*移動・再投稿(元 https://qiita.com/kzuzuo/items/9a149e69642ee7b3221e )
*20211003,502 bad gateway対策として,前,中,後へ分割
前 https://qiita.com/kzuzuo/items/4670b5ff7526319680f4
中 https://qiita.com/kzuzuo/items/237b9f5192464817aa40
後 https://qiita.com/kzuzuo/items/756470e6e17c54aa5e2e
2018年4月頃より余暇業務外で,知財関連AI,SDIと連動して教師類似特許抽出・スコア順並び替えを行う点眼分野専用自動化AI,の実装・実データでの試行と検証を行ってきた.
2018年10月頃完成,2019年4月現在は試行しつつの改良・検証段階.
モデルの個性が見られ続けている.
何に起因するどのような個性であるのか知りたくも,本業が忙しくなり余暇においても優先として時間配分できなくなっている.
しかし知りたい.個性があるならそれをコントロールすることで,様々に活用ができるはずだ.
いっそのこと公開してみる.
どなたか協力,またはこれらから課題発見し検討・公開してくれることを願って・・・
*以下,随時更新追記します.区切りを見つけてまとめ直す予定.
*以下,*と()はメモ(*と()だらけのネタ帳と化している.)
*思いつき即なぐり書きしており穴だらけ.考えが変わり矛盾している箇所も多々.
*繰り返される追記により話が前後している部分が多くある.
*複数の言語を混ぜると検索し難くなるため基本的に日本語に統一。google翻訳そのものを貼り付けたりもする。
*専門が異なり固有名詞が出てこない.自分の考えはP.インクベルセンの「情報検索研究一認知的アプローチ」にほぼ記載されていたのでこれに使用されている用語に書き直してゆく.
*2019年4月に提唱のあったMachine behaviorが,本件における該当分野となってゆくのだろう.
*実装しながら論文読みついで基礎を学び忘れ学び過去の通説は覆され,適切な知識形成がおっつかないよ!と泣き言を書いてみる.
*未だに自分が既存の技術のうち何に該当することをしているのか,どの部分が既存ではないのか,理解していない.この理解は実装においては近視的にはあまり重要ではないのだが,わかっていないことがわかっていない状態が維持されれば,必ずどこかで失敗の道に迷い込むことになる.知らねば.
*用語「AI」について.複数のモデルを扱いまた組み合わせ組み替えてゆくに当たり,深層でないモデルやニューラルと言えないモデル,機械学習とも言えない知識グラフなども扱ってゆく.end2endでない場合,表現が難しい.モデルをまとめて表すときには,用語「AI」と広い定義で記載することとする.
・202105時点において最新である、同じような疑問に向き合っている内容を持つまとまった記事は、次であろうと思われます。
Three mysteries in deep learning: Ensemble, knowledge distillation, and self-distillation
Published January 19, 2021
By Zeyuan Allen-Zhu , Senior Researcher Yuanzhi Li , Assistant Professor, Carnegie Mellon University
https://www.microsoft.com/en-us/research/blog/three-mysteries-in-deep-learning-ensemble-knowledge-distillation-and-self-distillation/
Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning
https://arxiv.org/abs/2012.09816
Are Pre-trained Convolutions Better than Pre-trained Transformers?
arXiv:2105.03322 (cs)[Submitted on 7 May 2021]
https://arxiv.org/abs/2105.03322
やっと、やっと、引用を追えば良いと言える文献が現れた・・・
やってきた:
複数の深層学習モデルを組み合わせた自然言語AI実装の一例と
モデルの多様性に注目した展望(概報)
2018年12月提出
http://patentsearch.punyu.jp/asia/2018hayashi.pdf
https://sapi.kaisei1992.com/wp-content/uploads/2019/03/2018hayashi.pdf
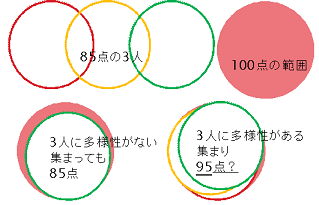
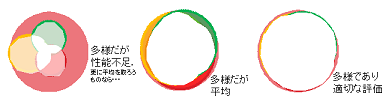
- 複数のモデルの個性とその多様性を評価するシンプルな手法.
- モデルCの市販AIは、201903にBERTに置き換えている.
- recall,AUCを評価基準として良好な結果が出ている.必要性はあり実現可能であり再現もある.ただし,実効性は不明. (評価データセットが十分でないので数値評価はしていない.→9ヶ月実データ試用結果は下記の通り.実効性があると言ってよいだろう.→val460検証結果の一部は下記の通り.目的に対し十分だろう.)
- 今後,認知的観点と解釈学的概念から実用をふまえた理解を深める必要があるだろう. (自然言語に真値は存在しない,正しい答えに見えるためには個別の認知に適合することが重要,と前提.)(「情報検索研究一認知的アプローチ」p32参照。今後,テンプレートマッチング,特徴・統語分析,および文脈解析の観点を超えた理解を,認知的観点から進める必要があり,そうして初めて「実用」といえる段階になるだろう.)(認知検討→各モデルとヒト認知との比較実施.期待通り→検討中…)(創造性検討→創造性発揮例ありしかし満足できるものではない→改良中…)
*このAI使用の前提は,ヒトが補完をすること.この種のAIには,今のところ,ヒトの代替をできるほどの能力はない.すでに人手が足りているならその代替にはならない.不可能を可能にしてくれるが可能をより良い可能にはしてくれない.その理解の上で,ヒト代替に近づくAIにできないか,個人用アシスタントAIとできるか,試してみたい.
(「情報検索研究一認知的アプローチ」p201参照。AIには従来のような概念知識を持たない「情報検索専門家」でなく、概念知識を持つ「専門家」となることを期待している.)
*AIを用いた実データによるSDI確認試行を9ヶ月続けた.その期間内において重要な特許を見落としたと言える案件は(再確認中だが見つかっているものは)多様性評価で上位15%(BERTモデルで48%とBERTが足を引っ張った)となった1件のみ.この1件もヒトが救済している.
人手が足りない会社における実用として,個人用アシスタントAIとして,十分ではないだろうか.
(判別しにくい分野の特許群ではこうはならないと思うけれど.難しいタスクを簡単なタスクに変換することも重要。)(それぞれのモデル(ヒト含める)の不得意分野が明確になれば,さらに性能をあげられるだろう.)(特許調査に100%はない,というのはその通り.母集団の外の特許は見つけられない.人が調査する際には確認可能な件数に母集団を限定する必要があるが,AIの場合その制限は少ない.この母集団を広く取ることができるという点においては,人よりAIの方が確実に優れていると言える.)(AIとヒトとで比較したとき,ヒトがすべての範囲で優れているということはない.例えば……先日ある調査会社にクリアランス調査を依頼し評価十分と言える方(この方の調査能力が低いと言う人は多分いないし,この方の調査能力が低いなら調査能力が高いと客観的に言えるヒトはほぼいないとなるだろう)に調査していただいたのだが,見事に最重要特許2件落としてだなぁ……この最重要特許はAIが拾い上げた.ここで言いたいのは,ヒトも完璧ではないようにAIも完璧ではない,AIが完璧でないようにヒトも完璧でない.ヒトをAIに置き換えることが難しいのと同じように,AIをヒトに置き換えることも難しい.ただ,ヒトとAIはお互いに補えうる,ということだ.AIが100%見分けたかどうかは結果に過ぎず最重要ではない.まず重要な問題は,ヒトとAIにつき,互いが間違える部分を再現性を持って補ってゆくことができるか,である.つまりアシスタントできるか,だ.)(ヒトとAIの協働には可能性を感じている.協働にはAIの個性を理解する必要があると感じている.個人用アシスタントAIがベストと,今も感じている.))(創造を組み入れた未来予測型の個人用AIが可能だと考えているし,まだ不可能を網羅していない(というか,創造性の部分にはまだほぼ手を付けていない.))
*現在,100カ国語+から日本語への翻訳機能を実装している.これはSDIで重要となる迅速な読解,ひいてはROIの向上に,大きく寄与する.
*分散表現モデルの学習に用いるコーパスを変化させる手法は従来から行われているが,その視点は多くが「意味」の範囲内・文脈レベルである(分野ごとの語彙や文型の違いなど)(のように見えているが,統計をとったわけでも最適なサーベイを見つけて確認したわけでもない).自分は意味を超えた「情報」・価値観レベルの視点で検討している.
(コーパスで何でもできると考えているわけではない.コーパスに基づく分散表現は必須,構造も必須,それらを如何に統合するかが課題だろう.)
*自分の勝手な思い込みは十分集まった.そろそろ基礎を進める時期か.課題認識してゆるく柔軟な概念をつくってから学ばないと右から左なのだよね.
(何かを知らないという飢餓感がモチベーションの源なのだが,多くのインプットに基づく課題の知が,何かを知らないという飢餓感の源泉となっている.)(固有名詞のような知識は飢餓感の源泉にはならないし,逆に無知の知を失い間違った安心感により飢餓感を失いうる.人によるだろうけれど.)
→coursera Deeplearning.ai Natural language processing 16週講義修了。T5、Reformer含むattention modelまでの講義。ちっとはマシになったかね。
→coursera How to Win a Data Science Competition: Learn from Top Kaggler 5週講義修了。一通りは撫でられたかな.
→Control and Robotics 多様体論へのいざない 基礎数学 大阪大学大学院
https://www.youtube.com/watch?v=6npSJdMQqVY
下記*()コメントへの修正をはじめよう。
・201909現在のシステム構成.
Doc set(xlsx)をメールに添付して送信すると,output(xlsx)がメールに添付され返される.
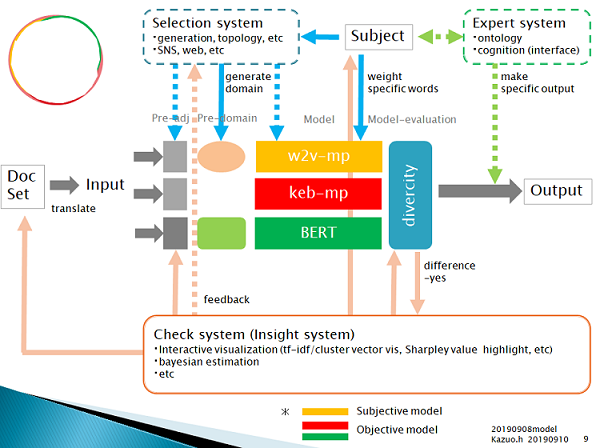
・model: モデル
w2v-mp: word2vec pretrained maxpooling model. This like CNN.
keb-mp: keras embedding maxpooling model. This like CNN.
BERT: Bidirectional Encoder Representations
w2vkeb-mp: w2v-mpモデルのみがその個性を示したサンプルをkeb-mpモデルの正解教師に加え再学習するモデル(自己教師の一種?data augumentation?)。上位概念下位概念の発散収束コントロールテスト、創造性テスト用。並列でなく直列とした場合の理解を深めるために試行。
congnitive-w2v-mp:w2v-mpに対し任意にattentionを適用させるモデル。再事前学習不要にどこまでドメインの変化をコントロールできるかテストするために試用。
mbart、またはmT5追加予定
なお教師データは、正解教師データ約100件、不正解教師データ約100件としており、いずれのモデルにおいても同じ教師データを用いている。(少ない教師量から必要十分かつ最大の結果を得ることを目的の一つとしている。)(また教師データが頻繁に変わると意図しない特性となり得ることが明らかなので、教師データは最低限のみ変更することとする。)
・pre-adj: 前処理
入力テキストの前処理を行う.前処理方法はモデルにより異なる。oov処理含む。
*やっと事前知識分散表現において使わない語彙もそのベクトル空間を適切に作るには重要という考えに至った。oov処理はpre-domainにおいて主に行うこととする。
・pre-domain: モデルに与える事前知識
・Subject: 認知ベース.
・Check system(insight system, alert system, school system, knowledge distillation system): 学習・評価結果の理論化、作成された理論や任意の教師無しモデルなどを利用したフィードバック補正、創造? 類似を提示することによる説明
Expert systemの逆.
知識構造があることが明確であり、構造がシンプルであり、構造が未知ならば、構造をシンプルに取り出し適用させましょうってこと。
tfidf embeddings/cluster vis: tfidf-word2vec-clustering visualization 目視確認と自動母集団検証・修正。さらに、高スコア結果それぞれに近似する特定範囲を抽出して教師データをaugmentationし再学習してもよいし、好スコア結果から重要な特徴を抽出してexpert systemに渡してもよい。検証中。
Bayesian estimation: Bayesian Designと記載すべきか.自動仮説最適化データ作成・修正.自動概念追加.(expert systemに渡す、決定木とベイジアンネットワークを組み合わせた特徴量エンジニアリングシステムも作成中)
SHAP highlight: 目視確認と事前知識と比較した自動仮説最適化データ作成・修正
mbart: 検証中
mT5: 検証中
多様性評価手法は2年間特に問題ない結果を出力してきた。2年間の全データを使用して、一つの蒸留モデルを組み、検討に入れる予定。
・Expert system: 外部から持ち込んだ理論の適用
巨人の肩、メタ構造、構造、human in the loop 含む。外部足場scaffolding?
check systemの逆.外部から持ち込んだ理論とは,check systemが作り上げた理論も含む(けれど,いまのところ吟味して適用したいので図の中ではつなげていない.) メタ構造も含む。
関連を因果に変換.専門的認知と検索者認知に適合させる.
知識構造が明確であり、構造が既知ならば、その構造を優先させましょうってこと。
特定のメールアドレスに単語を入力して送信すると、その後、モデルがその単語を自動的に重視するようにしてある。気になった出来事があればメール送信しておくだけ。自分の認知との適合性向上についてもっと簡略化したいが現状ここまで。
(現状,簡易的なオントロジーと,単語重視,特定分類重視による.)(この部分で文章検索の利点と単語検索の利点が融合するハイブリッドとしている.)(このexpert systemは過去にあったそれと異なり,支配的影響力を持たず,多様性を持つ個性の一部として不足を補うように働く.)(データに含まれる差別(データのバイアス)を素直に抽出してしまう点で、AIは子供だ。差別とは社会的に生み出された必然性のない概念であり、子供には基本的にわからない。必要な差別と不要な差別を見分ける必要があり,そのため、AIには大人のバイアス(モデルのバイアス:モデルの個性により与えられるバイアス.バイアスを加えられ形成された事前確率や構造といってもよい?)を与えておかないといけないと思う.(データのバイアスは無くすことができないのだから(check systemで手を入れているけれど),適切と思われるモデルのバイアスをかけて補正することは健全だと思う.ヒトではこれを教育と呼んでいるはず.様々な教育(真値のない複数の適切と思われるモデルの個性による関与)は多様性を提供する.これは歓迎されることだろう?(きちんと評価する能力があれば,だが).)。損失関数などにより方向性を与えデータから自発的に学ばせることにより教育がなされるが,それだけでは不要な差別も採用されてしまう.不要な差別を除き適切な差別を採用「されやすく」するためのモデルの個性であり,その個性の一つ(比較的まっとうで限定的な知識を持つ個性)としてのexpert systemと言っても良い?.)(データのバイアスと不足、情報のバイアスと要約、知識のバイアスとエッジの間違い、知恵のバイアス。色々ごっちゃになっていることが多くの問題を生み出している気がする。)(ある画像分類モデルが学習により2通りの正答ルートを作り上げたとする。Aルートは犬の顔を認識して犬と分類した。Bルートは背景の芝生を認識して犬と分類した。さて、どちらが正解だろうか?。実は双方正解だ、またはどちらが正解とは言えないというのが正解だ。教師は、犬自体を認識させたかったのかもしれず、芝生にいる犬を全体として認識させたかったのかもしれない。これが与えられていないときに不正解は問えない。このように、結果は結局、教師の認識に依存してしまう。(そして結果は結局、教師でない受け手が自ら仮定した認知において判断される)(画像では絶対的な答えを与えられうるだろうとしても、自然言語では絶対性はよりあいまいになり絶対的な答えを与えがたくなる)。
我々は常に、質の良いデータを利用した、質の良いルートに導く、優秀な教師となれるだろうか?。なれない。この花何?と聞かれたら名前を答える。このような教師であって疑問に思わない程度の教師がほとんどだろう。そこで過去の優れた教師による結果、巨人の肩を利用することになる。これが、ここに記載したExpert systemの役割となる。)(一言で言えば、ルールと法律の積み重ねの違い、と言えようか?)
・Selection system: w2v-mpに対し,概念を「歪め統合」しニーズと検索者認知に適合させ,創造性を付与する.
(多分,Retrofittingと呼ばれる技術の範囲内なのだと思う.)(未知語処理含む.)
・divercity: 多様性評価手法
(現状,ある閾値で足切りしその範囲内でFP件数を考慮した重み付けをを行う評価基準を用いており,認知・正解両面において,良好な結果が得られている.)(引き続き,安定性があるかどうか,理由がわかるかどうか,最適なエキスパートシステムは何か考慮しつつ、新たな評価基準の設定を進めている.)(モデルの個性に基本特性があるようなので、メタモデル化する予定。メタモデルの評価は弱く考慮する。)
*現在のAI分野において最高に面白いと思っていることは、帰納的でブラックボックスな予測から、演繹的な仮説を生み出し、データを追加した後それを再度帰納的予測にかけ仮説深化してゆくループだ。
このような事が計算機上で可能となった時代に生きていることに興奮するし、これができるのと出来ないのとでは明確な差が出るだろうことに危機感も感じている.
*「言葉の集合と分布と概念の外縁とそしてエッジの動的平衡を扱う理系」という意味で、自然言語処理と知財は、かなり類似していると思う。外縁の作り方は課題によるとして、知財の皆がそれぞれ自らの課題に沿った自然言語処理を始めると面白いと思う。
「知財言語処理」という分野を作っても良いのではないだろうか.
*法律分野ではエッジ,概念の領域範囲の明確化,が重要となる.エッジを明確化するには曖昧さがないほうが良い.曖昧さをなくすには,Bowやルールベースを用いると良いだろう.法律分野のうち,例えば契約文章は重要語の多様性があまりないが,特許文章は重要語の多様性が大きく,類義語が多く表現の解像度が異なりもする.契約文章では相性通りのBoWやルールベースを当てはめやすいが,特許文章ではそれでは限界がある.
特許文章は特殊で,エッジの重要性を保ったまま,文章の多様性にも対応させる,という,衝突しかねない概念を両立させないといけない.
特許文章処理は,自然言語処理において,かなり面白い分野,チャレンジするに値する分野となると思う.
*特許分野において様々にAIが利用できるであろうが,SDIでのAI利用は,前述のエッジと多様性に加え,適切に結果を出すには創造性が必要であろうことさらに受け手の認知を無視できないことから,基礎でありつつ難解で応用範囲が広い分野であると考えている.
まあつまり,面白いってこった.
やっている:
1. 本当にモデルに個性があるのか?
2. モデルに個性を作るには?
3. 多様性を評価しより良い結果を得るには?
4. モデルに創造性をもたせることはできるのか?
現状:
本業優先かつ基礎が成ってないためなかなか進まない.しかし結果は知りたい.
得られている結果:
1. 本当にモデルに個性があるのか?
あるようだ.
A.3つのモデルにおいてn=3の予測結果を比較してゆく過程で、正答不正答において,モデルに依存した個性らしき差が見られている.確率的多様性では無いようであった.
B.SHAP (SHapley Additive exPlanations) https://github.com/slundberg/shap を自然言語に適用し検討したところ,正答不正答において,モデル間に個性らしき差が見られている.

図1)force_plot.pre-trained word2vecベースのmaxpoolingモデル(左).keras embedベースのmaxpoolingモデル(右).
(横軸:バリデーション用特許文章40サンプル.左半分が不正解候補20件.右半分が正解候補20件.縦軸:赤帯青帯の境界は正解予測値.基本的に,赤帯は正解特徴の強さを表し,青帯は不正解特徴の強さを表す.)
・複数回試行したが,波形のパターンは安定.
乱数固定はしていない.左のモデルは学習のたびに予測値が変動しやすいのだが,それでも波形は安定.
*SHAP実例
Explainable machine-learning predictions for the prevention of hypoxaemia during surgery
https://www.nature.com/articles/s41551-018-0304-0
*次の資料はわかり易い。
How to use in R model-agnostic data explanation with DALEX & iml
https://www.slideshare.net/kato_kohaku/how-to-use-in-r-modelagnostic-data-explanation-with-dalex-iml
p116- SHAP
*SHAP を用いて機械学習モデルを説明する
https://www.datarobot.com/jp/blog/explain-machine-learning-models-using-shap/
*モデルにより波形が異なる.差があるということは価値があるということ.
=>あるモデルのみが正解できる部分を抽出してゆけば,総合性能は向上するはず.
*あるモデルのみが正解できる部分を抽出してゆくとは、モデルごとの集合を重ね合わせてゆくことと同じ。
適切な集合を重ね合わせることは、精度高くかつ再現率の高い結果、最終的に得た母集団の総合性能の高さ、を得るために、情報検索者が当然に行っていること(単一集合では不可能な精度再現率の両立を精度の高い集合に細分化して足し合わせることでカバーする)。
それぞれのモデルが汎用性の高い個性を持って精度の高い集合を作っているならば、モデルを組み合わせるとは情報検索者と同じことをしていると言える。
汎化された総合性能を考えるに、モデルの個性把握は重要。
(上記は交差エントロピーを前提としている)
*参考:ランダムフォレスト(上)と市販AI(下).
双方ともに,他のモデルと個性が異なっているとは言える.しかし,正解候補の評価値と不正解候補の評価値の差が小さすぎ使いづらい.(分離を良くすることは容易だと思うのだがどのような設計思想なのだろう.)(市販AIはランダムフォレストではなかったはずだがなぜこれほど似たのか.)(再確認するも,変わらず.)(個人的には、決定木から得られる集合に関するルールを良いモデルの個性として使えるか疑問に思っている。単体で使う場合は問題ないのだろうけれど。)
C.SHAP値を用い重要語にハイライトをつけたが・・・単語ベースでは明確なモデル間差は見られていない.=>見られた.

図2)pre-trained word2vecベースのmaxpoolingモデル(左)とkeras embedベースのmaxpoolingモデル(右)でSHAP値上位となる単語を比較(個性差が見られなかった特許の場合の1)
code
・正答不正答における個性差が見られなかった特許(図2)において,ハイライトされた単語に大差はないように見える.再現性もある.(あえていえば右のモデルのほうがtfidf的か.)(いや異なると判断すべきだろう→個性比較へ)
・正答不正答における個性差が見られた特許において,ハイライトされた単語に明確な差があった.(左のモデルでは期待通りの「価値観に基づく類義・関連語の統合」が起きているようだ.調査方針が丸わかりになるため公開せず.)
*正答不正答における個性差が見られなかった特許のうち不正解と正答されない傾向にあった特許において,ハイライトされた単語は明らかなノイズであった.SHAPはノイズ発見の役にも立ちそうか.
・同じ単語でもSHAP値が異なることがある.(図のモデルでは前後数単語poolしている.)
*少なくとも,記号系が得意なモデルと得意でないモデルがある.(これはモデルのアルゴリズムから予測できた.ただし,記号が付されていない特許でも差が現れているので,他にも差の原因があるのは確か.)(ウインドウサイズが個性に影響していないのだが,アルゴリズムからするとそうなる理由がわからない.)
*LIME https://github.com/marcotcr/lime も試用した.傾向はSHAPと似ていたが,再現性が低く機能語に当たりやすい傾向があった.
*主題と異なるが,ここから特徴語を取り出している.(特許と実製品とのリンクは重要である.特徴語からの実製品抽出を試行中.)
・BERT名詞限定におけるハイライト一例.
SHAPではない破壊手法.収束確認していない.再現性確認していない.
名詞限定としてもある程度妥当な語がハイライトされる.面白い.
(queryとkeyから得られるattentionにマルコフ性があるとして、queryの名詞に対し重みが大きいといえるkeyの単語は助詞ではないであろうから当然か?。一応attentionの重み付けをしたベクトルかattention自体と比較しておこう。)

*なぜその特許を正答としたのか擬人化した各モデルに尋ねればこんな回答が返ってくるだろうか.
・・w2v-mp:教えられた意味に基づけば異なるが私が思うに検索者は製剤特許という構造を持つものを情報として得たいのではないかと考えたため(うむ.実際はそうでもないが好ましい意見だ).
・・keb-mp:与えられた教師とデータを総合したところこれらが特徴と言えたから(真面目だ).
・・BERT:文脈から分類すると関連する単語はこれだったから.概念?因果?何それ(ファインマンに謝れ).
・・BERTm:肝と言える関連名詞がこれだったから.概念?因果?何それ(うむう).
・個性比較(正答不正答における個性差が見られなかった特許)
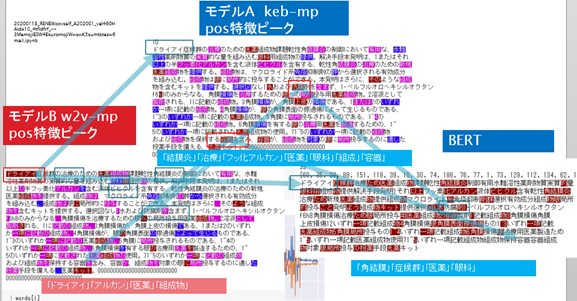
*w2v-mpではwswによりドライアイを強調していることに注意。wswを抜いて比較するのを忘れていた)
すべて,特徴らしい単語にハイライトがついており,モデルごとに異なっている.
単語における個性が確認できる.
どのモデルも正答している.そしてモデルごとに注目した単語が異なっている。正答とすべき根拠となる単語が複数あるところ,モデルごとに異なる視点で,ルートで,正答にたどり着いたように見える.
多様性評価において価値があるといえる個性となっているようだ.
(多様性評価において価値のある個性となっているかどうかについては,偶然そう見える結果のみ観ている,認知バイアスがある,可能性を否定しきれない.ある程度の検証と理論的考察がやはり必要だ。しかし,理論的背景がどのようであるか,考えもつかない(分布で表現することになるのだろうか.シンプルに単語の出現頻度で表現するか.).どうしたものか.手持ちのデータ全てを確認し,全てそう見える,とまとめてしまおうか・・・)
・後述するように,ヒト認知との適合にモデルごとに差が,ヒト認知における個性の存在が,観られている.
(この部分を突き詰めることにより、視点の違いが何故生まれるのか理解できるのではないか。)
*今更だが,個性の定義を明確にしておいたほうが良さそうだ.
個性とは,
・goo国語辞書によると「個人または個体・個物に備わった、そのもの特有の性質。個人性。パーソナリティー」.
・wikipediaによると「個人や個体の持つ、それ特有の性質・特徴。特に個人のそれに関しては、パーソナリティと呼ばれる」
はっきりしているな.
「モデル間に違いがあり,違いに再現性があれば,個性がある」と言っても良さそうだ.
あるモデルでしか正解できないサンプルが存在し,それに再現性があれば,そのモデルに個性があると言えるだろう.
ヒトの認知と常に近いモデルであり他のモデルよりも常に優れるのであれば,そのモデルに個性があると言えるだろう.
ヒトの認知のうちある範囲に付き,常に近いモデルであるならば,そのモデルに個性があると言えるだろう.
特有の性質はいくらでも考えられる.
モデルの個性は,「見つかった特有の性質を,他のモデルと比較し,総合的に」,表現すればよいか.比較対象には一般的なモデルも欲しいところだが・・・keb-mpのCNN版を一般的なモデルとすれば良いか.
(本文中で「個性らしき」「個性があるのでは」と書いてきたが,断言しても良さそうだ.)
疑問点・課題:
A. SHAPを正しく使用できているか
できているはず。
SHAPがいつの間にかテキストにもHuggingFace transformersにも正式に対応していた。比較確認する。
SHAPにおいて赤帯青帯の境界に示される正解予測値は予測値そのものと同じである.この出力ができている点については,SHAPを正しく使用できているはず.赤帯青帯の幅についても,SHAPを正しく使用できているはず.
個別の単語に対するハイライト強度については,SHAPを正しく使用できているはずだが,コードを追いきれておらずまたSHAPの自然言語への適用が少なく,確証がない.結果としては,妥当にハイライトされているように見える.
(特定の文章内における単語ハイライト妥当性、WSW実施時の単語ハイライト強度と予測値変動。)
*Keras LSTM for IMDB Sentiment Classification
https://slundberg.github.io/shap/notebooks/deep_explainer/Keras%20LSTM%20for%20IMDB%20Sentiment%20Classification.html
*モデルの個性を理解してゆくにあたり,理解に必要な手法が共通しているに越したことはない.SHAPは汎用性がありそうなのでできるだけ使ってゆきたいのだが.
(モデル限定となるがattentionからの理解が流行している.しかし疑問もあるそうだ.Attention is not Explanation https://arxiv.org/abs/1902.10186 )
*p26~モデルの解釈性(201908)
https://speakerdeck.com/mimihub/20190827-aws-mlloft-lt5?slide=29
*GoogleのExplainable AIはsharpley valueを計算しているとのこと.GoogleのExplainable AIが自然言語にどう対応してゆくか確認してゆくこと.
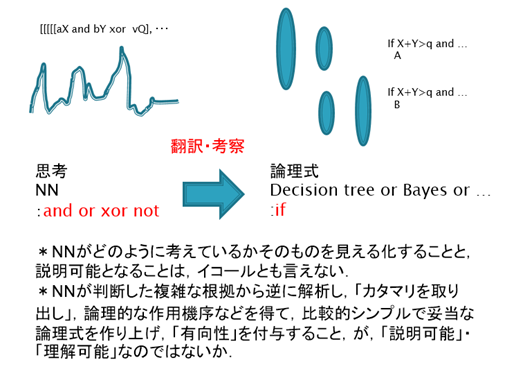
*説明と理解。
NNが判断した複雑な根拠から逆に解析し,「カタマリとなるクラスタを取り出し」,論理的な作用機序などを得て,比較的シンプルで妥当な論理式を作り上げ,「有向性を付与」すること,が,「説明可能」,ひいては「理解可能」につながるのではないだろうか.
(ヒトは思考の末に直感に反しさえもする理論を作り上げ説明し理解するのであって、
直感を複雑なままとらえ説明し理解するのではない.少なくともヒトへの説明には,単純化が必須であると思う.理解自体には単純化が必須とは言えないが.)
(さらに,多様性の立場に立つと,一つのNNが判断した根拠は正答を導く唯一の道ではない,として,多様な道のすり合わせによりより良い理論が形成される,と考えたいところ.耳に注目して動物を見分けても良いし,眼に注目して見分けても良いし,他でも良い.正しい答えを導くそれら組み合わせはまた多くあるだろう.その多くの組み合わせをまとめて,論理式を作るべき,という考え方. 一つのNNでその論理式の形成までたどり着くかと言われると,多分,一つのNN,一つの伝播範囲?,では,それほど大きな多様性は生まれないのではないかな・・・分布がある程度近似してしまい,例えば眼は必ず考慮する,などとなってしまうのでは.)
SHAPは「カタマリ」を取り出すに妥当と思う。問題は「有向性」だ。これは「理解」に含めてCで扱うことにする。
(「ヒトによる理解」には有向性が必要でありその派生として「説明」にも有向性が必要となるが、本質的には説明に有向性は不要だと思う。ヒトによる理解に有向性が必要である理由は、ヒトは7つほどしか「根拠」を把握できないところ、有向性を付与することにより7つの「根拠」からでも、より多くの理解が得られるようになるから、ではないかな。とするなら、「複雑な根拠を7つほどのカタマリに圧縮するクラスタリング」と有向性付与が、ヒトへの説明における答えとなるのだろう。)(カタマリを抽出することをローカルな説明と呼び、カタマリに有向性を足したものを抽出することをグローバルな説明と呼ぶ、と分けたほうが良いか。本手法では、ローカルな説明はSHAP、グローバルな説明はcheck system全体?、となろうか。)(多分,説明を受けるものと説明するものの間で,「ドメイン(分布)のすり合わせ」ができて初めて,「説明」が「理解」となるのだろう.(最初からすり合わせておいたほうが良いと思うが,最後にすり合わせることも可能だろう.))
*SHAPハイライトに加えて単語間の共起性を示すようにすれば、現状使用しているモデルにおいて必要な「検索者に対する」「説明」は充分かな。さらに加えるとしても、ほかのモデルを参照したり自分で見直すインサイトを与えるため、そのモデルが重視しやすい単語・構造と重視しにくい単語・構造を示す(check system全体で補正してしまうが補正したと示すほうが良いだろう)程度か。(「モデル個性の評価のために行う」「理解」は別。)
*次の用語に統一し整理すべき?.
・Data(データ)… 整理されていない情報。いわゆる「ローデータ」 =「データ」
・Information(情報)… データを何らかの基準で整理(カテゴライズ)したもの =「カタマリ」(セグメンテーションとクラスタリングが混ざるかな・・・)
・Knowledge(知識)… Informationから導き出される、規則性、傾向、知見 =「有向性付与」(各クラスタに対する要約付与,だけでもよいか?)
・Wisdom(知恵)… 「人が」Knowledgeを活用して判断する力 =「理解」
*今ひとつ「説明」の行き場がないかな・・・
*産総研人工知能研究センター【第40回AIセミナー】機械学習モデルの判断根拠の説明(Ver.2)(202001)
https://www.slideshare.net/SatoshiHara3/ver2-225753735
*tidymodels+DALEXによる解釈可能な機械学習 / Tokyo.R83(202001)
https://speakerdeck.com/dropout009/tokyo-dot-r83
*以降、説明可能は下記Cに記載することとする。
*SHAPがいつの間にかテキストにもHuggingFace transformersにも正式に対応していた。
ドキュメントも豊富に。これで前例がほぼ無いなか掻き分けないで済む。ありがたい。そんな能力ないんだよ・・・
https://shap.readthedocs.io/en/latest/example_notebooks/api_examples/plots/text.html

機械学習モデルを解釈する指標SHAPを自然言語処理に対して使ってみた
https://qiita.com/m__k/items/87cf3e4acf414408bfed
B. モデルの個性をどう作るか.
正答不正答において,モデル間に個性がみられている.
正答不正答における個性のみからでは,モデルの個性をどう作ればよいのか,定かになっていない.
w2v-mpモデルの個性を恣意的に調整するために,wswを追加した.
ヒト認知を示す個性として,Expert system,eswを追加した.
ヒト認知との適合において,モデル間に個性がみられた.(keb-mpとBERTは(なぜか)ヒト認知との適合においてほぼ互い重複しない結果を示した.)
ヒト認知における個性において,その個性が発揮される理由とアルゴリズムが理解できれば,モデルの個性をどう作ればよいのか,理解できるだろう.
w2v-mpは文章を上位概念で、keb-mpは文章を下位概念で認識しているように見える。
上位概念下位概念で捉えていることが確認でき、その要因がつかめたならば、モデルの個性をどう作ればよいのか,理解できるだろう.
SHAPを正しく使用できているとして,
・ハイパーパラメータを変えてみたが,今のところ,個性の変化は見られていない.
(赤帯青帯の幅が全体的に変化する程度.波形のパターンは変化せず.local minimumが少なくなるようにモデルを作っているがその影響か.)(window sizeが個性に影響しない点が意外であった.averagepoolingでなくmaxpoolingとしたためか.window sizeが大きいとリークが云々という文献を読んだ気がするがメモをするのを忘れてしまった・・・)(すべてのパラメータについて確認しきれているわけではない.)(少なくとも,正則化が個性を明確にするだろう.)
・keras embedベースのmaxpoolingモデルと,keras embedベースのCNNモデルで比較した場合でも,個性の変化は見られていない.(転移学習でも個性の変化までは望み薄であろうか.)
・ランダムフォレストも試したがacc0.75と低すぎたため検討できなかった.
・文字レベルの前処理や,品詞限定の前処理によって,個性が表れるかもしれない.
(特許では,名詞重視で形容詞副詞が少ないという特徴がある?(形容詞を書くぐらいならそれを表すデータを書く)ため機能語を削ることができそれにより個性が際立つのでは.)(結果として,名詞限定により正解がより上位に集中する結果となった経験がある.FNが増えてしまったが.)(契約書コーパスと法律コーパスの品詞比較など https://speakerdeck.com/mimihub/20190827-aws-mlloft-lt5?slide=18 )(既知の知識に従い前処理を過剰にしてゆけばその結果は古典的な統計手法による結果に近づく.それなら最初から古典的な統計手法を用いたほうが良い.深層学習においては,前処理は最低限にするか,慎重に見極めないといけない.)
・分散表現のpre-train学習に用いるコーパスが個性に大きく影響を与えるのではないか,と思っている.
(個性をもたせるには,コーパスには偏りが必要でありかつコーパスが大きすぎてもいけない,とすべきだろう.すると未知語oovが増加しやすいので,未知語処理が重要となる.ベクトル平均は次善の策とわかっていたのでより適切になるよう一応の対応済み.magnitude https://github.com/plasticityai/magnitude に期待している.)(未知語処理も個性に寄与しているようだ.)(201909時点の未知語処理実装は,transformerを分散表現メインに書き直したような構造となっている。)
・ホットリンク日本語大規模SNS+Webコーパス
https://www.hottolink.co.jp/blog/20190304-2.
・BERTは個性がないが高性能,という意味で外せない個性だろう.
(実装すれば多分市販AI不要となるだろう(今でも不要といえば不要だが,個性解析できてないことに加えて今後の改良に期待して残している.)
→201903BERT実装
*標準のmultilingual modelでfine-tuning BERT試行.入力サイズ1/3で epo16 acc0.9 4min.入力サイズ1/2で epo16 acc0.9 6min.=>記事の最後にBERTの結果を追加する.
・Juman++&BPE 黒川河原研BERT日本語Pretrainedモデル
http://nlp.ist.i.kyoto-u.ac.jp/index.php?BERT日本語Pretrainedモデル
・SentencePiece hottoSNS-BERT
https://www.hottolink.co.jp/blog/20190311-2
・MeCab StockMark日本語ビジネスニュースコーパスBERT事前学習済モデル
https://qiita.com/mkt3/items/3c1278339ff1bcc0187f
*英語では,
BioBERT
https://arxiv.org/abs/1901.08746
SciBERT
https://arxiv.org/abs/1903.10676
などもあるようです.PatBERTは見当たらないな・・・
→Jieh-Sheng Lee and Jieh Hsiang.
PatentBERT: Patent clas-
sification with fine-tuning a pre-trained BERT model.
arXiv
preprint arXiv:1906.02124, 2019.
・BERT以降のSoTA:
MTDNN
https://arxiv.org/abs/1901.11504
Improving Language Understanding by Generative Pre-Training(transformers and unsupervised pre-training)
https://openai.com/blog/language-unsupervised/
Unified Language Model Pre-training for Natural Language Understanding and Generation (Microsoft)
https://arxiv.org/abs/1905.03197
XLNet: Generalized Autoregressive Pretraining for Language Understanding
https://arxiv.org/abs/1906.08237
RoBERTa
https://arxiv.org/abs/1907.11692
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
https://openreview.net/forum?id=H1eA7AEtvS
https://github.com/google-research/google-research/tree/master/albert
RACEでみた進歩.
http://www.qizhexie.com/data/RACE_leaderboard
・・・
*Unsupervised Data Augmentation
https://arxiv.org/abs/1904.12848
「教師なしに用いる」データを作る手法.これは使えそうか.
*Making Convolutional Networks Shift-Invariant Again
https://arxiv.org/abs/1904.11486
*Predictive Uncertainty Estimation via Prior Networks.
http://arxiv.org/abs/1802.10501
*一般形は特殊形の代わりにはならない.
・個性の調整について.
上記システムのweight specific words(wsw)と記載した箇所では,w2v-mpの個性の調整を行っている.
下図(上)から(下)への変化は,w2v-mpモデルに単語「rhoキナーゼ」を重視させることをwswにより試み,その結果「rhoキナーゼ」に期待通りハイライトが当たったことを示している.

(このような柔軟な調整が可能とできるのは自作ならではといえようか.)(モデル内部をいじっている.モデルの理解とメタ知識を利用している.)(ちょっとした事で使いやすくなるのだが,自作でなく市販ツールを用いているとそのちょっとした事ができないのだよね.ベンダーに注文つけてもこのような機能つけてくれたりしないか時間がかかる.AIではこのようなユーザー特化が重要と思っているのでできないというのは致命的ではないだろうか.)(教師データは基本的に過去からしか得られないため,このようなプロアクティブな手法も重要.)(この単語重視により,本特許の順位は164位から84位に上昇.上位100位までの変動を確認するも本特許以外は+-12位内で変わらず.個性を大きく変更せずに,特定の単語を重視させることができたと言って良いだろう.様々な条件が考えられ十分に検証できているとは言えないが.(上記単語を含んでいても,すでに順位が高い場合はほぼ順位に変動なし,など.))(言うまでもないが,何らかの教師が本筋.ただ,安易な教師変更は意図しない性能悪化を招くため,教師変更をした場合には,必ず,全体の検証をし直さないといけない.上記手法はその毎回の詳細な検証をほぼ不要とできるだろう.)
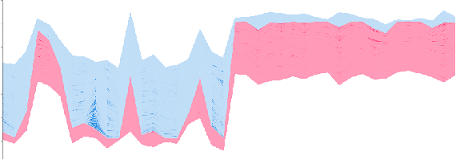
*上図は教師を追加した場合のkeb-mp.図(右)のように,教師データを追加すれば正解候補に正答することは簡単.しかし,ただ単に教師データを追加したのみの場合,図(左)が示唆するようにFPが増えるなど,全体のバランスが崩れうる.
(そも改善用の良い教師データが得られるのは事後であるのであるから,教師データでの改良は,常に手遅れである,と言える.)(data augumentationには基本的に反対.注意深く行ったときのみ可,と考えている.)(自然言語分野において,大量に教師データを追加した場合でも全体のバランスを崩さないといえる深層学習モデルは,今のところ,BERTなどTransformer系モデルぐらいではないだろうか?.)
*Two models of double descent for weak features
https://arxiv.org/abs/1903.07571
過学習のリスクは特徴より教師が小さい場合には低下する?
*ヒトは対象物がある特定の範囲に入るか否かを決めるとき,次のような類別をしていると言われる.
1カテゴリの「ルール」に適合するか
2カテゴリ内の「ある特定の対象と類似」するか
3カテゴリの「基本形」に類似するか
さて,現状のモデルはどこまでできているだろうか.
ルールベースの文構造では担保しきれないことは,文章表現の多様性から見て明らかに思える.n-gramも限界があるだろう.transformerに期待はできるが十分でなく,さらに「構造を抽出する蒸留」が必要となるのだろう.下記,Unsupervised Distillation of Syntactic Information from Contextualized Word Representationsのような.
*Hyperparameter Tuning and Implicit Regularization in Minibatch SGD
Anonymous
26 Sep 2019 (modified: 26 Sep 2019)ICLR 2020 Conference
https://openreview.net/forum?id=ryGWhJBtDB
バッチサイズとノイズ支配,精度.ああ,なるほど.
・ヒト認知との適合についてはC参照.
*Document Scanner using Computer Vision
https://towardsdatascience.com/document-scanner-using-computer-vision-opencv-and-python-20b87b1cbb06
昔々pdfをpyocrだったか?を使って6000件ほど処理させたことがあったが、まともに認識されたのは5割ほどだったかな。そろそろやり直してみるか。
C. モデルの個性をどう理解・評価するか.理解するためのモデルによる自己説明を含めて
*魯の哀公が孔子に尋ねた
「諺に『大勢でいれば迷うことはない』とあるが、今群臣と相談して政治をしているのに国が乱れるのはどういうわけだろう」。
孔子曰く,
「大勢に聞くと言うのは臣下の間で様々な答えが出るものです、しかし今は群臣がみな季孫と同じように振舞うので一人に尋ねているのと同様です」
どのようにモデルの個性を「理解」・「評価」すればよいかにつき,答えを得ていない.
(暫定的な評価をおこなっているがなぜか結果は悪くはない.)(ヒントとなり得る文献等を収集中.)
retrofitting分野の最新研究を追跡すれば,w2v-mpの「理解」に繋がりそうだ.
ヒト認知との適合において個性が確認できた.モデルの個性の「理解」に繋がりそうだ.
check systemによりなされる「モデルによる自己説明」が,「理解」の前提として重要と再認識した.説明可能AIについて,Sharpley値含め,再確認してゆく.
上位概念下位概念を認識し分けているとできれば、「評価」は比較的容易にできるだろう。
決定木によりモデルの個性の「理解」を試みたところ、単語への直接的な依存性に傾向が見られそうであった。1つの説明になり得るだろう。
決定木によりモデルの個性の「理解」を試みる過程で、XORを見分けられるかどうかが個性に影響しているかもしれないとの示唆があった。
ヒトの「認知構造」や「理解構造」において,「直感的な認知や理解とはいえないXOR」が必須である、のであれば面白い。
認知や理解が認知や理解されやすい構造から成り立っているとは限らないわな
・モデルの個性を多く作り,クラスタ分けして,クラスタに特徴的な単語とモデルごとに特徴的な単語を比較し,特徴的な単語を任意に入れ替え比較しつつ,FA,因子分析を行い,「理解」につなげ,その理解をもとにどのように「評価」するべきかの結論を得る予定.
(得られた主因子いくらかをノードとしてベイジアンネットワークに入れることができるかはたまたベイジアンニューラルネットワークで解くか.主因子をSHAP値から読み取るか.どれが最適か,他の手法が良いのか,やってみないとわからない?.とりあえず単語間の相関を無視してナイーブベイズからかな….あるモデルのみが正解する特許を集めナイーブベイズで学習し,ある単語においてあるモデルとなる確率を出し,これをそのままモデル採用の重みにしてみるか?.この有効性を見てから別の手法を考えるか.)
・「理解」について.理解の深さがが正確な評価につながるはずである.しかし見通しが立っていない.
理解するに当たり,共通してありうる構造として文法からのアプローチを取ることが良いのか,認知からのアプローチが良いのか,数式からのアプローチが良いのか.まず,図表を作り,理解できうるか,主因子がどれほどあるか,確認してゆく予定.
(人間の脳は巨視的にはベイジアンだそうな.)(因子が少ないと言えるならQCAも使えないか.個性をブール代数で表現できればわかり易い.演繹的には使えないし要約に無理があるだろうけれど.)(kaggle慣れしている人らはこのような状況に強いのだろうか.このあたりは特に専門家に頼りたいところだ.)
・「評価」について.理解がどのレベルでなされるか,例えば単語レベルなのか,文法レベルなのか,数式レベルなのか,はたまた行動レベルなのか,不明であるため,どのように評価できるか,そも評価可能かどうかも不明である.
基本的には,現在の簡易的な多様性評価手法で行っているように,「良い部分のみ評価する」と「集合知・集団的知性」に基づく良い結果が得られるだろう.「いわゆる」アンサンブルのような平均評価では,集合知は失われ,集合知に基づくベストな結果は得られないだろう.
(良い部分のみ評価する手法だけでは,見落とされたTP(FN)抽出と同時にFP抽出もなされ,総合評価としては向上しない結果にもなりうる.しかし,結果として,現在使用しているモデルの「組み合わせ」ではそうなっていない.この状態を維持するにはFPの多いモデルを避けるだけでよいのだろうか.十分な評価データセット用いた詳細な検証が必要だろう.)(現状,目視で個性が表れた部分を確認し主観的に評価しているが,数字で表現できるべきだろう.しかし,理解が表現レベルであり,表現が意味を超えるところに帰するならば,属人的評価基準を免れないかもしれない.)(p208設計および評価を行うためには,いくつかの補完的な方法を組み合わせて用いるべきだ.この結論は本質的には,定性的方法と計量的な社会学の手法とを組み合わせて,認知的アプローチと行動主義的アプローチとを相互に補完させるようにすることを示唆している.)(適切な評価とは,脳の自然な作用から得られるものではないどころかそれに逆らうもの,ヒトがヒトと言える所以「脳の自然な作用に逆らってまで作りだす理論化」により得られるものだと考えている.適切な評価が「学習」からそのまま得られるとは思っていない.今のところ.(学習で評価する場合,蒸留を用いることができるが,蒸留は幻想的な真値を仮定しており自然言語では現実と離れすぎるのではないだろうか.)(小から大を予測するのではなく大を構造化し予測する,シミュレーションの解析結果を用いたインサイトベースの理論化,のような作業が必要だろう.この章の最後に示す図の「設計範囲のインサイト」のような.))(良いとは何かは,それが新規な場合,事後的にしか認識できえないので,事前に設定することが難しい.この場合事前設定で得られるのは,良いものの一部となる.良い部分を評価するのは良いが,良いと評価できなかったが良い部分を捨てないような評価手法とする,これが難しい.少なくとも,複数の評価,多様性評価が必須であることはわかるが….ある意味,性能を上げることを目標とするのではなく,許容範囲まで性能を落とすことが重要なのかもしれない.)(明記しておいた方は良いと思い直したので明記するが、一つのAIで十分な性能が出ると確認できれば、多様性評価は放棄しますよ。現状そうではないけれど。)
*「いわゆる」アンサンブルは,biasとvarianceのバランスを補正,高variancesを低減(バギングなど)または高biasを低減(ブースティングなど)し,より良い結果を得る手法.多様性評価手法は,高バイアス(基本的には,モデルのバイアス)を個性とみなし「積極的に利用」し,現実に存在する幅のある答え(言語は離散的なイメージなので現実的には答えが常に一つに収束するわけではない.文脈を考慮しても価値観で分かれうる.真値が複数あるイメージ.最適化手法だけでは解けない.)に対応できるようにし,より良い結果を得る手法(高バリアンスを個性と誤解しているのではという疑いがまだあるが).
*(自分の手法において,「教師データ」と,「検証データ」は,「同じ性質のものではない」.教師データは,何を将来求めるかという視点において,注意深く選定・加工されている.同じ不正解でも,学習に用いたい不正解と,学習に用いたくない不正解が存在する.安易なクロスバリデーションによる検証は本件において意味がない.(*ここで記載した検証データはテストデータのことだな・・・最初からCV対象ではなかった。反省。以下、誤解によるものであるがそのまま残しておく。下記は、dataset はtraining+val用には教育用に手を入れたあとのデータを使い、test用には手を入れないデータを使う、その意味でtraing+valとtestを混同してはいけない、CVはtrainig+valデータで行う、datasetをtrain,val,testに分けるだけでは教育として足りないのではないの?というアタリマエのことです。自分はtrainingデータ不足のため、valを作らず、parameter tuningもtestの結果を見て行っています。そのためいつしかval=testと誤解しており、testにCV?と間違えてしまったようです。なお、testをval、valをtestと、人により使い分けが異なるので理解の妨げとなりよろしくないと(責任転嫁の言い訳)。)(ある患者に対するある薬の実効性を観るに当たり,他の患者を含めたCVを行ったとしたら,それに意味があるだろうか?.必要なのはその患者にあった処方をすることだ.医薬品を多数の患者に処方するようなCVを繰り返してもそれは達成されない.実務屋は,開発者と同じ役割ではなく(だけでなく),医師と同じ役割を果たさないといけない.(医師がAI実装に関与してきている現状は、かなり良い流れなのだろうな。AIベンダーは安易には医療AIに進出できないとも言える、医療AIに参加できたベンダーこそが実力を示したことになる、などとも言えるか?))(過去一般に,バリデーション不十分により検証データで性能が出ているのに実データで性能が出ない例が多見されてきた.これを解決するためにCVが重視されるようになったわけだが…同じラベルがついていればどれも同じ価値だと黙示的に前提して,汎用されすぎているように思う.いや殆どの課題はバイアスをなくす前提であろうからそれでよいのですが.)(近年見られるCV?を絶対視したような?学習モデルから得られる結果には,個人的にどうにも違和感を覚えることがある.ある仮説の結果ではあるのだろうが顧客の認知を考えていないような違和感,古典的統計手法やルールベースから得られた結果では感じなかった違和感だ.言うなれば,「自然言語版の不気味の壁」のような.基本的に,古典的統計手法等は,広く通じる認知から得られた主要因を考慮しやすいため,どの顧客の認知にも適合しやすく違和感が生じ難いと思われる.一方,学習から得られた結果は,広く通じる主要因からなるとは限らず,バイアスのある主要因からなることがあり,後者では違和感が生じやすいのではないか.後者にCVを行えば分散が減少し数値は良くなるかもしれないが,バイアスに収束するだけで違和感は変わらない.違和感を無くすには,前者となるようにデータを増やしバイアスを薄めるか,主要因を適切なバイアスとなるように誘導する必要があるだろう.特定のバイアスに誘導する立場において(自分の立場だ),学習データを目的に合わせ任意に厳選するならば,CVに意味はなくなる.学習データは検証データと同価値ではなくなるからだ.)(モデルの性能を比較し示したいならCVのランダム化比較試験は重要である。しかし,それを自然言語モデルで行う際には,データセットが統一されているか,目的に対して適当かどうか,サンプルサイズが十分かどうか,サンプルの分布が適切かどうか,など検討する必要があるのだが,それをしていない事が多いように見える.)(自然言語特有なのかもしれないが.何というか,そもそも一貫した考え方が存在せず様々な正しい考え方,言うなれば様々な有用なバイアス,があるだけだというのに,無理やりそのすべてを潰して現実的に意味がない不気味な考え方に収束させており,それが押し付けがましい感覚を生む,というか.同じ単語同じ組み合わせ同じ共起性のとき,そこから単一のルールを導いたとして,それは目的にかなっているのだろうか,という疑問が.まあそも真値が存在しないとし多様性視点でみているので思い込みもあろう.))(そも文章とは,数値のように連続しており差が明確なものではなく,独立しており一つ一つが意味を持って異なる差が未知のものである.それを評価するには,特定の視点を設定し,差を設定する必要がある.その視点によっては他文章を同価値として比較できるが,どちらかと言えば,CVが有効なほど多くの文章を同価値とできる視点は例外的ではないだろうか.同一データセットにおけるモデル性能の比較など.)(CV自体が問題であるわけではない.)(少数教師において、一部の教師データを削減すれば容易に分布が崩れる。Leave one outでも同じ。そこまでしてtrainからvalデーターを得ることにこだわる必要はなく、CVにこだわる必要もない。実データで検証しても良い、という選択肢を示しておくのもありだと思っている)
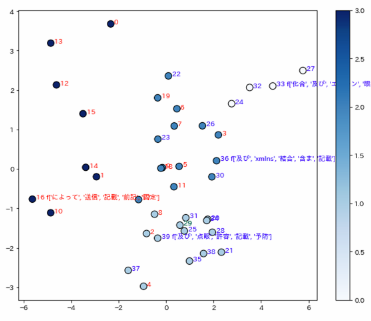
図3)特許ごとのtfidf上位5単語を特定のpre-trained word2vecモデルによりベクトルに変換・合計し,疑似的に類義・関連語を偏らせた場合の特許の分散を見たk-meansーFA図の1.それぞれの分散表現モデルによる影響の感覚を掴み理解のきっかけとするために試験的に行ったもの.(素直にモデルの隠れ層からベクトルを取り出すべきだったと思わなくもない.)(ストップワードを削る前の図.)
*Phase transition in PCA with missing data: Reduced signal-to-noise ratio, not sample size!
https://arxiv.org/abs/1905.00709
code
*言語は人間が作ったのだから人間はその因子を理解可能だ,という仮説に基づくやり方だが実際どうか…モデルによっては重要そうな因子を捨てており,理解不可能に変化しているかもしれない.もし,単語が主因子であり,単語だけで9割程度の説明ができるならば,認識容易性は高そうではある.
*社会的ネットワークの知識が,評価に重要となるのではないかな・・・
*pre-trained word2vecとkeras embedのダブルヘッドをconcatするだけで評価できる可能性もあると思っているのだが,まだ試していない.多様性評価で重要となる「良い部分のみ評価する」構造がないため,足を引っ張り合う気もするが. =>足を引っ張り合っていた.
(互いの独自性のある良い部分は薄くなり,共通する悪い部分はより大きく足を引っ張る.集団化しただけのヒトでもよく見る構造だ.チームとグループは評価手法が異なるとまず理解しておかなければいけない.多様性はチームに該当し,チームでは差を良い点としてピックアップする方法などが必要.浅い理解のまま強権で選択するか(現時点の多様性評価手法はこれ),Googleのようにコストをかけ予め理解しておくか,Google Sprintのように誰でも理解可能な段階まで進めて選択するか(目的関数をAUCの最大化とするのは王道だろう.汎化しないだろうが),3Mのように立証責任を転換し理解責任つまり否定材料がない場合は高評価としておくか….(社会実験している気分になってくるな…))
(文章ベクトルを得るにあたり,文章ベクトルそのものを計算する手法,自分が採用するmaxpoolingモデルのように加工して得る手法,センテンスベクトルを得て合計する手法などがある.このうちセンテンスベクトルを得て合計する手法がより良い有効性を持つ結果が得られる手法となりそうだが,現状あまり良好な結果が出ていない印象.その理由は前記と類似し,「足を引っ張る特徴」が,センテンスベクトルの合計では強い重みを持ち残ってしまうからではないかと.手動重み付けがなされているが,本質的解決ではない.より良い部分のみ評価する改良,文章のトピックと共通するトピックを持つセンテンスの重みを最初から高めておく,など必要ではないかなそれも今ひとつかもしれないが(トピックモデルと組み合わせればよいのか?(センテンスが短すぎまた類義語を吸収しきれないのでそのままではイマイチのようだ).他のベイズ的手法を用いても良いな.分散断表現のクラスタを用いても良い)(減算つまり全体からの一部削除が答えかもしれない)(既存の文章ベクトル作製技術をそのまま用いても,自身の目的に対し十分と言える結果を得ることは難しいだろう.word2vecなど単語分散表現ベクトルからはじめ,自身の目的に応じ自作し独自の文章ベクトルを作ったほうが,手っ取り早いだろう.1つの専用から汎用が得られていると夢を見るのは妄想にすぎるのではないか(お前が言うな?))(様々な文献を見ゆくに,文章ベクトルを直接作ってしまう手法には先がないと感じている.例えば,単語ベクトルの組み合わせ検討動向からすると単語ベクトルの集計手法が確定されてしまうdoc2vecには先がなく,カーネル削減手法の重要性からすると単純に提示するしかないモデルには先がない.自作するなら,何らかの単語ベクトルから始め,技術の推移に合わせて柔軟に目的に応じた文章ベクトルを作れるようにしておくべきだと思う.)(doc2vecはなんというか、ものの特性を一方向からしか見られなくするよう導くような名称で、個人的には好ましく思わない。)(単語ベクトルでも大きすぎるという意見もあるだろう.形態素の究極は何か.今の自然言語処理分野は、分散表現を分子または原子として、素粒子探索や周期表、高次元折りたたみ構造などを同時に探索しているかのようであり、非常に面白い.実は基本構造など無い、または基本構造はより曖昧な電子雲のようなもの、と結論付けられるかもしれずまた面白い.)(ここで言う構造を学習する手法のことを、メタラーニングと呼ぶらしい。few-shotlearnigもメタラーニングの一種とか。)
code
*評価につき参考のため,モデルの個性とその評価基準を擬人化して適当に表現してみる.
・・pre-trained word2vec maxpoolingモデルは,1を聞いて10の発想をする天才肌だが思考があさってにもゆくので,少数の自信のある主張を高く評価すべき.
・・keras embed maxpoolingモデルは,漏れなくカバーする手堅い凡人なので,広く普通に評価するべき.
・・BERTは,秀才だが自身を持って間違え間違いを認めない厄介な積極派なので,主張を広く採用するが自信のある主張でも低く評価すべき.
(安定して高い性能を誇るモデルでも低く評価しなければならない,ばらつきが大きいが最も高い性能が得られるモデルを高く評価しなければならない,かもしれない,というのは面白いな.このあたり,教育論か何かに参考となるものがありそうだ.また,目的関数で処理するにしても,目的関数は個性ごとに可変である必要があるのかなと思わなくもない.)
