「ゼロから作るDeep Learning」(斎藤 康毅 著 オライリー・ジャパン刊)を読んでいる時に、参照したサイト等をメモしていきます。 その6← →その6の3 → その7
お仕着せのMNISTデータセットを読み込んで、学習させるというのを2通りやってみましたが、MNISTデータセットではない画像集をMNISTの形式に変換して学習させる、というのもやってみようかと思います。
元データは、Kaggleの猫と犬のデータセット。下記サイトからダウンロードできます。
https://www.microsoft.com/en-us/download/details.aspx?id=54765
けっこう大きなファイルで、ダウンロードにも解凍にも時間がかかります。
ダウンロードした画像データの内容を調べて見る
ダウンロードしたファイルの中身
フォルダ PetImages の下にあるフォルダ Cat と Dog に、画像が入っています。
画像はカラーで、大きさはそれぞれ違っています。
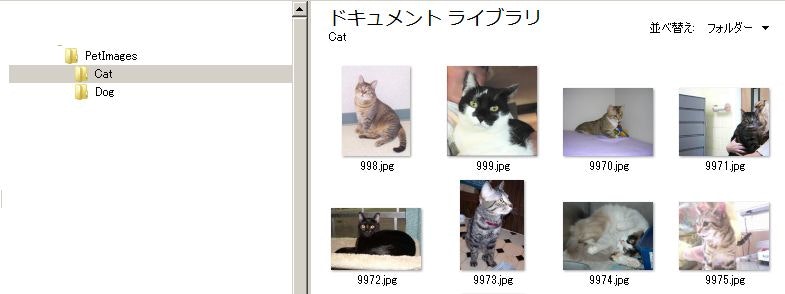
0.jpg から 12499.jpg とファイル名が連番になっていますので、犬、猫それぞれ 12500枚 ずつの画像があるということになります。
画像情報を配列に格納する
MNISTデータセットと同じようにするためには、
カラーをグレースケールにする
同じ大きさにそろえる
といった加工をしてから配列に格納しなければなりません。
まずは、画像データを1枚確認してみます。
import os.path
import matplotlib.pyplot as plt
from matplotlib.image import imread
dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset/Cat'
imgData = imread(dataset_dir + '/0.jpg')
plt.imshow(imgData)
plt.show()

この画像をNumPy配列に格納してみます。
import numpy as np
img = np.array(imgData)
print(img.ndim)
print(img.shape)
結果は
3
(375, 500, 3)
(高さ, 幅, 色)の3次元の配列として格納されているようです。
で、色が 0は赤、1が緑、2が青 ということらしいので、
確認してみます。
配列img と同じ形の配列imgRを0で初期化して、
imgの赤のデータだけをimgRに格納して表示してみます。
imgR = np.zeros_like(img)
imgR[:, :, 0] = img[:, :, 0]
plt.imshow(imgR)
plt.show()

確かに赤いですね。
同様に緑と青も確認。
imgG = np.zeros_like(img)
imgG[:, :, 1] = img[:, :, 1]
plt.imshow(imgG)
plt.show()
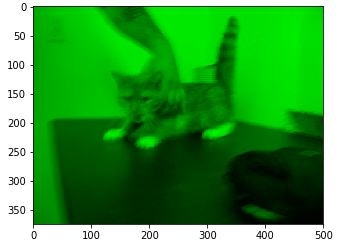
imgB = np.zeros_like(img)
imgB[:, :, 2] = img[:, :, 2]
plt.imshow(imgB)
plt.show()

念のため、RGBに分けた配列を集計して表示してみます。
imgRGB = np.zeros_like(img)
imgRGB = imgR + imgG + imgB
plt.imshow(imgRGB)
plt.show()

ちゃんと元の画像に戻りました。
グレースケールにしてみる
ライブラリPillowを使って、グレースケールに変換してみます。
from PIL import Image
imgGray = np.array(Image.open(dataset_dir + '/0.jpg').convert('L'))
print(imgGray.ndim)
print(imgGray.shape)
plt.imshow(imgGray,cmap=plt.cm.gray)
plt.show()
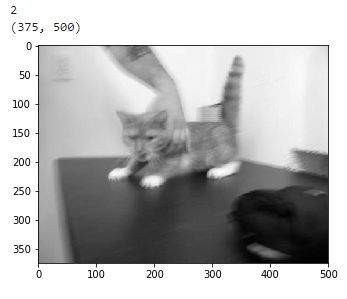
2次元の配列として格納されています。
上のほうで、RGBに分けて画像を処理してましたが、もしかしてRGBに同じ数値を入れればグレーになるのでは? と考えて、こんなことしてみました。
img=Image.open(dataset_dir + '/0.jpg')
imgN = np.array(img)
img0 = np.zeros_like(imgN)
img0[:,:,0]=imgN[:,:,0]
img0[:,:,1]=imgN[:,:,0]
img0[:,:,2]=imgN[:,:,0]
plt.imshow(img0)
plt.show()

グレーになりましたが、赤色部分だけなので、ちょっと感じが違います。
img=Image.open(dataset_dir + '/0.jpg')
imgN = np.array(img)
w, h, c =imgN.shape
imgX=np.zeros((w,h))
imgX[:,:]=imgN[:,:,0]//3 + imgN[:,:,1]//3 + imgN[:,:,2]//3
plt.imshow(imgX,cmap=plt.cm.gray)
plt.show()

なんかそれっぽくなりました。
リサイズしてみる
Pillowのresizeメソッドで256×256にしてみます。
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.image import imread
from PIL import Image
img=Image.open(dataset_dir + '/0.jpg').convert('L').resize((256, 256))
imgResize = np.array(img)
print(imgResize.ndim)
