機械学習を実務で使う場合、「ではお客様、ラベルデータを・・・」と申し出て色よい返事が返ってくることはあまりありません。また、例えば自動運転車を作るときに、データが足りないからその辺流してくるか、お前ボンネットに立ってデータとってな、とするのは大変です。

NICO Touches the Walls 『まっすぐなうた』 より
そこで必要になってくるのが転移学習です。
転移学習とは、端的に言えばある領域で学習させたモデルを、別の領域に適応させる技術です。具体的には、広くデータが手に入る領域で学習させたモデルを少ないデータしかない領域に適応させたり、シミュレーター環境で学習させたモデルを現実に適応させたりする技術です。これにより、少ないデータしかない領域でのモデル構築や、ボンネットに立つという危険を侵さずにモデルを構築することができるというわけです。
この転移学習の可能性は、NIPS 2016 Tutorialにて、あのCourseraの講師であるAndrew Ng先生が言及されています。機械学習の成功を今後推進するのは(最初の推進は教師あり学習)、教師なし学習、そして最近目覚ましい進化を遂げている強化学習でもなく、転移学習である、と。
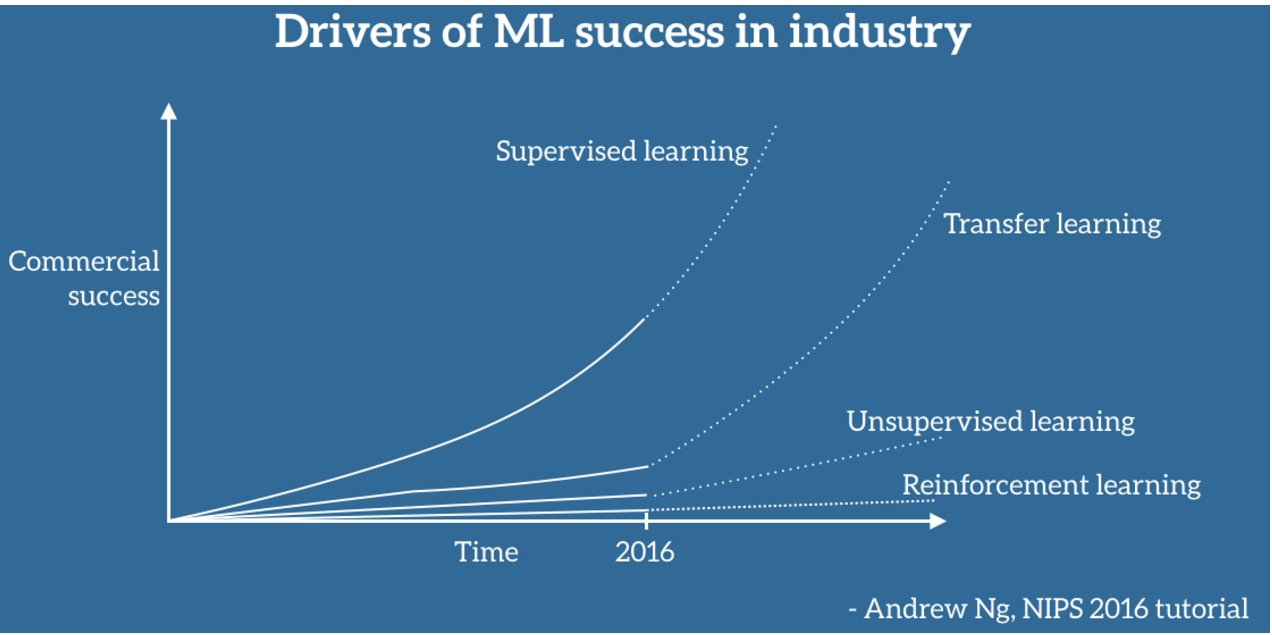
Transfer Learning - Machine Learning's Next Frontier より
本記事では、上の図の引用元でもあるTransfer Learning - Machine Learning's Next Frontierに刺激を受け、転移学習をこれから始めてみたい、という方にとって起点となるような内容をまとめます。私自身注力したかった分野でこの記事には先を越された感がすごいあったのですが、ここは先人のまとめを糧にさらに先へ、また多くの方により参考になる内容になればと思います。
機械学習における「ドメイン」
