.mean(guided_grads, axis=(0, 1))
cam = np.dot(output, weights)
# 画像を元画像と同じ大きさにスケーリング
cam = cv2.resize(cam, IMAGE_SIZE, cv2.INTER_LINEAR)
# ReLUの代わり
cam = np.maximum(cam, 0)
# ヒートマップを計算
heatmap = cam / cam.max()
# モノクロ画像に疑似的に色をつける
jet_cam = cv2.applyColorMap(np.uint8(255.0*heatmap), cv2.COLORMAP_JET)
# RGBに変換
rgb_cam = cv2.cvtColor(jet_cam, cv2.COLOR_BGR2RGB)
# もとの画像に合成
output_image = (np.float32(rgb_cam) / 2 + x / 2 )
return output_image , rgb_cam
from keras.preprocessing.image import array_to_img, img_to_array, load_img
predictions = model.predict(x_test)
def hantei_hyouji(i, x_test, t_test, predictions, model):
class_names = ['cat', 'dog']
x = x_test[i]
true_label = t_test[i]
predictions_array = predictions[i]
predicted_label = np.argmax(predictions_array)
target_layer = 'conv2d_5'
cam, heatmap = grad_cam(model, x, target_layer)
moto=array_to_img(x, scale=True)
hantei=array_to_img(heatmap, scale=True)
hyouji=array_to_img(cam, scale=True)
print("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]))
row = 1
col = 3
plt.figure(figsize=(15,15))
plt.subplot(row, col, 1)
plt.imshow(moto)
plt.axis('off')
plt.subplot(row, col, 2)
plt.imshow(hantei)
plt.axis('off')
plt.subplot(row, col, 3)
plt.axis('off')
plt.imshow(hyouji)
plt.show()
return
for i in range(100):
hantei_hyouji(i, dataset['test_img'], t_test, predictions, model)
で、結果は

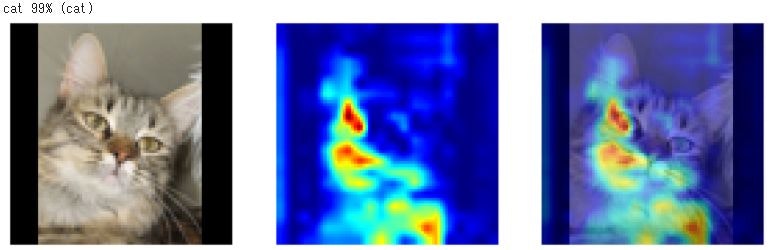



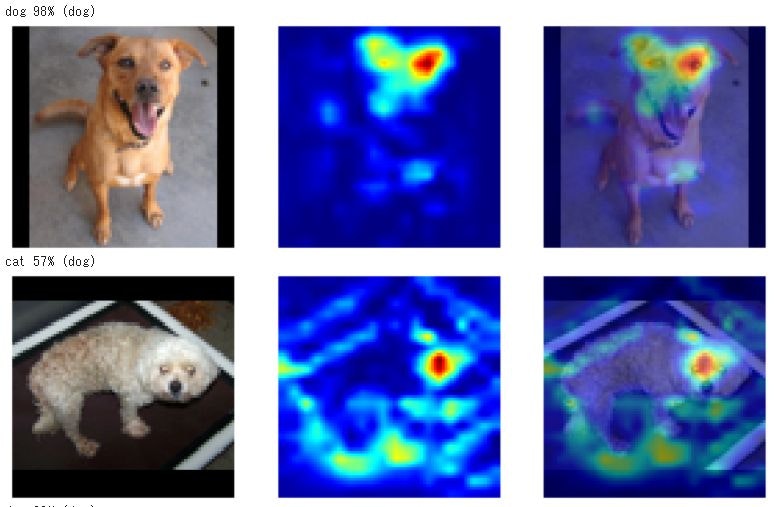
どうも、猫については耳とか目ではなく、体の模様とか、体のかたちとかを見ているような感じです。
犬のほうは、顔、特に鼻に注目しているようです。
1番目の画像例では、体形に注目していますが、それ以上に顔に注目した結果、僅差で犬と誤判定。
最後の画像例では、鼻に注目している一方で、体形、おそらく背中が丸くなっていることにも注目して、猫と誤判定したものと思われます。
2番目の例などは、猫そのものより周囲のほうに注意がいってて、おそらく、鼻とか犬の特徴がまったく見られないから猫と判定したのでは?
注目している箇所から考えてみると、AIは犬とか猫とかを「理解」して見分けているのではなく、特徴的な黒い部分(おそらく鼻)が有るか無いかだけで判別しているのではないか?
つまり、色や形のパターンは判別できている。しかし、それが何かは理解していないようだ。
参考サイト
kerasとtensorflowでGrad-CAMを実装してみた