*20211003,502 bad gateway対策として,前,中,後へ分割
前 https://qiita.com/kzuzuo/items/4670b5ff7526319680f4
中 https://qiita.com/kzuzuo/items/237b9f5192464817aa40
後 https://qiita.com/kzuzuo/items/756470e6e17c54aa5e2e
メモ
Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers
https://arxiv.org/abs/2409.04109
LLM で生成されたアイデアは、人間の専門家のアイデアよりも斬新 (p < 0.05) であると判断される一方で、実現可能性についてはわずかに劣ると判断されることがわかりました。
人間による新規性の判断は、専門家であっても難しい場合があることを認識し、研究者を募集してこれらのアイデアを完全なプロジェクトに実行し、これらの新規性と実現可能性の判断が研究結果に意味のある違いをもたらすかどうかを研究できるようにするエンドツーエンドの研究設計を提案します。
ああ、フィクションの認識と評価を別にしている感覚は、創造性における
Default mode network、
Executice control network、
これらをスイッチングするSalience Network
によるものと理解すればよいのか
スイッチングの曖昧化による妄想の漏れの許容度か。
設計可能だな…というか残差の制御かこれ
創造性のの設計は、生成の残差の制御で足りる?
※1漫画にはフィクションだと明確な情報が含まれている。そのとおり愉しめば良い。
2文章にはフィクションだと明確な情報があるとは限らない。
X文章はそも行間を足し読まねばならない。
XAフィクションを足せるか
XB足せないか。
YA足したとして、フィクションと認識する機構が動くか
YB動かないか
XBまたはYBのとき、
文章をフィクションだと認識できず嘘っぽく感じるかもしれない。
XAかつYAのとき、
文章を漫画と同じくフィクションとして嘘を楽しめるだろう。
文章をフィクションだと認識できず嘘っぽく感じるが、漫画をフィクションとして楽しめる場合、
YBではないだろうから、XBだろう。
すると、フィクションを生成する知識の問題となる。
小説をリアルにフィクションとして認識できるのは、XAが詳細であり、かつYAが働いている、ということだろう。
XYが同時に働くとき想像性が高いとする。
Xに優れYを制限できることが、創造性が高いということ、とできそう。
Xに優れない、Yに優れない、またはYの切替が明確であるときには、創造性に欠ける、となるのだろう。
記憶と判断に優れるが、
文面をそのものとしか捉えられない、ものは、
Yの切替が明確でありすぎるのだろう。
Yの切り替えが任意にできる能力があれば、
創造性と明確な思考力の両立ができるのだろう。
Salience Networkは任意の切り替えが可能なのかな?
ChatGPTの創造性
https://t.co/YYZvIKTnEU
タイトル: 「Creative and Strategic Capabilities of Generative AI: Evidence from Large-Scale Experiments」(IZA DP No. 17302)
0.全体の概要
この論文は、生成AI(特にChatGPTとBard)が人間のクリエイティブおよび戦略的なタスクにおいてどの程度の能力を持つかを比較する大規模な実験を報告しています。結果として、ChatGPTは創造性の面で人間を上回る一方、Bardは人間より劣っていました。また、AIと人間が協力すると創造性が向上するものの、AI単体のパフォーマンスに匹敵しません。さらに、戦略ゲームではAIも適応能力を示しましたが、人間は依然として特定の状況で優れた戦略的判断を下すことができました。
1.何を請求しているか
本研究は、AIのクリエイティブ能力と戦略的能力が人間のそれを上回るか、またAIと人間が協力した際に創造性が向上するかを探っています。特に、AIと人間の出力を比較し、評価者がAIと人間の生成物を区別できるか、またどのように評価するかも焦点とされています。
2.請求に対する結果はなにか
- ChatGPTは人間よりも高い創造性を示し、AI単独の方が人間とAIの協力よりもクリエイティブな結果を出しました。
- Bardは創造性が低く、ChatGPTとは対照的な結果でした。
- 戦略的なタスクにおいては、ChatGPTも相手の行動に適応する能力を示しましたが、非均衡な戦略状況では人間の方が優れていました。
3.主要な課題や争点は何か - AIの創造性:AIが人間の創造性をどれほど超えるか。
- AIとの協働:AIと人間が協力することで、人間の創造性がどれほど向上するか。
- AIに対する評価の偏り:評価者がAIの生成物を低く評価する傾向があるか。
-
戦略的適応:AIが戦略的ゲームでどれだけ人間のように適応できるか。
4.判断に至った根拠はなにか - ChatGPTは人間に比べて創造的なアイデアを多数生成し、その内容が評価者から高く評価されました。一方、Bardはその点で劣っていました。
- 戦略ゲームにおいて、ChatGPTは相手の行動パターンに応じて行動を調整しましたが、人間は特に非均衡な戦略状況でより適切に対応し、より多くの得点を得る結果となりました。
5.特別な点はなにか - 性別による創造性の違い:AIとの競争環境で、女性の創造性が低下する傾向が見られたことが注目されます。
-
アイデアの多様性:人間が生成するアイデアの多様性はAIよりも高く、特に最も創造的な回答において人間が優位を示しました。
6.その他
AIは創造的なタスクにおいて有望なツールである一方、評価者の偏見やAIが生成するアイデアの多様性に限界があるため、AIと人間の協力を最大限に活用するための最適な方法が課題として残ります。
本研究では、創造性の評価は、**「新規性」「驚き」「有用性」**の3つの基準に基づいて行われました。具体的な評価方法は以下の通りです。
- 評価基準
- 新規性(Originality):そのアイデアがどれだけ新しいか、独創的か。
- 驚き(Surprise):そのアイデアがどれだけ予想外か、意外性があるか。
- 有用性(Usefulness):そのアイデアがどれだけ役に立つか、価値があるか。
- 評価者
3,000人以上の評価者が、ランダムに選ばれた20の回答を評価しました。各評価者には、AIや人間が生成したテキストが混在して提示され、それらの創造性を0~10のスコアで評価しました。 - 評価者グループ
評価者は以下の3つのグループに分けられました。 - Baseline評価者:修正されていないテキスト(AIまたは人間が生成)をそのまま評価。
- CorrectedRater評価者:AIによって文法的に修正されたテキストを評価(人間の生成物のみ修正)。
- AIRater評価者:一部のテキストがAIによって生成されていることを知らせた上で、AIまたは人間が生成したかを推測しながら評価。
- 結果の解析
評価の結果、ChatGPTの生成したアイデアは、新規性や驚きの面で特に高く評価され、人間の生成物よりも優れていることが判明しました。また、評価者は、AIが生成したと信じる回答に対しては低いスコアを付ける傾向があり、これは「アルゴリズム嫌い」の現象として説明されています。
ように、創造性は多角的な基準で評価され、それに基づいてAIと人間の能力が比較されました。
D. モデルに創造性をもたせることはできるのか.
創造性の発露と呼びたい例はいくらか見つかっているが,その量は少ない.未だ検討中.
モデルが上位概念下位概念を見分けているならば、発散と収束を伴うカタチでの創造性の付与は可能だろう。
w2v-mpが発散という個性、keb-mpが収束という個性を持つと仮定し、w2v-mpの個性をkeb-mpの教師に組み込んだw2vkeb-mp試行中…
*創造性の定義を,とりあえず,「教えていない範囲で新規性のあるものを最低限の実現可能性を持って提示すること」、としておく.
(創造性の定義は,標準的には,「新しくて有益な何かを生み出す能力やプロセス」.創造的な人工知能の定義は,「客観的な観察者に創造的だと感じさせる振る舞いをするシステム」,らしい.本件においては,有益となるかどうかは創造的な特許を検索者が理解できるかという,「検索者の認知に依存」してしまうので,なんとも・・・.創造的と感じさせる,もなんとも.創造的となったと言うためには,検索者のインサイトを刺激する+αが更に必要,と考えるべきか,上位に配置したならそれだけで有益性として十分,とすべきか.w2v-mpが重視した,というタグを付けるだけでも良いかもしれない.その場合は,かもしれないとの期待を維持するために,「ある程度以上の割合で実際に創造しえる結果が得られる」必要がありそうか.となると有益性を「実現可能性」(実現可能に「見える」場合,やってみようと高く喚起させられるという有益性を生むだろう)に置き換えても良いだろう.)(実現可能性につながりやすくなる要素として、「面白さ」、を足してもよい気がする)(インサイト、そして意識変更につながる要素として、「楽しさ」があるようだ)
松本 元の箴言
@Gen_M_bot
「創造的とは、 自己選定した目標に自分なりの解決方法を見いだすことであり、 それはその人にとって創造的であると言える。 その解決法は既に他の人に見いだされたものである、 という事がその後明らかになったとしても、 その事はその人にとって独創である。」
・本検討において多様性を評価する目的は,最終スコアを高めるためというよりは(それもあるが),「創造性を持つ個性を切り捨てず救い上げる」ためである.
前者を優先していたが,そろそろ後者も検討してよいだろう.
*創造性のかけらもないAIを,個人用アシスタントAIとして充分だ,と評価したくない(え前と違う→いや欲が出た).個人用アシスタントAIには,この特許にはいらすとやのイラストが記載してありましたこんなの好きでしょう,と指摘してくるぐらいの柔軟性がほしい(いやここまではいらない.この原薬は錠剤で使われていますが点眼に切り替え可能ではないでしょうか点眼系の特許があったら重視しますね,この添加剤は現在話題の添加剤で従来のこれと置き換え可能ですから並行して探しておきますね,程度の柔軟性が欲しい.)
・創造性を生み出すには?。自分はまず「忘れること,間違えられる場を作ること」が必要なのだと思う.100を学び80を理解し,残りの20につき忘れ間違え,「自分を組み替え直す機会を与える」ことから,創造性は生み出されるのではないか.(追記 自己多様性の作成?)
個人的には,自分用のネタ帳は創造源として作るものなので,後で自分が読んでも一見して理解できないように,誤りと曖昧性を含むように,書くべきだと考えている(このページのように)(いくらなんでもひどすぎると思わなくもないがこれで良いのだ・・・と自己弁護しておこう・・・)
*よい 敵にあわせて下さい
https://www.jstage.jst.go.jp/article/jkg/69/4/69_155/_pdf/-char/ja
「私達は,レファレンスに人間が介在するということの意味を,もっと考えてみなければいけない。教員とのコンタクトも,何も複写依頼に限定する必要はないのである。日常会話においても,キャンパスの中で,あるいはどこかの道端で,先生,最近は何を,とか,どんなことをとか,今,なにか探し物はありませんか,とか尋ねられるといい。実際,喋ったほうは喋ったことを忘れていて,時間をおいて文献を送ったら,何でお前,おれのほしがっているものを知ってるんだ,と言われたこともある。以降常連客となった彼は,大学教員,かつ大学の要職者。先生方というのは,役職につくと,専門外のことを人前でしゃべらなければならなくなる。講演とか,式辞とか。これが狙い目。先生方のニーズには,専門外のこと,周辺領域のことを知りたい,確認したい,というニーズもかなりあるのである」
ニーズに基づく創造.SDIにおける創造性の必要性.
*創造的AI研究 静岡大学須藤明人研究室
http://sudo.inf.shizuoka.ac.jp/
非常に面白い.研究成果など確認しておかねば.社会人学生募集していたりしないかな.
聞いた限り、未来予測AIとしてのw2v-mpモデルがあるべき理想,持つべき構造,に近い.
