「ゼロから作るDeep Learning」(斎藤 康毅 著 オライリー・ジャパン刊)を読んでいる時に、参照したサイト等をメモしていきます。 その15← → その17
Google Colab がふつうに使えるので、この本の内容を TensorFlow でやってみることにします。
TensorFlow のサイト https://www.tensorflow.org/?hl=ja の初心者向けチュートリアル「はじめてのニューラルネットワーク」をやって、本の5章めくらいまではカバーできたかと思います。
なので、7章のSimpleConvNetに相当するものを keras で構築してみようと思います。
Conv1D ? 2D ? 3D ?
畳み込みには Convナントカ を使うんだろうな、というのは察しがつくのですが、1D 2D 3D と種類があって、 D はたぶん Dimension 次元 のことなんでしょうから、画像の処理は2次元 2D でいい、ということなんでしょうか?
そういうことなら、それでいいんですが、
が
1次元って、どんなものがあるの? 3次元って?
ということが気になります。
1D は時系列データ等で
Keras Documentationより
このレイヤーを第一層に使う場合,キーワード引数としてinput_shape(整数のタプルかNone.例えば10個の128次元ベクトルの場合ならば(10, 128),任意個数の128次元ベクトルの場合は(None, 128))を指定してください.
ということです
こんな例がありました。
時系列予測を一次元畳み込みを使って解く
時系列データに対する1次元畳み込み層の出力を可視化
2D は画像等で
このレイヤーをモデルの第1層に使うときはキーワード引数input_shape (整数のタプル,サンプル軸を含まない)を指定してください. 例えば,data_format="channels_last"のとき,128x128 RGB画像ではinput_shape=(128, 128, 3)となります.
3D は高さを含めた空間等で
このレイヤーをモデルの第一層に使うときはキーワード引数input_shape (整数のタプル,サンプル軸を含まない)を指定してください. 例えばdata_format="channels_last"の場合,シングルチャネルの128x128x128の立体はinput_shape=(128, 128, 128, 1)です.
空間内での移動方向のデータも3次元になるので、こんな例がありました。
加速度センサーで行動分類
Conv2D Convolution2D
パラメータ
filters, 畳み込みにおける出力フィルタの数
kernel_size, 畳み込みフィルタの幅と高さを指定します. 単一の整数の場合は正方形のカーネルになります
strides=(1, 1), 畳み込みの縦と横のストライドをそれぞれ指定できます.単一の整数の場合は幅と高さが同様のストライドになります
padding='valid', 出力のサイズが入力と違う(小さい)"valid"か、同じ"same"のどちらかを指定します
data_format=None,
dilation_rate=(1, 1),
groups=1,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform', 重みの初期化方法
bias_initializer='zeros', バイアスの初期化方法
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
data_format
"channels_last"(デフォルト)か"channels_first"のどちらかを指定します.これは入力における次元の順序です. "channels_last"の場合,入力のshapeは"(batch, height, width, channels)"となり,"channels_first"の場合は"(batch, channels, height, width)"となります.
これ、逆に考えると、Keras では channels_last 入力のshapeが(batch, height, width, channels) というのがデフォルトだよ、と言っているわけです。
で
注意しないといけないのが、「ゼロから作るDeep Learning」で扱っているMNISTデータは、(batch, channels, height, width) channels_first だということ。
ところが、このパラメータに "channels_first" を指定しても、エラーが出てしまいます。
結局、データを channels_last に変換して処理する事にしました。
padding については、こちらを参照しました→ Tensorflow - padding = VALID/SAMEの違いについて
SimpleConvNet
本のP229から説明されている SimpleConvNet を Keras で構築してみます。
Google Drive に保存している MNISTデータを使うので、ドライブのマウントやドライブにあるフォルダへのパスを定義します。
from google.colab import drive
drive.mount('/content/drive')
import sys, os
sys.path.append('/content/drive/My Drive/Colab Notebooks/deep_learning/common')
sys.path.append('/content/drive/My Drive/Colab Notebooks/deep_learning/dataset')
# TensorFlow と tf.keras のインポート
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from keras.layers import Dense, Activation, Flatten, Conv2D, MaxPooling2D
# ヘルパーライブラリのインポート
import numpy as np
import matplotlib.pyplot as plt
ドライブに保存してあるMNISTデータを読み込みます。
from mnist import load_mnist
# データの読み込み
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)
x_train.shape
(60000, 1, 28, 28)
(batch, channels, height, width) channels_first の形式です。
これを(batch, height, width, channels) channels_last に変換します。
X_train = x_train.transpose(0,2,3,1)
X_test = x_test.transpose(0,2,3,1)
X_train.shape
(60000, 28, 28, 1)
channel_last になりました。
また、ラベル t_train は整数の目的値なので、損失関数には sparse_categorical_crossentropyを使います。