print(imgResize.shape)
plt.imshow(imgResize,cmap=plt.cm.gray)
plt.show()

指定した大きさになりましたが、縦横の比率が変わってしまいました。画質も不鮮明に。
ためしにMNISTと同じ28×28の大きさにしてみると
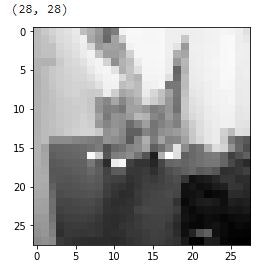
何の画像なのか、まったくわからなくなりました。
これとは反対に、元の画像のサイズが小さいものもあって、5534.jpgは 36×60 です。

これを256×256にリサイズすると、こうなります。

pillow を使わないで画像をリサイズ等する方法は その19の2
配列 dataset に画像データを格納する
猫12500枚のうち、最初の500枚をテストデータとし、残り12000枚を訓練データにします。犬も同様。
データは100×100のグレースケールに変換して、datasetに格納します。縦横の比率や画像の鮮明さが変わるのは無視します。
ラベルは、0:猫、1:犬 ということにして、datasetに格納するときに付加します。
フォルダ内の.jpgファイルを反復処理するために、次のようなプログラムを組んでみました。犬と猫はフォルダ別に分かれているので、フォルダ別に処理しています。
学習の際に与えるデータは犬猫がランダムに混在している必要はないはずだし、ミニバッチ処理ではランダムに抽出するので、これで問題はないと思います。
# 学習用データ編集
import os
import glob
from PIL import Image
import numpy as np
dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset'
catfiles = glob.glob(dataset_dir + '/Cat/*.jpg')
dogfiles = glob.glob(dataset_dir + '/Dog/*.jpg')
tsl = []
tsi = []
trl = []
tri = []
tst_count = 0
trn_count = 0
count = 0
for f in catfiles:
lblA = 0
img = Image.open(f).convert('L').resize((100, 100))
imgA = np.array(img)
imgA = imgA.flatten()
imgA = imgA.tolist()
if count < 500:
tsl.append(lblA)
tsi.append(imgA)
tst_count += 1
else:
trl.append(lblA)
tri.append(imgA)
trn_count += 1
count += 1
・
・
・
が、EXIFデータが壊れていると思われる、というメッセージが出て中断します。
C:\Users\021133\AppData\Local\Continuum\anaconda3\lib\site-packages\PIL\TiffImagePlugin.py:747: UserWarning: Possibly corrupt EXIF data. Expecting to read 80000 bytes but only got 0. Skipping tag 64640
" Skipping tag %s" % (size, len(data), tag))
C:\Users\021133\AppData\Local\Continuum\anaconda3\lib\site-packages\PIL\TiffImagePlugin.py:747: UserWarning: Possibly corrupt EXIF data. Expecting to read 65536 bytes but only got 0. Skipping tag 3
" Skipping tag %s" % (size, len(data), tag))
C:\Users\021133\AppData\Local\Continuum\anaconda3\lib\site-packages\PIL\TiffImagePlugin.py:747: UserWarning: Possibly corrupt EXIF data. Expecting to read 404094976 bytes but only got 0. Skipping tag 5
" Skipping tag %s" % (size, len(data), tag))
C:\Users\021133\AppData\Local\Continuum\anaconda3\lib\site-packages\PIL\TiffImagePlugin.py:747: UserWarning: Possibly corrupt EXIF data. Expecting to read 404619264 bytes but only got 0. Skipping tag 5
" Skipping tag %s" % (size, len(data), tag))
C:\Users\021133\AppData\Local\Continuum\anaconda3\lib\site-packages\PIL\TiffImagePlugin.py:747: UserWarning: Possibly corrupt EXIF data. Expecting to read 131072 bytes but only got 0. Skipping tag 3
" Skipping tag %s" % (size, len(data), tag))
・・・
OverflowError: Python int too large to convert to C ssize_t
調べて見ると、ファイル読み込みの繰り返し処理では、次のような順番でファイルを処理していました。この順番で826番目のファイル 1074.jpg でエラーが発生しています。
