0.概要
本記事では汎用言語表現モデルBERTを実際のタスクに応用させる中でその内部動作を可視化し、BERTの動作ロジックを解明しようと試みたものです。前回記事からの続編となります。
厳密性に欠く実験方法、主張など多々ございますが、BERTに関する議論のひとつの土台として読んでいただければと思います。
尚、文中に100Mコーパスなどの表記が出てきます。これはwikipediaの中から100Mbyte分のデータを抽出して8割をトレーニングに、2割をvalidationに使ってモデルを訓練したという意味です。
1.はじめに
本記事で検証する項目を整理します。
前回記事で、「BERTが転換点となってネットワーク(脳)のチューニングに重きが移るのではないか」という説を書きました。そこでBERTのより詳細な動作状況を解明すべく、今回は次のようなテーマを検証してみようと思います。
[テーマ]
汎用言語表現モデルBERTの動作メカニズムの解明
[検証項目]
テーマの検証に当たって、以下ふたつを観察します。
- BERTのAttentionの付け方の観察
- BERTによって生成される単語の内部状態の分布状況
2.検証背景
1.TransformerにおけるAttention
ここ最近、NLPの新スタンダードになってきているTransformerがあります。BERTの基本単位を構成するTransformerは言語タスクにおいて、人間の直感と近い注意の仕方をしていることが論文に記載されています。
Transformerで使われる自己注意の起源になったのが、Yoshua Bengio の研究グループが提案(Zhouhan Lin, last: Yoshua Bengio, 2017)した文章の埋め込みベクトルを求める手法です。

ポジネガ極性判定タスクを説かせると、極性をよく表す箇所にAttentionが当たっている様子が見えます。
ネットワークがタスクに応じて必要な情報に注意できることから、BERTの事前学習でも予測単語を推測するための文章全体からの周辺情報の活用と、隣接分予測のための文章の構造および大意を把握する情報に注意を向ける傾向があると思われます。
これが人間の直感的な注意の向け方と近しいものかどうかは気になるポイントです。
