今DL for NLP界で、BERTというモデルが話題です。PyTorchによる実装が公開されていたので、日本語Wikipediaコーパスに適用してみました。
コードはこちらに公開しております。
2018/11/27
作成したBERTのモデルを使って内部動作の観察とその考察を行いました。単語の潜在表現獲得の部分で感動的な結果を見せてくれました。ご興味あればご覧ください↓
https://qiita.com/Kosuke-Szk/items/d49e2127bf95a1a8e19f
この記事ではBERTのポイントの解説と、ポイントごとの実装を紹介します。
尚、記事の執筆にあたってこちらのリポジトリを参考にさせていただきました。
https://github.com/codertimo/BERT-pytorch
本記事は以下の4つで構成されています。
・BERTとは
・BERTのキモ
・BERTの弱点
・実装
・考察
BERTとは
 ## 概要
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[[論文](https://arxiv.org/abs/1810.04805)]
著者:Jacob Devlin, Ming-Wei Chang, Kenton Lee,
Kristina Toutanova(Google AI Language)
## 概要
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[[論文](https://arxiv.org/abs/1810.04805)]
著者:Jacob Devlin, Ming-Wei Chang, Kenton Lee,
Kristina Toutanova(Google AI Language)
2018年10月11日にGoogleからArxiv公開された論文です。双方向Transformerで言語モデルを事前学習することで汎用性を獲得し、転移学習させると8個のベンチマークタスクでSOTAを達成したそうです。
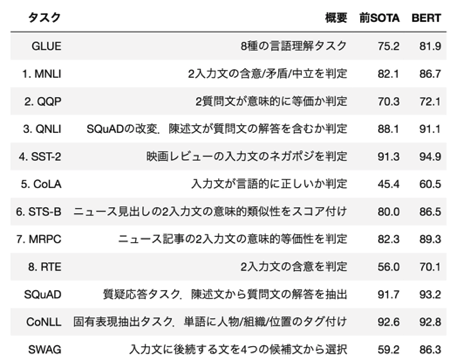
(引用元: https://twitter.com/_Ryobot/status/1050925881894400000)
ComputerVisionではImageNetで事前学習したVGGやResNetがありますが、今回BERTによって言語でそのようなポジションのモデルが作られました。
