「ゼロから作るDeep Learning 2 自然言語処理編」(斎藤 康毅 著 オライリー・ジャパン刊)を読んでいる時に、参照したサイト等をメモしていきます。
その20 ←
2章から4章にかけてやっているのは自然言語をベクトルに変換する方法についての説明
2章は、文章をデータ化して統計処理しているだけなので、理解しやすかったですが、それが何? という感じもしました。3章になると、ニューラルネットも出てきますが、何のために何をしているのか、わけが分からなくなってきました。
で
結局、現時点で理解できたのは、2章から4章では自然言語の文章をベクトルに変換する方法を説明しているだけだということ。
p170
図4-21 に示すように、自然言語で書かれた質問を固定長のベクトルに変換するこ
とができれば、そのベクトルを別の機械学習システムの入力とすることができます。
自然言語をベクトルに変換することによって、一般的な機械学習システムの枠組みで
目的の答えを出力すること(そして、学習すること)が可能になるのです。

ということのようです。
つまり、PTBデータセットをword2vecというニューラルネットで処理して、シソーラスのようなもの、単語ベクトルを自動で作成したということ。単語ベクトルを通せば、自然言語による質問はベクトル化して計算可能なものになり、計算結果を答えとして出力するシステムも作れるということでしょうか。
私が理解したイメージはこんな感じ
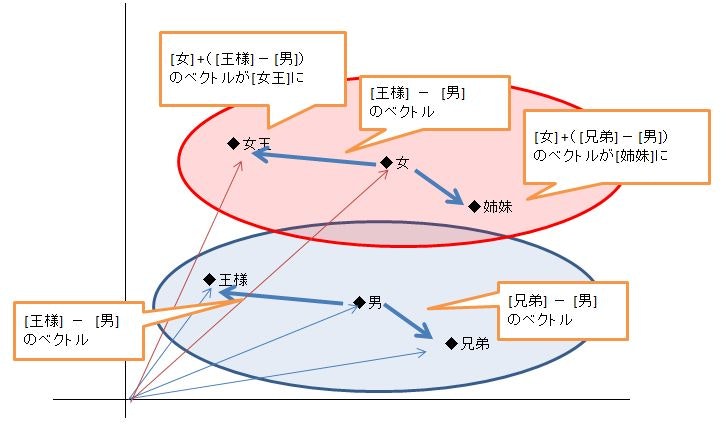
2章でやってたのは、「女」という単語の近くに「女王」や「姉妹」とか近い関係の単語が集まるようにベクトル化できる、ということ。
それが、3章になると、「王様」-「男」というベクトルを計算して、「女」に足すと「女王」のベクトルになる。つまり、単語と単語の関係もベクトルになる、単語の定義がベクトル演算でできてしまう、ということになりました。
自然言語をベクトル化すると、ニューラルネットに入力することができるので、いろいろなことができそうだ、ということです。じゃあ、何ができるのかについては、4章でもわかりやすい例は出てきていません。5章になると「言語モデル」という語が出てきて、機械翻訳や音声認識なども利用できるということです。
つまり、先はだいぶ長い、ということ。
SimpleCBOW
本の例題のままだと、語数が少ないし、遊べる余地がないので、The Beatles の元歌をそのまま読み込ませてみました。さらに、ニューラルネットのクラス定義にpredictメソッドも追加して、2つの単語を与えたら、どう答えをだすかやってみました。
from google.colab import drive
drive.mount('/content/drive')
import sys, os
sys.path.append('/content/drive/My Drive/Colab Notebooks/deep_learning/common2')
sys.path.append('/content/drive/My Drive/Colab Notebooks/deep_learning/dataset2')
import numpy as np
# SimpleCBOWの変更版
from layers import MatMul, SoftmaxWithLoss
class SimpleCBOW2:
def __init__(self, vocab_size, hidden_size):
V, H = vocab_size, hidden_size
# 重みの初期化
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(H, V).astype('f')
# レイヤの生成
self.in_layer0 = MatMul(W_in)
self.in_layer1 = MatMul(W_in)
self.out_layer = MatMul(W_out)
self.loss_layer = SoftmaxWithLoss()
# すべての重みと勾配をリストにまとめる
layers = [self.in_layer0, self.in_layer1, self.out_layer]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
# メンバ変数に単語の分散表現を設定
self.word_vecs = W_in
def forward(self, contexts, target):
h0 = self.in_layer0.forward(contexts[:, 0])
h1 = self.in_layer1.forward(contexts[:, 1])
h = (h0 + h1) * 0.5
score = self.out_layer.forward(h)
loss = self.loss_layer.forward(score, target)
return loss
def backward(self, dout=1):
ds = self.loss_layer.backward(dout)
da = self.out_layer.backward(ds)
da *= 0.5
self.in_layer1.backward(da)
self.in_layer0.backward(da)
return None
def predict(self, in0, in1):
h0 = self.in_layer0.forward(in0)
h1 = self.in_layer1.forward(in1)
h = (h0 + h1) * 0.5
score = self.out_layer.forward(h)
return score
歌詞を与えて学習。
from trainer import Trainer
from optimizer import Adam
from util import preprocess, create_contexts_target, convert_one_hot
window_size = 1
hidden_size = 5
batch_size = 3
max_epoch = 1000
text = 'You say yes and I say no. 以下省略'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
contexts, target = create_contexts_target(corpus, window_size)
target = convert_one_hot(target, vocab_size)
contexts = convert_one_hot(contexts, vocab_size)
model = SimpleCBOW2(vocab_size, hidden_size)
