背景
今更ながらGrad-CAMとGuided Grad-CAMを使う機会があったので、Keras実装のメジャーっぽいリポジトリを改造して利用したのですが、結構詰まりポイントが多かったので(私だけ?)復習もかねてソースコードを解説しようと思います。
そもそもGrad-CAM, Guided Grad-CAMとは?
簡単に言ってしまうと、CNNの判断根拠の可視化技術になります。
私は可視化については完全にビギナーなのですが、そんな私でも知ってるぐらい可視化の中ではメジャーどころなのではないでしょうか。
論文は2017に出されているので、おそらく発展手法(Grad-CAM++とか?)も沢山出ているとは思いますが、ビギナーなので情報の充実しているGrad-CAMを今回は使ってみました。
Grad-CAMの論文
見たことがあるかも知れませんがこちらがGrad-CAMとGuided Grad-CAMをかけた結果になります。
以下の場合、評価したモデルは入力画像を"犬"として分類しています。
| 入力画像 | Grad-CAM | Guided Grad-CAM |
|---|---|---|
 |
 |
 |
Grad-CAMではCNNが分類のために注視している範囲をカラーマップで表示してくれます。
Grad-CAMの発想は、予測クラスのoutput値に寄与の大きいところ(勾配の大きいところ)が分類予測を行う上で、重要な箇所なのではないか。といったものです。
勾配に関しては最後の畳み込み層(以下最後のconv層)の予測クラスのoutput値に対する勾配が用いられます。
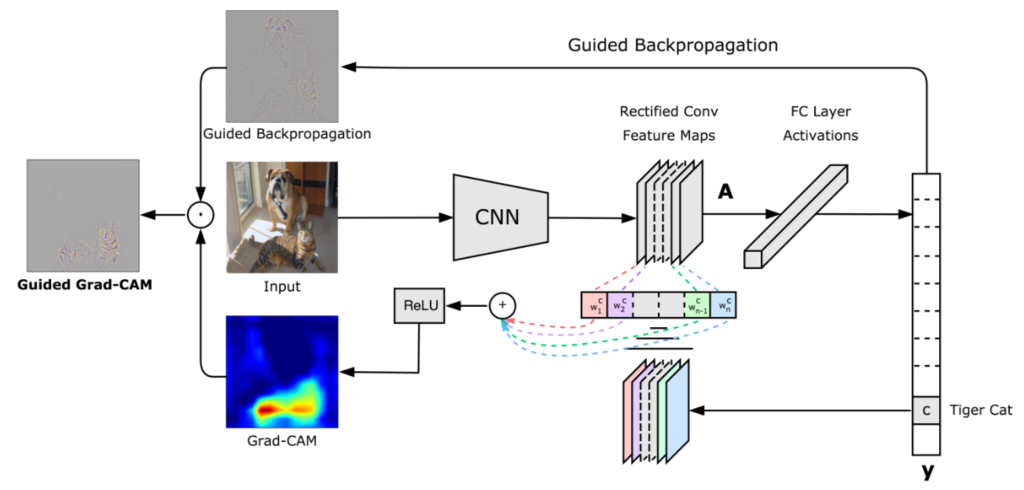
Guided Grad-CAMではより詳細にどういう特徴を拾って分類しているのかを可視化してくれます。
Guided Grad-CAMはGrad-CAMとGuidedBackPropagationを組み合わせて可視化する手法になります。
GuidedBackPropagationは以下の論文で提案されています。
基本的な発想は、最後のconv層に対する入力の勾配の大きいところを表示すれば、クラス分類に有意な情報を可視化できるのではないか。といったものです。
勾配を際立たせるために、順伝搬/逆伝搬で値がマイナスの部分は0に置き換えて、勾配計算を行います。
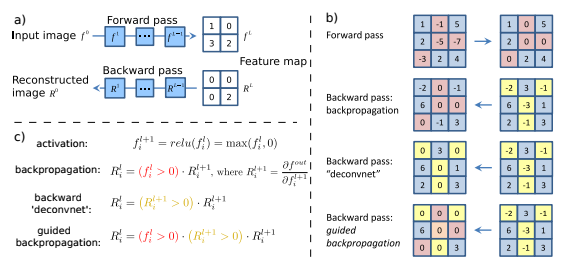
Striving for Simplicity: The All Convolutional Net
GuidedBackPropagationの結果とGrad-CAMのヒートマップの結果を足し合わせたものがGaided Grad-CAMとなります。
今回解説するリポジトリ
Grad-CAMのソースの解説
1. Grad-Camのmainの処理
mainの処理は
- 入力画像の読み込み
- モデルの読み込み
- 入力画像の予測確率(predictions)と予測クラス(predicted_class)の計算
- Grad-Camの計算
- 画像の保存
となっています。
「4. Grad-Camの計算」以外は特別な処理もないため、処理4のみ解説します。
# ① 入力画像の読み込み
# 入力画像を変換する場合はこちらを変更
preprocessed_input = load_image(sys.argv[1])
# preprocessed_input = load_image("./examples/boat.jpg")
# ② モデルの読み込み
# 自作モデルを使用する場合はこちらを変更
model = VGG16(weights='imagenet')
# ③ 入力画像の予測確率(predictions)と予測クラス(predicted_class)の計算
# VGG16以外のモデルを使用する際はtop_1=~から3行はコメントアウト
predictions = model.predict(preprocessed_input)
top_1 = decode_predictions(predictions)[0][0]
print('Predicted class:')
print('%s (%s) with probability %.2f' % (top_1[1], top_1[0], top_1[2]))
predicted_class = np.argmax(predictions)
# ④ Grad-Camの計算
# 自作モデルの場合、引数の"block5_conv3"を自作モデルの最終conv層のレイヤー名に変更.
cam, heatmap = grad_cam(model, preprocessed_input, predicted_class, "block5_conv3")