Transformer(Łukasz Kaiser et al.,2017)はSelf-Attentionを用いたEncoder-Decoderモデルです。TransformerのAttention状況を可視化すると、Attentionが構文や意味構造を理解していることがわかりました。
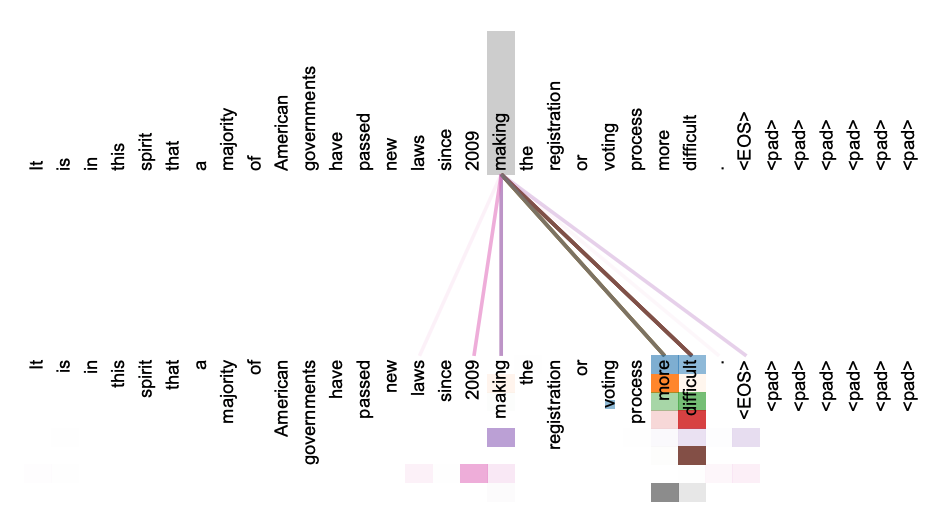
以下の画像はqueryがmakingだった場合のAttention状況を示しています。上がQueryで下がValueです。makingに対してmoreやdifficultなどに強いAttentionがあたっており、making ... more difficultという長距離で関係を持つ句関係を捉えていることがわかります。
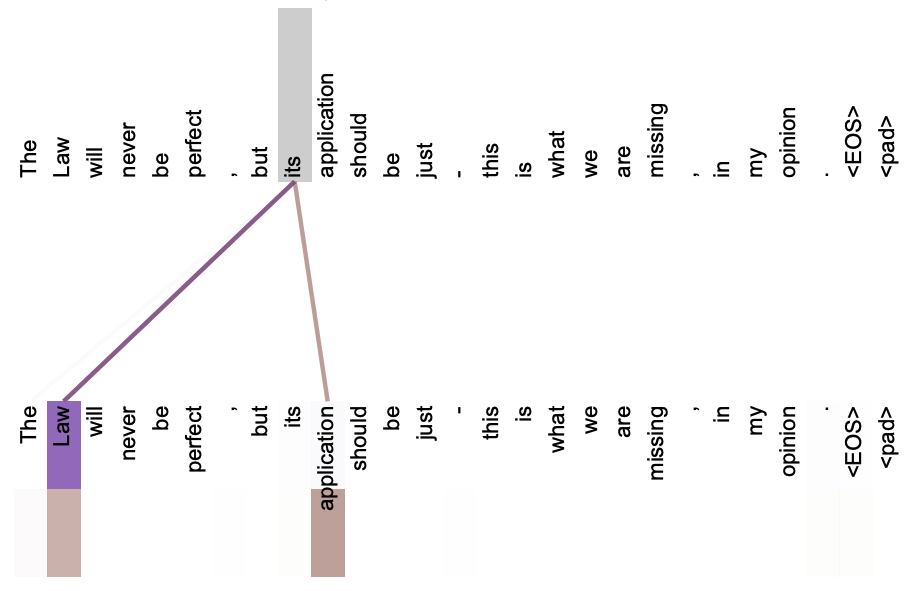
次の画像はqueryがitsだった場合のAttention状況です。LawとapplicationにAttentionがかかっており、its = Law = applicationという照応関係を捉えていることがわかります。
下の画像は、実験したBERTモデルにインプットするWikipediaテキストにBERTが付与したAttentionを可視化したものです。使用しているBERTモデルは100Mコーパスで学習し、隣接分予測の正解率を80%程度まで高めたものです。訓練の最中に問いていたタスクは隣接文予測とMASK(or Shuffle)単語予測です。文意が通じなくなっている文章は隣接文が別の文章に置き換えられたもので、緑色のマーカーで塗られている単語がモデルが予測すべき(MASK or Shuffle)単語です。

この図を見ていると、単語予測に必要な情報に注意が向けられている様子がなんとなく伺えますが、注意の向け方にどんな法則性があるのかが気になります。
そこで「ある単語は、その単語を説明するのに重要な別の単語郡によって定義されており、この重要性をBERTが学習的に決定しているのではないか」という視点でAttentionを眺めてみることにします。
2. BERTとWord2Vecの類似性
Word2Vec(Mikolov, 2013)は共起する単語を予測するタスクをNNに解かせて得られる内部状態行列を単語表現抽出機として活用するものです。
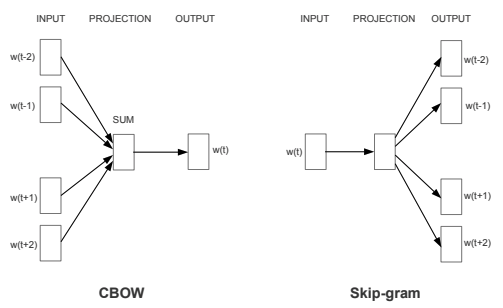
