なぜ自然言語処理にとって単語の分散表現は重要なのでしょうか?
この記事をご覧になっている方は Word2vec(Mikolov et al., 2013) についてご存知かもしれません。Word2vec ではまるで単語の意味を捉えられているかのような演算を行うことができます。例えば King から Man を引き Woman を足すと Queen が得られる(King - Man + Woman = Queen)というのは有名な例です。
 from https://www.tensorflow.org/get_started/embedding_viz
from https://www.tensorflow.org/get_started/embedding_viz
実はその内部では、単語を分散表現(あるいは埋め込み表現)と呼ばれる200次元ほどのベクトルで表現してベクトルの足し引きを行っています。この200次元ほどのベクトル内部に各単語の特徴が格納されていると考えられています。そのため、ベクトルの足し引きで意味のありそうな結果を得られるのです。
**単語の分散表現は現在の自然言語処理で当たり前のように使われる重要な技術です。**最近は自然言語処理の研究でも膨大な数のニューラルネットワーク(NN)ベースのモデルが提案されています。これらNNベースのモデルでは、単語の分散表現を入力として使うことが多いのです。
この記事では、「なぜ自然言語処理にとって単語の分散表現が重要なのか?」を説明します。説明の流れは、まず単語の分散表現について簡単に説明し、理解を共有します。その次に、メインテーマである単語の分散表現が自然言語処理にとって重要な理由を説明します。最後に、分散表現が抱えている課題について説明します。
単語の分散表現とは?
ここでは単語の 分散表現 の理解を目的とし、簡単に説明を行います。そのメリットを述べるための比較対象として、単語の one-hot表現 についても説明します。話の流れとしては、one-hot表現とその課題について説明した後、分散表現の説明に移ります。
one-hot表現
単語をベクトルで表現する方法としてまず考えられるのはone-hot表現です。one-hot表現というのはある要素のみが1でその他の要素が0であるような表現方法のことです。各次元に 1 か 0 を設定することで「その単語か否か」を表します。
例えば、one-hot表現でpythonという単語を表すとしましょう。ここで、単語の集合であるボキャブラリは(nlp, python, word, ruby, one-hot)の5単語とします。そうすると、pythonを表すベクトルは以下のようになります。
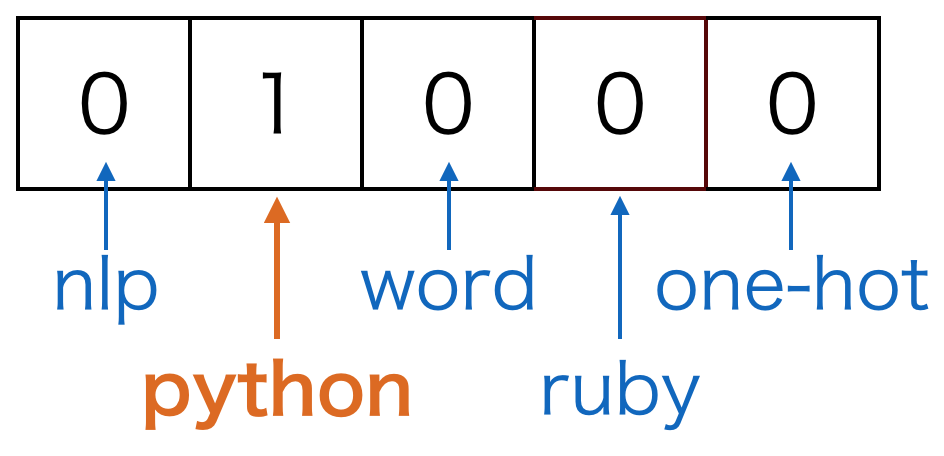
one-hot表現はシンプルですが、ベクトル間の演算で何も意味のある結果を得られないという弱点があります。例えば、単語間で類似度を計算するために内積を取るとしましょう。one-hot表現では異なる単語は別の箇所に1が立っていてその他の要素は0なので、異なる単語間の内積を取った結果は0になってしまいます。これは望ましい結果とは言えません。また、1単語に1次元を割り当てるので、ボキャブラリ数が増えると非常に高次元になってしまいます。
分散表現
それに対して分散表現は、単語を低次元の実数値ベクトルで表す表現です。だいたい50次元から300次元くらいで表現することが多いです。例えば、先ほど挙げた単語を分散表現で表すと以下のように表せます。

分散表現を使うことでone-hot表現が抱えていた問題を解決できます。例えば、ベクトル間の演算で単語間の類似度を計算することができるようになります。上のベクトルを見ると、python と ruby の類似度は python と word の類似度よりも高くなりそうです。また、ボキャブラリ数が増えても各単語の次元数を増やさずに済みます。
なぜ単語の分散表現は重要なのか?