# ⑤ 画像の保存
cv2.imwrite("gradcam.jpg", cam)
2. grad_cam関数の処理
Grad-Camの計算は以下の手順で行われます。
- 入力画像の予測クラスを計算
- 予測クラスのLossを計算
- 予測クラスのLossから最後のconv層への逆伝搬(勾配)を計算
- 最後のconv層のチャンネル毎に勾配を平均(Global Average Pooling)を計算して、各チャンネルの重要度(重み)とする
- 最後のconv層の順伝搬の出力にチャンネル毎の重みをかけて、足し合わせて、ReLUを通す → heatmapの計算が出来た!!
- 入力画像とheatmapをかける → Grad-Camの計算が出来た!!!
詳細の説明についてはソースコードにコメントを入れる形で解説していきます。
def grad_cam(input_model, image, category_index, layer_name):
'''
Parameters
----------
input_model : model
評価するKerasモデル
image : tuple等
入力画像(枚数, 縦, 横, チャンネル)
category_index : int
入力画像の分類クラス
layer_name : str
最後のconv層の後のactivation層のレイヤー名.
最後のconv層でactivationを指定していればconv層のレイヤー名.
batch_normalizationを使う際などのようなconv層でactivationを指定していない場合は、
そのあとのactivation層のレイヤー名.
Returns
----------
cam : tuple
Grad-Camの画像
heatmap : tuple
ヒートマップ画像
'''
# 分類クラス数
nb_classes = 1000
# ----- 1. 入力画像の予測クラスを計算 -----
# 入力のcategory_indexが予想クラス
# ----- 2. 予測クラスのLossを計算 -----
# 入力データxのcategory_indexで指定したインデックス以外を0にする処理の定義
target_layer = lambda x: target_category_loss(x, category_index, nb_classes)
# 引数のinput_modelの出力層の後にtarget_layerレイヤーを追加
# modelのpredictをすると予測クラス以外の値は0になる
x = input_model.layers[-1].output
x = Lambda(target_layer, output_shape=target_category_loss_output_shape)(x)
model = keras.models.Model(input_model.layers[0].input, x)
# 予測クラス以外の値は0なのでsumをとって予測クラスの値のみ抽出
loss = K.sum(model.layers[-1].output)
# 引数のlayer_nameのレイヤー(最後のconv層)のoutputを取得する
conv_output = [l for l in model.layers if l.name is layer_name][0].output
# ----- 3. 予測クラスのLossから最後のconv層への逆伝搬(勾配)を計算 -----
# 予想クラスの値から最後のconv層までの勾配を計算する関数を定義
# 定義した関数の
# 入力 : [判定したい画像.shape=(1, 224, 224, 3)]、
# 出力 : [最後のconv層の出力値.shape=(1, 14, 14, 512), 予想クラスの値から最後のconv層までの勾配.shape=(1, 14, 14, 512)]
grads = normalize(K.gradients(loss, conv_output)[0])
gradient_function = K.function([model.layers[0].input], [conv_output, grads])
# 定義した勾配計算用の関数で計算し、データの次元を整形
# 整形後
# output.shape=(14, 14, 512), grad_val.shape=(14, 14, 512)
output, grads_val = gradient_function([image])
output, grads_val = output[0, :], grads_val[0, :, :, :]
