「ゼロから作るDeep Learning」(斎藤 康毅 著 オライリー・ジャパン刊)を読んでいる時に、参照したサイト等をメモしていきます。 →その2
この本を読もうと思ったわけ
当方、長いことゾンビ化したメインフレーム上でシステムのお守りをしてきたコボラーでした。
もちろん、このご時世、それだけでやっていける訳もなく、PHPでWEBアプリに見えるようにお化粧したりしてごまかしてきましたが、ゾンビであることは変わりない。
そうこうするうち、歳月は過ぎていくもので、私もめでたく60歳に到達して、ゾンビ化。
で
ボケ防止のために、AIの勉強を始めたところ、
ニューラルネットワークがTensorFlowでkerasして、MNISTデータをモデルのレイヤーが損失関数を最小化してくれるという呪文を唱えると、意味不明のままでも、ちゃんとプログラムは動いてしまう。
プログラムはちゃんと動くし、ここを変えればこうなるんだろう、たぶん。
くらいのことまでは理解できたが、
このライブラリっていうやつは、結局、何をやっているんだ??
という所で行き詰まり。
そもそも、COBOLには便利なライブラリというものが存在せず、一からロジックを組み立てていかなければならなかったわけで、例えばクイックソートすら実装はされていないから、ロジックを組んで、しかも再起呼び出しができない仕様なので、スタックを用意しなければならず、最大データ量を見積もってスタックの上限を設定するとか、そういう基本的なことから積み上げてきたわけで、そういう人間にとってライブラリを参照して命令のパラメータを設定するだけ、というのはプログラミングとは思えない。
で
この本「ゼロから作るDeep Learning」(斎藤 康毅 著 オライリー・ジャパン刊)にたどり着きました。
現在5章まで読んだところですが、この本、確かに「ゼロから作るDeep Learning」という内容です。
ただし、読者の知識とスキルが「ゼロから」でいいという訳ではありません。
私は全くの「ゼロから」ではありませんでしたが、この本の説明だけではうまくいかなかったこと、理解できなかったことがけっこうあって、その都度この Qiita とかで調べて読み進めてきました。
この記事では、「ゼロから作るDeep Learning」を読むときに参照したサイトや試したことをまとめるつもりです。
python と Anaconda の環境について
本のおすすめにしたがって、Anaconda ディストリビューションをインストール。
https://www.anaconda.com/distribution
また、GitHub リポジトリからこの本で使うプログラムとデータをダウンロード
https://github.com/oreilly-japan/deep-learning-from-scratch
ここでわからなかったのが、Anacondaの環境、どこにインストールされたのか、どういうフォルダ構成なのか。また、ダウンロードしたプログラムをどこに置けばいのか、ということ。
私は、JupyterLabでプログラムを都度実行、確認してから本を読み進めていったので、この環境下で使えるように調整しました。
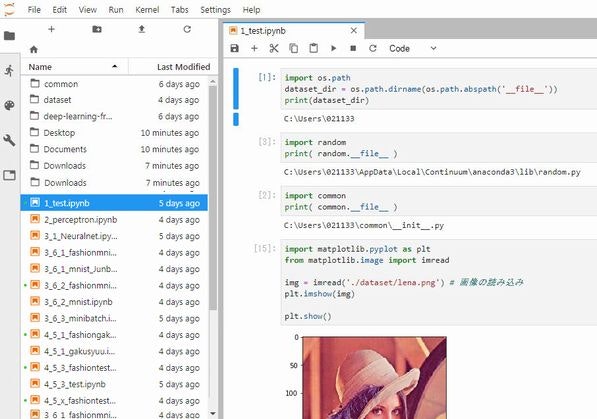
次のプログラムで、Anaconda のbase(root)ディレクトリーを調べてみました。
import os.path
dataset_dir = os.path.dirname(os.path.abspath('__file__'))
print(dataset_dir)
私の環境では、 C:\Users\(ユーザー名) となってます。
また、Anaconda本体は
C:\Users\(ユーザー名)\AppData\Local\Continuum\anaconda3
にありました。
GitHub からダウンロードしたファイルの中身は、次のようになってます。
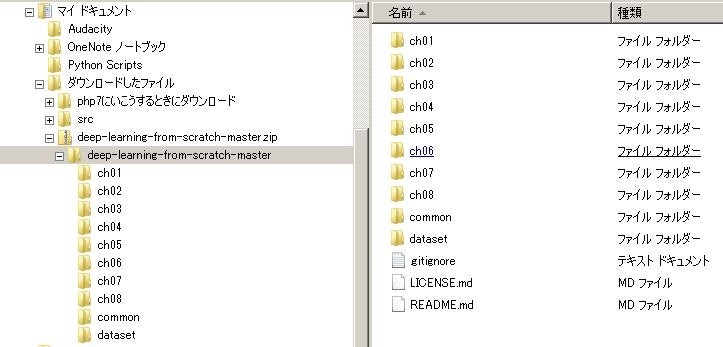
ch01 ~ 08 は、本の章立てに沿って、プログラムが置かれています。
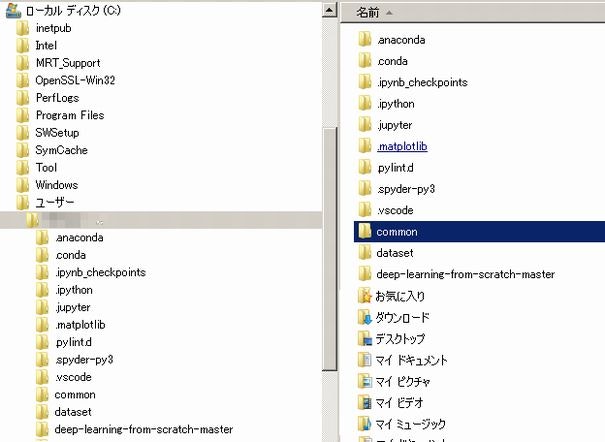
で、迷ったのが、 common と dataset フォルダの扱いかた。
結局、Anaconda のbase(root)ディレクトリーの下に置いて、必要な場合に本のプログラムの一部を変更して使いました。
P18 画像の表示プログラムは、画像ファイルを指定する部分を変更しました。
import matplotlib.pyplot as plt
from matplotlib.image import imread
img = imread('lena.png') # 画像の読み込み
plt.imshow(img)
plt.show()
import matplotlib.pyplot as plt
from matplotlib.image import imread
img = imread('./dataset/lena.png') # 画像の読み込み
plt.imshow(img)
plt.show()
P110(ニューラルネットワークに対する勾配) のプログラムで出てくる common というのは、GitHubからダウンロードしたファイルに中にあるフォルダのことです。
フォルダ base(root)ディレクトリー/common/ の下にある functions.py の中で定義されている関数 softmax とcross_entropy_error を import しています。
from common.functions import softmax, cross_entropy_error
from common.gradient import numerical_gradient
そしてch01~ch08にあるプログラムは、JupyterLabのnotebookにコピーしてから実行しています。
なお、よほどハイスペックのパソコンを使っているのでなければ、Anaconda で学習しても、メモリやCPU能力で壁にぶちあたります。そのため、現在、私は Google Colaboratory を使っています。これから学習するひとなら、最初からGoogle Colabo を使ったほうがいいかもしれません。
→メモその13 Google Colaboratoryを使ってみる
→その2
メモの目次等はこちらから 読めない用語集