optimizer = Adam()
trainer = Trainer(model, optimizer)
trainer.fit(contexts, target, max_epoch, batch_size, eval_interval=None)
word_vecs = model.word_vecs
for word_id, word in id_to_word.items():
print(word, word_vecs[word_id])
you [ 0.86038524 -0.83497584 0.66613215 -0.8185504 0.68793046]
say [-0.96950233 0.9139878 -0.0698488 0.96711737 0.8293194 ]
yes [ 0.5127911 -0.52933097 0.5187115 -0.539593 0.17091447]
and [-0.72404253 0.69723666 0.9553566 0.70232046 0.6445687 ]
i [ 0.8944653 -0.88193524 0.7035641 -0.89571506 0.12104502]
no [ 0.5423326 -0.51544315 0.50091434 -0.5078412 0.577903 ]
. [-0.70245194 0.69322383 -0.804429 0.70015544 0.5043572 ]
stop [ 0.51510733 -0.500861 0.5052154 -0.50537926 0.17358927]
go [ 0.5255579 -0.5212051 0.4808163 -0.521005 0.5663737]
goodbye [ 0.6193473 -0.5962919 0.6038276 -0.6169504 0.12250113]
hello [ 0.6442181 -0.6211034 0.60341436 -0.6134619 0.6989495 ]
dont [-0.25871328 0.417597 0.13021737 0.538679 -0.05671578]
know [ 0.38923997 -0.44210196 -0.72956645 -0.30691501 -0.7036062 ]
why [-0.13761514 0.39734542 -0.67426395 0.57774395 -0.3374435 ]
, [-0.5161161 0.48735517 0.6387698 0.5220987 0.5398749 ]
# 2つの単語を与えて、答えさせる
def change_one_hot_label(X, vocab_size):
T = np.zeros((vocab_size))
T[X] = 1
return T
def i_dont_know_why_you_say(w0, w1):
id0 = word_to_id[w0]
id1 = word_to_id[w1]
in0 = change_one_hot_label(id0, vocab_size)
in1 = change_one_hot_label(id1, vocab_size)
kekka = model.predict(in0, in1)
k = np.argmax(kekka, axis = None, out = None)
print(id_to_word[k], k, kekka)
return
i_dont_know_why_you_say('say', 'goodbye')
you 0 [ 5.92926253 -0.36584044 -2.43450667 3.41120451 -1.54544336 3.94312343
-5.8144207 -2.43553472 3.9297523 -0.63027178 4.39174084 2.22467596
-4.72490933 -8.39840079 5.77989598]
say と goodbye を与えたら、 you という答えに。
say と hello で .(ピリオド)に
i と you で say
goodbye と hello で say
わざと、元のコンテキストにはない組合せを入力しましたが、sayの前後の語を答えれば、それっぽくなる感じ?
映画レビューのテキスト分類
TensorFlowのチュートリアルで、テキストを扱う例があったので、そちらをやってみました。
kerasによるMLの基本>基本的なテキスト分類
IMDBデータセットについての説明は、本の2章で説明している、自然言語のベクトル化に相当します。PTBデータセットとは構成が違いますが、考え方の基本は同じようです。
しかし、この後やっているのは、言語モデルを作るというよりは、Fashion Mnistデータでやったことに近い。単語を処理するのではなく、レビューの文章を一次元のベクトルにして入力し、肯定的か否定的かに分類していきます。
# 入力の形式は映画レビューで使われている語彙数(10,000語)
vocab_size = 10000
embedding_dim=16
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, embedding_dim))
model.add(keras.layers.GlobalAveragePooling1D())
model.add(keras.layers.Dense(16, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
Model: "sequential"
Layer (type) Output Shape Param #
embedding (Embedding) (None, None, 16) 160000
global_average_pooling1d (Gl (None, 16) 0
dense (Dense) (None, 16) 272
dense_1 (Dense) (None, 1) 17
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
Embedding(埋め込み)層
keras.layers.embeddings.Embedding(input_dim, output_dim, ・・・)
引数
input_dim: 正の整数.語彙数.入力データの最大インデックス + 1.
output_dim: 0以上の整数.密なembeddingsの次元数.
入力 shapeが(batch_size, sequence_length)の2階テンソル.
出力 shapeが(batch_size, sequence_length, output_dim)の3階テンソル.