C:\Users\021133/dataset/Cat\0.jpg
C:\Users\021133/dataset/Cat\1.jpg
C:\Users\021133/dataset/Cat\10.jpg
C:\Users\021133/dataset/Cat\100.jpg
C:\Users\021133/dataset/Cat\1000.jpg
C:\Users\021133/dataset/Cat\10000.jpg
C:\Users\021133/dataset/Cat\10001.jpg
C:\Users\021133/dataset/Cat\10002.jpg
C:\Users\021133/dataset/Cat\10003.jpg
C:\Users\021133/dataset/Cat\10004.jpg
C:\Users\021133/dataset/Cat\10005.jpg
C:\Users\021133/dataset/Cat\10006.jpg
C:\Users\021133/dataset/Cat\10007.jpg
C:\Users\021133/dataset/Cat\10008.jpg
C:\Users\021133/dataset/Cat\10009.jpg
C:\Users\021133/dataset/Cat\1001.jpg
C:\Users\021133/dataset/Cat\10010.jpg
問題の写真とそのプロパティはこれ。
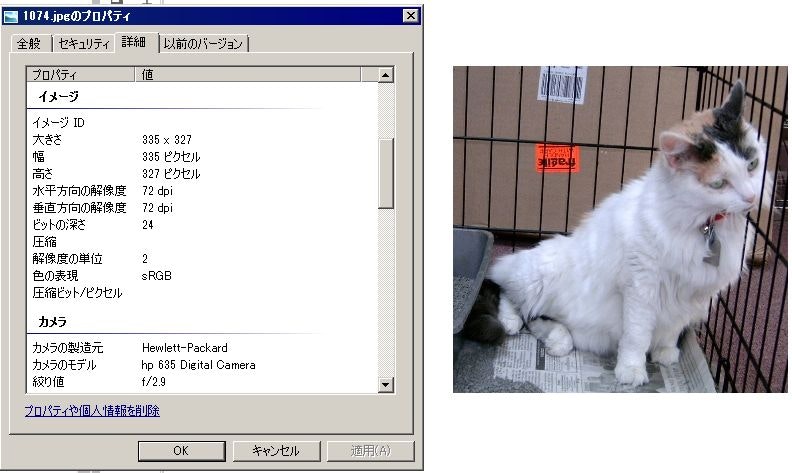
何が悪いのかよくわかりません。
しかたないので、エラーはエラーとして例外処理にして、その後の処理を継続できるようにしました。
# 学習用データ編集
import os
import glob
from PIL import Image
import numpy as np
dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset'
catfiles = glob.glob(dataset_dir + '/Cat/*.jpg')
dogfiles = glob.glob(dataset_dir + '/Dog/*.jpg')
tsl = []
tsi = []
trl = []
tri = []
tst_count = 0
trn_count = 0
count = 0
for f in catfiles:
try:
lblA = 0
img = Image.open(f).convert('L').resize((100, 100))
imgA = np.array(img)
imgA = imgA.flatten()
imgA = imgA.tolist()
except:
print(str(count)+":"+f+" error")
if count < 500:
tsl.append(lblA)
tsi.append(imgA)
tst_count += 1
else:
trl.append(lblA)
tri.append(imgA)
trn_count += 1
count += 1
count = 0
for f in dogfiles:
try:
lblA = 1
img = Image.open(f).convert('L').resize((100, 100))
imgA = np.array(img)
imgA = imgA.flatten()
imgA = imgA.tolist()
except:
print(str(count)+":"+f+" error")
if count < 500:
tsl.append(lblA)
tsi.append(imgA)
tst_count += 1
else:
trl.append(lblA)
tri.append(imgA)
trn_count += 1
count += 1
dataset = {}
dataset['test_label'] = np.array(tsl, dtype=np.uint8)
dataset['test_img'] = np.array(tsi, dtype=np.uint8)
dataset['train_label'] = np.array(trl, dtype=np.uint8)
dataset['train_img'] = np.array(tri, dtype=np.uint8)
結局、猫で3件、犬で3件異常データがありました。
825:C:\Users\021133/dataset/Cat\1074.jpg error
7088:C:\Users\021133/dataset/Cat\5127.jpg error
8790:C:\Users\021133/dataset/Cat\666.jpg error
1895:C:\Users\021133/dataset/Dog\11702.jpg error
10601:C:\Users\021133/dataset/Dog\829.jpg error
10686:C:\Users\021133/dataset/Dog\8366.jpg error
異常があった画像のところには、直前に格納した画像と同じものが格納されてしまっていますが、まあ、実害はないだろうから、このまま進めていく事にします。
この処理では画像サイズを100×100と、比較的大きめにしているので、メモリエラーになったりします。
MemoryError Traceback (most recent call last)
in ()
65 dataset['test_img'] = np.array(tsi, dtype=np.uint8)
66 dataset['train_label'] = np.array(trl, dtype=np.uint8)
---> 67 dataset['train_img'] = np.array(tri, dtype=np.uint8)