転移学習において重要なキーワードとして、「ドメイン」があります。転移学習はある領域=ドメインで学習させたモデルを、ほかの領域に適用する技術ですから、まずはこの「ドメイン」を定義しておきます。
以下は、文章に含まれる単語からそのタグを予測するようなモデルを図式化したものです。
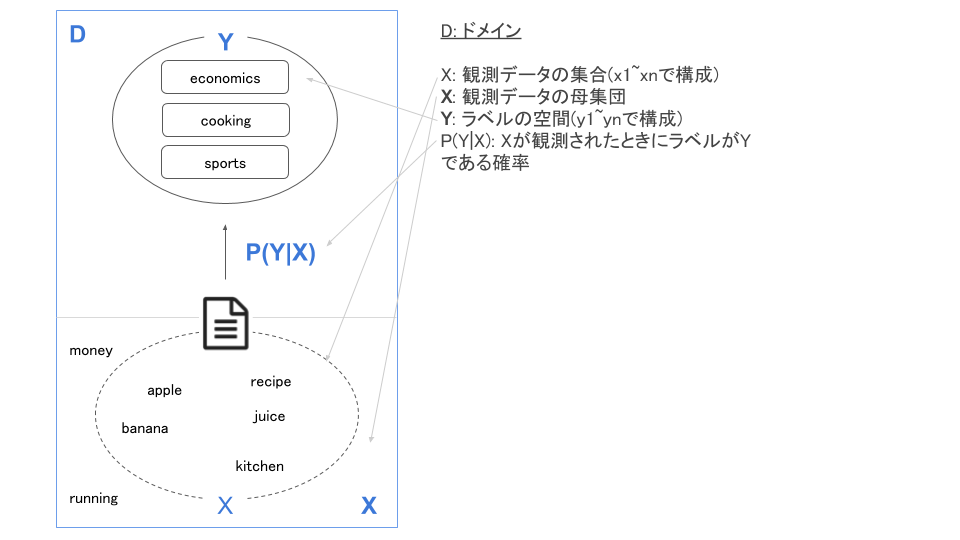
- 観測データ($X$):記事のデータセット
- 予測ラベル($Y$):記事のタグ
- (確率)モデル($P(Y|X)$):観測データがXの時、予測ラベルがYである確率
これらを一まとめにしたものが「ドメイン($D$)」になります。そして、転移学習においては元のドメインを「ソース($D_S$)」、転移先のドメインを「ターゲット($D_T$)」と呼びます。
$D_S$で構築したモデルを$D_T$に(より少ないデータで)適応させること、それが転移学習のミッションです。

転移学習の取り組む問題
当然ながら、この「ドメイン間の運び屋(トランスポーター)」の行く手には様々な障害があります。その、想定されるシナリオを順を追って解説していきたいと思います。
観測データが異なる
タスクは同じでも、観測データが異なるケースです($X_S \neq X_T$)。具体的には、以下のように言語が異なる場合などが挙げられます。
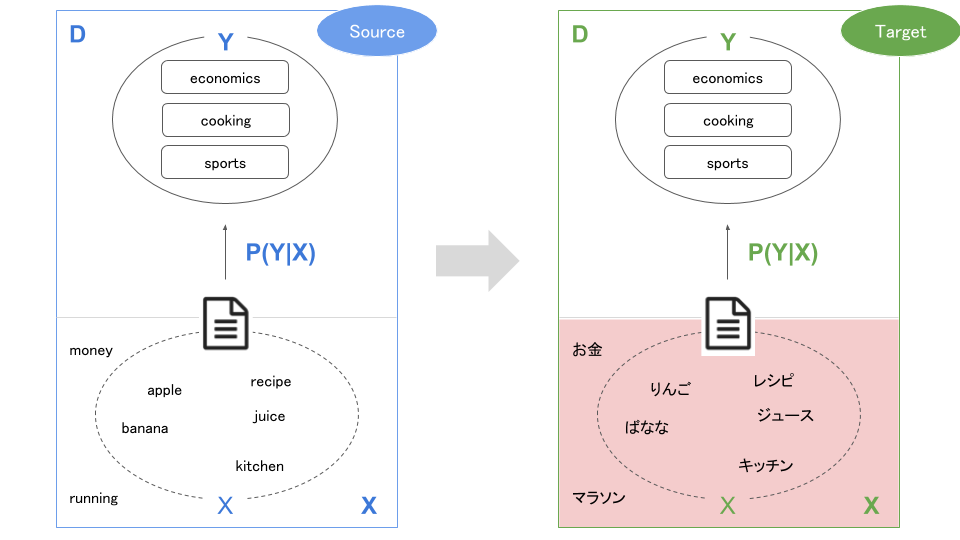
このケースへの取り組みは、Cross-xxx Adaptation(言語の場合なら、Cross-lingual)と呼ばれます。
観測データの分布が異なる
観測データは同じですが、その頻度が異なるケースです($P(X_S) \neq P(X_T)$)。実例としては、あるサイトで学習させたモデルを別のサイトで使うというとき、サイト間で話題が異なる(単語の出現頻度が異なる)といったケースが考えられます。
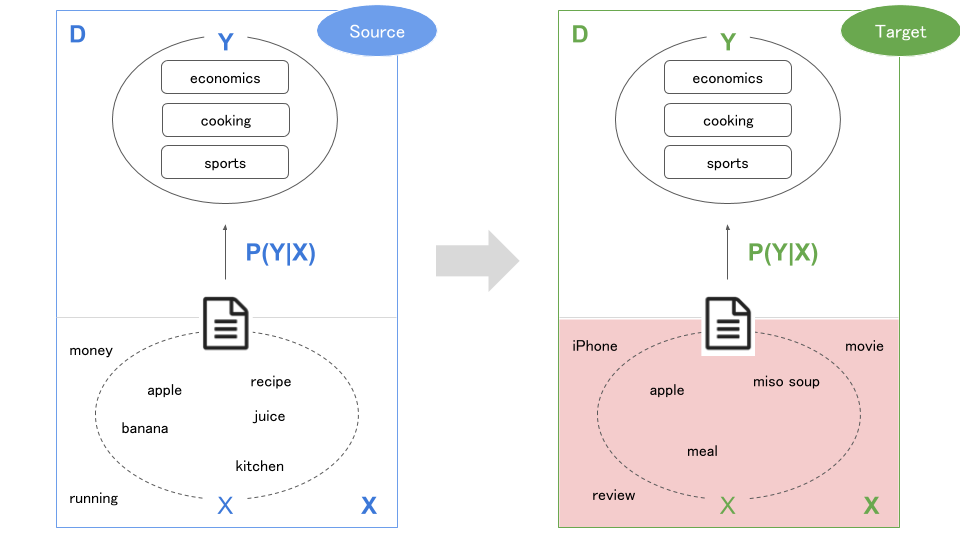