「ゼロから作るDeep Learning」P230
図7-23 に示すように、ネットワークの構成は、「Convolution - ReLU - Pooling - Affine - ReLU - Affine - Softmax」という流れです。
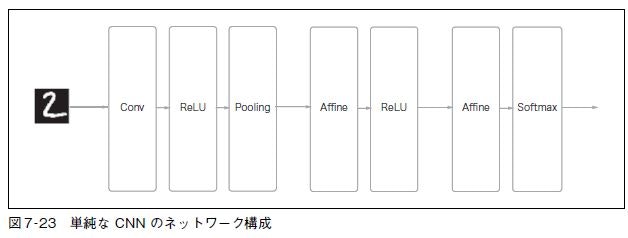
これをKerasで構築しました。活性化関数に relu を使うので、重みの初期値には he_normal を使っています。
input_shape=(28,28,1)
filter_num = 30
filter_size = 5
filter_stride = 1
pool_size_h=2
pool_size_w=2
pool_stride=2
hidden_size=100
output_size=10
model = keras.Sequential(name="SimpleConvNet")
model.add(Conv2D(filter_num, filter_size, activation="relu", strides=filter_stride, kernel_initializer='he_normal', input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(pool_size_h, pool_size_w),strides=pool_stride))
model.add(Flatten())
model.add(Dense(hidden_size, activation="relu", kernel_initializer='he_normal'))
model.add(keras.layers.Dense(output_size, activation="softmax"))
# モデルのコンパイル
model.compile(loss="sparse_categorical_crossentropy",
optimizer="adam",
metrics=["accuracy"])
model.summary()
Model: SimpleConvNet
Layer (type) Output Shape Param
conv2d (Conv2D) (None, 24, 24, 30) 780
max_pooling2d (MaxPooling2D) (None, 12, 12, 30) 0
flatten (Flatten) (None, 4320) 0
dense (Dense) (None, 100) 432100
dense_1 (Dense) (None, 10) 1010
Total params: 433,890
Trainable params: 433,890
Non-trainable params: 0
モデルを訓練します。
model.fit(X_train, t_train, epochs=5, batch_size=128)
Epoch 1/5
469/469 [==============================] - 27s 58ms/step - loss: 0.2050 - accuracy: 0.9404
Epoch 2/5
469/469 [==============================] - 27s 57ms/step - loss: 0.0614 - accuracy: 0.9819
Epoch 3/5
469/469 [==============================] - 26s 56ms/step - loss: 0.0411 - accuracy: 0.9875
Epoch 4/5
469/469 [==============================] - 27s 58ms/step - loss: 0.0315 - accuracy: 0.9903
Epoch 5/5
469/469 [==============================] - 27s 57ms/step - loss: 0.0251 - accuracy: 0.9927
tensorflow.python.keras.callbacks.History at 0x7f5167581748
かなり高い正解率になりました。
# 予測する
predictions = model.predict(X_test)
class_names = ['0', '1', '2', '3', '4',
'5', '6', '7', '8', '9']
def plot_image(i, predictions_array, t_label, img):
predictions_array = predictions_array[i]
img = img[i].reshape((28, 28))
true_label = t_label[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, t_label):
predictions_array = predictions_array[i]
true_label = t_label[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
# X個のテスト画像、予測されたラベル、正解ラベルを表示します。
# 正しい予測は青で、間違った予測は赤で表示しています。
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions, t_test, X_test)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions, t_test)
plt.show()

かなり難しい9番目の 5 もちゃんと判別できました。
レイヤーを個々に積み上げていく書き方もあります。
model = keras.Sequential(name="SimpleConvNet")
model.add(keras.Input(shape=input_shape))
model.add(keras.layers.Convolution2D(filter_num, filter_size, strides=filter_stride, kernel_initializer='he_normal'))
model.add(keras.layers.Activation(tf.nn.relu))
model.add(keras.layers.MaxPooling2D(pool_size=(pool_size_h, pool_size_w),strides=pool_stride))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(hidden_size))
model.add(keras.layers.Activation(tf.nn.relu))
model.add(keras.layers.Dense(output_size))
model.add(keras.layers.Activation(tf.nn.softmax))