MemoryError:
こうなると、同時に立ち上がっているプログラムをとめたり、再起動して使用していたメモリを開放したり、画像サイズを変えたり、処理件数を減らしたりと、いろいろやらないといけなくなります。
結局、猫と犬を別々に処理して、最終結果を連結することにしました。
まず、猫の処理をして、結果をpickleで退避
# 学習用データ編集
import os
import glob
from PIL import Image
import numpy as np
dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset'
catfiles = glob.glob(dataset_dir + '/Cat/*.jpg')
dogfiles = glob.glob(dataset_dir + '/Dog/*.jpg')
tsl = []
tsi = []
trl = []
tri = []
tst_count = 0
trn_count = 0
count = 0
for f in catfiles:
try:
lblA = 0
img = Image.open(f).convert('L').resize((100, 100))
imgA = np.array(img)
imgA = imgA.flatten()
imgA = imgA.tolist()
except:
print(str(count)+":"+f+" error")
if count < 500:
tsl.append(lblA)
tsi.append(imgA)
tst_count += 1
else:
trl.append(lblA)
tri.append(imgA)
trn_count += 1
count += 1
cat = {}
cat['test_label'] = np.array(tsl, dtype=np.uint8)
cat['test_img'] = np.array(tsi, dtype=np.uint8)
catlabel = np.array(trl, dtype=np.uint8)
catimg = np.array(tri, dtype=np.uint8)
import pickle
dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset'
save_file = dataset_dir + '/tempcat.pkl'
with open(save_file, 'wb') as f:
pickle.dump(cat, f, -1)
save_file = dataset_dir + '/tempcatL.pkl'
with open(save_file, 'wb') as f:
pickle.dump(catlabel, f, -1)
save_file = dataset_dir + '/tempcatI.pkl'
with open(save_file, 'wb') as f:
pickle.dump(catimg, f, -1)
次に、途中経過をクリアしてから、犬の処理
import gc
del tsl
del tsi
del trl
del tri
del cat
del catlabel
del catimg
gc.collect()
# 学習用データ編集
import os
import glob
from PIL import Image
import numpy as np
dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset'
catfiles = glob.glob(dataset_dir + '/Cat/*.jpg')
dogfiles = glob.glob(dataset_dir + '/Dog/*.jpg')
tsl = []
tsi = []
trl = []
tri = []
tst_count = 0
trn_count = 0
count = 0
for f in dogfiles:
try:
lblA = 1
img = Image.open(f).convert('L').resize((100, 100))
imgA = np.array(img)
imgA = imgA.flatten()
imgA = imgA.tolist()
except:
print(str(count)+":"+f+" error")
if count < 500:
tsl.append(lblA)
tsi.append(imgA)
tst_count += 1
else:
trl.append(lblA)
tri.append(imgA)
trn_count += 1
count += 1
dog = {}
dog['test_label'] = np.array(tsl, dtype=np.uint8)
dog['test_img'] = np.array(tsi, dtype=np.uint8)
doglabel = np.array(trl, dtype=np.uint8)
dogimg = np.array(tri, dtype=np.uint8)
import pickle
dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset'
save_file = dataset_dir + '/tempdog.pkl'
with open(save_file, 'wb') as f:
pickle.dump(dog, f, -1)
save_file = dataset_dir + '/tempdogL.pkl'
with open(save_file, 'wb') as f:
pickle.dump(doglabel, f, -1)
save_file = dataset_dir + '/tempdogI.pkl'
with open(save_file, 'wb') as f:
pickle.dump(dogimg, f, -1)
いったん終わらせてメモリをクリアしてから、退避した結果を読み込んで、連結します。
テスト用データの連結。
import os.path
import pickle
import numpy as np
dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset'
mnist_file = dataset_dir + '/tempcat.pkl'
with open(mnist_file, 'rb') as f:
cat = pickle.load(f)
mnist_file = dataset_dir + '/tempdog.pkl'
with open(mnist_file, 'rb') as f:
dog = pickle.load(f)
dataset = {}
dataset['test_label'] = np.append(cat['test_label'],dog['test_label'], axis=0)
dataset['test_img'] = np.append(cat['test_img'],dog['test_img'], axis=0)
import pickle
dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset'
save_file = dataset_dir + '/catdogmnist.pkl' #拡張子は.pkl
with open(save_file, 'wb') as f:
pickle.dump(dataset, f, -1)
訓練用データの連結。データが大きいため、ラベルと画像を別々にしている。
import os.path
import pickle
import numpy as np
dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset'
mnist_file = dataset_dir + '/tempcatL.pkl'
with open(mnist_file, 'rb') as f:
cat = pickle.load(f)
mnist_file = dataset_dir + '/tempdogL.pkl'
with open(mnist_file, 'rb') as f:
dog = pickle.load(f)
catdog = np.append(cat,dog, axis=0)
save_file = dataset_dir + '/catdogL.pkl'
with open(save_file, 'wb') as f:
pickle.dump(catdog, f, -1)
mnist_file = dataset_dir + '/tempcatI.pkl'
with open(mnist_file, 'rb') as f:
cat = pickle.load(f)
mnist_file = dataset_dir + '/tempdogI.pkl'
with open(mnist_file, 'rb') as f:
dog = pickle.load(f)
catdog = np.append(cat,dog, axis=0)
save_file = dataset_dir + '/catdogI.pkI'
with open(save_file, 'wb') as f:
pickle.dump(catdog, f, -1)
学習させてみる
# 2層ニューラルネットワークのクラス
import numpy as np
from common.functions import *
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# 重みの初期化
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
# x:入力データ、 t:教師データ
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def gradient(self, x, t):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
grads = {}
batch_num = x.shape[0]
# forward
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
# backward
dy = (y - t) / batch_num
grads['W2'] = np.dot(z1.T, dy)
grads['b2'] = np.sum(dy, axis=0)
dz1 = np.dot(dy, W2.T)
da1 = sigmoid_grad(a1) * dz1
grads['W1'] = np.dot(x.T, da1)
grads['b1'] = np.sum(da1, axis=0)
return grads
# 4.5.2 ミニバッチ学習の実装
import sys, os
import pickle
import numpy as np
from common.functions import *
def to_one_hot(label):
t = np.zeros((label.size, 2))
for i in range(label.size):
t[i][label[i]] = 1
return t
dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset'
mnist_file = dataset_dir + '/catdogI.pkl'
with open(mnist_file, 'rb') as f:
catdogImg = pickle.load(f)
x_train = catdogImg.astype(np.float16)