膨大なデータで教師なし学習をさせて、得られた内部状態を汎用的な単語表現抽出機としたところがBERTと似ていますね。特にCBOW(Countinuous Bag-of-Words)はインプット系列の周辺情報から間の単語を予測するタスクを解かせるので、BERTのMASK単語予測と近いタスク設定です。
Word2VecとBERTの差異として考えているのは以下三つのポイントです。
・Word2Vecは単語の内部状態を多次元空間の一点に収束させるため多義語の解釈ができない。一方でBERTは文脈によって単語の内部状態が異なるため多義語の場合、別々の語義は多次元空間上の別の場所に位置できる可能性がある。
・Word2Vecは固定長のウィンドウサイズの範囲でのみ共起性を考慮しているのに対して、Attentionは文章全体を考慮している
・Word2Vecではき出される単語内部状態は人間が理解できる表現ではないのに対して、Attentionは可視化することで人間が理解できる
これらの理由から、Attentionは文脈に基づいた観点から単語の表現を定義・獲得し、更にそれを人間が観察することができることに強みがあると考えています。
特に、同じ表層系を持つ単語の多義性を正しく認知できるとすると、word2vecよりも適切に文章を文章ベクトルに変換することができ、様々な応用が期待できます。
今回は、単語の内部状態をPCAで次元削減して可視化し、分布状況を観察してみることにします。
3.検証結果
検証項目1.BERTのAttentionの付け方
2500Mコーパスで隣接文予測精度89%程度まで学習させたBERT内部TransformerのAttentionを可視化しました。
今回使用したモデルには 8layer x 8head = 64headのAttention headがあります。そのすべてのheadの加算平均をとり、Attentionが強いほど濃い色でマークアップされるようにしてあります。
赤が通常の単語にかかるAttentionで、緑でマークアップされているものはBERTの事前学習のためにMASKされた単語を示しています。文章冒頭のUnshuffled / Isshuffledは隣接文がシャッフルされているかいないかを示しています。
以下の画像が結果です。

うーん、わからないです笑