この節では、自然言語処理における単語の分散表現の重要性について説明します。話の流れとしては、自然言語処理タスクへの入力の話をした後、入力として分散表現を使う話をします。そして、この分散表現がタスクの性能に影響を与える話をします。
自然言語処理には様々なタスクがありますが、多くのタスクでは入力として単語列を与えます。具体的には、文書分類であれば文書に含まれる単語の集合を入力します。品詞タグ付けなら分かち書きされた単語列を与えますし、固有表現認識も同様に分かち書きした単語列を与えます。以下のようなイメージです。
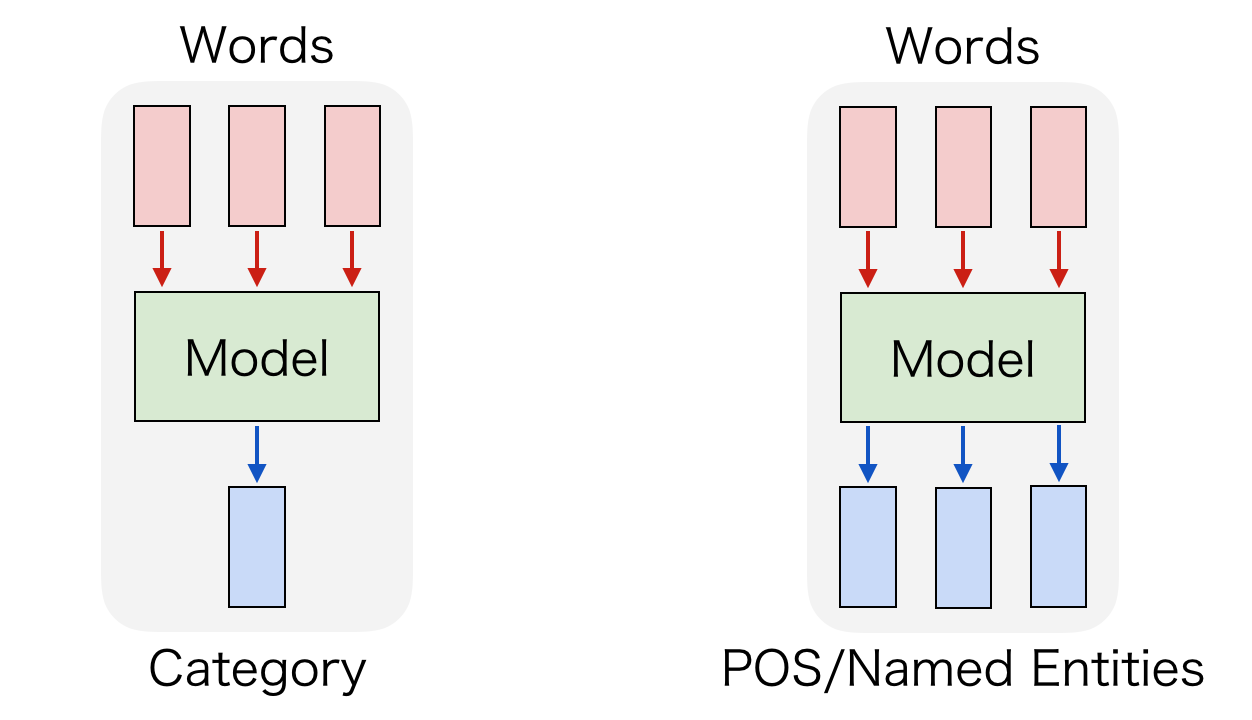
最近の自然言語処理ではニューラルネットワークを使うことも多いですが、入力として単語列を与えることが多いのは変わりません。従来からよく使われている RNN へ入力するのも単語ですし、最近注目されている CNN を使ったモデルに対する入力も単語レベルで入力することが多いです。以下のようなイメージです。
実はこれらニューラルネットワークへ与える単語の表現として分散表現を使うことが多いのです1。単語の意味をよりよく捉えている表現を入力として使えば、タスクの性能も向上するだろう、という期待に基づいています。また、大量のラベルなしデータを使って学習した分散表現をネットワークの初期値として使い、少量のラベル付きデータを使ってチューニングするということも行われます。
この分散表現がタスクの性能を左右するので重要なのです。分散表現を使わない場合と比べて性能が向上することも報告されています[2]。このように、多くのタスクの入力として使われることが多く、また性能に少なからず影響を及ぼすので単語の分散表現は重要なのです。
単語の分散表現が抱えている課題
単語の分散表現が自然言語処理における銀の弾丸かというとそうではありません。多くの研究の結果、様々な問題があることがわかっています。ここではその中から2つ選んで紹介します。
問題1: 実際のタスクで使用すると思ったより性能が向上しない
一つ目の問題として取り上げるのは、評価データセットで良い結果でも実際のタスク(文書分類など)で使用すると思っているより性能が向上しない、という問題です。そもそも単語の分散表現がどのように評価されているかというと、多くの場合、人間が作成した単語類似度の評価セットとの相関度で評価されます(Schnabel, Tobias, et al, 2015)。つまり、人間の評価と相関する結果を出せるモデルで得られた分散表現を実際のタスクに使用しても性能が向上しないのです。
原因としては、ほとんどの評価データセットでは単語の類似性と関連性を区別していないことが挙げられています。単語の類似性と関連性というのは、たとえば(male, man)は類似していて、(computer, keyboard)は関連しているけど類似していないという話です。区別しているデータセットでは実際のタスクとの間に性能の正の相関が見られることが報告されています(Chiu, Billy, Anna Korhonen, and Sampo Pyysalo, 2016)。
そのため、現在は実際のタスクと相関する評価データセットの作成が試みられています(Oded Avraham, Yoav Goldberg, 2016)。ここでは既存のデータセットに存在する2つの問題(単語の類似性と関連性を区別していない、評価者間でアノテーションスコアがばらつく)の解決を試みています。
また、評価データセットの作成以外にも実際のタスクを簡単に評価できるようにして分散表現を評価するといった研究が行われています(Nayak, Neha, Gabor Angeli, and Christopher D. Manning, 2016)。これにより、学習した分散表現が実際に行いたいタスクに近いタスクで有効なのかを簡単に検証できるようになることが期待されています。
個人的には新たなデータセットやタスクで評価することによって、今まで埋もれていたモデルが見直されるのではないかと期待しています。
問題2: 単語の曖昧性を考慮していない
二つ目の問題として取り上げるのは、現在の分散表現は単語の曖昧性を考慮していない、という問題です。単語には様々な意味があります。例えば、"bank" という単語は "銀行" という意味以外にも "土手" という意味があります。このように単語の多義性を考慮せず、一つのベクトルで表すのは限界があります。
この問題に対して、語義ごとに表現を学習する手法がいくつか提案されています[5][6][7][8]。SENSEEMBEDでは語義曖昧性解消をして語義ごとの表現を学習しています。語義ごとの表現を学習した結果、単語類似性評価での性能が向上したと報告されています。