創造に関わる構造の一部が提示された.SNS抽出共起テキスト群とwiki抽出分散表現知識グラフから得られる既知組み合わせ構造を学習する創造をもたらすこの研究室の手法は,valuenexの言う?「重要領域間の空の領域が重要」という概念に近いかもしれず?,下記に書いた?空ベクトルに近いかもしれない.w2v-mpモデルが予測的・創造的(特許の未来予測とは創造のことだ)に動いている(ように見え・・・なくもない)理由がおぼろげながら見えてきた気がする.w2v-mpモデルにおける歪め統合やここに記載していないベクトル処理が肝だったと言えるかもしれない.そうなるだろうと予想し作っておきながらなぜそうなったのか解析的に理解することができない状態から,ある程度開放されるか
(資源制下におけるブリコラージュ的手段は現実的な有用性が高いだろう)
意味空間上の演算は実世界における計算論的創造性に不可欠か?機械学習によるコンセプト創出手法の検討(2016)
https://www.jcss.gr.jp/meetings/jcss2016/proceedings/pdf/JCSS2016_OS05-6.pdf
「創造的な人工知能」の活用はイノベーションに直結するか? 組織内のアイデア創造プロセスを明らかにする社会シミュレーション・アプローチ(2017-2018)
https://www.taf.or.jp/files/items/1076/File/%E9%A0%88%E8%97%A4%E6%98%8E%E4%BA%BA.pdf
・w2v-mpの創造性について
気になる特許がある.
トラネキサムという単語を含むある特許だ.
1 w2v-mpのみ,この特許に高いスコアをつけた.再現もある.個性らしい.
2 w2v-mpのSHAP value highlightにおいて,「トラネキサム」がハイライトされた.w2v-mpは何らかの理由でトラネキサムに注目した.
3 教師データに,トラネキサムという単語は,含まれていない.
W2v-mpがトラネキサムに注目した理由は,教師データに含まれていたから,ではない.他に理由がある.
4 w2v-mpのpre-domain語彙に,トラネキサムという単語は,含まれている.
5 w2v-mpのpre-domainにおいて,トラネキサムとのcos類似度が0.84~0.87となるいくらかの単語,マレイン,グルコンは,教師データに含まれている.
6 w2v-mpが作り上げる構造からすると,トラネキサムと上記単語は,計算上同値とな*,「歪め統合」されているといえる.
結果 w2v-mpは教師データにあるマレインまたはグルコンの重要度に基づき,pre-domainから共起されるトラネキサムも重視し*,といえる.
(比較として,domain語彙上同じことをなし得たkeb-mpを示す)
ここまでは良い.
疑問 では,これは創造性の発露と言えるだろうか.
7 w2v-mpのpre-domainは,能動的な教師による学習から形成された知識構造とは異なる自発的な学習から形成された知識構造と例えることができ,ニーズの記載のあるコーパスより成り立っている.実際のコーパスを確認するに,トラネキサムとグルコン,マレインは,〜のような関係性である.
8 よって,「ニーズを考慮した歪め統合」となっていたといえ*,それにより見つかったこの特許は,**「w2v-mpモデルがニーズを発掘し新たな課題を見つけるという能力を発揮した結果見つかった特許である」**といえ*.ニーズを考慮したことにより,「未来予測型のAI」として働いたといえ*.
9 最後に,創造性の定義に適合するかどうかを確認する.その特許は,新規性,そして有益性,喚起性,実現可能性のいずれかがあるといえるだろうか.この場合の新規性とは,検索者が知らなかったという意味の新規性で十分だろう.これは問題ない.次に有益性,喚起性,実現可能性だが,特許の構成要素を置き換える範囲においては,まず実現可能性はあると言える.本件では構成要素となる単語の置き換えが起きているので,実現可能性があるといえる.新規性と実現可能性の提示で創造性が示されたと言えるとなれば,創造性の発露があったといえるだろう.ただし,検索者がそれを創造性と信用できなければ,創造性の発露は否定されうるだろう.信用には有益性が必要と思われる.そして信用に寄与する有益性は,有益であったと確認できる事後にしか得られない.とするならば**
~(確認中.創造性を示したと言ってよい,となるとよいのだが.
(トラネキサムとグルコン,マレインは,既存の文脈上同じ使われ方がなされるとは言いがたいだろうが,酸が付与されうる単語であるという代替可能性がある(周辺の単語を考慮する構造としていることで,最低限の実現可能性が担保できている,と言っても良いかもしれない)(解像度変換できないままでは代替候補の見落としは多くなりそうだが見落としがあっても創造性が低減するだけで大きな問題ではないか).この非文脈性と代替可能性は,創造性の種となる大きな因子だと考えている.非文脈性が過剰となればただのノイズとなるが,pre-domainがニーズベースの構造体となっているならば,ノイズではなく創造性と言えるようになるだろう.pre-domainの検討か.先が長い…)(valurnexの言うホワイトスペースにあるものを抜き出した,という評価でも良いかもしれない.手段として可能ではあるが,母集団の選び方が難しいな結論ありきでそのようにもできなくもないし.)
(web検索したところ,トラネキサムとグルコンは,化粧水の文脈では同時に現れるようだ.この特許は,ヒアルロン酸とトラネキサム酸の特許なので,見る人が見たなら,インサイトが得られたのかもしれない.AIが創造的でも,扱う側が創造的でないなら….いやまあ点眼分野専用にpre-domainを作ろうとしているので化粧水の提案をされても…いや待てよ.ああ,ロート製薬の特許でロート製薬の化粧水か…点眼と混ざっても仕方ないか…同一技術分野と捉え直すことも可能ではあるな….同一製品を保護する2つの特許,ヒアルロン酸&トラネキサム酸とヒアルロン酸&グルコン酸とを,教師のないまま同価値に調べた,と捉えるなら….いや後付にすぎるな.やはりコーパスを確認しなければ.)
(機能語の歪め統合も起きるわけだが,これはどう理解すべきだろうか.)
(AとBを変換するにそれが創造的変換と言えるには,一般的な共通要素に基づく置き換えでなく,特殊な共通要素に基づく置き換えとなるべきだろう.コーパスのバイアスの強さとその少なさを特殊な共通要素を生み出すための手段としているが、その特殊な共通要素はどうしても少量になる.より多量の特殊な共通要素を利用するための手法として,静岡大学須藤明人研究室に興味がある.創造性の量とノイズの量双方考慮しないといけないが….他に,解像度可変とすれば現状のままでもより多くの特殊な共通要素を使用できるようになるとも思われる.windowの範囲は固定しつつ、window内の形態素をランダムでドロップさせれば解像度可変になるといえばなるが…うーん、)(ルールベースの創造性で補正するか…いや喧嘩しそうだが)
(SNSコーパスからは、理解できる関係性は酸つながりぐらいしか見つからない。残念。「~美容品という名の医薬品はヘパリン類似物質とビマトプロストとワセリンとトラネキサム酸~」「~アジスロマイシン、フスコデ、トラネキサム酸飲んでて~」「~オロパタジンとポララミンとトラネキサム服用したの忘れてメコバラミン飲んじまった ~」「レボフロキサシン、トラネキサム、カルボシステイン、プランルカスト、オロパタジンってやつ 昼夜で飲ん~」「シナールとトラネキサム酸だけ4000Tとか~」「トラネキサム酸の消炎剤は目薬ですか?」「クロルヘキシジングルコン酸は医療現場でも良く使用」「悪名高きベンザルコニウムからクロルヘキシジングルコン酸塩に変」「ドルゾラミド塩酸塩・チモロールマレイン酸塩」)
(wikiコーパスからは、医薬品リストのようなページにおいて併記されていることが確認された。「一般用医薬品の種類と有効成分 フェノール クレオソート オイゲノール 塩化セチルピリジニウム グルコン酸ヘキシジン イソプロピルメチルフェノール チモール ヒノキチオール 抗炎症成分 グリチルリチン酸二カリウム グリチルレチン酸 サンシシ 止血成分 カルバゾクロム トラネキサム酸 組織修復成分 アラントイン 収斂成分 塩化ナトリウム 生薬成分」)
*SNSとwikiを組み合わせたことが本結果につながった、となると面白そうだ。しかし、単に、近傍に共通して出現する単語「酸」によりトラネキサムとグルコンなどが近似と判断され、歪め統合により代替された、と考えるほうが妥当であろう。単なる「創造性」という意味ではこれでもよいのだが、「ニーズ考慮」という意味ではなされているといえない。残念・・・。
SNSデータが絶対的に足りないか・・・。ニーズらしきものを発見してからコーパスにそのニーズらしき記載があるかどうか確かめる手法よりも、コーパスでニーズを見つけてそのニーズを見つけられているか確かめる手法がよいだろうか。結果と検索者の認知の共有という面では意味を失うが。創造がより頻繁に起きるならば前者でよいのだが。)
*単語ベクトルの類似性から別単語を取り出すのは語彙限界があり難しいな。単語生成が必要となるだろう。VAEのような手法で「単語を生成」できるだろうか.離散という意味では同じだが,語彙は化合物のように有限でないため,…無理やり漢字のような表意文字を持ってこれば可能か?
*mat2vec
https://github.com/materialsintelligence/mat2vec
論文紹介
https://speakerdeck.com/resnant/lun-wen-shao-jie-unsupervised-word-embeddings-capture-latent-knowledge-from-materials-science-literature
*クラスタリングは、正しくないからこそそこに創造性が生まれるという意味でも、基本的に良い手法ではないかな。セグメンテーションは逆。
* 渡辺星(静岡大学),藤原直哉(東北大学),須藤明人(静岡大学)(201911)
「Word Embeddingsを用いた斬新さと手堅さを兼ね備えた経済学における研究テーマの自動生成」
第17回情報学ワークショップ Workshop on Informatics 2019
https://sites.google.com/view/winf2019/awards
ああ参加すりゃよかった.WiNFか覚えとこう.諸事情により今はこちらから動き難いから声かけられないな・・・
*すでに存在するものから何かを生み出す創造性として,知財でよく使われる手法は次の通り.これを組み込むだけで良いかもしれない.(まあいわゆるデザイン手法なわけだが)
1ある用途に用いられる解決手段から検索(もの要素A用途B→もの要素A検索)
2検索された解決手段の課題をマイニングで抽出(もの要素A検索→課題C発見),課題の上位概念化(課題C→課題CC)…
3抽出された課題から検索(課題CC検索),その課題を問題とする用途をテキストマイニングで上位から抽出(用途D)
4用途ごとに手段の適用可能性を検討(用途D―もの要素A相関→実現可能性)…
5用途と手段の組み合わせ検索から実用性を確認(用途D―もの要素A検索→市場性)…
*なぜデザイン思考はゴミみたいなアイデアを量産してしまうのか
https://note.com/studies_ceo/n/nd3c499f24052
*特許文書を対象とした因果関係抽出に基づく発明の新規用途探索
https://www.jstage.jst.go.jp/article/pjsai/JSAI2018/0/JSAI2018_2L103/_pdf/-char/ja
http://hawk.ci.seikei.ac.jp/u-cees/
*阿部 慶賀(2019)
創造性はどこからくるか: 潜在処理,外的資源,身体性から考える (越境する認知科学)
共立出版
https://www.kyoritsu-pub.co.jp/bookdetail/9784320094628
「「創造性」というと,優れた人間が発揮する才能と思われがちだ。しかし近年の認知科学研究は,創造性は個人の才能ではなく,他者との協同や外化など,偏在する外部資源との相互作用なくしては成り立たないことを明らかにしてきた。一方,創造的思考を支える心的メカニズムの研究からは,アイデアの「生みの苦しみ」は単なる停滞ではないことや潜在的に洞察の準備が進んでいることも明らかにしつつある。
こうした知見を背景に,創造性はそれに特化したメカニズムや処理機構を前提としなくとも説明できる,ということが研究者間で合意を得つつある」
p86~99「三人寄れば文殊の知恵は本当か~協同する他者は実在しなくてもよいか~心のなかで作られる他者~創造性は一人で発揮できるか.問題を多角的に捉える契機.自己観察条件↓.偽他者観察条件=.他者成績条件はもともと早く解ける人にとっては軽微.自己の現在状態の評価に作用.「ここまでの知見を振り返ると,「創造性は環境や外敵資源の中にこそある」とは言い切れなさそうだ.~協同の効果は強力なものだが~でしか生まれないというわけでもない.他者を創造し,その他者と協同することができる.~むしろ重要な点は,他者の存在の有無や外的資源と心的処理の線引ではなく,他者を意識することによる自身の偏った見方や制約の見直しにあると言えるだろう.~」
AIでもある程度中間リークをさせるべきか・・・いや見直しの意味がないか.オントロジーベースの分散表現でこれは実現されているとも言えるし,ヒトが介在して顧客ベースでpre-domainが作られている時点でこれは実現されているとも言える.