翻訳や極性分析のときにみられたようなわかりやすい注意の傾向は見えません。
隣接文予測も同時に解いているので、そのためのAttentionの付け方も合わさって認識が難しくなっているのでしょうか・・・。
そこで、単語ごとのAttentionの強さと出現頻度の相関を調べてみることにしました。x軸がAttentionの強さ、y軸が出現頻度です。y軸は対数メモリにしてあります。overflowを防ぐために、log1pメソッド(データに1足してlogをとる)で対数化してあります。
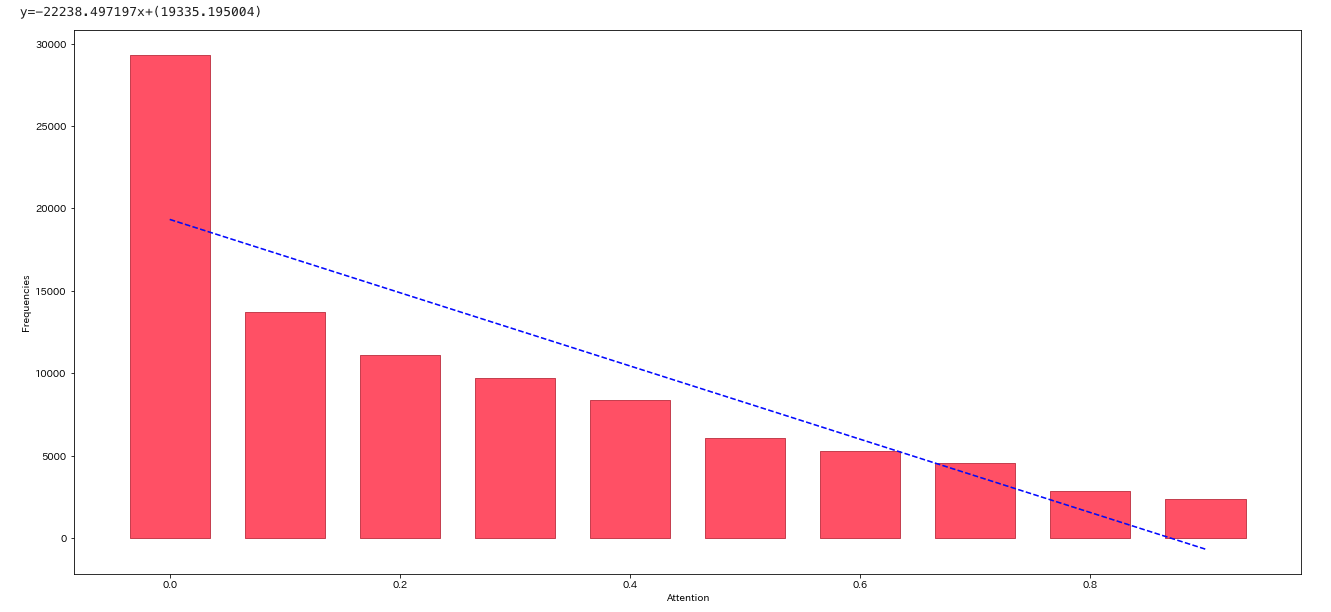
Attentionが強いものほど、単語の出現頻度が少なくなる傾向が見えます。
人間が文意を把握する場合、出現頻度が少ない(稀に見る)単語は偏ったトピックに出現している可能性が高く、文意を把握するにあたって重要な単語として注目するべきですし、出現頻度の高い(よく見る)単語は多様なトピックに普遍的に出現すると考えられるのであまり注意を置かなくても良いでしょう。この点で、BERTのAttentionの当て方の傾向は人間の直感に一致しているように感じます。
BERTの獲得する単語分散表現にますます期待が高まってきます。
検証項目2.BERTによって生成される単語の内部状態の分布状況
まず、カテゴリの異なる単語がどのようにマッピングされるかを観察してみます。
Word2Vecで同様の実験を行なっているこちらの記事を参考にしました
参考図書:「分類語彙表 増補改訂版」、国立国語研究所編、2004年
に記載してある、「1.4 生産物および用具」の単語集合から単語を選んでいます。
| 単語 | カテゴリ |
|---|---|
| マンション | 住居 |
| 寮 | 住居 |
| アパート | 住居 |
| 住宅 | 住居 |
| ワンピース | 衣料 |
| スーツ | 衣料 |
| 洋服 | 衣料 |
| 洋服 | 衣料 |
| 道路 | 土地利用 |
| 橋 | 土地利用 |
| ダム | 土地利用 |
| 港 | 土地利用 |
| 魚 | 食料 |
| 米 | 食料 |
| 牛肉 | 食料 |
| コーヒー | 食料 |
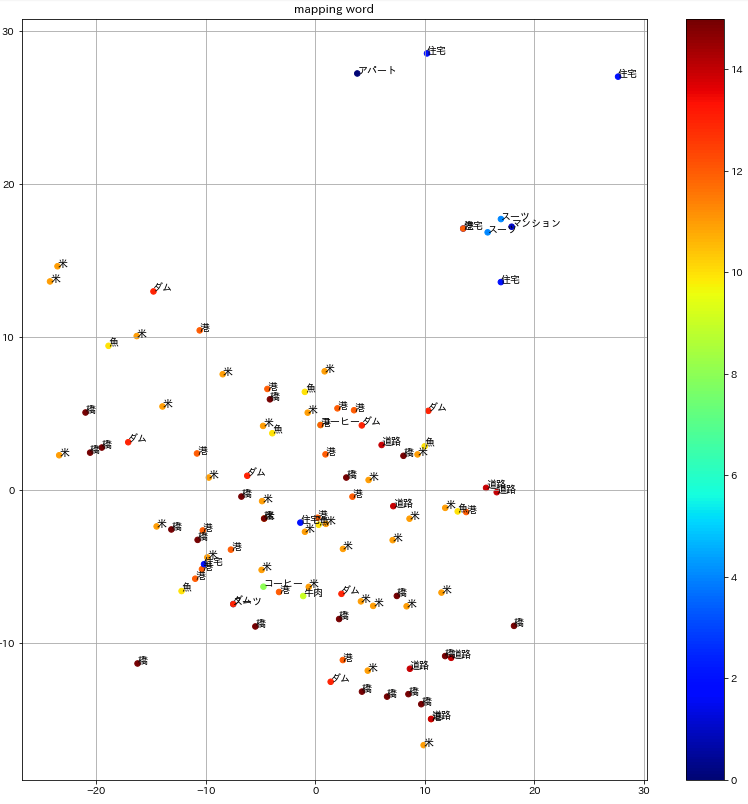
100Mコーパスで訓練したBERT
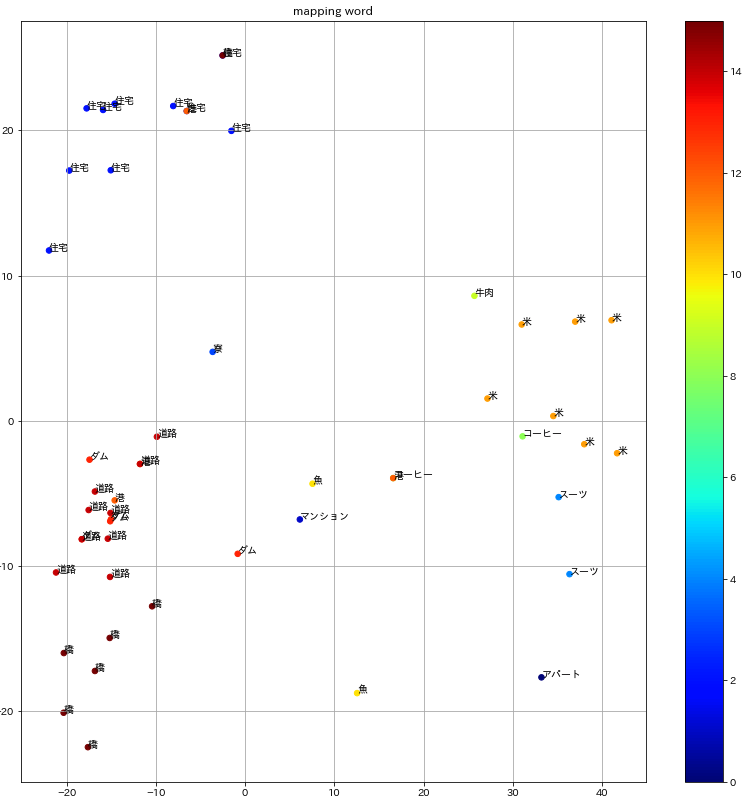