このケースへの取り組みは、Domain Adaptationと呼ばれます。新しい環境に適応させるイメージですね。
ラベルが異なる
予測ラベルが異なるケースです($Y_S \neq Y_T$)。自然言語のタスクだとあまりないかもですが(転用が効かないケースが多いため)、画像だと異なるラベルに転用するというのは多いと思ます。
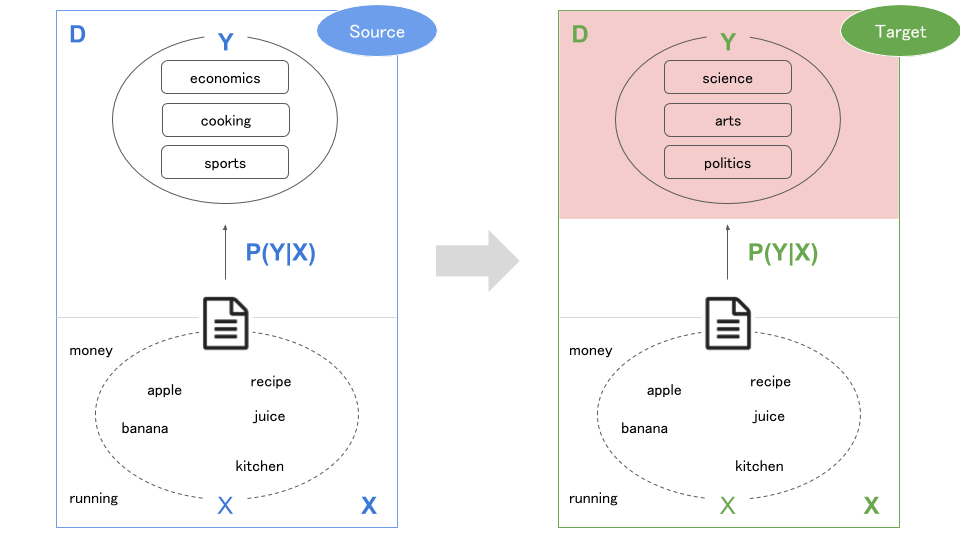
このケースへの取り組みは、Fine Tuningと呼ばれることが多いかもしれません。
ラベルの分布が異なる
ラベルの出現頻度が異なるケースです($P(Y_S) \neq P(Y_T)$)。元のサイトではあまりなかったタグの文章が、摘要先のサイトでは多い、といった感じです(元のサイトは料理の記事が多かったが適用先は経済の記事が多いなど・・・)。
(元の記事では条件付確率の差異になっていましたが、意味的にこちらの方が適していると思ったので修正しています)
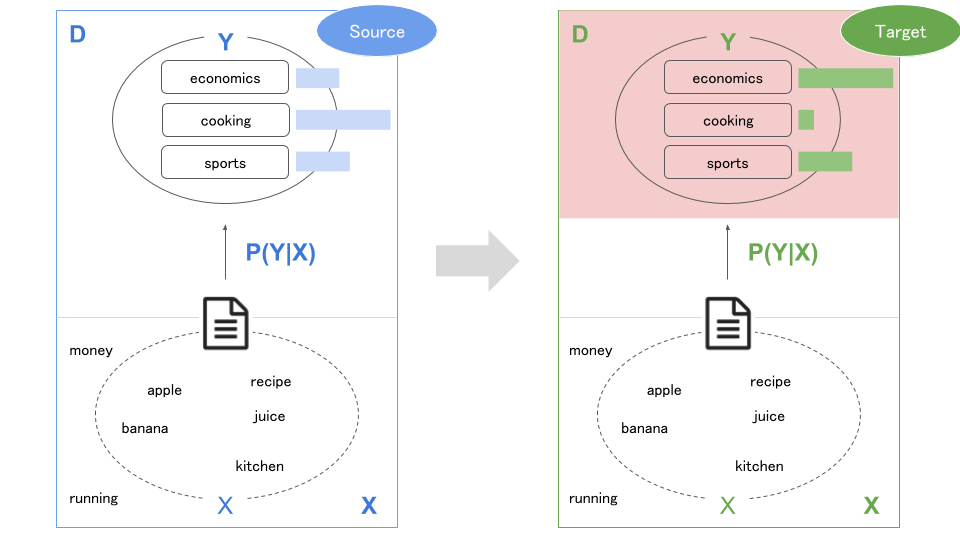
これは教師データの収集に際して特定のサンプルが多くなってしまった場合などにも起こるので、実際に直面する機会は多いかもしれません。
もちろん、上記4つのシナリオは複数が同時に発生することもあり得ます。これらのシナリオを克服することで、以下のようなことが可能になります。
- シミュレーターによる事前訓練
- 近い分野で学習させたモデルの転用
- モデルの個別化(ユーザーへの適応(音声認識など))
では、その克服のためにはどのような方法があるのか、についてみていきたいと思います。
転移学習を行うためのアプローチ
転移学習を行うためのアプローチとしては、以下のような手法があります。
学習済みモデル(Pre-trained Model)の適応