p145~「ひらめきの突発性はランダムに外部からアイディアを受信するからではなく,~処理として無自覚に進む自身の思考の変化に気づくことで起きる.~外的資源として寄与の大きいものとしては,協同する他者が挙げられる~他者は,必ずしも生身の実在する人間でなくともよい~創造性を特定の個人の才能として捉える見方は主流ではなく,人間一般に備わる認知機能の作用から生じるものとしてみている.~制約論的アプローチに従うと,試行錯誤を通して初期の誤った制約を解消することが洞察に至る堅実な方法だと言える」
読書猿さんの,アイディア大全や問題解決大全を振り返ると面白そうだな・・・
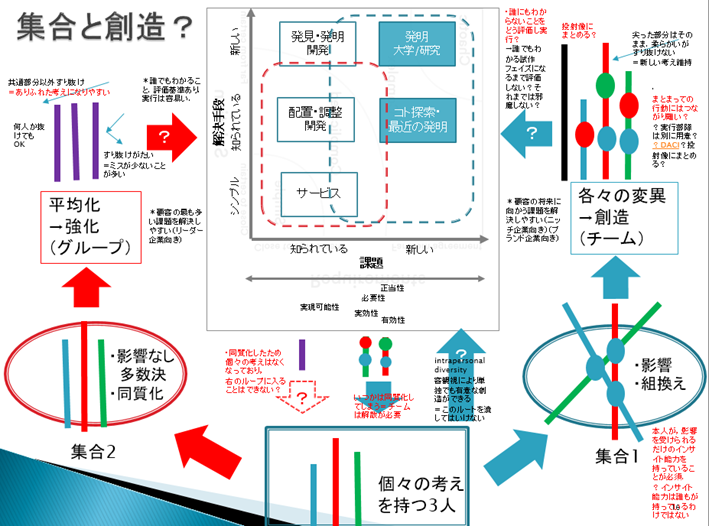
創造性とは、「複数の個性ベクトルに対し作用する組み換えベクター」による個性ベクトルの変異のようなもの、と考えるのも面白そうだ。そうならばベクターを作ればよいわけで。
(DACI(Driver,Approver,Contributors,Informed)の役割を果たす構造を含めることも重要に思える)(ティール組織のadvice processを有効とするような…)
*Ayano Fujiwara(202003)
Who is Generating New Innovations? : An Analysis of Blockchain Engineers
https://ieeexplore.ieee.org/abstract/document/9081416
個人の専門性が高まりすぎると集合しての多様性におけるイノベーションは阻害される。「自己内多様性」が重要、と示唆している?。
エキスパートシステムの組み合わせはイノベーションを生まない、という意味で納得であるが、それ以上はどう考えたものか。創造的AIはAIにエキスパートシステムを組み込んで曖昧にするぐらいでやはりちょうどよいのか?。AIによってエキスパートシステム同等の理論化ができつつある昨今であるがendtoendで自己内多様性を維持することができるのだろうか。
*清水大地(201906)
創造性の枠組み・測定手法に関するレビュー論文の紹介
cognitive studies 26(2) 283-290
https://www.jstage.jst.go.jp/article/jcss/26/2/26_283/_pdf/-char/ja
読み込むこと.
*歪め統合を利用したdata augumentationで入力を「実現可能に多様化」し、2d-CNNを適用したり複数のモデルの個性を組み上げることにより、「より多く」の「明確性の高い」創造的提案がなされうるかもしれない。予想外性は低減するだろうが。
*創造性の高い脳のネットワークに関与する、3つの重要なサブネットワーク
「1つめは「デフォルト・モード・ネットワーク(Default mode network)」
特に思考、関心、注意を伴わない、安静時の「基礎状態」とも呼べる脳の活動だ。これは空想に耽ったり、白昼夢を見るときなどに活動的になるといわれ、独創的なアイデアを考えつくためのブレインストーミングで重要な役割を果たすと研究者たちは考えている。
2つめは「実行機能ネットワーク(Executice control network)」
思い描くアイデアに集中したり、それをコントロールしたりする場合に活動する脳のネットワークだ。クリエイティヴなアイデアが実際に機能するかどうかを評価し、また目標に合わせて修正を加えたり、切り捨てるかどうかを判断する上で重要になるという。
3つめは「顕著性ネットワーク(Salience Network)」
「デフォルト・モード・ネットワーク」でのアイデア生成と、「実行機能ネットワーク」でのアイデア評価を交互に行うために重要だとされている。いわゆる、ふたつのネットワークを交互に切り替えるスイッチのような役割がある」
https://wired.jp/2018/03/31/brain-network-creative-person/
組換→実現可能性→(繰り返し)→創造,かな?.
実現可能性判断をヒトの担当とした場合,繰り返し部分の実装が難しそうかな.
*創造性とは自分を組み替えること。それには、まず、組み替えるべき幹が必要。
幹を作るのは豊富なインプット。リベラルアーツなどはその一部。
幹が小さければ、情報はスルーし組み換えは起こらない。
幹が大きければ、微細な情報でも幹に当たりインサイトを得て組み換えができうる。
幹のベースは主体性。主体性は多分教えられない。各人の望むものを与えることである程度はコントロールできるが、それに意味はあるのか。
最近読んだ書籍の内容をまとめるとこんなところか。
*田中るみ子,中山伸(2019)
文章からの化学物質名を含む単語の認識法の確立と化学物質名 の選択法の検討-特許公開公報を用いて
情報知識学会誌 2019 Vol. 29, No. 3 238-246
https://www.jstage.jst.go.jp/article/jsik/29/3/29_2019_038/_pdf/-char/ja
文章からの化学物質名を含む単語の認識参考.
201912頃,物質記載特許重視に変更したが,どうすべきかまだ考えがまとまっていない.現状,教師を緩めeswで抽出しており,認知に基づく創造的(というかランダム)な特許を上位に抽出できているが,特定の固有名詞に対する認知ならともかく,化学物質名に対する認知など当てにならない.より汎的な別の手法を検討すべきだろう.
*創造性を付与するに当たり,それをインサイトやイノベーションにつなげるためには,イノベーションの道筋の幹(道は限定されるものではないが幹はあると仮定)に沿った構造とできうることが必要となる.
例えば,次が参考となる.
一橋大学イノベーションセンターのResearch liblary
例えば
革新的な医薬の探索開発過程の事例研究
http://pubs.iir.hit-u.ac.jp/admin/ja/pdfs/show/1868
主体がどこに移動しそれぞれの主体に必要であったデータや情報はなんであったか,など.
歪め統合を行うに当たっての基礎知識としている.
*東北大学大学院法学研究科 吉永一行教授
*w2vkeb-mp組み込み。w2v-mpの結果を教師に加え再学習したモデル。上位概念下位概念の発散収束コントロールに能性テスト用。
*例えば、〜酸ナトリウムから単語ナトリウムを取り出し、ナトリウムは燃えるから〜酸ナトリウムも燃える、とするのは間違い。
これを創造性の視点から見た場合どう考えればよいのか。実現可能である提示ではないわけだが……。
うーん、適切なドメインの事前知識を与えていれば、上記のような間違いが起きる可能性は少ないから、実質的に問題はない、ある程度の実現可能性は担保される、と考えればよいのか?。
上記の例では化学ドメインでは不十分で無機ドメインと有機ドメインで切り分ける必要があったといえるだろうか…
少々恣意性が高すぎる気もするな……。
ドメインの違いと形態素区切りによる影響につき、どこかで検証しておこう。
*Research on Product Design Education Based on Evaluation Grid Method
https://ieeexplore.ieee.org/document/9066457
プロダクトデザイン教育に関して言えば、従来の授業では、机上調査や単純な現地調査、非厳格なインタビューなどを主な手段としており、ユーザーの真のニーズや嗜好を正確かつ体系的に把握することができていないことが多い。
本研究の目的は、プロダクトデザイン教育の新たな道筋を探り、学生の創造性を刺激し、学生が設計した概念スキームがユーザーの嗜好を正確に捉えていることを確認することである。
まず、市場調査や特許照会などで設計対象のサンプルデータを収集し、みりょくエンジニアリングの評価グリッド法(EGM)を用いて設計対象の魅力的な要素を抽出することが求められています。
そして、アンケート調査により利用者や潜在的な利用者の魅力評価を得て、定量化理論Ⅰ型(QTT□)を用いてアンケートデータの分析を行う。
最後に、デザイン対象の具体的な特性と需要意図との相関関係を構築し、学生がデザインイノベーションを行う際の参考とすることができる。
本研究は、学生がプロダクトデザインの実習を実施し、現在のプロダクトデザイン教育の科学的・厳密性を向上させるために役立つ。
www.DeepL.com/Translator(無料版)で翻訳しました。
*丸山 知能というものは、分かれば分かるほど先に行ってしまうという感じはします。この50~60年、私たちがやってきたのはそういうこと。では今のレベルで、どこに(知能とそうでないものの)線を引くかということです。
丸山宏氏
GAN(Generative Adversarial Network)のようなものはクリエイティブなことをやっているように見えるけれど、実際にやっているのは、ある統計モデルを作り、そこからサンプリングして出てきたものが、たまたま見栄えがいいと「創造的なもの」に感じる。
よく考えてみれば、バウンダリー(境界)がはっきりしていて、空間がはっきり定義されていて、なおかつ、その中からサンプリングしたものがいいか悪いかがある程度分かっているような問題に関しては、「クリエイティブ」と呼ぶかどうかは別として、ディープラーニングでうまくいく。ただし人は、ほんの時々であっても、今までに全くないものを考えるという能力があって、そこについてはまだ大きなギャップがあります。
〜
丸山 私はコンピューターサイエンスの観点から見ると、ディープラーニングの最大の功績は、「計算ってチューリング機械だけじゃない」ということを教えてくれたのが最大の功績のような気がします。
それは2つのことを言っていて、1つはチューリング機械っていうのは基本的に離散領域の計算しかしない。それに対してディープラーニングはベースのモデルは連続領域のモデルだということ。もう1つはもっと大事なことで、ディープラーニングが出てきたことで初めて帰納的(インダクティブ)なプログラミングができる。つまり計算のステップを与えるのではなく、計算の例を与えることによってプログラミングをするということが、ディープラーニングで初めてできるようになった。
〜
問題はその先なんですね。「再現可能計算」と呼んでいますが、「特定の入出力に関してはこれと同じことをやれ、でも、ここで指定されていないものに関しては、良きに計らえ」というようなタイプのプログラミング、これをディープラーニングが帰納的にやっている。
https://www.atmarkit.co.jp/ait/spv/2006/23/news021_2.html
参加者間の認識のレベルがかなり違うような記事かなという印象。
*日本認知科学会第37回大会 JCSS2020
*扁桃体の役割を射程に入れた「面白い」の言語理論の提案
中村太戯留
意味づけ論、不調和の解消とユーモア、偏桃体の役割についての見やすい総括含む。
AIによる創造性においては、AIと人との不調和段階をどう処理するかの課題が存在するはず・・・。偏桃体のような「ヒトが関連性を感知しやすくするための何らかの装置」は重要なのだろう。「創造性モデルにおいて高sharp値を示した一部の単語について、置き換え候補を自動提示する手段」はありかもしれない。
*「思い込み」の認知過程の定式化に向けて:画像回転課題と事前制約の関係の分析
亀井暁孝,日髙昇平
「人は,現象を説明可能な解釈が複数存在するときでも一つあるいは少数の解釈を選ぶ傾向にある.•論理的には複数存在する解釈の候補から少数を無意識に選択し信じる人の認知的な情報処理を,本研究では「思い込み」と呼ぶ.
クワス算は演算規則の解釈を例に帰納推論だけでは成立しない「思い込み」的な推論方法の存在を指摘している.