GlobalAveragePooling1D
keras.layers.MaxPooling1D(pool_size=2, strides=None, padding='valid')
引数
pool_size: マックスプーリングを適用する領域のサイズを指定します.
strides: ストライド値.整数もしくはNoneで指定します.Noneの場合は,pool_sizeの値が適用されます.
padding: 'valid'か'same'のいずれかです.
入力のshape (batch_size, steps, features)の3階テンソル.
出力のshape (batch_size, downsampled_steps, features)の3階テンソル.
本の1巻目で出てきたプーリング層は2次元のMaxプーリングで、画像の処理で使っていた。
今回は、1次元のテキストを入力しているから、1次元のAverageプーリング。
画像では主にMaxプーリングが使われるということですが、自然言語ではこっちなんでしょうか?
学習処理
この例題での入力は、次のようなレビューを
this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert is an amazing actor and now the same being director father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also to the two little boy's that played the of norman and paul they were just brilliant children are often left out of the list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all
単語を数字に置き換えたものです。
[ 1 14 22 16 43 530 973 1622 1385 65 458 4468 66 3941
4 173 36 256 5 25 100 43 838 112 50 670 2 9
35 480 284 5 150 4 172 112 167 2 336 385 39 4
172 4536 1111 17 546 38 13 447 4 192 50 16 6 147
2025 19 14 22 4 1920 4613 469 4 22 71 87 12 16
43 530 38 76 15 13 1247 4 22 17 515 17 12 16
626 18 2 5 62 386 12 8 316 8 106 5 4 2223
5244 16 480 66 3785 33 4 130 12 16 38 619 5 25
124 51 36 135 48 25 1415 33 6 22 12 215 28 77
52 5 14 407 16 82 2 8 4 107 117 5952 15 256
4 2 7 3766 5 723 36 71 43 530 476 26 400 317
46 7 4 2 1029 13 104 88 4 381 15 297 98 32
2071 56 26 141 6 194 7486 18 4 226 22 21 134 476
26 480 5 144 30 5535 18 51 36 28 224 92 25 104
4 226 65 16 38 1334 88 12 16 283 5 16 4472 113
103 32 15 16 5345 19 178 32 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0]
batch_sizeが15000, sequence_lengthが256 のテンソルです。
これを入力にして学習させます。
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
x_val = train_data[:10000]
partial_x_train = train_data[10000:]
y_val = train_labels[:10000]
partial_y_train = train_labels[10000:]
history = model.fit(partial_x_train,
partial_y_train,
epochs=40,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
Epoch 1/40
30/30 [==============================] - 3s 24ms/step - loss: 0.6925 - accuracy: 0.5402 - val_loss: 0.6898 - val_accuracy: 0.6847
・
・
Epoch 39/40
30/30 [==============================] - 0s 13ms/step - loss: 0.0964 - accuracy: 0.9756 - val_loss: 0.3096 - val_accuracy: 0.8820
Epoch 40/40
30/30 [==============================] - 0s 13ms/step - loss: 0.0959 - accuracy: 0.9756 - val_loss: 0.3126 - val_accuracy: 0.8826
results = model.evaluate(test_data, test_labels, verbose=2)
print(results)
782/782 - 1s - loss: 0.3232 - accuracy: 0.8737
[0.3232003450393677, 0.8736799955368042]
文章を判定させてみた
TensorFlowサイトでの説明はここまでしかありませんが、いくつかの例文を判定させてみました。
def text2list(text):
text = text.replace('.', '')
words = text.split(' ')
return [word_index[w] for w in words]
tlist = text2list("i can't stand it.")
tlist1= text2list("i watched this abortion of a movie in the middle of the night due to insomnia and it was absolute garbage the plot was horrible the acting was horrible")
tlist2= text2list("we see the power of hope and honor and love this films evokes many different emotions but the final feeling is one of admiration of the human spirit by tragedy")
tarray=[]
tarray.append(tlist)
tarray.append(tlist1)
tarray.append(tlist2)
print(len(tarray), type(tarray))
3 <class 'list'>
"i can't stand it." は、チャーリー・ブラウンの口癖から。耐えられない。
2番目の文は、test_dataの中の否定的レビューの抜粋。3番目は肯定的レビューの抜粋。
text_data = keras.preprocessing.sequence.pad_sequences(tarray,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
print(len(text_data[0]),text_data.shape)
256 (3, 256)
predictions = model.predict(text_data)
print(predictions.shape)
print(predictions)
(3, 1)
[[0.6715189 ]
[0.01489276]
[0.957998 ]]
0 が否定的、 1 が肯定的。
"i can't stand it." は0.67なので、やや肯定的という判定。?。
2番目は、0.01で否定的。3番目は0.95で肯定的。
garbage horrible とか、love admiration とか、わかりやすい単語が入っているので、このように判定したようです。
逆に言うと、ちょっとひねった婉曲な表現でレビューすると、本来の意図とは逆の判定になるのかもしれません。
Embedding が、いまだにわかったような分からんような感じ。つまり、わかってないんでしょうね。
とりあえず、先に進んでいこうかと。
その20 ←
メモの目次等はこちらから 読めない用語集