画像認識の世界では多くの「事前学習済み」のモデルが公開されており、これを利用することで新しいドメインへの適応が可能なことが実証されています。「実証」という通り、なぜうまくいくのかはよくわかってないのですが、どうやらConvolutional Neural Network(CNN)の下層の方では汎用的な特徴を学んでいるらしいという経験則があります。
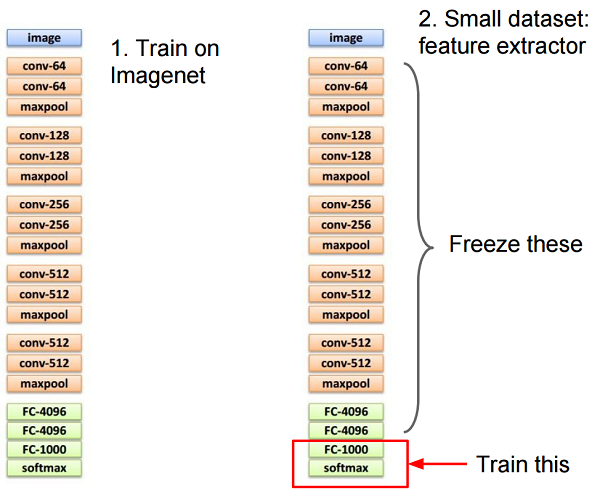
CS231n: Convolutional Neural Networks for Visual Recognition Lecture 7より
そのため、上図のように入力に近い部分の重みを固定し、出力に近い部分だけ学習させることで新しいドメインへの適用を行うことができます。
画像においてこの転移がうまくいっているのは、以下の要因があるためと考えられています。
- 画像における様々なタスクにおいて、「共通してとらえるべき特徴」が存在する
- 「共通してとらえるべき特徴」を得るのに、画像認識(クラス分類)が有効である
つまり、「タスク間に何らかの共通点」があり、その「共通点を学習する方法」が判明している、ということがポイントとなっています。
逆に自然言語においては、これらの点がまだ明らかになっていません。言語モデルは幾分か役に立ちますが(事前学習済みのword2vecを利用するなど)、画像のクラス分類ほど汎用的な特性の獲得には至っていないのが現状です。
強化学習では、最近「学習結果の持越し」に関する研究が行われています。まだ事前学習済みモデルが活用されるという段階ではありませんが、将来的にはその普及と活用方法が明らかになってくるかもしれません。以下の研究では、AtariのPongというゲームからAlienというゲームに移行していますが、Alienの時にPongの学習結果が活かされています。
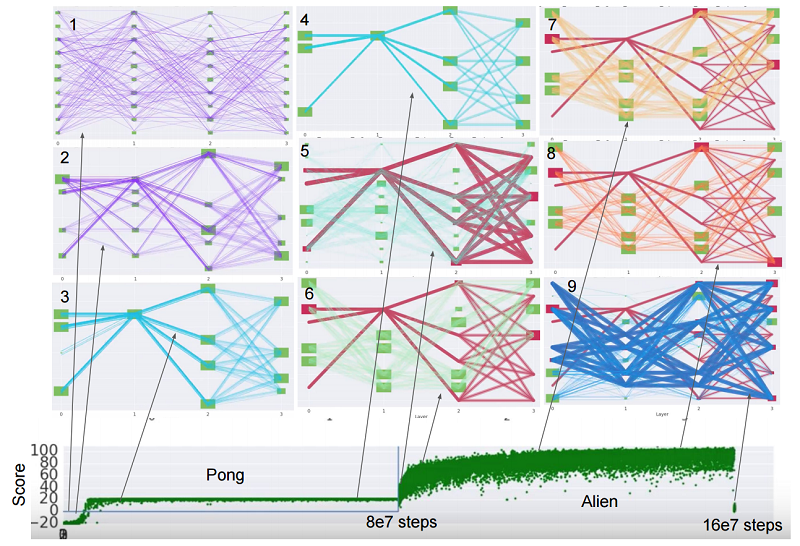
PathNet: Evolution Channels Gradient Descent in Super Neural Networks
ドメイン非固有の特徴の学習