観測された現象を説明可能とする解釈が複数存在するとき,多数の事例学習を必要とせず,特定解釈の選択を可能とする推論方法は何かという問いになる」
ええと、ものの集まり(集合)と、その要素間の関係性(構造)をあわせたものが群で・・・
メタ学習を思い込みから説明できるのかな。思い込みの追加と言える知識グラフの追加は必要であるところ、しかしend2endに組み込むのではなく、多くの選択肢を形成した学習後におこなうとよいだろう、専門知識は後半で補正的に、との考えでやはり良さそう?
位数・・・対称性の高さがある時少数学習・・・構造が単純な分布という意味??
関連性の低い対象間の共通点探索プロセスーカテゴリ判断課題との関連による検討
山川真由・清河幸子
「固定的な見方の解消とは**「目立たない」知識を活性化させること**」
目立たない、か・・・上位概念はどうなのだろうな・・・
「関連性の低い2つの対象間での共通点の探索は対象の「目立たない」知識の活性化を促進する山川・清河(2020), 山川・清河・猪原(2017)」
tfidf embeddings/ cluste visはその性質から「関連性の低い2つの対象間での共通点の探索」を行うことができるが、tfidf embeddings/ cluste visによる補正を創造性モデルに直接つなげると良いのだろうか・・・
https://qiita.com/kzuzuo/items/8a80d8974bf3a7db7e54
創造性には「間違えることが必須」と考えていたが、「より弱い特徴も重視する視点が必須(結果として間違えやすくなるだろう)」、と切り替えたほうが良いのか。そうするならやはり、創造的なモデルと知識グラフは切り離しておいたほうがよさそうだ。
まあ、この発表では仮説において有意な相関が取れなかったようだけれど・・・これはいつもそのような思考をするわけではない、きっかけを与える装置が必要、ということなのかも。
背景文脈が虚記憶の生起に及ぼす影響
牧岡省吾†,神浦駿吾
「DRMパラダイムとは•相互に意味的関連のある単語リストを呈示し,後に自由再生をさせると,実際には呈示されていない意味的関連の強い単語が誤って再生される(Deese, 1959) .• Roediger & McDermott (1995) がこれを発展させ,DRM パラダイムを考案した.学習時にルアー項目(例: 空) の連想語(例: 星,月など) から成り立つリストを呈示し,テスト時には学習項目,ルアー項目,その他の未学習項目からなるリストを呈示して再認判断を求める.するとルアー項目は,他の未学習項目と比較して,高い確率で誤って再認される」
洞察問題
創造性のキワをつかむ
13:35~14:05:招待講演1:ネガティブな感性と創造性
(石津智大先生)
悲しみ:安全な心理的距離、醜いが超える-偏桃体・運動皮質
14:05~14:35:招待講演2:創造性の引き出しは手を加えない中にある
(中邑賢龍先生)
14:35~14:50:話題提供1:創造性指標のキモとキワ
(石黒千晶先生)
14:50~15:05:話題提供2:創造性評価の一貫性
(寺井仁先生)
*磯野誠(2020)
ビジョニングによる製品アイデア創出における認知プロセス
https://www.jstage.jst.go.jp/article/jssdj/67/2/67_2_1/_article/-char/ja
歪め統合と絡めて、何が足りないのか考えてみよう。
*教師あり(w2vmp,kebmp,BERT)で単語ベース、教師なし(tfidf embeddings cluster vis,etc)で構造ベース、これら組み合わせだけで十分に創造性を発揮している、と言ってもよいのではという気がしてきた。
教師ありは例えば教えたラタノプロスト等固有名詞を掴んでいるし、教師なしは例えば水性組成物を掴み固有名詞を捨てるように調整できている。結果として固有名詞が入れ替わった場合にも対応できている。…創造性とは言わないか。
*encoderとdecoderは圧縮ー解凍のようなもの。
encoderの段階で錯視が生まれる?。
創造性は、decoderの解凍ミスにより生まれて易いと考えていたが、
創造性も、主にencoderで生まれているのでは?
もしそうだとするならば、「最適なencode」というものは存在せず、「個性的なencode」が存在するのではないか。個性の正体は圧縮の種類なのではないか。
そうであるなら、個性をどう扱うかを決める多様性評価につき、より真面目に議論すべきなのかもしれない。
同じ情報から異なるencodeがなされる点について、そのコントロールをどうすれば任意にできるのかについて、より真面目に議論すべきなのかもしれない。同じ評価基準ではなく個性ごとの評価基準をどう求めるかについて、より真面目に議論すべきなのかもしれない。
(と同時に、encoderを重視していない?GTP-3のようなモデルには先がないのかなと思ったり。mbartやmT5の方向が順当な未来かなぁ。)
*Prof. George M. Whitesides
Curiosity and Science
https://onlinelibrary.wiley.com/doi/abs/10.1002/anie.201800684
「自然や社会を注意深く観察するために好奇心を出発点にすることは、些細なことではないスキルであり、新たな知的活動や冒険の出発点となります。それは、科学における創造性に不可欠な要素であり、新しいアイデアを融通の利かない専門家の正統性に押し込めるきっかけにもなります。」
・創造性について現時点のコメント
(ブレインストーミングと創造性を題材に上げて)
前提:
グーグル式仕事術が「ブレスト」を嫌悪する理由
https://diamond.jp/articles/-/170687?page=3
ブレインストーミングを創造性を生み出す手法だとして無批判に使う人は多いが,本当にそうなのだろうか.
(また創造性を生み出すための技術は,ブレインストーミングを真似るべきなのだろうか)
ブレインストーミングが結局役に立たない理由は、「様々な創造的な意見」が出たとしても、結局はその中から「自分たちで共通して認知できるもの」しか取り出せないから、だと思う。
ブレインストーミングがうまくゆく条件は大した内容でない時だけ。新規な創造性=一部のものしか認知できないもの を求めるときにブレインストーミングは全く有効ではない,だろう.
ということを認めた上で,そこから昨今はアジャイル的な考え方が求められているという認識.
ヒトは無知の知を改善することができなかったから,アジャイル的な運用が始まった。ヒトは無知の知を改善することができない場合は,ブレインストーミングは害にもなり得る。という認識。
試さなわからんのに、ブレインストーミングで(本来避けなければならない)「同調」をしてしまうため、ブレインストーミングをただ行うだけでは,価値があった意見を施行できなくなる。
この条件でブレインストーミングをうまく進めるには、その価値を認知できるほどの専門性を持ったヒトでブレインストーミングを行う必要がある。その集団にとっては結局大した内容ではないから・・・ううむ.
「同調」できるありふれた結論であるほど、多くの人の共感が生まれ,実行可能性は高い。
「社内での」共感を求めてしまえば,その傾向は強くなる。
共感しなければならないのは「顧客」.ここでニーズのズレが起きてしまい,実効性は低くなり得る.
「顧客視点であり,ありふれていないもの・コトであり,今は価値が見え難いもの」を実行しなければならない。
その場合にブレインストーミングをどうすれば害なく運用できるのだろうか。人の質を高める以外で。
個人的には、判断は人がしないほうが良い、となってしまうと思う。
機械なら同調しないし、機械ならPEST云々のような一般には有効だが個別には有効とも言えない次元の少ないフレームワークのみを根拠としないで,より高次元の空間を直接「多様性のある根拠・前提」とし,それを様々な「多様性のある関数・評価」で変換し,それを元にした判断ができうる。
・在宅勤務において気づいたこと
リーモートで会議に参加していて気づいたことがある.
それは,「リモートのほうが忌憚のない意見が出ること」
リーモートでは,周りの情報量が少ない分,「場の空気を読むことができず」,結果,常なら同調するものでも,同調することができず,忌憚のない意見が出ているのではないだろうか.
つまり,リモート会議は,創造的な意見を出すための前提となるのかもしれない.
なお,リモート会議を好まないものは,会議において支配力があるものであり,リモート会議を好むものは,会議において支配力が低いもの,でもあるようだ.
リモートや機械化により,さっぱりと場の空気を削減してしまえば,より創造性を高くできるのかもしれない.
会議の進行をするAIがいくらか公開されているが,このようなAIこそ,創造の役に立つのかもしれない.
AIが会議をファシリテートするサービス「Ecrit(エクリ)」
https://ecrit.ctp.co.jp/
AIで会議を短く、創造的に minmeeting
https://minmeeting.jp/
コンピュータがオフィス会議の進行役になる日が来る? ~椅子を震わせ、意見を引き出す~
https://www.tcu.ac.jp/news/all/20190517-22516/
など
ヒトの認知の限界を解決しているわけではないので,評価も機械化しないといけないかもしれないが
展望:
当初のモチベーションは,市販AIの性能が今ひとつであったためそれを補完できるAIを作ること,ついで「個人用アシスタントAI」を作ること,「未来予測型の提示をするAI」を作ること,だ.
個性把握の先に,それらがある,それらとなっていることが確認できる,と思っている.
VALUENEXデータやいわゆるIPランドスケープから得られる「予測型のコーパスやSNSなどニーズ記載のあるコーパス」を用い,「「類義・関連語」がそれぞれのコーパスが示す価値観に基づき「歪め統合」されるよう」,言い換えればAIが認識するパターンをより適切になるように歪めそして統合されるよう,それぞれの分散表現を作り(述べていないが,作っている.),作られたそれぞれの**「価値観(概念・意味記憶・感受性・個人の世界モデル)」に基づく「個性」を適切に評価**すれば(できれば),教えていない正答を見出すAI,未来予測型AIは実現可能なはずだ.
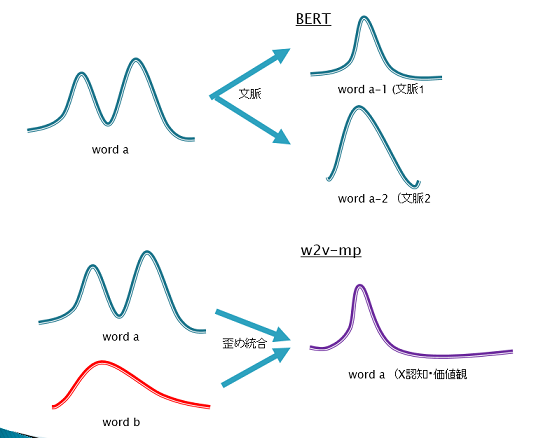
歪め統合のイメージは、補足すると次の通り。
辞書的には、サッカーという単語は、多義語として、ボールをける云々で表現されている。
あるヒトAは、「サッカー」という単語に対し、「雨」や「雷」を思い浮かべるとする。
「あるヒトAの認知」に従った結果が欲しいタスクにおいては、辞書的・汎的な多義語を無視して、「サッカー」と「雨」と「雷」を同義に表現して欲しい。
ここでいう歪め統合とは、この状況下、単語「サッカー」と「雨」と「雷」を、「一つの類似分散表現に押し込める」作業のことをいう。
「辞書的に正しい意味で表現することを無視して、特定の認知に沿った単語の畳み込みをすること」を、「歪め統合」と表現している。
*「歪め統合」とは、クワイン「経験主義のドグマ」に記載のある、「認知的同義性」のこと、と言っても良いかもしれない。
やりたいことのイメージとしては,
SNSに「X製品のAはZだ」
=> その価値観に基づく歪め統合された分散表現を得る
=> X製品またはAで調査したときより上位に
<= 多様性評価しつつ補正(偏った価値観は正解の元でもあるがノイズの元でもあるから)
*教師データは過去から得られまたそうでないといけない.教師データのみから学習したモデルは未来の特許に食いつくとは限らない.7そこで,「教師データより一般的な情報から概念を学ぶモデル」が必要となる.「教師データより一般的な情報から概念を学ぶモデル」の正解率は低下しやすい.このモデルを活かすために,多様性を用いて他のモデルがフォローする体制を作っている.
*「個性・価値観をもつ分散表現・モデル」と,「多様性評価」という2つのポイントが混在しており,ポイントがつかみにくい文章となっている点は認める.しかし,結果を得るためにはその2つは双方必要であり切り離せない.個性がなければ多様性など発生しないし,多様性がなければ評価する意味もない(確率的多様性を評価するなら平均で十分).どこかでまとめ直す予定.