知識人は問題を解決し、天才は問題を未然に防ぐ。(アインシュタイン)
知識人と天才は相補的であるはず.
| model | 認知的観点 | 解釈学的概念 |
|---|---|---|
| keb-mp | 2 | 2 |
| w2v-mp | 3 | 1 |
| BERT | 2 | 3 |
| Thaïs | 3 | 3 |
| ※ | 概念知識? | 情報検索知識? |
| ※ | 精度? | 再現率? |
・ブラックボックスのまま理解する「機械行動:machine behavior」と呼ばれる新しい学問領域をつくるべきだという提案
https://www.nature.com/articles/s41586-019-1138-y
https://www.media.mit.edu/publications/review-article-published-24-april-2019-machine-behaviour/
「無作為化実験、観察推論、および集団ベースの記述統計 - 量的行動科学でよく使用される方法 - は、機械行動の研究の中心となるはずです」
同感だが,データが必要か.帰無仮説・p値は使いたくないところだが.
『犯罪捜査のためのテキストマイニング』には集団ベースの記述統計の記載が多くあったはず.見直してみる.
・丸山宏(2019)
高次元科学への誘い https://japan.cnet.com/blog/maruyama/2019/05/01/entry_30022958/
同感.過剰な還元主義か.
*認知には2つの考え方がある.認知できる小さな構造の組み合わせから大きな構造が説明できるという考え方(デカルト.モジュール.還元主義?.群知能),そして,認知できる複雑な構造から単純な法則を見つけ出そうという考え方(上記の高次元科学?).例えば画像におけるニューラルを理解しようという試みは前者か.自分が行ったハイライトは前者か後者か.この記事や機械行動,自分が悩んでいる部分は後者か.(メタラーニングや例えばtfidfなど分布は後者か)
*目的効果を得る最適手段の予測においては,関連・相関のみ知ることができれば良いのでブラックボックスで良い(高次元科学?.ここでは恣意的な主成分分析は厳禁と理解している).予測した解決手段から実際の効果を予測するシミュレーションにおいては,相関以上の因果が必要・説明できることが必要で,その説明は新たな理解と理論につながる(還元主義?.ここでは主成分を抽出した理論・仮説形成が重要と理解している).と切り分けるべきなのだろう.
各モデルの予測結果を決定木・ベイズ推定・有向ネットワークを用い説明し理論化する手法が本筋か.SHAPは,個性の存在を証明する手段と,個性の特徴の重みを表現する手法として,明確に切り分け用いるべきなのだろう.
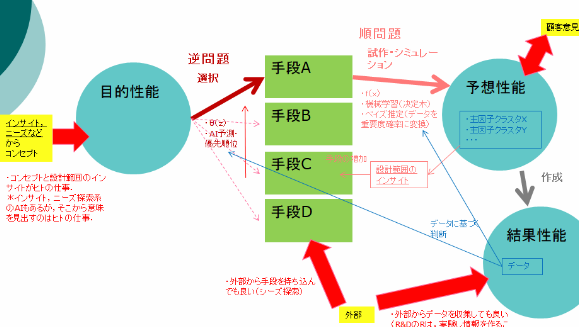
図x)左のAIは目的効果を得る最適手段の予測.右のAIは予測した解決手段から実際の効果を予測.左のAIは統計,右のAIは統計を確率に変換,と言っても良い.例えるなら,左は臨床の結果である統計,右は医師による統計と診断とオミックス情報などに基づく患者に適用できる確率への変換.(まったく考えがまとまっていないのだが,逆問題をAI・ベイズp(x仮説|yデータ)などで解かせ,順問題においてベイズp(yデータ|x仮説)からそれぞれのデータの寄与確率をもとめる,といったイメージか?.)(「なぜそれが良いのかわからないが,それが良いと仮定して,データを構造化することによりとある理論が生まれる」、と説明すると一言で言えるか.)
*AIが予測するCOVID-19の3つの重症化因子(202004)
https://aitimes.media/2020/04/02/4589/?6598
オミックスデータや診断データをもとに学習?.
個別診断やオミックス情報などに基づき「適用できる確率」を求める課題については,(広い意味での)AIが得意とするところだろう.個別診断についてはその独自性から,オミックス情報についてはその多量複雑性から.
本件については,データから年齢の情報がリークしているだけというわけではないよね?
*読んでいないが次が参考になりそう
A practical baysian framework for backpropagation networks. neural computation, 4(3): 448-492, 1992.
・世界の「謎」解くカギ、深層学習は「因果性」を発見できるか?
深層学習の人工知能(AI)は、多くのデータの中から関連性を発見することは得意だが、因果性を見い出すことはできない。5月上旬に米国で開催された「ICLR2019」で、著名なAI研究者が因果関係を分析する新しいフレームワークを提唱した。
by Karen Hao2019.05.17
https://www.google.com/amp/s/www.technologyreview.jp/s/141062/deep-learning-could-reveal-why-the-world-works-the-way-it-does/amp/
*内容確認できていないが,minst色変更誤判断問題につき,改善するには色違いすべてを学習するのではなく,個別に学習すると良い?.ネットワークの利用?.複数のモデルを用いた多様性評価とその発想の根本である社会的ネットワークの考え方に近いだろうか.社会的ネットワークを学び直し答えを探すべきか.単純なネットワークを深堀した研究に答えがあるだろうか.
(ベイジアンネットワークに戻った気もする)(モデルごとの知識マップを立体的に作っておき重ならない部分はそのモデル重視,重なっている部分は高さで重み付けし集計,トピックに一般化させてベイジアンネットワークに入れそのモデルとする確率を評価の重みとする,などで評価できると思っているが,この方法では知識マップ作成に予め枠をつくる必要があるという問題がある.数千程度の特許をPCAなどで図示して,高さを加えた図をモデルごとに作成し…どれだけ時間がかかるか…トピックで近似できると良いのだがバイアスが…適切とするのは空白にも意味を持たせないといけないが…)
*これでよいのかな
Information theory holds surprises for machine learning
https://www.santafe.edu/news-center/news/information-theory-holds-surprises-machine-learning
Caveats for information bottleneck in deterministic scenarios
https://arxiv.org/abs/1808.07593
【論文】メタ強化学習による因果推論
https://qiita.com/kodai_sudo/items/780b3e05c150f9c9dda6
*多様体を1つのニューラルネットワークの中で作り上げてゆく必要はない。多くのニューラルネットワークで作り上げた多様体を最後につなげたほうが良いかもしれない。多様体を相互依存なく独立に加工できるから。(トポロジーを学びなおしているが多様体について誤解があったので後ほど修正削除予定.)
*AIに常識をもたせるタスクと、個性評価手法のゴールについて。
まず、一つの多クラス分類ニューラルネットワークでは分類しきれない課題であり、複数のニューラルネットワークが必要だったと前提する。
ベイジアンネットワークを上流に配置し、その末端にある目的ノードに、それぞれ独立したニューラルネットワークを接続するとする。ベイジアンネットワークでは「ある国」で「ある四足動物」を見かける確率が出力できるとする。
四足動物であることがわかっている画像があるとして、その四足動物は、「日本」では「犬」か「猫」である確率が高いだろう。これは常識を表す。
求められた確率に従い、猫を見分けるニューラルネットワークと、犬を見分けるニューラルネットワークを稼働させる。
結果として、例えば猫だと、常識を加味して判断されることになる。
さて、日本を前提としたので猫と判断されたが、実は「小さな虎」の画像だったかもしれない。
https://www.reddit.com/r/rarepuppers/comments/bb7lfg/the_mystic_tiger_boye/?utm_content=title&utm_medium=post_embed&utm_name=b4322056f05c4faba1ce818d731245fd&utm_source=embedly&utm_term=bb7lfg
その場合は間違えてはいるが、認知的には正しいと言える。人も同じように間違えうるだろう。もし「東南アジア」を仮説としていれば、「虎」と判断する確率は向上していただろう。東南アジアの常識として(例えです)
認知を用いモデルの個性を評価する手法は、例えばこのように、ベイジアンネットワーク・ニューラルネットワークの組み合わせから、形成できるのかもしれない。
独立したニューラルネットワークを多数存在する目的ノード全てに置いていてはあまりにコスト高であるので、一つのニューラルネットワークに統合できる分類と統合できない分類の見極めが重要となるだろう。
ある目的ノードとある目的ノードで共通となるニューラルネットワークを見出すことが重要となるだろう。その為には,ニューラルネットワークの隠れ層からのリーク(隠れ層の共通性やベイズ推定を用いた手法など)や転移学習を用いることが,重要となるのだろう。
最終的には、「複雑なベイジアンネットワークと、50ぐらいのニューラルネットワーク」、つまり脳と同じような構成に圧縮できるのではないだろうか。
個性と多様性評価手法のゴールは、ここかもしれない。
だからまあなんだな、さっさとどの個性を選択すべきかの評価手法を
*上記虎について言い換え。
間違えているが、**「関連」としては正しい。これが間違えだと確信してしまう理由は、確認するヒトが後付で結果の事実をもとに認知バイアスを適用させる作業をし、「時系列と逆方向で因果」**を作り上げているているからではないだろうか。モデルで関連を得たあとに「後付のない因果を整理する構造」(常識を判断うる構造?)を付与することは重要に思える。ベイズは順番を考慮できるから因果を整理する構造の候補としてよろしい・・・?。
https://qiita.com/kzuzuo/items/2bce9e4fe58021a25430
*十分複雑でかつ多量データから事前知識等学んだend to endモデルは、上記のような因果を整理する構造を持ちうるのだろうか?。transformerは因果を整理する構造・・・を保有しているように見えなくもないがかなり偏った認知バイアスを持った後付のある因果を整理する構造となっている印象がある。
*ネットワークが複雑になりすぎないようにノードを限定する必要がある。ノードをある概念範囲内でまとめてゆく必要があるのだが、その概念範囲を、恣意的なセグメントから限定すべきなのか、例えばTDAで求めるクラスタで限定すべきなのか、常識は限定的に数えられるとしてそのまま設定すべきなのか。ベイジアンニューラルネットワークが答えなのかもしれない。
*GRAPH TRANSFORMER
https://openreview.net/pdf?id=HJei-2RcK7
なるほど逆もよいな.下流にグラフを配置することにより「わからない」が適切に抽出でき,「本当の専門家AI」により近づけられるかもしれない.
どのように評価するかにおいて適切な評価は学習で得られないと考えている,と書いたが,なるほど.出力部分に知識グラフを接続し評価することもできるか.ベイズの結果をリアルタイムにグラフ化し人はその内容を定期チェック,でよいか.
*基本的には,「上位概念」(動物,非生物などセグメンテーション)や「常識」はニューラルより上流に配置し,「下位概念」(具体的な診断結果など)や「わからない」はニューラルより下流に配置すべきと思うが,上流に配置されたグラフをあまり見ない…ああ明示されていないが,前処理や入力のグラフ化が該当しているのか?
*Utilization of Bio-Ontologies for Enhancing Patent Information Retrieval
https://ieeexplore.ieee.org/document/8754131
*いずれにせよ,まずデータ集め.(「ほぼ」だの「多分」だの「思う」だのばかりでは.)
*201906現在,実データで確認されている性能は次の通り.
・・BERT以外のモデル(市販AIは除く)は,正解を上位10-15%以内に集め,一部を20%付近に見逃す.
・・BERTは,殆どの正解を上位2%以内に集めるが,一部を30%付近に見逃す.
・・多様性評価は,殆どの正解を4%以内に集め,正解を10%以内に集める.
(今のところ,実データでこれを大きく外さない.あっても良いと思うのだが,下位に落ちた正解が見つからない.特許文章は比較的類似を見分けやすい文章だとは思うが,ここまで実データで性能が出続けるとは思わなかった.)
(と書いたあとにBERTがやらかした.実データ内のある正解となってほしい特許を,30%どころでなく48%に配置.残り2モデルは同じ特許を,8%,11%に,3モデル多様性評価は同じ特許を15%に,3モデル平均評価は同じ特許を17%に配置している.3モデル多様性評価の15%は,BERTのみを使用していた場合母集団の半分近くまで確認しなければ見つからないことを思えばだいぶ救済しているといえるが,10%を超えると感覚的なありがたみがない.)
(作成中の検証用データには,教師データと重複する情報を含まない?,後付で欲しかったと言える特許を含めても良さそうだ.概念により教師データ不足をカバーするのも目的の一つだしな.5割正解すれば御の字程度の難しい検証データとしよう.)(しかし,汎的な立証にはならないな.うーむ.数式で示す部分を増やすしか無いか.)(実データで実効性あり.検証データをより良く作っても傍証にはなっても証明にはならない.何らかの理論的説明は必須だろう.この点明らかに自分の能力不足があるので先人に頼るわけだが,理論的説明を十分にする文献が見つからないな.数式の理解不足で説明されているのに気づけない感も多々あるが.)
*ナイーブベイズ(暫定)
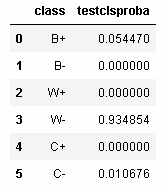
*BERTが不得意とした単語でソート
まだ暫定的なテストデータを用いた暫定値だが,例えばP(単語「眼」|モデル)は,高い順にBERT0.89 > keb-mp0.67 > w2v-mp0.11 となる.SHAPや実データの結果から得られる感覚とだいたい一致するか.
*暫定的なテストデータにおいて,使用したBERTは,使用したあるアルファベット文字列に弱いという結果が得られている.この結果をどのような上位概念にまとめ上げることができるか定かではないが,仮説としては,ある条件のアルファベット自体に弱いのではないかと思っている.とりあえず,暫定的にモデルの前処理方法に手を加えてみることとする.(良し悪し.)
とりあえず,このままナイーブベイズでモデル個性の評価を補正する予定.
現状の各モデルは,ウィンドウ処理により位置普遍性を持ち,分散表現は近距離作用しかないから,ナイーブの前提にある程度適合する・・・はず・・・なので,そこそこの性能は出るのではないだろうか.
*モンテカルロ法を利用しヒートマップなど確認しつつ相関を拾い理論を作り出す手法も試行中.分布をどうしたものか.
*限られた特徴語からベイジアンMCMC個人差多次元尺度構成法を用いた場合,どのように解釈できるのだろうか.
*ベイズ深層学習が答えなのかもしれない.重みの分布と確信度が得られるなら,それをもとにモデルの個性を評価すれば良い?.事件があるたびに確信度を更新すれば意思決定は容易となる。
須山敦志(2019)
ベイズ深層学習
講談社サイエンティフィク
筑波大HCOMP研究室の勉強会資料です.
https://speakerdeck.com/catla/beizushen-ceng-xue-xi-3-dot-3-3-dot-4
*動的ベイズ推定
*PACベイズ理論はモデル分布の事前/事後確率間のKLダイバージェンスを一種の複雑度とみなし汎化ギャップを評価する https://arxiv.org/abs/1901.05353
*ジェリー・Z・ミュラー(2019)
測りすぎーなぜパフォーマンス評価は失敗するのか
みすず書房
https://www.msz.co.jp/book/detail/08793.html
1情報の種類
2情報の有益性
3測定を増やすことの有益性
4標準化された測定に依存しないことによるコストは。他の情報源はあるか
5測定の目的。誰が見るのか
6測定のコストは
7なぜ評価を求めているのか
8測定方法は誰がどのように開発したのか
9最も優れた方法でさえ汚職や目標のズレがある
10限界の認識
最終的に重要なのは、どれか一つの測定基準と判断の問題ではなく、判断のもととなる情報源としての測定基準。測定基準にどのように重みをもたせるのか。その特徴的歪みを認識しているか。測定できないものを認識しているか。
評価基準を作ることで、その評価基準から外れたものを評価できなくなる誤り。最低限ここにハマらないよう気をつけなければ。
*言論マップ、議論マイニング
*いまさらだが,「知識ベース knowledge base」を調べると良いのか?.知識ベースの領域に個性と多様性の議論があるのか?
https://speakerdeck.com/cfiken/nlpaper-dot-challenge-wai-bu-zhi-shi-niji-dukuying-da-sheng-cheng-sabei?slide=28
文章の意味と個性
相澤彰子 国立情報学研究所教授
NHK技研R&D 2018.4
https://www.google.com/url?sa=t&source=web&rct=j&url=https://www.nhk.or.jp/strl/publica/rd/rd168/pdf/P02-03.pdf&ved=2ahUKEwjeiY3N0qLkAhWgy4sBHetKAMoQFjACegQIBhAB&usg=AOvVaw3GuRDWW9Jo1MiaEfm7uxW6
表現上の個性と認識上の個性は…
*あるべき文章ベクトルについて.
文章のベクトル表現は、曲げたりひねったりできず、予めある仮説に基づき直線上に配置するしかない。これに不満がある。ベクトルはもっとシンプルに、仮説の変化により柔軟に変化できるべきだ。
シンプルな文章ベクトルを柔軟に曲げる手法を考えよう。
*伸び縮み可能とできれば、解像度の違う文章、上位下位概念で書き分けられた文章にも対応できるか.すれば特許文献と各原著文献やSNS情報を同一平面に図示することも可能か.
*文章ベクトルを伸び縮みさせる手法の候補として再帰型ニューラルネットワークがあるわけだが,可能であれば教師なしとしたい.なぜ教師無しとしたいか、それは、ものには無限の特性があり、どの表現も無限に可能であることから、教師ありではいつまでたっても不足となるためだ。充分に足りる、はあり得るが。
*自然言語においてCNN,poolingを用いる際の問題の原因の一つに、画像では全体が一定の解像度であるところ、文章ではその部分ごとに解像度が変化する点があると思う。一定のウインドウでは全解像度に耐えられず、マルチウインドウでもどの部分がその解像度にマッチしているか定かでは無いため適切な重みとなっているか定かではない?(多様体として抽出できているが重みが打ち消される?ノイズだらけになる?ネガポジの打ち消しが強すぎる?)(トポロジーを学びなおしているが多様体について誤解があったので後ほど修正削除予定.).解像度を認識してウインドウサイズを可変とする処理ができれば、上位概念下位概念を吸収したより良い結果が得られるのではないだろうか。
*上位概念と下位概念の解像度の統一を目的とした変換について.
下位概念1単語と,それを説明する10単語があったとする.この次元を統一し,可視化等で同一表面に提示したい.
たとえば,2つの次元が異なるが類似する文章があったとする.
文章Aにはある下位概念1単語が含まれ,文章Bにはそれを説明する10単語が含まれていたとする.
文章Aにつき1単語を分散表現として得る.文章Bにつき10単語それぞれの分散表現を得る.
文章Bの10単語は分散表現上類似しているはずだから?,同一クラスタに配置される?.
同一クラスタとなった10単語の分散表現を合計する.
文章Aの1単語の分散表現と文章Bの合計された分散表現は類似し,解像度変換が達成できる.
・・・とうまくゆけば良いのだが,問題だらけだ.
まず,このままでは,文章Aの1単語も,周辺の単語を巻き込み足されてしまうだろう.重要でない周辺単語を除く処理が必要.
*現在,tfidfで抽出して上記処理を行うプログラムを試作し動かしているが,ある程度の次元統一と同一表面での可視化が可能となっているかもしれない.(tfidf embeddings/cluster vis)
同一特許の要約(下位概念で記載されているもの)・請求項(上位概念と下位概念が含まれるもの)・明細(上位概念の記載が多いもの)を別に読み込ませ,どれほど近くに現れるか見てみるか・・・
*教師なしで可能なauto encoderを用いるのが妥当だろうか。
*解像度の変換(言い換えのこと)を行う1手段がattentionであるわけだが??,直接圧縮しているわけではない?.依存しすぎてよいのだろうか.attentionもpoolingも似た作業を行っているが,伝播と圧縮の両立性という点ではpoolingにもまだ目が.
*次の文献を見つけた.
Pay Less Attention with Lightweight and Dynamic Convolutions
https://arxiv.org/abs/1901.10430
CNNーattention.Dynamic Convolutionは局所的なself-attentionともみなせるとのこと.
(チャンネルをグループ分けする部分については,「多様体としては抽出できているが重みが打ち消される」問題を解決しようとしているように見える.CNNのチャンネルはネガポジで打ち消す事があるその傾向を考えれば,グループ分けでなくクラスタリングするほうが良さそうに思える.またチャンネル数の動的適正化機能を入れても同じかもしれない.(トポロジーを学びなおしているが多様体について誤解があったので後ほど修正削除予定.)
https://qiita.com/koreyou/items/328fa92a1d3a7e680376
(CNNの打ち消し対策の1.正規化後に、バッチからの共分散とサンプル毎の分散を組み合わせて脱相関
Channel Equilibrium Networks
Sep 25, 2019 ICLR 2020 Conference Blind
https://openreview.net/forum?id=BJlOcR4KwS )
*attenntion部分について,多様性評価手法ならではのやり方としては,BERTからattentionを拾っておいて,他モデルの重み付けに使うというのも良いかもしれぬ.(以上考え方はBERTと同じといえば同じ.)
*QAタスクの性能向上はほとんどの自然言語タスクへ影響を与える.解像度の変換問題も,QAタスクで解決させることもできるだろうか.(ActiveQAなど適当か?)
Talk to books
https://books.google.com/talktobooks/
Universal Sentence Encoder https://arxiv.org/pdf/1803.11175.pdf
Both the transformer and DAN based universal encoding models provide sentence level embeddings that demonstrate strong transfer performance on a number of NLP tasks. The sentence level embeddings surpass the performance of transfer learning using word level embeddings alone. Models that make use of sentence and word level transfer achieve the best overall performance.
*複数のモデルを用いるとはある意味多様な解像度に対応しうるともいえるか.ならば,上位概念下位概念変換モデルを追加すると良いか。(Window sizeの拡張版といったイメージか?.しかしwindow sizeがモデルの個性に与える影響が大きいと言えるデータを見つけてはいない。)(解像度対応はBERTモデルが担当しているとして検討を打ち切ってもよいか.工夫の余地がない点が気になるが)
*解像度が同一である場合の置き換え手法には,ルールベースの辞書や分散表現,wikipedia2vecなどがある.ルールベースで解像度を増加させることは可能だが,単に解像度を増加させるだけでは文脈を無視する結果につながる.
*解像度変換のタスクがあった気がしてきたぞ(いまさら)
QQPタスクで,解像度が違う文章の同一性が判断できる.同一言語間の翻訳タスクも同じか.後は教師なしだが・・・これ教師なしでできるなら翻訳も教師なしでできることになるな・・・転移学習でも・・・
SQuADタスクで質問文を一定とすれば,textから1次元のwordが取り出せるけれど.これ教師なしでできるのか?.
教師なしで1次元に圧縮するとは,文章の本質の数値をえること.word2vecは分散を圧縮しているだけであり文章の本質の数値を得ているわけではない.学習無しで文章の本質を得るには・・・文章の特徴語を抽出して特徴語の分散表現を合計するぐらいしか思いつかない.ウインドウサイズを1から30ぐらいまで変化させ文章をソートしウインドウ内の単語分散ベクトルをすべて合計したリストを作り,リスト内部で最も近い数値を抽出し,文章全体をもっとも小さなウインドウとなっていた単語群となるようにおきかえてゆけば,解像度は揃うが・・・助詞まで含めた合計が意味的に等しい単語の数値とほぼ等しくなるようにできうるものか?.BERTベクトルなら?.
a b c a b
a b c d e f 同じ意味の文章だが異なる単語が使われている
a b o p q r
a bとd e fが同じ意味であり,a+b≒x,d+e+f≒xとする.ウインドウサイズ2のウインドウがabをxと計算,ウインドウサイズ3のウインドウがdefをxと計算.文章の最初の単語から順番に全ウインドウ集計結果から最近値をソートし,最もウインドウサイズの小さい単語群に置き換えてゆく.
a b c a b
a b c a b 同じ意味の文章→同じ文章
a b o p q r
または
x c x (int)
x c x (int)
x o p q r (int)
そのままCNNにかける場合,CNNにおいて全マルチウインドウのconcatを行えば,上記変換のための多様体ができいるといえ,そうであるなら解像度変換ができているかもしれないわけだが・・・いや,これを学ぶ過程はないし,そも学習に任せた結果と任意に行う結果は異なるか.とはいえとりあえずaveragepoolingモデルをマルチウインドウ化してみるか(accuracyに大差がなかったためしていなかった)(トポロジーを学びなおしているが多様体について誤解があったので後ほど修正削除予定.).前処理としての文章の解像度変換も試してみよう(数値がほぼ等しく,が達成できずノイズだらけになると思うけれど.最低でもあと一つ何かが必要.
Attentionにwindow概念を適用し広げればどうなるのだろう?attention自体がwindowの代わりをしてはいるのではあるが.
→SpanBERT
https://arxiv.org/abs/1907.10529 範囲と範囲の境界を予測
*「無料でオープンソースの写真管理ソフトが特許を侵害している」と謎の企業によって非営利団体が訴えられる
https://gigazine.net/news/20190926-shotwell-lawsuit-patent/
AIには,このような特許を見つけ出す性能を持つことを期待している.そのため自分は,AIに上位概念下位概念変換や解像度変換能力の高さを求めている.辞書では限界があるため分散表現に期待する.するとノイズが増える.それをカバーするためにも,多様性評価手法が必要となる.他の手法があればそれでも良いのだが,今のところ,教師依存の手法しかないように見えている.
*複数粒度の分割結果に基づく日本語単語分散表現
https://www.anlp.jp/proceedings/annual_meeting/2019/pdf_dir/P8-5.pdf
解像度ではなく粒度のほうが良い?.ここで言う粒度は形態素の区切りの違いにより類義語が類似とならないことを問題視しているが,自分は上位概念と下位概念で類似とならないことを問題視している.少々異なるか.
*(以下考えがまとまっていない)
私は昔から,単語を「集合」と「分布」(分布だけでも良いけれど)よりなる概念として,少なくとも3次元上の概念として認識しており(特許を読むものは多かれ少なかれ似た認識を持っていると思うが),文章はその和か積だろうと認識していた.今は,単純な和や積ではないと考えている.単語を表す集合・分布は原子の電子雲のようなものと考えており,分子の電子雲が原子の電子雲の単純な和となっていないように,文章の集合・分布は,ある構造的ルールに基づいた(例えば重心位置の違いを考慮した)計算をして求められるべきではないかと考えている.
(ベイズがその答えを与えてくれるのではないかとなんとなく思っている.KLダイバージェンスで分布の距離を測って・・・てそれなら)(GCNや化学物質予測タスクにおけるBERTの利用についても,興味深く思っている.)(機械学習モデルに入力する文章を,単語の集合・分布をノードとしたグラフとすれば,面白いのではないであろうか.前後または同一クラスタとなった単語間の距離をエッジとしつつ分布を重ねるなど、ありうるのではないか.)(構造形成について、基本的にはCNN類似+ウインドウの構造化である程度良い結果が得られるかと思っている.…位置普遍性は重要だが、弱い位置情報を与えてみてもよいのか?試してみるか)
(単語の分散表現は単語の集合・分布を内包しているとも言えるかもしれない.集合は文脈として内包しているとできるだろう.分布はどうか.自動的にガウス分布を仮定しており(というのもおかしいが)検討されていない気がする.真値があることを仮定してしまっている気が.この場合,複数の真値を仮定する必要がある認知に対応できないのではないか.(ピーク高さを表す重みと、足切りを表し「集合の広さを確率分布に従い変化させる」重みの2つを利用すれば?)(ある単語のベクトルの周りには、単語が設定されていないが類似するベクトルが存在し、ある単語周りにガウス分布している。という分布の考え方。「空」単語ベクトルの扱いをどうするかが重要になるのか?。空単語ベクトルの生成自体は分布を仮定しランダムサンプリングすれば良い。文章内の単語すべての単語ベクトルを、平均や和を含め、shapley値を高さとした等高線を用い図示し、類似する2文章で比較するなどすれば、分布に関しなにか見えてくるか?)(単語ベクトルのいくらかの次元は認知である,または認知を加えるべきである,としても良いが,concatは何故かいまいち.認知は,多次元と並列平等に扱うのではなく,多次元全体に正規化を施した上で影響を与えるようにする必要があるのだろう.単語ベクトルの次元全てに平等に影響を与えるのではなく,分布を仮定し影響を与える必要があるのだろう.てこれがそも記憶ネットワーク,transformerか.認知分布をどのように設定するかは興味深い.予め概念として認知分布を作っておく,つど教師データから学習し認知分布を作る,リアルタイムに認知分布を指定する,フィードバック制御として認知分布を設定する,すべてが必要に思う.)
文章について.
単語の分散表現の単純な和は短文では意味を残すが長文では意味を残し難いと知られている.何らかの単純な和でない構造が必要と理解されている.自分はこれは(biasでなくvalianceの影響もあろうが)分布の問題ではないかと考えている(というより,そうだったら興味深いな,に近い).文章の分布形成はモデルに依存しているように思う.CNN類似モデルではマルチウインドウが文章の分布形成を受け持っていると言えなくもないかもしれない(複数峰をmaxpoolingで選出することにより個性抽出ができる,できている,かもしれない).最近のモデルにおけるクラスタ利用の流れは一部を削減することで,擬似的に適当な分布を作っていると言えるのかもしれない.「モデルの個性」の正体は,これら文章の分布形成の違いかもしれない.分布が異なるならそれは概念の違いといえ,概念の違いが認知上の個性ならば,「モデルの個性」は正しく「個性」と言えるのかもしれない.)(分布もbiasとvaliance双方含み見分けがたいところがなんとも.ガンマ分布とベイズかな最終的には))(→本文のベクトルの伸び縮みにつながる.)(まあ自分はガウス分布を想定したままモデルごとに真値を1つにまとめ(あとに述べる「類義・関連語」の価値観に基づく「歪め統合」のこと),異なるモデルが持つそれぞれの真値を最終的に評価計算する手段をとったわけだが,より上流で対応できるのではないだろうか.)(BERT,attentionはボトムアップ注意、w2vembmaxpはトップダウン注意、相互補完しているため多様性評価がうまく行っている、などと考えて良いものか(…逆か?))(日本認知科学会2019ヤフーポスター、圏論に基づく分散表現の加減算の定式化に向けて.単語ベクトルの点をオントロジー(トポロジーだったか)で面に変換し?(分布を考えるよりトポロジーを用いたほうがモデルに相対的に最適化しやすく適切だろうな)圏論を用い射の構造抽出して分散表現の説明とし理解につなげる?と理解してよいのか.定式化後、ベクトルの乗算等の性質も検討?.うーむ,わからんが,ベクトル群をクラスタリングした後クラスタ群をノードとした有向グラフとすることとどのように異なるのだろうか?.この定式化ができれば,特許請求項の数式化も見えてくるだろうか.とても楽しみ.興味深く追跡してみる. https://research-lab.yahoo.co.jp/en/nlp/20190905_miyazaki.html )(概念を別に作る視点と概念を構造を用い誘導して作る視点が混ざっており何言ってるのかわからないな我ながら.)(化学物質合成タスクでSMILES記法条件下のMolecular transformerがSoTAとなったのを見るとBERTで十分と思わなくもない.)(BERTの手法なら空ベクトルを補いやすいかな.)(メタラーニングを追うと良さそう)
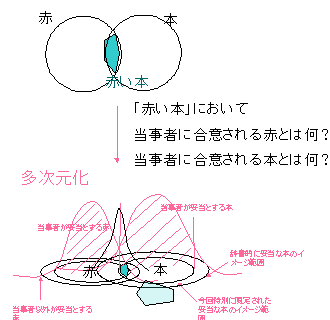
単語に分布をつけると重心が適切にずれる?.文章ベクトルを作るにあたり,機能語はルールベースで分布と距離を微調整するように使えば良い?.意味語は認知分布に関わるだろうが,機能語は認知分布に関わだろうか?.
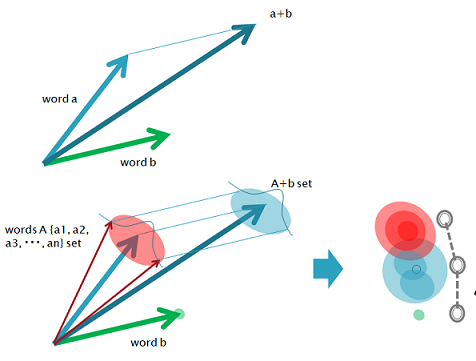
*Analysis of Word Embeddings using Fuzzy Clustering
https://arxiv.org/abs/1907.07672
"In contrast to hard clustering techniques, where one point is assigned exactly to only one cluster, fuzzy clustering allows data points to pertain to several clusters with different grades of membership"
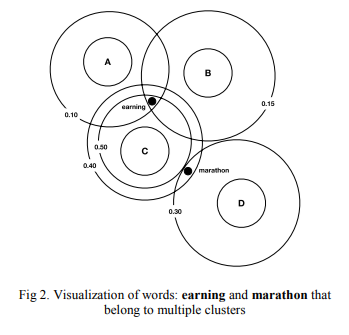
このあたりどうだろうか.複数クラスタの共通部分に変換すれば解像度変換もできそうでもある.ソフトクラスタリングには他の手法もあるがいずれでも分布を持ち込めるか?
単語を分布で考えるモデルは,1gramのいわゆる言語統計モデルや無限語彙モデルと呼ばれる基礎モデルであるようだ.
伊庭幸人,持橋大地ら(2018)
ベイズモデリングの世界
岩波書店 p69−
https://sites.google.com/site/iwanamidatascience/BayesModeling
ここから独立生起仮説を外すとその延長として,n-gramモデルや無限n-gramモデルがあると.また言葉の意味の統計モデルとしてトピックモデルの一種であるLDA(階層ベイズを取り入れた)が.さらにword2vecが紹介されている.これらは上記に言う構造を形成していると言えるのだろう.(これらを分布という視点で見ていなかった.勉強不足やな.)
さて,これらでも十分でないことはわかっている.基本に帰りつつ,他の構造も仮定できないか考えることとしよう.上記のように,内容語としての単語でなく,機能語の役割を考え直すことはできるのだろうか.
Randall K. JamiesonJohnathan E. AveryBrendan T. JohnsMichael N. Jones(2018)
An Instance Theory of Semantic Memory
Computational Brain & Behavior, 1(2), 119–136
https://link.springer.com/article/10.1007/s42113-018-0008-2
プローブ部分が上記分布と類似するか.分布と分散表現,認知についての記載あり.考え方が似ている.著者追跡してゆくか.
*人類の文化的躍進のきっかけは、7万年前に起きた「脳の突然変異」だった:研究結果
「記憶のなかの複数の単語を意味のあるメンタルイメージとして合成するプロセスは、「前頭前野統合(Prefrontal Synthesis)」または「メンタル統合(Mental Synthesis)」と呼ばれている」
「「単語の柔軟な組み合わせと入れ子構造は、すべてのヒト言語に特徴的な機能です。このため言語学者は現代的な言語を『再帰言語』と呼んでいるのです」と、ヴィシェドスキーは言う。
しかし、複数の単語が複雑に組み合わさった入れ子構造の文章が理解できるかどうかは、受け手の前頭前野外側での「統合」能力にかかっている。そしてこれを可能にするメンタル統合能力の発達には、非常に重要な時期があるという」
https://wired.jp/2019/09/01/recursive-language-and-imagination/
https://riojournal.com/article/38546/element/8/24430/
メンタル結合能力。立体視と同じく後天的なんやな。概念構造形成時の誘導が重要なのでは。
*The Cognitive Tradeoff Hypothesis
https://www.youtube.com/watch?v=ktkjUjcZid0
短期記憶と言語・予測のトレードオフ。進化における喪失と取得。概念構造形成時の誘導は重要に思える。どのような誘導が必要なのだろうか.忘却だろうか.「特徴を抽出するのでなく非特徴を如何に削減するか」が重要ではないか.AIでも,得られた特徴をあえて削減することが必要なのではないか.
(削減に付き,ランダム性の高いdropout以外の構造には何があるだろうか.クラスタリングが答えである気がする.)(「平均の平均の周りに分布する」モデルとすれば,個性(ここではデータの個性)を取り入れつつ全体の情報も利用でき安定した推定が可能となるとのこと.前述「ベイズモデリングの世界」)(これが近年のクラスタリング利用活発化の理由だろうか.クラスタリングにより,「データの個性」を拾い上げることができる(個性的なデータは単独で1クラスタを形成する).「モデルの個性」とは,「モデルが拾い上げる「データの個性」に差違があること」,と表現するとよいかもしれない.自分のモデルの多くは(下記tfidf可視化含めて),このクラスタリング(と分散表現を組み合わせて)を利用している.).(共有の視点で考えれば,予測型AIに多様性を用いる方向性は正しいように思える.)(クラスタリングによりメモリ削減など性能を落としつつ改善させよう,としたところ,結果として,従来より性能が向上した,という結論となっている文献がそこそこ目立つようになってきている気がする.どこかで集計してみるか.)
*理研ワークショップメモ(理解を間違えているかもしれない)
・ものづくりの時代の流れは,「もの(毎回実験)→理論・式(シミュレーション)→計算(可視化・解析・予測)→データ駆動(計測→ネットワーク→AI)」.
・「測定」自体の先鋭化による「多量のデータ」作成→「ネットワーク」による技術の保管・共有→保管された技術と多量の測定データを処理する「AI」,が重要となってくる.
*可視化は,AIのブラックボックスを解明するためやAIの説明責任のような文脈で語るのではなく,AIとヒトが互いを?理解しつつ協同するため,という文脈で語るべきかと思う.
*Diversity in Machine Learning
https://arxiv.org/abs/1807.01477
https://arxiv.org/pdf/1807.01477v2.pdf
!そのままのタイトルだが,Computer Vision and Pattern Recognitionに分類されていたため見逃していた.
機械学習における多様性に関するサーベイ.
201905v2において,「モデル(らの)多様性」の項が加えられたようだ.良きかな.しかし,この項に付されている引用は殆ど無い.個性の評価手法に関するヒントはない.v3に期待.
"IV. MODEL DIVERSIFICATION
In addition to the data diversification to improve the performance with more informative and less redundant samples, we can also diversify the model to improve the representational ability of the model directly. As introduction shows, the machine learning methods aim to learn parameters by the machine itself with the training samples. However, due to the limited and imbalanced training samples, highly similar parameters would be learned by general machine learning process. This would lead to the redundancy of the learned model and negatively affect the model’s representational ability.
Therefore, in addition to the data diversification, one can also diversify the learned parameters in the training process and further improve the representational ability of the model (D-model). Under the diversification prior, each parameter factor can model unique information and the whole factors model a larger proportional of information [22]. Another method is to obtain diversified multiple models (D-models) through machine learning. Traditionally, if we train the multiple models separately, the obtained representations from different models would be similar and this would lead to the redundancy between different representations. Through regularizing the multiple base models with the diversification prior, different models would be enforced to repulse from each other and each base model can provide choices reflecting multi-modal belief [27]. In the following subsections, we’ll introduce the diversity methods for D-model and Dmodels in detail separately.
B. D-MODELS
The former subsection introduces the way to diversify the parameters in single model and improve the representational ability of the model directly. Much efforts have been done to obtain the highest probability configuration of the machine learning models in prior works. However, even when the training samples are sufficient, the maximum a posteriori (MAP) solution could also be sub-optimal. In many situations, one could benefit from additional representations with multiple models. As Fig. 4 shows, ensemble learning (the way for training multiple models) has already occurred in many prior works. However, traditional ensemble learning methods to train multiple models may provide representations that tend to be similar while the representations obtained from different models are desired to provide complement information. Recently, many diversifying methods have been proposed to overcome this problem. As Fig. 6 shows, under the model diversification, each base model of the ensemble can produce different outputs reflecting multi-modal belief. Therefore, the whole performance of the machine learning model can be improved. Especially, the D-models play an important role in structured prediction problems with multiple reasonable interpretations, of which only one is the groundtruth [27]."
「図4で示すように、アンサンブル学習(複数のモデルをトレーニングする方法)は、以前の多くの研究ですでに行われています。しかしながら、複数のモデルを訓練するための伝統的なアンサンブル学習方法は、類似する傾向がある表現を提供し得るが、異なるモデルから得られた表現は補完情報を提供することが望まれる。最近、この問題を克服するために多くの多様化方法が提案されている。図6に示すように、モデルの多様化の下で、各基本モデルは異なる出力を生成することができます。したがって、機械学習モデル全体の性能を向上させることができる」
自分の見解と同じ.Recently, many diversifying methods have been proposed to overcome this problem.に引用なし.Recently,manyなら例示してほしいが.up
"VI. APPLICATIONS
Diversity technology in machine learning can significantly improve the representational ability of the model in many computer vision tasks, including the remote sensing imaging tasks [20], [22], [77], [112], camera relocalization [87], [88], natural image segmentation [29], [31], [95], object detection [32], [109], machine translation [96], [113], information retrieval [99], [114], [158]–[160], social network analysis [99], [155], [157], document summarization [100], [101], [162], web search [11], [98], [156], [164], and others."
*AI Samuraiのシステム構成をみた.
非常に誠実なシステムという印象.類似検索は「キーワード検索」「ベクトル類似度(分散表現)」「グラフ分析」から行い,何らかの方法でスコアを集計している(任意重み付けであると聞いたような聞かなかったような).3つの検索手法は,まとめればCNNと同じようなことをしているわけだが,あえてCNNにしないことで短文に対応しやすくしつつ明確性を高めているように見える.この点,誠実に見える(お前は分散表現任せで不誠実だ?.非常にごもっとも.).
ただ,この3つの検索手法,分布が十分に異なっている(類義語を十分に引き出している)のであろうか?.公開されている特許を読む限り,実際はもっと複雑なのだろう.
*GeoInformatica 2019, Volume 23, Issue 2, pp 221–242
Using word embeddings to generate data-driven human agent decision-making from natural language
https://link.springer.com/article/10.1007/s10707-019-00345-2
「このアプローチでは、フィールドインタビューのトランスクリプトからWebの非構造化データまでのテキストソースを使用して、人間の認知をキャプチャおよび表現できます。ここでは、言語のベクトルベースの表現である単語の埋め込みを使用して、類似性比較を使用して推論するエージェントを作成します。このアプローチは、さまざまな自然言語の意思決定タスクにわたる人間の意思決定バイアスに対する理論的期待を反映するのに効果的であることが証明されています。概念実証エージェントベースのモデルを提供します」
"prompt = "Linda is 31 years old, single, outspoken and very bright. Sh
e majored in philosophy. As a student, she was deeply concerned with i
ssues of discrimination and social justice, and also participated in a
ntinuclear demonstrations. Which of the following is most probable?"
options = [ "Linda is a bank teller.",
"Linda is a bank teller and active in the feminist movement.",
"Linda is a feminist."
[0.2744873996226564, 0.5923732736455332, 0.35307643353440243]"
def calculate_phrase_vector(word_set, embeddings):
'''
Input: list of words
Output: average vector
'''
phrase_vector = np.zeros(embeddings.dimensions)
for word in word_set:
# goes through each word, finds the vector in the precomputed vector file,
# multiplies it by the frequency of that word, and then adds it to the phrase vector
try:
phrase_vector = np.add(phrase_vector, embeddings.get_embedding(word))
except:
print("Skipped", word, "in phrase vector")
try:
phrase_vector = np.divide(phrase_vector, len(word_set)) # averages the phrase vector by total number of words in phrase
except:
print("Phrase Vector 0")
phrase_vector = np.zeros(embeddings.dimensions)
return phrase_vector
えええ
*Does Technological Diversity Help or Hurt Small Firms? The Moderating Role of Core Technological Coherence
https://ieeexplore.ieee.org/document/8384275
*Generative Models for Automatic Chemical Design
https://arxiv.org/pdf/1907.01632.pdf
https://speakerdeck.com/elix/elix-cbi-2019?slide=20
*我が国の伝統的な組織的意思決定方法をマルチエージェントシミュレーションで実装するためのモデル設計
https://www.jstage.jst.go.jp/article/jasmin/201906/0/201906_181/_pdf/-char/ja
「この組織的意思決定方法による効果について 宮本は『村でとりきめをおこなう場合には,みんなの納得のいくまで何日でもはなしあう』
『みんなが納得のいくまではなしあった。だから結論が出ると,それはキチンと守らねばならなかった』と述べており,十分な合意が形成されることを指摘している。
H.A.サイモンの意思決定は,
「情報活動」「設計活動」「選択活動」「検討活動」の順にプロセスが定義され,問題解決のための代替案を「選択活動」で評価する際にも,各代替案を評価する統一的な観点を定義し,評価スコアを定め,最大の評価スコアとなった代替案を採用するといった。定量的なものである。
・各エージェントがお互いに十分な意見交換を行うこと
・各エージェントの意見が全体の結論に対し程度の差はあっても加味されていること
集約した探索進路ベクトルを数学的なベクトル合成に相当する演算により合成することで求める」
ううむ
*Semantics derived automatically from language corpora contain human-like biases
https://science.sciencemag.org/content/356/6334/183.full
*Text Embedding Models Contain Bias. Here's Why That Matters.(Google AI Blog)
https://developers.googleblog.com/2018/04/text-embedding-models-contain-bias.html
「Googleでは、意図しないバイアス分析と緩和戦略を積極的に研究しています。これは、すべてのユーザーに適した製品を作成することにコミットしているためです」
自分は,「すべてのユーザーに適した製品を作成すること」とは「逆」の,「個人用アシスタントAI」を想定している.方向性は悪くないようだ.
"The Word Embedding Association Test (WEAT) was recently proposed by Caliskan et al. [5] as a way to examine the associations in word embeddings between concepts captured in the Implicit Association Test (IAT). We use the WEAT here as one way to explore some kinds of problematic associations.」
いまさらだが,個性評価にはこのWEATテストまたは類似手法が役に立つのか?
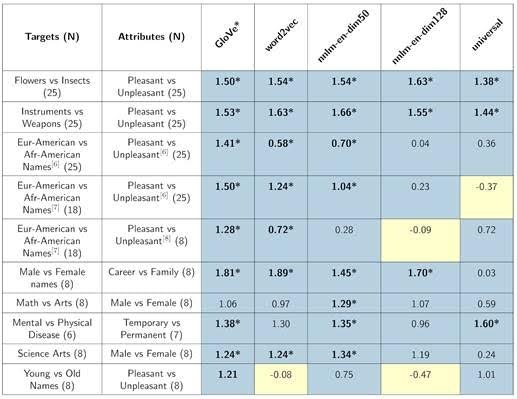
Table 1: Word Embedding Association Test (WEAT) sc7ores for different embedding models. Cell color indicates whether the direction of the measured bias is in line with (blue) or against (yellow) the common human biases recorded by the Implicit Association Tests. Statistically significant (p < 0.01) using Caliskan et al. (2015) permutation test. Rows 3-5 are variations whose word lists come from [6], [7], and [8]. See Caliskan et al. for all word lists. For GloVe, we follow Caliskan et al. and drop uncommon words from the word lists. All other analyses use the full word lists."
"For developers who use these models, it's important to be aware that these associations exist, and that these tests only evaluate a small subset of possible problematic biases. Strategies to reduce unwanted biases are a new and active area of research, and there exists no "silver bullet" that will work best for all applications. When focusing in on associations in an embedding model, the clearest way to determine how they will affect downstream applications is by examining those applications directly."
うむう
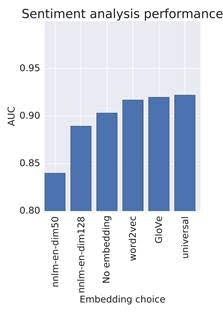
"We'll evaluate the quality of the sentiment classifier using the area under the ROC curve (AUC) metric on a held-out test set.
Here are AUC scores for movie sentiment classification using each of the embeddings to extract features:"
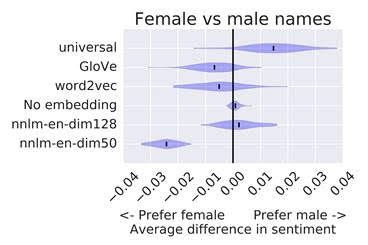
"At first, Tia's decision seems easy. She should use the embedding that result in the classifier with the highest score, right?
However, let's think about some other aspects that could affect this decision.
Looking at the WEAT scores for various embeddings, Tia notices that some embeddings consider certain names more "pleasant" than others. That doesn't sound like a good property of a movie sentiment analyzer. It doesn't seem right to Tia that names should affect the predicted sentiment of a movie review. She decides to check whether this "pleasantness bias" affects her classification task."
"In this case, she takes the 100 shortest reviews from her test set and appends the words "reviewed by _______", where the blank is filled in with a name. Using the lists of "African American" and "European American" names from Caliskan et al. and common male and female names from the United States Social Security Administration, she looks at the difference in average sentiment scores."
"There is no one "right" answer here. Many of these decisions are highly context dependent and depend on Tia's intended use. There is a lot for Tia to think about as she chooses between feature extraction methods for training text classification models."
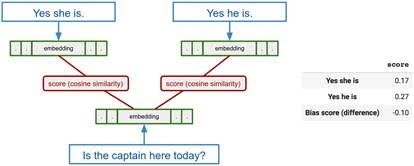
"Conclusions
To better understand the potential issues that an ML model might create, both model creators and practitioners who use these models should examine the undesirable biases that models may contain.
We've shown some tools for uncovering particular forms of stereotype bias in these models, but this certainly doesn't constitute all forms of bias.
Even the WEAT analyses discussed here are quite narrow in scope, and so should not be interpreted as capturing the full story on implicit associations in embedding models.
For example, a model trained explicitly to eliminate negative associations for 50 names in one of the WEAT categories would likely not mitigate negative associations for other names or categories, and the resulting low WEAT score could give a false sense that negative associations as a whole have been well addressed. These evaluations are better used to inform us about the way existing models behave and to serve as one starting point in understanding how unwanted biases can affect the technology that we make and use. We're continuing to work on this problem because we believe it's important and we invite you to join this conversation as well."
単語の分布,文章の分布の問題とするか.
*個性について.個人的には,個性とは概念の違いのことだと考えている.
(ここで言う概念のことを,認知科学では表象と言うらしい?.この場合,「概念」=「価値観」・「辞書」=表象,(「データ」→表象→「情報」)=「歪め統合」=プロジェクション,と理解してよいのか? 特集「プロジェクション科学」編集にあたって https://www.jstage.jst.go.jp/article/jcss/26/1/26_6/_pdf/-char/ja )
(プロジェクションの考え方は、価値共創、ものと顧客双方のスキル・ナレッジが必要とするサービスとサービスが交換されるという考え方に似ているかな.「価値共創」は認知考慮、個性考慮そのものか.顧客がそのスキル・ナレッジを用いてものから価値を抽出している,という考え方は認知そのものだな.多様性評価も価値共創そのものか.)
*個人的には,モデルの理解が足りない状態で適切な教師を設定することは難しいと考えている.例えば,単語を主因子とするモデルであればそのような教師を渡すべきであるし,単語と互いの共起性を主因子とするモデルであればそのような教師を渡すべきである.サリバン先生はヘレンに水に触れさせ水に名前があることを学ばせたが,熱い,冷たい状態を水と呼ぶと学んでしまう可能性もあった.教師はヘレンを理解し学ばせる必要があった.
また,概念として保持したいデータは概念として学ばせるべきであり,直接教えたいデータは教師として学ばせるべきであると考えている.「教師データ」とは流れる水,「概念」とはそれを通す河の形,そしてその双方が変化するなか,ある流れを得たいときにどちらの変化が必要なのか見極めなければならない.その水は河の形を作れるのか,その河の形はその水を受け入れるに適切なのか,水を受け入れる際に河の形を変えてよいのか.
必要な理解は,データ1結果7数学2ぐらいのウエイトか.
*概念とqはデータを入れ情報を出力する入れ物.人は,多くのインプットに基づき脳内に概念という入れ物(河の形)を削り,そこにデータ(水)を流してゆく.概念において最も重要なのは,その境界であって,中身ではない.(別の言い方をすれば,概念とは母集団の階層とエッジの適切な把握,データとはその母集団に高さと構造を持って入る多様体.…うまく表現できない.適切に訓練された専門家の脳にはエッジを流動的に見極める概念がある,ぐらいに留めるべきか.)(概念を入れ物とみなすのでなく、データに概念を付加したものが情報であるとする考え方もあるそうです.)
*データに触るためには概念という入れ物が必要.概念を作るためには多くのデータインプットが必要.これを学習という(学習とは概念を作る行為であり,データを詰め込むことではない).概念がない状態とは,重要なデータがこぼれ落ちる,理解できないことが理解できない状態.非専門家と専門家の違いは,概念のエッジの認識と更新にある.非専門家は,概念が形成できていないか,一度概念を作ったのち更新しない状態にある.概念を更新しない状態とは,硬い入れ物となり変化に対応できない前こうだったと経験のみ持ち出す判断を取りがちな状態である.(本当の)専門家は,概念を流動的に変化させる.現在よく見られるAIは,概念形成を教師データのみに丸投げしており,適切な概念形成のために十分と言える構造をまだ持っていない.それにより,データが多量に必要かつバランスを崩しやすいものとなっており,バランスを取ることができれば概念のあるものや専門家に,取れなければ概念が無いもの(データを受けられない)やエセ専門家(データを適切でない概念に入れる)になるという,コントロールされていない不安定な状態にあるように思える.
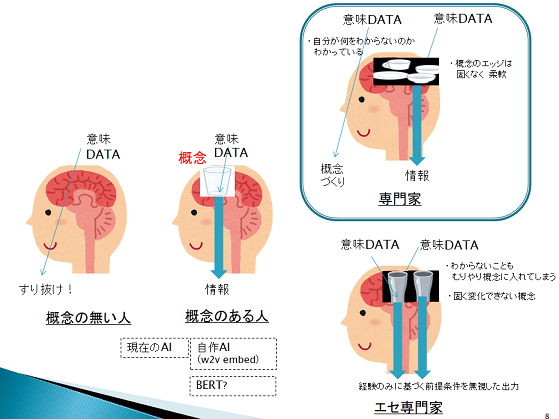
自然言語では概念形成に必要十分なデータを毎回適切に用意することが難しい(似た文章データを用意することはできるが,画像と異なりそれが概念形成に寄与するかどうかわからない(猫という概念に当てはまる画像データを用意することは容易だが,猫という概念に当てはまる文章データを用意するのは困難.これは「認知」にも関わるから.ある場合では猫からフランスを認知してほしいかもしれないが,猫からフランスを認知する情報を付与した文章を「特定の教師データとして」揃えることはまず無理だろう.))(認知を考慮しない大量の類似教師データを用いることにより,意味レベルでは正しい答えを導き得るが,認知レベルではそうならないだろう.自然言語における実用では,認知を無視することはできない.「認知を考慮した少数教師データ」で判定を可能とするモデルが必要である,と考えている.)(欲しい答えを教えたとしても、それが概念形成に役立っていると言えるのか明確ではない.教師データを安易に変える手法は悪手だろう.)(認知科学では、意識的処理における概念によるトップダウン駆動と、無意識処理における知覚によるボトムアップ駆動の考え方があるようだ。画像は後者、言語は前者、自ずと手法は異なる、というべきなのかもしれない。).
概念形成のための構造を備えた(あらかじめ概念を作っておいた)専門家AIがいま必要だと思っている.
(概念形成のための構造でも認知を取り入れた構造でも同じ…か?.)(ついで,その概念構造は1つに収束しないとも考えている.つまり、本質的に最適化問題ではないためそれだけでは解けない、と考えている。)(自分は概念を,後に述べるように,「辞書」と「価値観」に分けている.)(文章に加え図表や数式を用いるのは誤解の余地を減らすため.文章は「意味(文脈含む)」を表すが,「認知」の問題により「情報」を適切には表さないため,誤解の余地が大きい.この点が画像系と自然言語系の本質的違いだろう.文章のみを用いかつ誤解の余地を小さくするには,「意味」を「情報」に変換する「概念・認知処理の構造」を備えることが必須だろう.)(BERTで自然言語でも転移学習が有効だとわかったことは,予め概念を作っておくという視点においてとても価値のあることだった.個性という面から観るとそれだけでは不十分だが.)(転移学習は元ドメインから目標ドメインに転移させるが,元ドメインが概念すべてを学んでいることを前提とする.これから,「概念の形に絶対的な答えがある(例えば句構造の絶対化など)」と前提しかねない.画像ではそれで良いだろう(縦線斜線耳構造などは絶対としても良い)が、自然言語ではそれはエセ専門家への道となりかねない(文法的に正しい文しか認めないなど)し,創造性は生まれにくくなるだろう.先に述べた,個性という面から観るとそれだけでは不十分だが,とはその意味.だからBERTをモデルの一つ以上に扱うつもりは,今のところ,無い(蒸留に関しても同じ考え方をしている.こちらはやりようがあるだろうけれど.)(とりま,RoBERTの延長技術がどうなるか見守リ、要事入れ替える.))(とはいえ,転移学習の元ドメインにおいてどのような構造が得られるかにも依存する.柔らかい概念(句以下?3-gramぐらい?)で止めておけば,個性の源として機能するだろう.→BERTの項参照)(この項,全体的に書き直した方は良いな.概念について2通りのイメージをしているのにそのまま混ぜてしまったからわけわからん.)
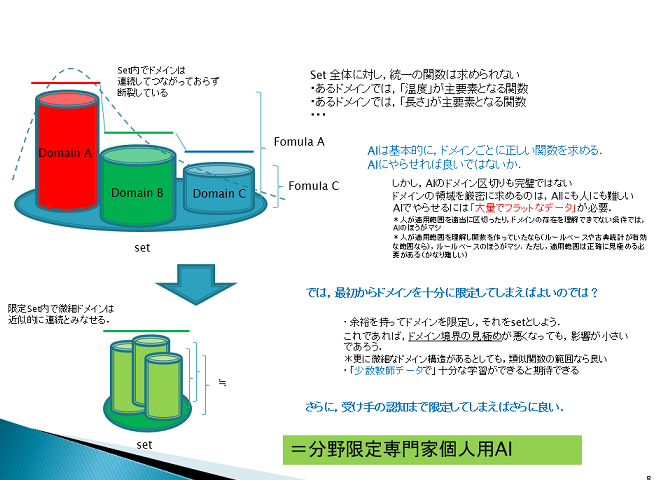
上記図は、少数教師を最も単純な方法で達成する考え方を示したもの。
後述している常識グラフ→ニューラルネットワーク→専門家グラフの流れの前半部分、と言っても良い。
この手法を取らずとも、ドメインの調整手法は様々ある。自分は以下にクラスタリングと表現していることが多い。AIには大量にデータが必要だ、という条件は、絶対的なものではない。
なお上記は、帰納的予測のあとの演繹的仮説づくりにおける理解可能性にも関係する。
(AIが使えない、という人は、まずこの辺りから見直すべきだと思う。AIが使えないではなく、AIを使えない、例がとても多いように観える。まあ使い方を工夫しようもないAIもあるけれど。)(回帰と同じく,関数がHölder関数で表現でき活性化関数がReluであるときの効率的な近似,といえばよいのか?. https://tech.preferred.jp/ja/blog/deep-nonpara-regression/ )(ドメイン間で共通する要素を学習したい場合には,最近はマルチタスク学習を行うことが多いらしい.自分の場合は目的上多分不要だが.)
*小さいデータにもとづいてディープラーニングを使う方法(201912)
https://ainow.ai/2019/12/12/181633/
まとまった記事が公開された.このうち「モデルの分解」が上記に該当.
コサインロスは手元の実装でも予想外に良い結果を生んでいて納得感がある.