x_train /= 255
catdogImg = []
mnist_file = dataset_dir + '/catdogL.pkl'
with open(mnist_file, 'rb') as f:
catdogLabel = pickle.load(f)
t_train = to_one_hot(catdogLabel)
# ハイパーパラメータ
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
network = TwoLayerNet(input_size=10000, hidden_size=50, output_size=2)
for i in range(iters_num):
# ミニバッチの取得
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 勾配の計算
grad = network.gradient(x_batch, t_batch) # 誤差逆伝播法 速い
# パラメータの更新
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
#学習経過の記録
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
# networkオブジェクトを、pickleで保存する。保存したオブジェクトは、推論処理で使う
import pickle
save_file = dataset_dir + '/catdogkekka_weight.pkl' #拡張子は.pkl
with open(save_file, 'wb') as f:
pickle.dump(network, f, -1)
これは、訓練データの読み込み部分以外は、これまで使ってきたプログラムと同じです。
学習したニューロネットで推論させてみる
import numpy as np
from common.functions import *
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# 重みの初期化
self.params = {}
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
import sys, os
import pickle
def normalize(key):
dataset[key] = dataset[key].astype(np.float32)
dataset[key] /= 255
return dataset[key]
def to_one_hot(label):
T = np.zeros((label.size, 10))
for i in range(label.size):
T[i][label[i]] = 1
return T
dataset_dir = os.path.dirname(os.path.abspath('__file__'))+'/dataset'
mnist_file = dataset_dir + '/catdogmnist.pkl'
with open(mnist_file, 'rb') as f:
dataset = pickle.load(f)
x = normalize('test_img')
t = dataset['test_label']
# network = TwoLayerNet(input_size=10000, hidden_size=50, output_size=10)
weight_file = dataset_dir + '/catdogkekka_weight.pkl'
with open(weight_file, 'rb') as f:
network = pickle.load(f)
accuracy_cnt = 0
for i in range(len(x)):
y = network.predict(x[i])
p= np.argmax(y)
if p == t[i]:
accuracy_cnt += 1
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
これも、これまで使ったプログラムと同じものです。
結果は
Accuracy:0.615
となっており、あてずっぽうより少しマシ、というレベル。
ccnt = np.zeros(2, dtype=np.int)
ecnt = np.zeros((2, 2), dtype=np.int)
for i in range(len(x)):
y = network.predict(x[i])
c = t[i]
p= np.argmax(y)
if p == c:
ccnt[c] += 1
else:
ecnt[p, c] += 1
print(ccnt)
print(ecnt)
[195 420]
[[ 0 80]
[305 0]]
1000件中725件を「犬」と判定している。うち420件が正解で、正解率58%。
275件を「猫」と判定し、195件正解で、正解率70%。
判定が犬に偏っています。
ところが、もう一度学習をし直すと、今度は猫に偏りました。
この形式のデータでは、犬か猫かの特長を明確につかめていないのかもしれません。
参考にしたサイト
今回は、画像データの処理について学習しました。
オリジナルの画像からデータセットを作成する方法
画像処理その3 ~NumPy配列~
Pythonの画像処理ライブラリPillow(PIL)の使い方
Pillowで画像を一括リサイズ(拡大・縮小)
PIL/Pillow チートシート
matplotlibのcmap(colormap)パラメータの一覧
また、pythonの list と numpy.ndarray の違いがよくわかっていなかったことを思い知らされました。
Pythonのリストと配列とnumpy.ndarrayの違いと使い分け
deep learning では、メモリを大量消費することもわかりました。