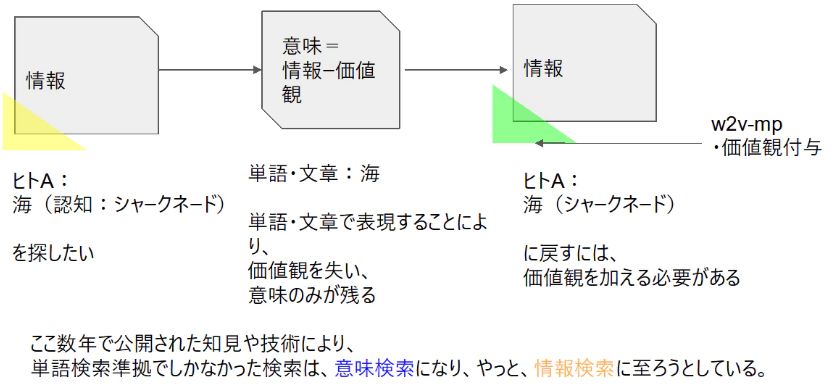
*比較的長距離の記憶をもたせる試みがなされてきているが,自分は入力した文章全体を記憶しても足りないと思っている.自然言語において最も必要な長距離記憶とは,入力した文章全体を超えた記憶,低バイアスの「辞書」または高バイアスの「価値観(概念・意味記憶・感受性)」,へのアノテーションではないかと.このうち「辞書」に注目したものがBERTだと思っている.自分は「価値観」に注目している.(辞書に該当するものは他にベイジアンネットワークやオントロジー,知識グラフなどか.)
(言語とはそも意味以上の情報を「失っている表現方法」なのだから,そこに価値観を「加えて」「意味を情報に再変換」する必要がある,と言っても良い.そう考えると,価値観は画像イメージや発意者の脳波,表情,イントネーションや書誌的立場でも良いな.(複数にソースを学習に利用することをマルチモーダル学習と呼ぶらしい.主体の概念はあるのだろうか.)
西田京介(201911)
事前学習言語モデルを用いたVision & Languageの動向 / A Survey of Pre-trained Language Models for Vision & Language
https://speakerdeck.com/kyoun/a-survey-of-pre-trained-language-models-for-vision-and-language/
VisualBERT等々)
(今のところ価値観をニーズ等からのバイアスに求めているが,特許の技術的範囲という価値観が必要なら明細からのバイアスに求めるほうが良いだろうとも思っている.)(テキストは知識表現,フルテキストは概念表現.に近いか.要約請求項は知識表現,明細は請求の範囲理解のための概念表現,価値観・個性に課題を加えたものは認知を元にした検索のための概念表現,に該当と言えばまとまりそうだ。)(概念をルールベースで作ってしまうと個性が固定され多様性が減少する(やるやらないの差はあるが,それは永遠に維持できるものではない).事業で重要な差異化の参考とする概念づくりであれば,)
*動的フィードバックがあると良い.フィードバックにより変化させるべき対象は,自然言語では教師データでなく,概念だろう.どこかでpretrained word2vecモデルの動的変更システムを組み込むこととしたい.()
*キーワード検索でしかなかった検索は、意味検索となり、やっと情報検索になろうとしている。
*画像分野であれば,個性を考慮する必要などなく,TensorFlow Hubなどから汎用の事前学習モデルを流用してきてもほぼ問題はないのだろう.誰が観るかによってゴリラがサルになったりはしない.しかし自然言語分野では,受け手が持つ概念により理解が大きく異なりえる.ゴリラとの記載からゴリラでなく特定の人と認識する人もいる.ハゲとの記載から京都御髪神社の小学生の絵馬,お父さんのようにハゲませんように,を認識する人もいる(おい)(個人的には,画像では価値観でなく常識,錯視,特にヒトなら後天的に学ぶ「平面から立体を予測する機能」の付加,がまだ足りないとは思っている.これをベースとして転移学習すればより性能は高くなるのでがないかな.すでになされているだろうけれど.(2018年にGQNあり.GQNはword2vecなどテキストの分散表現の影響を受けた,立体概念ベクトル,注目を戻すという点でBERTの画像版,といった印象.とりあえず動画と解説 https://youtu.be/RBJFngN33Qo
https://www.slideshare.net/mobile/MasayaKaneko/neural-scene-representation-and-rendering-33d
世界モデルなど認知的観点との関わり?.画像の場合は視点はどれでも平等で連続なので積和で良く視点のパラメータ化が可能なのだろう.自然言語の場合は概念のパラメータ化に相当するだろうがどうだろうか.自然言語では概念が平等でも連続でもないので少なくとも積和では足りないだろうか.)(Google AI Blog: Moving Camera, Moving People: A Deep Learning Approach to Depth Prediction
https://ai.googleblog.com/2019/05/moving-camera-moving-people-deep.html
運動視差の利用.差のみに注目するなら可能性はあるか.枠のあるベクトル内の差というくびきから逃れた差を求めるアルゴリズムであれば自然言語における概念を表現できるか.))(単語を認識する脳の領域と立体視を行う脳の領域は比較的近い。もしかしたら、単語の分散表現ベクトルとその座標表現は、予想以上に本質的なのかもしれない。)
(画像の立体化技術の一つ。特許調査の理想の一つは、調査対象の画像から立体化するなどしつつ構成を取り出し、文章化して調査することだろう。その過程において画像の立体化は必須。方法や組成は画像から抽出し難いであろうから立体化は手段の一つにしかならないが。総合的なリバースエンジニアリング手法ってあるのかな? )
(画像から構成を取り出す特許等検索システムについて。
自分なら、
テキスト上の構成から、ノードに構成、エッジに相対位置など示す知識グラフを作り、
画像から概要3次元化したデータに知識グラフを適用し、3次元構造を補正し、比較する、コードとするかな。
テキストを後半に置けば、クレームを作ることができる。エッジの特性を変化させれば、視座の多様性を設定することもできる。)
*自然言語系の機械学習において学習データの問題は汎化とまとめられていることが多い気がするが、
個人的には、一般的な構造と個別構造を同時に備える教師データが必要だという点を問題視し、より多くの議論をするべきだと思う。
個人的には、この2つは全く別に学習させる必要があると思う。
この2つを分けないことで,あえてタスクを難しくしている気がする.
難しいタスクを難しいまま処理することは理学的で意味はあるが,簡単なタスクにできるよう考えることがは,実用面に向かうべき現状において最も重要になるのではないだろうか.
*マルチタスク学習と多様性評価
複数のドメインに基づき訓練するところまでは共通するが,マルチタスク学習は全タスクでの平均的な性能を最適化する転移学習を用いた「汎化手法」であるのに対し,多様性評価手法はタスク間の平均でないデータの個性をモデルの個性に基づき抽出する「専門化手法」である点が異なる.
*意味論でなく語用論に焦点を当てている,といえばよいのか?
*創造性まで含めて,文章というものの文脈的意味の単一化容易性と情報の単一化非容易性の把握とその改善がテーマ,と表現すればよいのか?
*今のAIは、写真技術が発達した頃の絵画のように、目的の呪いにかかっている気がする。今後のAIは、ピカソが絵画において写真ではできない多視点や過去の記憶など含めた多面を一つに押し込める手法、キュビスムを生み出したように、AIでしかできない手法を生み出さないといけないのだと思う。
優れた写真や絵画は、1視点においても、受け手のヒト認知を引きずり出し結果として多面的な表現をするが、ヒト認知は安定しない。
ヒト認知を最初から押し込んでおきヒト認知に依存せずとも多面的に表現することが必要となってくるのではないか。
*個人的には、「眼の機械化」ができると良いな、と妄想している。
目玉を機械化してやりたいことは、「文章を画像のように直接脳に入力し理解すること」だ。
「文章を読まずとも一目で大意を理解できるようにすること。」これは多分、機械化した目でしか?できない(こともないけど脳に接続することは必要だろう)。
自然言語処理、文章処理の究極は、「多様体のある次元の概念への適切な圧縮」だろうが、これが適切にできたとしても、脳に直接入力しない限り、不自由な表現、例えば類似する単語で表現する「要約」など、をしなければならず、不可解な受け手の認知に頼ることになるだろう。これに不満を感じる。
この技術の可能性を探してもいる。
*自分がほしい機能は、何らかの文章を作成した際、総合的で任意の関連文章をリアルタイムで提示する機能だ。
まず関連法令、関連特許、関連商品。
表現を揃えることが難しい。上位概念下位概念変換や言い換え要約必須。これら畳み込む・統合した分散表現がほしい(見分けるのではなく)
コード:
求めに応じ,コードを整理した後公開予定.(記載しない2,3の工夫がさらにあるだけだが.)
code
個人的には,オープンベースとなっているAI技術の利用に費用がかかリすぎる現状が気に入らない.費用がかかる根本的な理由はクラウドの使用だと考えているが,ベンダーはクラウド前提から離れようとしない.
mail2mailの非クラウド形式(エッジAIとは違うか?)に整え,知り合いの個人や中小企業からノウハウ含め提供しようかと考えている.
安価なハード,Raspberry Pi,coral,Jetson Nanoなどで動く範囲にしたい.Docker imageを利用した配布が最も容易だろうか.
=> docker image作成.x86用とarm64用.git準備.
=> raspberry piでBERTを動かせないか試行中…メモリが少なすぎ無理そうだが.あと9GBほど.zramでも限界が.
*Raspberry Pi4 4GB & ALBERTならば,なんとかなるであろうか?.
以上.
追記
*BERT: 201903~
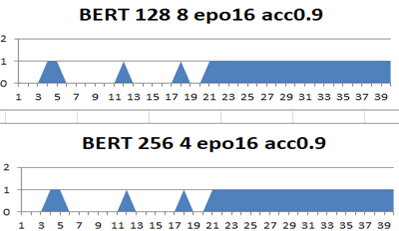
●multilingual model fine-tuned BERT試行.
・正解候補に全問正答.しかし不正解候補については明確に間違えている部分も.
・様々な制限により他モデルと同一の入力としていないが,標準のmultilingual modelからのfine tuningでは,recallが高いという個性が得られそうか.他のモデルを補いそうだ.
・結果はほぼ1 or 0.
code
*BERTの個性はSHAPではわからない.attentionから予想した次の記事を参考にしよう.
・Deconstructing BERT: Distilling 6 Patterns from 100 Million Parameters
https://towardsdatascience.com/deconstructing-bert-distilling-6-patterns-from-100-million-parameters-b49113672f77
https://towardsdatascience.com/deconstructing-bert-part-2-visualizing-the-inner-workings-of-attention-60a16d86b5c1
・BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model
https://arxiv.org/abs/1902.04094
マルコフ確率場言語モデル.フルコネクトかつattentionでwindow抽出した独立単語群と理解して良い?.ならattentionの精度が性能に直結か?.attentionには改良の余地がありそうだからまだ性能向上する?.近傍単語を重要視しているのは純粋に学習によるものであって,CNNのような強制的な構造化によるものではない?.てことは相補的になり得る?
・汎用言語表現モデルBERTの内部動作を解明してみる
https://qiita.com/Kosuke-Szk/items/d49e2127bf95a1a8e19f
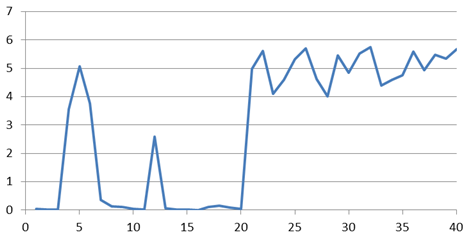
●multilingual model fine-tuned BERTを市販AIの代替とし,多様性評価手法総合判定試行.
・評価データにおいて(正解に配置すべきであった3,4(図の4,5)を除く条件で),市販AIより明確に,「上位すべてが正解候補となる理想状態」となった.(市販AIとの比較を出すべきだろうが,評価データ不足の現状では差が適切に示されず強調され過ぎと思われたため当面示さず.).