CNNの下層を利用する方法、またword2vecに代表される分散表現に似ていますが、ドメインをまたいで使える表現を学習しようというアプローチです(表現学習(Representation Learning)と呼ばれます)。
代表的な手法としては、Auto Encoderなどがあります。

UFLDL Tutorial Autoencoders より
最近は、GANを利用してその生成過程で獲得されている表現を抽出しようという試みも行われています。
自然言語における表現学習については、こちらの資料にとてもよくまとまっています。
Representations for Language:From Word Embeddings to Sentence Meanings
ドメインの違いを学習させる
最近行われているアプローチとして、あらかじめ「ドメイン間の違い」を認識させるというものがあります。ドメイン固有の部分とそうでない部分を意図的に分けるという形です。
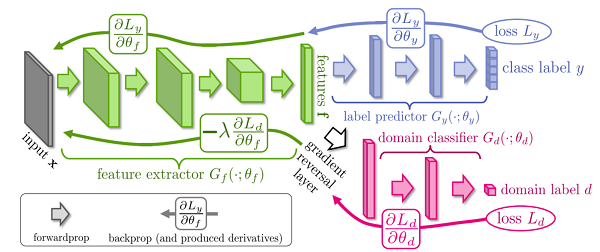
Confusing domains with a gradient reversal layer (Ganin and Lempitsky, 2015)
関連の研究としては、以下のものがあります。
最近発表されたDiscoGANなども、同様に「ドメイン間の変換」をあらかじめ学習させるアプローチです
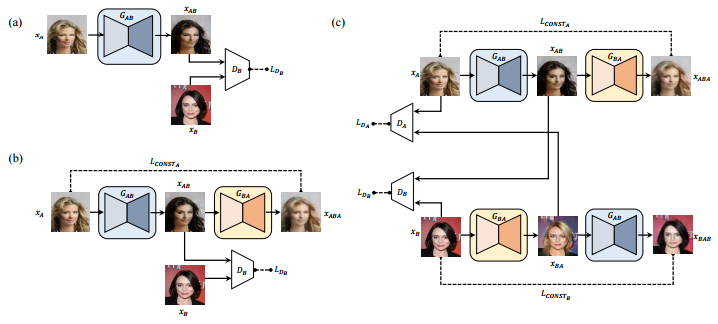
Learning to Discover Cross-Domain Relations with Generative Adversarial Networks
GANを用いてドメイン間の変換を学習させる研究はほかにもいくつかあり、今後も出てくると思います。
- Unsupervised Cross-Domain Image Generation
- Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks
- Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
転移学習の関連領域
転移学習を実現する手段について解説を行ってきましたが、最後に転移学習とかかわりの深い領域について紹介をしたいと思います。
少ないデータでの学習
転移学習したいのはそもそも少ないデータでも学習が可能なようにする、というモチベーションがありました。それに直接取り組むという研究があります。
- Semi-supervised learning(半教師あり学習)
- 少ないラベル付きのデータと、その他大勢のラベルの付いていないデータで学習をする方法です。予測精度の高かったものは教師ラベルとしてしまう(Self-training)などの手法があります。こちらによくまとまっています
- Active Learning
- 学習によく「効く」ラベル付きデータを選んで学習する手法です。こちらの資料がわかりやすいです
- x-shot learning
- 1-shot、はてはzero-shotといった、一枚だけ画像を学習させて、あるいはまったく学習させずに未知のデータを分類などするタスクのことです。
- 外部メモリを使った手法や、事前知識を組み込む手法などが提案されています。
マルチタスクの学習
転移するのでなく、そもそもマルチタスクが解けるモデルを作ってしまおうという試みです。画像分野では、領域識別とクラス分類を同時に解かせるといった方法が早い時期からとられています。
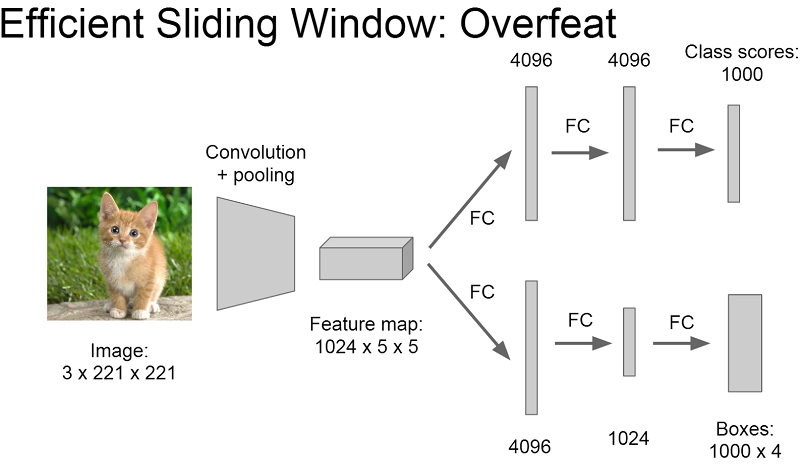
CS231n: Convolutional Neural Networks for Visual Recognition Lecture 11より
最近では、領域だけでなくその中の物体領域(セグメンテーション)の認識も併せて解かせるという研究もありました。