500Mコーパスで訓練したBERT
2500Mコーパスで訓練したBERT
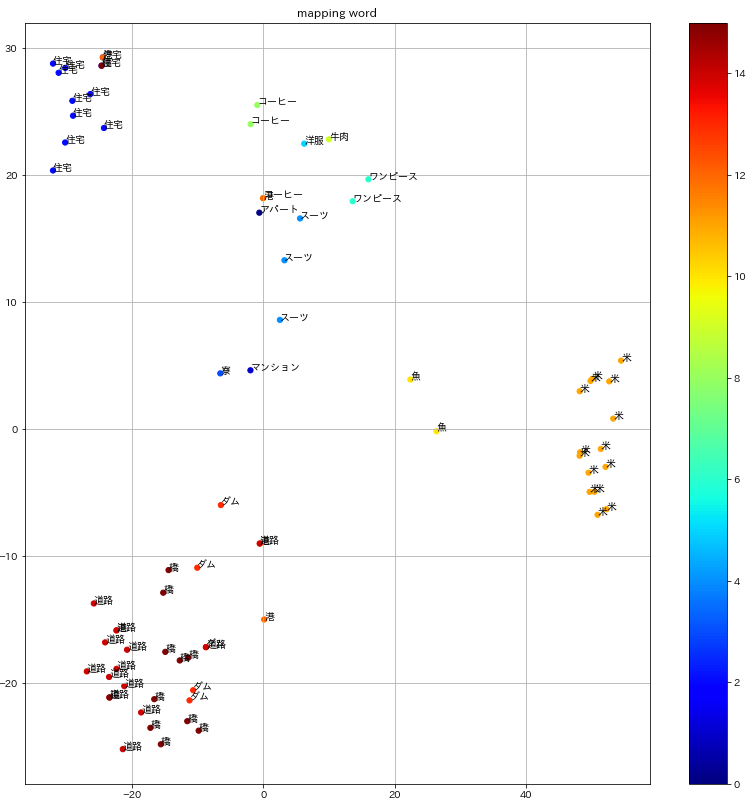
BERTの訓練に使うコーパスサイズが小さい時は単語が入り混じって分布していますが、コーパスサイズを上げていくにつれてクラスター分布がはっきりしていく様子がわかります。
同じ単語でも一点に収束せず、文章の数だけ違う点にマッピングされているのがBERTの特徴です。それでは多義語はどのようにマッピングされるかを観察してみます。
今回は「首」という単語をマッピングしてみることにします。
首には大きく三つの語義があります。
- 人体の一部の意の「首」
- 解雇、リストラの意の「首」
- 市長、知事などリーダーの意の「首」
「知事」「市長」「解雇」「退職」を検索単語として追加します。マッピング空間の位置関係を保つために、一個前の実験で使用した主要単語も一緒に空間に配置しておきます。
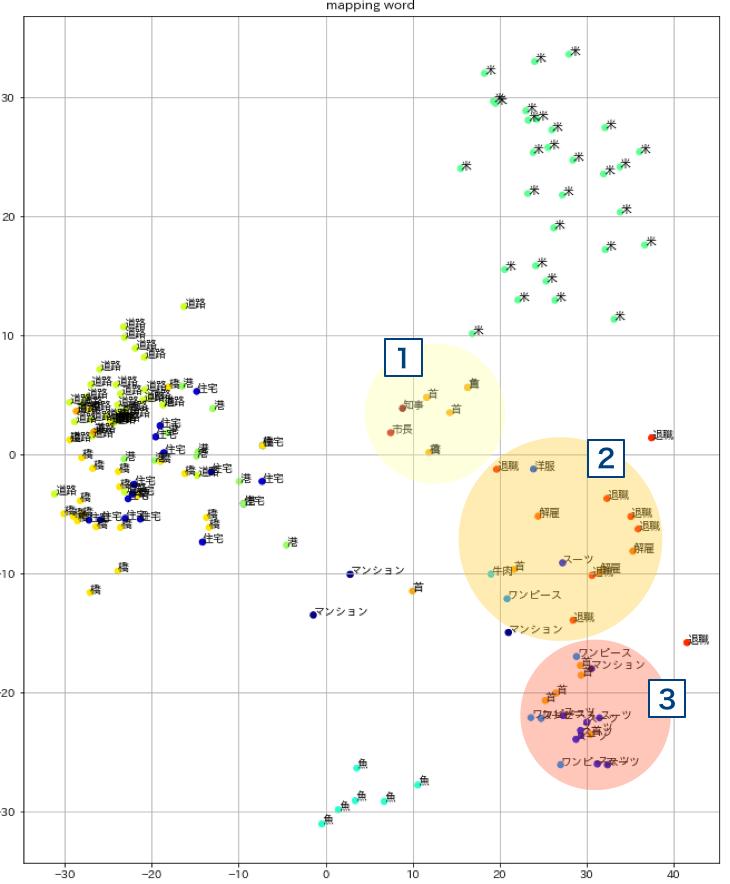
1.知事、市長の周りに集まっている「首」がリーダーの意と思われます。
2.退職、解雇などの近くにある「首」はリストラの意だと思われます。
3.ワンピース、スーツなどの近くにある「首」が人体の意だと思われます。
見方が若干恣意的すぎるかもしれませんが、首という多義語がそれぞれの意味空間にマッピングされている様子がうかがえます。
別の例もみてみましょう。
「右」や「左」には、方向の意と保守/革新の思想傾向を示す意があります。
検索単語に「右」「左」「右手」「左手」「保守」「革新」を付け加えた結果が以下です。
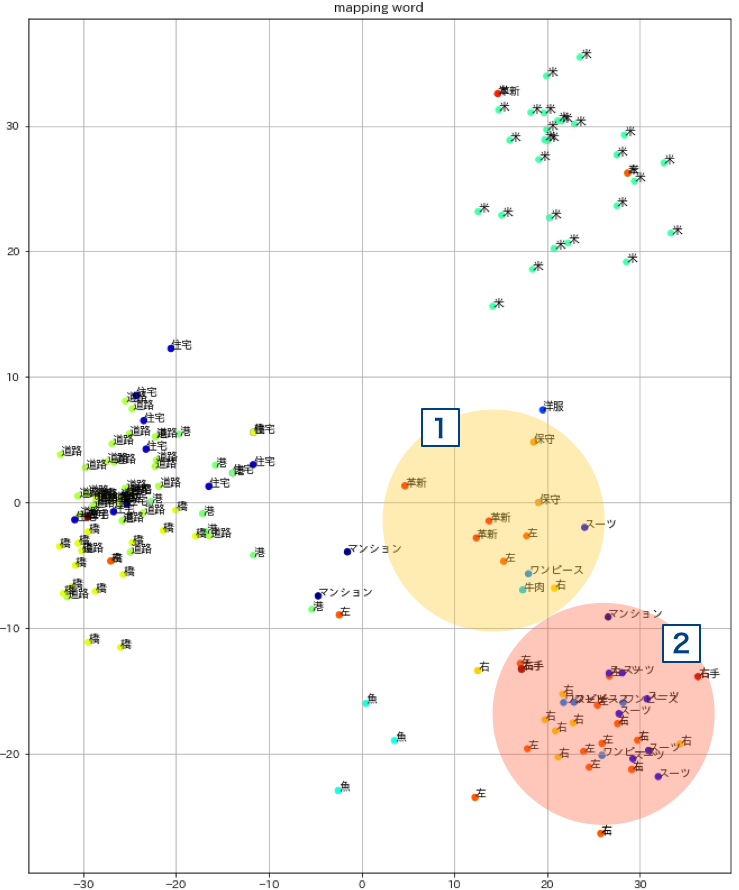
1.思想の意の側は保守や革新の付近に左と右という単語がマッピングされている様子が見えます。
2.方向の意ではスーツや右手、左手といった単語の付近に左と右がたくさん出現しています。
日常的な用法なので出現数が多いですね。
以上の結果から、BERTは文脈を考慮して単語をマッピングできるword2vecの進化版の位置付けと見ることができそうです。
4.考察
まず今回得られた結論について整理していきます。
今回は以下ふたつについて検証してきました。
- BERTのAttentionの付け方の観察