・各モデルは40問中3問は正答しない.multilingual model fine-tuned BERTでも2問正答していない.その条件下,多様性評価手法を用い総合判定させることにより,正答しない問は0となった.つまり,多様性評価手法は,現状の簡易方法でも,(使用した条件の)BERTより優れた結果を出すことができている.市販AIに多様性評価手法を適用したときと同じように.
・この評価データセットではこれ以上の評価はできない.そろそろデータも蓄積されてきた.教師データの再検討と,評価データセットの作り直しをするべきか.(モデルの個性という偏った課題であるため,標準データセットが用意しがたいのが悩みどころ.)(AIの補完をヒトで行っているわけだが,現状,実データで見落とし等の問題が見られていない.)
*予想よりは,処理速度は速くメモリ負荷も軽かった.BERT実装しておこう.何でも食って性能向上できうるってのはこの個性,多様性評価手法の良いとこだ.
●実データで,multilingual model fine-tuned BERT試行.
・eval_accuracy = 0.9.しかし評価ほぼ1のFPが目立つ.意外と単語レベルでは簡単な問題でFNも.
・文字ベース512制限では情報量が少なすぎるのか,標準モデルは特許情報を全く食っていないこともあり学習済みの文脈情報とずれすぎているのか,判定器のコード修正が必要なのか・・・.改良必要だ・・・(個人的には,文法構造自体にはある程度の理論的必然性があり,それを壊しすぎると限界があるのでは,と思っている.サブワードはOOVを無くすという当面の課題の解決には良いのだが,やりすぎてもいけないのでは.)(日本語は主体も語順も助詞も多様なので,文法構造を壊してもそれほど大きな問題とはならないとも思うが.)(どの言語でも文法とは結果として見られる傾向であって従うべき理論に昇華されてはいないという意見もある.)
*vocab数の問題もあるかもしれない。vocab内の単語のみで評価するのでFP・・・XORを考慮できないと仮定するならつじつまが合わないか?。自前の事前学習は現実的ではないが・・・
*過学習はeval_lossの傾向からすると、していないように見える。
●評価データで,黒川河原研BERT日本語Pretrainedモデルfine-tuned BERT試行.
・予想以上に[UNK]が多い,eval_accuracy = 0.675.
・文字ベースではFP多量かつ意味希薄化,単語ベースでは[UNK]多量かつ語彙限界.sentencepieceモデルは中間だろうか.BERTでは巨大なコーパスを食い文脈を徹底的に見分ける方向が本筋だと思うのだが,上記ほか様々な制限(たとえば入力の制限.入力自体が文脈を分けるほどの情報量を持つことができない?)があるため,hotlinkのように,分野別に学習したモデルを使うのが適切と言えるのかもしれない.しかし,BERTの事前学習は負荷が大きすぎる.実現可能性においては文字レベルに分があるが,有効性においては単語レベルに分があるだろう.どうするか・・・.結果に差がなかったため,直和直積concatの有効性は低いだろう.内容語に限定してみるか.(特許の名称要約請求項までであり辞書的なモデルに食わせることを条件とするならば,前述の理由に加え,体言止めが多いこと,日本語らしからず述語の重要性が低い?ことから,やはり機能語を除いても良いように思える.)
●実データで,multilingual model fine-tuned BERT(名詞限定)試行.
・eval_accuracy = 0.9.個別確認しかできていないが,市販AIが見逃す正解を掴んでいる.名詞限定により非限定よりもFPが減少した.
●評価データ,実データで,黒川河原研BERT日本語Pretrainedモデルfine-tuned BERT(名詞限定・tokenization.pyコメントアウトなし)試行.
・eval_accuracy = 0.9.1サンプルに1箇所ほど[UNK]あり.評価データから得られた波形はmultilingual modelと変わらず.個別確認しかできていないが,市販AIが見逃す正解を掴んでいる.黒川河原研モデルはmultilingual modelより多少,良いかもしれない.
(AttentionがBERTの性能に主因子であるとして、self-attentionが文章内でより強い意味を示すであろう名詞のみを使い計算されているので、文脈が考慮されすぎず、このような結果になるのであろうか…)(Positional encodingの意味は?。)
*BERT Rediscovers the Classical NLP Pipeline
Ian Tenney, Dipanjan Das, Ellie Pavlick
(Submitted on 15 May 2019)
Pre-trained text encoders have rapidly advanced the state of the art on many NLP tasks. We focus on one such model, BERT, and aim to quantify where linguistic information is captured within the network. We find that the model represents the steps of the traditional NLP pipeline in an interpretable and localizable way, and that the regions responsible for each step appear in the expected sequence: POS tagging, parsing, NER, semantic roles, then coreference. Qualitative analysis reveals that the model can and often does adjust this pipeline dynamically, revising lower-level decisions on the basis of disambiguating information from higher-level representations.
https://arxiv.org/abs/1905.05950
*The Bottom-up Evolution of Representations in the Transformer: A Study with Machine Translation and Language Modeling Objectives
https://arxiv.org/abs/1909.01380
https://lena-voita.github.io/posts/emnlp19_evolution.html
・・・
*BERTは優秀な(有向性がないという意味で)辞書ではあるが,「それだけでは」現実的な発展性があると感じないな・・・
(p26「情報検索の本質的目標は、単に意味を検索することではなく、それを超えた何か、すなわち情報を検索することだ」という視点において.)
*BERTは,意味論において邪魔な統制語彙を社会的認知観点に基づき避けるが,個人的認知的観点からの歪め統合をできていないはず.当面そのような個性と認識しておこう.
*試行した条件下のBERTでは,特徴抽出を自動に任せる手法よりも,特徴を任意に限定する手法のほうが適しているかもしれない.入力からのストップワード除去がクリティカルになる感覚がある.
(不要要素や同時出現要素の削減,入力値の次元圧縮,語順変更など興味深い.マルコフ確率場生成モデルという点が気になる.(語順をtfidf順に変更した場合,attentionは理解不能であった.とはいえ理解可能と言えうる箇所もあった.試す価値はあるか.BERTはその辞書的性質と入力制限から,トピックとの組み合わせにおいてより良い結果が得られそうに思える.該当トピックの文章で学習したBERTを用いるならトピックも不要かもしれないが,その場合でもトピックが動的な場合はなお課題が残っているだろう))
*厚生労働省第7回保健医療分野AI開発加速コンソーシアム資料 人工知能を用いた患者安全性向上のための事故報告からの知識抽出 https://www.mhlw.go.jp/content/10601000/000502269.pdf
文字レベルと単語レベルの直和.recallはこれで課題に対し十分なのだろうか.BERTの結果記載有り.ベースはこれ?.2016年のSoTA.
Neural Architectures for Named Entity Recognition https://arxiv.org/abs/1603.01360
*課題と教師とモデルを適切に調整すれば,少数教師は可能と思う.このまま少数教師で性能が出るようであれば,現在の教師群を雛形とした,1教師簡易無効資料調査機能を実装してみる予定.
(文章レベルやセンテンスレベルにおけるベクトルの類似から無効資料調査や権利化可能性を探る手法が流行だが,今のところ,充分と言える成果を見ない.その理由は,文体や文法の多様さの影響をネガティブにも強く受け,距離が離れすぎてしまうことがあるからかもしれない.文法から離れ単語を重視しそうなBERTからセンテンスベクトルをとる手法は現在の手法より見込みがありそうに思える.諦め,雛形を用いると現実的な成果が出る感覚がある.)(とりあえず、文章上の解像度が異なる上位概念・下位概念を同一次元で表現する手法が最低限必要だと思う.word2vecとaveragepoolingを用いたマルチウインドウCNNで擬似的に解像度統一はできるかもしれない。いや、マルチウインドウより文章の解像度を判定しウインドウサイズを決定する手法のほうが良いか。ベクトルなら、分散表現を作成する際のコーパスで調整できるか?.特許ならコーパスに明細を含めるだけである程度の成果が得られそうな感もある.)
*Facebook FAIR's WMT19 News Translation Task Submission
https://arxiv.org/abs/1907.06616
Transformer,データクリーニング,アンサンブル,全結合層拡大など.人の翻訳を超える評価.BERT対応,方向性はあっているのかな
*Ken'ichi Matsui(202001)
BERT入門
https://www.slideshare.net/matsukenbook/bert-217710964
詳細.
ある単語を類似単語との合成ベクトルに変換し新たな単語ベクトルとするのはどうだろうか.例えば,kidとplayingの合成ベクトルが,元のkidの単語ベクトルとなる,などと.
特定の単語に対し,予め統合したい単語を任意に合成しておき,「任意の歪め統合」を達成する,というのも面白いかもしれない.
(違うな.これは統合でなく分散になるな.とはいえなにかに使えそうだから覚えておこう.「任意に文脈を変更」するある程度の助けになる,かもしれない.)
*BERTを1年ほど使用して思うところだが,そも最適な使い方ができていないことはおいておいて,BERTは学習データが多いほど優秀となる,のはよいとして,BERTは学習データが少ない,CNNと同等である,場合,他の手段より無能となるようだ.豊富な学習により文脈を学習しきらなければただの内積になりかねないというところに注意が必要に思える.より良い学習済みモデルが欲しいtところだ・・・
*exBERT
トランスフォーマーモデルで学習した表現を調べるための視覚分析ツール
A Visual Analysis Tool to Explore Learned Representations in Transformers Models
Benjamin Hoover, Hendrik Strobelt, Sebastian Gehrmann
Large language models can produce powerful contextual representations that lead to improvements across many NLP tasks. Since these models are typically guided by a sequence of learned self attention mechanisms and may comprise undesired inductive biases, it is paramount to be able to explore what the attention has learned. While static analyses of these models lead to targeted insights, interactive tools are more dynamic and can help humans better gain an intuition for the model-internal reasoning process.
We present exBERT , an interactive tool named after the popular BERT language model, that provides insights into the meaning of the contextual representations by matching a human-specified input to similar contexts in a large annotated dataset. By aggregating the annotations of the matching similar contexts, exBERT helps intuitively explain what each attention-head has learned.
Thanks to Jesse Vig for feedback. Please let us know what you think by commenting below!
http://exbert.net/
BERTのattentionハイライト。
*Received October 31, 2019, accepted November 13, 2019, date of publication November 18, 2019,date of current version December 23, 2019.
Improving BERT-Based Text Classification With Auxiliary Sentence and Domain Knowledge
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8903313
*huggingface/transformers の日本語BERTで文書分類器を作成する
https://qiita.com/nekoumei/items/7b911c61324f16c43e7e
pip install transformersで,様々なBERT派生モデルなどが使える.
SpanBERT入るかな・・・
https://github.com/huggingface/transformers
https://github.com/facebookresearch/SpanBERT
These models have the same format as the HuggingFace BERT models, so you can easily replace them with our SpanBET models. If you would like to use our fine-tuning code, the model paths are already hard-coded in the code :)
とあるな.
*Camphr: spaCy plugin for Transformers, Udify, KNP
https://qiita.com/tamurahey/items/53a1902625ccaac1bb2f
色々と揃ってきた。そろそろ素のBERTから乗り換えても良いかも。
(BERTをTensorflow2.0に対応させるべく色々修正してみたが・・・あきらめた.ラッパーで十分なのさあたしゃ・・・→tf2用BERTがあるらしい https://stackabuse.com/text-classification-with-bert-tokenizer-and-tf-2-0-in-python/)
*BERT Encoder
https://peltarion.com/knowledge-center/documentation/modeling-view/build-an-ai-model/blocks/bert-encoder
https://peltarion.com/static/bert_encoder_block.svg
*DistilBERTの日本語事前学習モデルを公開しました。
BERTモデルと比較して、サイズが約40%小型化、推論が約50%高速化、精度は分類タスクで約90%となっています。
https://github.com/BandaiNamcoResearchInc/DistilBERT-base-jp
*ストックマークが公開した言語モデルの一覧と振り返り(20200626)https://tech.stockmark.co.jp/blog/list_of_the_published_learning_models/#bert
体験談は非常に面白い。
追記:
・概念を明確化するために多様性評価手法に名前つけとけば,とのこと.「タイス Thaïs」にしておく.