# ----- 4. 最後のconv層のチャンネル毎に勾配を平均を計算して、各チャンネルの重要度(重み)とする -----
# weights.shape=(512, )
# cam.shape=(14, 14)
# ※疑問点1:camの初期化はzerosでなくて良いのか?
weights = np.mean(grads_val, axis = (0, 1))
cam = np.ones(output.shape[0 : 2], dtype = np.float32)
#cam = np.zeros(output.shape[0 : 2], dtype = np.float32) # 私の自作モデルではこちらを使用
# ----- 5. 最後のconv層の順伝搬の出力にチャンネル毎の重みをかけて、足し合わせて、ReLUを通す -----
# 最後のconv層の順伝搬の出力にチャンネル毎の重みをかけて、足し合わせ
for i, w in enumerate(weights):
cam += w * output[:, :, i]
# 入力画像のサイズにリサイズ(14, 14) → (224, 224)
cam = cv2.resize(cam, (224, 224))
# 負の値を0に置換。処理としてはReLUと同じ。
cam = np.maximum(cam, 0)
# 値を0~1に正規化。
# ※疑問2 : (cam - np.min(cam))/(np.max(cam) - np.min(cam))でなくて良いのか?
heatmap = cam / np.max(cam)
#heatmap = (cam - np.min(cam))/(np.max(cam) - np.min(cam)) # 私の自作モデルではこちらを使用
# ----- 6. 入力画像とheatmapをかける -----
# 入力画像imageの値を0~255に正規化. image.shape=(1, 224, 224, 3) → (224, 224, 3)
#Return to BGR [0..255] from the preprocessed image
image = image[0, :]
image -= np.min(image)
# ※疑問3 : np.uint8(image / np.max(image))でなくても良いのか?
image = np.minimum(image, 255)
# heatmapの値を0~255にしてカラーマップ化(3チャンネル化)
cam = cv2.applyColorMap(np.uint8(255*heatmap), cv2.COLORMAP_JET)
# 入力画像とheatmapの足し合わせ
cam = np.float32(cam) + np.float32(image)
# 値を0~255に正規化
cam = 255 * cam / np.max(cam)
return np.uint8(cam), heatmap
こちらのソースのなかで疑問点が3つあります。
分かる方いましたら是非教えてください。
- 疑問1 : camの初期化はzerosでなくて良いのか?
- KerasのVGG16でcat_dog.pngを読み込んだ際は、加重平均後のcamの値が-400~1065と1に対して大きいため問題になりませんが、私の自作モデルではcamの値が1に近かったためzerosで初期化しないとぼやけたヒートマップになってしまいました。
- 疑問2 : (cam - np.min(cam))/(np.max(cam) - np.min(cam))でなくて良いのか?
- 私の自作モデルでcamをzerosで初期化した際は問題にはならなくなりましたが、onesで初期化した際はcamの値が正規化前から0以上だったため、最大値を1に正規化するだけではヒートマップがぼけてしまいました。
- 疑問3 : np.uint8(image / np.max(image))でなくても良いのか?