事前学習(Pre-Training)
BERTがここまでさわがれている理由のひとつに、BERTが自然言語処理における汎用的な事前学習モデルであることがあります。
そもそも、何かのデータを統計的に処理したい時に、画像処理の場合はピクセル、音声処理の場合は音声信号といったように基本入力が決まっているのに対し、自然言語では処理対象とするテキストをどのように表現すべきか決まった方法がなく、タスクに応じて決定されます。例えば、情報抽出の場合はテキストを単語の集合(Bag of words)として扱うのが主流で、機械翻訳のようなより高度なタスクでは品詞解析、係り受け解析などより複雑な表現方法が用いられることがあります。統計的自然言語処理では、テキストをどのような特徴量を使って表現するかの選択が重要です。
自然言語処理では単語の組合せ(n-gram)を古くから特徴量として用いてきましたが、組合せの種類が膨大になり、十分な訓練サンプルが確保できなくなるなどの問題がありました。
「表現学習」はこれらの有効な特徴の組み合わせを自動的に学習させる手法です。深層学習では層を深く重ねることで単純な特徴量の組み合わせからより複雑な特徴の表現を獲得できます。
大規模なデータを元に表現学習を行うと、汎用的な特徴量抽出器となることが期待されます。様々なタスクへの応用を前提としたこの表現学習を事前学習(Pre-Training)と呼びます。
単語の出現は前後の文脈に依存して決まるので、単語や文章同士の一般的な依存関係が事前に与えられていれば、あるタスクを解くために必要な特徴が入力に出現していない場合でもそれを補うことができます。特に、特徴の出現がスパース(疎)な自然言語の場合は、事前学習は重要な役割を持つイメージが付きやすいと思います。
そして、事後学習(Post-Training)では事前学習で得られた有効な特徴の組合せを使って目的とするタスクを学習します。
BERTは、大規模コーパスから事前学習させたモデルに対して、タスクごとに事後学習を行わせた結果、あちらもこちらも最高得点(State of the Art)を叩き出したので、あらゆるタスクはこのBERTを土台にして取り組めるのではという機運が高まっているわけですね。
以上が、BERTが汎用的な言語モデルとして注目を集める所以です。

BERTを作るモチベーション
上記の背景から、様々な自然言語処理タスクにおいて事前学習が有効なことが示されています。
・文レベルのタスク→文同士の関係性を学ぶ
・トークンレベル→トークン同士の関係性を学ぶ
事前学習のアプローチには大きく二種類あります。
Feature basedアプローチ
N-gramモデルやWord2Vecなどがこれに当たります。独自の分散表現で、様々なNLPタスクの素性として活用されます。
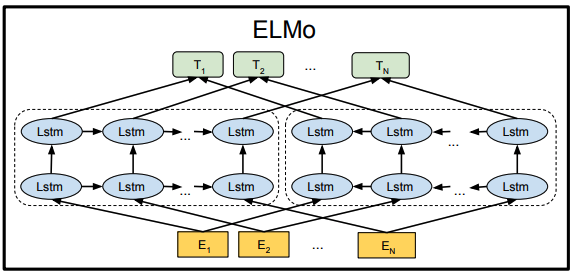
最近ではELMo[Peters et al., 2017, 2018]が有名です。獲得した素性をNLPタスクの入力層及び隠れ層に連結するだけで、性能の向上が図れるというものです。
Fine tuningアプローチ
言語モデル(次の単語を予測するモデル)を生成する形で事前学習を行います。その後に教師ありタスクでFineTuningすることでタスクにフィットさせるアプローチです。
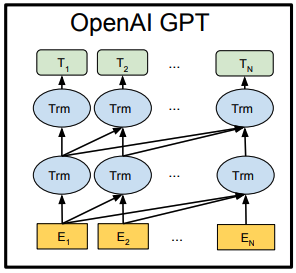
最近ではOpenAI GPT[Radford et al. 2018]が有名です。
もっと良い事前学習モデルが欲しい!
BERTは従来の事前学習の有効性を踏襲しつつ、弱点を克服する形でより汎用性の高い事前学習モデルを学習できたところが革新的です。
BERTのモデル
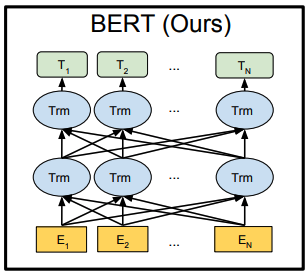
BERTは双方向Transformerです。
です。と言われてもよくわからないので、そもそもTransformerとは何で、従来と何が違うのかから探ってみましょう。
Transformerとは
Transformer( 論文 )は、Attentionのみを使用したニューラル翻訳モデルで、わずかな訓練でSOTAを達成しました。Attention機構は、加法注意・内積注意・ソースターゲット注意・自己注意に分類されます。この中でも、自己注意(Self-Attention)は汎用的かつ強力であり、言語処理のあらゆるタスクにおいて高い性能を発揮します。
Transformerに関してはこちらのブログがとても参考になります。
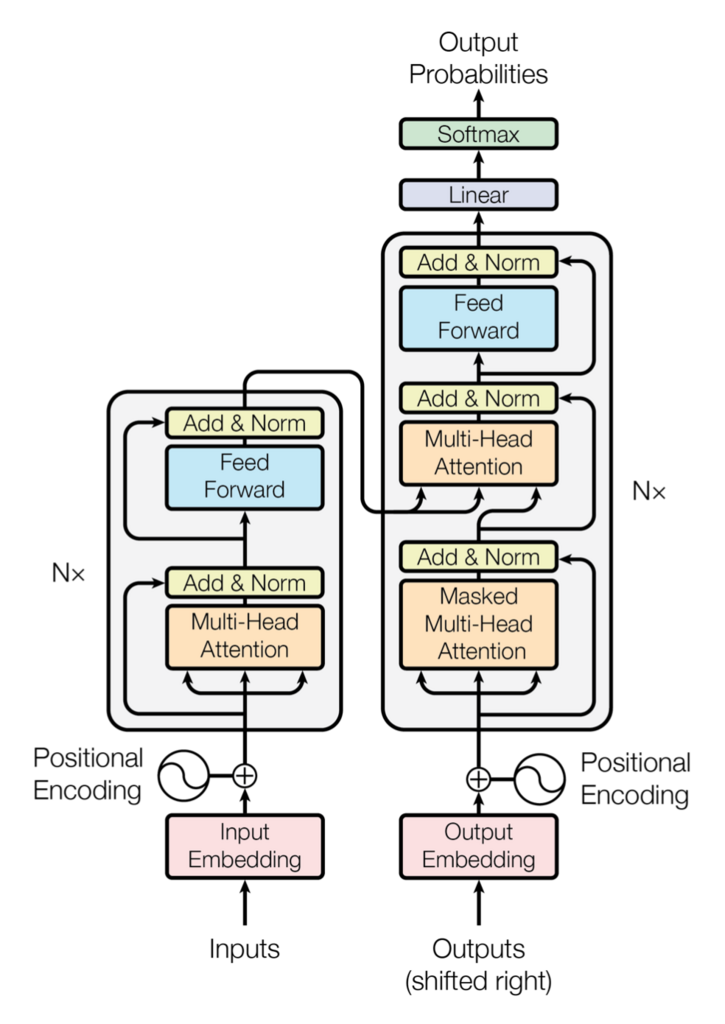
BERTではこのTransformerのEncoder部分をユニットとして活用しています。
ユニットの中身を拡大するとこのようになっています。Q:Query, K:Key, V:Valueにそれぞれ対応しています。Q,K,V3つのテンソルを放り込むとよしなに動いてくれるのがSelf-Attentionです。詳しく見てみましょう。
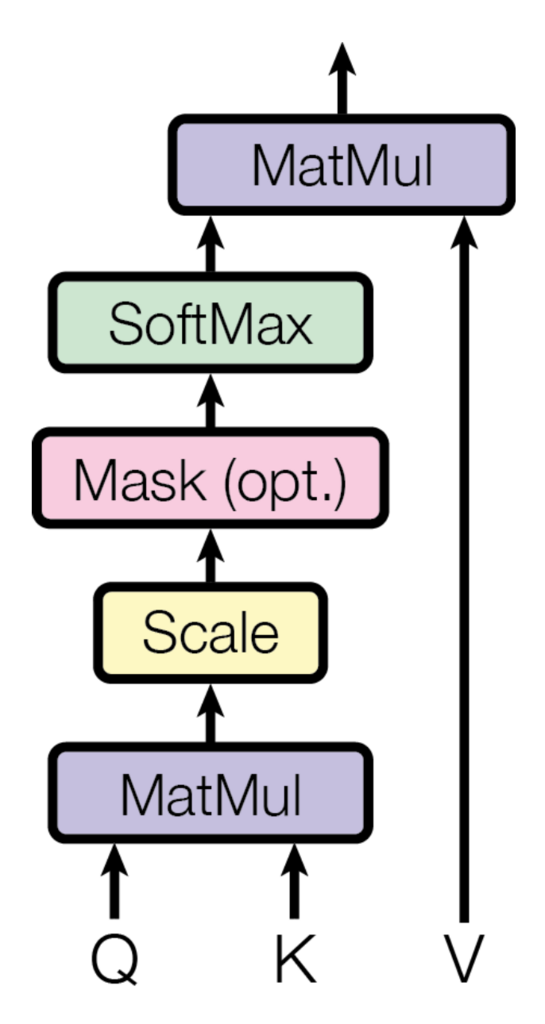
そもそもAttentionとは
Attentionにおいて、Query, Key, Valueと名前がついているのにはわけがあります。Attentionでは、Query(検索クエリ)に一致するKeyを索引し、対応するValueを取り出す操作と見ることができます。Encoder-DecoderモデルにおけるAttentionでは、隠れ層のの内部状態をValueとして、Queryに関するvalueのみをAttentionの重みの加重和として取り出します。必要な情報にだけ"注意"しているわけです。
Self Attentionとは
Attentionは、Key-Valueがどこをソースとするかで二種類に分類されます。
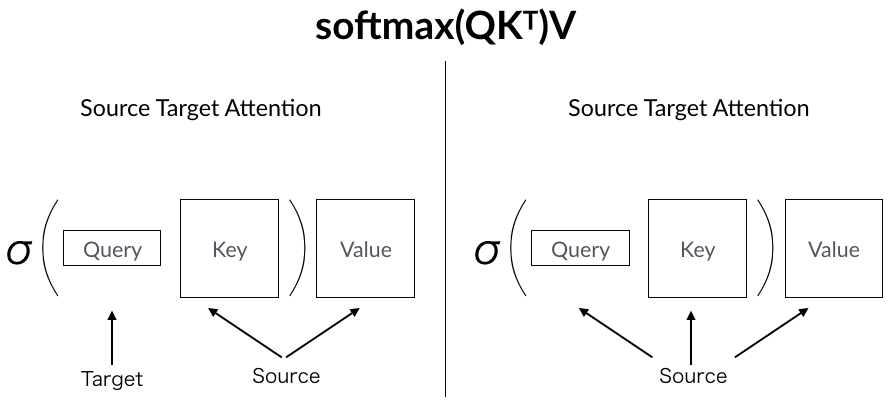
Source-Target-Attention
KeyとValueはEncoderの隠れ層から、QueryはDecoderの隠れ層からきます。Decoderの要請に応じて注意を払う場所を決めるのがこちらのAttentionです。
Self-Attention
一方で、Query、Key、Valueが全て同じ場所からくるのが自己注意です。下の層からの同じ入力がQ,K,VとしてAttentionに流されます。

Self-Attentionは、下の層全ての情報の全てを参照してある位置の出力を自己定義することができます。
下の層の全てから、どの情報に注意して(重みを付加して)自己の出力を定義するかを学習的に決定できるのが、局所的な情報から出力を決定するCNNとの差異です。
Multi-Head-Attention
Multi-Head-AttentionはSelf-Attentionを並列に複数並べたものになります。
Scaled Dot-Product AttentionがSelf-Attentionのことで、この出力をConcatして上の全結合層に流します。
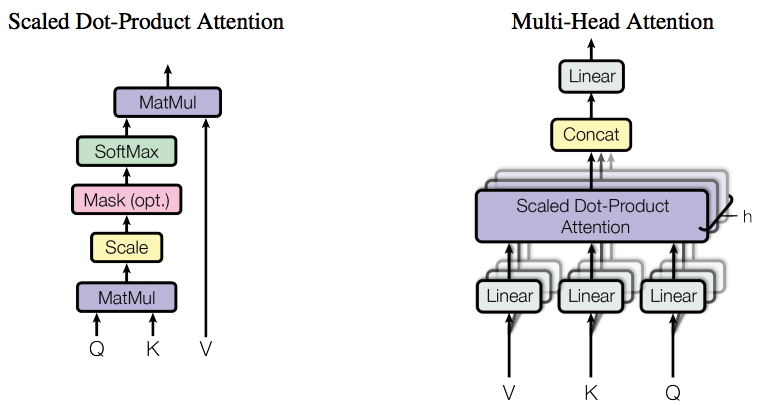
このMulti-Head-Attentionをひとつのユニット(BERTモデル図中のTrm)として、全結合的に接続したものがBERTモデルです。
従来との違いは?
事前学習を行う際、言語モデルを学習させることが一般的です。しかし、言語モデル(次の単語を予測するモデル)を事前学習に用いる場合、現在の予測プロセスの際に、予測するべき未来の単語情報を用いてはいけません。(カンニングになってしまうからです)
OpenAI GPT
OpenAI Transformerは未来の単語位置のネットワークにマスクをかけねばならず、単方向Transformerになります。
ELMo
ELMoでは順方向LSTMと逆方向LSTMを同時に学習することができません。
しかし、left-to-rightモデル(OpenAI GPT)や双方向の連結モデル(ELMo)より、更に強力な双方向モデル(BERT)を利用したいところです。
そこでBERTでは、次の単語を予測するのではなく、ランダムにマスクされた単語を周辺情報から予測することを事前学習タスクとしました。
従来、モデルの中に暗黙的に組み込まれていたマスクを、学習データのほうで直にマスク(または別単語に置換)したことで代替したのです。
これによって双方向Transformerを使うことができるようになりました。
BERTのキモ
事前学習のタスク選択
事前学習① マスク単語の予測
系列の15%を[MASK]トークンに置き換えて予測します。
そのうち、80%がマスク、10%がランダムな単語、10%を置き換えない方針で変換します。
<モチベーション>
片方向しか情報が伝播しないネットワークよりも、両方向に情報が伝播したほうが強力に学習できそうです。
しかしながら、双方向モデルは、一般的な条件付き言語モデルでは学習できません。
一般的な条件付き言語モデルというのは、
p(x_n|x_1, x_2, ... , x_{n-1})
のように、n-1番目までの情報からn番目の単語を予測するタスクです。前述したように、このタスクを解くときは現在の予測プロセスの際に、予測するべき未来の単語情報を用いないようにする制約が必要です。したがって、モデル自身は前後の文脈を考慮できず、前の文脈情報のみで次を推測しなければいけませんでした。
そこで、モデル側ではなく入力データ側を穴埋め問題形式的に制約をかけることにしました。

MASKされた単語を予測するタスクにおきかえることで、前後の文脈を考慮するモデル(双方向)で学習させることができるようになりました。
事前学習② 隣接文の予測
二つの文章を与え、隣り合っているかをYes/Noで判定します。
文章AとBが与えられた時に、50%の確率で別の文章Bに置き換えます。
<モチベーション>
QAや自然言語推論では2つの文章の関係性を理解できることが重要です。
しかし、文章同士の関係性は単語の共起性から単語の発生確率をモデリングしている言語モデルのみではとらえきれない特徴量を含んでいると考えられます。
隣接文予測を解かせることで、文章の単位での意味表現を獲得できます。
word2vecが単語表現モデルであったのに対し、BERTはより広範的な言語表現モデルとして機能できる理由のひとつです。
BERTの弱点
BERTは学習に時間がかかります。これは学習の際に予測するべき単語が学習データの中で15%しか存在しないためです。
一方で、従来の言語モデルでは毎単語を予測対象としていたので、学習のペースに大きな差があります。
ちなみにGoogleはBaseとLargeという二種類のモデルを用意しています。後者のLargeはGoogleの本気モードです。お高くつきます。
Baseの学習:4TPUS(16TPUチップ) x 4日
Largeの学習:16TPUS(64TPUチップ) x 4日
同様の学習をGPUで行うと40~70日かかるとか・・・
実装
今回は日本語版BERT実装するにあたって新規性のある部分だけピックアップして解説しようと思います。
コードはこちらにjupyter notebook形式で公開してありますのでご参照ください。
jupyter notebookに全部載せているので構造がわかりにくくなっていますが、BERTの全体構成は以下のようになっています。
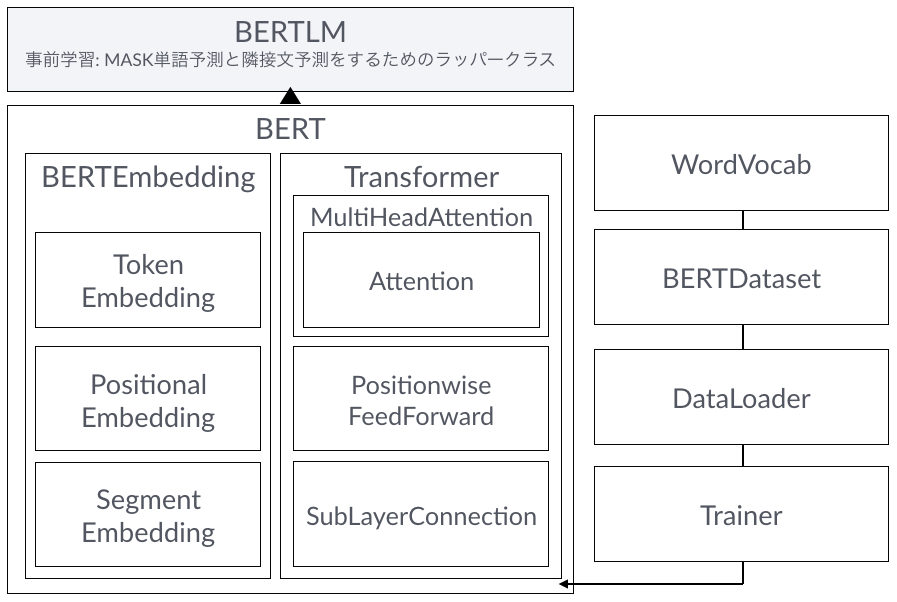
データセットの準備
日本語Wikiからコーパスを作成します。今回は100Mbyte程度のコーパスを作成します。
基本的に text_preprocess.ipynb のコードを上から実行しけばデータセットが完成します。
コーパス作成の流れ
- コーパスを作るもとになるWikipediaの日本語ダンプデータをダウンロードします
- Wikiextractorで不要なマークアップを取り除きます
- htmlタグ削除、空白・改行削除、大文字小文字変換などの前処理を施します
- 単語単位で文章を分割します
- 使いたいデータ量分だけ切り出す
- Wikipediaの一項目の文書が、偶数個の文章から成るようにする(BERTのNext Sentence Predictionのため)
事前学習
隣接文予測
どちらもBERTからはきだされた内部状態テンソルをInputとして一層のMLPでクラス分類しているだけです。シンプルですね。
これとほぼ同じようにFine Tuningの際の追加層もくっつけられるってことなんですね。蛇口の出口にアダプター取り付けるだけであらゆるタスクに対応できる便利さ・・・。
class NextSentencePrediction(nn.Module):
"""
2クラス分類問題 : is_next, is_not_next
"""
def __init__(self, hidden):
"""
:param hidden: BERT model output size
"""
super().__init__()
self.linear = nn.Linear(hidden, 2)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, x):
return self.softmax(self.linear(x[:, 0]))
マスク単語予測
class MaskedLanguageModel(nn.Module):
"""
入力系列のMASKトークンから元の単語を予測する
nクラス分類問題, nクラス : vocab_size
"""
def __init__(self, hidden, vocab_size):
"""
:param hidden: output size of BERT model
:param vocab_size: total vocab size
"""
super().__init__()
self.linear = nn.Linear(hidden, vocab_size)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, x):
return self.softmax(self.linear(x))
実際にやってみると
Googleが実際にやった規模で動かすのはコスト高なので、実験的に100M程度のデータセットで事前学習をさせてみました。
経験則ですが、データセットが小さい場合は、モデルサイズも小さくしないとうまく動かないようです。(Lossが減少しても、Next Sentence PredictionのAccが向上しません。)
実はこのトピックは、BERT-pytorchのgithubリポジトリのIssueで最も盛り上がっているものの一つです。データサイズやハイパーパラメーター設定によってAccの向上スピードが全く異なってきます。手元の実験の際には、adam_weight_decayを0、dropoutを0にしてトレーニングデータにフィットしやすい状態にしました。
参考までに、こちらでAccが向上したときのハイパーパラメータは以下の通りです。
hidden = 256 # originally 768
layers = 8 # originally 12
attn_heads = 8 # originally 12
seq_len = 60
batch_size = 64
epochs = 10
num_workers = 5
with_cuda=True
log_freq = 20
corpus_lines = None
lr = 1e-3
adam_weight_decay = 0.00 # originally 0.01
adam_beta1 = 0.9
adam_beta2 = 0.999
dropout = 0.0 # originally 0.1
min_freq = 7 # これでvocabサイズを50,000程度に抑えた
まとめ
日本語コーパスでBERT Pre-Trainedモデルを作成する方法を解説しました。
とにかく時間がかかります。GPUを使ってもなかなかAccuracyが向上しません。
どの程度の学習状況で、事前学習モデルとして性能を発揮するかは、実際に動かしてみるまで未知数ですね。
(この記事を書いている間にGoogleからPre-Trainedモデルが公開されました。リンク)
ということで、次回以降はBERTモデルを実際の言語タスクに適用するFine Tuning以降を実装していこうと思います。
考察
BERTは深層自然言語処理のひとつの大きな転換点になるのでは、と思っています。ポイントは
**「今後はネットワーク(脳)のチューニングから、学習タスク(教育)のチューニングに重きが移りそう」**ということです。
画像領域での深層学習の快進撃には目をみはるものがあり、もはや人間にできないことまでやり遂げています。一方で言語領域では根本的なブレイクスルーがなかなか起こらず、機械翻訳の発展などがありつつも、全体的にはいまひとつというラインで留まっていました。
CNNを筆頭とする画像分野での深層学習の革新の背景には、アルゴリズムを自然画像に適用すると、エッジまたは特定の色のエッジを検出する特徴量を人間のように学習することだったのではないかと考えています。下の画像のような特徴検出は、人間の一次視覚野に存在することが知られているガボール関数を想起させるものです。だからこそ、VGGやResNetのような大規模データで事前学習を行った画像モデルは、一般的な特徴量抽出器として性能を発揮するのでしょう。

一方で、自然言語処理では上のように人間らしい認知回路はなかなか出てきていないように思います。それは言語というものが、離散的情報であり、シンボルを基軸とした論理や構造を含む情報だからなのかもしれません。結果的に、統計的言語処理を用いて言語タスクを解く際にはタスクに特化させてネットワークを組み、タスクに特化させて特徴量をヒューリスティックに設計するアプローチが取られてきました。いわば、タスクに合わせて脳のネットワーク構造を改造するアプローチを取ってきたわけです。
深層自然言語処理以前の言語処理は、形態素解析、構文解析、意味解析、文脈解析など、人為的に言語論理を組み込んだフレームワークで処理を行ってきました。それが、深層学習によるEnd-to-Endの統計的言語処理により、単純なタスク解決においてはより効率的に解を示しました。しかし、タスクを変えてしまうと全く性能を発揮しなくなるフレーム問題は乗り越えられずにいました。
ここがBERTが転換点になると思っているポイントです。BERTはマスク単語予測と、隣接文予測というふたつのタスクを事前学習することにより、従来のタスク特化型のモデルに負けず、諸々のベースラインタスクで圧倒的な性能を示しました。憶測の域を出ませんが、より人間に近い形で、重層的な言語認知(注意)をしているのではないかと考えています。その中には構文解析的な認知状態や、まだ人間が定義できていない新しい認知状態も含まれるかもしれません。
以上が、今後は脳(ネットワーク)にどんな教育(事前学習タスク)を施すかの方法論に重きが移っていくのではないかと考えている理由です。
End-to-Endで自動的に汎用的な特徴量を抽出する表現学習を行えるとすると、過去に画像機械認識で起こった認知革命が言語にも起こるかもしれない!楽しみですね。
参考
・BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
・Attention is all you need
・論文解説 Attention Is All You Need (Transformer)
・BERT-pytorch
・日本語版text8コーパスを作って分散表現を学習する
プロジェクト紹介
本記事の内容は、株式会社サイシードのシンボルグラウンディングプロジェクトの一貫として進めています。
このプロジェクトは、コンピューターサイエンスだけでなく、言語学、心理学、脳科学などの多角的な切り口から、実世界と記号空間のシステマティックな接続を実現する野心的な試みです。
サイシードではシンボルグラウンディングプロジェクトに一緒に取り組んでくれる熱意ある仲間を募集しています!