*いまいち。わたしゃAIモデルを多次元空間の多様体を表すものとみなしており、その多様体のエッジは動的平衡を保つ為うごめいており確定するものやさせるべきものではない、と考えている(法と同じく)。
多次元空間のブヨブヨした多様体と言う字面は、クトゥルフ神話を思い起こさせるなぁ。「ヨグYog」のほうが良いか?
そろそろセサミストリートつながりの名前はつけられなくなり、クトゥルフ絡みの名前がつけられるようになったりしてなぁ。
#類似研究:
見つけ次第追記.
個人的には当たり前すぎるやり方だと思うのだが,意外と目につかない.(無効資料調査で1890年の文献まで遡ったことがある.異なる視点と用語が使われているだけで車輪の再発明だったってのはよくある話だ.)
*以下引用は当面のメモ.
Xiaochuang Han, Jacob Eisenstein.
Unsupervised Domain Adaptation of Contextualized Embeddings: A Case Study in Early Modern English.
arXiv: 1904.02817
Gözde Gül Şahin, Clara Vania, Ilia Kuznetsov, Iryna Gurevych
LINSPECTOR: Multilingual Probing Tasks for Word Representations
arXiv: 1903.09442
L. Elisa Celis, Vijay Keswani
Implicit Diversity in Image Summarization
arXiv: 1901.10265
Abdulaziz M. Alayba, Vasile Palade, Matthew England, Rahat Iqbal
A Combined CNN and LSTM Model for Arabic Sentiment Analysis
arXiv: 1807.02911
Alex Wang, Kyunghyu8n Cho
BERT has a Mouth, and It Must Speak:BERT as a Markov Random Field Language Model
arXiv: 1902.04094
佐藤 進也 (2018)
検索対象の多面的理解支援のためのWikipedia記事中の列挙を利用した関連情報発見
知能と情報, 30(6), 788-795
https://www.jstage.jst.go.jp/article/jsoft/30/6/30_788/_article/-char/ja/
「既知の主題内容の外枠にある新しい概念,概念関係の外枠を欲する」「検索対象の多面的理解を支援することを目的として,ユーザーが与えたクエリから関連情報を発見する方法」
P.インクベルセン (1995)
"情報検索研究一認知的アプローチ"
トッパン
「複数の異なった複雑なモデルを実際に組合せて,知識べ一スに基づいたコンピュータ仲介機構をも含む相互作用的情報検索システムを設計するための理論および枠組みを,打ち立てる」ことを目指した理論書」
https://www.jstage.jst.go.jp/article/jcul/47/0/47_387/_pdf/-char/ja
見つけた!?
Tatsunori B. Hashimoto, Hugh Zhang, Percy Liang (2019)
Unifying Human and Statistical Evaluation for Natural Language Generation
arXiv:1904.02792
Iyad Rahwan,et al. (2019)
Machine behaviour
Nature, 568, 477–486
「人工知能を搭載した機械は、社会的、文化的、経済的および政治的相互作用をますます仲介しています。人工知能システムの動作を理解することは、それらの行動を制御し、それらの利益を享受し、それらの害を最小限に抑えるための私たちの能力にとって不可欠です。ここで我々はこれがコンピュータサイエンスの規律を組み込んで拡張し、科学全体からの洞察を含む機械の挙動を研究するための幅広い科学的研究アジェンダを必要とすると主張する。最初にこの新興分野に欠かせない一連の質問を概説し、次に機械の挙動の研究に対する技術的、法的および制度的制約を探ります」
「人々は何百年もブラックボックスを研究する科学的方法を発展させてきましたが、これらの方法はこれまで主に『生き物』に適用されてきました」と、マサチューセッツ工科大学(MIT)メディアラボの研究者であるニック・オブラドヴィッチ博士は述べる。オブラドヴィッチ博士は、4月24日付でネイチャー誌に発表された新しい論文の共同執筆者だ。「新たなブラックボックスであるAIシステムを研究するために、同様の多くのツールを活用できます」。
産業界と学術界の多様な研究者で構成する同論文の著者グループは、「マシン・ビヘイビア(機械行動:machine behavior)」と呼ばれる新しい学問領域をつくるべきだと提案している。動物や人間をこれまで研究してきたのと同じ方法、つまり、経験的観察と実験によってAIシステムを研究しようするアプローチだ。
https://www.media.mit.edu/publications/review-article-published-24-april-2019-machine-behaviour/
(参照 20190428)
Hiroshi Maruyama's Blog/ 丸山宏
高次元科学への誘い
https://japan.cnet.com/blog/maruyama/2019/05/01/entry_30022958/
(参照 20190502)
「複雑だけど構造を持つ、すなわち「非常に多くのパラメタがあるが、それぞれがお互いを束縛しながら動くことで出来るモデル(数学的には超多次元空間に埋め込まれた多様体で表現されるようなもの)」という考え方もあると思います。このような考え方が、生物学や社会学や、科学におけるその他の多くの「面白い問題」のモデル化に必要になってきている、という認識が私が「高次元科学」と呼ぶものの正体です」
財津亘 (2019)
"犯罪捜査のためのテキストマイニング"
共立出版
世界の「謎」解くカギ、深層学習は「因果性」を発見できるか?
深層学習の人工知能(AI)は、多くのデータの中から関連性を発見することは得意だが、因果性を見い出すことはできない。5月上旬に米国で開催された「ICLR2019」で、著名なAI研究者が因果関係を分析する新しいフレームワークを提唱した。
by Karen Hao2019.05.17
https://www.google.com/amp/s/www.technologyreview.jp/s/141062/deep-learning-could-reveal-why-the-world-works-the-way-it-does/amp/
(参照20190521)
石垣 司,他 (2011)
日常購買行動に関する大規模データの融合による顧客行動予測システム
人工知能学会, 26(6), 670-681
https://staff.aist.go.jp/takenaka-t/5075626C69636174696F6E_reD-B61takenaka.pdf
ベイジアンネットワーク
足立 康二,他 (2010)
ベイジアンネットワークによる複合機故障診断技術
富士ゼロックステクニカルレポート, 19, 78-87
https://www.fujixerox.co.jp/company/technical/tr/2010/t_01.html
Zhunchen LuoEmail authorJun ChenXiao Liu (2018)
Real-Time Scientific Impact Prediction in Twitter
CCF Conference on Big Data Big Data 2018: Big Data, 108-123
Lizhong Xiao ; Guangzhong Wang ; Yuan Liu (2018)
Patent Text Classification Based on Naive Bayesian Method
2018 11th International Symposium on Computational Intelligence and Design
(ISCID)
TF-IDFとナイーブベイズでacc93.9%.TF-IDFベースでそこまで?
ナイーブベイズでのモデル適用確率算定にも期待が持てる?
ワタシから始めるオープンイノベーション
価値共創タスクフォース報告書 (201906)
(知的財産戦略本部会合2019年6月21日 参考1書類)
https://www.kantei.go.jp/jp/singi/titeki2/190621/sankou.pdf
「脱平均」「融合」「尖った人材」.考え方は同じだが、尖った人材をどう活かすかについての記載はない。そこが要点だと思うのだが扱いきれるのかね。
Diversity in Machine Learning
https://arxiv.org/abs/1807.01477
https://arxiv.org/pdf/1807.01477v2.pdf
伊庭幸人,持橋大地ら(2018)
ベイズモデリングの世界
岩波書店 p69−
https://sites.google.com/site/iwanamidatascience/BayesModeling
Aylin Caliskan1,, Joanna J. Bryson1,2,, Arvind Narayanan1,e al (2017)
Semantics derived automatically from language corpora contain human-like biases
Science Vol356, Issue6334, pp. 183-186
https://science.sciencemag.org/content/356/6334/183.full
以下保留
#*付録:
pythonで可能とできることが多く感動している.
特にpandasとjupyter notebookの便利さと言ったら.
ごく簡易に迅速に母集団を確認する際には,pythonで基礎集計部分を作っておいたnotebookに読み込ませpandasベースで確認したほうが,下手に使わない機能ばかり豊富な市販ツールやexcelより便利.
私は自動車ではロードスターを好むが,linuxやpythonはロードスターと,いらない機能は余裕なんかではないただの贅肉で思考や行動を限定させる足枷だ,という部分で共通している気がする.イノベーション「となっている」発明にも関わるこの考え方,とても好きだ.
Google「怠惰であることは美徳.シンプルに大事なとこを」
code
簡易迅速確認ならワードクラウドを加えるのも良いか.
code
5分でできるわけで.(ワードクラウドは,数式に色がついて見えたベーテの逸話や不思議の国のアリス症候群を想起させてくれるお気に入り.)
ついで,頻出語だけでは理解し難いのでtfidf上位語に限定したワードクラウドを・・・
会社名でもIPCでも審判情報でもなんでもソートできるが,例えば単語&ベクトルでソートしたところ,2015年に出願の山がみられた.2015年前後の特徴語はなんだろう.2015年以前が複数抽出装置,以後が単語文章学習方法装置.ルールベースから深層学習への切り替わりかな.Yoon Kimの自然言語CNNの文献が2014年の公開だが,このあたりの影響が大きいのであろうか(適当).当時のSNSのトレンドは・・・
独立した単語のみを見ていてもわからないから単語共起ネットワークも見るか・・・
IPCネットワークを図示させ分類上の共起性の変化からより詳しい動向を(分類共起についてはよりやりようがあるだろう.個人的には分類の正確性に疑問を持っている,というと怒られるが,分類の主観性が分野によっては邪魔をすると言うか・・・ので,後回しにしている.)・・・
ついで,TF-IDF上位語を前述のようにベクトル化し,plotlyを用い各特許の類否をインタラクティブに可視化し,トレンドやトピックをみるのも良いか
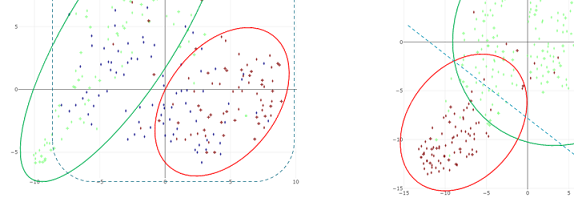
(TF-IDF上位語を用いる手法ではモデルの相違ならともかく特許間の類似を見ることは難しいが.)(と思っていたのだが,固有名詞が適度に削れ,絞り込みを前提とするなら悪くないかもしれぬ.母集団を変更すると特徴語が変わりその点がとても使いやすい(TF-IDFは動的に,上位語母集団では上位語を特徴とし下位語母集団では下位語を特徴とする.インサイトを得つつ絞り込みをすると適切なものを得やすい.静的に目的物を抽出する教師ありとは異なる使いやすさがある.valuenexは本当に良い視点を持っていたのだのう).請求項とTF-IDFの相性も良い.)(とはいえ,少し固有名詞を救済するとより良いだろう.トピックごとの抽出や名称重視の抽出を行っても良いかもしれぬ.クラスタリング実装(こちらのクラスリングは,非特徴を削減すると言うよりも,余分な類似を統合し文章の意味を特定数に磨き上げていると言うと,イメージに近い.概算上,クラスタリング前は0.62単位,クラスタリング後は0.80単位,30%ほどの性能向上となる.)(SCDVはもう少し柔軟性が高いとよいのだが.行き止まりではあるが補強に使えるか.)(あらたに検証データ460件を前向きに集めた.不正解候補なし,2分類.この検証データを本手法にかけロジスティック回帰をおこなったところ,accuracy0.9875となった.本手法は,不正解候補なしの2値分類ならば,この程度の性能も出る.そして不正解候補が混ざってもこの可視化の目的において問題とならない.十分だろう.しかしきれいに分かれるものだ・・・自分の主観的なラベルと文章ベクトルの傾向が見事に一致している(この手法については標準データセットを用い評価すべきだろう.適当なものを探す予定.).なお,下図左,ノイズ教師データあり,2分類,のように,ノイズ教師データ(この場合は不正解候補と言い換えても良い.以下まとめてノイズと表記する)(青点)の分類はできない.本手法においては,他と類似し難く一定の集団をとれないノイズは,このように全体に分散されてしまうのだろう(これは理論的な説明が可能だろう)(このノイズが全体に分散される現象は,キーワードベースに重みで対応しているvaluenex ~Radarでは起きないのでは.自分はこうすることで可能性が増えている,例えば創造的なインサイトが増える(分構造の類似性のみの共通性からのインサイトも得られる),と思っているが,母集団のとり方によっては意味不明にもなるだろう.).このノイズは教師ありでないと見分けることは難しいだろう(下図左は教師データ.つまり教師ありではこのノイズを見分けている・・・いや,教師データを見分けられるのは当たり前として個別に確認したことがなかった.どのように見分けているか確認しておくべきか).))(本記事内容を入力しG06Nの特許群においてベクトルの類似を見たところ,5798624が最近となり,富士通5733166モデル全体の合成,富士通2018170004患者行動予測,Preferred Networks 5816771学習装置ユニット内部状態共有接続システム(重要そうな特許だな)が近くに現れた.興味深い.)・・・
→tfidf/cluster vis: tfidf-word2vec-clustering visualization
https://qiita.com/kzuzuo/items/dcdf5550bcb024897de0
Mixout: Effective Regularization to Finetune Large-scale Pretrained Language Models
https://deepai.org/publication/mixout-effective-regularization-to-finetune-large-scale-pretrained-language-models
モデル間リーク.自分は中間部分でのリークに手を出す気はないcheck systemの設計が難しいから.