また、自然言語の分野でもマルチタスクを解かせる研究が行われています。
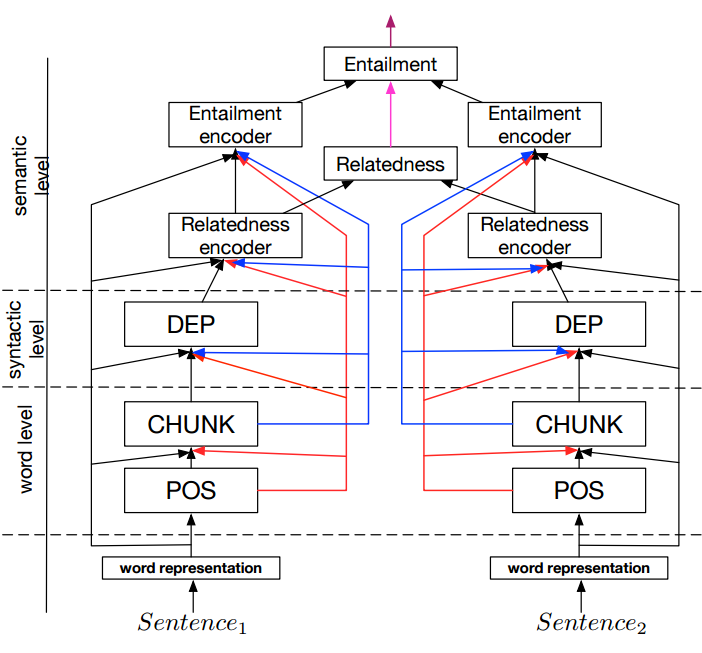
A Joint Many-Task Model: Growing a Neural Network for Multiple NLP Tasks
この研究では、品詞づけ・文節判定・係り受け・文意関係(補強・反対・普通)・文関係の度合い、といった複数のタスクをこなす一つのネットワークを構築し、最高精度を達成します。
強化学習においても、補助タスク(auxiliary tasks)を解かせることで学習速度・精度を上げる試みが行われています。
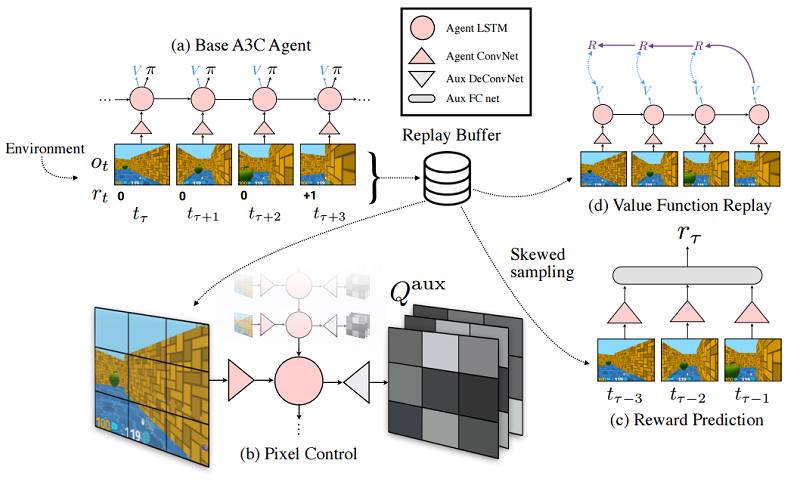
REINFORCEMENT LEARNING WITH UNSUPERVISED AUXILIARY TASKS
学習の仕方を学習
「どう学習すればいいか」がわかっていれば、異なるドメインにおいても素早く最適なモデルを構築することができます。こうした「学習方法の学習」はメタラーニングと呼ばれる領域になります。
Neural Architecture Search with Reinforcement Learning
まだ人手よりは効率的なパラメーターサーチに近い状態ですが、今後進展してくればより少ないデータでのモデルの学習にも応用できるかもしれません。
いかがだったでしょうか。転移学習を利用することで、機械学習はそれほどデータが取れない領域にも進出することが可能になるかもしれません。その「次のフロンティア」に漕ぎたすにあたり、本記事が参考となれば幸いです!

なお、今回論文の引用に使用したarXivTimesは、論文の一言まとめを共有しているGitHubリポジトリになります。今後も論文をどんどんシェアしていこうと思っていますので、よろしければStar & フォロー頂ければと思います。投稿・またコメントもお待ちしています!