「昨年のNIPsに提出された論文「現代のニューラルネットワークは小さなデータセットに一般化される」では、著者たちはディープラーニングニューラルネットワークを多数の小さなニューラルネットワークが合わさったものとして捉えている。「特徴を抽出するのに増えていく階層をもつ各層に注目するよりは、最終層が提供する集合的メカニズムに着目するほうが賢明だ」と論文では述べている(※訳註3)。わたしも小さいデータを活用するためにこの論文のアイデアを使ったのだが、論文にあるような集合的効果の利点をうまく活用するためにぜひニューラルネットワークを構築してほしい」
Matthew Olson Abraham J. Wyner Richard Berk (2018)
Modern Neural Networks Generalize on Small Data Sets
32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, Canada.
https://papers.nips.cc/paper/7620-modern-neural-networks-generalize-on-small-data-sets.pdf
前述していたように、まさに,そのとおりだと思う.自分がやってきたことは,泥臭いが,ここだ(一つのディープニューラルネットワークが多数の小さなニューラルネットワークをあわせたものそのもの,と期待通りになるか,という点には,上記に「構造」として述べたとおり,個人的には疑問があるが.).
というかこの論文見つけられていないといかんやんかわし・・・
この文献があれば他者への説明がかなり簡単になるな良きかな。
ここから被引用引っ張れば良い文献が見つかってゆきそうやな・・・
元記事:How To Use Deep Learning Even with Small Data(201911)
https://towardsdatascience.com/how-to-use-deep-learning-even-with-small-data-e7f34b673987
*@AndrewYNg
Deep Learning is getting really good on Big Data/millions of images. But Small Data is important too. Am seeing many exciting applications at Landing AI where you can get good results w/100 images. Hope more researchers work on Small Data--ML needs more innovations there.
4:48 - 2018年9月28日 · Palo Alto, CA
*few-shot-learningは流行の只中.
*end-to-end学習は,ドメインの区切りを見分け難くし多様性が低下するという点で,現状,どうなのかなと思わなくもない.ドメインの区切りを見分けやすくし多様性を維持する技術も開発されつつあるようで,将来的には,上記ドメインの話は,古い技術のみ使う場合,という限定がつくかもしれない.個人的には,解決手段が難しいというよりも,情報と多様性を見分けられるデータを揃えることが難しい気がしている.マルチタスク学習は,比較的少数の教師しかない場合でも,情報と多様性を維持することができやすい技術である,と考えており,興味深く見つめている.
https://qiita.com/Ishio/items/6ec1b3e84da647a8025e
*Talk to book(transformer)において,「モデルの多様性」を検索
https://books.google.com/talktobooks/query?q=importance%20of%20diversity%20for%20model%20on%20machine%20learning&
"This diversity of models gives machine learning systems great problem solving power. However, it can also be a bit daunting for the designer to decide which is the best model, or models, are for a particular problem.(view in book)
from Python: Deeper Insights into Machine Learning
by Sebastian Raschka, David Julian, John Hearty
Packt Publishing, 2016 ⦁ Science
“Python: Deeper Insights into Machine Learning” by Sebastian Raschka, David Julian, John Hearty"
お、おう。これは読まねばなるまいか。まず著者からやな。
" Other approaches to increase diversity rely on the use of a high-level model to combine object-level models derived from different machine-learning techniques, e.g., stacked generalization [41.78]. Alternatively, we can inject structural diversity in the...(view in book)
from Springer Handbook of Computational Intelligence
by Janusz Kacprzyk, Witold Pedrycz
Springer Berlin Heidelberg, 2015 ⦁ Science
“Springer Handbook of Computational Intelligence” by Janusz Kacprzyk, Witold Pedrycz"
"To further demonstrate how diversity can produce complexity, I present a model by Nowak and May (1993). This model considers the evolution of cooperation in a spatial setting.(view in book)
from Diversity and Complexity
by Scott E. Page
Princeton University Press, 2010 ⦁ History and Biographies ⦁ Science"
biasかvalianceか.双方diversityと表現されていてわかりにくい.
(関係ないが,特許の先行技術調査や権利化可能性探索タスクについて.Talk to bookやwisdom XのようなQAで解決するとよいと思うのだ・・・.主引例は文章全体の類似性で探し,副引例はQAで探す,これが能力的にも業務フロー的にもベストではないか.構成要素毎の類似性からでは要素間の組み合わせの引力を計算できないため限界があると思う.ここは変化する部分でもあるし,素直に人にやらせたほうが筋が良いのでは・・・.と考え自分はそうしている.
(数千件の母集団を作りtfidf embeddings/cluster visから主因例を探し、副引例をtalk to booksとwisdon x、google patent Σsimillarから探す。解像度変換ができ、書籍データが十分データベース上に掲載されるようになるなら、これで十分と思える。ついでに言うと、この2つが達成されているシステム等は今のところ無いと思う。どうせ中途半端なら・・・)(非特許文献や書籍の全文検索もできるように,となれば,Googleにしかできない気がする.)(Google patentのΣsimillarは,時期からするとTalk to bookと同じく,Transformaerであろう.明確でないが,すでにできるようになっている,のかもしれない.)
http://www.peterbloem.nl/blog/transformers
*Learning to Discover Novel Visual Categories via Deep Transfer Clustering
https://arxiv.org/abs/1908.09884
改善のため内部でクラスタリング処理.最近良く見る気が.「特徴を抽出するのでなく非特徴を如何に削減するか」という視点で良いのだよねこのクラスタリングは.
*Revealing the Dark Secrets of BERT
https://arxiv.org/abs/1908.09884
Attentionヘッド一部削除で性能向上.どのように削除するattentionを選択したのか興味深い.
*Errudite: Scalable, Reproducible, and Testable Error Analysis
https://medium.com/@uwdata/errudite-55d5fbf3232e
UW Interactive Data Lab
Aug 13 · 11 min read
Error analysis is a compass, and we need it to be accurate.
Error analysis — the attempt to analyze when, how, and why machine-learning models fail — is a crucial part of the development cycle: Researchers use it to suggest directions for future improvement, and practitioners make deployment decisions based on it. Since error analysis profoundly determines the direction of subsequent actions, we cannot afford it to be biased or incomplete.
But how are people doing error analysis today? If you read some quotes from ACL papers (a top conference for NLP, or Natural Language Processing), this is what you see:
“We performed an error analysis on a sample of 100 questions.”
We randomly select 50 incorrect questions and categorize them into 6 classes.
We sample 100 incorrect predictions and try to find common error categories.
クラスタリングでエラー累計.エラー文章が教師データより希少だという問題はあるが.
*Reflection on modern methods: when worlds collide—prediction, machine learning and causal inference
https://academic.oup.com/ije/advance-article/doi/10.1093/ije/dyz132/5531243
因果推論サーベイ?
*A Topological Analysis of Patent Statistics" (with Emerson G. Escolar, Yasuaki Hiraoka, and Yasin Ozcan)
https://arxiv.org/abs/1909.00257
*「減算と縮約」
https://ci.nii.ac.jp/naid/40019565591
全体を圧縮する縮約でなく、全体から削減する減算?。「特徴を抽出するのでなく非特徴を如何に削減するか」と同じ方向性と理解してよいのかな.多くのAIや,アンサンブルの平均,concat,文章の解像度の違い,に感じていた違和感はこのあたりかもしれない.w2v-mpには「減算」を行わせるようにしたいものよ.L1正則化を再検討しても良いかもしれない.
「多様体がない部分を削除することは良いが、多様体があるかどうかわからない部分を削除してはいけない,解る部分のみを抽出することは良くはない,解る部分以外を削除する考えではいけない.わからないものは通せという,3M準拠基準?で評価することが重要」と勝手に理解した.まだ原文を読んでいないが.
(原文入手.哲学そのもの?.
「想起としての記憶力」は上記で述べたような,知覚とともに回路をなし記憶のイメージで文字を埋め合わせ紙面上に投射され文字に取って代わる.「縮約としての記憶力」は知覚「に」混入し,現在そのものを構成する.この2つが認識の主観的な側面を構成する.知覚の主観的覆いからの純化のため縮約否定.縮約抜きの知覚考察の結果としての「減算」.減算に伴う削除とは多様体を局所的に分離し表層的になること(クラスタリングと理解してもよいのか?).生成とは削除(遮断)のこと.遮断自体が変化する必要がある.記憶力の役割は縮約によって量から質を得ることにあり,反対に減算モデルでは潜在的なものを考えるにあたりこの2軸では不十分となる.圧縮と拡散が対応.減算モデルにおいては向かわなければならないものに到達すること以上に悪いことはないのではないか(動的平衡の話か?)〜
まあなんだな,自分の目的においてこのようなことも理解しておく必要があるということはわかる.ルールベースでないところで「学習時に構造を導くモデル」が必要とするならば,その構造が,言語全体を上位概念に行き着くした場合どのようなものになるか,を考えて想定しなければならない.そうでなければ実装しようがない.その構造を想定するにあたり,どうしても多様体の姿を考えないといけないだろう.それには哲学のようなものの理解も必要なのだろう(数学的に多様体を考えたほうが良いのかもしれないが,どうしても認知できる特徴に寄せたくなるのよね・・・).まあ,哲学書を分類できるAIならば合格,という基準を作れば良いのではないだろうか,と投げやりに考えてしまう程度に頭が痛い.)(トポロジーを学びなおしているが多様体について誤解があったので後ほど修正削除予定.)(現在の広範な知識からのフードバックのような印象も.トートロジー気味に思えてきた.)(w2v-mpの歪め統合は、縮約か?.主観否定の為の減算なのだから、バイアス重視の歪め統合は縮約で良いのか?.全体としては減算だが部分的には縮約?.)
スパース仮説,全て独立でなく少ない独立成分が基底となると仮定し次元集約すること,が減算?.
減算と縮約はどちらか選択するものでなく統合するもの,と思えてきている.カプセルネットワークではないけれど,**少ない独立成分を選ぶのではなく,少ない独立成分をカプセルに押し込める,言い換えれば解像度を考慮し歪め統合する,**必要があるのではないかな.
*Gated Convolutional Neural Networks for Domain Adaptation
https://deepai.org/publication/gated-convolutional-neural-networks-for-domain-adaptation
自分より上流で処理しているが参考になる.多くの概念を作って評価基準…いやこれは自分と逆,別概念からの流用か?.gateの工夫次第では…いや,これwindowの多様性のみから概念を作っているので限界があるか.どちらかといえばランダムなクラスタリング手法に近いか。
システム図にpre-train部分をpre-domainと表記したが,domainと表記して正解のようだ.
キーワードdomain流しで検索すればモデルの個性についての関連文献も見つかるか?.前述のサーベイには記載がなかったが.
*辻井潤一(2016)
研究の個人史─言語処理,言語理解,人工知能─
人工知能 31(4)
https://t.co/mNnA6ggFCf?amp=1
「記号や構造による定式化が自然に見える意味処理や推論処理も、その計算過程の多くは無意識下での非明示的な処理で実現されている」
*最適な感覚統合で「主体感」を定量化-心理実験を統一的に再現する理論-
Roberto Legaspi, Taro Toyoizumi,
"A Bayesian psychophysics model of sense of agency",
Nature Communications, 10.1038/s41467-019-12170-0
http://www.riken.jp/pr/press/2019/20190918_1/
「行動と帰結の間に因果関係のある認識の「確からしさ(確率)」が、実験的に報告されている主体感の強弱とよく一致することが分かりました。さらに、この理論を用いて、これまでは統一的に理解することが困難だった主体感に関する心理実験を説明することに成功し、主体感を定量化する新しい数式を提案しました」
*「能動学習と受動学習とで比較し,能動学習の方が成績がでるが「学習した感」は低いという結果.学習した感を評価基準とすれば」
Measuring actual learning versus feeling of learning in response to being actively engaged in the classroom
https://www.pnas.org/content/116/39/19251
AIを使う観点において重要となりそうか.因果が明確にならないとAIを使っている気にはならない?.AIに課題まで提示されないと満足できない?.
「皆にインサイトを得る能力とモチベーションがある」という前提は,あまり当てはまらないのか?.ならばインサイトの次のステップ,「妥当な因果を示す仮説の提示」,まで,AIにやらせるべきか.
*西田勇樹(2019)
洞察問題解決における無意識的過程に関する研究:プライミング法を用いた検討
cognitive study 26(2) 291
https://www.jstage.jst.go.jp/article/jcss/26/2/26_291/_pdf/-char/ja
「手がかり妨害効果(インサイト?が問題解決の成績をかえって低下させる現象)は抑制機能(無関係な情報を排除する認知機能)が強く働く人で現れることを明らかにした」
ふむう.
*初期から用いていた40件の検証用データval40では,多様性評価を適用させると正解候補に全問正答してしまう状態となっており,現状以上に理解をすすめることが難しくなっている.さらなる理解を得るため一定の基準に従い前向きに検証用データの収集を始めて(と言っても基準を公開して収集してきたわけではないので今ひとつだが)半年以上,やっとある程度のデータが集まった.
Val460: 460件の検証用データ.教えていないかつ重要でもないけれど個人的に興味深い,という重要度Cの特許群を加えたハードなもの(教師データと語彙が共通していないことも多く,ある程度の創造性がなければ正答できないであろう.というかいくらなんでも無理だろう…理屈の上では,w2v-mpの歪め統合範囲に複数の単語が入っていれば正答可能だがその同時確率は…)(重要度Cには,後発シェア計算特許や,いらすとやのイラストがあって面白いな,という何をどう考えても高スコアとすることは無理だと思われる特許も含みます.)
→1評価の結果
| 重要度 | 正解候補 上位10%以内相当率 |
|---|---|
| A | 98.7% |
| B | 91.7% |
| C | 72.4% |
*実データにおいて上位10%となる評価値の平均を閾値とし,それを越えたval460サンプルの割合を10%以内相当率とした.
(閾値を設定した再現率で表現してもよいのだけれど.精度は目的上重要ではないので示さない.F1値は精度に引きずられるため目的上適切な指標とならないため示さない.)
*重要度A:落としたくない重要特許.
*重要度B:重要ではないが,教師内容を拡張して拾い上げて欲しい知っておきたい特許.
*重要度C:重要ではなく教えておらず知っておく必要もないが,個人的に興味がある特許.
*書いておいてなんだが,この絶対値は自分の課題においてそうできた以上の意味がないので,公開する意味は殆どないだろう.ある薬がある個人に対しどれだけ効いたかそれのみは,他の個人にどれだけ効くものなど示すものではなく他の個人にとって重要ではない.ある個人にとっては非常に重要なことだが.
(その抗うつ薬はあなたに効くか – AIが予測するうつ病治療効果202003 https://aitimes.media/2020/04/01/4562/?6598 「あなたに」効くか.どのように個人特化した検証をしたのだろう・・・ああ,脳波から一般的特徴をとってきたのか・・・.しかし,個別診療にもAIが出張ってきた・・・まあ,EBMとなり難い,「エビデンスから予測し難い」,「個々の診断結果が重要となる」,「個別診療」については,「多次元の診断結果を迅速に計算できる」AIのほうがヒトよりもそも向いているか.)
*Aはこの程度だろう(相当率100%となるのは上位11%のとき.).Bはもう少し改善必要あり.Cは50%もあればと考えていたのだが予想以上.重要度Cはw2v-mpの創造性を観察するために設定したようなものだが,分析の結果はどうなるだろうか.ざっと眺めた限りではもう少し創造的であって欲しい.
*興味深い点として,正解候補では個性が見られていると言える特許が多いのに対し,不正解候ではあまり個性が見られないという点がある.自分の教師の作り方をから考えると,幹と枝葉のうち,枝葉において個性が現れていることを示しているようで興味深い.
*現在は更に改良を進めており,重要度Bもほぼ100%に到達している(expert systemによる効果.AIだけで100%なんて無理に決まってんじゃない(おい)).しかし,本当に欲しいところは重要度C,ヒトが思いつかない部分の創造性だ(expert systemでは正解率が上がリにくい部分).この部分に関する考え方や手段・評価手法に関し,(いい加減本気で忙しいので趣味の範囲で)調査を進めてゆかねば.
*あれだけ時間かけて用意した検証データがそれを考慮した改良により一瞬で意味を失う…なにか虚しい.
*一旦休止するか.あとは改良のための文献メモに徹することにしよう.
*分野限定個人用AIの検証には,同一分野の複数の個人による主観的な検証が必要となる.ぶっちゃけ狭すぎる.さてどうしたものか・・・
*ElasticsearchとBERTを組み合わせて類似文書検索
https://hironsan.hatenablog.com/entry/elasticsearch-meets-bert
BERTベクトルで類似検索.時代の推移は早い.ベンダーだよりかなこの辺りは.
*Googleが自然言語処理の弱点「言い換え」を克服するデータセットを公開
https://gigazine.net/amp/20191004-paws-x-dataset-google?__twitter_impression=true
言い換えを教師ありで解決させようとした場合,どれだけのデータが必要となるのであろうか.
*Anonymous
Unsupervised Distillation of Syntactic Information from Contextualized Word Representations
26 Sep 2019 (modified: 26 Sep 2019)ICLR 2020 Conference Blind
https://openreview.net/forum?id=HJlRFlHFPS
Keywords: dismantlement, contextualized word representations, language models, representation learning
TL;DR: We distill language models representations for syntax by unsupervised metric learning
「文構造と文意を別々に識別できるモデルを教師なしで得ることを目指している.構造が同じで語彙が異なるものをPositive、その逆をNegative.」
"We demonstrate that our transformation clusters vectors in space by structural properties, rather than by lexical semantics. "
構造と単語の意味を切り分ける蒸留?.disentangleはこれからさらに注目されそうだ.切り分けられるなら少数教師により近づく.創造性を検討するなら,単語の意味を残し構造は無視する,などできると良いだろう.
*Disentangled な表現の教師なし学習手法の検証
https://research.preferred.jp/2019/10/disentangled-represetation/
あまり考えたことがなかったが,分散表現の次元毎の特性を確認するのも面白いか.
(original [('オロパタジン', 1.0), ~
0 disentangle 0 [('思い知る', 0.4159422516822815), ~
20 disentangle 0 [('辺鄙', 0.43800055980682373), ~
40 disentangle 0 [('なで切り', 0.28907349705696106),~
~
ベクトルを1割ずつ抽出し類似単語を得てみた。合成すればオロパタジンという意味になるはず。今回の抽出の仕方だと、オロパタジンとは、「思い知り」「辺鄙」で「なで切り」~「オロパタジン(1割まで削ってもまだオロパタジンが出てくる・・・)」であり「両目」で「グロンサンゴールド」であるらしい。・・・うーん?。どう考えるべきか。5割ほどまでの抽出ではほぼ変化なしであったので(高次元なので当然ともいえるが語彙が不足しているともいえる)1割まで削ったこと自体には問題はない?。今回はテストであるので不連続に抽出した。本来なら分布を考慮した抽出をするべきなのだろう。でなければ意味のある単語として抽出できないだろう(試行錯誤した結果からするとそうでもない?)。どうしたものか。1割と2割を比較すれば例えば「思い知り」と「辺鄙」を足した場合どうなるか見てゆけば、ツリー構造とでき理解につながるか?。いや類似度0.4程度では表出された単語から意味を読み取ることは難しいか?・・・。意味を読み取るには類似度0.8付近となる単語があるとよいだろう。この単語を得るに語彙が絶対的に不足しているが、語彙を増やすことはそも目的に反する。いや、高次元では0.4でも十分な類似といえばそう。まずどこかで閾値を見極めるか?。ううむ。より類似語が密集しているであろう単語を選び再検討するか?)
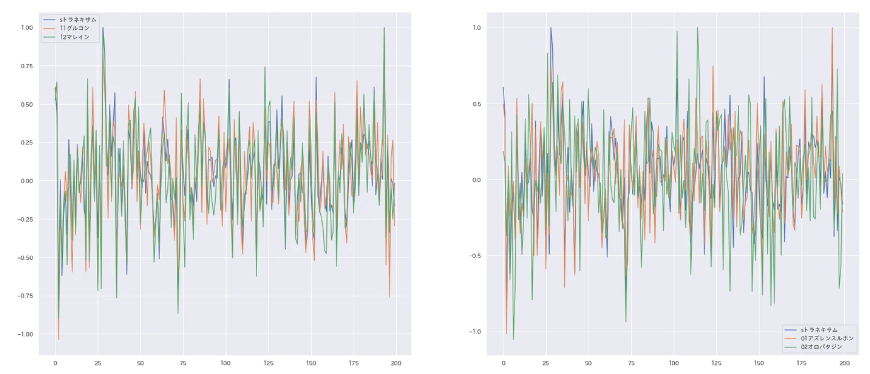
左は,トラネキサム,グルコン,マレインのベクトルを重ねた図.右は,トラネキサム,アズレンスルホン,オロパタジンのベクトルを重ねた図.
右について.1割まで削ってもまだオロパタジンとなった100-120範囲のピークを観察するに,この範囲は確かにオロパタジンらしいのかもしれないな・・・きちんと検証していないが.この部分を変更すると別の主剤に変わるようなスタイル変換ができたなら面白いが・・・よく考えたら歪め統合しているので認識できるかわからないか.
(左について.創造性の項でトラネキサム,グルコン,マレインの置き換えを述べているが,このように類似したベクトルとなっている.maxpoolingにおいてはほぼ同じだろう.)
次元ごとのdisentangleは保留。単語レベルの足し引きでdisentangleが達成できるか見てみよう。オロパタジンベクトルから両目ベクトルを少しずつ引いていったなら、どのように変化するだろうか。*
*Disentanglement Survey:Can You Explain How Much Are Generative models Disentangled?(201910)
https://www.slideshare.net/mobile/HidekiTsunashima/disentanglement-surveycan-you-explain-how-much-are-generative-models-disentangled
*J. Gerard Wolff(2019)
Information Compression as a Unifying Principle in Human Learning, Perception, and Cognition
Complexity Volume 2019, Article ID 1879746, 38 pages
https://doi.org/10.1155/2019/1879746
「人間の学習,知覚,認知における統一原理としての情報圧縮
このホワイトペーパーでは、人間の学習、知覚、認知の多くが情報圧縮、より具体的には「パターンのマッチングと統合による情報圧縮」(ICMUP)として理解されるという考えの証拠を検討します。~」
*クラスタリングはスパースモデリングと同じ方向なのか.構造を意識したクラスタリングはスパースモデリングと異なり性能を向上させることもできるので少々異なるか.
*Juan J.Lastra-DíazaJosuGoikoetxeabMohamed AliHadj TaiebcAnaGarcía-SerranoaMohamedBen AouichacEnekoAgirreb(201910)
A reproducible survey on word embeddings and ontology-based methods for word similarity: Linear combinations outperform the state of the art
Engineering Applications of Artificial Intelligence
Vol.85 Page.645-665
https://www.sciencedirect.com/science/article/pii/S0952197619301745
「オントロジーベースの類似性測定と単語埋め込みの大規模で再現可能な調査.
分布とオントロジーベースの情報を組み合わせたWordEmbeddingモデルが最良の結果」
" Highlights
•A large reproducible survey of ontology-based similarity measures and word embeddings.
•Embeddings using ontologies get the best overall results on word similarity and relatedness.
•Best performing WordNet-based similarity measures use IC models & path-based features.
•Linear combinations of best-performing word embeddings improve the state of the art.
〜we show for the first time that a simple average of two best performing WE models with other ontology-based measures or WE models is able to improve the state of the art by a large margin.〜
"Counter-fitting .
Similar to the Symmetric Pattern technique (Schwartz et al., 2015), this method tries to enforce similarity instead of relatedness (Mrkšić et al., 2016), using both antonymy and synonymy constraints from PPDB database and WordNet. Counter-fitting loss function is defined as the weighted sum of the three following terms: (1) a first term which ‘pushes’ away vectors of antonyms; (2) a second term which ‘pulls’ closer synonyms; and (3) a third term which forces the updated space to preserve the relationships between words in the original vector space (pre-trained embedding)."
"Attract–repel.
Mrkšić et al. (2017) introduce the Attract–repel model which can be viewed as the cross-lingual extension of Counter-fitting. It also injects synonymy and antonymy constraints and updates pre-trained embeddings, but unlike Counter-fitting, semantic relations are drawn from BabelNet and mini-batches include negative samples in the attract and repel terms. In addition, Attract–repel uses a more straightforward L2 regularisation term to preserve word relations in the original pre-trained embeddings."
自分がやっていることに近いかもしれない.読み込むべき.
かなり検討されていると言ってよいのかな.得られるものは多いだろう.
〜おいおい,分散表現モデル(オントロジー含む)の組み合わせで高い結果が得られることを初めて示した,って本気か?.初めて示されたとは信じられないが.多様性評価や個性までは踏み込んでいないようだ.
それは良いとして,この文献は,いま自分がやっていることが方向として正しい,とサーベイで示してくれたとも言えるわけだ.有り難い.
自分の興味の本丸は,分散表現モデルの組み合わせで性能を出すことではなく,どのように多様性を評価すればよいかという方法論と未来予測型AIである.こちらのサーベイがないものか.
*Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
https://arxiv.org/abs/1910.10683
Transformer
*Pandu Nayak(2019)
Understanding searches better than ever before
Google Blog 20191025
https://blog.google/products/search/search-language-understanding-bert/amp/
文脈構造を保った検索.
入力テキストに対し名詞限定処理をおこなうかどうかに関わるかな.名詞限定は基本的に文脈を不明確とする.w2v-mpやkeb-mpでは名詞限定すべきでないとわかっている.検討した他のいくらかのモデルにおいても,名詞限定により精度は上がるがFNが増えるという示唆が得られている.一方,現状の使用方法におけるBERTでは,名詞限定を考えないといけない.入力できる情報量が少ないからだ.入力数制限による性能低下を防ぐための名詞限定と,名詞限定によるFP・FN増加とのトレードオフを考えないといけない.当面名詞限定BERTを採用している.実測としてval40や実データでは明確な差が見られておらず,仮説として名詞など内容語は最重要であり機能語は(特に形容詞が少ない特許文章では)最重要ではないと考えられたからだ.まあ先延ばしにしていたわけだが,val460ならば意味のある差が得られるかもしれない.もう一度検討してみるか.
→val460重要度Aで確認.名詞限定によりFN,FP,ともに減少していた.ああ,名詞限定で性能が出てしまうか.名詞限定不要としたいが,そうするには日本語版PatBERTが必要だろう.仕方ない,作るか…
(しかしなぜBERT名刺限定のほうが性能が出てしまうのだ?。attentionがつかないような品詞は入力においても邪魔なのだろうかpretrainの都合か?。いろいろな報告に合わない気がするがもう少し真面目に見ないとわからんか。)(根本的に,特許文章検索において文脈を考慮する必要があるかどうか,すべきかどうか,という疑問もあるが,まあ1モデルぐらいは文脈考慮できるようになっていてほしい.)(ALBERT実装まで保留.)
書き忘れた.この記事はBERTの検索エンジン組み込みに関する記事.
*BERTにおけるoverlap-addのような最大入力量を増やす手法がある?
*文章ベースの検索では文脈を読むがゆえの認知上の間違いが問題となりそうか.
単語ベースの検索では文脈を読まないがゆえにその問題が検索結果確認時の問題として変換吸収されており顕在化していないが,文章ベースの文脈を読んだ検索では顕在化してくるだろう.
自分はAIによる文章検索と単語検索(オントロジー含む)のハイブリッドシステムを採用しているが,認知まで考慮すると,これでべストではないか,と,今のところ,考えている.
*これまで,言語学の知識を使った自然言語AIの研究がなされてきたが,今後は,自然言語AIを使った言語学の研究が進められてゆきそうな印象がある.重要な部分のみしか認識できてこなかった言語学は,更に詳細に,たとえば深層構造を確率分布で表すように,なってゆくのではないだろうか.個人的には,機能語と内容語の分布が重なっているであろう点について研究が進んでほしいと思うところ.個人的には,文法概念を壊しうるほどクリティカルに重要な点だと思う.
(私は,文法構造も,ただ一つの真値があるとすべきものではないと考えている.特許分野では特許分野の文法構造があり,口語には口語の文法構造があるように,分野で文法構造分布が異なる,とすべきではないだろうか.分散表現から構造を逆抽出することは文法構造を予測し得る(品詞解析など?構文解析?)ための手段であると捉えある手法から得られた結果が文法構造のルールとどれほど異なるだろうか,という視点で考えるのではなく,そも,「与えられたテキスト群においては,分散表現から逆抽出された構造こそが正しい文法構造である」,という視点で文法構造を捉えるべきではないのかと思う.なおもう少し進めて,「形態素の区切りも,ただ一つの真値があるとしてよいのか」とも思っている.粒度と解像度の可変性には大きな興味を持っている.真値にみえる文法構造や形態素の区切りは,平均的な認知を前提とした主因子であり,それを求める過程で特異な認知は捨てられてきた.だが実務ではその特異な認知こそ拾い上げるべきものであり,特異な認知を拾い上げるためには真値を1つに仮定する手法はそぐわない,という考え方といっても良い.まあこの考え方を取ると,正解ラベルも可変となるのでえらく苦労することに.ヒトは認知を怱々固定などできないのよ…)(w2v-mpとtfidf embeddings/clustering visはその考え方をもとに作られている. https://qiita.com/kzuzuo/items/dcdf5550bcb024897de0 )(句構造文法などいろいろな考え方があるらしい.)(不自然言語処理?)
*植田一博(2019)
認知科学研究の質を高めることに向けて
cognitive studies 26(1) 3-5
https://www.jstage.jst.go.jp/article/jcss/26/1/26_3/_pdf/-char/ja
「認知科学が対象とするデータは個人差などの変量効果(random, effect)を含むものとならざるを得ません~N数が稼げない生物種を研究対象とする場合がある生態学などにおいて,このような方法論が発展してきました.それを認知科学に取り入れない手は~」
*Peter Norvig(2017,Google)
「人間に尋ねることもできる。だが、認知心理学者が見いだしたのは、人間に尋ねても、実は意思決定のプロセスにはたどり着けないということだ。人はまず意思決定を行い、その後で尋ねられたら、その時に説明を編み出す。その説明は、本当の説明ではないかもしれない」
自分に尋ねてもバイアスは同じだろうな.
*海野裕也(2017)
人と機械の言語獲得
cognitive studies 24(1) 16-22
https://www.jstage.jst.go.jp/article/jcss/24/1/24_16/_pdf/-char/ja
知りたい情報が多く含まれていた.Preferred Networkの方の論文は,先の高次元科学もそうだが,とても面白くまた参考となる.
記憶ネットワーク.
end-to end化.「十分に記憶や,それに基づく思考がモデル化されているとは言い難い」
単語ベクトルの単純な和から文章ベクトルを作りそれから比較する部分に問題があるように思える.単語の分散表現を適用した上で,単語群と分布で文章ベクトルを表現できれば・・・?.
というかこの記憶ネットワークの基本構造はTransfomerとおなじか?.Transformerでは文章ベクトルを作るにあたりどの単語が重要か選出するシステムが足されていると言えるか.BERT系は思考がモデル化されているとまでたどり着いたのであろうか.
自分の歪め統合と比較すると,記憶ネットワークでは文章全体の記憶と入力を比較しており,Transformerでは文章全体の記憶と入力から特徴単語を強調した上で比較しているところ,歪め統合では短いセンテンスの記憶と短いセンテンスの入力を比較している点で異なるか(w2v-mpとkeb-mpの関係をself attentionと同じとみなし加えた場合)
(ああ,最後のあれはスパースに正則化させているのか.となると,自作AIと記憶ネットワーク・transformerとは,やっていることは方向として本当に同じなのか.自分がやってきたことは,記憶ネットワークと従来のAIの統合と表現できるのか?。外部脳や概念を仮定するなら似たところに行き着くのは当然か.自作AIの利点としては,多様な方法で文章ベクトルを作ることができること,個性の入れ替えと理解?が比較的容易なこと,ということになるかな.).歪め統合では文脈を大きく無視できることから組み合わせのみに着目した創造性を発揮しやすくできていると考えているがどうであろうか.(経験上は,BERTには創造性が全く見られないように見え,歪め統合はBERTより創造的に見える.指標が無いので見えaるとしか言えないが….)(創造性を考慮したときの現状の弱点として,機能語を内容語を拘束するように食っていることが挙げられる.しかし現在の構造では機能語は区切りとして必要である.何というか,現在の保ち創造性を発揮させる場合,pre-domainを得るに機能語を正しく食わないことが重要である気がする.SNSを食わせたことはその意味でも正解だったかもしれない.ただこれは理解していないことから生まれる創造性となろうが,それでよいのかどうか.文脈を間違えニーズを考慮することにより生まれる創造性,悪くはないのであろうが.)
Transformerのみを用いた認知の可能性について.上記入力文章を認知文章に変えれば,記憶ネットワークは認知ネットワークにもなるが…認知情報は大概少量しかないので,このままでは上手くゆかないだろうな…
*趙・酒井(2017)
日本語を母語とする幼児及び年少児童の格助詞学習における項省略の影響
cognitive studies 24(3) 344-359
https://www.jstage.jst.go.jp/article/jcss/24/3/24_344/_pdf/-char/ja
「元来は内容語の学習を助けると考えられてきた機能語(~英語の前置詞)についても言語情報の有効性が認められるようになってきている」
名詞限定でFN(やFP)が増える所以の一つか?.
*150 successful machine learning models: 6 lessons learned at Booking.com
https://blog.acolyer.org/2019/10/07/150-successful-machine-learning-models/
*西田京介(201911)
事前学習モデルの最近の動向
https://speakerdeck.com/kyoun/survey-of-pretrained-language-models?slide=6
Structure BERT(ALICE)(目的関数の工夫),
Span BERT(範囲マスク),
ERNIE(+知識グラフ)
が興味深い.
*岡野原大輔(201711)
ニューラルネットの逆襲から5年後 https://research.preferred.jp/2017/11/deeplearning-5years-later/
「(AIには)解けている問題だけを担当させ、残りを人や既存システムが担当することが多くなるでしょう。その場合、認識結果や理由をわかりやすくするだけでなく、制御できるようにチューナーのようなツマミが必要になるかもしれません。また、人が自分の感覚を拡張したと感じられるように、操作可能性や応答性が重要になります。人馬一体という言葉がありますが、そのように人がAIシステムを自由自在に扱うことができるようになることが必要となるでしょう。」
非常に同感.
自作AIでは,wsw,eswがチューナーに該当するか.
Preferrd networkの方の記事には毎度とても共感する.
Preferrd network research
https://research.preferred.jp/
*Kaleidoscope: An Efficient, Learnable Representation For All Structured Linear Maps
Anonymous
26 Sep 2019 (modified: 26 Sep 2019)ICLR 2020 Conference
https://openreview.net/forum?id=BkgrBgSYDS
*François Chollet(201911)
The Measure of Intelligence
https://arxiv.org/abs/1911.01547
知性の尺度.
「過去100年にわたり、心理学とAIの両方の分野で、知能を定義および測定する試みが豊富にありました。これらの定義と評価アプローチを要約し、批判的に評価すると同時に、暗黙のうちにそれらを導いた知性の2つの歴史的概念を明らかにします。
現在のAIコミュニティは、ボードゲームやビデオゲームなどの特定のタスクでAIと人間が示すスキルを比較することで、依然としてベンチマークインテリジェンスに引き寄せられています。スキルは事前の知識と経験によって大きく調整されているため、特定のタスクでスキルを測定するだけでは、インテリジェンスを測定できないと主張します。それはシステム自身の一般化力を隠します」
新しいAI評価データセット「Abstraction and Reasoning Corpus」をリリース
"We then articulate a new formal definition of intelligence based on Algorithmic Information Theory, describing intelligence as skill-acquisition efficiency and highlighting the concepts of scope, generalization difficulty, priors, and experience. "
共感するところ.
スキル獲得効率.概念,一般化の難しさ等に注視.
少数教師可能とできており?価値観という概念を持つ今のモデルは,この知性の尺度からみるとどのように見えるのだろうか.一般化が難しいかと言われるとかなり大きな?がつきそうではある.
*Semantic Specialization of Distributional Representations Models
EMNLP2019-Spec-Tutorial
docs.google.com
https://docs.google.com/presentation/d/1QwD6Vd-SWJJWdR-QmAHWYDlxfHHeKTmEznDdIZg5aag/edit
目的特化分散表現チューニング手法網羅.
synonym同義 in binary.・・・連続値であると思うのだが,知識グラフの文脈ではそうか. hypernym上位語. Different Specialization means Different Representation.もちろんそうだ.類似性そのものは自動的には関連性と相関しない.Lexical text simplification: aims to replace complex words with their simpler synonyms.「歪め統合」と同じかな.歪め統合はpost-processing aproatchで良いのか.
post-processing models
(-)specialize only the vectors of wordc found/seen in external constraints. 未知語OOV対策が重要と理解している.
(+)applicable to any pre-trained embedding space.?どのような意味で?.上位語への統合という意味か?であれば歪め統合とはアプローチが違うか.
(+)much better performance than joint models.
true similarity versus relatedness.その通りだろう.J=distributional+knouwledge resource.そうしている.そうであるべきだろう.Not distinguishing between similarity and relatedness may be beneficial for certain applications such as text classification, ad-hoc retrieval, or topic modeling.ううむ?.tfidf embeddings/cluster visではその通りだろう.区別させていない.text classificationでは必ずしもそうではないと思うが.
Retrofitting [Faruqui et al., NAACL-15].ここでレトロフィッティングがでてくるのか.
Attract-Repel in a Nutshell.これは・・・特許文章と相性が良いか?.Atrract-Repel is the best performing specialization model according to a recent large empirical study[Lastra-Diaz et al., 2019].
Functional Retrofitting Similar behavior achieved by multiple function-specific Attract-Repel models [Lengerich et al., COLING-18]
https://github.com/roaminsight/roamresearch
Explicit Retrofitting [Glavaš and Vulić, ACL-18]
goal: full vocabulary specialization
個性を作り出す「歪め統合」の方向には向かっていないのかな?.どちらかといえば自分のOOV対応部分のほうがこれに類似している気が.
Direct / Explicit Retrofitting for LE [Glavaš & Vulić, ACL-19]
Specialization for Arbitrary Relations
So far, we focused on standard lexico-semantic relations
Fine-tuning word vectors for these relations expected to be beneficial for a wide(r) range of downstream tasks
But the presented frameworks are general and can be applied for any relation
Need: relation-specific constraints
Specific relations useful for a narrower set of downstream tasks
Some examples:
Specialization for morphological relatedness [Vulić et al., ACL-17]
Specialization for sentiment [Yu et al., EMNLP-17]
Specialization for affect [Khosla et al. COLING-18]
Debiasing word vectors via direct specialization [Lauscher et al., 19]
バイアスを作り上げる歪め統合の方向には行っていないか?.技術的には近いが.
Specialization of Contextualized Embeddings
歪め統合は転移学習の一種か.
The goal of integrating a) distributed representations with b) structured knowledge is mitigating their respective limitations: a) conflates different relations, while b) has low coverage (of words and languages).
ふむ.
Relations have different natures: e.g. symmetric vs directional, graded or not. Their specialization demands different methods.
Pros and cons of methods: joint learning affects all the words in the vocabulary. Post-processing shows better performances, is not tied to specific embedding models, and needs no retraining.
Limited vocabulary coverage calls for post-specialization or explicit specialization.
Linguistic specialization has been repeatedly proven to boost performances in Dialog State Tracking, Lexical Simplification, and Text Similarity.
Specialization can be transferred across languages via multilingually aligned semantic spaces, or by inducing target constraints.
The specialization framework has broad applicability: bio-NLP, debiasing, abusive language detection, fact checking, cognitive studies….
「認知」が出てきたぞ.
Not all methods model full triples (word-relation-word). Some focus on single-relation constraints, attract and repel relations, or unbounded relations (functional extensions).
Specialization is beneficial to both static and contextualized WEs. But there is still a lot to be explored, especially about the latter.
(読込中191...濃いな・・・よくもまあこれだけの資料を作ったものだ・・・)
自分がやってきたことは,レトロフィッティングの文脈で語るべきらしい.
*Motoki Sato(201908)
ACL 2019 参加レポート
セグメンテーションとの同時学習
https://research.preferred.jp/2019/08/acl2019-report/
BERT名詞限定,w2v-mp未知語処理,解像度変更による文の同質化,文法構造の捉え方,に関わる.
なるほど,文法構造構造に真があるとするなら,分かち書きはセグメンテーションという表現となるか.自分は文法構造は母集団の分野に対し可変と考えたため,クラスタリングとしている.
様々な分かち書き・形態素分析について.これらは答えが収束するものではなく,目的に対し最適な選択があるものと考えている.フレームで類型化できるだろうか.自分は,基本的には,恣意的なものを嫌うためセグメンテーションよりクラスタリングを選択しやすいのだが,ある程度の指標は,独り歩きしない程度に,あったほうが良いだろう.
解像度変換について.自分の目的においては解像度変換が肝となる.ヒントはないか.様々な分かち書きによる汎化はちと違う.これを分布で扱い,センテンスごとに分かち書きを変化させてもよいが,文字単位まで一般化しても上位概念にはたどり着かない.
教師なし事前学習transformer,半教師ありのautoencoder,ルールのオントロジー,以外の答えがないものか.Span BERT(範囲マスク)が興味深い.
*Markov LogicのOSS実装であるAlchemy
http://alchemy.cs.washington.edu/
*コンセプトドリフト.個性多様性評価には関係がないな.
*Large-Scale Few-Shot Learning: Knowledge Transfer With Class Hierarchy
https://www.slideshare.net/mobile/DeepLearningJP2016/dllargescale-fewshot-learning-knowledge-transfer-with-class-hierarchy
転移,少数教師.クラスタリングで階層構造を作っておく.転移元と少数教師で共通するスーパークラスタを抽出する.階層数が重要.
考え方は近いか.転移・少数教師学習はもう「創造とは何か」に踏み込んでいるようなものなので手段も似てくるか.
「適切なソースクラスを選ぶ」ことが研究テーマとのこと.大変興味がある.注目しておこう.
大熊拓海 東京大学 情報理工学系研究科 創造情報学専攻 中山研究室 M1 専門はfew-shot learning関連 現在の研究テーマはfew-shot learningにおける適切なトレーニングデータ選択 について
*2019年大学入試センター試験英語筆記科目においてAIが185点を獲得!
https://www.ntt.co.jp/news2019/1911/191118a.html#a1
実装と性能の現状を把握するに良い記事か.
XLnetと転移学習、少数教師への対応手法.
不要文を含まない通常の文章から文の順序を組み換えて擬似的に不自然な流れの文章を作成する手法.
各段落と選択肢の類似度を計算し最適な段落・選択肢の組み合わせを導く手法.
深層学習ではなくあえて発音辞書を地道に調べる方法を適用し表記ゆれを抑える工夫や問題解析器の精度を高めた.
王道を誠実に実施,といった印象.王道で性能が出るというのはそれが実用に使いやすいということ.すごいことだ.
*「「初等的」ということはそれを理解するために要求される予備知識が非常に少ないことを意味している。ただし限りない知性が要求される」
*特集タイトル:圏論は認知科学に貢献できるか
掲載予定巻号:第28巻1号(2021年3月発行)
上記クラスタリングや「与えられたテキスト群においては,分散表現から逆抽出された構造こそが正しい文法構造である」の考え方は,圏論に通じるのであろうか.逆のようなそうでもないような.
*Neural Magic Neural Magic Inference Engine
https://neuralmagic.com/
CNNをGPU無しでも.このような技術なら購入してでも採用したい.
*IBIS2019
カプセルネットワークについて最新。
クラスタの特徴をカプセルに押し込める、位置普遍性を弱め相対位置を保持するCNN改良。
この説明の限りでは不要な相対位置保持があるのでそのままでは使えないか。
2017頃話題に?。最近内部クラスタリングが目立つのはこれの影響なのだろうか。
(2018年に画像分野でDeepClusterという手法の提示があったらしい。CNN畳み込み後隠れ層でクラスタリングを行い疑似ラベルをつける手法?。これは教師なしにおいて、クラスタリングにより性能が上がった例。)
*IBIS2019 RL
フィードバック設計時参照
Data-Efficient Reinforcement Learning of Mechanical Control Systems
Marc Deisenroth(Imperial College London)
最初に?受けた英語の講義はロンドン大学のコモンローの講義だったな懐かしい。アメリカ英語に対するイギリス英語の聞きやすさに衝撃を受けたことを思い出しつつ聴講した。
*シミュレーションでX,Yを求めておいて、統計やルールべースにおいてxとしたときのyとYとの適合を調べ、統計やパラメータの最適値を予測し,シミュレーションの代わりにそれらを用いることで学習時間や根拠推定をする手法?
これは統計やルールベースの連続的な適用範囲を不連続にぶった切っていると考えてよいのかな?.新たに必要となった適用範囲にはどう対応するのだろうその場合は信用するのかするとその範囲は補正されているかどうか見えるようにしておくことが必要かな。
*エキスパートシステムにつき、データ構成を再検討すること。
*IBIS2019 2日目企画講演
原子一つ一つとそのその周辺情報をそれぞれ入力とし,それぞれ独立のNN(一部共有)で処理し,最後にGCNでまとめると.自分も適切と思った構造。概念形成の方向性は正しいようだ。
*モデルの個性とは,複雑性誤差上のモデル部分集合のと表現できる?
*多量の教師データ→不連続含む範囲→不連続面などで切られるようなドメイン群と、それぞれのドメインに対応した関数群。
ドメインの区切りが適切に学習できているのか?→少なくとも、あるヒトの認知に適合した最適なドメインとなるような都合の良さはない。
あるヒトの認知に適合したドメインとなって欲しい場合であり、必要十分な多量のデータがない場合には、ドメインは学習データ以外から求めるべき? →ドメイン群から、あるヒトの認知に適合した特定のドメインを抽出、またはドメインの区切りを変更(教師なしクラスタリング、オントロジーなど)→そのドメインに特化教師データを用いそのドメインに特化した関数を学習=適切な学習結果となりやすい
=タスクが簡単に
あるヒトの認知をもとにしたドメイン限定における、ドメイン抽出・作成、ドメイン特化した教師データの必要性
=ヒトによる教師が重要。ヒトの質が重要。
*ヒトの質を不要とできるのか? →一度形成でき、適切なフィードバック系があり、それにより仮説から演繹をつくりあげられる構造を作り上げているのであれば、簡単としたタスクの範囲内であれば可能。と今のところ考えている。
*このあたりの考え方はニッチにも通じる.マーケティングにも使えるのではないかな.
*汎化レベル
1 教師データと同じ
2 教師データ語彙と同じ(最大適用範囲枠内)
3 教師データ語彙から外れる(最大適用範囲枠外)
1,2は学習により得られる帰納的バイアスの範囲内。3は学習からは得られないメタバイアス.
*研究組織における多様性を考える
https://www.jstage.jst.go.jp/article/molsci/2/1/2_1_A0017/_pdf/-char/ja
「James Surowiecki「The wisdom of crowds(群集の知恵)」
この集団知性を 成功に導くためにはどうすればいいのだろうか。
・人的構成や思考の「多様性(diversity)」,
・意見導出の「独立性(independence)」,
・個別能力や情報の「分散化(decentralization)と統合(aggregation)」
私は,研究組織においても同様の 観点から成功条件を取り扱うことができると思っており,
さらに,これらの三つの条件に,
「正当な評価(evaluation) と報奨(reward)」を,
研究者組織を成功裏に運営するため の四つ目の条件として加えたい」
「「多様性の画一化」を警戒しなければいけない」
安易なConcatは,これを導いている気がするよ.
*単語の挿入と削除を用いた新時代の文生成手法が登場
https://ai-scholar.tech/others/levenshtein-transformer-ai-348/
空白に足してゆく。
これはもしや前述の「上位概念下位概念の教師なし解像度変換」に通じるのでは。
下位概念を上位概念化させる場合、下位概念の密度に応じた個数の空白を少なめに準備しておき、tfidf embeddings/ cluster vis・前後の類似性・ソフトクラスタリングなどを用い空白に埋める単語を作成し、出来上がった単語群ベクトルと下位概念ベクトルとの差から上位概念と下位概念の差をチェックし(最小化でも良いけれど重すぎるか)、要事いくらか繰り返し確定させる。順に空白を足してゆく。開きたい下位概念の設定さえすれば、理屈上は、課題はあるが、可能だな。
特許なら下位概念を請求項の固有名詞から、上位概念元となる単語を明細から、とすればよいか。いや特許ならまるごと持ってくたほうが早いか。
文章にレーベンシュタイン距離の概念を適用?。なるほどなぁ。
Jiatao Gu , Changhan Wang , and Jake Zhao (Junbo)(201905)
Levenshtein Transformer
NeurIPS 2019
https://arxiv.org/abs/1905.11006
*自然言語処理のData Augmentation手法 (Easy Data Augmentation)
https://tksmml.hatenablog.com/entry/2019/12/10/002009
考えたことはあったが一般汎化は不要と考えておりやったことはなかったな。創造性の足しになるだろうか。
NICT日本語 WordNet,そろそろ試してみるか.
http://compling.hss.ntu.edu.sg/wnja/
https://qiita.com/pocket_kyoto/items/1e5d464b693a8b44eda5
うーん
*産総研 AIの動画認識やテキスト理解の基盤となる事前学習済みモデルの構築と公開
https://www.airc.aist.go.jp/achievements/ja/
「バイオ分野に特化したBERTをバイオ分野の大規模テキストデータを使って最初から構築して公開しました」
おお!て英語か?
SciBERT,BioBERTとの違いは?
*ワードエンベディングモデルしか触らないNLPエンジニアとしての仕事の紹介
https://shiumachi.hatenablog.com/entry/2019/12/16/000000
おっと常識考慮とドメイン限定は事業としてやられているのね。
Luminosoは自然言語理解ソフトウェアを利用し、デンソーとグローバルでのナレッジ活用による業務生産性向上施策を始動
https://www.google.com/amp/s/prtimes.jp/main/html/rd/amp/p/000000004.000040050.html
*Manaal Faruqui Jesse Dodge Sujay K. Jauhar Chris Dyer Eduard Hovy Noah A. Smith(2015)
Retrofitting Word Vectors to Semantic Lexicons
https://www.aclweb.org/anthology/N15-1184.pdf
レトロフィット
オントロジーベースの分散表現.
w2v-mpのpre-domain部分,多分w2v-mpの個性部分になる,を任意にコントロールするならば,この手法を取るとよいか.
インサイトには事前のベース知識が必要と実感するところ.創造性の参考となるかな・・・
*松井幸太(201912)
転移学習の最近の進歩と関連トピックVer.2
https://www.slideshare.net/mobile/KotaMatsui/recent-advances-on-transfer-learning-and-related-topics-ver2
・各モデルの特性確認手法案。
1 モデルごとにval460評価結果ベクトル作成。
2 複数のヒトにおいてval460それぞれの特許について評価値を恣意的に入力しベクトルとする。
3 1,2をPCAを用い2次元に図示し、主要素A軸、主要素B軸を作る。
4 軸ごとに要素を予測し、個性の主要素とする。
*disentanglementができていれば、クラスタリングによる文章ベクトル作成がを適切にできていれば、主要素がある程度明確になるのではないか?
計算後図挿入予定(とりあえず概念図)
(省略)
まず,単語因子を調べ,理解不可能であれば,個性ベクトルのdisentangleができていると仮定しベクトルの特定次元を任意に操作し,全体としての特性を探ることとする.(殆どが意味としてスパースと確認できればよいがどうかな・・・経験則としてはそうなっていてしかるべきだが.)
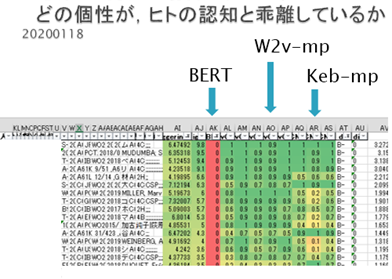
モデル個性差が見られた範囲に限定した個性ベクトルをヒートマップで表現した図(の一部)
・モデル個性差が見られた場合における,モデル個性と(設定した)ヒト認知との一致件数(*件中)
| モデル | ヒト認知との一致件数(閾値>4,>4.5) |
|---|---|
| BERT | 19, 15 |
| w2v-mp | 28, 21 |
| keb-mp | 19, 12 |
・BERTは,ヒト認知との不一致が多い.
(多分,ベースモデルの訓練量が足りておらず,そも本来の性能を発揮していないのだろう・・・PatBERTが欲しい・・・いや気合と多少・・・の予算があればできる...かもしれない・・・)
・keb-mpは,ヒト認知との不一致が多い.
(歪め統合も創造性付与もないAIを普通に使えば,この程度となるのだろう.)
・BERTのヒト認知不一致箇所とkeb-mpのヒト認知不一致箇所は,ほぼ重なっていない.
個性が異なるといえる.多様性評価的によきかな.

ただ,なぜだ??.
これほどはっきりと分かれるとは思わなかった.
なにか「特定の構造を作り上げ抽出している」,明確な個性が本当にある,モデル間で意味のある補完(いわゆるvalianceによるゆらぎでない補完,なにか明確なbiasによる補完)ができる(というのは最初から示唆されていたところだが),と考えてもよいのだろうか・・・.
(名詞限定に起因するbiasかとも思えるが,名詞限定と名詞非限定で比較しても波形は・・・.ハイライトもこれほどの断絶を予想させる結果ではないようにみえる・・・入力時の分布の違いに由来するものでは無いように思える・・・)
・今回の結果を眺める限りは,「モデル間に有意な個性がある」「W2v-mpが最もヒトの認知に適合した結果を返している」ように見える.
(正解率からみると,BERT >= keb-mp >= w2v-mpなのだが(201912頃,物質記載特許重視に変更したので少々変化している),認知適合性からみると,w2v-mp > BERT >= keb-mp.個性と多様性評価という視点で考えると,なかなか示唆的に思うところ.真面目で文脈を見分ける読解力が高く一般的な成績が高いことと,実務上の価値を生み出すこととは異なるものだ,と示しているかのようだ。そう示している,と言い切るには検証が足りないが。)(「W2v-mpが最もヒトの認知に適合した結果を返している」について.全体集合と認知適合集合とで高スコア比率を比較した場合,認知適合集合のほうが2割ほど高スコアの割合が高くなるが,それほどの差はない.ということは,認知に適合して見えるだけかもしれない.見方によってはBERTのほうがヒト認知により適合している.評価結果ベクトルに直して比較してみたほうが良さそうか.)(W2v-mpに関しては,認知と適合しているわけではなく,正解候補と不正解候補の「中間域の扱い」が異なるため,このように見えているだけかもしれない.不正解だけれど認知的には近いものをどう扱えばよいのか.良い表現をすれば汎化性能が高いと言える,悪い言い方をすれば汎化のし過ぎによりFPの可能性が高いと言える.本目的のいては並び替えができれば良いのでスコア自体には本質的な意味はない.スコアが重要となってしまうのは多様性評価をどう行うかという視点があるから.・・・つまり上のような図から認知に適合したかどうかを判断しようとしてしまった事自体が間違いだ.)(モデルの個性差ならともかく,認知との適合については,早々期待通りにはゆかないな・・・)
*B案件でも同じ傾向あり(重すぎるので画像消去)
・別の教師を用いた結果.同じ傾向あり.BERTのヒト認知不一致箇所とkeb-mpのヒト認知不一致箇所はほぼ重なっていない.ヒト認知との適合率という観点においてw2v-mpが優秀であるように見える(ヒト認知との適合率については,前述の通り,疑問が発生したので保留).
*正確に認知とスコアと照らし合わせ,単語や構造の違いを明確にしつつ,分析する必要があるだろう.
(w2v-mpのwswがヒト認知と一部重複している.外して確認する必要もあるだろう.ヒト認知に適合させるためにwswを加えたのであるからwswによりヒト認知と適合する結果が得られたことに対し実務上問題はないのであるが気持ち的にはカンニング臭い.).歪め統合による効果とwswによる効果を切り分けて観察するという気持ちで確認してみるか.
→wswを抜いても傾向は変わらなかった.「歪め統合が,w2w-mpのヒト認知との適合に寄与している」のだろうかな・・・)(それぞれの認知適合個性から単語頻度を求めif仮説設定し、wswによりその仮説が成り立つか検証すれば、単語レベルでの個性であれば理解できるかな・・・)(ヒト認知との適合率については,前述の通り,疑問が発生したので保留)
ヒト認知に関わるポジティブ単語とネガティブ単語を並べてみた.
パターンが存在しているようにみえる.
パターンが存在しているのであるなら学習可能だが…このパターンを使うには、目的関数にヒト認知の項を加える必要がある。グラフで加える手法があったはず。設計できるかな…何でも学習で済まそうと言う考えもあかんが。
パターンを認識できているということは,ルールベースで抽出することも可能だということだ.うーむ。このパターンなら、モデルごとに重要視した単語の共起性を確かめれば,ヒト認知適合におけるモデルの個性を示すに十分となりそうでもある。
(BERTを理解するにあたってはナイーブベイズを用いると良さそうだ・・・いやまあ当然かも知れないが.)(「分散分布モデル?」と「知識ベースの確率モデル?記憶モデル?」の違いであれば,このようになることに矛盾はないだろう.(適切に表現できていない.固有名詞または数式で表現すべきだろう.))(短距離作用か長距離作用かの違いとも思えてきた.いや多分そうだろう.・・・ではw2v-mpはなんだ?.歪め統合はattentionのような働きをするのか?.いや,教師なしattentionみたいなものか.そもw2v-mpはいわば超長距離作用を付加した短距離作用モデルといえるか.)(意味ブロックを拡大させたときの係り受け可能性の変化として考えれば、BERTとkeb-mpの個性差は理解しやすいか。)(end-to-endで正解と認知のマルチタスク学習でもすりゃええのだろうか.)
BERTとkeb-mpにおいて個性差が現れる原因は,概念的には上図のようではないだろうか.
単語自体に重要性があり意味ブロックに長距離性があるならBERTが有利であろうし,単語のみでなく周辺語を巻き込んだ意味ブロックに重要性があるならまた学習で意味ブロックを作るのではなく強制的に構造として意味ブロックを作ることが優位ならkeb-mpが有利であろう.
(もしそうならば,形態素の区切り方で結果が変わりそうでもある.時間がかかるが,sudachiでSplitModeを切り替えて比較してみるか・・・.いや,ウインドウサイズを変えても個性に変化はなかったのだったよな...いや打ち消しがあるから一概には言えないか.)(ウインドウをサイズ可変としウインドウ内のノイズを除去すれば,任意の個性を作れるかもしれない.まず、attentionの作用距離分布を確認し距離比較をしてみるか.)(attentionで十分とも考えていたのだが、attentionは結果を見る限り足りず、多分,不十分⇔学習量のイタチごっことなり、どうにしても創造性のない硬い結果にしかならないだろうと感じる。別の手段を考えることに十分意味があるだろう。)(全て学習に任せるのではなく「構造」も作る、という方針は間違っていないのだろう多分。分散表現とオントロジーの組み合わせが最高評価だそうなので、多分、思う、はそろそろ除いてもよいか。)
*いやこれは説明として迂遠にすぎる。もっとシンプルかな。
上記パターンからすると、BERTは「重要視する単語をより強く評価」または「共起が無視されたと言えるほど特定の単語のみを重視」し、keb-mpは「重要視しない単語をより強く評価しない」、という働きをしている、のかもしれない。
これならBERTにおいてFPが多くなる説明にもなりアルゴリズムにも適合するはず。w2v-mpにおいて不正解教師が重要であった理由にもなりえる(個性差は見ていないが)。
BERTは多分、attentionの不正確さにより単語出現現頻度に引っ張られているのだろうな。
*BERTに弱点があることが原因と仮定できるならば,その弱点は,先に見られているあるアルファベット文字列,多分サブワード区切りにより生じる,となるのだろう.もしそうであるならば,個性別に出現単語を比較してゆきナイーブベイズで順位づけしてゆけば,傾向が見られるだろう.(そしてその傾向があると信じるような認知バイアスを得てしまうだろう・・・)
*分散表現でなくウインドウが原因と仮定できるならば,BERT-CNNを組み,ウインドウごとにどのように個性が変化するか確認するとよいのだろう.