最後に,気になった特許を教師とし自作AIにかけ,特許の類似度に基づく並び替えをするのもありだな.
(出願番号など検索用データをplotlyの範囲指定で得ても良いが,前記TF-IDFの手法では性能が不十分で教師として適切な特許のみを選択することが難しい.)(教師なしで作成されたベクトルから適切な並び替えができるほどの類似情報を得ることは,前述の通りまだ限界があると思っている(9割が限界か?).最後はやはりニューラルが適当かな.)・・・
など,自己の課題の求めるまま,最低限に便利にできる.
類似特許を近くに表示するだけなら難しくはない.表現をすべて吸収し漏れなくかつ特定の傾向を持たせようとすると難しいか.(後者2つは教師ありに任せれば良いことなので多様性評価の立場からするとどうでも良い.補えばよいだけ.)
自作AIにより得られた重要特許を教師なしの文章ベクトルとして可視化し,特定の母集団から得られた文章ベクトルと重ねて表示し,見落としのチェックをする,母集団変更の必要性をチェックする,などもありえる.
自作AIの3,ヒトの1,ベクトル可視化の1,計5つの個性を用い多様性評価をしたことになる.
また,類似する特許群が設定した正解特許の近くに図示されており,その内容がインタラクティブに確認できることにより,他分野からの流用・置き換え・別の効果の示唆など,豊富なインサイトも得られるようになっているとも言える.

(多様体仮説.トポロジー.ホモロジー.パーシステント図.)(教師なしベクトルによるインサイト・仮説づくり→教師あり自作AIによる予測→ベイズによる仮説に寄与するデータの確率化→・・・のループを作ることができれば,知財や研究における一通りが終了するのだろうか.(ほぼ完成))
最終的には,知識グラフを作っても良い.
Evaluation of a Visual Tool for Early Patent Infringement Detection During Design
https://link.springer.com/chapter/10.1007/978-3-030-24781-2_12
課題を最も理解している実務屋こそ,pythonを使った自作をすべきと感じる.自由度の高さは質にも影響するだろう.
幸い,自作のハードルは高くない.
「僕はこのときはっとした。なぜプリンストンの実験室から、どんどん報告が出ているのかに思い当たったからだ。彼らは実際に自分たちの手で造りあげた装置で研究しているのだ。だからこそどこに何があり、何がどう働いているかが、ちゃんとわかっているのだ。(ファインマン)」
*もちろん自作ではできない範囲はある.しかし,それができないとわかってからその機能を持つ製品を採用してもよいだろう.自作の過程で,何がどのような理由でできないのか,課題を理解したわけだから,より良い選択と採用が可能となっただろう.
*実務で使うとなると権利関係のクリアランスにそれはそれは苦労をするわけだが.
*ベンダーの製品を使う理由は、1それで十分であり2希望するものが迅速に手に入り3法的リスクを自ら負わないこと、など、にある。この内、1,2は、従来のフレームでは対処できない差別化、新ルール、ニッチ化が進む中、不十分と言える。それに気づいている会社は、自作も検討していると思う。問題は3と開発コストだけれど。
*深層学習の場合でも教師の質をより重く問わなければいけないと思う.
教師データの質ではなく,教える主体としての「教師」,つまりAIを現場で扱うヒト側の質だ.実務の上では,AIの優れている点を引き出せない教師とならないこと,ヒトがAIの足を引っ張らないこと,が重要となるのではないだろうか.
(何を教えるか,ではなく,不用意に削らないことのほうが重要に思う.)(ここで言う教師とは,自学できる年齢の生徒に対する教師ではなく,自学するにおぼつかない年齢の生徒に対する教師に相当する.生徒が本当に自学できるようになったのなら,教師の重要視は薄れる.自作AIはできるだけ早くそちらに持ってゆきたい.)(生徒が本当に自学できるよう←メタ学習の分野といってよいのか?)
http://publications.jrc.ec.europa.eu/repository/bitstream/JRC113826/ai-flagship-report-online.pdf
*失敗から学ぶ機械学習応用
https://www.slideshare.net/mobile/HiroyukiMasuda1/ss-181844477
*Designing the nteract Data Explorer
https://makoto-shimizu.com/news/jupyter-nteract-intro/#
Jupyter notebook代替。
Pandas dataframeを何もせずインタラクティブに表示。これすごいな…
*私は,手段の完璧さと目的(課題)の混乱が最大の問題である論者です.好きな人物は,と問われれば,ファインマン,ベンジャミン・フランクリン,アインシュタインを挙げます.また,リベラルアーツを評価しています(課題を持てていないものの多くがリベラルアーツ不足に見えるという理由の範囲で).
*「評価の低いモデルをただ捨て去るのは間違いである.シンプルなモデルが役に立つ場合それは必ずしもすべての実験データなどと一貫性がある必要はない」,という理解は,物理生物学など持ち出すまでもなく広い範囲で言えるところ.
必要なモデルとは,「予め得られるドメイン知識と教師・非教師データを用い構成され,今後得られる実データから個別に設定された課題を解決できるモデル」.そのモデルという手段が汎的に使えるかどうか,手段が汎的に評価が高いかどうか,は,あまり重要ではない.
ここを勘違いしている人が多すぎることは,実装普及において最大の問題の一つだと感じている.
(まず,評価はある目的を達成するための手段であり,目的ではない.評価結果から拡大解釈すれば当然に間違える.)(ガイドラインに従えばすべての患者を適切に治療できるか,と問われれば,そうではない,というのが答えだ.それと同じ.実務では個別の患者に,個別の課題に,注目することが重要.)(「モデルの予測精度評価は動作確認程度のもので、これ自体をKPIにするのはマズい」そのとおりでしょうな.)(適用範囲が絞り込まれていない(適用範囲が未知と言っても良い)ことが多く、この点からも動作確認程度の指標に過ぎないと言えるだろう。なお、モデルの適用範囲を理解できていないことは、PoC倒れの大きな原因となっているのだろう。)
*少々古いが,最初に次を修了するとよいのではないかと感じている.学び始めて1年経過したが,学会を除き,どの「いわゆる」わかりやすい講習等より役に立った.
Machine Learning
by Stanford University
Andrew Ng
https://www.coursera.org/learn/machine-learning/home/welcome
11週間.毎週テストとプログラム提出必要.修了するとCongratulations! You've successfully completed Machine Learning!と.
講師のAndrew Ng御大は人を乗せるのがとてもうまく,非常に楽しく学べた.多分わざと入力を間違えて見せリラックスさせたり.いや面白かった.課題を持っていないものは価値のあるコードを書けない,小手先の知識など課題がなければ意味がない,とも教えてもくれた(のはこの講義だったか)
最初に良い先生に出会うかどうかはクリティカルで,固有名詞の説明のみから入る講義を最初に受けてしまえばその段階で発想できなくなるという重い負債を得てしまう,感覚がある.
Advice on building a machine learning career and reading research papers
by Prof. Andrew Ng
https://www.kdnuggets.com/2019/09/advice-building-machine-learning-career-research-papers-andrew-ng.html
多々入門者向けの人工知能系の講習会や書籍があるが,そんなものに何度も参加したり読むより,論文を読み学会に参加したほうが良いと思うよ.
(自然言語AI分野のように,まさに日進月歩と言える分野においては特に,固有名詞の説明のような基礎講習など,評価しているつもりの偏見持ちを増やす程度にしか,役に立たない.ものを理解するにあたり「最初に」枠を示す教え方・得る覚え方,迅速に柔軟性のない偏見を作るようなやり方,は,発想を阻害するため好むところではない(誤解の無いように一応書きますが,枠自体が本体である法律などは別です.これは外枠から始め外枠を調整してゆかねばならない.始めから無限の要素を備えており枠をいくらでも拡大できる「もの」とは違う.))(同じく,「考える」ときにはできるだけ固有名詞を非除して考え,ある程度考えがまとまってから適切な固有名詞を探すことにしている.これをやらないならそれは演繹的に何かを導いているだけで「考えている」とはならない.まあやりすぎると単なるいいかげんや効率の悪さに帰するしそちらに寄りすぎている自覚はある.だが自分は「知りたい」のだ.「納得したい」ではなく.)(このような考え方を取るのはファインマンの影響.)(固有名詞から始める危険性のことを,知識の呪いやセンメルヴェイス反射,早まった一般化,自然主義の誤謬や合成の誤謬にハマりやすくなる、などと呼んでも良いけれど.)(認知科学では、「事物全体制約」「言語隠蔽効果」などの用語で表現するようだ。)(「創造性はどこからくるか(2019)」p80~83 言語化は創造性の敵か味方か.「言語として考えていることはアイディアを歪めてしまう危険をはらんでいる」「ただし言語化すること自体は自分の認知状態を振り返る上では有効だとされる事例も」~「長期間のアイディア探索をするような場合には,言語化に寄る時間をおいた思考の見直しがひらめきの契機を生むこともある」耳が痛い.)
*特許SDIにAIを用いるにあたり、AIに求められる「最も」重要といえる能力は、再現率もそうであるが、「教師データとして教えていない未知の特許・新しい特許のうち、少なくともヒトが必要と認識できるものをきちんと提供できるか」どうか。これはいわゆる汎化(意味不明なほど広いが)の問題でもあるし、創造性の問題でもある。これができず類似だけ観ている特許SDI用AIは、すべてアウト、というと言い過ぎか...すべてファウルだろう。
・言語処理学会NLP2019,とても面白かった.
・日本認知科学会JCSS2019,とても刺激的であった.
・情報論的学習理論ワークショップ IBIS2019,再認識することが多かった.
・日本知財学会2019,非常に興味深いものだった.
・言語処理学会NLP2020,具体的な示唆が得られた。交流の手段が限られたことは非常に残念だった。
・言語処理学会NLP2020,ルールとデータの融合、ヒト認知とのインタラクティブ融合に萌芽がみられたようで興味深かった。
*いつか誰かが「皆が欲しがるもの」を作ってくれる。これは達成されるだろう。しかし、いつか誰かが「自分の欲しいと思うもの」を作ってくれる、これは、多分達成されない。
きっと、多様性の時代には、自分の多様性を押し殺し二律背反を抱えて生きるか、無いなら自分で作り自由に生きるか、の2択を選ぶことになる。
後者のほうが、面白いのではないだろうか。
*20211003,502 bad gateway対策として,前,中,後へ分割
前 https://qiita.com/kzuzuo/items/4670b5ff7526319680f4
中 https://qiita.com/kzuzuo/items/237b9f5192464817aa40
後 https://qiita.com/kzuzuo/items/756470e6e17c54aa5e2e