- BERTによって生成される単語の内部状態の分布状況
検証項目1について
文章のAttention状況を可視化しても、人間の直感にすんなりなじむような注意傾向は感じられませんでした(少なくとも自分は。)
この原因としては
- ニューラルネットワークが人間の認知回路とアナロジーを持たない独自の回路で認知をしているため理解できない
- 人間の潜在的な認知回路(視覚における一次視覚野のような)とはアナロジーを持つが、人間が意識的に理解する認知回路とは違うため理解できない
があると思われます。次に統計的なアプローチからAttentionの傾向を探ると、単語として出現頻度の少ないものほどAttentionが強くなる大域的な傾向が見えました。ある情報を説明する際に、固有性の強い周辺情報を使って説明する能力をBERTが持っていると見ることができるでしょう。
固有性の強い情報によって、語義を定義するのは国語辞典と同じアプローチです。従って、BERTは一般言語を表現するにあたって、より適切な形で表現する能力を持っていると推察できます。
そこで、「より適切な形」というのが一体なにであるのかを次の仮説で検証しました。
検証項目2
BERTは単語を多次元空間にマッピングすることができました。さらにマッピングされた単語郡は意味の近いもの同士が近くに集まり、クラスターを形成しています。ここまではWord2Vecと同じです。BERTは文脈によって語義を定義しているので、ある単語が登場した回数分だけ空間上に点がプロットされます。
Word2Vecでは同じ表層形を持つ単語は一点に収束してしまいました。これにより、多義語であっても多次元空間上では一点に収束してしまうという問題が発生します。BERTではこれを克服しており、多義語の場合は同じ表層形であっても別の意味同士の単語は別々の場所にマッピングされました。(方向としての「右」と、思想傾向としての「右」が違う場所にマッピングされた、などです。)
これより、BERTは単語の分散表現獲得において、より文脈に即した形で潜在意味表現を獲得していることが推察できます。従来のWord2Vecの弱点を克服した形であり、Word2Vecでは性能が足りなかった様々なタスクへの応用が期待できます。
BERTはなぜ汎用的なのか