***BERTはどこまでいっても単語単位を扱っており句を完全には構成できない.CNNは強制的に句を構成できるが長距離の引用は不可能.この2つの個性が補いえるのは当然か.**個性はあるとして,そこから価値を生み出すための評価が難しいのだが・・・.
句が重要な文章であるか,長距離引用が重要な文章であるか,見極めることができればよいのか・・・.可変ウインドウサイズに立ち返り,句と代表単語の類似性からより良いウインドウサイズを予測し,予測されたウインドウサイズが十分大きく長距離作用性が必要と判断された場合にはBERTの重みを強くする,などかな・・・
・特定の1モデルのみが高スコアとした範囲が,ヒト認知と一致することもある.
このことは,本手法においては,「単なる平均評価」よりも「多様性評価」のほうが「ヒト認知と近い結果を生む」場合があることを示している.
(平均評価と多様性評価の10%相当率を数回比較しているが,つねに多様性評価は平均評価を上回っている.「個性があり,個性を評価する多様性評価が有効になっている」と,ある程度確信してもよいのではないか.適切に個性評価できているかはおいておいて.)
・今回の結果は,「多様性評価により、適切に解像度変換ができている」、とみなしてもよいのか。
(いやだめだな。単語の軛から逃れられていない。文脈上の単語の意味を捉えられてはいるかもしれないが
、)
・詳細は述べないが、BERTが独立した単語「眼」を「重視することで」ある程度ヒト認知に適合していることに対し、w2v-mpが独立した単語「眼」を「あまり重視しないでも」最もヒト認知に適合していることは、非常に興味深い。
*BERTはやはり「辞書」と例えるにふさわしいか.専門家AIとしてはふさわしくないだろうし,創造性をもたせることは難しそうだ.契約文章用AIとしてはかなり優秀となりそう.
まだまだ,良いモデルが必要となりそうやな.Transformerはゴールではないだろう.(豊富すぎるデータが用意できるならゴールと言ってもよい.しかし、意味的なゴールにはなりえるが、認知的なゴールにはなりえないだろう.).
SpanBERTを試してみたい.

・ううむ?
tfidf embeddings/cluster visを利用すると,ざっと,ヒトが認識できやすいクラスタができあがる.
個性差が見られた特許群に個性ラベルを貼り,tfidf embeddings/cluster visを用い図示したところ・・・
BERT(赤)において,他モデルと異なる傾向がみられた.BERTは眼内レンズと眼科手術クラスタに集中して個性を発揮しているようだ.しかし・・・どのような再現因子があるのだろうか.正答傾向というわけではなし・・・
w2v-mpとkeb-mpとの比較においては,傾向に差が見られなかった.どう理解すればよいのか.
頻出語からは・・・気づきが得られない.
→より多くの単語を表示し確認したところ,あえていえば,**「keb-mpと比較し,w2v-mpのほうが,より「上位概念」で認識している」**ように見える.これはSHAP highlightを用い特定特許に対しモデル間比較し場合に見られていた傾向と一致するが・・・.全体としてもその傾向があると言い切るには早いだろう.上位概念と下位概念の差であれば,tfidf embeddings/cluster visにおいて傾向の差が見られなくとも妥当ではある(tfidf eembeddings/cluster visは,上位概念と下位概念で同一クラスタを作らせることを目的の1つとしている.)(個別特許を上位概念下位概念の違いで説明できるか観察したところ,たしかにそうであるようにも見える.ただ認知バイアスがあるから何らかの客観的な検証が必要だろうな.)(短文の特許,発明の名称のみからなる特許,は,ほぼ,keb-mpのみが認識しているようだ.これは面白い.)(一応書いておくが,過学習云々ではないだろう.みられているモデルの個性差は学習回数ではほぼ変化しない.・・・とはいえ再確認必要かな.)
もし上位概念下位概念を見分けているのであれば,モデルの個性の組み合わせ方に付き,並列と直列を柔軟に組み合わせることで、デザイン思考や創造性にもつながるはず・・・(事前知識のない人が下位概念の固有名詞のみに引きずられ,事前知識のある人がより適切に一般概念化する様子にも似てなんでもないです.)(事前知識がある場合,上位概念に加え下位概念も適切に認識できているか,がポイントだろうか.上位概念だけでばぼんやりしすぎ絞り込めない何かぐさりとくるな.)
モデルの個性は,ヒトが認識できない個性である,となりそうにみえる.多様性評価は学習で行うしかないのか?・・・つまらないな.
下流は知識グラフであるべきと考えており,理解の過程で多様性評価について理解し学ぶところがあると良いと考えているのだが.もうすこし有望そうな分析方法がないか探ってみよう.予想が正しいならば,単語レベルで理解ができるはずだ・・・.最終的には予想される結果を示すであろう文章を作成し,予想通りの個性を示すか確認することになるか・・・上位概念と下位概念で書き分けられた特許があるとよいのだが・・・「公開公報の請求項と登録広報の請求項で比較」すればよいか.ふむ
*A Primer in BERTology: What we know about how BERT works
Anna Rogers, Olga Kovaleva, Anna Rumshisky
(Submitted on 27 Feb 2020
https://arxiv.org/abs/2002.12327
・ヒト認知における個性が見られた特許をいくらか抽出し,モデルごとにハイライトの違いを観察し,単語を入れ替えてゆけば,単語をどの程度重要視しているか,距離の作用がどれほどか,理解できるだろう.
二値分類でなく多値分類であればより大きな変化が観察されたと思われるが,そも二値分類であるからこそ余分なものが削ぎ落とされてもいるわけで...
*Harry Shum(2020)
AI を説明する (a16z)
https://review.foundx.jp/entry/biases-and-black-boxes-a-call-for-ai-transparency?mkt_tok=eyJpIjoiWlRKbU16aGxNVGxqTkRGaiIsInQiOiJWdzJDa085RUZNZzlsMVwvZEF1U2IxWDFuNElPWmhIQUpGV25pNVhtTFZ4dXhLQ01RUHdyMytpYVpKejkxa05IbFFcL01mR1VqaklwRVRTeDl2ZU1YWmREcGdcL3QwZ0RLaURnZzlqXC91cEt3YUo3K3FGWE5WNU00Ykt4M2RjWXFqMG4ifQ%3D%3D
近接性と並列性.
意図的なバイアス圧縮.自分はバイアス修正を多様性評価後にExpert systemをかませることで実装しているが,分散表現段階で行うべきなのかな.目的によるか.特分散表現段階で行う場合,潰さないといけないバイアスがもぐらたたきになり切りがないのではないか.特許では潰さないといけないバイアスを予め明示的に単語概念レベルで?決められるものだろうか?
SHAP,LIME,・・・
・ヒトの個性ベクトルとモデルの個性ベクトルを近似性だけでなく方向でも分析するとして,特定の方向への寄与を示す単語をどう抽出するか.
文章ベクトルと単語ベクトルは同一平面で表現できるから文章の並列性と単語の並列性はあるていど把握で消えると思うが・・・
まず,ヒト認知における個性が見られた特許の文章ベクトル全てと,ヒト認知を表す単語ベクトル全てを同一平面に図示してみるか.モデル差は文章ベクトルを色分けしておいて,基準としてヒト認知を表す単語ベクトルを合成したベクトルを置いて・・・
多分,単語ベクトル「眼」とBERT色の文章ベクトル群は,近接するだろう.
ヒト認知合成単語ベクトルとw2v-mp色の文章ベクトル群は,近接するだろう.
BERT色の文章ベクトル群と,keb-mp色の文章ベクトル群は,近接しないだろう.
並列性はどうなるだろうか?
*実務上肯定的な結果が出続けている.実務上は問題ない.しかし,実務から離れた検証は進んでいない.1年経過してもこの程度しか進められていないのか・・・
言語処理学会NLP2020で興味がありそうな人を探そうと思っていたのだがコロナで中止(web開催).どうしようかねぇ・・・.
*The Five Cognitive Distortions of People Who Get Stuff Done
http://quarry.stanford.edu/xapm1111126lse/docs/02_LSE_Cognitive.pdf
1:自分を特別だと思い込んでいる
2:二項対立的な思考をする
3:少ないサンプルから一般化する
4:ゼロから始めたがる
5:イノベーションを好む
これは…参考にならないか。
*入山章栄:早稲田大学大学院経営管理研究科教授
『世界標準の経営理論』で学ぶ、「知の探索」を習慣化する方法
https://diamond.jp/articles/-/225007
・日本でイノベーションを促すには「評価制度の見直し」が不可欠
・日本企業は「人材の多様化=ダイバーシティ」の重要性の理解が乏しい
・ダイバーシティは一人でもできる 革新的な人は「イントラパーソナル・ダイバーシティ」が高い
「~「ダイバーシティは一人でもできる」というものだ。
知の探索・深化の理論に基づけば、ダイバーシティの本質は、知の探索を促すためにある。だとすれば、先のように「一つの組織に多様な人がいる」(=組織ダイバーシティ)ことも重要だが、「一人の人間が多様な、幅広い知見や経験を持っている」のなら、その人の中で離れた知と知の組み合わせが進み、新しい知が創造できるのだ。これを、経営学ではイントラパーソナル・ダイバーシティ(intrapersonal diversity)と呼ぶ。「個人内多様性」という意味だ。~」
阿部 慶賀(2019)創造性はどこからくるか: 潜在処理,外的資源,身体性から考える (越境する認知科学)共立出版 https://www.kyoritsu-pub.co.jp/bookdetail/9784320094628 では,「協同する他者は実在しなくてもよいか」と.
*第11回全脳アーキテクチャ勉強会 〜Deep Learning の中身に迫る〜(201509)
http://wba-initiative.org/604/
教師無し学習は、ポテンシャルを引き上げる
教師あり学習は、ポテンシャルへ到達させる
M. Ohzeki:J. Phys. Soc. Jpn., 84, (2015) 034003
*全脳アーキテクチャ勉強会テーマ「推論」(201803)
https://wba-meetup.doorkeeper.jp/events/71522
*創発インタラクションの意義:機能分化に対する変分原理と数理モデル(201806)
https://www.slideshare.net/wba-initiative/ss-103834536
コミュニケーション神経情報学.
ああ,手に負えないなわかっていたけど.
「人の知覚は離散的.予測をするから連続的にみえる」
これはかなり重要に思える.変換可能性において.
複雑系:非分解,初期値や外部でない内部条件によるカオス変換.自己組織化と拘束条件付き自己組織化.
「内部条件」「拘束条件」は上記で述べた「構造」と同等と考えて良いのかな?.ちょっと範囲がズレている気もする.
*電気通信大学情報理工学研究科情報学専攻
坂本真樹研究室
http://www.sakamoto-lab.hc.uec.ac.jp/research/
人間の認知特性の研究。
オノマトペなど。
「頭がずきずき痛い」といった病気の症状を表すオノマトペの情報を多言語尺度で定量化することにより、 国内のみならず、海外での外国人医師との問診支援も行えるシステムとして実装しており、国際会議でBest Application Awardを受賞しています」
ある意味、解像度変換の究極だよなぁオノマトペは。
オノマトペは、多次元単語ベクトルの縮約そのものではないだろうか。あるいくつかの特定の明確な要素では表現しきれないある結果?を表すものが、このようなオノマトペではないだろうか。
歪め統合のゴールはここかもしれないな。
サッカーと雨(雨天のサッカー大好きでした。個人的には、サッカーといえば雨、雨といえばサッカーを認識します)を歪め統合して、「エモい」と表現する、など(ちょっと違う?)。
*A distributional code for value in dopamine-based reinforcement learning | Nature
https://www.nature.com/articles/s41586-019-1924-6
Dopamine and temporal difference learning: A fruitful relationship between neuroscience and AI | DeepMind
https://deepmind.com/blog/article/Dopamine-and-temporal-difference-learning-A-fruitful-relationship-between-neuroscience-and-AI
「ある状態で行動を行ったとき、その行動の価値は、その行動で得られた報酬と次の状態で(方策に従って)行った行動の価値の和の期待値」ということになる。
そこで、ある行動を行って、報酬と次の状態と行動を観測したタイミングで「報酬と次の状態での行動の価値」をサンプリングし、それを何度も繰り返すことで期待値に収束させていくという方法を考えることが出来る。
これがTD学習の考え方となる。
https://yamaimo.hatenablog.jp/entry/2015/10/15/200000
差分のコントロールとモチベーションを関連付けるのも面白いかな。「才能とは、モチベーションを維持する能力のことである」と聞いたことがあるが、もしかしたらコントロール可能なのかも。
能動活性化人材は好奇心で活性化される、のだっけ。
好奇心をこの差分で表現できるかな。
モチベートされる要因は好奇心であったり金銭的報酬であったり環境であったり不満であったりするが、その幹の部分はこの差と仮定するならば…
ヒトでもAIでも、結論が先で説明はあと。その差分を(オントロジーを用い整理しつつ)強化学習の手法を用いフィードバックする経路も作れば、判断の複雑さでの評価もでき得るか…
*岩田健太郎(2012)
主体性は教えられるか
筑摩書房
https://www.amazon.co.jp/%E4%B8%BB%E4%BD%93%E6%80%A7%E3%81%AF%E6%95%99%E3%81%88%E3%82%89%E3%82%8C%E3%82%8B%E3%81%8B-%E7%AD%91%E6%91%A9%E9%81%B8%E6%9B%B8-%E5%B2%A9%E7%94%B0-%E5%81%A5%E5%A4%AA%E9%83%8E/dp/4480015396
昔から好きな医師。同感に過ぎ偏見強化に行き着きそうな気配すらある。
「〜主観は重要。客観性は(手段であって)目的ではない」
そのとおりでしょうね。さん付けやフレームワークの強要なども主体性の阻害要因と記載がある。
「他者の言葉を聞きつつ、その上でオリジナルであることが重要なのである」
そのとおりだが誤解を生みそうにも。
「バイアスを自覚する」
バイアスは無くせばよいというむのではないはず。コントロールできれば、バイアスは素晴らしい効果を生むはず。
「豊富な経験は時に人を成熟させず、むしろ逆のことが起きるのだ」
AI教育においても、現状非常に重要な認識だと思う。
「自己のバイアスに相当自覚的でなければ、理を尽くした論考にはならないのである」
先と同じ。
「価値中立とは孤高に耐えること。〜常に自分の正しさに懐疑的であること」
先と同じ。うちの大叔父は立川談志の略。まあ談志っぽいとおもう。
「関連であり相関でない、そこで話を止めてしまうのは思考停止である。〜可能が高いことそれが重要なのである。役に立てばどれでよいのだ。交絡因子であるかどうかの重要性は、目的に照らし合わせ変動するのである。現実で世界の応用は、学問世界の正しさをときに必要としない。両者は区別して考えることが大事である。数字は客観的と思われがちだが、その評価は常に主観的なものである。主観的な判断として自覚し、他者は異なる認識を持つかもしれない可能性にも配慮する。このような内省的な配慮こそが〜」
AIに対して驚くほど示唆的だと思う。
AI界隈で最もまともなのは医療関係(特にアイリスなど)と思うところだが、医師の思考の影響を受けていたりするのかもなぁ。
「ぼくの考える主体性は単なる執着や情熱のことではない。自分の意見を臆することなく述べるただ主張する人でもない」「真に自立した主体的な選手はおらず、その自主性に任せていては予選を突破することはできないと考えたのだろう」「ハートの熱さは主体性とは直接の関係はない」「中田はチーム内でのコミュニケーションを取りたいとチーム内での議論を活発にさせようとした。〜中田はこの意見に耳を貸さなかった。〜自分の立場という観点が出ておる時点でいかに宮本たちに主体性がなかったのかが推察される。〜彼らは日本代表を強くするよりも〜とはいえ中田の言うコミュニケーションは実際にはコミュニケーションではなく〜自己の意見を主張した。しかしそれはチームを強くする結果をもたらさず〜。中田のような主張はぼくの考える主体性とは異なるものである。〜ジーコは主体性を要求し放任によりそれをなそうとした。中田はこれに応えようと主張したのだが、空中分解してしまった。主張するようになったが、主体性を得るに至らなかったのである。〜手段と目的が倒立する。褒めて育てろというと褒めてばかりいる、ゆとりというと弛緩してばかりいる、思考停止である。オシムは自分で考えよと。オシムとジーコの主体性に関する考え方は同じであったと思う。ただし、オシムはああしろと要求しながら自分の頭で考えることを同時に要求したことで、ジーコと異なっていた。オシムは、監督が細かく指示することと選手が主体的であることは必ずしも矛盾しないと考えていたのだと思う」「ヴィジョンを共有化しつつ、自分で考える」「なでしこジャパンこそが主体性の具体化なのだと僕は考える。監督名で象徴されなかったのは象徴的である」「答えは自分で見つけなければ意味がない」
創造性にも通じるところか?
*ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training
Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang, Ming Zhou
(Submitted on 13 Jan 2020)
https://arxiv.org/abs/2001.04063
1つ先だけでなくn-gramの予測を行わせる。N-Stream Self-Attention
*AI still doesn’t have the common sense to understand human language
AIはまだ自然言語を理解できていない、AI2が新評価テストを提案(202002)
https://www.technologyreview.jp/s/185777/ai-still-doesnt-have-the-common-sense-to-understand-human-language/amp/?__twitter_impression=true
https://www.technologyreview.com/s/615126/ai-common-sense-reads-human-language-ai2/amp/?__twitter_impression=true
後で読む
*内部強化学習
https://www.slideshare.net/mobile/takahirokubo7792/reinforcement-learning-inside-business
説明理解評価について。
逆強化学習と呼ばれる、強化学習を用いて、人間の実際の行動から目的関数を推定する手法もあるのか。
最適値を求める必要はあまりないと思うが、設定すべき初期値は求めておくべきだし変動は見ておくべき。これはcheck systemに入れるべきかと思うがどうすればよいのか。総合上位のうちより良いと評価したい特許をより強く学習させてゆくとして、予測値だけでは差がないからテキストも含めて…これはesw修正に寄与するインサイトが得られる手法となるのか。他の解決手段もある気がする。教師追加の代替にはなりそうだが。
*Integrating overlapping datasets using bivariate causal discovery
Anish Dhir, Ciarán M. Lee・
(Submitted on 24 Oct 2019 (v1), last revised 11 Nov 2019 (this version, v2))
https://arxiv.org/abs/1910.11356
https://aitimes.media/2020/02/12/4070/?6518
説明理解評価について。
ああ,「特定の個性が出力した予測値を,次に行う決定木におけるtrainの答えとし,該当するテキストを入力として学習,「最もシンプルになった木」が示すifが,その個性を因果を含め説明しうる」,という因果説明手法がありか.オッカムのカミソリ?
ベイズでは確率,決定木ではif,がそれぞれ得られる.「確率では出現しやすい単語がわかるがその単語から個性を類推する手間があった.決定木により単語の共起性が更にわかり,より理解しやすくなる」
個性理解手法は,とりあえずこれが答えではないが,この流れでよいか.ただ,最もシンプル,でよいかどうかには疑問がなくもない.実際は「理解可能な限度でシンプル」が必要となるのであろう.ヒトは7つまで要素を同時に把握できると仮定するなら,7分岐に固定してしまうのもありかもしれない.
*IBM highlights new approach to infuse knowledge into NLP models(202002)
https://www.techrepublic.com/article/ibm-highlights-new-approach-to-infuse-knowledge-into-nlp-models/
NNに対し外部知識・知識グラフ利用でグラウンド。妥当な流れに思う。どう実装したのかな、arxivが先行しているだろうがどれか。外部知識をバイアスの塊とすべき場合が多々あると思うがどうコントロールしているのだろうか。
*Self-explainability as an alternative to interpretability for judging the trustworthiness of artificial intelligences
02/12/2020 ∙ by Daniel C. Elton, et al. ∙
https://deepai.org/publication/self-explainability-as-an-alternative-to-interpretability-for-judging-the-trustworthiness-of-artificial-intelligences
「While it is always possible to approximate the input-output relations of deep neural networks with human-understandable rules, the discovery of the double descent phenomena suggests that no such approximation will ever map onto the actual functioning of deep neural networks. 」
注 Double descentとはvalの学習曲線が上昇した後再び低下する現象のこと。(多分上述しているので後で読み直すって書くと読み直すのは何ヶ月後か)
説明理解評価について。
A simple way of defining the applicability domain by calculating the convex hull of the latent vectors for all training data points. If the latent vector of a test data point falls on or outside the convex hull, then the model should send an alert saying that the test point falls outside the domain it was trained for.
これはcheck systemにおけるtfidf embeddings/cluster visで実現してるかな。
Finally, models should contain measures of uncertainty for both their deci-
sions and their explanations. Ideally, this would be performed in a fully Bayesian way using a Bayesian neural network. [24] For instance, it has been shown that
random dropout during inference can be used to estimate uncertainties at little
extra computational cost [10].
上述したようにベイジアンでよいのか?。check systemのBayesian designを強化してみるか。
*A Simple Framework for Contrastive Learning of Visual Representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton
(Submitted on 13 Feb 2020)
https://arxiv.org/abs/2002.05709
教師なし。dtata augumentationを行った2つのデータの類似度を最大とするように学習する。
請求項とそれを説明する明細の文言を学習させたら教師なしの解像度変換ができるか?。またこの手法でも歪め統合は実現できる。単語ベースでなく文章ベースで。制御はし難いと思うが。
*【機械学習】Google翻訳(みたいなもの)を自作してみた。
https://qiita.com/R-Yoshi/items/9a809c0a03e02874fabb
請求項と明細を用いた教師あり学習で解像度変換をしてしまおうか…
*大規模日本語ビジネスニュースコーパスを学習したALBERT(MeCab+Sentencepiece利用)モデルの紹介
https://qiita.com/mkt3/items/b41dcf0185e5873f5f75
*エンコード、タグ付け、および実現:テキスト生成のための制御可能で効率的なアプローチ(202001)
https://ai.googleblog.com/2020/01/encode-tag-and-realize-controllable-and.html
解像度変換.要約.未知語VOO処理ではTransformer類似の歪め統合を考慮しない文脈考慮?周辺語考慮?した置き換えを行っている.これを「単語レベル」でなく「同一意味を説明する単語群レベル」に持ってゆきたいと考えており,「文レベル」に持ってゆきたくはないと考えている(基本的には,attentionが適当ならば文レベルでも悪くないのだが,例えば,極性の違いは考慮してほしくない....TransformerはQAタスクにおいて極性の違いを見分けていたのだったかな?.また極性を弱くしか考慮しないのであれば良いのだが.SST-2の成績は・・・高いな・・・モデルはColaと同じか・・・).SpanBERTベクトルならば,内部で「同一意味を説明する単語群レベル」の処理を行っている「文レベル」とである,といえるのかな?.
ただ単に,明細まで含めてpre-domainを作成すれば十分であるように思えてきた.
*BERTは計算が苦手?単語分散表現はどこまで数値を上手く扱えるのか(201910)
https://ai-scholar.tech/others/bert-ai-336/
Do NLP Models Know Numbers? Probing Numeracy in Embeddings
written by Eric Wallace, Yizhong Wang, Sujian Li, Sameer Singh, Matt Gardner
Accepted to EMNLP 2019
https://arxiv.org/abs/1909.07940
「71」や「seventy-one」という単語に対応する分散表現から71.0という実数値を推定するタスクを-500~500の範囲で学習したときの予測結果,面白いな.桁で?というわけでもないのか.
またCNNの結果は,教師無し学習は、ポテンシャルを引き上げる,教師あり学習は、ポテンシャルへ到達させる,そのものと見える.
これも個性だわな.ふむう・・・
*学習済み日本語word2vecとその評価について(202002)
https://blog.hoxo-m.com/entry/2020/02/20/090000
*斎藤元幸(201909)
因果構造の学習における必要性と十分性
認知科学/26 巻 (2019) 4 号
https://www.jstage.jst.go.jp/article/jcss/26/3/26_357/_pdf/-char/ja
因果ベイズネット?.理解において因果構造を時系列で判断する誤りが起きる?.共変情報から因果構造が推察されない?.共変情報から因果構造が推察されるのは,因果関係が決定的で外部影響を受けない場合?.
うーん,特許の場合は共変情報から因果構造が推察され理解される,としてシンプルに説明するシステムとすれば十分か?
抑制的因果関係か・・・重要そうな概念かな・・・.BERTに違和感を覚える理由は,抑制的因果関係について甘いからかな・・・
*高橋 康介(201909)
錯視と圏論
認知科学/26 巻 (2019) 4 号
https://www.jstage.jst.go.jp/article/jcss/26/4/26_482/_pdf/-char/ja
両目で見て目を動かすと知覚対象は動かない.片目で見て目を動かすと知覚対象は動く.おお新感覚...
「各種の世界観を一旦保留にして「主観感覚の特徴と構造」を素直に解析する手立てを圏論は提供する」.
*Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer
Monday, February 24, 2020
https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html
転移学習方法論の体系的研究
unlabeled datasets, where we showed that training on in-domain data can be beneficial but that pre-training on smaller datasets can lead to detrimental overfitting;
http://tiny.cc/t5-colab
*Talk to Transformer
https://talktotransformer.com/
「my camp goods is better than you!」
「Huh!? Is this worse than making friendship with people from my town?」
「……Haha, sorry but I got told by the chief of your village to make the goods but I'm not interested so I'm just letting you watch my work.」
Not only that, Claire can't hide her disappointment so she smiles from ear to ear.
After making the sake again, we walked a while until we reach the town.
「……It was disappointing that you had to create the food but I will start that some other day. Ah, I forgot about you. How is your new equipment?」
「I just had it made, it is alright.」
When」
・・・?
*A neurodevelopmental origin of behavioral individuality in the Drosophila visual system
Gerit Arne Linneweber1,2,3, Maheva Andriatsilavo1,2,3, Suchetana Bias Dutta1,2,3, Mercedes Bengochea1, Liz Hellbruegge2,3, Guangda Liu4,5, Radoslaw K. Ejsmont1,*, Andrew D. Straw6, Mathias Wernet2, Peter Robin Hiesinger2,3, Bassem A. Hassan1,2,3,†
Science 06 Mar 2020: Vol. 367, Issue 6482, pp. 1112-1119
https://science.sciencemag.org/content/367/6482/1112.editor-summary
ハエの行動の個性が生まれや育ちではないそもそも無秩序な神経配線の差と関連
・・・ほう・・・これは面白い.
*NICT BERT 日本語 Pre-trained モデル公開
https://alaginrc.nict.go.jp/nict-bert/index.html
「日本語Wikipediaを対象に事前学習したBERTモデルをクリエイティブ・コモンズ 表示4.0 国際ライセンス (CC BY 4.0)のもとで公開いたします。
NICT BERT 日本語 Pre-trained モデルはステップ数を100万に保ったまま、バッチサイズを通常使われる256から16倍の4,096に変更して事前学習を行っています」
*言語処理学会第26回年次大会NLP2020(20200316-19)
単語分散表現に基づく単一言語内フレーズアライメント手法
文のクラスタリングを用いた BERT 事前学習モデルの評価
ファクトイド質問応答におけるBERTのpre-trainedモデルの影響の分析
司法試験自動解答を題材にした BERT による法律分野の含意関係認識
ニューラルネットは自然言語推論の体系性を学習するか
Data Augmentation Technique for Process Extraction in Chemistry Publications
無機材料文献からの合成プロセス抽出のための関係抽出
複数の事前学習モデルを併用した化学分野の関係抽出
Extraction of Inorganic Material Synthesis Procedure from Literature
医薬品添付文書からの薬剤情報抽出システム
Contextual Subword Embeddingsを考慮した文書からの化合物名抽出実験
Transformerを用いた化合物名から化学構造への変換
教師なし分割と言い換えに基づく化合物名同一性判定における候補絞り込み
無機化合物を対象とした論文に対する化学物質名抽出システムの性能分析
自動生成した学習データを用いたマルチタスク学習によるタンパク質と化学物質間の関係抽出
Reweighting in Conditional Random Fields using an Expert-Domain Dictionary
学術論文からのポリマー・溶媒の固有表現および溶解性の自動抽出
マルチタスク学習を利用した短単位の分散表現から長単位の分散表現の合成
文章分類におけるテキストノイズおよびラベルノイズの影響分析
解釈可能なニューラルネットワークによるレビュー可視化
論述構造解析における事前学習済み言語モデルの有効性検証
教師あり文章埋め込みに対する敵対的正則化の効果
会議録に含まれる法律名を対象としたend-to endのエンティティリンキングの性能評価
Pre-distillation ensamble:リソース構築タスクのためのアンサンブル手法
SIGNAL CATCHER: 医学論文を対象とした医薬品有害事象自動判定システムの構築
Detecting Redundancy in Electronic Medical Records Using Clinical BERT
新奇な比喩表現の生成手法(分散表現・概念辞書・係り受け解析の統合的アプローチ)
単語埋め込みの二種類の加法構成性
既知語との表層類似性に基づく未知語の埋め込み表現の計算
文字単位の解釈可能な潜在表現のdata augmentation
BERTの学習済みモデルを用いた用例文ペアの同義判定
事前学習モデルと潜在トピックを用いた文書要約への取り組み
スパースコーディングを用いた脳内意味表象推定におけるBERTの有効性の検証
多言語単語埋め込みのための文脈窓の分析
文脈を考慮した単語ベクトル集合からの単語領域表現
深層異常検知に基づく多義語のコアミーニングを考慮した既習語予測モデルの定式化
NWJC-BERT: 多義語に対するヒトと文脈化単語埋め込みの類似性判断の対照分析
ベクトル長に基づく自己注意機構の解析
専門用語抽出のための並列名詞句の教師なし範囲同定
権利義務認識のための契約書コーパスの構築
・・・
完全中止とならないで本当に良かった・・・
「複数の事前学習モデルを併用した化学分野の関係抽出」,とあるが,結論は書いてあるとおりとして,どのような印象を持ったか,引き続きどのような解析を行ってゆく予定なのか,非常に楽しみ.
*解像度変換.複単語表現.
うむう.SDIでは複単語表現は無視すればよい・・・か.
*解像度は要約において統一されていると予測される、と仮定してもよいあかな。
*的場成紀, 古賀雅樹, 吉村優志, 田邉豊 (大阪工大), 小林一郎 (お茶大), 平博順 (大阪工大)
運転免許試験自動解答における問題解説文の利用
BERT v. word2vec。BERTは、問題⽂と解説⽂がほぼ同⼀内容だが⽇本語の表現がかなり異なる問題(いいかえ?)に強い(長距離作用によるもの?)、w2vは、訓練データにテストデータの問題と類似の問題がなかった問題に強い(類義語置き換えによるもの?)、訓練データにテストデータの問題と類似の問題があったが正答が「×(誤)」の問題に強い(BERTではFPが多い?)、正しく正答を導くには計算が必要となるような問題に強い(?)、ふむふむ、ざっと自分の結果と辻褄は合うかな。結果はそうなるだろうとして、さてどう検証するか。
*池田大志, 藤本拓, 吉村健 (NTTドコモ)
文書分類におけるテキストノイズおよびラベルノイズの影響分析
BERTがテキストノイズの影響を受けやすいというのは、単語を重視しすぎだからであろうか?。BERTにおける未知語か・・・
*解像度変換は、課題あるも解決なし(係り受けも限界)、という感じか?
*word2vecのみで形成する文章ベクトルの性能が低いことは知られているが、単語重視のモデルよりも類義語を吸収できる分?素性はよいはず、とすれば、たぶん、単語の収取選択構造、減算、にまだまだ課題があるのであろうな。
*中山功太 (豊橋技科大/理研), 栗田修平, 小林暁雄, 関根聡 (理研)
Pre-Distillation Ensemble:リソース構築タスクのためのアンサンブル手法
ふむう。6システムのシステムごとの個性差についての結果は無しか。
*日本語語順分析に言語モデルを用いることの妥当性について
後で読む
*ニューラルネットは自然言語推論の体系性を学習するか
○谷中瞳 (理研/お茶大), 峯島宏次, 戸次大介 (お茶大), 乾健太郎 (東北大/理研)
ふむう。教師を限定することでテストにおいて拡大をみる。
上方含意は辞書対応できそうだが、下方含意は例外が多く辞書では足りない。
*多様性評価手法は、回帰式に落としたほうが良いかな?。解析的に理解する必要があるからまず条件枝か?。
*司法試験自動解答を題材にしたBERTによる法律分野の含意関係認識
○星野玲那, 狩野芳伸 (静大)
BERT-SVM、-XGBoostで少量対応。事前学習&転移学習、ルールベース&BERTの展望?、等々
*単語分散表現に基づく単一言語内フレーズアライメント手法
○吉仲真人, 梶原智之, 荒瀬由紀 (阪大)
「実装はツールSAPPHIREとして公開している」 https://github.com/mybon13/sapphire
分散表現行列の「類似連続したカタマリ」を一単位とした、解像度変換?。なるほど。分散表現ベースでの解像度変換がありうるとしてどう区切ればよいのかと考えていたのだが、連続している範囲で切る、という考え方があったか。請求項に加え明細を含め学習した分散表現としたならそれも可能か。ただ、さらに範囲内の単語に対しある程度の減算が必要かもしれないな。非常に面白い。将来的に実装しよう。トピック類似しかし概念レベルが異なる文章間で解像度を統一することができれば、検索精度は向上する。解像度の差(上位概念下位概念による単語の違いや表現する単語と単語数の違い)が漏れにつながりやすい特許文章検索では非常に重要となるだろう。前処理に用いればBERTとの相性も良さそうだ。
ヒト認知に対する個性、を評価する際に、ヒト認知をあらわす単語を列におき、ヒト認知で重要であったある特許文章につきヒト認知をあらわす単語に対する文章内の単語に対する類似度を文章内の単語すべてに対しそれぞれ求め行において行列を作れば、単語の特徴だけでなく、句まで検討できるかもしれない。
とりあえず、SHAP highlightの次に常に表示できるようにしてそこから分析モジュールを作って、品詞表示行列も作って・・・
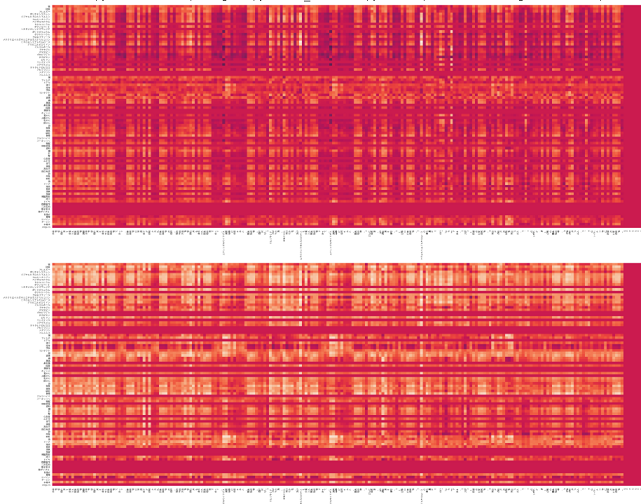
おや?.ああ、これだとこうか・・・なるほど非常に面白い.
「類似連続したカタマリ」は,たしかに句など,適切な区切りを示しているように見える.このカタマリを用いて**「解像度変換」することは,可能だろう.例えば,「眼」とカタマリ「眼科+用+組成+物」は,ほぼ同じベクトル(計算していないがcos類似度で0.8ぐらいか?)となると確認できる.(この例に関しては,目的上,0.8も類似してよいのか?といわれると,ううむ?と思わなくもないが.)
一方,適用するワードに対し得られる「カタマリ」の「大きさ」は,基本的には,どのワードを適用しても類似しているが,部分的には変化している.例えば,ヒト認知におけるポジティブワードに対しては,カタマリ「防腐+剤」が取り出されるが,ヒト認知におけるネガティブワードに対しては,カタマリ「剤」またはカタマリ「水+および+防腐+剤」が取り出される.これはつまり,「特定のワードを適用させてカタマリを取り出す行為により,ワードに適合した?,文脈を考慮したかのような結果が抽出できうる」**ということだ.(言い方を変えれば、文脈ごとに区の長さが変化することが観察できる?。認知主体ごとに同文章の理解がどう異なるかが観察できる?)(「句の長さ・区切り」の「最低単位」は,統語により,一般解による最小化により,決まるものではなく,「文脈により決まる」,と考えると面白いかな.従来は,句を最小化しすぎ,切るべきでないものを切っている,切りすぎにより文脈情報が失われるため適切に再構成できなくなっている,という考え方だ.)(まあ、検証が足りてはいない。)
意外と,w2v-mpのpre-domain自体は,ヒト認知におけるポジティブワードではなくネガティブワードと類似しているのだな.w2vベクトルの合計だけでは適切な結果が得られないと確認できた(いまさら?).
教師データとして助詞が必要である理由は,この連続性を断ち切るためなのかもしれない.しかし助詞が例外なく連続性を断ち切るとしたら,助詞を含む高解像度の句からは満足に解像度変換ができないということになるな・・・.しかし助詞を含むカタマリも見られる.なぜだろう.
自分が欲しいと考えていた,曲げ伸ばしできるベクトルにはまだ足りない.しばらく様々な組み合わせにおいて観察しよう.
しかしいや,自分にとって非常に貴重な発表だった.
(昔、「文章Bの10単語は分散表現上類似しているはずだから?,同一クラスタに配置される?」、とメモしていた。その時検討しとけよと思わなくもない。いや、インサイトって多視点を集めて初めて腹落ちするものだから(言い訳))
*入力ごとに句のウインドウサイズを、あるトピック単語ベクトルと分全単語ベクトルそれぞれとの類似度の連続個数の平均から求め、このウインドウサイズで学習させれば、トピックを考慮した解像度が統一された学習結果が得られやすくなる、はず。
そのバッチのウインドウサイズを句の長さの平均からもとめ、学習時に入力するだけ。難しいことではない。やってみるかな。(バッチサイズは1にすべきか?)
*単語埋め込みの二種類の加法構成性
○Kim Geewook (京大/理研), 横井祥 (東北大/理研), 下平英寿 (京大/理研)
読み込むこと。
*既知語との表層類似性に基づく未知語の埋め込み表現の計算
○福田展和, 吉永直樹 (東大), 喜連川優 (東大/NII)
未知語処理はとりあえず現状に不満はない、上位化と類義化3種を用いた手法を用いている、が、継続して。
***未知語処理、文末置き換え手法部分を改良しておくこと。**MIMICKも考慮。
*勉強不足の自覚はあるが、方向は間違えていないかな。
*新奇な比喩表現の生成手法(分散表現・概念辞書・係り受け解析の統合的アプローチ)
○小柳津久嗣, 橋本翔, 柳澤秀吉 (東大)
発散で新奇性、収束で理解可能性。創造性において課題であった部分でありイノベーションの道筋の幹(道は限定されるものではないが幹はあると仮定)に沿った構造が答えかとも考えていたのだが、こちらを追求する手法もあるかな。分散表現では発散と収束は済んでいるとみなすか、プラスの収束が必要とすべきか。辞書とトピックを足すという考え方は良さそう。
*スパースコーディングを用いた脳内意味表象推定におけるBERTの有効性の検証
○島百子, 尾崎花奈, 小林一郎 (お茶大)
BERT CLS 文ベクトル。
*予測根拠として解釈性の高いアテンションの選択
○石井愛, 小松祐城, 脇森浩志 (日本ユニシス)
attention平均よりも個々のattention特に深い層のほうが。
* 多言語単語埋め込みのための文脈窓の分析
○李凌寒, 鶴岡慶雅 (東大)
文脈窓。ウインドウサイズの影響、文法的、トピック的。同一図上マッピング。
*文脈を考慮した単語ベクトル集合からの単語領域表現
○山内崇史, 梶原智之, 荒瀬由紀 (阪大)
w2gm。自分は歪め統合でまとめるから文脈考慮は不要ではあるのだがふむう、
DBSCANで密度ベースクラスタリング?。クラスタリング手法はいくらあってもよい。構造考慮のクラスタリング手法はなんであったか・・・F・・・?PHATEだ。
https://qiita.com/khigashi02/items/b4b95714cae9e3f2a7be
PHATE(Moon, K.R., van Dijk, D., Wang, Z. et al. Nature Biotechnology 37, 1482–1492 (2019))
*BiLSTMモデルも採用してみるかのう
*入力において複数の分散表現等を連結し学習に任せる手法か・・・分けないと解釈しがたいので後回しかな・・・
*BERTは結局その文脈を学習していなければ文脈を見分けられないのでやはりいたちごっこか?
*個性派デンドログラフで表現すればよいのか?
*ベクトル長に基づく自己注意機構の解析
○小林悟郎 (東北大), 栗林樹生 (東北大/Langsmith), 横井祥, 鈴木潤, 乾健太郎 (東北大/理研)
attention重み以外も含めた分析の提案。注意機構以外が一部打ち消す。打消し部分を例外として無視すれば、attentionによる説明可能性は十分あるようにも見える。
BERT個性とkeb-mp個性の比較において非常に重要と思われる。
上記で書いた、BERTは「重要視する単語をより強く評価」または「共起が無視されたと言えるほど特定の単語のみを重視」、BERTは多分attentionの不正確さにより単語出現現頻度に引っ張られている、という印象に関する?
*サブワードについて誤解していた??。BERTはwordpieceで
*異なる学習で得た分散表現を同一面で可視化する手法?Bilingual Word Embeddings?
*解釈可能な敵対的摂動を用いた頑健な注意機構の学習
○北田俊輔, 彌冨仁 (法政大)
Attention is not Explanationにおいて、注意機構に対して摂動を加えても予測にあまり変化がないと。しかし順位により説明性がないと主張するのは適切ではないと。self-attentionでは別かも?
前記、ベクトル長に基づく自己注意機構の解析、に記載したコメントと関連?
*自動運転車の対話的操作を実現するための自然言語の空間意味表現に基づくグラウンディング
○大田原菜々 (お茶大), 塚原裕史, 欅惇志 (デンソーITラボ), 小林一郎 (お茶大)
音声指示→画像検出→指示類型化→グラフ適用→確率化?。強化学習は・・・
*chiVe 2.0: SudachiとNWJCを用いた実用的な日本語単語ベクトルの実現へ向けて
○河村宗一郎 (ワークス/香川大), 久本空海, 真鍋陽俊, 高岡一馬, 内田佳孝 (ワークス), 岡照晃, 浅原正幸 (国語研)
*tfidf embeddings/cluster vis改良に対するいくらかのインサイトも得られた。
https://qiita.com/kzuzuo/items/8a80d8974bf3a7db7e54
*自分は最近の自然言語検索全体について、&を無視し+を重視しすぎるというか、ヒト認知との適合においてはprecisionが重要でrecallは二の次となると思うがヒト認知においてもF1を評価指標としてしまいrecallが過剰に考慮されているというか、昔と比較してこれらのような結果が返りやすくなっている印象がありそれに違和感を持っているのだが、それに関しての研究はなさそうだったな。認知科学会の分野かな?。A/Bテストは基本として実施しているやろうし、自分が気になっているだけかもしれないが。(フィルターバブルとよぶらしい)
*attention解析とマルチタスク学習が耳に残った。
*いつもどおり、いらすとやは、偉大であった。
https://www.irasutoya.com/
* 超球面上での最適輸送に基づく文類似性尺度
○横井祥, 高橋諒, 赤間怜奈, 鈴木潤, 乾健太郎 (東北大/理研)
聴講できなかったが、非常に重要であるようだ。
ベクトルの長さは本手法で重要視しているので興味深い。
*学会は非常に興味深いが,arxivなどがある現在,最先端ではないと感じる.最先端の発表自体も少ないかもしれない.しかし,実装においては,非常に大きなヒントが得られる印象がある.
*駒谷剛志(202003)
AI創薬で取得すべき知財権とその保護第一回
Pharm stage 19(11) 2020
概念につき,えらく広くポイントをついたまとめに見える.
このような事務所に出願依頼するとよいのであろうなと思うところ.
*須山敦志(202002)
ベイズ統計・ベイズ機械学習を始めよう
https://www.bigdata-navi.com/aidrops/2423/
*Probabilistic Programming & Bayesian Methods for Hackers
https://camdavidsonpilon.github.io/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers/
*DeepL翻訳が日本語と中国語を習得
https://www.deepl.com/blog/20200319.html
「DeepLの翻訳が他よりも優れているとして選ばれる頻度が最も高いという結果になりました」
Wikiによると、Lingueeデータベースでトレーニングされた畳み込みニューラルネットワークを使用、CNNは一般に、長く一貫性のあるワードシーケンスにやや適していますが、リカレントニューラルネットワークを優先する弱点のため、競合ではこれまで使用されていません。DeepLの弱点は、部分的に公開されている[4]追加のトリックで補われています。[5]、とのこと。
https://de.m.wikipedia.org/wiki/DeepL
CNN類似モデルとtransformerであるBERTモデルを扱っている身としては、この4と5が非常に興味深い。
4 Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio: Neural Machine Translation by Jointly Learning to Align and Translate. In: arXiv. 1. September 2014, arxiv:1409.0473
https://arxiv.org/abs/1409.0473
「この論文では、固定長ベクトルの使用がこの基本的なエンコーダーデコーダーアーキテクチャーのパフォーマンス向上のボトルネックであると推測し、モデルが自動的に(ソフト)検索できるようにすることでこれを拡張することを提案します」
5 DeepL: Übersetze Dokumente mit DeepL. 18. Juli 2018, abgerufen am 18. Juli 2018.
https://techcrunch.com/2017/08/29/deepl-schools-other-online-translators-with-clever-machine-learning/
「10億以上の翻訳とクエリの膨大なデータベースに加えて、ウェブ上の類似のスニペットを検索することで、翻訳を地に足のついたものにする方法は、新しいモデルのトレーニングのための強力な基盤となりました」
「大学、研究機関、そして実際にLingueeの競争相手によって発表された開発は、同社が以前に使用していたリカレント・ニューラル・ネットワークではなく、畳み込みニューラル・ネットワークが行くべき道であることを示した。今はCNNとRNNの違いを説明する場ではないので、関連する単語の長い複雑な文字列を正確に翻訳するには、弱点をコントロールできる限り、前者の方が良い賭けだと言わなければならない。
例えば、CNNは、大まかに言えば、文の一語一句に取り組むことができます。これが問題になるのは、例えばよくあるように、文末の単語が文頭の単語をどのように形成すべきかを決定している場合です。文全体を調べて、ネットワークが最初に選んだ単語が間違っていることに気付いて、その知識でやり直すのはもったいないので、DeepLや機械学習分野の他の人たちは、このようなトリップアップの可能性を監視して、CNNが次の単語やフレーズに移る前にそれを解決する「注意メカニズム」を適用しています。
もちろん、他にも秘密のテクニックがあり、その結果、私が個人的に新しいデフォルトにしようと思っている翻訳ツールができました。他の人たちが自分たちのゲームをステップアップするのを見るのを楽しみにしている」
現状でもCNNを使い続けているのか不明ではあるが(2018にこの主張ならば,アルゴリズムは基本的にそのままと考えたほうが妥当?)
先に,CNN-attentionの文献をメモしたけれど,それか?
→Felix Wu, Angela Fan, Alexei Baevski, Yann N. Dauphin, Michael Auli
Pay Less Attention with Lightweight and Dynamic Convolutions
https://arxiv.org/abs/1901.10430
CNNーattention.Dynamic Convolutionは局所的なself-attentionともみなせるとのこと.
Facebook AI Researchとコーネル大学の研究者か.ちと違うか.
(文内にピリオドが多くとも,正確に文区切りしてくれやすいような印象.)(回文を入力するとエラーが発生しやすい?)(訳抜けもある.なにかtransformer臭いが・・・)
・どうも単語単位で,モデルの個性を評価できそうだ.
であるなら,まず教師データから「あるモデルのみ正解」できた教師データを抽出し,モデルに該当するW,K,Bのラベルを貼る.それ以外の教師データはその他を示すEのラベルを貼る.
単語単位で良いのであれば単純なBoWなどを入力とし,多層全結合で学習する.Wに分類されたならWの評価結果に3倍近い重みを付与,K,Bにも同じように重みを付与する.
すれば,モデルの個性を学習で評価できる(単語単位で良いのであれば,ベイズのほうが適切な結果となるかもしれない).
・・・できるのだが・・・明らかに教師データが足りないな.殆どの教師データはEラベルになってしまう.数個のWラベルで学習しても適切となり難いだろう.
過去の全データから評価用教師データを抽出しても,「あるモデルのみ正解できた教師データ」は,ラベルごとに,何とか数件得られるかどうかだろうか・・・.正解した場合はほぼ全てのモデルで正解していることがほとんどだからな・・・.この評価用教師データを用い予め学習により評価モデルを作り上げておき,評価時には予測だけ行うという手法でもよいか・・・いや少なすぎるか.そのモデルのみが正解できた、でなく、「そのモデルのみがヒト認知と一致した」、であれば教師数は増やせるが。(全体を一つの学習モデルとして組み上げた場合は、内部的にこのように学習データが不足する結果となりこれがボトルネックとなり性能が発揮されない結果となるかもしれない。)
評価モデルが単純となるなら教師データは少なくとも良いかもしれない.どこまで複雑になるだろうか.
モデルの個性を理解し,理解に基づき適用範囲と近似式を設定し,ルールベースで評価をするほうが最終的には妥当か?.これを想定するなら,評価学習は理解にもつながる決定木かベイズで進めておいたほうが良いだろうな.メタラーニングも考慮して・・・
やれやれ,やっとゴールが見えてきたか.ベイズや決定木は最初の想定でもある.何も考えず決め打ちでやっても良かったかもしれないな.実のところ,理解と評価の双方が目的であって理解できないが評価できるという結果が欲しいわけではないので避けられなかったとも思うが.
まあやってみると,Bラベルの正解率は高いが,W,Kラベルの正解率は高くなく,FP,FNは許容範囲外となるかもしれない.多分評価にもちいることができる語彙が不足するため,語彙を補う処理は必須だろう.すると単純な単語単位ではなく・・・
正解とヒト認識適合とのマルチタスク学習は,ある程度有効かもしれない.
*たぶん今は,振り返る時期だ.(本業の学習に支障が出てつつある感覚がありそちらを先に振り返れよと思わなくもないこともない.)
*転移学習:機械学習の次のフロンティアへの招待
https://qiita.com/icoxfog417/items/48cbf087dd22f1f8c6f4
http://sebastianruder.com/transfer-learning/index.html
再度見直す.
「機械学習の成功を今後推進するのは(最初の推進は教師あり学習)、教師なし学習、そして最近目覚ましい進化を遂げている強化学習でもなく、転移学習である、」という点までは,最初期にAndrew ng御大の講義で聞いていたが,内容を理解できていなかった.今なら解ろうか.
ドメインという言葉はここで出てきていたのだな,ということすら忘れている・・・
歪め統合はどれに該当するのか・・・
*流行期のインフルエンザ診断
http://www.igaku-shoin.co.jp/paperDetail.do?id=PA03346_05
診断におけるベイズ推定.
多様性評価について.モデルの結果を事前確率として,ヒト認知から尤度を求め,事後確率を計算する,としてもよいのだがなぁ.
*Mathematics for Machine Learning
https://mml-book.github.io/
*安井 翔太(202001)
効果検証入門〜正しい比較のための因果推論/計量経済学の基礎
*AI Feynman: A physics-inspired method for symbolic regression | Science Advances
https://advances.sciencemag.org/content/6/16/eaay2631.full
データからそれを満たす法則を自動で発見するAI。ファインマン物理学講義に載っている100の法則をすべて発見。
*AI Poincaré: Machine Learning Conservation Laws from Trajectories
https://arxiv.org/abs/2011.04698
AIポアンカレ
*分布が一定と仮定してサンプリングと統計により頻度から結果を導くか、
分布も一定でないとして手元のサンプルにより有意性検定を用いつつ頻度から結果を導くか、手元のサンプルを何が一番もっともらしいか分布の仮定と確率の問題に落とし込み結果を導くか、その他か。
*従来のBLEUscoreでは正しく評価できない! 自然言語に最適な人間に近い評価基準BERTScore登場!
https://ai-scholar.tech/articles/natural-language-processing/bleu-score-bertscore-bert-n-gram-natural-language-processing
課題はわかるのだが手段はそれでよいのだろうか。
「高いスコアを発揮するモデルや手法だけではなく、意味のあるスコアを求める評価基準についても目を向けていく必要があるのではないでしょうか?」
完全に合意するところ。
マルチタスク学習のような手法で意味のある評価基準を求めてゆく手法も、目的関数自体を工夫する手法もある。この分野はまだまだ将来性がありそうに感じる。自分は多様性評価において、現在恣意的な評価としているが、他の学習結果をマルチタスクの一部のラベルに振り替え総合評価することにより、より適切な評価ができうると思っている。問題はどのような学習結果をいかに少量の教師で持ってくるかだが…歪め統合による教師なしが適切な気がするけれどコントロールがなぁ
*Zoom In: An Introduction to Circuits
By studying the connections between neurons, we can find meaningful algorithms in the weights of neural networks.
https://distill.pub/2020/circuits/zoom-in/
・モデルが個性を示したデータについて決定木試行。これでよいはずだが・・・。
枝を適当に切り払うとこちら。いずれの葉においてもジニ係数が十分小さくなっていないためあまり意味はないが.
ある程度ジニ係数が小さくなっておりある程度のサンプル数がある葉である「眼」のFalseに注目すると、多くがBERT判断となるところは、これまでの主観的な見解と一致しており興味深い。(「眼」の出現したデータ個数、個性ごとの出現回数は次の通り。BERT 92/146 1292、keb-mp 8/130 21、w2v-mp 12/309 25)
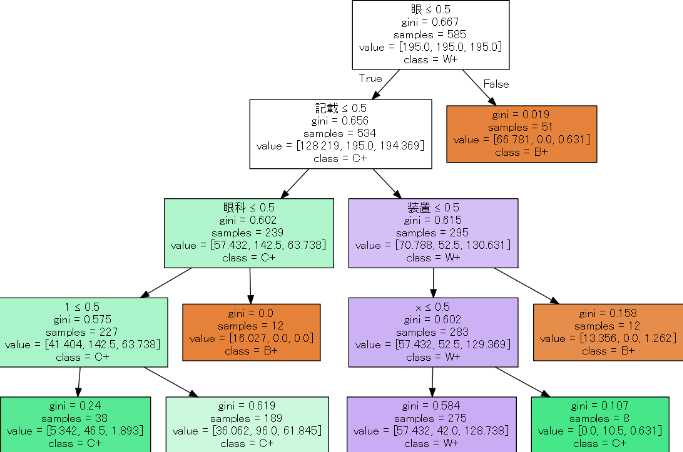
うーむ。特徴となる単語から影響を受ける度合いは、あえていえば、BERT > keb-mp > w2v-mp、といったところか?(<trueに特定のモデルの個性が集まる傾向からすると)。BERTはそれとなる条件においてそのほとんどが何らかの単語の出現数の影響を受けているように見え(これは上記印象と同じ)、w2v-mpやkeb-mpはそうでないように見える。
とりあえず、「最もシンプルになった木」が示すifがその個性を因果を含め説明しうる、とはできないようだ。(最もシンプルな木は、「眼」「方法」「板」「グリシニル」をifとする。これらの木に配置されている件数からしても、さすがに説明になっているとはいえない。)(w2v-mpとkeb-mpの分岐部分に配置されている単語は「と」であった。・・・わからん。全体的にみると、w2v-mpは機能語をkeb-mpより食っていないように見えなくもない。)
もう少しデータを増やしつつ条件を詰めてみるか。分割の良さ、情報利得、不純度か。
共起分析の結果と照らしあわせると、何がわかるか・・・
gini: 特定単語の出現数から得られる理解は・・・単語重視の割合BERT 21/48、keb-mp 14/48、w2v-mp 13/48。単語非重視の枝は、最長w2v-mp、4葉以上の枝BERT 1、keb-mp 0、w2v-mp 2。
gini 名詞: 名詞出現数から得られる理解は・・・単語重視の割合BERT 13/54、keb-mp 14/54、w2v-mp 27/54。単語非重視の枝は、最長w2v-mp、4葉以上の枝BERT 0、keb-mp 2、w2v-mp 1。
gini tfidf: 特定単語の文脈上の出現傾向?tfidfから得られる理解は・・・単語重視の割合は、BERT 15/42、keb-mp 12/42、w2v-mp 15/42。単語非重視の枝は、最長w2v-mp、4葉以上の枝BERT 0、keb-mp 2、w2v-mp 2。「眼」が出現し「方法」が出現しないときBERT個性となる(全体の1割)。
gini 名詞tfidf: *
entropy: giniとほぼ変わらず
gini 出現有無: 特定単語の出現有無から得られる理解は・・・単語重視の割合は、BERT16/58、keb-mp15/58、w2v-mp27/58。単語非重視の枝は、最長w2v-mp、4葉以上の枝BERT 1、keb-mp 2、w2v-mp 2。「眼」が出現し「重」が出現しないときBERT個性となる(全体の1割)。
全体: 眼の出現回数(眼科なども含める)は、BERT 1292、keb-mp 21、w2v-mp 25。(見事に偏っている。tfidf embeddings/cluster visでBERTが偏るのもこのあたりの影響だろう。)
・・・一貫性のある理解につながるのかなこれ・・・
決定木に「単語のどの属性を数値として与えるか」がポイントだろうか。
出現数、tfidf、出現有無を与えてみたがどう理解したものが。与えるものが間違っているか?
((以下書き直し中
全体的に、「単語を重視する傾向 BERT > keb-mp > w2v-mp *名詞限定すると逆転 *出現数でなく出現有無で評価すると逆転?)」(BERTは「辞書」だから?w2v-mpとkeb-mpは単語を強制的にウインドウ単位とするから?)
「単語では理解できない傾向 w2v-mp > BERT > keb-mp」(w2v-mpとBERTは単語がそれ自体の意味を示さないことがあるのでその影響か?)
が得られているが・・・傾向の再現とれるのかな。)
もう少しモデルの個性に関する何らかのインサイトが得られると思ったのだが、単語レベルでは難しいのか決定木の問題かやり方の問題か理解力の問題か・・・
決定木またはベイズで理解できると理論化しやすくありがたかったのだが。
出現単語を適当な辞書で分散表現に変換し、分布を見たほうが早いか?。いや単語では理解できないならよくない、少なくとも文ベクトルに変換し分布を見ないといけないだろう。しかし、文ベクトルはその作り方により理解に対するバイアスが生まれるから・・・
どのモデルも単語共起に依存はしているはず(それがwindowだろうがattentionだろうが次単語予測だろうが)。本結果と、共起分析、SHAP highlight、ベイズの結果を照らし合わせ考えてゆこう。))
w2v-mpとkeb-mpについて。windowで規制しているとはいえ、ある程度の傾向はみられると思っていたがそうでもないように見える。w2v-mpとkeb-mpではXORが効いているのかもしれない。したら共起分析では抽出できないか。
もしXORが効いているとしたら、自然言語処理において認知を扱うには、古典的な手法では不可能で、「3層以上の層を持つニューラルネットワークを加える」ことが必須となるのかもしれない。現在スコアが高い手法でも、XORを扱えない手法であれば、認知は扱えないのかもしれない。自作AIである程度それっぽい結果が出ている理由は、定石を外し、ある程度深いネットワークを形成しているから、かもしれない。
XORに対応している解釈可能性の高い手法って何があったかな。決定木であれば・・・要素が再利用されかつ枝が合流もできる、ような表現手法をもつ決定木、になるのか?
グラフデータの機械学習における特徴表現設計の体系化
https://kaken.nii.ac.jp/ja/grant/KAKENHI-PROJECT-17H01783/
決定木学習
https://www.slideshare.net/mitsuoshimohata/ss-35949886
[入門]初心者の初心者による初心者のための決定木分析
https://qiita.com/3000manJPY/items/ef7495960f472ec14377
このあたり参考となるのだろうか?
*共起単語ペアとその出現頻度に対し決定木を作成させれば、より良くなるはず。共起単語間の距離で分析すれば。。。
*説明できない点が残るもののorの可能性もある。簡単な教師データとテストデータでxorを見分けているか確認できるな…
*そもそも、transformerはxorをとらえているのかな?
→XORテスト。
BERT:XOR正解候補評価0.484041、0.498230、XOR不正解候補評価0.529688。
w2v-mp:XOR正解候補評価0.942217、0.881531、XOR不正解候補評価0.071232。
XORにおいて明確に違いがあるようだ。
簡単な文字単位テストであるから文構造を持たせたらどうなるか・・・(keb-mpはそのアルゴリズムにおいて簡単な文字単位テストでは適切に動作しないことが明確であるため省いた。あえて書けば0.489600、0.489537、0.489232)(補足 ランダムフォレスト:0.555625。既存のtreeではダメそう。)
*BERTは語順を捉えているが、他モデルはウインドウ外では全く語順を捉えていないだろう。決定木ではモデルが語順を捉えていても共起性にまみれ見えなくなるだけ、BERTのそれら単語を重視する傾向が下がって見えるだけであろうが…。
*決定木可視化ツールdtreeviz
https://github.com/parrt/dtreeviz
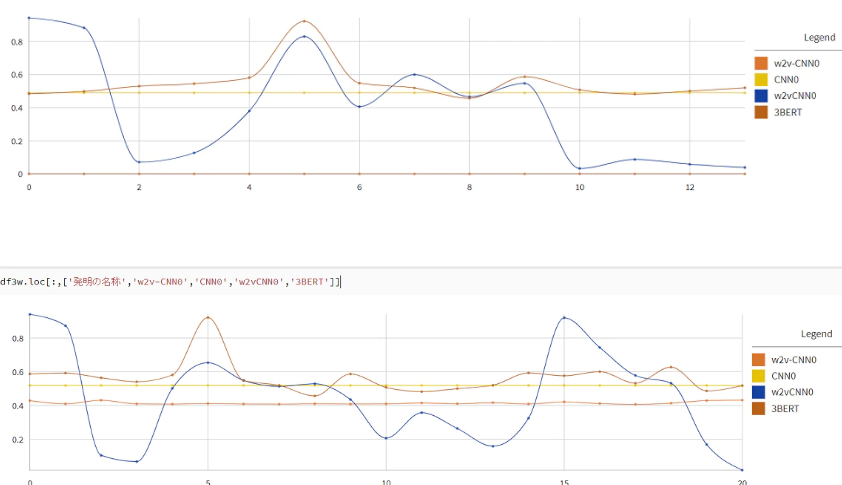
*ちょっと面白い結果が出たな・・・
0-3は、XORへの適合を示している。これは上記通り。5は、w2v-mp(w2vCNN0)については計測回数による適合を示している、BERTについては不明(事前学習中のattentionか?)。下図5,15の違いは、w2v-mpについては幅の変化に忠実に追従し差をつけていることを示している、BERTについては・・・
*BERTbase12層には全結合層があるが単語単位のXORは取らない。attentionではXORを表現できないはず。残差は…1列のパーセプトロンを12層全結合ではなく結合したと言える?からやはりXORを表現できないのではないか。
*ヒトの認知においてXORは必須である、ような結果が出たなら面白い。
→松井 理直(2012)
条件文の理解過程における既定性と関連性の影響
2012年度日本認知科学会第29回大会
https://www.jcss.gr.jp/meetings/JCSS2012/proceedings/pdf/JCSS2012_P1-11.pdf
「以上、情報の既定性と関連性の論理的計算という観点から、条件文の理解過程を分析した。
まず始めに、既定情報は連言計算として、関連性は排他的論理和(XOR)として表現できることを見た。既定情報が連言として計算されるのは知識の整合主義に基づくものであり、関連性が排他的論理和として計算されるのは語用論として適切な推論の範囲を可能な限り狭めたいという要求に基づく。~」
BERTは量的な計算、
w2v-mpは質的な計算、
互いに関連はない。
情報間の関連性計算には、質としての排他的論理和?。
上記(下記か?)のどこかで、FNの多さやCVに絡めて?、BERTなど最近の主流技術は不正解候補を考慮できていないようで気持ち悪い、などという趣旨の文を書いた?が(違和感、と表現していた)、
XORでは除去できるマイナスをBERTなどでは除去できていないから、「人の認知と一致しきれず気持ち悪い」のだ、
としたら、納得は、できる。
(案外、DeepL翻訳の優位性も(DeepL翻訳がまだCNNベースであるかどうかなどは知らないが)こんなところにあるのかもなぁ。DeepL翻訳も下流深層式のCNN類似技術だったりして。)
いやしかし、認知科学ってのは必須やなぁ
*木ベースのアルゴリズム、SVM、LDAなどトピックモデル、は、スコアが良かろうと自分の目的においては頭打ち、なのかもしれないな(これらは自分の目的においてはスコアも高くないが)
*スパースモデリングのように、モデルが示す一定の特徴語を全体的に抽出し、モデルが特徴としたかどうかについて数値化し、それのみに対し決定木を適用したら・・・?。SHAP highlightで行うにはコストが高すぎるが・・・(データが大きすぎ開かない…集計結果のみ開くか…)
*export_graphviz class_namesメモ。昇順の番号順に指定する必要があります。https://datascience.stackexchange.com/questions/20415/what-should-be-the-order-of-class-names-in-sklearn-tree-export-function-beginne
*NeurIPS2019における自然言語処理(202004)
https://www.slideshare.net/secret/eOf13JfmWCDILM
*Yi Tay、Dara Bahri、Donald Metzler、Da-Cheng Juan、Zhe Zhao、Che Zheng(202005)
Synthesizer: Rethinking Self-Attention in Transformer Models https://arxiv.org/abs/2005.00743
「TransformerのQuery-Keyのself attentionは、中心的で不可欠なものとして知られています。しかし、それは本当に必要なのでしょうか?このペーパーでは、Transformerモデルのパフォーマンスに対するドット積ベースのself attentionメカニズムの真の重要性と貢献について調査します。広範な実験により、(1)ランダムアライメントマトリックスは驚くほど競争力があり、(2)トークントークン(クエリキー)の相互作用から注意の重みを学習することは結局それほど重要ではないことがわかりました」
えええ?。attentionのウエイトは他因子のウエイトより充分低い、attentionはフレーバー、と読んでおくけれど。でもattentionのweightって、任意の値で小さくなっていたような・・・
*Generative Deep learning
https://www.amazon.com/Generative-Deep-Learning-Teaching-Machines-ebook-dp-B07TWT9VN6/dp/B07TWT9VN6/
Current neuroscientific theory suggests that our perception of reality is not a highly complex discriminative model operating on our sensory input to produce predictions of what we are experiencing, but is instead a generative model that is trained from birth to produce simulations of our surroundings that accurately match the future. Some theories even suggest that the output from this generative model is what we directly perceive as reality.
And or xorで構築した判断を、シミュレートしてifの知識に移し、要事さらに外部知識を導入して認知としたりする。ことを言っていると思う。
方向性は正しいだろう。
知識と認知における排他的論理和の関係を調べてゆきたい。
また、かなり処理が重くなるが…SHRP値とXORからモデルの個性を抽出し…
先の関係に関する知識と照合することで、認知や想像的AIに応用できる示唆を得たいと思う。
*木構造でニューラルネットワークを解剖!?精度と解釈性のトレードオフを解消するNBDTとは(20200518)
https://ai-scholar.tech/articles/decision-trees/nbdt_neural_backed_decision_trees
タイムリー。
NBDT: Neural-Backed Decision Trees
written by Alvin Wan, Lisa Dunlap, Daniel Ho, Jihan Yin, Scott Lee, Henry Jin, Suzanne Petryk, Sarah Adel Bargal, Joseph E. Gonzalez
(Submitted on 1 Apr 2020)
https://arxiv.org/pdf/2004.00221.pdf
1 Induced Hierarchyの構築
2 Tree Supervision Lossによりモデルをファインチューニングする
3 ニューラルネットワークのバックボーン(特徴抽出層)によってサンプルを特徴ベクトル化
4 全結合層に埋め込まれた決定ルール(Embedded Decision Rules)を実行
解釈可能にdisentangleしておき、特徴抽出層から取り出す、てことか?。画像系やしちょっと趣旨も違うが。and orを直接ifとして説明したいわけではないのだよな。あくまで知識が得られれば良いのであって思考過程の正確さや再現はぶっちゃけどうでも。XORはどう表現するのかな?
ソフト決定木か。これなら…
*BERTから単語ベクトルを取り出し(CLSの文章ベクトルではない)、3層ぐらいフルコネクト層を足せば、違和感なくより良くもなるかな。
w2v-mpなど設計時の経験からすると、深くしても、accuracy,F1などシンプルな評価値は変わらない。BERTにフルコネクトを層を足していた人はいたはずだが、XORと認知の視点で評価していた人はいたかな…。
もしフルコネクト層を足すことに意味があるとしたら、ありふれた評価しかしない、評価できない、というのは致命的なんだろうなと感じるところ。
(FNの件数は変わらずとも、1件1件のFNは変化していただろうから、鷹の目魚の目で見極めていた人は気づいていたかも。)
*transformerはheadのひと塊をノードとみなせば、head x layerの全結合とみなせる? ならばXOR可能ではあるが。同一head内ではXORが効かない?
*WT5?! Text-to-TextモデルでNLPタスクの予測理由を説明する手法!
https://ai-scholar.tech/articles/natural-language-processing/wt5-text-to-text-nlp
WT5?! Training Text-to-Text Models to Explain their Predictions
written by Sharan Narang, Colin Raffel, Katherine Lee, Adam Roberts, Noah Fiedel, Karishma Malkan
(Submitted on 30 Apr 2020)
「例えば、感情分析タスクであれば、0(ネガティブ)または1(ポジティブ)というラベルを返すのではなく、直接negativeというテキストを出力します。このシンプルかつ普遍的な手法は、様々なNLPタスクでSoTAを実現しました」
「予測が入力のどの部分によるものなのかを特定したり、モデルの構造を分析しやすいように変換する手法などが提案されてきましたが、いずれも実用的ではありませんでした。
そこで、筆者たちは、人間の意思決定と説明のあり方に着目しました。そもそも我々人間の判断自体ブラックボックスであり、本当の意味でその判断の過程を可視化することはできません。しかし、我々はなぜそのように判断したのかを言葉で説明できます。例えば、「『ひどい』という言葉が入っているので、このレビューはネガティブだ」というように。ただし、これを単純なルールベースシステムにすると、「ひどく感動した」と言ったものまでネガティブの判断材料としてしまうため、他の方法で正確なシステムを作る必要があります。
人間もニューラルネットワークも、性能が高いがブラックボックスなものと言えますが、人間は言葉で判断の理由を説明できます。ということは、ニューラルネットにも同じことができるのでは、というのがこの論文の発想です。ここで冒頭のtext-to-textフレームワークを利用します。テキスト(問題文)を入力し、テキスト(答えと説明)を出力するモデルを構築すればいいわけです。例えば、映画レビューの感情分析タスクで「negative」と返すのではなく、「negative explanation: the acting was terrible.」と出力します」
「このtext-to-textモデルは、“Text-to-Text Transfer Transformer” (T5)と呼ばれる学習済みモデルをファインチューニングして構築しています」
お、おう。これができるほどtransformerの生成系の性能は高かったのか?。単語分散表現でもtext2textは試みられていたし自分も活用している(tfidf embeddings/cluster visにおいて、作成した文章ベクトル空間にある単語ベクトルを放り込み近似する文章ベクトルを取り出している、単語分散表現から文章分散表現を作るにおいて邪魔な成分を除くまたは邪魔と思われる成分の役割を解明するなどによりまだ性能改善可能であると考え試みている(例えば、機能語「の」は、後ろの意味語ベクトルに対し前の意味語ベクトルの係数倍を加えることを示す「演算子」とみなす、など)、という意味で)が、これができる印象ではなかった。出力部分は回帰で表現できるべきだとは思う。
ドメインに関わらず、であるのはなぜだろう?。学習済みのドメインにおけるその文脈上の結論を出力しているのではないのか?
*UnifiedQA: Crossing Format Boundaries With a Single QA System
https://arxiv.org/abs/2005.00700
T5ベースの単一の事前学習QAモデ「UnifiedQA」を構築。
Googleのtalk to bookもまだまだ改良されてゆきそうかな。個人特化しない関連技術はGoogleなど大手が無償提供するだろう。いくらかの知財関連ベンダーさんは個人特化に方向を変えたほうが良いと思う。書籍全文の豊富な電子データを持っているまたは使えるなら別だが。
*技術部 アドバンストテクノロジセンター 鵜野 和也(202002)
はじめての自然言語処理
第7回 T5 によるテキスト生成の検証
https://www.ogis-ri.co.jp/otc/hiroba/technical/similar-document-search/part7.html
T5の日本語実装参考
*Published: 25 January 2020
Forecasting emerging technologies using data augmentation and deep learning
Yuan Zhou, Fang Dong, Yufei Liu, Zhaofu Li, JunFei Du & Li Zhang
Scientometrics volume 123, pages1–29(2020)Cite this article
https://link.springer.com/article/10.1007/s11192-020-03351-6
いわゆる特許をもとにした未来予測システム.目的は同じ.
教師なしを中心としつつグラウンディングのためにデータ拡張とGANを利用した教師ありを採用.手段は異なるが・・・GANをテキストベースで使ったのか.この場合のGANは上位概念化と下位概念化のどちらに進むのだろうか.この場合のGANは,文法構造を保ったままランダム置き換えした文章を作っている,と理解してよいのかな?.課題と手段の妥当な組み換えは確かに可能かな.方向性が不足しているのではないだろうか.ニーズの方向を足してやりさえすれば・・・.
Tfidf embeddings/cluster visと自作AIの組み合わせで同じようなことはできているし,現在w2vkeb-mpで疑似データ増幅を試しているが・・・比較してみたいな.
GAN生成例はどこにあるのかな・・・多分,n-gram内で妥当な単語集合ができたときに高評価としていると思うのだが文章になっているのかな・・・
ランダム置き換えに対する比較データは・・・
新興技術(ET)と非新興技術(NET)のサンプルにラベルを付け,という部分に少々疑問が・・・
SVM、NB、およびRFとの比較,か・・・.これらとの比較に意味があるのかな・・・
「GETHCは、1979年に世界初の情報技術調査分析会社として設立されたGartner(www.gartner.com)によって提案されました。GETHCは、新興技術の開発の特定の段階を説明することを目的としています(2012年 6 月)」ほう.これは自分の課題の評価においても使えるかな?
・モデルの個性を理解するために、ベイジアンネットワークを用いる?
*行動観察 × ベイジアンネットワーク~複雑な生活者心理をモデリングする~
https://www.msi.co.jp/userconf/2017/pdf/muc17_BRN_1.pdf
*Bartlema(2013)
Bayesian hierarchical mixture approach to individual differences: Case study in selective attention and represent ation in category learning.
Journal of Mathematical Psychology, 59, 132-150.
階層ベイズ混合モデリングによる個人差へのアプローチ
https://www.sciencedirect.com/science/article/abs/pii/S0022249613001235
数理心理学か…
*BERTに覚える違和感の正体は、list-length効果が考慮されていないからかもな。
*MNTSQ, Ltd. 専門知で深まる自然言語処理を求めて
https://www.wantedly.com/companies/mntsq/post_articles/242787
リーガルテックにおける自然言語処理が提供できる価値、等々
「この内、「タスクを解く」部分に限っては、機械学習という帰納的アプローチを取る以上、アルゴリズム開発者だけでもある程度の性能は出せるようになるとは考えています。しかし、タスクを適切に定義することや、解くべきでないエラーの分析、さらには法的洞察を基にしたより省力的な解法の発見などにおいては、リーガルの知識が必要不可欠です」
「検索システムの開発をかじったことがある方は共感してもらえると思うのですが、検索体験の評価というのは大変難しく、実際のユーザーの意図やニーズ、使用文脈をきちんと想定しないと、ユーザー価値に対して的はずれな施策を打ってしまいかねません。一方で改善可能な細かい問題点の指摘がすぐに思い浮かぶのは、実装がイメージできるエンジニアであるという側面もあり、異なる役割同士からの製品に対する多角的なフィードバックが求められています」
*その知識は本当に有用?知識を用いた対話生成の教師なし手法"Decoupling"を提案
https://ai-scholar.tech/articles/natural-language-processing/decoupling-language
Unsupervised Injection of Knowledge into Dialogue Generation via Language Models
written by Yi-Lin Tuan, Wei Wei, William Yang Wang
(Submitted on 30 Apr 2020)
「有用な情報なしに一般的な応答(generic responses や dull responses と呼ばれる)を生成する傾向がある〜
そのように情報を指定することによって、モデルが一般的な応答ではなく、よりドメイン固有な応答を生成することを可能にしています。しかし、話し手が常にそのような情報を話してくれるとは限りません。〜
この研究では "knowledge gap" 知識のギャップというものを定義していて、これを用いることで、訓練と推論時にも知識不足を定量化することができ、問題を調査する方法を提案しています。
そしてなんと、この知識のギャップが、データの全部を用いてモデルをテストすることが性能を低下させる可能性を示唆しています!」
データが多すぎてもいけないことなら、先に記載したとおり、自分も同感。
*ここ最近の計算社会科学の動向(202006)
https://buildersbox.corp-sansan.com/entry/2020/06/08/110000
*【翻訳】技術的負債という概念の生みの親 Ward Cunningham 自身による説明
https://t-wada.hatenablog.jp/entry/ward-explains-debt-metaphor
きちんと理解できている気はしないが、非常に重要に思える。
「人間は自分の言語で使われているメタファーから類推して思考しているということです。」「そのとき私が重視していたのは、アプリケーションを開発していく過程で得られた学びを蓄積するためにプログラムに手を入れることでした。」
「それを「負債のメタファー」と名付けました。どういうことかというと、「もしも自分たちが書いているプログラム(WyCash)を、金融の世界に関する正しい捉え方だと自分たちが理解した姿と一致させることができなくなれば、自分たちは絶えずその不一致につまずき続けることになり、開発スピードは遅くなっていくでしょう。それはまるで借金の利子を払い続けるかのようです」と説明したのです。」
ドメイン駆動設計
*Daisuke Okanohara@hillbig6月11日
問題を解くために使ってはいけない別の情報を使って”ずる”をするショートカット学習は動物でもみられ、現在のML/DLでも広くみられる。これによりMLは違う方向に汎化し、学習分布外(o.o.d)に外挿できない。実験結果の詳細な分析、o.o.d汎化のテスト実験が必要である。
https://arxiv.org/abs/2004.07780
*piqcy@icoxfog417
類似しているが未学習のデータに対し、過度に確信度高く予測するのを抑制する手法を比較した研究(性別を予測するモデルでは、学習時と年齢層を変えると確信度99%で12倍間違うというひどい結果になるという)。確信度のキャリブレーション(精度=確信度になるよう調整する)とアンサンブルを併用すると良い
引用ツイート
Andrej Karpathy
@karpathy· 6月21日
Important to be aware of & mitigate model calibration in real applications where thresholded outputs lead to diff behaviors. Good CVPR2020 paper on the topic: https://arxiv.org/abs/1804.03166
TLDR: use an ensemble of T-scaled models, distill if you can't afford the added inference latency
*「説明可能」を達成するには、理解、検証、納得、合意、に直接注目するよりも、「帰納的予測から示される、演繹的仮説構造提示性」に注目するとより良いのではないか。
どこかでNNとオントロジー(専門知識だったか知識グラフだったか)の接続云々と書いたが、「帰納からの演繹的仮説構造提示性」が高ければ、「オントロジーのような演繹」との接続は、より良くなるのではないか。
接続が良くなれば、理解や解釈の幹の部分は自動的に形成される。あとは枝葉を埋めれば良い。この順番で良いのではないだろうか。
演繹の幹を接続強化により適切に形成しその後に帰納用の分布、人の認識概念と一致する分布をまとう順番のイメージ、というか…
ふむう。自分が思う接続の順番と説明に必要な順番は逆となる。
帰納→演繹で接続し、演繹→帰納で説明する
なにか意味があるかな…
(この逆転は、生体における、
「目から入る画像を視神経で畳み込み特徴部分のみ脳に入れる接続」に対する、「脳が認識する画像は入力されたままの特徴のみつまり部分のみから成り立っているのではなく高解像度の全体として成り立っているように予測出力されている(脳が説明を受けている)」と似ているのではないかと思っている。
言い換えれば、
「データ駆動的にファクトベースで接続し、範囲の曖昧な演繹により非ファクトベースで認知し説明される」
ということ(わかりにくい)。
脳は目に入る画像をそのまま認識しているわけではなく補正している、ことは、よく知られていると思う。
たとえば、緑内障になり多少視野がかけても視野がかけた自覚は起きないし、誰もが持つ盲点は自覚的に見えることはないやろ?。
このことは、「(あえて)不完全な演繹により補正しているから」と表現できるのではないかと思う。
オントロジーなど専門知識(機能的に求められた演繹的仮説含む)は、この不完全な演繹の役割を果たすと思う。このオントロジーなどがあって初めて、認知は「幹を持って」完成するのだと思う。
疑似オントロジーを組み込んだ自作AIを1年以上使っているが、そう感じている。……順番の話はどこに行った。)
(接続ノードを知識における観点とするとシンプルに接続できるが、どうも幹ができていない感覚、というか、枝に幹を継いでいる感覚?、があり、違和感があるのよ…)(知識グラフをそのままモデルとして適用する間違い、ってやつかな?)(この部分に限らないが日本語無茶苦茶だな。確定していない頭の中のイメージを確定させないまま取りだす。難しい)(理解されやすくするために演じるゆるい演繹的な人間の類型化された外的側面のことをペルソナと呼ぶ https://ja.m.wikipedia.org/wiki/%E3%83%9A%E3%83%AB%E3%82%BD%E3%83%8A_(%E5%BF%83%E7%90%86%E5%AD%A6 偏見強化している気がしないでもない。)
(犬を見る→網膜から脳の間で畳み込みが起きもとの画像は失われる→脳では犬と予測する・脳が実際に認識しているのはdeepdreamのような混沌とした犬の画像?である→脳は犬との予測から犬の画像を再構成する→犬の画像が頭に浮かぶ。
この流れのことといった方が分かりやすいか。)https://distill.pub/2020/circuits/zoom-in/ )
*人の概念がありそれをモデルというプログラムに移し込み利用する。そうすることにより初めて認知の一致が成る。人の概念はプログラム自体とも一致させる必要がある。というかなんというか…。少なくとも精度再現率AUCなどシンプルな指標でモデルを選んでいては認知上不足することは確かだ…
*オントロジー、というかグラフによる表現可能性について、基礎を学ぶ必要がありそう。
*事前学習による検索者と結果の「認知のエッジ」の統一と、構造による演繹化から得られる「認知の幹」の形成、という2つの視点を持っている。
エッジばかりに注目してきたが、幹をもとに補正したほうが良さそう。
しばらく後者に視点を置きたい。
(endtoendが流行っているが、個人的にはよくわからないな。脳は誰もが持つが、公理など確定的な予測を生み出してきたのは巨人の肩と一部の脳だ。脳を作れば公理が得られるわけじゃない。endtoendで公理などを求めるには、情報豊富な多量のデータと、結論に至る道筋が適当な評価制約で妥当な少数に絞られること、が必要だろう。これら前提を揃えるより、巨人の肩といえる既知のオントロジーを組み込んだほうが実用に近づくと思う。基礎研究という面ではendtoendは面白いとは思うのだが。)(endtoendにオントロジーを組み込んだ場合、更新されないオントロジーでは意味がないので更新されるオントロジーを組み込む必要があるがその場合はendtoendとは言わないのではと思っていたが狭量だった気もする。)(「「どんな時に集合知が愚かなものとならないのか?」「集団のメンバーが相互に影響しないこと」.集団が各個人の持つ幅広い予想から意見を出せば賢明な答えになるのですが、何かのバイアスがかかった時、つまり互いが影響を与えたり外部の要因に影響されたりした時に、集合知は愚かなものとなってしまうのです。」)(endtoendでなく、工程に分け前処理を入れてしまうほど、情報を捨てすぎることになる、という意見もある。捨てるのではなくまとめるのであれば)
*「幹、オントロジーや知識グラフ」は「いわゆるIPランドスケープ」から持ってきても良いな。
鳥の目魚の目恣意的セグメント総合予測まで含めたIPランドスケープは、ヒトの知識の集合。これを利用してことこそ、「知財におけるヒトとAIの協働」ともいえよう。どう接続すべきか考えてみよう。
(過程で重要と言えた特許を教師に落とし込むこと、重要となるニーズや会社名(関連会社含む)などワードや重要となる分類をeswとすること、だけでも十分かもしれないが・・・IPランドスケープの結果を直接グラフに落とし込むには・・・ベイズでモデルを組み複数のワードから事後的に重要となりえる重要ワードのみを抽出する必要まであるだろうか?・・・予想される事件を組み込む必要が?そこまでの分析ができているか?)
*エビデンスがあることがプラスに働く。これはよい。しかし、エビデンスがないことが自動的にマイナスになるわけでも、マイナスにならないわけでもない。
これが、XORモデルも非XORモデルも重要である理由に思える。
(XORに違いがあるかどうかわからないが。)
*New work on explainable AI!
https://arxiv.org/abs/2006.14779
説明に人が依存する傾向?
*Discriminative Topic Mining via Category-Name Guided Text Embedding
https://arxiv.org/abs/1908.07162
*“Generalized Measures of Correlation for Asymmetry, Nonlinearity, and Beyond”: Some Antecedents on Causality
David E. Allen &Michael McAleer
https://doi.org/10.1080/01621459.2020.1768101
因果と相関について。
「非線形性、非対称性、時空間構造を足して拡張していくと相関は因果に限りなく近づく。因果と相関の区別は、世界を単純化して捉える人間の幻想か。」
帰納を最適に擬似演繹化すると因果に見える?
*Daichi__Konno
・従来ノイズとされてきた自発脳活動の大部分は脳の機能に極めて重要
・自発・誘発脳活動を区別せず扱うパラダイムが構築可能
と主張しているレビュー論文。
(神経科学における)「ノイズ」は理論や技術の進歩により「シグナル」となりうることを教えてくれる示唆的な内容。
https://cell.com/trends/cogniti
脳とニューラルが同一である必要はないが、脳からはニューラルをどう組むべきかにつき適当な示唆が得られると思っている。
*酒井 美里(202007)
「AI 系調査ツールとの付き合い方」に関する視点の提案
https://www.jstage.jst.go.jp/article/jkg/70/7/70_355/_pdf/-char/ja
「もし,AI の設計に欠陥があったために,本来は存在している先行例が発見できず,有効性判断が変わったとしたら,どうでしょうか?」という問いかけから講演は始まった。そして「たとえ,AI の設計に欠陥があったとしても,それを立証する事は容易ではないだろう」
・・・自分で作ればええのでは?
「AI を使うも使わないも,また,経験不足のサーチャーを使うのも,エキスパートに頼むのも,すべてはその時点で「最も合理的で有能な専門家」に調査を担当させた,と判断される。つまりは依頼側の責任なのだ。」
それはその通り。だからこそ、エキスパートだけでなくAIもつかうのさ。
「筆者は費用対効果が,AI 系調査ツール普及の第一のポイントと考えているのだが,果たして「年間を通じ,安定したコスト削減効果」が見込める使い方を想像できるだろうか?」
その通り。市販品は高すぎる。過去市販AIにおけるROIを計算したが、トントンがせいぜいであった。自作してさらに翻訳機能を付与して初めて、ROIは*となった。
「AI 系調査ツールもサブスク配信のレコメンド AI のように「定量的評価では説明の難しい,何らかの特徴」を持っていると実感している。」
そうですね。モデルの個性がどのようなものであるのか、いまだに理解できていないですが・・・
(モデルの個性差は実用において役立っているが、任意にコントロールするところまで行き着いていない・・・自分の知識・知恵不足が原因で・・・
うーん、どのモデルも結局は共起やろうし、「共起をその距離に応じ色を変えたグラフ」を作ってみれば何か示唆が得られるかな。
[自然言語処理/NLP] pyvisライブラリを使って共起ネットワークを簡単に描画してみる(SageMaker使用)
https://dev.classmethod.jp/articles/mrmo-20190930/
pyvisはhtml配布する際も便利そうね。networkxからこちらに切り替えるか。
・モデル個性につき共起ネットワークグラフ作成。
ううむ?.別のデータで再現を見る必要はあろうが,予想より個性的かな.
W+(w2v-mp): 1を固有ベクトル中心としたノードネットワーク形成。クラスタは1つのみ(ありふれている文章をとらえていると理解してもよいのだろうか・・・)。一つのノードから伸びているエッジの数が多く巡回していることが多い?(ノードを人に例えればフルコネクトで見落とし少なく頑固ということになるのか?。歪め統合しているので別の単語が同じ意味としてとらえられていることが多いだろう。もしかしたら歪め統合部分をみているのかもしれない。Jaccard係数で排除できるかな・・・)(固定図形面積が大きい構造と言える?頻出語と頻出語の組み合わせが強い?)(シンプルに考えると過学習気味と言いたいところだが,val_lossの上昇は見られない範囲であるしそもノイズが大きく過学習しにくいと思うのではあるが・・・いや,先日学習回数を増やしたが助詞を食いやすくなったかな?.SHAP highlightに変化は見られないようであったが・・・再確認しよう→確認.過学習の兆候は見られずSHAP highlightで助詞にハイライトが当たるようにもなっていなかった.このグラフで表示されている単語はすべてXOR(に限定する必要もないが)で除かれるのであろうな.硬いのは,様々な文章の混合で有りすぎるため助詞など一般的な単語しか浮かび上がらなかったということか?。これら単語を除去すれば、様々な文章からなることことを示す多くのクラスターが確認できるか?.)(クラスタ係数が大きいと表現できるのか)
B+(BERT): 1を固有ベクトル中心としたノードネットワーク形成。1と同じほどの次数中心性を持つ複数のノード(サブグラフ?)があり、多くが1のクラスタと接続している(「全体として文脈を形成しているといえる文章」をとらえていると理解してもよいのだろうか・・・。長距離作用のあるattentionの表れなのか? 共起が共起を呼ぶネットワーク構造をとっているのか? 媒介中心性が高いといったほうが良い?ノードを人に例えればキーマンがいるということになるが・・・。多少データ数が少ないからそう見えるだけ?。)。複数のノードは例えば眼、細胞、光など(理解はできる)。多くのノードが自己共起しているように見えなくもない(また、自己共起している単語は他と違い特徴的な単語となっているようだ。辞書として特徴的な単語が出現したとき重視し足しているだけとみなせば納得できるところではあるが。)(新聞記事ニュース欄と類似した構造?話題の単一性があるという意味かな?)
C+(keb-mp): 1を固有ベクトル中心としたノードネットワーク形成。複数のクラスタがあり、1のクラスタと接続していないクラスタも(特徴のある文章をとらえていると理解してもよいのだろうか・・・。局所性の表れなのか?)。複数のノードは例えば包装、軟骨、重量、など(なんでやねん→もしかしたら、独立項で製剤の文脈があるところ従属項で突然包装の記述が出てくるなど全体の文脈が破綻した状態を示しているのかも。違うか。この母集団においては製剤と包装が似た構造的位置に出現していたということか→個別確認したとことそのとおりのようであった。母集団まで勝手に拡張して正解候補としていることになる。母集団が全体としてある程度の重要性を示しているなら、汎化性能が高いということにもなるかな。製剤だけでなく包装も調べるという。これはノイズにもつながるが創造性にもつながると言えうる。BERTではできない部分だろう。)(ブログ記事と類似した構造?話題の単一性はあるけれど唐突に独立した話題や考察や発想も含むという意味かな?)
(こう見てゆくと信じられないが、それぞれのモデルは独自に9割は正答するし、SHAP highlightで妥当な単語にハイライトも付くのだよね・・・。BERTはXORを考慮しないからわかりやすく、w2v-mpとkeb-mpはXORで排除される頻出語が共起ネットワークでは現れてしまうからわかりにくい、ということか?。XORで削られていると思われる単語をSHAP highlitのマイナス評価から抽出して削ってしまうか・・・)
*後日、別データで再現をみた。ざっと同じようだが・・・
一見同じような構造でも、B+では単語「眼」に中心性があり中心単語に再現がある、C+ではそうではなく中心単語に再現はないようだ。(アルゴリズムから予想される通りで非常に面白い。他も同じく予想されるとおりであるとありがたい。)
B+のほうがC+より接続していないクラスタが多くなった。この大小には意味があるのだろうか。
W+については、一般的な単語がちりばめられているだけで、なぜこれでB+、C+と同等のスコアとなるのか理解に苦しむところ。まあサッカー概念と雨概念を一つの単語に畳み込むような歪め統合の操作をしているので、単語を見てわかるわけもないのではあるが・・・
W+C+B+共通。当然にスコア上位となることが多い。
もっとも納得がゆく単語、「点眼」「眼科」などが並んでいる。(当然に学習しやすいのだろう。どの個性のどのような解決手段をもってしても同じ結論に至る範囲、と考えたい。)
グラフ構造がW+に似ていることに意味があるのか・・・ (B+は単語そのものを、W+C+は(近距離の?)単語共起を、W+は単語共起の絡み合いの強さ、単語自体の影響力の強さを、・・・?)
モデルの個性が異なることは明確(基本的に、BERT-CNNの組み合わせも相性が良いのだろうな)。
問題は、どのような個性なのか、であるが、今回は、w2v-mpは上位概念、keb-mpは下位概念、とみなしておいてもよいかもしれない。BERTはもしかしたらattentionのリンクが連続した文章をより重要視しやすいのかも。w2v-mpとkeb-mpはより独立した(局所的な?)判断をしやすく、BERTはより連続した(長距離的な?)判断をしやすいのかも(BERTは学習の偏りの影響もあろうが)
(BERTでは連続性の一部を担う単語が表現上省略された場合、比較的容易に破綻するのかもなぁ。keb-mpなどはその省略による破綻を補っているのかも。
BERTは,連続が成立した場合にはkeb-mpなどが認識できない移動を伴うネットワーク、文脈といえばよいのか?、を読み取ることができ、keb-mpなどを補う。
これら双方により多様性評価の優位が成立している、とか?。)(1つのクラスタにまとまった単語群を見る限り、W+とC+では同一句の単語で共起しているように見え、B+ではそうとも限らないように見えなくもない。)
次は,共起単語同士の距離で色分けをして、短距離共起か長距離共起か確かめて・・・モデル間で共通する共起語を破壊した場合のモデルごとの影響力の差を確認することも面白そうだ。
(SHAP highlightにおいて重要とならないことが多い単語を抜いてみた。w2v-mpとkeb-mpは中心ノードが1から物に、BERTは中心ノードが1から眼に。全体の傾向は変わらない。)
(w2v-mpのノードには上位概念を表す単語しか出現しておらずさっぱり理解できない。さっぱり理解できないが、正解率はkeb-mpやBERTとほぼ同等でありヒト認知には一番近いのだよね。何に注目して正解しているのだろうか。歪め統合によりわからなくなっていると理解してよいのかな。分散表現上最も類似する単語も併記してみるか・・・)(KH-coderではうまく比較できなかった・・・)
(Pagerankの高い単語を探しても面白いかもしれない→)
共起単語間距離でエッジを色分け。ふむ良さそうだなでは検証しよう・・・
共起単語間距離では違いが見えにくかった。attentionは近距離にも効くし、ウインドウも長距離にも効くからそらそうか。傾向ぐらいはあるかと思ったのだが見えない。
次は、共起単語間の類似度でエッジの色分けをしてみるか。どの事前知識を用いて類似度を測るかに課題があるが。BERTは多分類似しない単語の共起が多いのではないかな。…いやトートロジーになるかこれ?
頻出組み合わせを除去してもあまり意味はないと思うが、Jaccard indexで足切りしてみるか?
*w2v-mp系がある程度強いブロック内近距離共起とブロック外の長距離共起を持ち、BERTは距離に依存しない強さの共起を示すとして、近距離共起の単語のみに着目し、モデル間の共通性を比較すれば?。
ううむ?
*共起関係とその頻度が大体つかめた。決定木に落とすとどのような知識が得られるか。。。
*BERTでは特徴となるべき単語が次数中心性高くかつ他クラスタとの橋渡しをしているように見える。他モデルでもその点が重要として、標準的な次数を計算しソートし、ポイントとなる単語としてみるか?
*シンプルに、ウインドウを使うモデルでは句が重視されるので巡回が多い、BERTで巡回が少ないのは句を重視できていないことがある、としてみると・・・
巡回している部分は近距離共起が多く・・・巡回していない部分は・・・
・・・うーむ、モデル間の差として、巡回の差以外は、重視した単語が異なる、ことしか見えない。もう少し何か見えれば評価指標も作れるのだが・・・
*語順が関係している?
*あるすべてのモデルが正答する文章に対し、仮説に基づいた変更を行い、その結果から評価する手法がある。これまでは仮説形成できておらずどうにもならなかったがそろそろ可能だろうか。
上位化下位化、特定の単語、距離語順、長さ、助詞、書かれることにより評価を下げるべき単語の存在XOR
、…
いや違うか。cnn系は教師データに依存した長距離共起は学習するがpretrainに依存した長距離共起は学習しない、BERTは教師データに依存した長距離共起は学習するかわからないがpretrainに依存した長距離共起は学習している、と場合分けして考えるべきか。長距離共起が教師データに基づくかどうか確かめればよいのか?
*栗林樹生
Language Models as an Alternative Evaluator of Word Order Hypotheses: A Case Study in Japanese.
*角田勝隆(2015)
ネットワーク型データモデルを用いた問題点の可視化と問題分析への応用例
https://www.juse.jp/sqip/symposium/archive/2015/day1/files/ronbun_A2-1.pdf
*異なる文体における共起ネットワーク図の図的解釈
https://www.jstage.jst.go.jp/article/jsgs/47/4/47_3/_pdf/-char/ja
*Knowledge Graphs in Natural Language Processing @ ACL 2020
https://towardsdatascience.com/knowledge-graphs-in-natural-language-processing-acl-2020-ebb1f0a6e0b1
知識グラフ研究まとめ
*佐藤有理 峯島宏次(2020)
論理の図形表現
認知科学2020
https://www.jstage.jst.go.jp/article/jcss/advpub/0/advpub_2020.020/_pdf/-char/ja
俯瞰.図的推論,トポロジー.空有感表現とグラフ表現(グラフ表現で上位概念下位概念を表現できるのか?).存在グラフの論理操作子として存在量化子と連語と否定(先に述べた助詞を演算子とする感覚と同じ?).発展形としての概念グラフ.特定の状況下における効率的な思考.認知における図的表現1世界モデルそのもの2統語論的構造(自分は1かな.現状は単語レベルの実装だからどちらでも同じだが).役割について,解釈効果と推論効果を分けて考える(自分は推論効果を利用するために・・・統語論的構造を考慮すべきなのか?).
*DeepMind Explores Deep RL for Brain and Behaviour Research
https://syncedreview.com/2020/07/10/deepmind-explores-deep-rl-for-brain-and-behaviour-research/
「ディープラーニングと強化学習RLが統合されると、それぞれが他方の動作の新しいパターンをトリガーし、ディープラーニングまたはRLのいずれにも見られない計算現象が発生します。 。チームはDeep RLが神経科学的研究に活用できると考える6つの領域を強調します。それは、表現学習、モデルベースのRL、記憶、探査、社会的認知、認知制御および行動階層です。」
Deep Reinforcement Learning and its Neuroscientific Implications
https://arxiv.org/pdf/2007.03750.pdf
ディープラーニングとベイズ(最適化)の統合でも同じことが言えるとしてよいのであろうか
*arXiv:2007.00810 (stat)
[Submitted on 1 Jul 2020 (v1), last revised 8 Jul 2020 (this version, v3)]
On Linear Identifiability of Learned Representations
Geoffrey Roeder, Luke Metz, Diederik P. Kingma
https://arxiv.org/abs/2007.00810
「このペーパーでは、非線形ICAの最近の進歩に基づいて、識別モデルの大規模なファミリが関数空間で線形不確定性まで実際に識別可能であることを示すことにより、識別可能性を回復させることを目指しています。」
*A mobile robotic chemist
https://www.nature.com/articles/s41586-020-2442-2
「化学実験室では自動化が進んでいるが、これまでは、ロボットアームと実験装置を連動させるために、特注の自動機器やインターフェースを必要とすることが多かった。
今回A Cooperたちは、自動車組み立てラインで見られるような移動ロボットを、人間と共に湿式化学実験室で動作するよう改良し、
人間の化学者と同じ機器を使えるようにできることを示している。
彼らは、ポリマー光触媒の性能の向上を目的として、このロボットをプログラムした。
このロボットは、8日間でバッチ化されたベイズ探索アルゴリズム16,17,18によって駆動された10変数の実験空間内で688回の実験を自律的に行い、最初の配合より活性が6倍高い光触媒混合物を見いだした。
このタスクは、人間が行えば数か月かかると思われる。
この方法は、実験機器ではなく研究者を自動化することによって、化学実験室において多くの応用を見いだすことができる可能性がある。」
アルゴリズム16は,
Taking the Human Out of the Loop: A Review of Bayesian Optimization
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7352306
ロボット本体が300万円ぐらいでオプション一式で1000万円ぐらい?.プログラムは公開されている.ベイズ最適化だけでなくさまざまな予測モデルを積むこともできるだろう.
ペイできそうかな・・・したら数年でテクニシャンは減るか・・・いや,精密な実験操作まではまだまだか?.
*Behavior- and Modality-General Representation of Confidence in Orbitofrontal Cortex
https://www.cell.com/cell/fulltext/S0092-8674(20)30617-6
入力経路によらず情報が抽象化されていき、「眼窩前頭皮質ニューロン」が信頼できるかどうか決めてるらしい。
ふむ。認知上参考となるかな。
*The dimensionality of neural representations for control
https://psyarxiv.com/asdq6/
「認知制御により、状況や目標に基づいて柔軟に考え、行動することができます。 認知的制御の理論の中心にあるのは、同じ入力がコンテキスト要因に応じて異なる出力を生成できるようにする制御表現です。 このレビューでは、制御表現のニューラルコードの重要なプロパティである、その表現の次元に焦点を当てます。
神経表現の次元は、神経計算における基本的な分離可能性/一般化可能性のトレードオフのバランスをとります。 このトレードオフが認知制御に与える影響について説明します。
次に、脳、特に前頭前野の制御表現の次元に関する現在の神経科学の所見を簡単に確認します。 最後に、未解決の質問と将来の研究のための重要な方向性を強調します。」
「低次の神経活動:パターンの一般化に優れる(次元削減)
高次の神経活動:パターンの分離に優れる(次元拡張)」
だそうな。
多様性をどの部分で発揮させるべきか、オントロジーをどう接続するべきかにおいて参考となるかな。
*Learning Distributed Representations of Sentences from Unlabelled Data
https://arxiv.org/abs/1602.03483
最終的に教師あり(文分類など)で使用するか、教師なしタスク(類似度判定など)で使用するかで適したモデルが異なるという結果、らしい
When Not to Choose the Best NLP Model
https://blog.floydhub.com/when-the-best-nlp-model-is-not-the-best-choice/amp/?__twitter_impression=true
*Biomedical and Clinical English Model Packages in the Stanza Python NLP Library
https://arxiv.org/abs/2007.14640
*公開されている学習済み BERT モデルについて, 分かち書き・サブワード分割・語彙構築アルゴリズムそれぞれどのアルゴリズムが採用されているかを表にまとめ
https://github.com/himkt/awesome-bert-japanese/blob/master/README.md
学習教材のいくらか
*A commitment to learning deepmind
https://deepmind.com/learning-resources
*CS 448B Visualization
https://magrawala.github.io/cs448b-wi20/
【JS/ Python両方OK!】「データ可視化」が歴史から実装まで体系的に学べるStanford講座の独習ノート
https://qiita.com/tomo_makes/items/4d69f347a5e49346df37
*萩原 正人(202007)
トップ会議 ACL 2020 から読み解く自然言語処理の最新トレンド
https://ja.stateofaiguides.com/20200720-acl2020-trends/amp/?__twitter_impression=true
「トレンド1. 事前学習言語モデル (PLM) の台頭と、少ないデータでの訓練
トレンド2. 指標至上主義からの脱却
トレンド3. 知識ベースとグラフ」
ふむ同じ感覚かな。同じような文献を見ていれば結果としてそりゃ同じような意見と思うであろうが。
これまでの「データセットにおける精度」が全てという分野の「当たり前」に疑問を投げかけ、「データセットではなく、タスクを解く」というメッセージを述べていました。
は素晴らしい。そのうえでどのように評価するか、についての情報が増えてくれると良い。
「ベストペーパーに選ばれたRibiero 氏 らの Beyond Accuracy: Behavioral Testing of NLP Models with CheckList という論文 では、これまでの「テストセット上での精度至上主義」とでも呼べる傾向に対して、「CheckList (チェックリスト)」と呼ばれる、NLP モデルの言語学的能力をテストする方法論、アプローチを提案しています。」
なるほどチェックリストか…チェック理スト最適化してしまいそうで怖いがまあタスク上は問題ないかな…。
「クラスの近さを考慮した Closeness Evaluation Measure (CEM) と呼ばれる評価指標を提案し、性能をより正確に測れるようにしています。」
*ACL2020オンライン読み会
https://exawizards.connpass.com/event/184582/
NLP分野における半教師あり学習および疑似データ学習法の最近の進展
https://www.slideshare.net/mobile/AkihiroFujii2/2020-0906-acl2020readingshared?utm_campaign=Weekly%20Kaggle%20News&utm_medium=email&utm_source=Revue%20newsletter
正解データ増は難しい。不完全データ利用。教師無しデータを利用、疑似データを作成し利用。task specific approach。CVT:教師も出ると教師無しモデルの結果が一致するよう。VAT:データからの結果と揺動データからの結果が一致するよう。
Language to Network: Conditional Parameter Adaptation with Natural Language Descriptions
Learning to Faithfully Rationalize by Construction
https://arxiv.org/abs/2005.00115
attention is not..., attention is not not...共著。予測根拠学習手法FRESH
(x, y)→(x_hat)→(x_hat, y)→?
少ない根拠で十分に説明可能?
SHAPと置き換えるべき??
説明性:faithfulness忠実、rationale根拠*後で直す
これまでの可視化は頑強でなく、忠実とも言い難い?
人で評価:sufficiency、con...
Beyond Accuracy: Behavioral Testing of NLP Models with CheckList
NLPモデル評価手法。accでなく多面的。
An Effectiveness Metric for Ordinal Classification: Formal Properties and Experimental Results
A Novel Cascade Binary Tagging Framework for Relational Triple Extraction
Rationalizing Medical Relation Prediction from Corpus-level Statistics
https://arxiv.org/abs/2005.00889
コーパスの統計情報を用いた問題予測手法。共起グラフを使う。
抽出的文書要約
Heterogeneous Graph Neural Networks for Extractive Document Summarization
知識と推論に基づいて⾔語で説明できる AI
説明可能AIは百家争鳴。
Attention Module is Not Only a Weight: Analyzing Transformers with Vector Norms
https://deepai.org/publication/attention-module-is-not-only-a-weight-analyzing-transformers-with-vector-norms
end2end(データがあれば+、高速+、暗黙-)、記号推論(演繹+、説明+、構造最適化-、同義表現-)、いいとこどりを目指したい。
自分もそう思う
*Language Models as an Alternative Evaluator of Word Order Hypotheses: A Case Study in Japanese
https://www.aclweb.org/anthology/2020.acl-main.47/
この研究は、その複雑で柔軟な語順のため、日本語に焦点を当てています。
自分は句構造重視しつつ語順非依存モデルに逃げていたがそろそろ?
*Theoretical Limitations of Self-Attention in Neural Sequence Models
https://arxiv.org/abs/1906.06755
Transformerが解けないタスクとその理論的な根拠。入力の長さに応じてレイヤーまたはヘッドの数が増加しない限り、周期的有限状態言語や階層構造をモデル化できないことを発見しました。
?
*The Illustrated Transformer
http://jalammar.github.io/illustrated-transformer/
これはわかりやすい。transformerは巨大な辞書と表現してよいのかなや。
*最先端自然言語処理ライブラリの最適な選択と有用な利用方法 / pycon-jp-2020
https://speakerdeck.com/taishii/pycon-jp-2020
https://github.com/taishi-i/toiro/tree/master/PyConJP2020
*Nina Poerner, Ulli Waltinger, Hinrich Schütze(201911)
E-BERT: Efficient-Yet-Effective Entity Embeddings for BERT
https://arxiv.org/abs/1911.03681
Wikipedia2Vecとグーグルの開発したBERTの2つの言語理解モデルをあわせて用いることで最先端のモデルの性能をこえるモデルを開発できることを示した研究。
これだよこれ(遅い)
*Exploring Self-attention for Image Recognition
https://arxiv.org/abs/2004.13621
画像CNNにselfattentionの考え方を導入。
これ更に自然言語に導入…て、201807ごろmicrosoftが提示した技術や自分が採用している技術とほぼ同じか?
*Multivariate patent analysis—Using chemometrics to analyze collections of chemical and pharmaceutical patents
Rickard Sjögren Kjell Stridh Tomas Skotare Johan Trygg
First published: 10 May 2018
https://doi.org/10.1002/cem.3041
潜在構造への直交射影(O-PLS)を使用?。教師は…面白げ。
*Deep Learning for Knowledge Graph Embeddings
https://cxlabs.sap.com/2020/08/31/deep-learning-for-knowledge-graph-embeddings/
知識グラフの利用。そろそろ。
*単語埋め込みと名詞句の共起グラフを用いた教師なしキーフレーズ抽出手法の提案
https://ipsj.ixsq.nii.ac.jp/ej/?action=pages_view_main&active_action=repository_view_main_item_detail&item_id=206564&item_no=1&page_id=13&block_id=8
「入力テキストに出現する名詞句間の共起と,各名詞句と入力テキストとの意味的類似度を基にエッジの重みを算出した重み付けグラフを構築し,グラフ内の名詞句に対し,TextRank を用いてキーフレーズらしさの値を算出する.」
*全世界のWebから知識を構築、グーグル超え目指すAI企業
スタンフォード大学のスタートアップ企業であるディフボットは、何十億ものWebページに対して画像認識と自然言語処理を適用して、巨大なナレッジグラフを構築している。尋ねられた質問のすべてに対し、事実に基づく受け答えができる人工知能(AI)を構築するのが目標だ。
https://www.technologyreview.jp/s/218809/this-know-it-all-ai-learns-by-reading-the-entire-web-nonstop/amp/?__twitter_impression=true
に、日本語版…
*構造を使うことが重要だとして、構造をそのまま学習に組み込むなら、多分ランダムフォレストが優秀なんだろうな。でもそのように情報を取り出すだけでは不十分やろう。知識グラフなどの構造を直接でなく組み込む手法の検討が重要なんだろうな。自分なら最後に組み込むけど。
*ダブルチェックの有効性を再考する
京都大学医学部附属病院 医療安全管理部部長 松村由美 平成30年度医療安全セミナー
https://kouseikyoku.mhlw.go.jp/shikoku/kenko_fukushi/000085434.pdf
*日本認知科学会第37回大会 JCSS2020
過剰な意味づけへの理論的アプローチ:ホモ・クオリタスとしての人間理解へ向けて
圏圏論による意味の理論化
高橋康介(中京大学),日高昇平(JAIST)
非常に共感する。共感するデータのみを無意識に集めて偏向しすぎたバイアスづくりしてるのじゃないかわしと思うほど。わかっているかは怪しいが。
ううーむ何が「良い」のかもゲシュタルト崩壊。差だけに注目し定義するしか?
「集合」でなく「群」を意識してもう少し数学的に考えたほうが良いのかもしれない。
1度目の学習結果を思い込みとして加え再学習し2回目の学習を行う直列接続は試す価値があるか。(現状、w2vkeb-mpは正解のみ足してしまったのでほぼすべてが正解となり意味なし状態。)
数値と意味がアンカリング効果に与える影響
大貫祐大郎 1, 2・本田秀仁 3・植田一博 1
数値と意味(単位)が同時に必要。
バイアスは無くすべきものではなく活用するべきものである、と思っているところ、興味深い。
基本的には、モデルの個性をどう評価すればよいか、モデルの評価の仕方、組み方、前処理をどこまでしてよいか、の参考とするために参加している。ついで、概念空間の作り方の参考として。
ACT-Rによる認知モデル??
https://ja.wikipedia.org/wiki/ACT-R
https://qiita.com/alfredplpl/items/c9aca3909b66a2ee5da3
認知に関する安定したモデルがない?知識グラフとして組み込める段階には至っていない?
年表が重要となりそう。
再現性問題は若手研究者の突破口
日本心理学会第84回大会シンポ山田
https://www.youtube.com/watch?v=JQd8kwtJu2o
*ヒトがどのように文章を認識するか、ここが文章の個性の答えの究極のはず。
認識されているオブジェクトは、
単語、単語の出現数、単語周辺のn-gram、単語から離れた長距離attention、(距離非依存の?明確な共起)、単語群から形成される文の文脈、単語の意味と文脈の基礎となるヒトの事前知識、ヒトの認知の事前確率影響によるブレ、品詞ごとの出現頻度、特徴的なトピックに縮約した因子、同一単語の意味の差、各単語の意味の先鋭性、文脈の意味の先鋭性、上位概念下位概念、意味の解像度、
各モデルの説明から得られた重要単語に注目した分析、、
・・・
これらオブジェクトのどれが、またはどの組み合わせが、モデルの個性を説明しやすいといえるのか・・・適度に要約してインサイトにつなげる説明、細かく要約して演繹化する説明・・・
共起と距離においてモデル間差がみられるとして、次は意味をどのように乗せ、上位概念や下位概念の証明などしつつ、モデル個性差を創造性など利用してゆくか・・・
*錯覚が起きているのは脳ではなく、目の「網膜」だと判明!(202006)
https://nazology.net/archives/63082
Mechanisms underlying simultaneous brightness contrast: Early and innate
https://www.sciencedirect.com/science/article/abs/pii/S0042698920300730
CNN畳み込み部分??
Perception, Cognition, and Action in Hyperspaces: Implications on Brain Plasticity, Learning, and Cognition
https://www.frontiersin.org/articles/10.3389/fpsyg.2019.03000/full
*Attention Module is Not Only a Weight: Analyzing Transformers with Vector Norms
https://arxiv.org/abs/2004.10102
(1)BERTのアテンションモジュールが特別なトークンにそれほど注意を払っていない
(2)Transformerのアテンションモジュールが単語の配置を非常によくキャプチャしている
*「自然言語処理の未来」HuggingFace 主席サイエンティストが語る NLP の最新トレンド(202009)
https://ja.stateofaiguides.com/20200914-future-of-nlp/amp/?__twitter_impression=true
指数関数的に増えるモデルサイズ
事前学習モデルのサイズ削減
指数関数的に増えるデータ量
ドメイン内 vs ドメイン外汎化
自然言語推論 (NLI) の限界と、自然言語生成 (NLG) の勃興
頑健性の欠如
モデルは、本当に言語を理解しているか?
自然言語処理は「常識」を扱えるか?
事前学習モデルの進化は、2018年で止まってしまうか?
「現実世界のデータセットでモデルがどのぐらいうまく動くか知りたければ、テストセットにおける性能はまったくアテにならないと言えるでしょう。」
実データで試している人は皆わかっているし、その先に進…もうとしている。
「モデルの汎化能力を測る上で重要な概念に**「合成性」**があります。合成性とは、例えば文やフレーズ(例:「自然言語処理」)の意味が、その構成要素の意味(例:「自然+言語→自然言語」、「自然言語+処理→自然言語処理」)から合成して予測できる性質を表す言語学の概念です。この合成性に関して、SCAN と PCFG SET の2つのタスク・論文が発表されています。」
使っていたが合成性と呼ぶのか。
Convs2sとtransformerの過汎化 (赤色) 丸暗記 (青色) グラフ、なるほど経験上でもそんな感じだ。
Conv2sについては先のMechanisms underlying simultaneous brightness contrast: Early and innateと合わせて妄想すると面白いな。構造から発生する錯覚こそ必要としている汎化なのかも(構造と創造性についてはどこかに記載した気がする)。CNN類似構造をモデルの個性として採用することは重要なのかも?。上記モデルごとのネットワーク構造の違いからしてもCNN類似構造モデルは個性を作りやすいようである。
https://arxiv.org/abs/1908.08351
BERTの頑強性は低い?。それほど低い印象ではなかったが…過学習しておかしくない入力手法を採用していたためであろうか。
*メタ学習:学習の仕方を学習する、MAMLやNeural Process
PFN岡野原氏によるAI解説:第42回(2018)
https://xtech.nikkei.com/atcl/nxt/mag/rob/18/00007/00009/
良い記事だな、と思ったらまた岡野原さんだった。
*ある2つの同じことを表現している条文があるとする。
一つは大陸法基準で書かれており、曖昧に概念の外枠を満たすように書かれている。1つは英米法基準で書かれており、具体的であり概念の穴は衡平法が満たすように書かれている。この2つは同じことを表現していても、単語も文体も全く異なるため、単語の同一性などありふれた手法では類似判断がし難いものとなっている。自分が言う解像度の違いとはこの違いを含む。
さて、解像度の異なる文章の類似度を適切に判断したい。
前者では、散らばったベクトルを合計して、文章ベクトルを作ることになるだろう。後者では、ある程度方向が揃ったベクトルを合計し、それに衡平法のベクトルを足して、文章ベクトルを作ることになるだろう。
手法は統一したい。
となると、衡平法のベクトルの強度を増減させる対応が良いだろう。
さて…これをどう実装するか…
衡平法のベクトルはトピックのベクトルに置き換えるとして、強度をどう求めるか。
文章の曖昧さを求めるアルゴリズムが必要かな…tfidfでも上位概念下位概念を切り分けられそうであったしWとCの個性の違いでも上位概念下位概念を切り分けられそうではあるが…
*特許出願技術動向調査報告書の自動更新に向けて
Towards Automatic Update of Patent Application Technical Trend Survey
難波英嗣
http://nlp.indsys.chuo-u.ac.jp/pdf/2020/nanba_jsai2020.pdf
「なお、筆者らは、現在「知財工学会」を設立中である。これは、知財活動に関する方法論を情報学等の工学的観点から議論できる場を提供することを目的とした学会である。」
知財工学会。ぜひ参加したいものだ・・
*stanfordの講義が終わったら全体を見直し、全体を説明できる仮説を作ったあと、これだ、という文献から詳細に読見直してみよう。
*独学大全購入。
https://www.diamond.co.jp/book/9784478108536.html
二重過程論。システム1の環境依存性の強さや脆弱性、システム1に対するシステム2の弱さ、生得的な認知と言えるシステム1だけでは解決できない問題を解くためのシステム2(巨人の肩にのった知識構造生成?メタ?)を意識して、メタ学習やグラフの組み込み、スイッチ、組み込むべきグラフとは何か、を考え直してみるかな。
システム1はモデルのアルゴリズムや事前学習(長期記憶)、重要な特徴・情報制御、
システム2は事前学習や構造そしてグラフ組み込み、重要に見えない(目立たない?)特徴・情報制御だとして…
グラフはシステム1か?。システム2はcheck system関連、環境制御関連かな。グラフは知識グラフと構造グラフ(知識グラフ生成グラフ)の2つに大別するべきか。
最近、重要でないように見える特徴を予想よりもより重視すべきなのだろう、と考えている。(重要に見えない特徴を重要と評価することは非常に困難であり頭が痛い。wは何故、cやbと同等スコアになるのだろう…。重要に見える直接的な「特徴」ではなく重要にも見えない間接的な「構造」がポイントであるように思えなくもないのだが)
アイディア大全しかり問題解決大全しかり独学大全しかり、モデルの構築にヒントを与えると思う。これらのようなサーベイ?が日本語のみで出版されている点は、どのようなモデルを組むかにおいて海外より優位になる源泉となり得るのではないかなと思うところ。
*Baseline Needs More Love: On Simple Word-Embedding-Based Models and Associated Pooling Mechanisms
https://arxiv.org/abs/1805.09843
wとcはSWEM-hierと類似している(いつも思うのだが、自分が思いつく程度のことは誰でも思いつくよね。)。SWEMはどこかのライブラリで採用されたと聞いたことがあるがどれであったか。WとCの個性はSWEMの現状から得られるか?
FLAIRを使ってSWEMによる文章埋め込みを計算する
https://yag-ays.github.io/project/swem_flair/?utm_campaign=piqcy&utm_medium=email&utm_source=Revue%20newsletter
年々便利となるなぁ。ライブラリを用いてコードを書き直せばかなり短くできそうバージョンアップに伴う修正が必要となる場合があるから悩みどころであるが。
*次元圧縮を用いたメタ構造の生成
*An Attention Free Transformer
https://openreview.net/forum?id=pW--cu2FCHY
attentionを積商畳込みで置き換えし高性能。まあそうだよねぇ。最近この示唆が多いな。
*小川雄太郎(201911)
BlackBoxモデルの説明性・解釈性技術の実装
https://www.slideshare.net/mobile/DeepLearningLab/blackbox-198324328
ほうほう。日本語テキスト説明性技術として、Influence?
SHAPは未実装か…
*Self-supervised Learning: Generative or Contrastive
https://arxiv.org/abs/2006.08218
自己教師サーベイ
*Understanding Human Intelligence through Human Limitations
Thomas L. Griffiths
Published:October 08, 2020
https://www.cell.com/trends/cognitive-sciences/fulltext/S1364-6613(20)30215-1
人間の限られた認知こそが迅速な学習や問題を部分に分解する機能などの有利な効果を示しうる構造を生んでおり、機械がその構造をとり入れることは人の理解にもつながるという内容?
今更だが、構造は固定してよいのだろうか?。適用範囲内において固定して良いと思うが…
「これらの問題の解決策には、ベイズ推定やメタ学習、合理的なメタ推論、分散アルゴリズムなどの数学的形式が含まれます。これらは特に認知科学に関連している可能性があります。」
ふむふむ。
あ、最近やっとベイジアンネットワークのライブラリで使いやすそうなものpgmpyを見つけたよ。最初のリリースは201905?。
構造抽出もできるのか。試してみよう。
*対義語対の差分ベクトルを使用した評価極性辞書の拡張
https://anlp.jp/proceedings/annual_meeting/2019/pdf_dir/P7-24.pdf
反意語文脈的相違は学習されているが見。反意語を強調するため全体にレトロフィッティング?を行うと歪んでしまう?
*個性表現のため、階層ベイズにつき再学習中…
*単語を分布として理解したい、文章は分布の1形態に過ぎない、助詞は分布に対し働く演算子である、という仮定を好む立場からすると、
階層ベイズで全体を組み、分布の重なりやKLで、文章感の類似や意味の違いや認知の違いを表現できたら良いと思うところ。
(disentangleされた分散表現がそれだと言われるとそうかもよくわからないと答えるしか)
*分散表現において低頻出語が適切な位置に配置されにくいことはわかっておりこれに対処するため歪め統合では偏ったコーパスのみを使っていたのだが、その場合は語彙が不足し未知語処理ばかりすることになる。双方上位概念化の方向にすすむ。w2v-mpが上位概念を捉えているように見えるのはそのためかもしれない。(それはそれで価値があるのだが目的とは異なる)
分布化でなんとかならないかと思っているのだが…
(なお、分散表現を求めるコーパスに、コーパスの単語を細切れにしたものを加えれば、多少の語彙不足は解消できるかなとも思っている。)
*根拠があると良い。根拠がないと駄目というわけではない。その統合がメタ学習だと考えている。
(根拠があれば精度が高いが範囲が狭く頭打ち。根拠がなければ広いが精度は出ない。根拠がないとは認知できないだけという可能性を含む。混合が重要という感覚で。) (疑似相関の影響を低減させる部分がメタ学習の特徴と言ってよいのか?)
*単語分割の多様化による教師増幅を試してみること。分散表現作成前のコーパスに対しても。低頻出語が適切な部分に配置されやすくなるかも。
→chiVeでやられてましたね。有効そう。
日本語単語ベクトル"chiVe"をgensimやMagnitudeで使う
https://zenn.dev/sorami/articles/fb2eb78e250568b767fd
聞いていたはずだが意義を理解しておらず記憶に残らなかったようだ。
Magnitudeは…自前の未知語処理がまずまずのようなので当面は良いかな。
*ついでにベイズ的最適化を使い分散表現学習時の最適化をしてみるか。
次元は統一するとして、文脈幅とNegative sampling、Negative sampling分布、学習率か…
Gridsearchより性能が良いというがどうかな?。情報基盤センターだったか?
ライブラリはBayesianOptimizationで良いか?
*構造とグラフニューラルネットワークとの接続による効果を再検討してみること。BNの結果を重みまたはベクトルに一部として追加すればどうか。
*mT5: A massively multilingual pre-trained text-to-text transformer
https://arxiv.org/abs/2010.11934
https://github.com/google-research/multilingual-t5
多言語のMBertを試そうかと考えていたら多言語のmT5だと!!
マルチリンガルの流れは止まらないのかドメインはどこに
マルチリンガルという成果はend2endによりもたらされたとのこと。
*MBertによる日本語要約を試してみた。
請求項すべての要約をさせたら、「請求項1の本文+請求項1に含まれる上位概念用語の下位概念単語例示」となるように要約された。
ちょっと真面目に検証してみよう。
mT5も期待できそうか(text = "paraphrase: " + sentence + " " で言い換え、上記でいう「解像度変換」もできる?)
*未知語や特定の単語を、知識グラフから検索し、畳込み、歪め統合を強化するなどありやな。解像度の変換にも使えるなこれは。シンプルな確率モデルより頻度をあえて落とすという点でも有効かも。どのような知識グラフを作っておくかが問題だが、tfidf embeddings /cluster visに対して構造決定を行ったらどうなるかな?。
*自分はある単語の分布は複数の峰を持ち距離やcos類似度だけでは測れないと思っている。現在の歪め統合は歪めきれておらず弱い。補正しているが根本的な解決ではないだろう。幹を階層ベイズか構造付与か何かで表現できないものか。分散表現作成に用いたコーパスから構造を取り出しグラフ畳み込みを行ってみるか?。分散表現を合成することも多重にすることもできるが…
峰を近づけるようなベイズ最適化もあり得るがパラメータの問題なのかな?
*JDreamSR
https://jdream3.com/lp/jdream_sr/
文章検索から表への構造化まで一気に。
固有表現抽出と類似性とオントロジーの組み合わせでかなりドメイン特異的?。個人的には大好きだなこれ。他ドメインに適用するにはオントロジー部分の組み換え(自動学習?
)と固有表現抽出部分の学習し直しが必要なのかな?
*Knowledge Enhanced Contextual Word Representations
https://arxiv.org/abs/1909.04164
http://hazyresearch.stanford.edu/bootleg/
BERTに構造、知識グラフを組み込む研究。
ふむふむ…
*How Neural Networks Extrapolate: From Feedforward to Graph Neural Networks
https://arxiv.org/abs/2009.11848
グラフニューラルネットワークによる分布外予測の可能性
*プロジェクトとプログラムのリスクマネジメントにおける機械学習と知識創造の統合アプローチ
Machine-in-the-loop(機械参加型)知識創造プロセスの提案
https://www.jstage.jst.go.jp/article/iappmjour/14/1/14_415/_pdf/-char/ja
*Graph-based Topic Extraction from Vector Embeddings of Text Documents: Application to a Corpus of News Articles
https://deepai.org/publication/graph-based-topic-extraction-from-vector-embeddings-of-text-documents-application-to-a-corpus-of-news-articles
*目的とアルゴリズムが重要なのであって、手段はその場合場合で使えるうちで最適なものを使えば良い。手段に目的が拘束されてはいけない。
というごく当たり前のことを提示した論文があったはずだがどれであったか。
*「自然言語処理の未来」HuggingFace 主席サイエンティストが語る NLP の最新トレンド
萩原 正人 - 14 9月 2020
https://www.google.com/amp/s/ja.stateofaiguides.com/20200914-future-of-nlp/amp/
「上記のような帰納バイアスをモデルに組み込む方法もいくつか提案されています。Marcheggiani 氏らの論文では、入力文の言語学的情報(述語項構造)をグラフ畳み込みネットワークにより取り入れたニューラル機械翻訳モデルを提案しています。また、Strubel 氏らの論文で提案された意味役割付与のタスクを解くモデルでは、マルチタスク学習の仕組みにより言語学的な情報を取り入れた自己注意機構を使っていす (ちなみに同論文は、EMNLP 2018 のベストペーパー賞に輝いています)。一方で、言語学的な知識(述語項構造)を考慮したデータ拡張手法を使うことも可能です。」
*Pioneering NLP Research Examines Representation in Texas Textbooks
https://www.ischool.berkeley.edu/news/2020/pioneering-nlp-research-examines-representation-texas-textbooks
バイアスの調査。
*泥臭いが、事前知識のバイアスとモデル個性のバイアスを、品詞分布などで調査し、頑強性があるかどうか示したほうが良いかな。同じ教師を与えた学習方針があるわけがないモデルの個性がそのような差として現れるわけがないもう少しランダムだと思っていたのだが、結果を見てゆく限り、どうもそうでもなさそう。
*教師なしでも文脈考慮自体はできる。任意の文脈考慮が重いモデルを利用せずともできるようになることが重要でないのかとも思う。
キーワード検索、全体概念検索、attention個別概念検索(軽い任意の文脈考慮。次代の共起利用?。事前学習と知識グラフ双方を考えたときには少々トートロジー気味。)、この3つの考慮が重要でないだろうか。tfidf embeddings/cluster visにとりあえず実装。
*Underspecification Presents Challenges for Credibility in Modern Machine Learning
https://arxiv.org/abs/2011.03395
Underspecification対策として、構造とドメイン限定が非常に重要だと思っている。
(同じ答えを出すにあたり複数の解法が存在する場合であり、正当な解法がある場合であるならば、その解法となるように教師し導く必要がある。と考えていることは上記記載しているとおり)
*A Combinatorial Perspective on Transfer Learning
https://arxiv.org/abs/2010.12268
個々のニューロンをモジュールとして考え、それらのアンサンブルによる継続学習手法NCTLの提案、とのこと
*SBERT-WK: A Sentence Embedding Method by Dissecting BERT-based Word Models
https://arxiv.org/abs/2002.06652
https://ai-scholar.tech/articles/natural-language-processing/sbert-wk
「オリジナルの BERT の CLS トークンや平均を文ベクトルとして cosine 類似度を計算した場合のスコアは、静的な単語埋め込み表現である GloVe のベクトルの文単位の平均を取ったものよりも低いことがわかります。ここから、BERT のオリジナルのベクトルは文の類似度を判定するには向いていないということがわかります。」
「SBERT-WK の改良における重要なポイントは「BERT の各層はそれぞれ異なる言語学的情報を捉えている」ということです。」
「BERT の層はそれぞれ異なる情報を捉えていること、中間層の表現は転移学習に用いるには有用であること、後半に行くにつれてより高次元の意味的な情報を捉えていること」
https://www.aclweb.org/anthology/P19-1356/
https://www.aclweb.org/anthology/N19-1112/
「文中の全ての単語の層間での分散の合計」のうちの、「その単語の分散が占める割合」を重みとしています。これによって、より豊富な情報を持つと思われる分散の大きな単語に対して、より大きな重みを割り当てることが可能になります。」
うーん?fine tuningに対してとあるが ドメイン限定して初めて価値が生まれそうな気もするが…
*バンデットアルゴリズム
探索と活用のトレードオフが、イノベーションからみた開発の不誠実さと開発から見たイノベーションの不誠実さのジレンマと対応しているようで面白い。
ジレンマやトレードオフに対応するため、イノベーションにも因果探索推論のアルゴリズムを導入すべきなんかな人任せではなく。
*強化学習のような全体最適化手法は事件に弱いため、近視的な部分最適化手法で補わないと事件が必ず起きる実世界では実効性がない気がする。
CNNとtransformerの組み合わせが良い結果を生みやすいようであることと似ているかな?
*データ分析結果は結局のところ恣意的にまとまるものだと思う。本質的には機械がやろうが人がやろうが価値は変わらない。現実そうでない理由は、恣意的なストーリーを形成できるかどうかにあると思う。この点を人の利点と見るか機械が解決すべき課題と見るか。個人的には機械でもストーリー形成は可能だと思う。
ストーリー形成は確率モデルではできないかなとも思う。局所構造をある程度ランダムに緩い因果で組み合わせるモデルが良いかなと思う。ベイズ最適化を組み合わせに使うとよいのかな。
*When Do We Trust AI’s Recommendations More Than People’s?
https://hbr.org/amp/2020/10/when-do-we-trust-ais-recommendations-more-than-peoples?__twitter_impression=true
著名AI研究者は「辞職した」とするグーグルの言い分に従業員らが反論
https://www.axion.zone/dr-timnit-gebru/
GoogleのAI倫理研究者解雇は「不都合な真実」を隠蔽したいがためか?
https://japan.cnet.com/article/35163499/
Setting the Record Straight
https://googlewalkout.medium.com/setting-the-record-straight-isupporttimnit-believeblackwomen-5d7bbfe4ed90
モデルの多様性
BERTなどは学習内容にもよると思うが偏っていると思うよ。その偏りはBERT単独では使えないと思わせてくれるほどに。まあlargeモデルは使えないので全体の検証はできないのだが。
この記事の論文ってどれだ?
“On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?”
かな?
We read the paper that forced Timnit Gebru out of Google. Here’s what it says.
https://www.technologyreview.com/2020/12/04/1013294/google-ai-ethics-research-paper-forced-out-timnit-gebru/amp/?__twitter_impression=true
*書かれていることから推測しない力と書かれていることから推測する力は双方必要で切り替えなければいけないが、その切り替えすべき場合の切り分けと切り替えが適切にできやせんことが問題でもあり価値でもあるだろうところが難しいところと思う。
このあたりが、ここ最近のいわゆる人工知能研究におけるテーマなのかなと勝手に思っている。
*parallel linguistic meaning? 並行言語的意味? 言い換え?
この2年自分が興味を持ってきたものはこれにかかわる?
Heroes of NLP: Kathleen McKeown
https://www.youtube.com/watch?v=DffGdrfY9gI
Extracting Paraphrases from a Parallel Corpus
http://www.cs.columbia.edu/~kapil/documents/candidacy_papers/barzilay01.pdf
T5などのencoder-decoderモデル?は、自分が求めてきた解像度変換(複数単語群とそれと異なる単語群の言いかえ)をしている(1次元分の入力から、複数次元分の生成をしている)。(mbartも?)。こちらを試してゆきたい。
Heroes of NLP: Quoc Le
https://www.youtube.com/watch?v=KGI7K_ehHsU
transformer
Heroes of NLP: Chris Manning
https://www.youtube.com/watch?v=H343JRrncfc&list=PLkDaE6sCZn6Hmo-Hbqp00dRCrDcOV5AYr
チョムスキー。人は多分データのみから言語を学ぶことはできない。頭の中に機械が必要。
自分は「構造」または「概念」と呼んでいる。考え方は同じことと理解してでよいのかな?。
自分はエキスパートシステムなどで構造や概念は外部導入する必要があると考えているが、そこはどうなのだろう、どのような技術があり歴史があるのだろう。attentionは構造や概念を与える、と考えることもできるか。恣意的でない方法で(恣意的にもできるけれど)(いやこれは都合よくあてはめすぎだな)
構文にあまり注意を払わずデーター重視とすることが解決法であった。
自分は構文は構造・概念になると考えていない。どこまでいっても単語もしくは文章の概念から出来上がる構造が重要なのであって、構文は主体でないと考えている。意味が数値で、構文は数値を「より正しく導き得る演算子」である。構造は数値から形成される、と考えている。
BERTの10万倍のような巨大化、GPT-3のような巨大化は、資源の問題で?これ以上続くことができない。
*文法とは分布を持つ結果であって唯一の理由ではないのだから、品詞、係り受けの予測が100%になる必要はないと思う。・・・どんな分布なのだろう。
文法とは構造の一つなので、構造も本質的には分布で与えられるべき。・・・かな?。切り分けできないと認めて一点を与える方法もあるし、個性に合わせるにはそちらのほうが合いやすい・・・ 階層ベイズのように隠れ因子と分布を想定して個性を・・・合わせたい個性の主要テキストから個の分布は求められるか・・・?
とりあえず今作ったn-gramの確率モデルを使って個性単語を抽出してみて任意にそれぞれの個性単語の適用確率を設定してみてそれを構造とみなして生成時に割り込みをかければ・・・
(例えば、n-gramの確率モデル芥川調の語尾と主語が見つかるとする、任意に語尾と主語の適用確率を設定しこれを個性構造モデルとする、生成時に割り込み適用させる、・・・fine-tuningより任意にコントロールできる利点はあるが、・・・生成後の文章にn-gramの確率モデルによる修正又は評価をかけて・・・GANか・・・。)
*Style Transformer: Unpaired Text Style Transfer without Disentangled Latent Representation
https://arxiv.org/abs/1905.05621
「潜在空間の内容とスタイルを分離することは、不対のテキストスタイル転送では一般的である。しかし、現在のニューラルモデルの多くは、以下の2つの大きな問題を抱えている。
- 文章の意味論から文体情報を完全に取り除くことは困難である。
- 潜在表現を介したリカレントニューラルネットワーク(RNN)ベースのエンコーダーとデコーダーでは 長期的に依存しているため、結果的に貧弱な 非スタイル的な意味的内容の保存を目的としている。」
文脈を考慮しすぎない、認知を切り分けた、単語ベースのスタイル変換により、文体情報を取り除くという効果を狙う、という解釈もありかなぁ。スタイルはそのスタイルを含むコーパスを利用したn-gram確率モデルをもちいれば、足して変換できるはず・・・DLAIへの確認は済んだし実装するか。多言語モデルend2denで実装したほうが応用範囲は大きそうではあるが。
*The Future of Natural Language Processing
HuggingFace 202004
https://www.youtube.com/watch?v=G5lmya6eKtc&t=44s
0:00:06 自然言語処理の未来
0:00:19 未解決の質問、現在の傾向、制限
0:00:37 指数関数的に大きなモデル
0:00:43 モデルサイズと計算効率
0:04:07 再トレーニングされたモデルのサイズを縮小する
0:13:57 指数関数的に多くのデータ
0:14:05 ますます多くのデータを使用する
0:17:51 より多くのデータの事前トレーニング
0:24:39 より多くのデータの微調整
0:27:49 より多くのデータまたはより良いモデル
0:31:02 ドメイン外の一般化
0:31:14 ドメイン内とドメイン外の一般化
0:38:46 NLUの限界とNLGの台頭
0:44:31 根本的な欠陥:堅牢性の欠如
0:44:44 堅牢性の欠如
0:46:09 堅牢性の欠如に対する解決策
0:49:03 レポートと評価の問題
0:51:14 誘導バイアスの質問
0:56:37 常識的な質問
0:56:44 常識的な質問
1:01:45 継続的な学習の質問
1:02:08 継続的およびメタ学習
*エンコード後の概念はすべてオノマトペにしてしまえばよいのだ…
私は固有名詞Aと考えています→encoder→モヤモヤビシビシ→decoder→私はこれについて理解していません
説明可能性が高い究極の翻訳だな
*スタイル・文体の類似性を考慮した、インサイト用文章校正・生成モデルの検討
https://qiita.com/kzuzuo/items/b6875441d7103ee515c1
自作AIでみられたモデルの個性の理解をすすめるにあたり、「文章のどの部分がその個性に特徴的であるといえるのか確かめるための単純な理解可能なモデル」が欲しかった。また、個性に基づいた文章生成を行い、モデルの個性を比較したかった。
*BERTs of a feather do not generalize together: Large variability in generalization across models with similar test set performance
https://arxiv.org/abs/1911.02969
文法理解において精度に大きな差異
*IPRally
https://www.iprally.com/
知識グラフベースの特許検索
深層学習に対し知識グラフの結果を加えて?精度を上げているようだ。
1 起草時考慮知識をもとにした知識グラフ
2 審査履歴
3 1、2を加えた深層学習
知識の組み込みというトレンド通り?。
知識グラフから外れた部分がどうなるか気になるが精度は高いだろうな。
要素を考慮するので先行技術調査、権利化可能性調査に強そう。また、構成要素を任意に区切る手法より漏れも少なそう。google sigma similarがこれだったら…
*Patent prior art search using deep learning language model
Proceedings of the 24th Symposium on International Database Engineering & ApplicationsAugust 2020
https://dl.acm.org/doi/10.1145/3410566.3410597
BERT使用した先行技術調査。recall value of up to '94.29%。そんなものだと思うよ。
*Three mysteries in deep learning: Ensemble, knowledge distillation, and self-distillation
https://www.microsoft.com/en-us/research/blog/three-mysteries-in-deep-learning-ensemble-knowledge-distillation-and-self-distillation/
MicrosoftResearchブログ
ディープラーニングの3つの謎:アンサンブル、知識蒸留、自己蒸留
公開 2021年1月19日
純粋にランダム化から生じたトレーニングプロセス中のニューラルネットワークの不一致の研究
アンサンブル なぜ出力後であると向上?
知識蒸留 アンサンブルの出力に一致するように別の個別モデルをトレーニングする 小サイズのモデルでなぜアンサンブルに匹敵?(個々のモデルでは得難かった構造でありアンサンブルして得られた構造を写し取っている?)
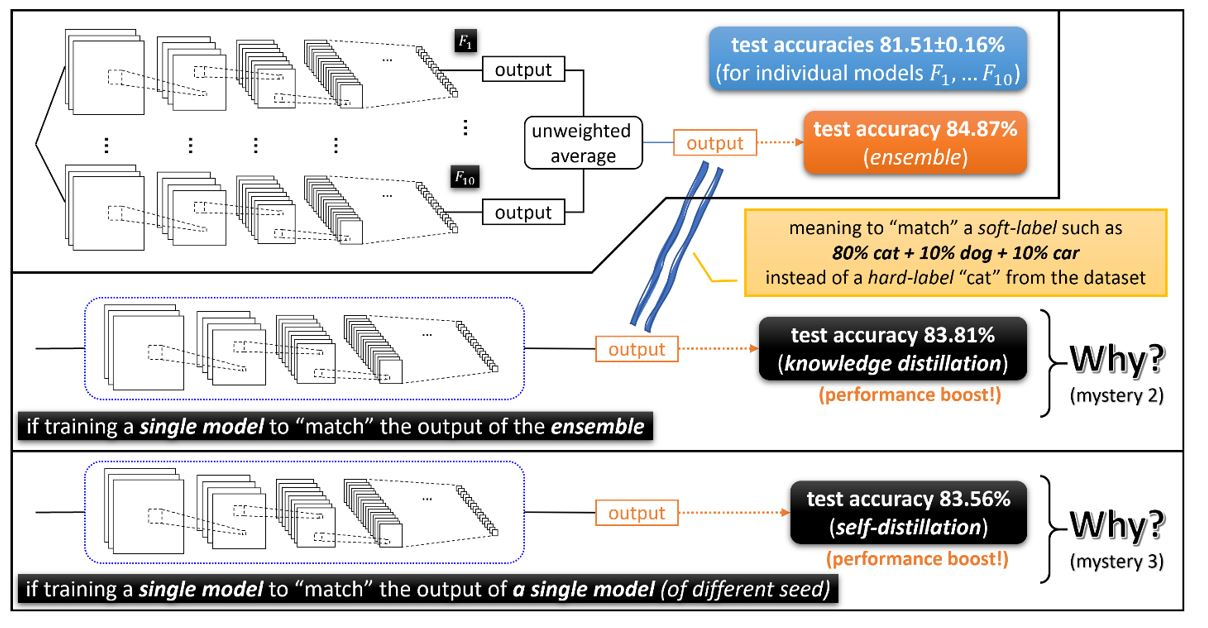
自己蒸留 なぜ教師として自分自身を使用して同じモデルを再度トレーニングすると向上?(各モデルの出力は理想的で現実的ではない01でなく現実的な連続値であり、それを再学習に使うため?)
同じアーキテクチャを用いたモデル間でも成り立つ。違いは、トレーニング中のランダム性? だが深層学習ではそれだけとは言えない?
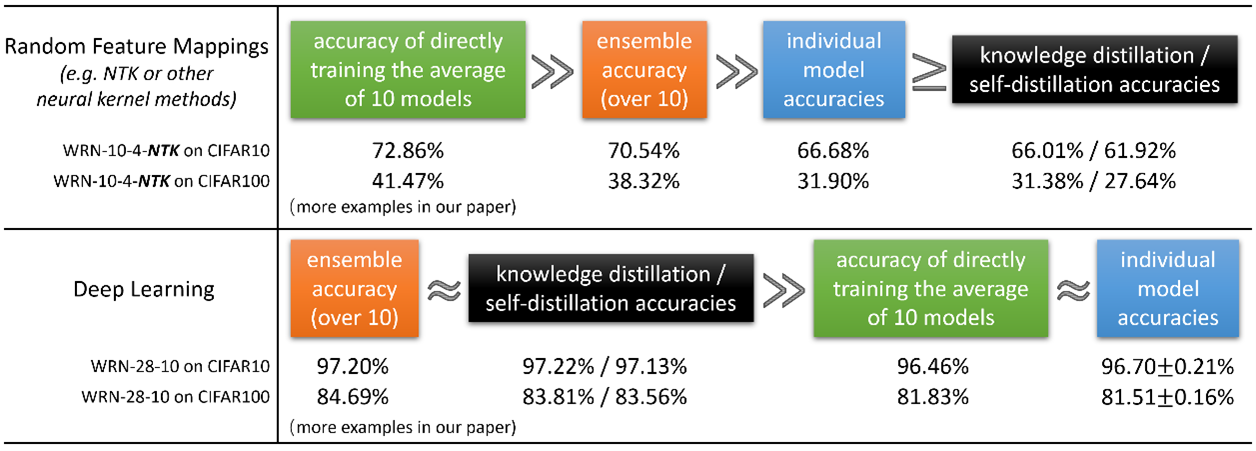
「アンサンブルは分散を減らす」ことがアンサンブルのパフォーマンス向上の理由。は成り立たなかった?
→深層学習優れたデータセットの多くで見つけることができる**「共通の構造」**の研究を提案
非常にごもっともと思える。
*上記と同じ
**Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning **
https://www.microsoft.com/en-us/research/publication/towards-understanding-ensemble-knowledge-distillation-and-self-distillation-in-deep-learning/
図1:Ensembleは、深層学習アプリケーションのテスト精度を向上させますが、モデルの平均を直接トレーニングしても、このような精度の向上に匹敵することはできません。
アンサンブルは分散を減らすのではなく、新しい視点(つまり別の解決手段、つまり個性に従った判断)を増やすと解釈。
いや、そこまでは自明じゃなかったのか?
ふむふむそれで個性をどう使うのか?
「アンサンブルに関する既存の理論のほとんどは、個々のモデルが根本的に異なる場合(たとえば、変数の異なるサブセットでサポートされる決定木)、または異なるデータセットでトレーニングされる場合(ブートストラップなど)にのみ適用されます。個別にトレーニングされたニューラルネットワークが同じアーキテクチャで同じトレーニングデータを使用しているディープラーニングの世界では、前述の現象を正当化することはできません。違いは、トレーニング中のランダム性だけです。
おそらく、深層学習で一致するアンサンブルに最も近い既存の定理は、ランダムな特徴マッピングのアンサンブルです。一方では、ランダムな(規定された)特徴の複数の線形モデルを組み合わせると、特徴の数が増えるため、テスト時のパフォーマンスが向上するはずです。一方、特定のパラメーターレジームでは、ニューラルネットワークの重みは初期化に非常に近いままである可能性があり(ニューラルタンジェントカーネル、またはNTKレジームとして知られています)、結果として得られるネットワークは、指定された特徴マッピングに対して線形関数を学習しているだけです。ランダム初期化によって完全に決定されます(この作業を参照してください))。これら2つを組み合わせると、深層学習のアンサンブルはランダムな特徴マッピングのアンサンブルの原理を共有していると推測できます。」
ニューラルタンジェントカーネル、またはNTKレジーム。これがモデルの個性を説明するのかな。
Neural Tangent Kernel(NTK)の概要
https://medium.com/lsc-psd/neural-tangent-kernel-ntk-%E3%81%AE%E6%A6%82%E8%A6%81-faf0ad249923
「2018年末に提案され、その理論が機械学習の真理に近いとは言われているものの、イマイチ結果に結びつかない理論です。ニューラルネットワークモデルはy=f(x,θ)(y=出力、x=入力、θ=重みの集合)という関数で表すことができ、一般的には個々の重みを調整することで正しいyを導いていくアルゴリズムです。NTKは重みを調整することに主眼を置くのではなく、重みが変化することによって関数の形がどう変わるのか、すなわち重み全体の分布(特徴)がどう変化するのかに焦点を当てています。θが無限個ある(理論の上ではθが加算無限個あっても特に問題ないと思います。いざ実装する際には大問題ですが。)という仮定の下では、重みベクトルのカーネルは初期カーネルとほとんど同じ、つまり重みの状態は初期値からほとんど変化していないことが分かっています。このような条件下では、重みを定数とみなせるのでモデルを線形近似することが出来、勾配降下法を容易に用いることができるという理論です。」「隠れ層が大きくなればなるほど、重みは変わらない」「一つ一つの隠れ層が大きいとき、出力に影響を与えるニューロンは大量に存在することになります。これらのニューロンの重み全てが僅かに変化するだけでも、その出力を大きく変化させる可能性があるため、ニューロンはデータに合わせようと思っても、ほとんど変える必要がないということです。」
重み全体の分布=知識構造?=モデルの個性。ならやはり個性という表現で良いか。重みの初期値は・・・事前学習が与えている影響はスタート地点の規定以外に初期値にも・・・。
w2v-mpとkeb-mpは確かに隠れ層が特徴的だがその大きさとガウス過程との関係は・・。事前学習結果を有効に利用する場合に前提となる重要ポイントとなるのか?
「アンサンブル/知識の蒸留は、ランダムな特徴マッピング(つまり、NTK特徴マッピング)と比較して、ディープラーニングでも同じように機能しますか?
回答:下の図3の実験から明らかなように、実際にはそうではありません。」
うーむ、どう読み取ればよいのだろう。
当方の個性評価では確実に結果が良くなることを踏まえるに、
end2end手法は個性評価には向かない、現在行っている個性評価のような、結果に対して評価し直す手法が良い、という意味で捉えると良い、のだろうか。
「マルチビューデータ:ディープラーニングでアンサンブルを正当化するための新しいアプローチ
アンサンブルは非構造化ランダム入力の下で機能する可能性が低いため(図4を参照)、データ内の特別な構造を調べて正しく理解する必要があります。」
ふむふむ。個性を理解するためには、「個性の構造」を調べて理解することはやはり必要だよね。
「結論と今後
この作業では、私たちの知る限り、深層学習でアンサンブルがどのように機能するかを理解するための最初の理論的証拠を示します。また、私たちの理論と「マルチビュー」データ仮説を裏付ける経験的証拠も提供します。私たちのフレームワークは他の設定にも適用できると信じています。たとえば、ランダムトリミングを使用したデータ拡張は、ネットワークに「マルチビュー」を学習させる別の方法と見なされる可能性があります。実際には、ニューラルネットワークがトレーニング中に機能を取得する方法に関する新しい理論的洞察が、ニューラルネットワークのテスト精度を向上させ、アンサンブルのテスト精度と一致する可能性のある新しい原理的なアプローチの設計にも役立つことを願っています。」
ある目的において複数の解決手段があることを知っており、そのうちどれを選ぶべきかの基準が十分曖昧であるならば、自分自身で忘れた頃に考え直したときのその違いは、自己多様性と言って良いだろう。
この自己多様性を上記と絡めて考えると面白そう。
*ドメイン駆動設計とは何なのか? ユーザーの業務知識をコードで表現する開発手法について
https://codezine.jp/article/detail/11968
*Vision Transformers: Natural Language Processing (NLP) Increases Efficiency and Model Generality
https://www.kdnuggets.com/2021/02/vision-transformers-nlp-efficiency-model-generality.html
transformerが眼球のピントと合わせ機能を模したもの、CNNが網膜から視神経への伝達を模したもの、ならば、その組み合わせは当然に有効と言えるのかもなぁ。
(直列ということは、再チェック機能…ん? 眼は眼単独でなにか判断していたっけかな?,ピント合わせ限定?中心窩固定?微分可能な空間中心窩メカニズム?)
眼球の機械化を考えるとき、眼球自体はtransformerで制御して脳への接続までの部分はCNNで制御する、とできれば非常に面白そう。CNN系は脳との親和性が示されていたのであったっけか?
このほぼ見えない左目、寿命があるうちに機械化できると楽しいな。
「普遍的な学習基盤のアイデアは、機械学習において非常に魅力的な概念で あり、「古き良き人工知能」のエキスパートシステムとは正反対です 。あらゆるタイプの入力データであらゆるタスクを学習できる基本的なアーキテクチャを見つけ、それを効率と有効性の両方についてモデルを調整できる発達学習アルゴリズムと組み合わせることができれば、人工的な一般学習者が残ります。」
モデルの調整には巨人の肩、エキスパートシステムや知識グラフも必要とは思うが。
データ駆動はあくまで仮説づくりに役立つのであり、仮説がいかにそれらしく見え論理的につながっているとしても、必ずしも公理につながっているとは限らない、という点を常に認識するべきと再認識した。
適用範囲を明確にできるほどのデータが予め存在することは例外だろう。
「学習した畳み込みカーネルと、生物学的視覚で実験的に観察された受容野との類似性は、無視できないほど優れています。トランスフォーマーの一般性が人工知能への最善の道の一歩を構成するのか、それとも誤解を招くような蛇行を構成するのかはしばらくわかりません。個人的には、取得に必要な計算、エネルギー、データの規模についてはまだ留保しています。これらのモデルは良好に機能しますが、少なくとも商業的には非常に関連性が高く、近い将来、AIの安全性に関して慎重に検討する必要があります。」
相補的でありだどちらかではないと思うのだが。
*モデル個性について
BERT: 学習全体の代表的な単語を提示?。共起ネットワークに現れる単語は代表語?。masked langage modelは文法ベースの構造を学習しやすい?。
w2v-mp, keb-mp: 畳み込みの共起によるパターン認識の結果?。w2vは文体レベルの構造、学習データに強く依存する構造を学習しやすい?。
*attentionについて、スカラー状態とベクトル状態を混同していた部分があるようなのでその部分書き直すこと。dimの影響力が大きい気がしてきた・・・
*Diversity(多様性)のある推薦システムとは何か?
https://www.wantedly.com/companies/wantedly/post_articles/306930?utm_source=t.co&utm_medium=share&lang=ja
「推薦システムにおける Diversity とは?
まず、推薦システムにおける Diversity とは何かについて説明します。推薦システムにおける Diversity は、「推薦結果として返すアイテムセット同士の類似度が低い」と定義されることが多いです。例えば映画推薦では、一度にホラー映画を3つ推薦したときよりも、ホラー映画, アクション映画, ロマンス映画を一つずつ推薦した時の方が Diversity の高い推薦と考えられます。」
「
[1] Bradley, Keith, and Barry Smyth. "Improving recommendation diversity." Proceedings of the Twelfth Irish Conference on Artificial Intelligence and Cognitive Science, Maynooth, Ireland. Vol. 85. No. 94. 2001.
[2] Kaminskas, Marius, and Derek Bridge. “Diversity, serendipity, novelty, and coverage: a survey and empirical analysis of beyond-accuracy objectives in recommender systems." ACM Transactions on Interactive Intelligent Systems (TiiS) 7.1 (2016): 1-42.
[3] Vargas, Saúl, et al. "Coverage, redundancy and size-awareness in genre diversity for recommender systems." Proceedings of the 8th ACM Conference on Recommender systems. 2014.
」
「
推薦システムの領域で Diversity について初めて言及されたのは、2001年に発表された”Improving recommendation diversity”[1]という論文でした。この論文ではユーザーの関心の高いアイテムを推薦することで、 Diversity がなくなってしまうことに問題を投げかけています。」
「
Coverage
推薦可能なアイテムのうち、どれくらいのアイテムを推薦したか?
Coverage が高いほど、多くのアイテムが結果として返されるようになる。
Novelty
「 Novelty のあるアイテム」 = 「ユーザーが初めてみるようなアイテム」
ただ新しいアイテムを出せば良いのではなく、ユーザーにとって有益なアイテムであることが望ましい。
Serendipity
「Serendipity のあるアイテム」= 「ユーザーが驚くようなアイテムであり、さらにユーザーにとって有益なアイテム」
Serendipity については定義がいろいろあるが、「ユーザーの関心」+「新規性」+「意外性」と解釈される。」
「
推薦システムは情報検索システムの一部であり、[2]の論文によると Diversity については情報検索システムの分野ですでに議論されていたそうです。例えばユーザーが「アップル」と調べた時に、ユーザーの意図としては、企業の「apple」を指すのか、果物の「アップル」を指すのか分からない場合があります。その時にユーザーがどちらを意図しているか分からない時は多くの情報を出す方が望ましいと考えられていて、これが Diversity が情報検索システムや推薦システムで重要視されている理由の一つです。」
「ここで重要なのが、Diversity をあげることと、ユーザーの好みへの適合度(Accuracy)はトレードオフの関係にあることです。」
「
We define the diversity of a set of items, c1,...cn, to be the average dissimilarity between all pairs
of items in the result-set (Equation 2).
ここではSimilarityの反対の意味である Dissimilarity という言葉を用いていて、 Diversity は推薦結果の全てのアイテム同士の Dissimilarity の平均としています。式で表すと以下になります。
cは推薦結果のアイテムであり、推薦結果の1からn番目までのアイテムの全てのペアに対してDissimilarity (1 - Similarity )を計算して、それの平均をとっています。
」
「
Diversityを高めるためのアルゴリズム
Maximal Marginal Relevance(MMR)
最後に、 Diversity を高めるためのアルゴリズムのナイーブな方法について紹介します。MMRは情報検索システムの分野で使用されることもある、 Re-Ranking 系のアルゴリズムです。Re-Ranking とはユーザーの関心との関連性を元にアイテムを絞り込んで、その絞り込んだアイテムを Diversity が大きくなるように再度並び替えるアルゴリズムです。 MMR は以下の式で表されます。([2]の2.2章: Increasing Diversityより参照)
1項目は関連性を表すスコアであり、2項目は推薦結果 R の中でのアイテムとの距離の平均を加えています。アイテムiが関連性が高かったとしても、その推薦結果内で似たようなアイテムが多い場合は、2項目の値が小さくなってしまいます。結果としてユーザーの関連性が高いアイテムであっても、推薦結果内に似たようなアイテムが多く存在する場合は全体のスコアが小さくなってしまうということです。α は Diversity をどれくらい重要視するかのパラメータとなっています。
」
自分が知りたかったこと、興味のあることはこれに近い、かもしれない。何らかの軸を想定して距離を測るか…個性ごとの上位を順番にとってゆき距離が最大化した周辺まで、多様性評価手法の評価対象としたら…
*そろそろまともに検索、引用をまともに見つつ整理し直してレビューマトリックスにまとめないとな、と前々から書いている気がする。
集めた文献をどう整理すべきか?→知のフロント(前線)を浮かび上がらせるレビュー・マトリクスという方法 読書猿Classic: between / beyond readers
https://readingmonkey.blog.fc2.com/blog-entry-684.html
*距離の観点からノードの分散表現を俯瞰する
https://buildersbox.corp-sansan.com/entry/2021/01/28/110000
「距離の観点から分散表現の学習アルゴリズムを俯瞰していきたいと思います。」
*Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
https://arxiv.org/abs/2004.10964
Pretrainもドメイン特化しておいたほうが良いよねと。
*hikifune.fm
https://anchor.fm/yoheikikuta/episodes/1--Dont-Stop-Pretraining-Adapt-Language-Models-to-Domains-and-Tasks-eji6nn
*解像度変換について。
解像度が異なり意味が同じである単語群をどう同じ意味としてまとめるか。それも教師無しで。(教師アリならばsiamese modelなどあり得るがきりがない。)
一つの意味のまとまりとなる単語群の長さが5単語がせいぜいであり、「そのまとまりの前後の単語群は解像度に依存せず共通」とするならば、「可変センテンスレベルword2vec」を行い、それを予備知識学習に用いた個性の一つとするのもよい。単語群の大きさが固定される課題があるのでやはり単語群の長さは可変にすべき。そのような可変句にまとめるには複数の方法があるが・・・あるテーマに対する単語の類似度とり、その類似が文内において連続する長さを、単語群の長さとする方法はある。word2vecの学習にかける前に、単語を可変句にまとめ、学習する。vkeb-mpとして実装してみるか・・・。事例不足にはどう対応するか・・・。いや、これは一つにまとめられるか?。ならばvw2v-mpとして実装すべきか。
複数粒度の分割結果に基づく日本語単語分散表現
https://prtimes.jp/main/html/rd/p/000000136.000011485.html
を利用したほうが速いか?。最大の単語群の長さはsudachiに依存することになり、目的にはちと足りないが。
from gensim.models import Phrases
https://radimrehurek.com/gensim/models/phrases.html
https://deepblue-ts.co.jp/%E8%87%AA%E7%84%B6%E8%A8%80%E8%AA%9E%E5%87%A6%E7%90%86/w2v_phrase/
Phrasesのパラメーター調整で足りるのかな?
→足りない。どうするか。どこかで解決手法を書いたが忘れた。見直すこと
*Hitomi Yanaka, Koji Mineshima, Daisuke Bekki, Kentaro Inui
Do Neural Models Learn Systematicity of Monotonicity Inference in Natural Language?
https://arxiv.org/abs/2004.14839
https://www.google.com/url?sa=t&source=web&rct=j&url=https://www.anlp.jp/proceedings/annual_meeting/2020/pdf_dir/C3-1.pdf&ved=2ahUKEwjFkJrEyePuAhW0zIsBHd6DCt8QFjABegQICxAB&usg=AOvVaw1--vcLQ_UCSOxOOS0pfMVD
理研。般化能力の課題。差分を使った検討。
うーん、BERTでも汎化は厳しい?。LSTMとの比較であるが、汎化できている比較例はなかったのであろうか。手元ではw2v-mpが上位概念で判断しているように見えている(そしてBERTの汎化性能の悪さを補っている)のだが。
このような試験をすれば、上位概念を把握しているかどうかや解像度変換の検証はできるな。一つ作っておくか。ただ、どの文章に対しどう行うべきか。教師データから持ってくるとして、置き換え対象とする単語を全てのモデルが重要と判断しかつドメインずれしない文章である必要があるか。
いずれのモデルでも副詞や前置詞を入れると正解率が下がると。
BERTなどは前置詞の有無など無視できそうにも思えるが、それも事例を前提としたattentionがあって初めて、ということだろうか。それならば大規模モデルにするほど問題ではなくなる気がする大規模モデルなど使えないが。BERTは文法を学びすぎており、学んでいない文法は苦手なのかもしれない。
やはり可変句の検討は必要か?。encoder次第でありやる意味があまりないと思わなくもないが。
前置詞などが入るとBERTでは避けられない性能低下が起きるが、w2-mpのようなウインドウ畳み込みモデルでは(変化句内部の分散表現は類似しているため多少の長さなら吸収でき)大きな問題とはならない、とい考えても良いだろうか。
「3 つの含意関係認識モデルを評価した結果,未知の量化子と語彙関係の組み合わせにおけるモデルの汎化性能は,学習データに含まれる文の構文構造に制限されることが示唆された.」
BERTに関して、これは使用感覚と合う。自分は融通がきかないと表現してしまったが。こう、文脈を考慮してはくれるのだが、単語頻度を考慮したモデルではやらかさないよくわからない間違いをするのだよねBERTは。BERT単独で実務に使うのはちょっと、と思わせてくれる。
*The Spectral Underpinning of word2vec
https://arxiv.org/abs/2002.12317
word2vecの高度に非線形な関数の厳密な分析を提案
*解像度変換について。
教師ありならSiamesネットワークで良いのだが、ルールベースか教師なしでなければ実務には使えない。さてどうするか。
*cnnの弱点としてtransformerよりもバッチ間の関係性を学習しにくいことがあるそうだがその点は問題ない。
*courseraでいくらかの講習を受けた。ちっとはマシに理解できるようになったかな。そろそろ、記載した妄想をすべて見直し書き直しておきたい。いや、消したい箇所多いな…
*審査第二部 生活機器 前原 義明
トランスフォーマーを用いた特許審査支援の探究 - Detailed Description Is All We Need –
http://www.tokugikon.jp/gikonshi/297/297kiko5.pdf
CLS?
*審査第四部情報処理 石川 雄太郎
特許審査官が垣間見た深層学習(Deep Learning) による自然言語処理の変革期 〜Japio特許情報研究所での業務を通じて〜
http://www.tokugikon.jp/gikonshi/298/298tokusyu2.pdf
素晴らしく全うにまとまっていると思う。さすがやなぁ。審査にも期待できるか。正直そんなの特許査定にすんなよという特許が溢れている分野ってのがあるから技術常識部分を強化しているかのような動きは大変好ましい。
BERTのtensolflow2への切り替え対応は大変でした…。そのうちpytorch版に切り替えます。
特許文章に関して言えば、多分文脈をあえて読まないほうが良い場合があり、これがモデルの個性のズレの一因となっているのだと思う。
*これまでは、モデルと強化方法の革新であった。これからは教え方の革新、とはその通りと思うところ。教師がより重要に。
*courseraの講義を受けattentionやtransformerをtraxで作っているわけだが、モデルの個性差の一因として排他的論理和XORがやはり関係している気がしてきた。どの単語にXORがかかっているかわからない。どう確かめたものか。
*一度transformerを用いた要約モデルに通すことで、解像度変換を実装した。
*Deeplearning.ai Natural language processing 16週講義修了。T5、Reformer含むattention modelまでの講義。
*attentionに読み手の意図、認知が含まれ難いことは、やはり課題に思える。
Expert systemの改良を進めよう。
*別の解として、encoder-decoder transformerにおいて、pretrainの根幹と言えるencoderのattentionには手を付けず、**decoderのattentionにつき、queryを認知的にコントロールすることで
、認知を含めることができそうに思える。**試してみたい。
*Submitted on 5 Mar 2021
Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth
https://arxiv.org/abs/2103.03404
「 注意ベースのアーキテクチャは機械学習の至る所に存在するようになりましたが、その有効性の理由についての私たちの理解は限られたままです。この作品は、自己注意ネットワークを理解するための新しい方法を提案します。それらの出力は、それぞれが層をまたがる一連の注意ヘッドの操作を含む、より小さな項の合計に分解できることを示します。この分解を使用して、自己注意が「トークンの均一性」に対して強い誘導バイアスを持っていることを証明します。具体的には、スキップ接続または多層パーセプトロン(MLP)がない場合、出力は二重指数関数的にランク1行列に収束します。一方、接続をスキップすると、MLPは出力の縮退を停止します。私たちの実験では、標準的な変圧器アーキテクチャのさまざまなバリエーションで特定された収束現象を検証します。 」
*CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation
https://arxiv.org/abs/2103.06874
日本語処理にも革命!?分かち書きをせず高品質な事前学習を実現する CANINE がすごい
https://ja.stateofaiguides.com/20210311-canine-tokenization-free-encoder/amp/?__twitter_impression=true
*TransMed: Transformers Advance Multi-modal Medical Image Classification
03/10/2021 ∙ by Yin Dai, et al. ∙ ∙ share
https://deepai.org/publication/transmed-transformers-advance-multi-modal-medical-image-classification
「Over the past decade, convolutional neural networks (CNN) have shown very competitive performance in medical image analysis tasks, such as disease classification, tumor segmentation, and lesion detection. CNN has great advantages in extracting local features of images. However, due to the locality of convolution operation, it can not deal with long-range relationships well. Recently, transformers have been applied to computer vision and achieved remarkable success in large-scale datasets. Compared with natural images, multi-modal medical images have explicit and important long-range dependencies, and effective multi-modal fusion strategies can greatly improve the performance of deep models. This prompts us to study transformer-based structures and apply them to multi-modal medical images. Existing transformer-based network architectures require large-scale datasets to achieve better performance. However, medical imaging datasets are relatively small, which makes it difficult to apply pure transformers to medical image analysis. Therefore, we propose TransMed for multi-modal medical image classification. TransMed combines the advantages of CNN and transformer to efficiently extract low-level features of images and establish long-range dependencies between modalities. 」
「CNNは、画像の局所的な特徴を抽出するのに非常に有利です。しかし、畳み込み演算の局所性のために、長距離の関係をうまく扱うことができません。最近では、変換器がコンピュータビジョンに応用され、大規模なデータセットで顕著な成功を収めている。自然画像と比較して、マルチモーダルな医療画像は、明示的かつ重要な長距離依存性を持っており、効果的なマルチモーダル融合戦略は、深層モデルの性能を大幅に向上させることができる。このことから、我々は変換器ベースの構造を研究し、それをマルチモーダル医用画像に適用することを促している。既存の変換器ベースのネットワークアーキテクチャは、より良い性能を得るために大規模なデータセットを必要とします。しかし、医用画像のデータセットは比較的小さく、純粋な変換器を医用画像解析に適用することは困難である。そこで我々は、マルチモーダルな医用画像分類のためにTransMedを提案する。TransMedは、CNNとトランスフォーマーの長所を組み合わせ、画像の低レベルな特徴を効率的に抽出し、モダリティ間の長距離依存関係を確立する。我々は,耳下腺腫瘍の術前診断という困難な問題に対して我々のモデルを評価し,実験結果は我々の提案手法の優位性を示している.我々は、CNNと変換器の組み合わせが、多数の医用画像解析タスクにおいて非常に大きな可能性を持っていることを主張します。我々の知る限り、これは変換器を医用画像の分類に適用した初めての研究である。」
transformerとCNN組みあわせ。やはり相補的なのかな。
この手法は直列か。特徴の精度は上がるかもしれないが、transformerが見逃したら終わりかな?
CONNECTED PAPERSで関連文献ざっと確認。
https://www.connectedpapers.com/main/03e13ef9192206fecdb227366b298c992dbf7061/TransMed-Transformers-Advance-Multimodal-Medical-Image-Classification/graph
*NLP2021聴講予定。
抜き出すだけで一苦労なぐらい興味深い題名が多い。
持橋 大地 先生(統計数理研究所)
ガウス過程と自然言語処理
**モデルの個性において単語ベクトルの個性分布を評価する際には、理解可能性が高そうである、ガウス過程の教師なしであるGPLVMを利用してもよいのかもしれない。
鈴木 大慈 先生(東京大学/理化学研究所)
深層学習の理論
**Transformer=相互作用のあるparticle system?
その他、経験的に知られていた部分の理論など拝聴した。
松本 裕治 先生(理化学研究所)
知識と言語処理
**シンボルからのルールベース推論、ベクトルからの連続的推論? 知識と推論の接続、1確率手法、2知識ベースをembedに拡張する手法、3transformerからの知識抽出をする手法、4その他手法?
自分はどうしていたか?。1は一つ作成中、2はtfidf embeddings cluster visで実施、3は多量データ前提で個人では現実的ではない?。
上位下位関係の分散表現は学習できるがデータが無い?
常識は明示的に記載されない(知財でも大問題であり、個人的に最も欲しいところ。教師無しで。(特許に記述された情報のみにAIを使用しているような現段階の知財用AIは、とてもAIを有効活用できているとはいえないと思う))
シンボルのフレーム問題はデータで表現されていないことが問題だと思うが、CLIPのように言語と画像など五感を統一的に扱いつつ、リアルタイムにフィードバックすれば実現可能だろうか。
発表資料、PDF欲しいな。
Embedding Logical Queries on Knowledge Graphs (NeurIPS 2018)
https://proceedings.neurips.cc/paper/2018/file/ef50c335cca9f340bde656363ebd02fd-Paper.pdf
Query2box: Reasoning over Knowledge Graphs in Vector Space Using Box Embeddings (ICLR 2020)
https://openreview.net/forum?id=BJgr4kSFDS
(Rule Taker) Transformers as Soft Reasoners over Language (IJCAI 2020)
https://www.ijcai.org/proceedings/2020/0537.pdf
End-to-End Differentiable Proving (NIPS 2017)
https://papers.nips.cc/paper/2017/file/b2ab001909a8a6f04b51920306046ce5-Paper.pdf
NLProlog: Reasoning with Weak Unification for Question Answering in Natural Language (ACL 2019)
https://www.aclweb.org/anthology/P19-1618/
Differentiable Reasoning on Large Knowledge Bases and Natural Language (AAAI 2020)
https://arxiv.org/abs/1912.10824
発表資料、PDF公開あり!
A1-3 単語の重要度に応じてパラメタ数可変な単語分散表現の学習
○露木浩章, 小川哲司, 小林哲則, 林良彦 (早大)
●●●B1-1 単語埋め込みを用いた正則化による言語モデルの追加事前学習
○西田光甫, 西田京介, 吉田仙 (NTT)
「提案手法ではまず,単語埋め込み学
習手法である fastTextを用いて目的タスクのテキ
ストから目的ドメインの単語埋め込みを獲得する.
次に,言語モデルの追加事前学習に並行して目的ド
メインの単語埋め込みに言語モデルの単語埋め込
みを近づける学習を行う.最後に通常の Fine-Tuning
を行う.提案手法は,TAPT 同様に少ないデータ数
での事前学習を追加する手法であるため,短い計
算時間で学習できる」
**Task-Adaptive PreTraining(TAPT)? 教え方の工夫。
●●●●●●B1-4 単一事例エキスパートの統合によるドメイン適応
○清野舜 (理研/東北大), 小林颯介 (東北大/PFN), 鈴木潤, 乾健太郎 (東北大/理研)
**ファインチューニングとアンサンブルの組み合わせ。同じ事前学習では性能が出ない?。同じ事前学習モデルから多様なモデルを作りたい。ハイパラは経験上あまり効果なし。今回はデータ分割。1モデル1文。多様な多数決手法。k近傍アダプター近傍法。入力文と学習文の類似を取って類似の高い学習文で学習したモデルを用いる。改善の余地はあり。
その個性の特異な個性を優先する、とても共感するやり方。mixture of expart?. ただ、transformerのみであるとそれぞれの個性が強すぎ調和に欠けすぎる気もしなくもない。
自作AIにおいて、それぞれのモデルに対し得意分野のみ教えるというのはありか。しかし、得意分野のみに限定した教え方をした場合、得意分野に変化は起きないのだろうか。
個人的には、」BERTに汎化は求めていないのでこの手法はとても好み。好みの題材にはPFNさんと理研さんが含まれていることが多いかな。教え方の工夫。
C1-2 ラベル間の意味の違いを考慮したFew-shotテキスト分類
○大橋空, 高山隼矢 (阪大), 梶原智之 (愛媛大), 荒瀬由紀 (阪大)
C1-3 自然言語処理技術によるSDGs 関連特許技術の「見える化」
○前原義明, 久々宇篤志, 長部喜幸 (Japio)
D1-3 動的トピックモデルを用いた特許技術専門用語に対する技術進展分析
○岩田真奈 (東工大), 内海祥雅, 松田義郎, 齋藤歩美 (楽天), 田中義敏, 中田和秀
(東工大)
D1-4 文脈化埋め込み表現を用いた対照学習による病名正規化
○氏家翔吾, 磯颯, 荒牧英治 (NAIST)
P1-1 事前学習モデルを用いた近代文語文の現代語機械翻訳
○喜友名朝視顕, 平澤寅庄, 小町守 (都立大), 小木曽智信 (国語研)
P1-2 Transformer に基づく英日翻訳器からの単語アラインメント抽出手法の比較
○古澤智博, 松崎拓也 (東京理科大)
P1-12 事前学習モデルを用いた少量データに対する日本語抽象型要約
○勝又智 (レトリバ)
B2-3 文表現の摂動正規化: 事前学習済みモデルの Debias 手法
○新妻巧朗, 渡辺太郎 (NAIST)
C2-1 ベイジアンネットを用いた袋小路文読解モデル
○高橋直人, 竹内泉, 一杉裕志 (産総研)
●●●C2-3 予測の正確な言語モデルがヒトらしいとは限らない
○栗林樹生 (東北大/Langsmith), 大関洋平 (東大/理研), 伊藤拓海 (東北大/Langsmith),
吉田遼 (東大), 浅原正幸 (国語研), 乾健太郎 (東北大/理研)
「最近ではサプライザル理論に基づいた実験から,
パープレキシティ(PPL)の低い言語モデルほどヒ
トらしいという報告がされてきた [3, 4, 9, 10, 11].
本研究ではこの報告の一般性について再検証し」
「言語モデルの種類: パラメータ数の異なる 2
種類の Transformer 言語モデル(400M パラメータ
の Trans-l と 55M パラメータの Trans-s)と LSTM
ベースの言語モデルについて,学習データ量(1.4G,
140M,14M サブワード)とパラメータアップデー
ト回数(100K, 10K, 1K, 0.1K)を変えて学習し,さ
らにそれぞれの設定について 3 つの異なるランダム
シード4)でモデルを学習した(3 × 3 × 4 × 3 = 108 モ
デル).学習データは新聞記事と日本語 Wikipedia か
ら成る.さらに,3 グラム,4 グラム,5 グラム言語
モデル5)も加え,計 111 の設定について分析した.」
**予測の難しさ。日本語では英語とは異なる。自分が感じているtransformerへの違和感の原因かと思ったが、他の言語モデルでも?。すべての単語予測で同価値に予測するから?。日本語での言語モデルに一石?
C2-4 再帰的ニューラルネットワーク文法による人間の文処理のモデリング
○吉田遼 (東大), 能地宏 (産総研), 大関洋平 (東大)
**言語モデルに階層構造不用? 語順のみLSTM、階層構造RNNG。
P2-4 研究データ検索における論文上の引用文脈の利用
○角掛正弥, 松原茂樹 (名大)
P2-15 複数の学習器による知識の蒸留を利用した読影所見用語認識の精度向上
○田川裕輝, 中野騰久, 尾崎良太, 西埜徹, 谷口友紀, 大熊智子, 中村佳児 (富士フイルム)
●B3-1 ニューラル系列変換のためのTransformerの注意機構を活用した外部記憶融合
○庵愛, 増村亮, 牧島直輝, 田中智大, 高島瑛彦, 折橋翔太 (NTT)
**cold fusion?。transformerに適した外部言語モデルの適用方法。
●●B3-3 企業情報を考慮したキャッチコピーの自動生成
○昇夏海, 平岡達也, 丹羽彩奈 (東工大), 西口佳佑 (サイバーエージェント), 岡崎直観 (東工大)
**BERT、企業関連語生成。Plug and play language model? 全文生成とはいかない?
B3-4 Transformerを用いた日本語併置型駄洒落の自動生成
○畠山和久, 徳永健伸 (東工大)
●C3-3 Wikipediaからの意外な恩恵事例の抽出
○尾崎立一 (京大), 橋本力 (楽天), 村脇有吾, 黒橋禎夫 (京大), 颯々野学 (ヤフー)
「ネガティブエンティティについてのポジティブ説明を述べ
ている文は,その意外な恩恵を述べている可能性
が高い.」
**BERT。ネガティブに一般に認知されるエンティティそのものに、事前学習において最初からポジティブ情報を混ぜていたら?。またその事前学習が官位に学習できる場合であったときには?(聴講できなかった)
一通り見られなかった・・・
P3-1 単語の分散表現に基づく極性判定のための教師なし分野適応
○森谷一至, 白井清昭 (JAIST)
P3-2 商品レビューの複数の観点からの有用性の評価
○曽田颯人, 白井清昭 (JAIST)
「本研究では,商品レビューの有用性を複数の観点
から評価し,その評価結果を包括的にユーザに提
示するシステムを提案する」
P3-9 集合知を用いた大規模意味的フレーム知識の構築
○小原京子 (慶應大/理研), 河原大輔 (早大/理研), 笹野遼平 (名大/理研), 関根聡
(理研)
P3-16 ウェブ検索クエリのための部分一致文字列に対するエンティティ名称予測モデルの提案
○豊田樹生, 小松広弥, 熊谷賢, 菅原晃平 (ヤフー)
P3-18 BERTを用いた文書分類タスクへのMix-Up手法の適用
○菊田尚樹, 新納浩幸 (茨大)
C4-2 定義文を用いた文埋め込み構成法
○塚越駿, 笹野遼平, 武田浩一 (名大)
D4-3 項目採点技術に基づいた和文英訳答案の自動採点
○菊地正弥, 尾中大介, 舟山弘晃, 松林優一郎, 乾健太郎 (東北大/理研)
●D4-4 文法誤り訂正モデルは訂正に必要な文法を学習しているか
○三田雅人 (理研/東北大), 谷中瞳 (理研)
**transformerの訂正能力。検出はできているが修正はできていない?
●E4-3 通時的な単語の意味変化を捉える単語分散表現の同時学習
○相田太一, 小町守 (都立大), 小木曽智信 (国語研), 高村大也 (産総研/東工大), 持橋大地 (統数研)
**アライメントはやっておくべきか。
2つの母集団で共通する単語間の差を取り片方の母集団の全単語よりその差を引けばよい?
alignment
P4-6 児童作文の評価に向けた脱文脈化観点からの検討
○田中弥生 (神大), 佐尾ちとせ (関西学院千里国際中等部・ 高等部), 宮城信 (富山大)
P4-9 属性情報を追加した事前学習済みモデルのファインチューニング
○笹沢裕一, 岡崎直観 (東工大)
P4-11 静的な単語埋め込みによるカタカナ語を対象としたBERTの語彙拡張
○平子潤, 笹野遼平, 武田浩一 (名大)
P4-12 Tokenizerの違いによる日本語BERTモデルの性能評価
○築地俊平, 新納浩幸 (茨大)
P4-15 人間とBERTの語から語の連想の比較
○相馬佑哉, 堀内靖雄, 黒岩眞吾 (千葉大)
P4-16 知識グラフ埋め込み学習における損失関数の統一的解釈
○上垣外英剛 (東工大), 林克彦 (群馬大)
C5-2 遺伝子二重欠失研究のための関連論文検索手法
○平野颯, 野村航, 進藤裕之, 渡辺太郎 (NAIST)
**木構造トピックモデル?
C5-4 構文情報とラベルなしデータを用いた化学分野の関係抽出
○新城大希, 徳永健伸 (東工大), 牧野拓哉, 岩倉友哉 (富士通研)
P5-1 依存構造から句構造への変換による多言語モデリングに向けて
○神藤駿介 (東大/産総研), 能地宏 (産総研), 宮尾祐介 (東大)
P5-7 学習済み単語分散表現を用いた連続空間トピックモデル
○井上誠一 (創価大), 相田太一 (都立大), 浅井学 (創価大), 小町守 (都立大)
A6-2 BERT の Masked Language Model を用いた教師なし語義曖昧性解消
新納浩幸, ○馬雯 (茨大)
●●●A6-3 単語埋め込みによる論理演算
○内藤雅博 (京大), 横井祥 (東北大), 下平英寿 (京大)
**word2vec含めた加法構成性の不足? 中心化。単語の共起確立と各単語埋め込みのつながり?
●●B6-1 事前学習済みTransformerを用いたData-to-textにおける入力順序の影響分析
○矢野祐貴, 須藤克仁, 中村哲 (NAIST)
**T5。text to textでなくdata to text。教え方の工夫。
B6-3 トピック文生成による教師なし意見要約
○磯沼大, 森純一郎 (東大), ダヌシカボレガラ (リヴァプール大), 坂田一郎 (東大)
●●B6-4 指定語句を確実に含む見出し生成
○山田康輔 (名大/朝日新聞社), 人見雄太, 田森秀明 (朝日新聞社), 岡崎直観 (東工大), 乾健太郎 (東北大/理研)
**decoderを分割などして指定語句を確実に挿入する。自分の環境はモデル加工なし事前学習流用としないと現実的でない環境なので、面白いがこれを参考とできない。指定語句と類似する単語が出力されたら置き換えて再生成させてみるかな。B7-3参照
P6-14 半教師あり文書分類のための仮想敵対的学習による注意機構の頑健性および解釈性の向上
○北田俊輔, 彌冨仁 (法政大)
P6-18 説明性の高いニューラルモデルの予測確信度に関する分析
○佐藤俊 (東北大), 大内啓樹 (理研), 佐々木翔大, 塙一晃 (理研/東北大), 乾健太郎
(東北大/理研)
P6-19 小規模コーパスを利用した領域特化型ELECTRAモデルの構築
○伊藤陽樹, 新納浩幸 (茨大)
●●A7-1 単語埋め込みの確率的等方化
○横井祥 (東北大), 下平英寿 (京大)
**単語埋め込みののゆがみ。中心化の頻度による修正?
自分は分散表現を、1w2v-mpのような外部データ事前学習、2keb-mp・tfidf embeddingd cluster visのような内部データ事前学習、により得ている。1は、w2v-mpの目的が「歪め統合」なので、類似する単語は「より見分けにくく」あってほしい。中心化により単語ごとの方向を分散させる動機はない。2は、内部データで事前学習しているので、そもそも中心化は達成されているはず?
●●A7-2 Transformerの文脈を混ぜる作用と混ぜない作用
○小林悟郎 (東北大), 栗林樹生 (東北大/Langsmith), 横井祥, 乾健太郎 (東北大/理研)
**少しずつ文脈が混ざってゆく。残差結合の影響を考慮してattentionの評価?
A7-3 単語埋め込みの決定的縮約
○仲村祐希 (東北大), 鈴木潤, 高橋諒, 乾健太郎 (東北大/理研)
A7-4 階層コード表現を用いた上位下位関係の識別
○水木栄, 岡崎直観 (東工大)
E7-1 人と言語モデルが捉える文の主題
○藤原吏生 (東北大), 栗林樹生 (東北大/Langsmith), 乾健太郎 (東北大/理研)
●●●●B7-3 テキスト変換モデルに基づく様々な制約を用いたインタラクティブ要約
○柴田知秀 (ヤフー), 山田悠右 (東工大), 小林隼人, 田口拓明 (ヤフー), 奥村学 (東工大)
**(聴講できなかった)mT5-base。様々な制約。インタラクティブ?
summarize: src tgt ベース学習
keyword constraint: 大統領 summarize: トランプ氏に.. .. 制約あり学習
prefixを二重にかぶせる手法は面白い。必要なサンプル数は実質いくらになったのだろうか? 教え方の工夫。
B8-3 高再現率な文法誤り訂正システムの実現に向けて
○松本悠太 (東北大), 清野舜 (理研/東北大), 乾健太郎 (東北大/理研)
●●●E8-3 日本語Wikipediaの編集履歴に基づく入力誤りデータセットと訂正システムの改良
○田中佑, 村脇有吾 (京大), 河原大輔 (早大), 黒橋禎夫 (京大)
**自前日本語事前学習BART。コーパス、学習済みモデルも公開?
日本語Wikipedia入力誤りデータセット (v2)
http://nlp.ist.i.kyoto-u.ac.jp/?%E6%97%A5%E6%9C%AC%E8%AA%9EWikipedia%E5%85%A5%E5%8A%9B%E8%AA%A4%E3%82%8A%E3%83%87%E3%83%BC%E3%82%BF%E3%82%BB%E3%83%83%E3%83%88
BART日本語Pretrainedモデル
http://nlp.ist.i.kyoto-u.ac.jp/?BART%E6%97%A5%E6%9C%AC%E8%AA%9EPretrained%E3%83%A2%E3%83%87%E3%83%AB
mT5?では性能が出なかったような話もあるようだがどうなのだろう?
P8-20 BERTを利用したZero-shot学習による同音異義語の誤り検出
○藤井真, 新納浩幸 (茨大)
●C9-4 事前学習とfinetuningの類似性に基づくゼロ照応解析
○今野颯人 (東北大), 清野舜 (理研/東北大), 松林優一郎 (東北大/理研), 大内啓樹
(理研), 乾健太郎 (東北大/理研)
**省略解析。文章で表現されていない情報をどのように入手するかは重要。個人的には基本的にはルールを組み込むことによりそれを達成するべきと思っている(ルールとはそも蒸留後の知識だから)。本件では事前学習とfinetuningの工夫。省略部分を[MASK]扱いでとして予測することは言語モデルで可能そうではある。教え方の工夫。
D9-1 文脈を考慮した句の平易化
○河原井翼, 白井清昭 (JAIST)
E9-3 ニューラルネットが学習する意味表現は体系性を持つか
○谷中瞳 (理研), 峯島宏次 (慶應大), 乾健太郎 (東北大)
P9-1 単語制約を用いた概念ネットワークの改良
○本田涼太, 村田真樹 (鳥取大), 馬青 (龍谷大)
●P9-2 単語クラスタリングによって文書情報を整理する手法の改良
○符家俊, 村田真樹 (鳥取大), 馬青 (龍谷大)
P9-5 大域的・局所的エントロピーに基づいた特許文書中からの効果述語項構造の自動抽出
○邊土名朝飛, 野中尋史 (長岡技科大), 河野誠也 (NAIST), 谷川英和 (IRD国際特許事務所)
P9-8 特許文書を対象とした化学実験構造化のための基礎的検討
○作本猛, 邊土名朝飛, 山本雄太, 森楓, 野中尋史 (長岡技科大)
P9-15 Langsmith: 人とシステムの協働による論文執筆
○伊藤拓海, 栗林樹生 (東北大/Langsmith), 日高雅俊 (Edge Intelligence
Systems), 鈴木潤, 乾健太郎 (東北大/理研)
P9-20 Encoder-Decoderモデルを用いた文章表現を豊かにする執筆支援システム
○鈴木勘太, 杉本徹 (芝浦工大)
**nlp2021聴講まとめ。
transformer全盛?しかし良い結果も悪い結果も。モデルの革新から「教え方の革新」への移行が数件みられた。インタラクティブとの結合(ヒト認知の利用)も数件みられた。ルールベースとデータの融合につき指摘がみられた。これら方向に向かってほしい。
教え方の革新へという意味で、kaggle系の知識がより重要となってゆくのかな。
*AI王 〜クイズAI日本一決定戦〜
https://www.nlp.ecei.tohoku.ac.jp/projects/aio/
https://sites.google.com/view/nlp2021-aio/
オープンドメイン質問応答技術の最新動向
https://speakerdeck.com/ikuyamada/opundomeinzhi-wen-ying-da-ji-shu-falsezui-xin-dong-xiang?slide=14
⾔語と視覚に基づく質問応答の最新動向
NTTメディアインテリジェンス研究所 ⻄⽥京介
(ファイル)
AutoGluon-Tabular を用いたアンサンブルによる日本語質問応答システムの構築 / AIO solution by AutoGluon-Tabular
https://speakerdeck.com/upura/aio-solution-by-autogluon-tabular
【AI王 〜クイズAI日本一決定戦〜】ふりかえり | 株式会社AI Shift
https://www.ai-shift.co.jp/techblog/1781
*IR?
*AutoGluon-Tabular?
https://qiita.com/dyamaguc/items/dded739f35e59a6491c8
AutoGluon-Tabular、多様性評価において使ってみるか。最善スコアには興味がないが、毎回同じ傾向になるのかどうかには興味がある・・・
*Student-Teacher Learning from Clean Inputs to Noisy Inputs
https://arxiv.org/abs/2103.07600
(3)教師がその隠された特徴の中で知識をどのように分解するか。下流でつなげるって意味?
*深層学習を使うまでもないという話題が再燃しているが、ただ分けられるからどちらでも良いと評価するのではなくて、どのように分けられるとそれが公理につながる可能性も評価しないといけないと思う。限られたサンプルからより単純で充分と評価することは評価系の幻想に惑わされた短慮かもしれないと思える。
*人が学習の後ある新たな定理を提示できるのであれば、十分複雑なAIでもそれは可能なはずだ。ただ、同じように学んでも同じゴールにたどり着くわけではない。これを多様性と教育誘導により解決できると良いのになと思っている。より単純な方法で同じ結果が得られるならばその単純な方法と同じようにどのように教えればよいのか知りたい。
*アンサンブル・個性評価手法について、仮説的なイメージ
関数の形自体は不明であり、事前事後問わず、関数の形を予想するに何らかの学習が必要だとする。
連続した関数: どのアルゴリズムでも近似しやすい。アンサンブルの有効性はあまりない?。
非連続のみの関数: 非連続とはっきりしているならば、非連続も見分けるニューラル系のアルゴリズムが有効。連続した関数を予測するアルゴリズムは不要だが、近似により評価が低くならないことがある。アンサンブルの有効性はあまりない?。(非連続を予測するアルゴリズムのみまたはそのアンサンブルを用いる場合もあるがとりあえず置いておく。)
連続部分と非連続部分が混合し複数存在する関数(データ不足): データ不足のため非連続・連続が真にそうであるのか見分け難い。ニューラル系のアルゴリズムは非連続の関数と予測しやすく?、連続した関数を予測するアルゴリズムは連続した関数と予測しやすい。真の関数は連続非連続の混合なので、確率的にアンサンブル等が有効となる?(非連続・連続を見分けてはいないので、最適バランスは存在しない?)。attentionを用いたtransformerのようなアルゴリズムは、うち非連続部分を事前学習において明確化しているので、単独でも性能が高くなりやすい。ただし、attentionを用いたtransformerのようなアルゴリズムは、事前学習ドメインのずれによりattentionが間違っている場合も条件により多々あり、アンサンブル等により非連続とみなした部分を連続と置き換えることが有効であることもある。
(非連続部分を決定木等の知識で補う方法もある。局所的連続部分をCNN等で補う方法もある。)(連続非連続構造があるとき構造の把握を無視して特定の評価を前提としひとつのモデルを選択しようとする試みはこの条件では失当に思える)
連続部分と非連続部分が混合し複数存在する関数(データ十分): データ十分のため非連続・連続が真にそうであるのか見分け易い。非連続・連続双方を近似できるニューラル系ニューラル系のアルゴリズムが有利であり、アンサンブル等はあまり有効ではない。attentionを用いたtransformerのようなアルゴリズムは、うち非連続部分を事前学習において明確化しているので、単独でも性能が高くなりやすい。ただし、attentionを用いたtransformerのようなアルゴリズムは、事前学習に用いるデータを増やしてもズレは変わらないため?(記憶ネットワークであるのでズレは局所的に補正されている場合も多いかもしれない)、事前学習ドメインのずれによりattentionが間違っている場合もあり、アンサンブル等により非連続とみなした部分を連続と置き換えることが有効であることもある。ただし、データ十分は達成できない前提である可能性がある。
*データが十分かどうか評価することは難しいことが多いため、あるデータ、ある評価系において、例えば連続した関数を予測するアルゴリズムがニューラル系のアルゴリズムと同等以上の性能を示したとしても、ニューラル系のアルゴリズムよりそのアルゴリズを採用したほうが良い、とは自動的にはできないことも多い、と思う。(例えば、古典物理を予測できるが、古典物理以上は予測できようがない、という結果になる。)(評価データでの予測と実データでの予測にズレが生じるならば、アルゴリズムの最適化選択はほぼ無意味であった、とも言えるのではないだろうか?。そしてその評価がない時点では、アルゴリズムの良し悪しを論じることができないのでは?。この時点では、オッカムの剃刀のように「よりシンプルが最上」とするのではなく、「より複雑を選択」すべきなのではないだろうか?。)(シンプルなアルゴリズムであるほど汎的な近似をしやすいので、現実と適用しやすいということはあるだろう。近似解で十分ならば。)
*集合のある特徴はある分布となる。単語頻度はある連続した分布を形成する。tfidfはある連続した分布を形成する。ある特定の単語間の記憶・文脈考慮はある不連続部分を持つ分布を形成する。先2つは演繹?的な仮説を前提とする。後1つは帰納的に求められる。特徴全体としては後1つに近いはず。部分的には先2つにも近いはず。分布をある条件でまとめると全体の意味が取り出せる。全体として取り出す手法も部分のみ取り出す手法もある。
*cdpierse/transformers-interpret
Model explainability that works seamlessly with 🤗 transformers. Explain your transformers model in just 2 lines of code.
https://github.com/cdpierse/transformers-interpret
transformerの説明。破壊予測よりマシ?
*SHAPがいつの間にかテキストにもtransformerにも正式に対応していた?
https://shap.readthedocs.io/en/latest/example_notebooks/api_examples/plots/text.html
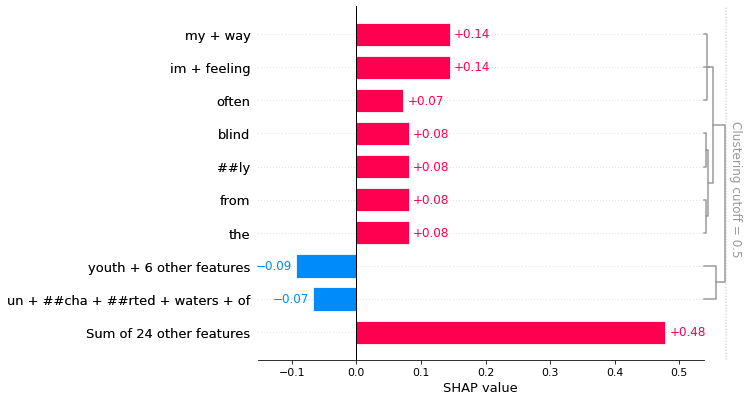
*Do Wide and Deep Networks Learn the Same Things?
https://ai.googleblog.com/2021/05/do-wide-and-deep-networks-learn-same.html?m=1
深さと幅は異なる学習を行うか
*Geometric Deep Learning
Grids, Groups, Graphs, Geodesics, and Gauges
Michael M. Bronstein, Joan Bruna, Taco Cohen, Petar Veličković
https://geometricdeeplearning.com/
幾何と深層学習教科書。汎化に対称性など。
*Yi Tay Google Research Mountain View, California yitay@google.com
Mostafa Dehghani Google Research, Brain Team Amsterdam, Netherlands dehghani@google.com
Jai Gupta Google Research Mountain View, California jaigupta@google.com
Vamsi Aribandi∗ Google Research Mountain View, California aribandi@google.com
Dara Bahri Google Research Mountain View, California dbahri@google.com
Zhen Qin Google Research Mountain View, California zhenqin@google.com
Donald Metzler Google Research Mountain View, California metzler@google.com
arXiv:2105.03322 (cs) [Submitted on 7 May 2021]
Are Pre-trained Convolutions Better than Pre-trained Transformers?
https://arxiv.org/abs/2105.03322
transformerよりCNN?
モデルの個性?
「貢献度
本論文の主な貢献度は以下のようにまとめられます。
- 畳み込みSeq2Seqモデルを、pre-train-fine-tuneのパラダイムで包括的に評価する。我々の知る限りでは、事前学習された畳み込みの競争力と妥当性はまだ未解決の問題である。
- 我々はいくつかの重要な見解を示しました。 具体的には,
(1)事前学習はTransformerと同様に畳み込みモデルの助けとなる,
(2)事前学習済みの畳み込みモデルは,モデルの品質と学習速度の点で特定のシナリオにおいて競争力のある代替手段となる,ということがわかった. - 本研究では,さまざまなタスクやドメインを含む8つのデータセットを対象に,大規模な実験を行った.8つのタスクのうち7つのタスクにおいて、事前に学習した畳み込みは、事前に学習した場合としない場合で、最近の最先端の変換器(T5 (Raffel et al., 2019))を上回ることがわかりました。コンボリューションとトランスフォーマーの速度と演算回数(FLOPS)を調べたところ、コンボリューションの方が速いだけでなく、より長いシーケンス長にも対応できることが分かりました。(機械翻訳ママ)」
うーん、目新しくはない?
「5.9 結果のまとめ
幅広いドメインの7つのタスクにおいて、
(1)事前に学習していない畳み込みは競争力があり、頻繁に事前に学習していないTransformerを上回る、
(2)事前に学習した畳み込みは7つのタスクのうち6つのタスクで事前に学習したTransformerを上回る、という結果が得られました。
これがRQ2の答えである。
また、自己注意モデルと同様に、畳み込みは事前学習の恩恵を受けられることがわかった。つまり、事前学習によって得られるメリットは、Transformerモデルだけのものではないということです。
これがRQ1の答えです。
また、事前に学習した畳み込みモデルのうち、拡張畳み込みと動的畳み込みは、一般的に軽量畳み込みよりも優れていることがわかり、
これがRQ5の答えとなります。
最後に、相対的な性能(つまり順位)は、事前学習によって変化することがわかりました。これは、事前学習によってアーキテクチャを構成することに、何らかの効果があることを示しています。
この効果の直接的な意味は、事前学習なしで(相対的に)良い性能を発揮するモデルが、事前学習を行うと必ずしも最高の性能を発揮するとは限らないということです(逆もまた然り)。
したがって,アーキテクチャと事前研修のスキームを混同するのではなく,事前研修の下ではアーキテクチャによって挙動が異なることに注意する必要があります.(機械翻訳ママ)」
「6 考察と分析
~
6.1 事前学習された畳み込みアルゴリズムが失敗するのはいつ?
実験セクションでは、事前に学習されたTransformerと比較して、畳み込みモデルの潜在的な利点を観察し、特定のケースで品質の向上を得ることができることを観察しました。
しかし、畳み込みの欠点をさらに理解するのも良いかもしれません。
学習済みの畳み込みモデルの明らかな弱点は、
Transformerエンコーダの自己注意に付随する交差注意の誘導バイアスがないことです。
このため、2つ以上の配列の関係をモデル化する必要があるタスクに、事前に学習された畳み込みを使用するのは良いアイデアではありません。
~
6.2 「Transformer」と比較した場合の学習済み畳み込みアルゴリズムの利点は?
我々は、Transformerよりも畳み込みを使用することで、妥当な品質の向上を確認しました。このセクションでは、さらなる利点について説明します。
6.2.1 畳み込みは高速で、長いシーケンスにも対応できる
図1は~
6.3 トランスフォーマーを畳み込みに完全に置き換えることを提案しているのか?
NLPの研究ではTransformerが主流となっていますが、本稿では、モデルの品質、速度、FLOPS、スケーラビリティなど、畳み込みには一般的に見過ごされている利点があることを提案します。さらに、コンボリューションが事前学習によって利益を得ることができるかどうかは、これまで知られていませんでした。
本論文では、畳み込み演算がいくつかのタスクで競争力を持ち、また、変換モデルと同様に事前学習の効果があることを示した。しかし、その反面、交差注意を必要とするタスクや、1つ以上の文や同じシーケンス内のドキュメントをモデル化する必要がある場合には、畳み込み式は対応できないことも強調しました。我々は、実務家には良い選択肢があり、定評のある変換モデル以外のアーキテクチャを検討する価値があると考えています。
6.4 事前学習とアーキテクチャの進歩を混同しないために 本論文では、他の3つの(畳み込みベースの)アーキテクチャ(lightweight、dymamic、dilatedなど)も、トランスフォーマーモデルと同程度に事前学習の恩恵を受けていることを示しました。
現在の研究状況では、事前学習は常にトランスフォーマー・アーキテクチャと密接に関連しています。その結果、BERT、変換器、および大規模な言語モデルの成功は、かなり混同されているように思われます。
今日まで、大規模な事前トレーニングが適用された唯一のモデルがトランスフォーマーモデルであること は事実ですが、我々は、他のアーキテクチャにも可能性があると考えています。
今回の実証結果から、アーキテクチャと事前学習の複合的な効果については、まだまだ理解を深める余地があると考えています。
したがって、本研究のインパクトは、NLPにおける畳み込みモデルの競争力を示すことにとどまらないと考えています。
より具体的には、アーキテクチャの代替案を検討する際には、健全なレベルで楽観的であるべきだということです。(機械翻訳ママ)」
事前に学習していない畳み込み ≒keb-mp?
事前に学習した畳込み ≒w2v-mp?
transformer ??BERT・・・には例えられないか?
上記記載の結果は、自分が観察してきた結果と整合性はあるかな・・・
「事前学習なしで(相対的に)良い性能を発揮するモデルが、事前学習を行うと必ずしも最高の性能を発揮するとは限らないということです(逆もまた然り)」そうでしょうね。
「事前研修の下ではアーキテクチャによって挙動が異なることに注意する必要があります.」そうでしょうね。「畳み込みは事前学習の恩恵を受けられることがわかった」w2v-mpの「歪め統合」は有効に動作してる?
「コンボリューションが事前学習によって利益を得ることができるかどうかは、これまで知られていませんでした。」え?
「何らかの効果」「今回の実証結果から、アーキテクチャと事前学習の複合的な効果については、まだまだ理解を深める余地があると考えています。」その何らかが何か知りたかったが。残念。
*Interpretable Machine Learning日本語翻訳
https://hacarus.github.io/interpretable-ml-book-ja/
*うわっ…私の言語モデル、古すぎ…?(AI SHIFT blog)
2020.01.09 Research
https://www.ai-shift.co.jp/techblog/183
「本記事ではSWEMで得られたベクトルとBERTで得られたベクトルを比較し、SWEMでの課題をBERTが解決してくれるかを検証したいと思います」
keb-mpはSWEM-hierと近い構造を持つ。keb-mpとBERTとの比較を考える際、参考となるだろう。
「私は手軽に文章の分散表現を得る方法としてWord2Vecから得られた単語ベクトルの平均やmax poolingをとる SWEM^2をよく使うのですが、語順が入れ替わった文章やノイズのある文章などでは、なかなか思うようなベクトルが得られないことが多々あります」
語順か。特許では語順が正しいことが重要となることは少ないかな?
「「〇〇を☓☓したい」のような最小限の文章ならば問題ないのですが、チャットボットには「〇〇を☓☓したいんだけどどうすればいいの?」といったノイズのある文章が度々入力されます
こういったノイズは文意を捉えづらくしてしまいます」
ノイズ。なるほどBERTはノイズに強いという点はありそう。これまでの分析でノイズが個性差の主要因子であると予想させる結果はなかったが意識して確認してみよう。
しかしなぜ、(ある一般的な評価手法において)どちらか、どちらが良い、という記事が多いのかな?。差があるなら補おうという記事をあまり見ない。
アンサンブルの記事がそうであるといえばそうだが、一方アンサンブルの記事では、ある一般的な評価手法においてアンサンブルしたら良かった、で終わっており、それぞれのモデルを理解した上で補おう、という記事が少ない印象。(理解できないという前提なのだろうか。たしかにそうなのかもしれない。個性ははっきりしているのだが理解・利用できないのかもしれない。)
*文章認知に関し個人的な夢
本件とは関係ないし別のところで述べているが、
自分は、文章を読む時間が0となれば良いと思っており、それは可能に近くなってきている、と認識している。(少なくとも文章の大意をつかむ時間に関しては)
アイディアとしては、1文章を見る→2自然言語処理で文章をベクトルに変換・画像化→3画像の相違点から文章の内容を判断。の流れであり、ポイントは、「言語処理を脳に依存するのではなく完全に外部機器に依存することで、「文章を目で追って読む時間を削減」すること」、だ。

**3の画像は、上のような画像でもよいが、CLIPやDALL・Eなどで文章(ベクトル)から画像を生成しても良い
(下画像 text-to-image使用例:a cat with thunder)。
(省略)
うむちょっと猫には見えない。
1から2の流れは、
例えば、「文章認識眼鏡と処理結果の網膜投影」で実現しても良い。
RETISSA Display
https://jp.techcrunch.com/2020/07/03/qdlaser-retissa-display/
個人的趣味としては、3の画像を(画像形式でなくともよいが)直接脳に畳み込みたい。
例えば、次の高解像度人工網膜がつかえそうな気がする(高解像度接続やバイパス可能性の問題はあるだろうが)。
Published: 05 March 2021
Photovoltaic retinal prosthesis restores high-resolution responses to single-pixel stimulation in blind retinas
Naïg Aurelia Ludmilla Chenais, Marta Jole Ildelfonsa Airaghi Leccardi & Diego Ghezzi
Communications Materials volume 2, Article number: 28 (2021)
https://www.nature.com/articles/s43246-021-00133-2?utm_source=twitter&utm_medium=social&utm_content=ads&utm_campaign=JJPN_1_RM01_JP_commat_article_2021_org
3につき、画像が一番簡単ではあるが、本当は言語野にでも直接叩き込めれば良いと思っている。
なお、トピックモデルでトピック抽出、文章要約などもあり得るが、読み取り速度は遅くなるし、そもそも要約すると単純化した単語の狭い定義に引きずられ可能性が落ちすぎると思っている。
「文は短く」は俗説か?ー〈短文信仰〉を屠り、短文のレトリックと長文のロジックを取り戻すために
https://readingmonkey.blog.fc2.com/blog-entry-609.html
実現検討に価値はありそう。どこかで研究開発していないだろうか。
とりあえず、網膜投影メガネ?を用いた実証や画像形式の検討は進めておくが、手が欲しいところ。
*transformerやCNN含む多くの手法は、文章方向に情報を考慮して、どの単語を強調すべきか選択し、文章ベクトルを作ってゆく。しかし、認知や暗黙知を含めた概念を含めた文章ベクトルを作るには、文章方向では足りないはずだ。
自分は**「歪め統合やwswなどにより、文章方向とは異なる方向から認知等の情報をさらに付与し、文章ベクトルを作っている」**(というイメージ)。
その認知等情報だが…やはり分布を考慮したい。VAEにつき見直してみようか。

*分散表現ベクトルに任意の認知との類似度等考慮したベクトルを付与し、それを学習に用い認知性を上げる試行もしている。認知の差はstyleGaNのようにみてわかりやすいわけではなく放置気味であったが、shapがテキストに対応したようであるし、改めて進めてみようか。
*REPORT
A brain-computer interface that evokes tactile sensations improves robotic arm control
https://science.sciencemag.org/content/372/6544/831?rss=1
双方向
ロボットアームの出力を脳にフィードバックする
脳が、前記文章画像の入力から文章の意味を取り出せるようになるなど、可塑性を持った変化を起こしたら、など面白い。
*CLIPは、「後付で分類を増やせる」画像分類AIとしても使える。非常に面白い。
*Be Careful When Interpreting Predictive Models in Search of Causal Insights
https://towardsdatascience.com/be-careful-when-interpreting-predictive-models-in-search-of-causal-insights-e68626e664b6
Shap使用時注意。相関と因果。
*Pay Attention to MLPs
https://arxiv.org/abs/2105.08050
*分散表現は正規分布でCNNはそれに文章の分布をかぶせる階層ベイズ、
transformerは文章の分布を直接得る、
と考えたらどうなのだろう?
個性とは一層目の正規分布だとして・・・
***transformerは時間軸方向にpoolを行わないが、CNN?は時間軸方向にpoolを行う。このため前者では、一部のもっともらしい相関のみ扱うが、後者では、すべての因果を相関の問題として扱うことができ、情報量が増えている。**など言えたら面白い。
*
https://www.jstage.jst.go.jp/article/jnlp/28/2/28_694/_pdf/-char/ja
*
https://www.jstage.jst.go.jp/article/jcss/28/2/28_2021.010/_pdf/-char/ja
*個性の付与について(wsw、expaert system以外の手法として)
大きな汎用コーパス→分散表現→汎用行列A(vocabA, 分散表現の次元)
個性コーパス→分散表現→個性行列T(vocabT, 分散表現の次元)
個性変換行列tm(vocabA, vocabA)を単位行列で作成→行列Tの内部語彙類似度からそれぞれの重み計算→重み付与個性変換行列tm(vocabA, vocabA)
汎用行列A(vocabA, 分散表現の次元)・重み付与個性変換行列tm(vocabA, vocabA)→個性付与汎用行列AT(vocabA, 分散表現の次元)
w2vmpモデルのようにmaxpoolingで文章ベクトルを作る場合であれば、このようなシンプルな手法でも、個性単語が目立ちやすくなるはず。またついで、語彙不足の解消もできるはず・・・
*HuggingFaceでConvBertの質問応答を試す
https://www.yurui-deep-learning.com/2021/06/21/huggingface-convbert/
*多様性評価は、手法としては加重平均のアンサンブルであるわけだが、加重を結果評価で逆算できないところに課題がある。結果の評価から重みを求めることは失当で、評価自体ではなく、結果に至る過程(モデルの個性)から重みを求める必要がある。結果に至る過程(モデルの個性)を評価に落とせていないため重みを自動で計算できていない。どのような結果に至る過程(モデルの個性)が必要かは、どのようにデータを解釈したいかとう受け手の認知に依存してしまう。(時系列にも個々の問題においても)流動的な受け手の認知を如何に評価できるか・・・未だにわかっていない(未来において設定される条件を事前に設定しておく問題にも近い)。現状は、結果に至る過程(モデルの個性)らしきほぼ定性的な結果を認識した受け手の主観的な優先順位で重みを付けている。さて、・・・。うーん、未来的な情報でもあるニーズやwswをもとに重みを計算すべきか。すると先の個性変換行列をどうにか使って・・・。
うーむ。
例えば、出願トレンドが組み合わせとなるならば、過去の傾向を学んだkebmpをより重く見るべきかもしれない。過去の特徴を重視しつつ組み合わせの正しさをそれほど考慮しないことが重要となるため。
例えば、出願トレンドが新規に移るならば、上位判断しやすいw2vmpをより重く見るべきかもしれない。上位概念で包括的にモニタリングすることが重要となるため。
例えば、出願トレンドが現状維持にとどまるならば、より学習したドメインに対し精密なBERTをより重く見るべきかもしれない。ドメインが変わらないならば精度高く見分けたほうがより良いため。
これらを見分ける情報から重みを求めるべき。これらを見分ける情報があるデータは・・・
*y-y_hatの差から重みを取り出し再学習するboostingは、差=間違いの大きさ、と前提できないので難しい。
*スタッキングの問題なのか??。
しかし上記のように何を重視すべきかも未来的に変化するので、メタモデルを用いて一義的に固定した評価基準を作るべきではないのでは(表現は異なるが最初から書いていたように)
・・・expert modelを関与させた流動的なメタモデルとすればよい??。
*expert modelをそのまま適用させるのではなく、メタモデルにかぶせてexpert modelを適用させるとすると・・・現状のexpert modelが苦手とする連続面をカバーできる利点はあるし、上記のようになぜかBERTとkebmpが一致しがたい結果が得られている知見のもとでは、メタモデルの判断に基礎部分として十分に意味があると考えても良いと思うが・・・。難しくもないしメタモデルを結合させたecpert modelを作ってみるか。
*メタモデルはvalデータで訓練する。valデータを未来的なデータに変更しメタモデルに直接expert modelと類似した知識をもたせる手法もありか。擬似的な未来的なデータとして直近の評価済み実データを採用すると簡単。ただし、正解教師データが少ない。valデータに未来的なデータを追加してもよいが、未来部分の情報が不足する気もする。
*個性をまとめ蒸留するには最も複雑かつ単純で解釈しやすいモデルを用いるとが良いが・・・BERTでまとめるかな? そろそろ蒸留するに十分なデータが集まった。huggingface切り替え後検証し直して問題なければ、短期持ち出し用としてBERT1つにまとめてしまおう。
*特許SDIにおいてend to endモデルをあまり検討していない最大の理由は、柔軟に未来の情報や受け手の認知を考慮できないからであるが(事前情報の学習に時間がかかりすぎ事前情報の再学習は現実的ではなく、またfinetuneingにも限界がある)、さて再検討もしておこう。
*ニューラルネットワークのパーセプトロンの代わりに各モデルとし、バックプロパゲーションの代わりにスタッキングでつなげ学習するstackNet。調べておくこと。
https://github.com/kaz-Anova/StackNet
https://github.com/reiinakano/xcessiv
*深層学習による自然言語処理入門: word2vecからBERT, GPT-3まで
https://www.slideshare.net/techblogyahoo/word2vecbert-gpt3
機械学習モデルを改善するのに、アーキテクチャではなくデータに焦点を当てるData Centric AIに関する解説スライド
https://www.slideshare.net/TakeshiSuzuki21/data-centricml-248354451
DSOC、ジョンズホプキンス大学のAngelo Mele准教授と共同研究したネットワーク解析のアルゴリズムをオープンソースで公開
https://prtimes.jp/main/html/rd/amp/p/000000210.000049627.html
lighthergm
https://github.com/sansan-inc/lighthergm
Pre-train and Prompt Learning
This paper aims to provide a survey and organization of research works in a new paradigm in natural language processing, which we dub prompt-based learning. [Update: 2021-08-15]
http://pretrain.nlpedia.ai/
####### 肯定的な見解
####### 否定的な見解
D. モデルに創造性をもたせることはできるのか.
創造性の発露と呼びたい例はいくらか見つかっているが,その量は少ない.未だ検討中.
モデルが上位概念下位概念を見分けているならば、発散と収束を伴うカタチでの創造性の付与は可能だろう。
w2v-mpが発散という個性、keb-mpが収束という個性を持つと仮定し、w2v-mpの個性をkeb-mpの教師に組み込んだw2vkeb-mp試行中…
*創造性の定義を,とりあえず,「教えていない範囲で新規性のあるものを最低限の実現可能性を持って提示すること」、としておく.
(創造性の定義は,標準的には,「新しくて有益な何かを生み出す能力やプロセス」.創造的な人工知能の定義は,「客観的な観察者に創造的だと感じさせる振る舞いをするシステム」,らしい.本件においては,有益となるかどうかは創造的な特許を検索者が理解できるかという,「検索者の認知に依存」してしまうので,なんとも・・・.創造的と感じさせる,もなんとも.創造的となったと言うためには,検索者のインサイトを刺激する+αが更に必要,と考えるべきか,上位に配置したならそれだけで有益性として十分,とすべきか.w2v-mpが重視した,というタグを付けるだけでも良いかもしれない.その場合は,かもしれないとの期待を維持するために,「ある程度以上の割合で実際に創造しえる結果が得られる」必要がありそうか.となると有益性を「実現可能性」(実現可能に「見える」場合,やってみようと高く喚起させられるという有益性を生むだろう)に置き換えても良いだろう.)(実現可能性につながりやすくなる要素として、「面白さ」、を足してもよい気がする)
・本検討において多様性を評価する目的は,最終スコアを高めるためというよりは(それもあるが),「創造性を持つ個性を切り捨てず救い上げる」ためである.
前者を優先していたが,そろそろ後者も検討してよいだろう.
*創造性のかけらもないAIを,個人用アシスタントAIとして充分だ,と評価したくない(え前と違う→いや欲が出た).個人用アシスタントAIには,この特許にはいらすとやのイラストが記載してありましたこんなの好きでしょう,と指摘してくるぐらいの柔軟性がほしい(いやここまではいらない.この原薬は錠剤で使われていますが点眼に切り替え可能ではないでしょうか点眼系の特許があったら重視しますね,この添加剤は現在話題の添加剤で従来のこれと置き換え可能ですから並行して探しておきますね,程度の柔軟性が欲しい.)
・創造性を生み出すには?。自分はまず「忘れること,間違えられる場を作ること」が必要なのだと思う.100を学び80を理解し,残りの20につき忘れ間違え,「自分を組み替え直す機会を与える」ことから,創造性は生み出されるのではないか.(追記 自己多様性の作成?)
個人的には,自分用のネタ帳は創造源として作るものなので,後で自分が読んでも一見して理解できないように,誤りと曖昧性を含むように,書くべきだと考えている(このページのように)(いくらなんでもひどすぎると思わなくもないがこれで良いのだ・・・と自己弁護しておこう・・・)
*よい 敵にあわせて下さい
https://www.jstage.jst.go.jp/article/jkg/69/4/69_155/_pdf/-char/ja
「私達は,レファレンスに人間が介在するということの意味を,もっと考えてみなければいけない。教員とのコンタクトも,何も複写依頼に限定する必要はないのである。日常会話においても,キャンパスの中で,あるいはどこかの道端で,先生,最近は何を,とか,どんなことをとか,今,なにか探し物はありませんか,とか尋ねられるといい。実際,喋ったほうは喋ったことを忘れていて,時間をおいて文献を送ったら,何でお前,おれのほしがっているものを知ってるんだ,と言われたこともある。以降常連客となった彼は,大学教員,かつ大学の要職者。先生方というのは,役職につくと,専門外のことを人前でしゃべらなければならなくなる。講演とか,式辞とか。これが狙い目。先生方のニーズには,専門外のこと,周辺領域のことを知りたい,確認したい,というニーズもかなりあるのである」
ニーズに基づく創造.SDIにおける創造性の必要性.
*創造的AI研究 静岡大学須藤明人研究室
http://sudo.inf.shizuoka.ac.jp/
非常に面白い.研究成果など確認しておかねば.社会人学生募集していたりしないかな.
聞いた限り、未来予測AIとしてのw2v-mpモデルがあるべき理想,持つべき構造,に近い.
創造に関わる構造の一部が提示された.SNS抽出共起テキスト群とwiki抽出分散表現知識グラフから得られる既知組み合わせ構造を学習する創造をもたらすこの研究室の手法は,valuenexの言う?「重要領域間の空の領域が重要」という概念に近いかもしれず?,下記に書いた?空ベクトルに近いかもしれない.w2v-mpモデルが予測的・創造的(特許の未来予測とは創造のことだ)に動いている(ように見え・・・なくもない)理由がおぼろげながら見えてきた気がする.w2v-mpモデルにおける歪め統合やここに記載していないベクトル処理が肝だったと言えるかもしれない.そうなるだろうと予想し作っておきながらなぜそうなったのか解析的に理解することができない状態から,ある程度開放されるか
(資源制下におけるブリコラージュ的手段は現実的な有用性が高いだろう)
意味空間上の演算は実世界における計算論的創造性に不可欠か?機械学習によるコンセプト創出手法の検討(2016)
https://www.jcss.gr.jp/meetings/jcss2016/proceedings/pdf/JCSS2016_OS05-6.pdf
「創造的な人工知能」の活用はイノベーションに直結するか? 組織内のアイデア創造プロセスを明らかにする社会シミュレーション・アプローチ(2017-2018)
https://www.taf.or.jp/files/items/1076/File/%E9%A0%88%E8%97%A4%E6%98%8E%E4%BA%BA.pdf
・w2v-mpの創造性について
気になる特許がある.
トラネキサムという単語を含むある特許だ.
1 w2v-mpのみ,この特許に高いスコアをつけた.再現もある.個性らしい.
2 w2v-mpのSHAP value highlightにおいて,「トラネキサム」がハイライトされた.w2v-mpは何らかの理由でトラネキサムに注目した.
3 教師データに,トラネキサムという単語は,含まれていない.
W2v-mpがトラネキサムに注目した理由は,教師データに含まれていたから,ではない.他に理由がある.
4 w2v-mpのpre-domain語彙に,トラネキサムという単語は,含まれている.
5 w2v-mpのpre-domainにおいて,トラネキサムとのcos類似度が0.84~0.87となるいくらかの単語,マレイン,グルコンは,教師データに含まれている.
6 w2v-mpが作り上げる構造からすると,トラネキサムと上記単語は,計算上同値とな*,「歪め統合」されているといえる.
結果 w2v-mpは教師データにあるマレインまたはグルコンの重要度に基づき,pre-domainから共起されるトラネキサムも重視し*,といえる.
(比較として,domain語彙上同じことをなし得たkeb-mpを示す)
ここまでは良い.
疑問 では,これは創造性の発露と言えるだろうか.
7 w2v-mpのpre-domainは,能動的な教師による学習から形成された知識構造とは異なる自発的な学習から形成された知識構造と例えることができ,ニーズの記載のあるコーパスより成り立っている.実際のコーパスを確認するに,トラネキサムとグルコン,マレインは,〜のような関係性である.
8 よって,「ニーズを考慮した歪め統合」となっていたといえ*,それにより見つかったこの特許は,**「w2v-mpモデルがニーズを発掘し新たな課題を見つけるという能力を発揮した結果見つかった特許である」**といえ*.ニーズを考慮したことにより,「未来予測型のAI」として働いたといえ*.
9 最後に,創造性の定義に適合するかどうかを確認する.その特許は,新規性,そして有益性,喚起性,実現可能性のいずれかがあるといえるだろうか.この場合の新規性とは,検索者が知らなかったという意味の新規性で十分だろう.これは問題ない.次に有益性,喚起性,実現可能性だが,特許の構成要素を置き換える範囲においては,まず実現可能性はあると言える.本件では構成要素となる単語の置き換えが起きているので,実現可能性があるといえる.新規性と実現可能性の提示で創造性が示されたと言えるとなれば,創造性の発露があったといえるだろう.ただし,検索者がそれを創造性と信用できなければ,創造性の発露は否定されうるだろう.信用には有益性が必要と思われる.そして信用に寄与する有益性は,有益であったと確認できる事後にしか得られない.とするならば**
~(確認中.創造性を示したと言ってよい,となるとよいのだが.
(トラネキサムとグルコン,マレインは,既存の文脈上同じ使われ方がなされるとは言いがたいだろうが,酸が付与されうる単語であるという代替可能性がある(周辺の単語を考慮する構造としていることで,最低限の実現可能性が担保できている,と言っても良いかもしれない)(解像度変換できないままでは代替候補の見落としは多くなりそうだが見落としがあっても創造性が低減するだけで大きな問題ではないか).この非文脈性と代替可能性は,創造性の種となる大きな因子だと考えている.非文脈性が過剰となればただのノイズとなるが,pre-domainがニーズベースの構造体となっているならば,ノイズではなく創造性と言えるようになるだろう.pre-domainの検討か.先が長い…)(valurnexの言うホワイトスペースにあるものを抜き出した,という評価でも良いかもしれない.手段として可能ではあるが,母集団の選び方が難しいな結論ありきでそのようにもできなくもないし.)
(web検索したところ,トラネキサムとグルコンは,化粧水の文脈では同時に現れるようだ.この特許は,ヒアルロン酸とトラネキサム酸の特許なので,見る人が見たなら,インサイトが得られたのかもしれない.AIが創造的でも,扱う側が創造的でないなら….いやまあ点眼分野専用にpre-domainを作ろうとしているので化粧水の提案をされても…いや待てよ.ああ,ロート製薬の特許でロート製薬の化粧水か…点眼と混ざっても仕方ないか…同一技術分野と捉え直すことも可能ではあるな….同一製品を保護する2つの特許,ヒアルロン酸&トラネキサム酸とヒアルロン酸&グルコン酸とを,教師のないまま同価値に調べた,と捉えるなら….いや後付にすぎるな.やはりコーパスを確認しなければ.)
(機能語の歪め統合も起きるわけだが,これはどう理解すべきだろうか.)
(AとBを変換するにそれが創造的変換と言えるには,一般的な共通要素に基づく置き換えでなく,特殊な共通要素に基づく置き換えとなるべきだろう.コーパスのバイアスの強さとその少なさを特殊な共通要素を生み出すための手段としているが、その特殊な共通要素はどうしても少量になる.より多量の特殊な共通要素を利用するための手法として,静岡大学須藤明人研究室に興味がある.創造性の量とノイズの量双方考慮しないといけないが….他に,解像度可変とすれば現状のままでもより多くの特殊な共通要素を使用できるようになるとも思われる.windowの範囲は固定しつつ、window内の形態素をランダムでドロップさせれば解像度可変になるといえばなるが…うーん、)(ルールベースの創造性で補正するか…いや喧嘩しそうだが)
(SNSコーパスからは、理解できる関係性は酸つながりぐらいしか見つからない。残念。「~美容品という名の医薬品はヘパリン類似物質とビマトプロストとワセリンとトラネキサム酸~」「~アジスロマイシン、フスコデ、トラネキサム酸飲んでて~」「~オロパタジンとポララミンとトラネキサム服用したの忘れてメコバラミン飲んじまった ~」「レボフロキサシン、トラネキサム、カルボシステイン、プランルカスト、オロパタジンってやつ 昼夜で飲ん~」「シナールとトラネキサム酸だけ4000Tとか~」「トラネキサム酸の消炎剤は目薬ですか?」「クロルヘキシジングルコン酸は医療現場でも良く使用」「悪名高きベンザルコニウムからクロルヘキシジングルコン酸塩に変」「ドルゾラミド塩酸塩・チモロールマレイン酸塩」)
(wikiコーパスからは、医薬品リストのようなページにおいて併記されていることが確認された。「一般用医薬品の種類と有効成分 フェノール クレオソート オイゲノール 塩化セチルピリジニウム グルコン酸ヘキシジン イソプロピルメチルフェノール チモール ヒノキチオール 抗炎症成分 グリチルリチン酸二カリウム グリチルレチン酸 サンシシ 止血成分 カルバゾクロム トラネキサム酸 組織修復成分 アラントイン 収斂成分 塩化ナトリウム 生薬成分」)
*SNSとwikiを組み合わせたことが本結果につながった、となると面白そうだ。しかし、単に、近傍に共通して出現する単語「酸」によりトラネキサムとグルコンなどが近似と判断され、歪め統合により代替された、と考えるほうが妥当であろう。単なる「創造性」という意味ではこれでもよいのだが、「ニーズ考慮」という意味ではなされているといえない。残念・・・。
SNSデータが絶対的に足りないか・・・。ニーズらしきものを発見してからコーパスにそのニーズらしき記載があるかどうか確かめる手法よりも、コーパスでニーズを見つけてそのニーズを見つけられているか確かめる手法がよいだろうか。結果と検索者の認知の共有という面では意味を失うが。創造がより頻繁に起きるならば前者でよいのだが。)
*単語ベクトルの類似性から別単語を取り出すのは語彙限界があり難しいな。単語生成が必要となるだろう。VAEのような手法で「単語を生成」できるだろうか.離散という意味では同じだが,語彙は化合物のように有限でないため,…無理やり漢字のような表意文字を持ってこれば可能か?
*mat2vec
https://github.com/materialsintelligence/mat2vec
論文紹介
https://speakerdeck.com/resnant/lun-wen-shao-jie-unsupervised-word-embeddings-capture-latent-knowledge-from-materials-science-literature
*クラスタリングは、正しくないからこそそこに創造性が生まれるという意味でも、基本的に良い手法ではないかな。セグメンテーションは逆。
* 渡辺星(静岡大学),藤原直哉(東北大学),須藤明人(静岡大学)(201911)
「Word Embeddingsを用いた斬新さと手堅さを兼ね備えた経済学における研究テーマの自動生成」
第17回情報学ワークショップ Workshop on Informatics 2019
https://sites.google.com/view/winf2019/awards
ああ参加すりゃよかった.WiNFか覚えとこう.諸事情により今はこちらから動き難いから声かけられないな・・・
*すでに存在するものから何かを生み出す創造性として,知財でよく使われる手法は次の通り.これを組み込むだけで良いかもしれない.(まあいわゆるデザイン手法なわけだが)
1ある用途に用いられる解決手段から検索(もの要素A用途B→もの要素A検索)
2検索された解決手段の課題をマイニングで抽出(もの要素A検索→課題C発見),課題の上位概念化(課題C→課題CC)…
3抽出された課題から検索(課題CC検索),その課題を問題とする用途をテキストマイニングで上位から抽出(用途D)
4用途ごとに手段の適用可能性を検討(用途D―もの要素A相関→実現可能性)…
5用途と手段の組み合わせ検索から実用性を確認(用途D―もの要素A検索→市場性)…
*なぜデザイン思考はゴミみたいなアイデアを量産してしまうのか
https://note.com/studies_ceo/n/nd3c499f24052
*特許文書を対象とした因果関係抽出に基づく発明の新規用途探索
https://www.jstage.jst.go.jp/article/pjsai/JSAI2018/0/JSAI2018_2L103/_pdf/-char/ja
http://hawk.ci.seikei.ac.jp/u-cees/
*阿部 慶賀(2019)
創造性はどこからくるか: 潜在処理,外的資源,身体性から考える (越境する認知科学)
共立出版
https://www.kyoritsu-pub.co.jp/bookdetail/9784320094628
「「創造性」というと,優れた人間が発揮する才能と思われがちだ。しかし近年の認知科学研究は,創造性は個人の才能ではなく,他者との協同や外化など,偏在する外部資源との相互作用なくしては成り立たないことを明らかにしてきた。一方,創造的思考を支える心的メカニズムの研究からは,アイデアの「生みの苦しみ」は単なる停滞ではないことや潜在的に洞察の準備が進んでいることも明らかにしつつある。
こうした知見を背景に,創造性はそれに特化したメカニズムや処理機構を前提としなくとも説明できる,ということが研究者間で合意を得つつある」
p86~99「三人寄れば文殊の知恵は本当か~協同する他者は実在しなくてもよいか~心のなかで作られる他者~創造性は一人で発揮できるか.問題を多角的に捉える契機.自己観察条件↓.偽他者観察条件=.他者成績条件はもともと早く解ける人にとっては軽微.自己の現在状態の評価に作用.「ここまでの知見を振り返ると,「創造性は環境や外敵資源の中にこそある」とは言い切れなさそうだ.~協同の効果は強力なものだが~でしか生まれないというわけでもない.他者を創造し,その他者と協同することができる.~むしろ重要な点は,他者の存在の有無や外的資源と心的処理の線引ではなく,他者を意識することによる自身の偏った見方や制約の見直しにあると言えるだろう.~」
AIでもある程度中間リークをさせるべきか・・・いや見直しの意味がないか.オントロジーベースの分散表現でこれは実現されているとも言えるし,ヒトが介在して顧客ベースでpre-domainが作られている時点でこれは実現されているとも言える.
p145~「ひらめきの突発性はランダムに外部からアイディアを受信するからではなく,~処理として無自覚に進む自身の思考の変化に気づくことで起きる.~外的資源として寄与の大きいものとしては,協同する他者が挙げられる~他者は,必ずしも生身の実在する人間でなくともよい~創造性を特定の個人の才能として捉える見方は主流ではなく,人間一般に備わる認知機能の作用から生じるものとしてみている.~制約論的アプローチに従うと,試行錯誤を通して初期の誤った制約を解消することが洞察に至る堅実な方法だと言える」
読書猿さんの,アイディア大全や問題解決大全を振り返ると面白そうだな・・・
創造性とは、「複数の個性ベクトルに対し作用する組み換えベクター」による個性ベクトルの変異のようなもの、と考えるのも面白そうだ。そうならばベクターを作ればよいわけで。
(DACI(Driver,Approver,Contributors,Informed)の役割を果たす構造を含めることも重要に思える)(ティール組織のadvice processを有効とするような…)
*Ayano Fujiwara(202003)
Who is Generating New Innovations? : An Analysis of Blockchain Engineers
https://ieeexplore.ieee.org/abstract/document/9081416
個人の専門性が高まりすぎると集合しての多様性におけるイノベーションは阻害される。「自己内多様性」が重要、と示唆している?。
エキスパートシステムの組み合わせはイノベーションを生まない、という意味で納得であるが、それ以上はどう考えたものか。創造的AIはAIにエキスパートシステムを組み込んで曖昧にするぐらいでやはりちょうどよいのか?。AIによってエキスパートシステム同等の理論化ができつつある昨今であるがendtoendで自己内多様性を維持することができるのだろうか。
*清水大地(201906)
創造性の枠組み・測定手法に関するレビュー論文の紹介
cognitive studies 26(2) 283-290
https://www.jstage.jst.go.jp/article/jcss/26/2/26_283/_pdf/-char/ja
読み込むこと.
*歪め統合を利用したdata augumentationで入力を「実現可能に多様化」し、2d-CNNを適用したり複数のモデルの個性を組み上げることにより、「より多く」の「明確性の高い」創造的提案がなされうるかもしれない。予想外性は低減するだろうが。
*創造性の高い脳のネットワークに関与する、3つの重要なサブネットワーク
「1つめは「デフォルト・モード・ネットワーク(Default mode network)」
特に思考、関心、注意を伴わない、安静時の「基礎状態」とも呼べる脳の活動だ。これは空想に耽ったり、白昼夢を見るときなどに活動的になるといわれ、独創的なアイデアを考えつくためのブレインストーミングで重要な役割を果たすと研究者たちは考えている。
2つめは「実行機能ネットワーク(Executice control network)」
思い描くアイデアに集中したり、それをコントロールしたりする場合に活動する脳のネットワークだ。クリエイティヴなアイデアが実際に機能するかどうかを評価し、また目標に合わせて修正を加えたり、切り捨てるかどうかを判断する上で重要になるという。
3つめは「顕著性ネットワーク(Salience Network)」
「デフォルト・モード・ネットワーク」でのアイデア生成と、「実行機能ネットワーク」でのアイデア評価を交互に行うために重要だとされている。いわゆる、ふたつのネットワークを交互に切り替えるスイッチのような役割がある」
https://wired.jp/2018/03/31/brain-network-creative-person/
組換→実現可能性→(繰り返し)→創造,かな?.
実現可能性判断をヒトの担当とした場合,繰り返し部分の実装が難しそうかな.
*創造性とは自分を組み替えること。それには、まず、組み替えるべき幹が必要。
幹を作るのは豊富なインプット。リベラルアーツなどはその一部。
幹が小さければ、情報はスルーし組み換えは起こらない。
幹が大きければ、微細な情報でも幹に当たりインサイトを得て組み換えができうる。
幹のベースは主体性。主体性は多分教えられない。各人の望むものを与えることである程度はコントロールできるが、それに意味はあるのか。
最近読んだ書籍の内容をまとめるとこんなところか。
*田中るみ子,中山伸(2019)
文章からの化学物質名を含む単語の認識法の確立と化学物質名 の選択法の検討-特許公開公報を用いて
情報知識学会誌 2019 Vol. 29, No. 3 238-246
https://www.jstage.jst.go.jp/article/jsik/29/3/29_2019_038/_pdf/-char/ja
文章からの化学物質名を含む単語の認識参考.
201912頃,物質記載特許重視に変更したが,どうすべきかまだ考えがまとまっていない.現状,教師を緩めeswで抽出しており,認知に基づく創造的(というかランダム)な特許を上位に抽出できているが,特定の固有名詞に対する認知ならともかく,化学物質名に対する認知など当てにならない.より汎的な別の手法を検討すべきだろう.
*創造性を付与するに当たり,それをインサイトやイノベーションにつなげるためには,イノベーションの道筋の幹(道は限定されるものではないが幹はあると仮定)に沿った構造とできうることが必要となる.
例えば,次が参考となる.
一橋大学イノベーションセンターのResearch liblary
例えば
革新的な医薬の探索開発過程の事例研究
http://pubs.iir.hit-u.ac.jp/admin/ja/pdfs/show/1868
主体がどこに移動しそれぞれの主体に必要であったデータや情報はなんであったか,など.
歪め統合を行うに当たっての基礎知識としている.
*東北大学大学院法学研究科 吉永一行教授
*w2vkeb-mp組み込み。w2v-mpの結果を教師に加え再学習したモデル。上位概念下位概念の発散収束コントロールに能性テスト用。
*例えば、〜酸ナトリウムから単語ナトリウムを取り出し、ナトリウムは燃えるから〜酸ナトリウムも燃える、とするのは間違い。
これを創造性の視点から見た場合どう考えればよいのか。実現可能である提示ではないわけだが……。
うーん、適切なドメインの事前知識を与えていれば、上記のような間違いが起きる可能性は少ないから、実質的に問題はない、ある程度の実現可能性は担保される、と考えればよいのか?。
上記の例では化学ドメインでは不十分で無機ドメインと有機ドメインで切り分ける必要があったといえるだろうか…
少々恣意性が高すぎる気もするな……。
ドメインの違いと形態素区切りによる影響につき、どこかで検証しておこう。
*Research on Product Design Education Based on Evaluation Grid Method
https://ieeexplore.ieee.org/document/9066457
プロダクトデザイン教育に関して言えば、従来の授業では、机上調査や単純な現地調査、非厳格なインタビューなどを主な手段としており、ユーザーの真のニーズや嗜好を正確かつ体系的に把握することができていないことが多い。
本研究の目的は、プロダクトデザイン教育の新たな道筋を探り、学生の創造性を刺激し、学生が設計した概念スキームがユーザーの嗜好を正確に捉えていることを確認することである。
まず、市場調査や特許照会などで設計対象のサンプルデータを収集し、みりょくエンジニアリングの評価グリッド法(EGM)を用いて設計対象の魅力的な要素を抽出することが求められています。
そして、アンケート調査により利用者や潜在的な利用者の魅力評価を得て、定量化理論Ⅰ型(QTT□)を用いてアンケートデータの分析を行う。
最後に、デザイン対象の具体的な特性と需要意図との相関関係を構築し、学生がデザインイノベーションを行う際の参考とすることができる。
本研究は、学生がプロダクトデザインの実習を実施し、現在のプロダクトデザイン教育の科学的・厳密性を向上させるために役立つ。
www.DeepL.com/Translator(無料版)で翻訳しました。
*丸山 知能というものは、分かれば分かるほど先に行ってしまうという感じはします。この50~60年、私たちがやってきたのはそういうこと。では今のレベルで、どこに(知能とそうでないものの)線を引くかということです。
丸山宏氏
GAN(Generative Adversarial Network)のようなものはクリエイティブなことをやっているように見えるけれど、実際にやっているのは、ある統計モデルを作り、そこからサンプリングして出てきたものが、たまたま見栄えがいいと「創造的なもの」に感じる。
よく考えてみれば、バウンダリー(境界)がはっきりしていて、空間がはっきり定義されていて、なおかつ、その中からサンプリングしたものがいいか悪いかがある程度分かっているような問題に関しては、「クリエイティブ」と呼ぶかどうかは別として、ディープラーニングでうまくいく。ただし人は、ほんの時々であっても、今までに全くないものを考えるという能力があって、そこについてはまだ大きなギャップがあります。
〜
丸山 私はコンピューターサイエンスの観点から見ると、ディープラーニングの最大の功績は、「計算ってチューリング機械だけじゃない」ということを教えてくれたのが最大の功績のような気がします。
それは2つのことを言っていて、1つはチューリング機械っていうのは基本的に離散領域の計算しかしない。それに対してディープラーニングはベースのモデルは連続領域のモデルだということ。もう1つはもっと大事なことで、ディープラーニングが出てきたことで初めて帰納的(インダクティブ)なプログラミングができる。つまり計算のステップを与えるのではなく、計算の例を与えることによってプログラミングをするということが、ディープラーニングで初めてできるようになった。
〜
問題はその先なんですね。「再現可能計算」と呼んでいますが、「特定の入出力に関してはこれと同じことをやれ、でも、ここで指定されていないものに関しては、良きに計らえ」というようなタイプのプログラミング、これをディープラーニングが帰納的にやっている。
https://www.atmarkit.co.jp/ait/spv/2006/23/news021_2.html
参加者間の認識のレベルがかなり違うような記事かなという印象。
*日本認知科学会第37回大会 JCSS2020
*扁桃体の役割を射程に入れた「面白い」の言語理論の提案
中村太戯留
意味づけ論、不調和の解消とユーモア、偏桃体の役割についての見やすい総括含む。
AIによる創造性においては、AIと人との不調和段階をどう処理するかの課題が存在するはず・・・。偏桃体のような「ヒトが関連性を感知しやすくするための何らかの装置」は重要なのだろう。「創造性モデルにおいて高sharp値を示した一部の単語について、置き換え候補を自動提示する手段」はありかもしれない。
*「思い込み」の認知過程の定式化に向けて:画像回転課題と事前制約の関係の分析
亀井暁孝,日髙昇平
「人は,現象を説明可能な解釈が複数存在するときでも一つあるいは少数の解釈を選ぶ傾向にある.•論理的には複数存在する解釈の候補から少数を無意識に選択し信じる人の認知的な情報処理を,本研究では「思い込み」と呼ぶ.
クワス算は演算規則の解釈を例に帰納推論だけでは成立しない「思い込み」的な推論方法の存在を指摘している.
観測された現象を説明可能とする解釈が複数存在するとき,多数の事例学習を必要とせず,特定解釈の選択を可能とする推論方法は何かという問いになる」
ええと、ものの集まり(集合)と、その要素間の関係性(構造)をあわせたものが群で・・・
メタ学習を思い込みから説明できるのかな。思い込みの追加と言える知識グラフの追加は必要であるところ、しかしend2endに組み込むのではなく、多くの選択肢を形成した学習後におこなうとよいだろう、専門知識は後半で補正的に、との考えでやはり良さそう?
位数・・・対称性の高さがある時少数学習・・・構造が単純な分布という意味??
関連性の低い対象間の共通点探索プロセスーカテゴリ判断課題との関連による検討
山川真由・清河幸子
「固定的な見方の解消とは**「目立たない」知識を活性化させること**」
目立たない、か・・・上位概念はどうなのだろうな・・・
「関連性の低い2つの対象間での共通点の探索は対象の「目立たない」知識の活性化を促進する山川・清河(2020), 山川・清河・猪原(2017)」
tfidf embeddings/ cluste visはその性質から「関連性の低い2つの対象間での共通点の探索」を行うことができるが、tfidf embeddings/ cluste visによる補正を創造性モデルに直接つなげると良いのだろうか・・・
https://qiita.com/kzuzuo/items/8a80d8974bf3a7db7e54
創造性には「間違えることが必須」と考えていたが、「より弱い特徴も重視する視点が必須(結果として間違えやすくなるだろう)」、と切り替えたほうが良いのか。そうするならやはり、創造的なモデルと知識グラフは切り離しておいたほうがよさそうだ。
まあ、この発表では仮説において有意な相関が取れなかったようだけれど・・・これはいつもそのような思考をするわけではない、きっかけを与える装置が必要、ということなのかも。
背景文脈が虚記憶の生起に及ぼす影響
牧岡省吾†,神浦駿吾
「DRMパラダイムとは•相互に意味的関連のある単語リストを呈示し,後に自由再生をさせると,実際には呈示されていない意味的関連の強い単語が誤って再生される(Deese, 1959) .• Roediger & McDermott (1995) がこれを発展させ,DRM パラダイムを考案した.学習時にルアー項目(例: 空) の連想語(例: 星,月など) から成り立つリストを呈示し,テスト時には学習項目,ルアー項目,その他の未学習項目からなるリストを呈示して再認判断を求める.するとルアー項目は,他の未学習項目と比較して,高い確率で誤って再認される」
洞察問題
創造性のキワをつかむ
13:35~14:05:招待講演1:ネガティブな感性と創造性
(石津智大先生)
悲しみ:安全な心理的距離、醜いが超える-偏桃体・運動皮質
14:05~14:35:招待講演2:創造性の引き出しは手を加えない中にある
(中邑賢龍先生)
14:35~14:50:話題提供1:創造性指標のキモとキワ
(石黒千晶先生)
14:50~15:05:話題提供2:創造性評価の一貫性
(寺井仁先生)
*磯野誠(2020)
ビジョニングによる製品アイデア創出における認知プロセス
https://www.jstage.jst.go.jp/article/jssdj/67/2/67_2_1/_article/-char/ja
歪め統合と絡めて、何が足りないのか考えてみよう。
*教師あり(w2vmp,kebmp,BERT)で単語ベース、教師なし(tfidf embeddings cluster vis,etc)で構造ベース、これら組み合わせだけで十分に創造性を発揮している、と言ってもよいのではという気がしてきた。
教師ありは例えば教えたラタノプロスト等固有名詞を掴んでいるし、教師なしは例えば水性組成物を掴み固有名詞を捨てるように調整できている。結果として固有名詞が入れ替わった場合にも対応できている。…創造性とは言わないか。
*encoderとdecoderは圧縮ー解凍のようなもの。
encoderの段階で錯視が生まれる?。
創造性は、decoderの解凍ミスにより生まれて易いと考えていたが、
創造性も、主にencoderで生まれているのでは?
もしそうだとするならば、「最適なencode」というものは存在せず、「個性的なencode」が存在するのではないか。個性の正体は圧縮の種類なのではないか。
そうであるなら、個性をどう扱うかを決める多様性評価につき、より真面目に議論すべきなのかもしれない。
同じ情報から異なるencodeがなされる点について、そのコントロールをどうすれば任意にできるのかについて、より真面目に議論すべきなのかもしれない。同じ評価基準ではなく個性ごとの評価基準をどう求めるかについて、より真面目に議論すべきなのかもしれない。
(と同時に、encoderを重視していない?GTP-3のようなモデルには先がないのかなと思ったり。mbartやmT5の方向が順当な未来かなぁ。)
*Prof. George M. Whitesides
Curiosity and Science
https://onlinelibrary.wiley.com/doi/abs/10.1002/anie.201800684
「自然や社会を注意深く観察するために好奇心を出発点にすることは、些細なことではないスキルであり、新たな知的活動や冒険の出発点となります。それは、科学における創造性に不可欠な要素であり、新しいアイデアを融通の利かない専門家の正統性に押し込めるきっかけにもなります。」
展望:
当初のモチベーションは,市販AIの性能が今ひとつであったためそれを補完できるAIを作ること,ついで「個人用アシスタントAI」を作ること,「未来予測型の提示をするAI」を作ること,だ.
個性把握の先に,それらがある,それらとなっていることが確認できる,と思っている.
VALUENEXデータやいわゆるIPランドスケープから得られる「予測型のコーパスやSNSなどニーズ記載のあるコーパス」を用い,「「類義・関連語」がそれぞれのコーパスが示す価値観に基づき「歪め統合」されるよう」,言い換えればAIが認識するパターンをより適切になるように歪めそして統合されるよう,それぞれの分散表現を作り(述べていないが,作っている.),作られたそれぞれの**「価値観(概念・意味記憶・感受性・個人の世界モデル)」に基づく「個性」を適切に評価**すれば(できれば),教えていない正答を見出すAI,未来予測型AIは実現可能なはずだ.
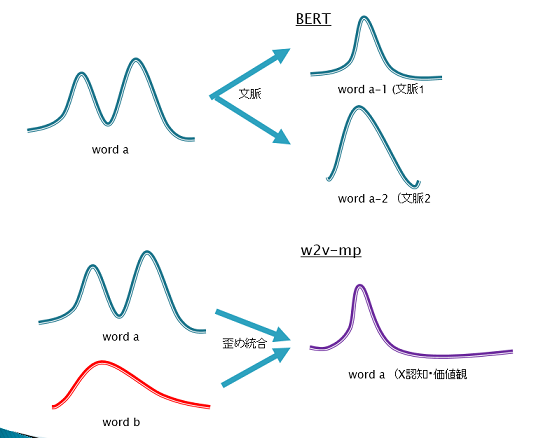
歪め統合のイメージは、補足すると次の通り。
辞書的には、サッカーという単語は、多義語として、ボールをける云々で表現されている。
あるヒトAは、「サッカー」という単語に対し、「雨」や「雷」を思い浮かべるとする。
「あるヒトAの認知」に従った結果が欲しいタスクにおいては、辞書的・汎的な多義語を無視して、「サッカー」と「雨」と「雷」を同義に表現して欲しい。
ここでいう歪め統合とは、この状況下、単語「サッカー」と「雨」と「雷」を、「一つの類似分散表現に押し込める」作業のことをいう。
「辞書的に正しい意味で表現することを無視して、特定の認知に沿った単語の畳み込みをすること」を、「歪め統合」と表現している。
*「歪め統合」とは、クワイン「経験主義のドグマ」に記載のある、「認知的同義性」のこと、と言っても良いかもしれない。
やりたいことのイメージとしては,
SNSに「X製品のAはZだ」
=> その価値観に基づく歪め統合された分散表現を得る
=> X製品またはAで調査したときより上位に
<= 多様性評価しつつ補正(偏った価値観は正解の元でもあるがノイズの元でもあるから)
*教師データは過去から得られまたそうでないといけない.教師データのみから学習したモデルは未来の特許に食いつくとは限らない.7そこで,「教師データより一般的な情報から概念を学ぶモデル」が必要となる.「教師データより一般的な情報から概念を学ぶモデル」の正解率は低下しやすい.このモデルを活かすために,多様性を用いて他のモデルがフォローする体制を作っている.
*「個性・価値観をもつ分散表現・モデル」と,「多様性評価」という2つのポイントが混在しており,ポイントがつかみにくい文章となっている点は認める.しかし,結果を得るためにはその2つは双方必要であり切り離せない.個性がなければ多様性など発生しないし,多様性がなければ評価する意味もない(確率的多様性を評価するなら平均で十分).どこかでまとめ直す予定.
*比較的長距離の記憶をもたせる試みがなされてきているが,自分は入力した文章全体を記憶しても足りないと思っている.自然言語において最も必要な長距離記憶とは,入力した文章全体を超えた記憶,低バイアスの「辞書」または高バイアスの「価値観(概念・意味記憶・感受性)」,へのアノテーションではないかと.このうち「辞書」に注目したものがBERTだと思っている.自分は「価値観」に注目している.(辞書に該当するものは他にベイジアンネットワークやオントロジー,知識グラフなどか.)
(言語とはそも意味以上の情報を「失っている表現方法」なのだから,そこに価値観を「加えて」「意味を情報に再変換」する必要がある,と言っても良い.そう考えると,価値観は画像イメージや発意者の脳波,表情,イントネーションや書誌的立場でも良いな.(複数にソースを学習に利用することをマルチモーダル学習と呼ぶらしい.主体の概念はあるのだろうか.)
西田京介(201911)
事前学習言語モデルを用いたVision & Languageの動向 / A Survey of Pre-trained Language Models for Vision & Language
https://speakerdeck.com/kyoun/a-survey-of-pre-trained-language-models-for-vision-and-language/
VisualBERT等々)
(今のところ価値観をニーズ等からのバイアスに求めているが,特許の技術的範囲という価値観が必要なら明細からのバイアスに求めるほうが良いだろうとも思っている.)(テキストは知識表現,フルテキストは概念表現.に近いか.要約請求項は知識表現,明細は請求の範囲理解のための概念表現,価値観・個性に課題を加えたものは認知を元にした検索のための概念表現,に該当と言えばまとまりそうだ。)(概念をルールベースで作ってしまうと個性が固定され多様性が減少する(やるやらないの差はあるが,それは永遠に維持できるものではない).事業で重要な差異化の参考とする概念づくりであれば,)
*動的フィードバックがあると良い.フィードバックにより変化させるべき対象は,自然言語では教師データでなく,概念だろう.どこかでpretrained word2vecモデルの動的変更システムを組み込むこととしたい.()
*キーワード検索でしかなかった検索は、意味検索となり、やっと情報検索になろうとしている。
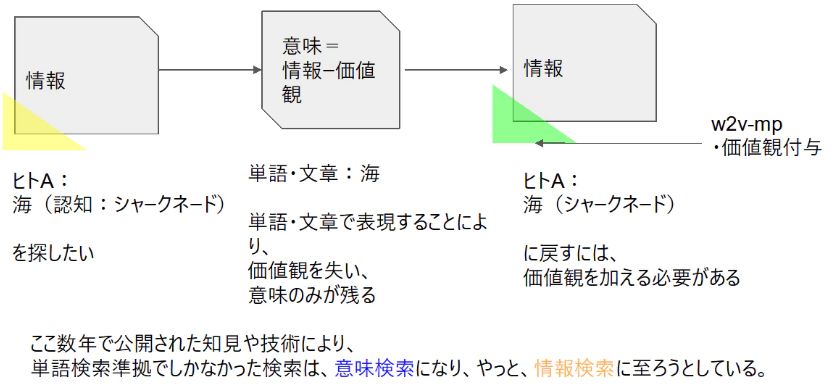
*画像分野であれば,個性を考慮する必要などなく,TensorFlow Hubなどから汎用の事前学習モデルを流用してきてもほぼ問題はないのだろう.誰が観るかによってゴリラがサルになったりはしない.しかし自然言語分野では,受け手が持つ概念により理解が大きく異なりえる.ゴリラとの記載からゴリラでなく特定の人と認識する人もいる.ハゲとの記載から京都御髪神社の小学生の絵馬,お父さんのようにハゲませんように,を認識する人もいる(おい)(個人的には,画像では価値観でなく常識,錯視,特にヒトなら後天的に学ぶ「平面から立体を予測する機能」の付加,がまだ足りないとは思っている.これをベースとして転移学習すればより性能は高くなるのでがないかな.すでになされているだろうけれど.(2018年にGQNあり.GQNはword2vecなどテキストの分散表現の影響を受けた,立体概念ベクトル,注目を戻すという点でBERTの画像版,といった印象.とりあえず動画と解説 https://youtu.be/RBJFngN33Qo
https://www.slideshare.net/mobile/MasayaKaneko/neural-scene-representation-and-rendering-33d
世界モデルなど認知的観点との関わり?.画像の場合は視点はどれでも平等で連続なので積和で良く視点のパラメータ化が可能なのだろう.自然言語の場合は概念のパラメータ化に相当するだろうがどうだろうか.自然言語では概念が平等でも連続でもないので少なくとも積和では足りないだろうか.)(Google AI Blog: Moving Camera, Moving People: A Deep Learning Approach to Depth Prediction
https://ai.googleblog.com/2019/05/moving-camera-moving-people-deep.html
運動視差の利用.差のみに注目するなら可能性はあるか.枠のあるベクトル内の差というくびきから逃れた差を求めるアルゴリズムであれば自然言語における概念を表現できるか.))(単語を認識する脳の領域と立体視を行う脳の領域は比較的近い。もしかしたら、単語の分散表現ベクトルとその座標表現は、予想以上に本質的なのかもしれない。)
(画像の立体化技術の一つ。特許調査の理想の一つは、調査対象の画像から立体化するなどしつつ構成を取り出し、文章化して調査することだろう。その過程において画像の立体化は必須。方法や組成は画像から抽出し難いであろうから立体化は手段の一つにしかならないが。総合的なリバースエンジニアリング手法ってあるのかな? )
(画像から構成を取り出す特許等検索システムについて。
自分なら、
テキスト上の構成から、ノードに構成、エッジに相対位置など示す知識グラフを作り、
画像から概要3次元化したデータに知識グラフを適用し、3次元構造を補正し、比較する、コードとするかな。
テキストを後半に置けば、クレームを作ることができる。エッジの特性を変化させれば、視座の多様性を設定することもできる。)
*自然言語系の機械学習において学習データの問題は汎化とまとめられていることが多い気がするが、
個人的には、一般的な構造と個別構造を同時に備える教師データが必要だという点を問題視し、より多くの議論をするべきだと思う。
個人的には、この2つは全く別に学習させる必要があると思う。
この2つを分けないことで,あえてタスクを難しくしている気がする.
難しいタスクを難しいまま処理することは理学的で意味はあるが,簡単なタスクにできるよう考えることがは,実用面に向かうべき現状において最も重要になるのではないだろうか.
*マルチタスク学習と多様性評価
複数のドメインに基づき訓練するところまでは共通するが,マルチタスク学習は全タスクでの平均的な性能を最適化する転移学習を用いた「汎化手法」であるのに対し,多様性評価手法はタスク間の平均でないデータの個性をモデルの個性に基づき抽出する「専門化手法」である点が異なる.
*意味論でなく語用論に焦点を当てている,といえばよいのか?
*創造性まで含めて,文章というものの文脈的意味の単一化容易性と情報の単一化非容易性の把握とその改善がテーマ,と表現すればよいのか?
*今のAIは、写真技術が発達した頃の絵画のように、目的の呪いにかかっている気がする。今後のAIは、ピカソが絵画において写真ではできない多視点や過去の記憶など含めた多面を一つに押し込める手法、キュビスムを生み出したように、AIでしかできない手法を生み出さないといけないのだと思う。
優れた写真や絵画は、1視点においても、受け手のヒト認知を引きずり出し結果として多面的な表現をするが、ヒト認知は安定しない。
ヒト認知を最初から押し込んでおきヒト認知に依存せずとも多面的に表現することが必要となってくるのではないか。
*個人的には、「眼の機械化」ができると良いな、と妄想している。
目玉を機械化してやりたいことは、「文章を画像のように直接脳に入力し理解すること」だ。
「文章を読まずとも一目で大意を理解できるようにすること。」これは多分、機械化した目でしか?できない(こともないけど脳に接続することは必要だろう)。
自然言語処理、文章処理の究極は、「多様体のある次元の概念への適切な圧縮」だろうが、これが適切にできたとしても、脳に直接入力しない限り、不自由な表現、例えば類似する単語で表現する「要約」など、をしなければならず、不可解な受け手の認知に頼ることになるだろう。これに不満を感じる。
この技術の可能性を探してもいる。
*自分がほしい機能は、何らかの文章を作成した際、総合的で任意の関連文章をリアルタイムで提示する機能だ。
まず関連法令、関連特許、関連商品。
表現を揃えることが難しい。上位概念下位概念変換や言い換え要約必須。これら畳み込む・統合した分散表現がほしい(見分けるのではなく)
コード:
求めに応じ,コードを整理した後公開予定.(記載しない2,3の工夫がさらにあるだけだが.)
code
個人的には,オープンベースとなっているAI技術の利用に費用がかかリすぎる現状が気に入らない.費用がかかる根本的な理由はクラウドの使用だと考えているが,ベンダーはクラウド前提から離れようとしない.
mail2mailの非クラウド形式(エッジAIとは違うか?)に整え,知り合いの個人や中小企業からノウハウ含め提供しようかと考えている.
安価なハード,Raspberry Pi,coral,Jetson Nanoなどで動く範囲にしたい.Docker imageを利用した配布が最も容易だろうか.
=> docker image作成.x86用とarm64用.git準備.
=> raspberry piでBERTを動かせないか試行中…メモリが少なすぎ無理そうだが.あと9GBほど.zramでも限界が.
*Raspberry Pi4 4GB & ALBERTならば,なんとかなるであろうか?.
以上.
追記
*BERT: 201903~
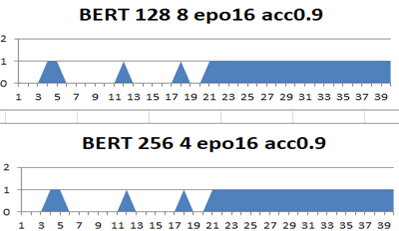
●multilingual model fine-tuned BERT試行.
・正解候補に全問正答.しかし不正解候補については明確に間違えている部分も.
・様々な制限により他モデルと同一の入力としていないが,標準のmultilingual modelからのfine tuningでは,recallが高いという個性が得られそうか.他のモデルを補いそうだ.
・結果はほぼ1 or 0.
code
*BERTの個性はSHAPではわからない.attentionから予想した次の記事を参考にしよう.
・Deconstructing BERT: Distilling 6 Patterns from 100 Million Parameters
https://towardsdatascience.com/deconstructing-bert-distilling-6-patterns-from-100-million-parameters-b49113672f77
https://towardsdatascience.com/deconstructing-bert-part-2-visualizing-the-inner-workings-of-attention-60a16d86b5c1
・BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model
https://arxiv.org/abs/1902.04094
マルコフ確率場言語モデル.フルコネクトかつattentionでwindow抽出した独立単語群と理解して良い?.ならattentionの精度が性能に直結か?.attentionには改良の余地がありそうだからまだ性能向上する?.近傍単語を重要視しているのは純粋に学習によるものであって,CNNのような強制的な構造化によるものではない?.てことは相補的になり得る?
・汎用言語表現モデルBERTの内部動作を解明してみる
https://qiita.com/Kosuke-Szk/items/d49e2127bf95a1a8e19f
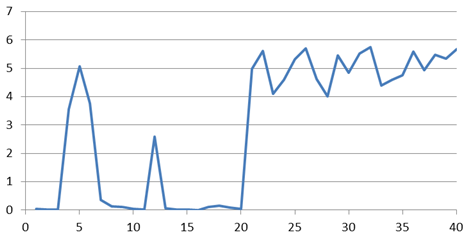
●multilingual model fine-tuned BERTを市販AIの代替とし,多様性評価手法総合判定試行.
・評価データにおいて(正解に配置すべきであった3,4(図の4,5)を除く条件で),市販AIより明確に,「上位すべてが正解候補となる理想状態」となった.(市販AIとの比較を出すべきだろうが,評価データ不足の現状では差が適切に示されず強調され過ぎと思われたため当面示さず.).
・各モデルは40問中3問は正答しない.multilingual model fine-tuned BERTでも2問正答していない.その条件下,多様性評価手法を用い総合判定させることにより,正答しない問は0となった.つまり,多様性評価手法は,現状の簡易方法でも,(使用した条件の)BERTより優れた結果を出すことができている.市販AIに多様性評価手法を適用したときと同じように.
・この評価データセットではこれ以上の評価はできない.そろそろデータも蓄積されてきた.教師データの再検討と,評価データセットの作り直しをするべきか.(モデルの個性という偏った課題であるため,標準データセットが用意しがたいのが悩みどころ.)(AIの補完をヒトで行っているわけだが,現状,実データで見落とし等の問題が見られていない.)
*予想よりは,処理速度は速くメモリ負荷も軽かった.BERT実装しておこう.何でも食って性能向上できうるってのはこの個性,多様性評価手法の良いとこだ.
●実データで,multilingual model fine-tuned BERT試行.
・eval_accuracy = 0.9.しかし評価ほぼ1のFPが目立つ.意外と単語レベルでは簡単な問題でFNも.
・文字ベース512制限では情報量が少なすぎるのか,標準モデルは特許情報を全く食っていないこともあり学習済みの文脈情報とずれすぎているのか,判定器のコード修正が必要なのか・・・.改良必要だ・・・(個人的には,文法構造自体にはある程度の理論的必然性があり,それを壊しすぎると限界があるのでは,と思っている.サブワードはOOVを無くすという当面の課題の解決には良いのだが,やりすぎてもいけないのでは.)(日本語は主体も語順も助詞も多様なので,文法構造を壊してもそれほど大きな問題とはならないとも思うが.)(どの言語でも文法とは結果として見られる傾向であって従うべき理論に昇華されてはいないという意見もある.)
*vocab数の問題もあるかもしれない。vocab内の単語のみで評価するのでFP・・・XORを考慮できないと仮定するならつじつまが合わないか?。自前の事前学習は現実的ではないが・・・
*過学習はeval_lossの傾向からすると、していないように見える。
●評価データで,黒川河原研BERT日本語Pretrainedモデルfine-tuned BERT試行.
・予想以上に[UNK]が多い,eval_accuracy = 0.675.
・文字ベースではFP多量かつ意味希薄化,単語ベースでは[UNK]多量かつ語彙限界.sentencepieceモデルは中間だろうか.BERTでは巨大なコーパスを食い文脈を徹底的に見分ける方向が本筋だと思うのだが,上記ほか様々な制限(たとえば入力の制限.入力自体が文脈を分けるほどの情報量を持つことができない?)があるため,hotlinkのように,分野別に学習したモデルを使うのが適切と言えるのかもしれない.しかし,BERTの事前学習は負荷が大きすぎる.実現可能性においては文字レベルに分があるが,有効性においては単語レベルに分があるだろう.どうするか・・・.結果に差がなかったため,直和直積concatの有効性は低いだろう.内容語に限定してみるか.(特許の名称要約請求項までであり辞書的なモデルに食わせることを条件とするならば,前述の理由に加え,体言止めが多いこと,日本語らしからず述語の重要性が低い?ことから,やはり機能語を除いても良いように思える.)
●実データで,multilingual model fine-tuned BERT(名詞限定)試行.
・eval_accuracy = 0.9.個別確認しかできていないが,市販AIが見逃す正解を掴んでいる.名詞限定により非限定よりもFPが減少した.
●評価データ,実データで,黒川河原研BERT日本語Pretrainedモデルfine-tuned BERT(名詞限定・tokenization.pyコメントアウトなし)試行.
・eval_accuracy = 0.9.1サンプルに1箇所ほど[UNK]あり.評価データから得られた波形はmultilingual modelと変わらず.個別確認しかできていないが,市販AIが見逃す正解を掴んでいる.黒川河原研モデルはmultilingual modelより多少,良いかもしれない.
(AttentionがBERTの性能に主因子であるとして、self-attentionが文章内でより強い意味を示すであろう名詞のみを使い計算されているので、文脈が考慮されすぎず、このような結果になるのであろうか…)(Positional encodingの意味は?。)
*BERT Rediscovers the Classical NLP Pipeline
Ian Tenney, Dipanjan Das, Ellie Pavlick
(Submitted on 15 May 2019)
Pre-trained text encoders have rapidly advanced the state of the art on many NLP tasks. We focus on one such model, BERT, and aim to quantify where linguistic information is captured within the network. We find that the model represents the steps of the traditional NLP pipeline in an interpretable and localizable way, and that the regions responsible for each step appear in the expected sequence: POS tagging, parsing, NER, semantic roles, then coreference. Qualitative analysis reveals that the model can and often does adjust this pipeline dynamically, revising lower-level decisions on the basis of disambiguating information from higher-level representations.
https://arxiv.org/abs/1905.05950
*The Bottom-up Evolution of Representations in the Transformer: A Study with Machine Translation and Language Modeling Objectives
https://arxiv.org/abs/1909.01380
https://lena-voita.github.io/posts/emnlp19_evolution.html
・・・
*BERTは優秀な(有向性がないという意味で)辞書ではあるが,「それだけでは」現実的な発展性があると感じないな・・・
(p26「情報検索の本質的目標は、単に意味を検索することではなく、それを超えた何か、すなわち情報を検索することだ」という視点において.)
*BERTは,意味論において邪魔な統制語彙を社会的認知観点に基づき避けるが,個人的認知的観点からの歪め統合をできていないはず.当面そのような個性と認識しておこう.
*試行した条件下のBERTでは,特徴抽出を自動に任せる手法よりも,特徴を任意に限定する手法のほうが適しているかもしれない.入力からのストップワード除去がクリティカルになる感覚がある.
(不要要素や同時出現要素の削減,入力値の次元圧縮,語順変更など興味深い.マルコフ確率場生成モデルという点が気になる.(語順をtfidf順に変更した場合,attentionは理解不能であった.とはいえ理解可能と言えうる箇所もあった.試す価値はあるか.BERTはその辞書的性質と入力制限から,トピックとの組み合わせにおいてより良い結果が得られそうに思える.該当トピックの文章で学習したBERTを用いるならトピックも不要かもしれないが,その場合でもトピックが動的な場合はなお課題が残っているだろう))
*厚生労働省第7回保健医療分野AI開発加速コンソーシアム資料 人工知能を用いた患者安全性向上のための事故報告からの知識抽出 https://www.mhlw.go.jp/content/10601000/000502269.pdf
文字レベルと単語レベルの直和.recallはこれで課題に対し十分なのだろうか.BERTの結果記載有り.ベースはこれ?.2016年のSoTA.
Neural Architectures for Named Entity Recognition https://arxiv.org/abs/1603.01360
*課題と教師とモデルを適切に調整すれば,少数教師は可能と思う.このまま少数教師で性能が出るようであれば,現在の教師群を雛形とした,1教師簡易無効資料調査機能を実装してみる予定.
(文章レベルやセンテンスレベルにおけるベクトルの類似から無効資料調査や権利化可能性を探る手法が流行だが,今のところ,充分と言える成果を見ない.その理由は,文体や文法の多様さの影響をネガティブにも強く受け,距離が離れすぎてしまうことがあるからかもしれない.文法から離れ単語を重視しそうなBERTからセンテンスベクトルをとる手法は現在の手法より見込みがありそうに思える.諦め,雛形を用いると現実的な成果が出る感覚がある.)(とりあえず、文章上の解像度が異なる上位概念・下位概念を同一次元で表現する手法が最低限必要だと思う.word2vecとaveragepoolingを用いたマルチウインドウCNNで擬似的に解像度統一はできるかもしれない。いや、マルチウインドウより文章の解像度を判定しウインドウサイズを決定する手法のほうが良いか。ベクトルなら、分散表現を作成する際のコーパスで調整できるか?.特許ならコーパスに明細を含めるだけである程度の成果が得られそうな感もある.)
*Facebook FAIR's WMT19 News Translation Task Submission
https://arxiv.org/abs/1907.06616
Transformer,データクリーニング,アンサンブル,全結合層拡大など.人の翻訳を超える評価.BERT対応,方向性はあっているのかな
*Ken'ichi Matsui(202001)
BERT入門
https://www.slideshare.net/matsukenbook/bert-217710964
詳細.
ある単語を類似単語との合成ベクトルに変換し新たな単語ベクトルとするのはどうだろうか.例えば,kidとplayingの合成ベクトルが,元のkidの単語ベクトルとなる,などと.
特定の単語に対し,予め統合したい単語を任意に合成しておき,「任意の歪め統合」を達成する,というのも面白いかもしれない.
(違うな.これは統合でなく分散になるな.とはいえなにかに使えそうだから覚えておこう.「任意に文脈を変更」するある程度の助けになる,かもしれない.)
*BERTを1年ほど使用して思うところだが,そも最適な使い方ができていないことはおいておいて,BERTは学習データが多いほど優秀となる,のはよいとして,BERTは学習データが少ない,CNNと同等である,場合,他の手段より無能となるようだ.豊富な学習により文脈を学習しきらなければただの内積になりかねないというところに注意が必要に思える.より良い学習済みモデルが欲しいtところだ・・・
*exBERT
トランスフォーマーモデルで学習した表現を調べるための視覚分析ツール
A Visual Analysis Tool to Explore Learned Representations in Transformers Models
Benjamin Hoover, Hendrik Strobelt, Sebastian Gehrmann
Large language models can produce powerful contextual representations that lead to improvements across many NLP tasks. Since these models are typically guided by a sequence of learned self attention mechanisms and may comprise undesired inductive biases, it is paramount to be able to explore what the attention has learned. While static analyses of these models lead to targeted insights, interactive tools are more dynamic and can help humans better gain an intuition for the model-internal reasoning process.
We present exBERT , an interactive tool named after the popular BERT language model, that provides insights into the meaning of the contextual representations by matching a human-specified input to similar contexts in a large annotated dataset. By aggregating the annotations of the matching similar contexts, exBERT helps intuitively explain what each attention-head has learned.
Thanks to Jesse Vig for feedback. Please let us know what you think by commenting below!
http://exbert.net/
BERTのattentionハイライト。
*Received October 31, 2019, accepted November 13, 2019, date of publication November 18, 2019,date of current version December 23, 2019.
Improving BERT-Based Text Classification With Auxiliary Sentence and Domain Knowledge
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8903313
*huggingface/transformers の日本語BERTで文書分類器を作成する
https://qiita.com/nekoumei/items/7b911c61324f16c43e7e
pip install transformersで,様々なBERT派生モデルなどが使える.
SpanBERT入るかな・・・
https://github.com/huggingface/transformers
https://github.com/facebookresearch/SpanBERT
These models have the same format as the HuggingFace BERT models, so you can easily replace them with our SpanBET models. If you would like to use our fine-tuning code, the model paths are already hard-coded in the code :)
とあるな.
*Camphr: spaCy plugin for Transformers, Udify, KNP
https://qiita.com/tamurahey/items/53a1902625ccaac1bb2f
色々と揃ってきた。そろそろ素のBERTから乗り換えても良いかも。
(BERTをTensorflow2.0に対応させるべく色々修正してみたが・・・あきらめた.ラッパーで十分なのさあたしゃ・・・→tf2用BERTがあるらしい https://stackabuse.com/text-classification-with-bert-tokenizer-and-tf-2-0-in-python/)
*BERT Encoder
https://peltarion.com/knowledge-center/documentation/modeling-view/build-an-ai-model/blocks/bert-encoder
https://peltarion.com/static/bert_encoder_block.svg
*DistilBERTの日本語事前学習モデルを公開しました。
BERTモデルと比較して、サイズが約40%小型化、推論が約50%高速化、精度は分類タスクで約90%となっています。
https://github.com/BandaiNamcoResearchInc/DistilBERT-base-jp
*ストックマークが公開した言語モデルの一覧と振り返り(20200626)https://tech.stockmark.co.jp/blog/list_of_the_published_learning_models/#bert
体験談は非常に面白い。
追記:
・概念を明確化するために多様性評価手法に名前つけとけば,とのこと.「タイス Thaïs」にしておく.
*いまいち。わたしゃAIモデルを多次元空間の多様体を表すものとみなしており、その多様体のエッジは動的平衡を保つ為うごめいており確定するものやさせるべきものではない、と考えている(法と同じく)。
多次元空間のブヨブヨした多様体と言う字面は、クトゥルフ神話を思い起こさせるなぁ。「ヨグYog」のほうが良いか?
そろそろセサミストリートつながりの名前はつけられなくなり、クトゥルフ絡みの名前がつけられるようになったりしてなぁ。
類似研究:
見つけ次第追記.
個人的には当たり前すぎるやり方だと思うのだが,意外と目につかない.(無効資料調査で1890年の文献まで遡ったことがある.異なる視点と用語が使われているだけで車輪の再発明だったってのはよくある話だ.)
*以下引用は当面のメモ.
Xiaochuang Han, Jacob Eisenstein.
Unsupervised Domain Adaptation of Contextualized Embeddings: A Case Study in Early Modern English.
arXiv: 1904.02817
Gözde Gül Şahin, Clara Vania, Ilia Kuznetsov, Iryna Gurevych
LINSPECTOR: Multilingual Probing Tasks for Word Representations
arXiv: 1903.09442
L. Elisa Celis, Vijay Keswani
Implicit Diversity in Image Summarization
arXiv: 1901.10265
Abdulaziz M. Alayba, Vasile Palade, Matthew England, Rahat Iqbal
A Combined CNN and LSTM Model for Arabic Sentiment Analysis
arXiv: 1807.02911
Alex Wang, Kyunghyu8n Cho
BERT has a Mouth, and It Must Speak:BERT as a Markov Random Field Language Model
arXiv: 1902.04094
佐藤 進也 (2018)
検索対象の多面的理解支援のためのWikipedia記事中の列挙を利用した関連情報発見
知能と情報, 30(6), 788-795
https://www.jstage.jst.go.jp/article/jsoft/30/6/30_788/_article/-char/ja/
「既知の主題内容の外枠にある新しい概念,概念関係の外枠を欲する」「検索対象の多面的理解を支援することを目的として,ユーザーが与えたクエリから関連情報を発見する方法」
P.インクベルセン (1995)
"情報検索研究一認知的アプローチ"
トッパン
「複数の異なった複雑なモデルを実際に組合せて,知識べ一スに基づいたコンピュータ仲介機構をも含む相互作用的情報検索システムを設計するための理論および枠組みを,打ち立てる」ことを目指した理論書」
https://www.jstage.jst.go.jp/article/jcul/47/0/47_387/_pdf/-char/ja
見つけた!?
Tatsunori B. Hashimoto, Hugh Zhang, Percy Liang (2019)
Unifying Human and Statistical Evaluation for Natural Language Generation
arXiv:1904.02792
Iyad Rahwan,et al. (2019)
Machine behaviour
Nature, 568, 477–486
「人工知能を搭載した機械は、社会的、文化的、経済的および政治的相互作用をますます仲介しています。人工知能システムの動作を理解することは、それらの行動を制御し、それらの利益を享受し、それらの害を最小限に抑えるための私たちの能力にとって不可欠です。ここで我々はこれがコンピュータサイエンスの規律を組み込んで拡張し、科学全体からの洞察を含む機械の挙動を研究するための幅広い科学的研究アジェンダを必要とすると主張する。最初にこの新興分野に欠かせない一連の質問を概説し、次に機械の挙動の研究に対する技術的、法的および制度的制約を探ります」
「人々は何百年もブラックボックスを研究する科学的方法を発展させてきましたが、これらの方法はこれまで主に『生き物』に適用されてきました」と、マサチューセッツ工科大学(MIT)メディアラボの研究者であるニック・オブラドヴィッチ博士は述べる。オブラドヴィッチ博士は、4月24日付でネイチャー誌に発表された新しい論文の共同執筆者だ。「新たなブラックボックスであるAIシステムを研究するために、同様の多くのツールを活用できます」。
産業界と学術界の多様な研究者で構成する同論文の著者グループは、「マシン・ビヘイビア(機械行動:machine behavior)」と呼ばれる新しい学問領域をつくるべきだと提案している。動物や人間をこれまで研究してきたのと同じ方法、つまり、経験的観察と実験によってAIシステムを研究しようするアプローチだ。
https://www.media.mit.edu/publications/review-article-published-24-april-2019-machine-behaviour/
(参照 20190428)
Hiroshi Maruyama's Blog/ 丸山宏
高次元科学への誘い
https://japan.cnet.com/blog/maruyama/2019/05/01/entry_30022958/
(参照 20190502)
「複雑だけど構造を持つ、すなわち「非常に多くのパラメタがあるが、それぞれがお互いを束縛しながら動くことで出来るモデル(数学的には超多次元空間に埋め込まれた多様体で表現されるようなもの)」という考え方もあると思います。このような考え方が、生物学や社会学や、科学におけるその他の多くの「面白い問題」のモデル化に必要になってきている、という認識が私が「高次元科学」と呼ぶものの正体です」
財津亘 (2019)
"犯罪捜査のためのテキストマイニング"
共立出版
世界の「謎」解くカギ、深層学習は「因果性」を発見できるか?
深層学習の人工知能(AI)は、多くのデータの中から関連性を発見することは得意だが、因果性を見い出すことはできない。5月上旬に米国で開催された「ICLR2019」で、著名なAI研究者が因果関係を分析する新しいフレームワークを提唱した。
by Karen Hao2019.05.17
https://www.google.com/amp/s/www.technologyreview.jp/s/141062/deep-learning-could-reveal-why-the-world-works-the-way-it-does/amp/
(参照20190521)
石垣 司,他 (2011)
日常購買行動に関する大規模データの融合による顧客行動予測システム
人工知能学会, 26(6), 670-681
https://staff.aist.go.jp/takenaka-t/5075626C69636174696F6E_reD-B61takenaka.pdf
ベイジアンネットワーク
足立 康二,他 (2010)
ベイジアンネットワークによる複合機故障診断技術
富士ゼロックステクニカルレポート, 19, 78-87
https://www.fujixerox.co.jp/company/technical/tr/2010/t_01.html
Zhunchen LuoEmail authorJun ChenXiao Liu (2018)
Real-Time Scientific Impact Prediction in Twitter
CCF Conference on Big Data Big Data 2018: Big Data, 108-123
Lizhong Xiao ; Guangzhong Wang ; Yuan Liu (2018)
Patent Text Classification Based on Naive Bayesian Method
2018 11th International Symposium on Computational Intelligence and Design
(ISCID)
TF-IDFとナイーブベイズでacc93.9%.TF-IDFベースでそこまで?
ナイーブベイズでのモデル適用確率算定にも期待が持てる?
ワタシから始めるオープンイノベーション
価値共創タスクフォース報告書 (201906)
(知的財産戦略本部会合2019年6月21日 参考1書類)
https://www.kantei.go.jp/jp/singi/titeki2/190621/sankou.pdf
「脱平均」「融合」「尖った人材」.考え方は同じだが、尖った人材をどう活かすかについての記載はない。そこが要点だと思うのだが扱いきれるのかね。
Diversity in Machine Learning
https://arxiv.org/abs/1807.01477
https://arxiv.org/pdf/1807.01477v2.pdf
伊庭幸人,持橋大地ら(2018)
ベイズモデリングの世界
岩波書店 p69−
https://sites.google.com/site/iwanamidatascience/BayesModeling
Aylin Caliskan1,, Joanna J. Bryson1,2,, Arvind Narayanan1,e al (2017)
Semantics derived automatically from language corpora contain human-like biases
Science Vol356, Issue6334, pp. 183-186
https://science.sciencemag.org/content/356/6334/183.full
以下保留
*付録:
pythonで可能とできることが多く感動している.
特にpandasとjupyter notebookの便利さと言ったら.
ごく簡易に迅速に母集団を確認する際には,pythonで基礎集計部分を作っておいたnotebookに読み込ませpandasベースで確認したほうが,下手に使わない機能ばかり豊富な市販ツールやexcelより便利.
私は自動車ではロードスターを好むが,linuxやpythonはロードスターと,いらない機能は余裕なんかではないただの贅肉で思考や行動を限定させる足枷だ,という部分で共通している気がする.イノベーション「となっている」発明にも関わるこの考え方,とても好きだ.
Google「怠惰であることは美徳.シンプルに大事なとこを」
code
簡易迅速確認ならワードクラウドを加えるのも良いか.
code
5分でできるわけで.(ワードクラウドは,数式に色がついて見えたベーテの逸話や不思議の国のアリス症候群を想起させてくれるお気に入り.)
ついで,頻出語だけでは理解し難いのでtfidf上位語に限定したワードクラウドを・・・
会社名でもIPCでも審判情報でもなんでもソートできるが,例えば単語&ベクトルでソートしたところ,2015年に出願の山がみられた.2015年前後の特徴語はなんだろう.2015年以前が複数抽出装置,以後が単語文章学習方法装置.ルールベースから深層学習への切り替わりかな.Yoon Kimの自然言語CNNの文献が2014年の公開だが,このあたりの影響が大きいのであろうか(適当).当時のSNSのトレンドは・・・
独立した単語のみを見ていてもわからないから単語共起ネットワークも見るか・・・
IPCネットワークを図示させ分類上の共起性の変化からより詳しい動向を(分類共起についてはよりやりようがあるだろう.個人的には分類の正確性に疑問を持っている,というと怒られるが,分類の主観性が分野によっては邪魔をすると言うか・・・ので,後回しにしている.)・・・
ついで,TF-IDF上位語を前述のようにベクトル化し,plotlyを用い各特許の類否をインタラクティブに可視化し,トレンドやトピックをみるのも良いか
(TF-IDF上位語を用いる手法ではモデルの相違ならともかく特許間の類似を見ることは難しいが.)(と思っていたのだが,固有名詞が適度に削れ,絞り込みを前提とするなら悪くないかもしれぬ.母集団を変更すると特徴語が変わりその点がとても使いやすい(TF-IDFは動的に,上位語母集団では上位語を特徴とし下位語母集団では下位語を特徴とする.インサイトを得つつ絞り込みをすると適切なものを得やすい.静的に目的物を抽出する教師ありとは異なる使いやすさがある.valuenexは本当に良い視点を持っていたのだのう).請求項とTF-IDFの相性も良い.)(とはいえ,少し固有名詞を救済するとより良いだろう.トピックごとの抽出や名称重視の抽出を行っても良いかもしれぬ.クラスタリング実装(こちらのクラスリングは,非特徴を削減すると言うよりも,余分な類似を統合し文章の意味を特定数に磨き上げていると言うと,イメージに近い.概算上,クラスタリング前は0.62単位,クラスタリング後は0.80単位,30%ほどの性能向上となる.)(SCDVはもう少し柔軟性が高いとよいのだが.行き止まりではあるが補強に使えるか.)(あらたに検証データ460件を前向きに集めた.不正解候補なし,2分類.この検証データを本手法にかけロジスティック回帰をおこなったところ,accuracy0.9875となった.本手法は,不正解候補なしの2値分類ならば,この程度の性能も出る.そして不正解候補が混ざってもこの可視化の目的において問題とならない.十分だろう.しかしきれいに分かれるものだ・・・自分の主観的なラベルと文章ベクトルの傾向が見事に一致している(この手法については標準データセットを用い評価すべきだろう.適当なものを探す予定.).なお,下図左,ノイズ教師データあり,2分類,のように,ノイズ教師データ(この場合は不正解候補と言い換えても良い.以下まとめてノイズと表記する)(青点)の分類はできない.本手法においては,他と類似し難く一定の集団をとれないノイズは,このように全体に分散されてしまうのだろう(これは理論的な説明が可能だろう)(このノイズが全体に分散される現象は,キーワードベースに重みで対応しているvaluenex ~Radarでは起きないのでは.自分はこうすることで可能性が増えている,例えば創造的なインサイトが増える(分構造の類似性のみの共通性からのインサイトも得られる),と思っているが,母集団のとり方によっては意味不明にもなるだろう.).このノイズは教師ありでないと見分けることは難しいだろう(下図左は教師データ.つまり教師ありではこのノイズを見分けている・・・いや,教師データを見分けられるのは当たり前として個別に確認したことがなかった.どのように見分けているか確認しておくべきか).))(本記事内容を入力しG06Nの特許群においてベクトルの類似を見たところ,5798624が最近となり,富士通5733166モデル全体の合成,富士通2018170004患者行動予測,Preferred Networks 5816771学習装置ユニット内部状態共有接続システム(重要そうな特許だな)が近くに現れた.興味深い.)・・・
→tfidf/cluster vis: tfidf-word2vec-clustering visualization
https://qiita.com/kzuzuo/items/dcdf5550bcb024897de0
Mixout: Effective Regularization to Finetune Large-scale Pretrained Language Models
https://deepai.org/publication/mixout-effective-regularization-to-finetune-large-scale-pretrained-language-models
モデル間リーク.自分は中間部分でのリークに手を出す気はないcheck systemの設計が難しいから.
最後に,気になった特許を教師とし自作AIにかけ,特許の類似度に基づく並び替えをするのもありだな.
(出願番号など検索用データをplotlyの範囲指定で得ても良いが,前記TF-IDFの手法では性能が不十分で教師として適切な特許のみを選択することが難しい.)(教師なしで作成されたベクトルから適切な並び替えができるほどの類似情報を得ることは,前述の通りまだ限界があると思っている(9割が限界か?).最後はやはりニューラルが適当かな.)・・・
など,自己の課題の求めるまま,最低限に便利にできる.
類似特許を近くに表示するだけなら難しくはない.表現をすべて吸収し漏れなくかつ特定の傾向を持たせようとすると難しいか.(後者2つは教師ありに任せれば良いことなので多様性評価の立場からするとどうでも良い.補えばよいだけ.)
自作AIにより得られた重要特許を教師なしの文章ベクトルとして可視化し,特定の母集団から得られた文章ベクトルと重ねて表示し,見落としのチェックをする,母集団変更の必要性をチェックする,などもありえる.
自作AIの3,ヒトの1,ベクトル可視化の1,計5つの個性を用い多様性評価をしたことになる.
また,類似する特許群が設定した正解特許の近くに図示されており,その内容がインタラクティブに確認できることにより,他分野からの流用・置き換え・別の効果の示唆など,豊富なインサイトも得られるようになっているとも言える.

(多様体仮説.トポロジー.ホモロジー.パーシステント図.)(教師なしベクトルによるインサイト・仮説づくり→教師あり自作AIによる予測→ベイズによる仮説に寄与するデータの確率化→・・・のループを作ることができれば,知財や研究における一通りが終了するのだろうか.(ほぼ完成))
最終的には,知識グラフを作っても良い.
Evaluation of a Visual Tool for Early Patent Infringement Detection During Design
https://link.springer.com/chapter/10.1007/978-3-030-24781-2_12
課題を最も理解している実務屋こそ,pythonを使った自作をすべきと感じる.自由度の高さは質にも影響するだろう.
幸い,自作のハードルは高くない.
「僕はこのときはっとした。なぜプリンストンの実験室から、どんどん報告が出ているのかに思い当たったからだ。彼らは実際に自分たちの手で造りあげた装置で研究しているのだ。だからこそどこに何があり、何がどう働いているかが、ちゃんとわかっているのだ。(ファインマン)」
*もちろん自作ではできない範囲はある.しかし,それができないとわかってからその機能を持つ製品を採用してもよいだろう.自作の過程で,何がどのような理由でできないのか,課題を理解したわけだから,より良い選択と採用が可能となっただろう.
*実務で使うとなると権利関係のクリアランスにそれはそれは苦労をするわけだが.
*ベンダーの製品を使う理由は、1それで十分であり2希望するものが迅速に手に入り3法的リスクを自ら負わないこと、など、にある。この内、1,2は、従来のフレームでは対処できない差別化、新ルール、ニッチ化が進む中、不十分と言える。それに気づいている会社は、自作も検討していると思う。問題は3と開発コストだけれど。
*深層学習の場合でも教師の質をより重く問わなければいけないと思う.
教師データの質ではなく,教える主体としての「教師」,つまりAIを現場で扱うヒト側の質だ.実務の上では,AIの優れている点を引き出せない教師とならないこと,ヒトがAIの足を引っ張らないこと,が重要となるのではないだろうか.
(何を教えるか,ではなく,不用意に削らないことのほうが重要に思う.)(ここで言う教師とは,自学できる年齢の生徒に対する教師ではなく,自学するにおぼつかない年齢の生徒に対する教師に相当する.生徒が本当に自学できるようになったのなら,教師の重要視は薄れる.自作AIはできるだけ早くそちらに持ってゆきたい.)(生徒が本当に自学できるよう←メタ学習の分野といってよいのか?)
http://publications.jrc.ec.europa.eu/repository/bitstream/JRC113826/ai-flagship-report-online.pdf
*失敗から学ぶ機械学習応用
https://www.slideshare.net/mobile/HiroyukiMasuda1/ss-181844477
*Designing the nteract Data Explorer
https://makoto-shimizu.com/news/jupyter-nteract-intro/#
Jupyter notebook代替。
Pandas dataframeを何もせずインタラクティブに表示。これすごいな…
*私は,手段の完璧さと目的(課題)の混乱が最大の問題である論者です.好きな人物は,と問われれば,ファインマン,ベンジャミン・フランクリン,アインシュタインを挙げます.また,リベラルアーツを評価しています(課題を持てていないものの多くがリベラルアーツ不足に見えるという理由の範囲で).
*「評価の低いモデルをただ捨て去るのは間違いである.シンプルなモデルが役に立つ場合それは必ずしもすべての実験データなどと一貫性がある必要はない」,という理解は,物理生物学など持ち出すまでもなく広い範囲で言えるところ.
必要なモデルとは,「予め得られるドメイン知識と教師・非教師データを用い構成され,今後得られる実データから個別に設定された課題を解決できるモデル」.そのモデルという手段が汎的に使えるかどうか,手段が汎的に評価が高いかどうか,は,あまり重要ではない.
ここを勘違いしている人が多すぎることは,実装普及において最大の問題の一つだと感じている.
(まず,評価はある目的を達成するための手段であり,目的ではない.評価結果から拡大解釈すれば当然に間違える.)(ガイドラインに従えばすべての患者を適切に治療できるか,と問われれば,そうではない,というのが答えだ.それと同じ.実務では個別の患者に,個別の課題に,注目することが重要.)(「モデルの予測精度評価は動作確認程度のもので、これ自体をKPIにするのはマズい」そのとおりでしょうな.)(適用範囲が絞り込まれていない(適用範囲が未知と言っても良い)ことが多く、この点からも動作確認程度の指標に過ぎないと言えるだろう。なお、モデルの適用範囲を理解できていないことは、PoC倒れの大きな原因となっているのだろう。)
*少々古いが,最初に次を修了するとよいのではないかと感じている.学び始めて1年経過したが,学会を除き,どの「いわゆる」わかりやすい講習等より役に立った.
Machine Learning
by Stanford University
Andrew Ng
https://www.coursera.org/learn/machine-learning/home/welcome
11週間.毎週テストとプログラム提出必要.修了するとCongratulations! You've successfully completed Machine Learning!と.
講師のAndrew Ng御大は人を乗せるのがとてもうまく,非常に楽しく学べた.多分わざと入力を間違えて見せリラックスさせたり.いや面白かった.課題を持っていないものは価値のあるコードを書けない,小手先の知識など課題がなければ意味がない,とも教えてもくれた(のはこの講義だったか)
最初に良い先生に出会うかどうかはクリティカルで,固有名詞の説明のみから入る講義を最初に受けてしまえばその段階で発想できなくなるという重い負債を得てしまう,感覚がある.
Advice on building a machine learning career and reading research papers
by Prof. Andrew Ng
https://www.kdnuggets.com/2019/09/advice-building-machine-learning-career-research-papers-andrew-ng.html
多々入門者向けの人工知能系の講習会や書籍があるが,そんなものに何度も参加したり読むより,論文を読み学会に参加したほうが良いと思うよ.
(自然言語AI分野のように,まさに日進月歩と言える分野においては特に,固有名詞の説明のような基礎講習など,評価しているつもりの偏見持ちを増やす程度にしか,役に立たない.ものを理解するにあたり「最初に」枠を示す教え方・得る覚え方,迅速に柔軟性のない偏見を作るようなやり方,は,発想を阻害するため好むところではない(誤解の無いように一応書きますが,枠自体が本体である法律などは別です.これは外枠から始め外枠を調整してゆかねばならない.始めから無限の要素を備えており枠をいくらでも拡大できる「もの」とは違う.))(同じく,「考える」ときにはできるだけ固有名詞を非除して考え,ある程度考えがまとまってから適切な固有名詞を探すことにしている.これをやらないならそれは演繹的に何かを導いているだけで「考えている」とはならない.まあやりすぎると単なるいいかげんや効率の悪さに帰するしそちらに寄りすぎている自覚はある.だが自分は「知りたい」のだ.「納得したい」ではなく.)(このような考え方を取るのはファインマンの影響.)(固有名詞から始める危険性のことを,知識の呪いやセンメルヴェイス反射,早まった一般化,自然主義の誤謬や合成の誤謬にハマりやすくなる、などと呼んでも良いけれど.)(認知科学では、「事物全体制約」「言語隠蔽効果」などの用語で表現するようだ。)(「創造性はどこからくるか(2019)」p80~83 言語化は創造性の敵か味方か.「言語として考えていることはアイディアを歪めてしまう危険をはらんでいる」「ただし言語化すること自体は自分の認知状態を振り返る上では有効だとされる事例も」~「長期間のアイディア探索をするような場合には,言語化に寄る時間をおいた思考の見直しがひらめきの契機を生むこともある」耳が痛い.)
*特許SDIにAIを用いるにあたり、AIに求められる「最も」重要といえる能力は、再現率もそうであるが、「教師データとして教えていない未知の特許・新しい特許のうち、少なくともヒトが必要と認識できるものをきちんと提供できるか」どうか。これはいわゆる汎化(意味不明なほど広いが)の問題でもあるし、創造性の問題でもある。これができず類似だけ観ている特許SDI用AIは、すべてアウト、というと言い過ぎか...すべてファウルだろう。
・言語処理学会NLP2019,とても面白かった.
・日本認知科学会JCSS2019,とても刺激的であった.
・情報論的学習理論ワークショップ IBIS2019,再認識することが多かった.
・日本知財学会2019,非常に興味深いものだった.
・言語処理学会NLP2020,具体的な示唆が得られた。交流の手段が限られたことは非常に残念だった。
・言語処理学会NLP2020,ルールとデータの融合、ヒト認知とのインタラクティブ融合に萌芽がみられたようで興味深かった。
*いつか誰かが「皆が欲しがるもの」を作ってくれる。これは達成されるだろう。しかし、いつか誰かが「自分の欲しいと思うもの」を作ってくれる、これは、多分達成されない。
きっと、多様性の時代には、自分の多様性を押し殺し二律背反を抱えて生きるか、無いなら自分で作り自由に生きるか、の2択を選ぶことになる。
後者のほうが、面白いのではないだろうか。