さらに詳しく知りたい人のために
以下のリポジトリでは単語や文の分散表現に関する論文や学習済みベクトル、Python実装の情報をまとめています。
awesome-embedding-models
スターをつけていただけると励みになりますm(_ _)m
おわりに
単語の分散表現は活発に研究されている面白い分野です。この記事が皆様の理解の一助となれば幸いです。
以下のTwitterアカウントで 機械学習 / 自然言語処理 / コンピュータビジョン に関する最新の論文情報をわかりやすく配信しています。この記事を読んでくれた方にとって興味深い内容を配信していますので、フォローお待ちしています。
@arXivTimes
また、私のアカウントでも機械学習や自然言語処理に関する情報をつぶやいていますので、この分野に興味のある方のフォローをお待ちしています。
@Hironsan
注釈
参考資料
- Mikolov, Tomas, et al. "Efficient estimation of word representations in vector space." arXiv preprint arXiv:1301.3781 (2013).
- Pennington, Jeffrey, Richard Socher, and Christopher D. Manning. "Glove: Global Vectors for Word Representation." EMNLP. Vol. 14. 2014.
- Schnabel, Tobias, et al. "Evaluation methods for unsupervised word embeddings." EMNLP. 2015.
- Chiu, Billy, Anna Korhonen, and Sampo Pyysalo. "Intrinsic evaluation of word vectors fails to predict extrinsic performance." ACL 2016 (2016): 1.
- Oded Avraham, Yoav Goldberg. "Improving Reliability of Word Similarity Evaluation by Redesigning Annotation Task and Performance Measure." arXiv preprint arXiv:1611.03641 (2016).
- Nayak, Neha, Gabor Angeli, and Christopher D. Manning. "Evaluating Word Embeddings Using a Representative Suite of Practical Tasks." ACL 2016 (2016): 19.
- Trask, Andrew, Phil Michalak, and John Liu. "sense2vec-A fast and accurate method for word sense disambiguation in neural word embeddings." arXiv preprint arXiv:1511.06388 (2015).
- Iacobacci, I., Pilehvar, M. T., & Navigli, R. (2015). SensEmbed: Learning Sense Embeddings for Word and Relational Similarity. In ACL (1) (pp. 95-105).
- Reisinger, Joseph, and Raymond J. Mooney. "Multi-prototype vector-space models of word meaning." Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, 2010.
- Huang, Eric H., et al. "Improving word representations via global context and multiple word prototypes." Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers-Volume 1. Association for Computational Linguistics, 2012.
-
実際にはone-hot表現で与えた後、分散表現に変換します。 ↩