さて、今回BERTの内部動作を探るにあたって、このモデルの高性能さの所以を垣間見てきました。個人的に重要な示唆だと感じたのは、多義語が多次元空間上の異なる場所にマッピングされたことです。より厳密には多義語だけではありません。辞書の用法上、同一とされる言葉でさえ空間上では異なる場所にマッピングされます。なぜなら、文脈によって単語それぞれが持つ意味というのは微妙に変容していくからです。当たり前のことに聞こえますが、NLPひいてはシンボルグラウンディング問題において非常に重要な示唆だと思います。
文脈に応じてニュアンスを解釈するというのは人間が無意識のうちにこなせることですが、そもそも人間はどのように言語を認知し、コミュニケーションしているのでしょうか。
私達が日常的に意思疎通を行う時、万人に受け入れられている「記号表現」(シニフィアン)を利用しています。人間は言語を前提とした記号表現を媒介としてコミュニケーションを行うことで、「イメージ」(シニフィエ)を想起して理解します。
コミュニケーションを意味情報のEncode-Decodeモデルとして解釈してみたのが以下の図です。
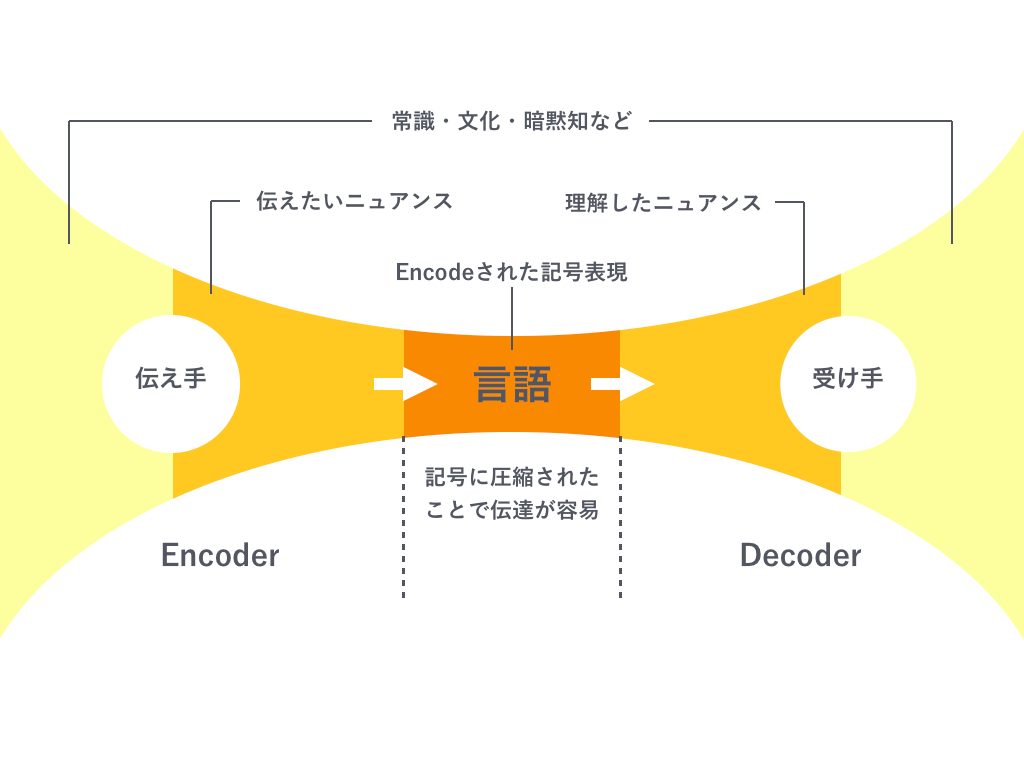
人間が何か情報を伝えようとするとき、それは伝え手が所属する時代・文化・常識などに立脚して伝えたいことのニュアンスを想起しているはずです。そしてニュアンスを記号表現にエンコードすることで、情報量を圧縮して伝達可能な表現に変換します。この記号表現はエンコードされた時点である程度情報を失っていますが、受け手側が伝えて側と同じ時代・文化・常識観に所属している場合はうまくデコードすることができます。記号表現に圧縮されて失われた情報を受け手側が補うことができるからです。
もちろん、海外旅行に行った時のように、言語という記号表現を共有しない人同士ではコミュニケーションは円滑に進みません。
さらには、今の20代と、今の80代の方々では「平和」という言葉をやりとりした時、解釈は異なるはずです。それぞれ人生で経験してきたこと、時代的、文化的な常識背景が異なっているからです。
しかしながら、私たち(例えば日本人)は日本語という普遍的な記号表現を用いて膨大な意味を共有し、会話をし、文章を書いています。記号に紐づく意味というのは常に変遷の途中にあるものであり、それらの意味は所属する時代や文化から規定されていくものである、というのがここでの考察です。
最後に、この考察に立脚してBERTの汎用性の所以と今後の展望の期待を書いて終わりたいと思います。
以下の図はWord2VecとBERTが学習で使う情報の違いを示す観念図です。
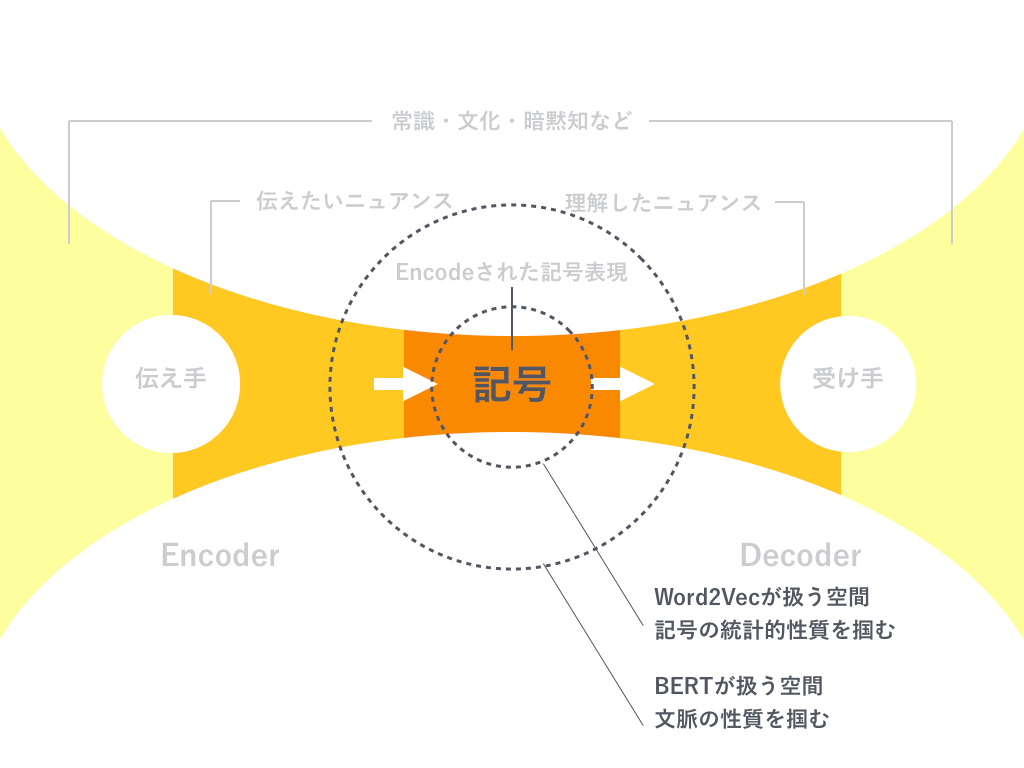
Word2Vecでは言語系列をwindowサイズで機械的に分割し、分割された範囲内での記号表現の統計的性質(共起性)を掴むことで、単語を多次元空間にマッピングし、単語ベクトルの足し算引き算が成立するような、記号表現同士の関係性をうまく捉えていました。しかし、これはあくまで記号空間に限定された性質でした。
対して、BERTが単語をマッピングする多次元空間は同じ単語であってもある程度の分散を持ったクラスターを形成します。Attention機構を重層的に組み合わせて事前学習タスクを工夫することで、文脈情報を考慮した学習を行なっていると考えられます。BERTで多義語の解釈が可能になっていることからも、上図のように、記号空間から一回り大きい表現空間から情報を掴んだことがBERTが汎用性を獲得した背景だと考えています。
そして本来、言葉という記号表現を形成するものは周辺文脈だけでなく、時代や文化、その場の環境情報など様々な非言語情報がファクターとなっているはずです。
今回の結果をうけて、より開けた系の中で情報を取得し咀嚼していくネットワークが、今後さらに人間らしい言語理解を獲得していくのではないかと思います。
プロジェクト紹介
本記事の内容は、株式会社サイシードのシンボルグラウンディングプロジェクトの一貫として進めています。
このプロジェクトは、コンピューターサイエンスだけでなく、言語学、心理学、脳科学などの多角的な切り口から、実世界と記号空間のシステマティックな接続を実現する野心的な試みです。
サイシードではシンボルグラウンディングプロジェクトに一緒に取り組んでくれる熱意ある仲間を募集しています!
参考資料
https://arxiv.org/pdf/1301.3781v3.pdf
https://arxiv.org/pdf/1706.03762.pdf
http://kenichinakatsu.blog.fc2.com/blog-entry-104.html
https://qiita.com/inuneko/items/93ae06f2314598a18eb2