私が自作モデルで使用する際は疑問1, 2の部分を変更して使っています。
Guided Grad-Camのソース解説
3. Guided Grad-Camのmain処理
mainの処理は
- GuidedBackPropagation用勾配の実装
- ReLUの勾配計算をGuidedBackPropagationの勾配計算に変更
- GaidedBackPropagation計算用の関数の定義
- GaidedBackPropagationの計算
- Guided Grad-CAMの計算
- 画像の保存
となっています。
ここでは本筋の処理である1~3の処理の関数について解説を行います。
# ① GuidedBackPropagation用勾配の実装
register_gradient()
# ② ReLUの勾配計算をGuidedBackPropagationの勾配計算に変更
guided_model = modify_backprop(model, 'GuidedBackProp')
# ③ GaidedBackPropagation計算用の関数の定義
# 自作クラスを使う場合は、こちらの引数に最後のconv層のレイヤー名を追加で指定
saliency_fn = compile_saliency_function(guided_model)
# ④ GaidedBackPropagationの計算
saliency = saliency_fn([preprocessed_input, 0])
# ⑤ Guided Grad-CAMの計算
gradcam = saliency[0] * heatmap[..., np.newaxis]
# ⑥ 画像の保存
cv2.imwrite("guided_gradcam.jpg", deprocess_image(gradcam))
4. register_gradient関数の処理
こちらの関数ではGuidedBackPropagationの処理を登録しています。
今回作成する勾配関数「_GuidedBackProp」の処理としては、
逆伝搬してきた勾配のうち、順伝搬/逆伝搬の値がマイナスのセルのみ0にして逆伝搬する
になります。
def register_gradient():
# GuidedBackPropが登録されていなければ登録
if "GuidedBackProp" not in ops._gradient_registry._registry:
# 自作勾配を登録するデコレーター
# 今回は_GuidedBackProp関数を"GuidedBackProp"として登録
@ops.RegisterGradient("GuidedBackProp")
def _GuidedBackProp(op, grad):
'''逆伝搬してきた勾配のうち、順伝搬/逆伝搬の値がマイナスのセルのみ0にして逆伝搬する'''
dtype = op.inputs[0].dtype
# grad : 逆伝搬してきた勾配
# tf.cast(grad > 0., dtype) : gradが0以上のセルは1, 0以下のセルは0の行列
# tf.cast(op.inputs[0] > 0., dtype) : 入力のが0以上のセルは1, 0以下のセルは0の行列
return grad * tf.cast(grad > 0., dtype) * \
tf.cast(op.inputs[0] > 0., dtype)
5. modify_backprop関数の処理
こちらの関数では、モデルのReLUの勾配を、定義した"GuidedBackoProp"に置き換えています。
def modify_backprop(model, name):
''' ReLU関数の勾配を"name"勾配に置き換える'''
# with内のReLUは"name"に置き換えられる
g = tf.get_default_graph()
with g.gradient_override_map({'Relu': name}):
# ▽▽▽▽▽ 疑問4 : 新規モデルをreturnしているのに、引数のモデルのreluの置き換えが必要なのか? ▽▽▽▽▽
# activationを持っているレイヤーのみ抜き出して配列化
# get layers that have an activation
layer_dict = [layer for layer in model.layers[1:]
if hasattr(layer, 'activation')]
# kerasのRelUをtensorflowのReLUに置き換え
# replace relu activation
for layer in layer_dict:
if layer.activation == keras.activations.relu:
layer.activation = tf.nn.relu
# △△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△
# 新しくモデルをインスタンス化
# 自作モデルを使用する場合はこちらを修正
# re-instanciate a new model
new_model = VGG16(weights='imagenet')
return new_model
こちらの処理での疑問点としては疑問4の引数のモデルのKeras ReLUをtensorflow ReLUに置き換えているところです。
戻り値として新規作成したインスタンスを返しているのに、引数のモデルを変更して意味があるのかがわかりませんでした。
私の環境で試したところ 「# ▽▽~」と「#△△~」の間をすべてコメントアウトしても、動作が変わらないように思えました。
6. compile_saliency_function関数の処理
こちらの処理では指定レイヤーに対する入力の勾配を計算する関数を作成しています。
def compile_saliency_function(model, activation_layer='block5_conv3'):
'''指定レイヤーのチャンネル方向最大値に対する入力の勾配を計算する関数の作成'''
# モデルのインプット
input_img = model.input
# 入力層の次の層以降をレイヤー名とインスタンスの辞書として保持
layer_dict = dict([(layer.name, layer) for layer in model.layers[1:]])
# 引数で指定したレイヤー名のインスタンスの出力を取得 shape=(?, 14, 14, 512)
layer_output = layer_dict[activation_layer].output
# チャンネル方向に最大値を取る shape=(?, 14, 14)
max_output = K.max(layer_output, axis=3)
# 指定レイヤーのチャンネル方向最大値に対する入力の勾配を計算する関数
saliency = K.gradients(K.sum(max_output), input_img)[0]
return K.function([input_img, K.learning_phase()], [saliency])
まとめ
今回はGrad-CAMとGuided Grad-CAMのソースコードの処理について詳細に解説してみました。
疑問点がいくつかあるのでタイトルは誇大広告気味ですが、わかる方がいらしたら是非教えてください。
Gitリポジトリ
今回解説したコメント入りのソースになります。
kinziro/keras-grad-cam
参考にさせて頂いたサイト
Grad-Cam関係
ディープラーニングの判断根拠を理解する手法
Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization