きっかけ
・汎用の文章校正ツールではなく、「特定のスタイル・文体を考慮した文章校正ツール」が欲しかった。(薬事申請書類用の校正ツール、特許明細チェック用の校正ツール、契約用の校正ツール、判例言い回しを適用するための校正ツール、特定の著者のスタイルを真似るための校正ツール、など。)
・自作AIでみられたモデルの個性の理解をすすめるにあたり、共起や決定木では確認できない、またshapley valueほど重くない、「文章のどの位置がその個性に特徴的であるといえるのか確かめるための単純かつ理解可能なモデル」が欲しかった。また、個性に基づいた文章生成を行い、モデルの個性を比較したかった。
・文章のスタイル変換を、理解可能な泥臭い方法で行ってみたかった。
・深層学習ではない、スモールデータで必要十分に予測する理解可能な手段が欲しかった。
・文体とは何か理解したかった(どのような鋳型があるか理解したかった。現時点では、文体を学習させたり評価関数に落とし込んだり鋳型として利用するにしても、あまりにも何もわからなすぎる。理解を捨てて蒸留に走るのはどうもモヤモヤして。)
マルコフ性を仮定したn-gramの確率モデルを改変すればどうかな、ということで組み上げ。
*メモ書きのまま放置しています。transformerと照らし合わせ検討したのち、8割方消す予定です。
参考
・本コードは、DLAIのコードを基にしており、その許可のもとに作成・開示しています。(自由にして構わんよただし元がわかるように記載しちゃだめよまたDLAIが大本だとだけ書いてね(意訳)とのこと。)
*誤り訂正なら、mbartやmt5などの言語モデルでできるって?。いやその通りなのですが、スタイル・文体ごとに数十時間もfine-tuningしたくないので・・・また、moduleのupdateごとに修正し直すのは懲り懲りなんですよ。
→mt5の誤り訂正モデル例(後述)
*Style Transformer: Unpaired Text Style Transfer without Disentangled Latent Representation
https://arxiv.org/abs/1905.05621
を読み思うところがあったところ。
文体構造?を完全に除去できずスタイル変換が難しいといえるのであれば、スタイルを後から任意に足してやる手法も良いのではないかな。(少なくとも微視的な)スタイルは長距離依存性との相関はない?だろうから独立させても問題ないだろう。また個人的には、記憶ネットワーク以外の解決方法もありそれらにも特有の強みがあると思うのだよね。適切な演繹が見つかるならば、演繹的に置き換えて帰納的にチェックするのもよいのではないかな?。すでに様々ありますが。
https://www.connectedpapers.com/main/ae60d15ec4f6c3839df2db19154ee5971a1e9640/Style-Transformer-Unpaired-Text-Style-Transfer-without-Disentangled-Latent-Representation/graph
*私のブックマーク「自然言語処理による文法誤り訂正 (Grammatical Error Correction based on NLP)」
https://www.ai-gakkai.or.jp/resource/my-bookmark/my-bookmark_vol33-no6/
「一般に誤りに見えても」その著者のスタイル・文体と言えるのであれば検出する必要はないし、「一般に正しく見えても」その著者のスタイル・文体と異なるのであれば検出したい。
自分は、文法的に完璧である真値らしき文章には興味はなく、個性的な文章に興味がある。
*京大日本語Wikipedia入力誤りデータセット (v2)
http://nlp.ist.i.kyoto-u.ac.jp/?%E6%97%A5%E6%9C%AC%E8%AA%9EWikipedia%E5%85%A5%E5%8A%9B%E8%AA%A4%E3%82%8A%E3%83%87%E3%83%BC%E3%82%BF%E3%82%BB%E3%83%83%E3%83%88
約70万文ペア
ありがたし。しかしgoogle/mt5-baseにおいて500文ペアのpre-trainingに2時間かかる自前のnon-CUDA(GPUメモリ不足)環境ではとても活用しきれないうむう。
*東北大学wikipedia事前学習BERTを用いた文章生成もどき(MASK部分の予測)を試行。
fine-tuningしない条件ではこんな感じ。最終的には比較してみたい。
['[CLS]', '吾', '##輩', 'は', '[MASK]', 'で', 'ある', '。', '名前', 'は', 'まだ', '無い', '。', '[SEP]']


['[CLS]', 'その', '規', '[MASK]', 'は', '顧客', 'の', 'ニーズ', 'に', '適合', 'し', 'ない', '[SEP]']

MASK予測よりもQAのほうが面白そうですね。
夏目漱石の小説をディープラーニングに読ませていろいろ質問してみた
https://note.com/tokyoyoshida/n/n55dc1f5cf622
「吾輩は誰?
['下女', '主人', '寒月君']」
猫=主人という深い回答
*個人的には、transformerのような記憶ネットワークモデル?には、融通の利かない頑固さを感じる(BERTを実用に22ヶ月使ってきての印象なのでtransformerというのは広げすぎているかも)。品詞の順番を学習した文法構造に強制してくる感じ?。精度が高ければどのような課題においてもより良いとは限らないというか経験のみから学べば間違えやすくなるというか傾向と公理は異なるというかポスト構造主義的な視点においてというか・・・ こちらを見る限りどうにかなりそうだが。
BERTs of a feather do not generalize together: Large variability in generalization across models with similar test set performance
https://arxiv.org/abs/1911.02969
(自分が感じているこれら違和感は、多様性、Diversityの問題として議論されているようだ?。
Diversity(多様性)のある推薦システムとは何か
https://www.wantedly.com/companies/wantedly/post_articles/306930 )
*n-gramモデルは巷にあふれているといえますが、最適なものが10分探して見つからないならば調査を続けるより作ったほうが早い、という方針でやっております。
*sklearn CountVectorizerのngram_rangeは使っておりません。手を入れにくいから。
#コード概要
0 準備
・学習用の文章ファイルを特定のフォルダに放り込み(生の文章でOK)
・テスト用文章を入力
1 前処理
2 OOV等処理
3 n-gramを用いた複数の確率モデル(マトリックス)作成
・双方向とした
4 モデル実行
付与対象テキストに対し双方向にモデルを適用し、テキスト内の各単語がモデルにより推測されたかどうか確認
モデル学習外の単語が検出された場合、その単語の後に●を付与
5 出力
●が付与されたテスト用文章を出力
コード
・足切り検討、スタイル特化の修正、コードの体裁修正、DLAI要求への対応、その他修正中・・・
・少々長くなってしまったため、どこに置くか検討中・・・
*テスト用に青空文庫の特定著者著作抽出コードを作成している。よく忘れるのでメモ。
1 aozorabunko_textより全ファイルダウンロード、解凍
https://github.com/aozorahack/aozorabunko_text
2 下記関数において解凍したフォルダへのパスと抽出したい著者を指定、特定著者の著作のみ抽出
def file2data(path, exti='', aut=0):
"""
ファイル読み込み
"""
data = ''
#下位フォルダすべて
for current, subfolders, subfiles in os.walk(path):
for file in subfiles:
if file.endswith('.txt'):
try:
with open(current+'/'+file, 'r', encoding='utf-8') as f:
fd = f.read()
except:
with open(current+'/'+file, 'r', encoding='Shift-JIS', errors='ignore') as f:
fd = f.read()
#除外(著者限定の後に入れたほうが良いがコードを深くしたくないためこちらに)
if exti=='':
pass
elif exti in fd[:20]:
print(exti,'●除外しました', file, fd.replace('\n',' ')[:50])
continue
#特定著者限定
if aut==0:
data += fd + '\n'
print(file, fd.replace('\n',' ')[:50])
continue
for a in aut:
#autareastart = fd.find('\n')#2行目に著者名がある・・・とは限らないので修正したほうが良い
#autareaend = fd[autareastart+1:].find('\n') + autareastart
autareaend = fd.find('\n\n')#\n\nの前が著者名20210116修正
autareastart = fd[:autareaend].rfind('\n') + 1
if a in fd[autareastart:autareaend]:
data += fd + '\n'
print(file, fd.replace('\n',' ')[:50])
return data
train_data = file2data(path, aut=['宮沢','太宰','福沢','夏目','芥川'])
#'芥川'とすると'芥川紗織'なども含まれます。確認しつつ要事除外など行い、使用してください。
#コードに入れませんでしたが、リスト内の著者を無視する機能を付けてもよいでしょう。
gingatetsudono_yoru.txt 銀河鉄道の夜 宮沢賢治 -------------------------------------
gusukobudorino_denki.txt グスコーブドリの伝記 宮沢賢治 ---------------------------------
kazeno_matasaburo.txt 風の又三郎 宮沢賢治 --------------------------------------
kenjukoenrin.txt 虔十公園林 宮沢賢治 --------------------------------------
・・・
print(train_data[:200])
銀河鉄道の夜
宮沢賢治
【テキスト中に現れる記号について】
《》:ルビ
(例)言《い》われたり
~
試行
試運転時出力1

読み方: ['s','骨','形成']を与え次単語予測。実際は「を」。学習後確率は「さ」約7.1%、~

間違いに●が付されている。
*目的を達成できているといえるか検証中・・・
*次単語予測モデルであるので、文章生成もできる。(皆さんご存じの通り、シンプルな確率モデル(をシンプルに適用させるだけ)ではまともな文章生成はできないが、今回は、ヒトに理解可能なインサイトを与えることが目的なので問題ではない。)
試運転時出力2

*用途特許として新しいといえる箇所?に●が付された。next sentence predictionも関連単語まで届くウインドウも持っていない・・・いやぎりぎり届いているが・・・ので偶然だろう。
(文章内の全正答確率を足し合わせ処理することにより、「その文章の新規性の程度」を見積もることも可能なのでは、と思えてきた。tfidf embeddings cluster visにおいて記号の大きさとして示してみようか。)

間違いに●が付されている。

句読点後の●付与についてはあきらかに調整が必要。BERTを真似て双方向から学習させるのも面白いかも?。
→双方向学習に変更。よきかな。
*青空文庫の全テキストを学習させたらメモリ13GB使用中(増え続けている)とえらいことに・・・。transformerは重いが泥臭く作るよりはよほど軽いのだよなと再認識。
n-gramモデルは文体比較や簡単なオートコンプリートなどメモリを少なく抑えても問題がない課題以外では使い難いかなやはり。
青空文庫を用いた著者文体抽出の試行
・文学作品は固有名詞の特殊性と係り受けなど構文の特殊性が混ざりやすく難しい。係り受けなどの特殊性はスタイル抽出に寄与するので良いとして、固有名詞の特殊性は著者でなく著作に依存してしまうことも多いためできるだけ除去したい。
転移学習のようにドメインが浮き上がりやすくなるように差分を取るか、名詞は●付与の対象外としてしまうか、OOVの問題としてtfidfなどで除去してしまうか(再現性や判断の一貫性に問題がある=理解しがたくなる、だろうけれど)…
・新実南吉「おじいさんのランプ」に対する、aut=['宮沢','太宰','福沢','夏目','芥川']学習モデルによる●付与とexti='おじいさん', aut=['新美']学習モデルによる●付与の差分(新美南吉らしさ部分?の一部)

作家の文体の類似性 情報量木カーネルの導入による構文間距離を用いた分析
金川絵利子 佐原諒亮 岡留 剛 The 29th Annual Conference of the Japanese Society for Artificial Intelligence, 2015
https://www.ai-gakkai.or.jp/jsai2015/webprogram/2015/pdf/2K1-1in.pdf
「新美と宮沢は児童作家であり,芥川や太宰・
夏目より比較的短い文を書くとい共通点がある.青空文庫中
の新美の全作品で使用している係り受け構造の種類は 19,124
種類であり,宮沢は 36,428 種類である.新美の方が使用する
係り受けの種類数が少ない.また,新美と宮沢の係り受け構造
の使用回数上位 20 を比較すると,新美はすべて文節間距離 1
の係り受けであるのに対し,宮沢は文節間距離が 4 や 7 のも
のが存在する.よって,新美は文を構成するのに重要な頻出す
る,文節間距離の小さい係り受け構造を多く使用し,特徴的な
係り受け構造は少ないため他の作家との距離が小さくなったと
考えられる.それとは対照的に宮沢は,短い文のなかに様々な
構造の係り受けを用いる文を書くと考えられる.」
語彙と文脈に着目した文学作品の著者推定
花畑圭佑 青野雅樹 言語処理学会 第25回年次大会 発表論文集 (2019年3月)
https://www.anlp.jp/proceedings/annual_meeting/2019/pdf_dir/P7-27.pdf
「」
これら参考に考察する。(考察というよりバイアスに基づく辻褄合わせである気もするがとりあえずおいておく)
まず、上記差分において、「ひらがなに開かれている単語」に●が付されている(「~君はいった」、「叱りはじめた」、「道のほこり」、「とんでいった」、「日ぐれ」、など)
このようなひらがなに開かれた単語は、児童作家である新美南吉のスタイル・文体を示す部分としてふさわしい、と言えるだろう。
ほか、上記差分において、「何だア」という表記に●が付されている。
独特な表現であるかどうか、夫々のモデルの学習後確率を確認してみた(逆モデルはとりあえず除く)

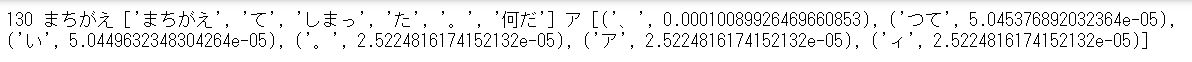
「何だア」という表記は、おじいさんのランプ以外の新美南吉の著作においても使われているようだ。また、宮沢らの著作では(あまり?)使われていないようだ。
「何だア」という表記は、新美南吉のスタイル・文体の一部、とみなしてもよいだろう。
(原文から同じ単語は見つからない。文末にアが来ることは多いようだ?。)
ほか、上記差分において、「外の道へ」「子供には思えるのである」という表記に●が付されている。
わからないが、少々独特な表現ではないだろうか。道へ、私には思える、子供は思う、が、よくつかわれる表現ではないだろうか。
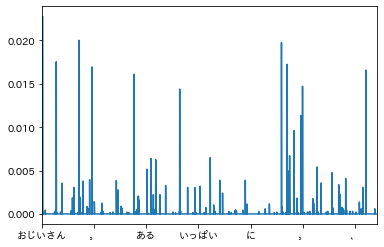
青線が著者に特有と予想される文体を示す単語。(この前後のある範囲を取って品詞名に置き換えたブロックのみを教師とすれば、「比較的わかりやすくかつより精度の高い著者推定」も可能となるのではないだろうか?)
*
言い回しは単発で独特となる傾向、といってもよいかな。人物表現に対する文体が特殊ではないのだが調和しつつ豊かである気がする。
・テスト対象として文体特徴が少ないようである新美南吉を採用した点は適切ではなかった気がしないでもない。次は宮沢賢治。
宮沢賢治「銀河鉄道の夜」

うむさっぱりわからん(おい
いや良いのだよ実用向けのインサイト用なので何を読み取るかは読み手の能力とドメイン知識に依存するのだから。
気づく範囲であえていえば、「急いでそのままやめました」「なんだかどんなこともよくわからない」という表記は、文節間距離が長い特徴的な表記に思える。
学習後確率からすると、「みんな」「そして」付近にも特徴があるようだ。
あえていえば、「●が付されている個数」が多いかもしれない。
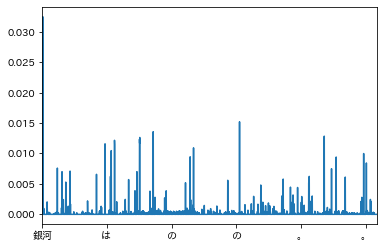
*
言い回しは独特、固有名詞は独特ではない傾向、といってもよいかな。
・芥川龍之介と夏目漱石
作家の文体の類似性 情報量木カーネルの導入による構文間距離を用いた分析
金川絵利子 佐原諒亮 岡留 剛 The 29th Annual Conference of the Japanese Society for Artificial Intelligence, 2015
https://www.ai-gakkai.or.jp/jsai2015/webprogram/2015/pdf/2K1-1in.pdf
「表 1 から分かるように,他の作家との類似度を比較した場
合,芥川と夏目の情報量木カーネル値が大きい.それゆえ,こ
の二人は一般的に珍しい係り受けを用いた文を多く書くこと
で,構文的に似ていると推測できる.珍しい係り受けには,そ
の作家らしさ,作家の文体の特徴が含まれていると考えられ
る.宮沢と新美の情報量木カーネル値が小さいことから,この
二人は構文的に似ていない文を書くといえよう.」
「これより,夏目は一文の中に,「私のコップと彼のコッ
プ」のような同じ構造を 2 回使う対照的な文を他の作家に比
べ多く書くという特徴があるといえる.また,芥川は「私の友
達の麻衣子を探す」のような「麻衣子を探す」だけではなく,
「私の」や「友達の」といった細かい描写が他の作家と比べて
比較的多いという特徴があると考えられる.」
芥川龍之介「羅生門」


あえていえば、「連続して●が付されている」ことが多いかもしれない。
学習後確率からすると、「そこで」「光」付近にも特徴があるようだ。
「火の光」については、著作の特徴なのか著者の特徴(細かい描写?)なのか。
(個人的には、「羅生門」において「火の光」から強い印象を受けている。羅生門から絵画的な印象を受けているが、その一因がこの部分だと思う。(印象が「地獄変」と混ざっている気もしなくもない。あちらは火と絵画そのものやし。))(地獄変の記載から火の光が著者に特徴的と計算されたのかもしれない。)
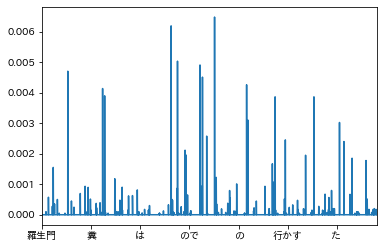
*
固有名詞は多く、独特であることも多い、といってもよいかな。「固有名詞を説明する範囲で言い回しも独特となることがある(あえてしている?)」ようにも予想できなくもない。
もし、著作の印象的な場面において、あえて言い回しや係り受けを特徴的とすることで印象を強めている、としたら、感服するところである。もしそうならば、●周辺のみ読めばあらすじが分かるだろうか。(刻読しやすいスタイル、と表現すればよいだろうか。)
*芥川龍之介からは、手塚治虫との共通点を感じ始めた。「漫画のコマ」は「文章の特徴点を抜き出したもの」とすると、原作があれば自然言語処理で書くべきコマを決定することが可能かなとも。そして書くべきコマに対応する単語群を抽出し、その単語群をCLIPやDALL・Eにかければ、自動で漫画が描けたりするのではないだろうか、とも思え始めた。
夏目漱石「吾輩は猫である」

あえていえば、「*」という表記が特徴的な表記に思える。
学習後確率からすると、「始め」「分ら」付近にも特徴があるようだ。
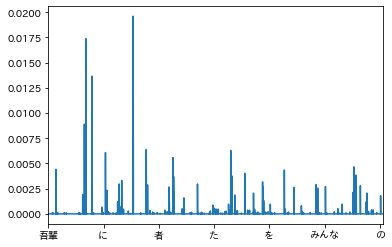
*
特定の固有名詞は独特である、といってもよいかな。「〜にゃ」のような、少数の特定の語尾や語頭により少々無理矢理に印象を作ろうとしている感あり。芥川より短い単語で特徴を出している?。
・●を付す前は、これらのような印象を持てていなかった気がする。
「今回付した●には確率的に確実な意味がある。●を付すことにより、なにかあるはず、と深読みできる。」
このような「確信性・信用・認知可能性」が、「インサイト、創造性?、に寄与する」と言って良いかな?
(創造性は自作AIでも検討しているところであるが、このような確信性や認知可能性は、自作AIやtfidf embeddings cluster visでは得られにくい。今回のようなツールを組み込むとよいのかもしれない。)
・さて、本来の目的で使ってみるか・・・
メモ
**文体のうち、独特な言い回しは判断できるが、係り受けは判断できないかな。
**係り受けにつき、予想より長距離の影響を受けているようだ。重みづけを変えてみるかこのモデルの範囲外とするか。
→影響距離を延ばす対応中。
→疑似next sentence prediction追加。長距離の重みづけをより重視するよう変更。
n10, 3-9。うーむ

n100, 2-9

n*100, 1-5

**係り受けにつき、●の波形から解析できないか・・・。著者推定でありこの条件ならば、特定ドメインにおける文章内全体のある範囲単位の特徴を考慮できるCNNで良いかな?。構造が必要であり内容は不要なので・・・各単語は品詞名に置き換えるか?。単語(または品詞)ごとに範囲が変わると仮定できるならGRUでもよいが。
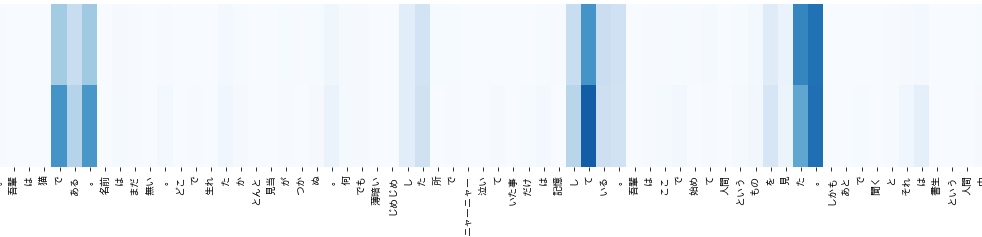
**逆予測でしか予測できない範囲にも特徴があるか?
(ここに図を示していたが、revを逆にすることを忘れていたようなので確認と差し替え中。)
※夏目作品は,文末に特徴があるそうな
そうであるなら,上記は特徴を捉えていると言えるのだろう.
**吾輩は?
参考のため、夏目(「吾輩は猫である}除く)、夏目以外、東北大学事前学習BERT(fine-tuningなし)の3つにつき、「我輩は」の次の単語を出力させてみた。



(学習データが異なるので当然語彙は異なる。)
BERTは「吾輩」を示す名詞そのもののみを出力した。自分はtransformer?のこのような堅苦しさが嫌いなんだ・・・もう少し無駄話を挟んでからそのような単語が提示されても良いだろうに。犬ならどのような犬なのだ?。これを示す可能性を消去した、「文体がことごとく消去された蒸留されたかのような言語モデル」は、実際には「文法モデル」であって「言語のモデル」ではないのではないだろうか・・・。評価値は良いだろうさ。しかしA/Bテストも行えばあたしゃ、この堅苦しさが嫌い、と答えるだろうかな・・・。
あたしゃ、文法とは「結果として得られる構造」であって、「従うべきルール」ではないと考えている(英語では語順が重要なのでその限りではないが)。transformerによる生成は「従うべきルール」に従った生成であるかのようであり、どうにも気に入らない。
(decoderなしのBERTでしかもMaskを用いた次単語生成もどきなので、そもそもtransformer全体に言えるわけではないかもしれない。BERTのmasked langage modelに特有の性質と言われればそのような感覚もある。)
ところで・・・BERTというか日本語wikipediaは、ジャンルが偏りすぎじゃないですかね?

BERTも英語では渋い。
transformer(encoder-decoder)の1、mbartではどうなる?

な、なぜシンハラ語?
うむ私が悪かった。finetuningしないとどうにもならない。
以下遊び。
TXT = "</s> 吾輩は<mask>である。名前はまだ無い。</s> ja_XX"
→吾輩はGoogleである。名前はまだ無い。
facebook先生!?
TXT = "</s>吾輩は猫である。名前</s> ja_XX"
→吾輩は猫である。名前を「ア」と「ア」とととととととととととととととととととととと
greedyさん!?
TXT = "</s>私はコルビジェ。話に登場する</s> ja_XX"
→コルビジェは、クトゥルフ神話に登場するココルビジェの仲間である。クトゥルフ神話では、コルビジェはクトゥルフ
いきなり流暢になったなってコルビジェさん!?
コルビジェは人間ではなかったらしい。pretrainは真実を明らかにするのだな(棒)おやだれかきt
*生成時の設定は次参照
How to generate text: using different decoding methods for language generation with Transformers
https://huggingface.co/blog/how-to-generate
**任意に文脈をかますための知識が得られると役に立ってよいのだが。頑強性のない文脈考慮手法以外の任意性の強い解決手段が欲しい。
**隠れ層を任意のトピックで修正したい、または隠れ層の代わりに任意のトピックを加えたい。
**名詞を分散表現に変換し、任意のトピックと類似した単語を優先するように生成させると面白いかもなぁ。モデルは文体を含むので文体が生成されやすくしかもトピックを切り替えられるわけだ。
**●全てのベクトルを合計し、それに沿った生成をしたらどうだろう?。助詞が多ければ助詞が多くなるしテーマがあればそれに沿うのでは。いや合計してはだめか。分布を取らなくては
**RNNは関数が1つにまとまる性質上、全体の変換(翻訳)には向くが、文生成には向かないはず・・・。RNNにはDoc2Vecと同じく、異なるものを平等に扱うことを前提としたことによる、構造的な行き止まり感を感じる。
**transformerに対する不満として、ドメイン切り替えが容易にできない点がある。この手法であれば、文章に存在する遠い単語は考慮できないが、文章に存在しないテーマを考慮し統一できるわけだ。文章に存在する遠い単語も言ってしまえば文章に存在しないかもしれないテーマに従っているわけであるので、文章に存在する遠い単語の重要度は実際は低いかもしれない。(transformerは文章に存在する遠い単語と文章に存在しないテーマを同時に処理するが、ここから文章に存在しないテーマを切り離すことが難しいまたは処理に時間がかかる、と言って良い?。自分はattentionを切り離し適用したほうが良いのではと思っている。)
*対象文章各単語に対し、同一著者データと他著者データから各々attentionを取り、それをCNNの補正などに用いると面白そうだ。これらにより得られる結果から長距離作用部分を抽出できるかもしれない。。
*差分から類似を取り判定するやり方は、転移学習にも近いし、類似のみで判断するという意味でone-shot学習にも近い?。学習していないが。
*著者共通特徴と著者共通特徴ラベルと空特徴ラベルをconcatしたサンプルと、特定著者特徴と空特徴ラベルと特定著者特徴ラベルをconcatしたサンプルとをまとめて学習することにより、特定著者特徴を予測的に取り出せるようになる、はず。これを利用してシンプルな著者推測をしたらどうなるかな?。
また、特定著者特徴を著者共通特徴に変換し、変換済特定著者特徴をencoderに、特定著者特徴をdecoderに入力して、transformer生成モデルをfine-tuningしたらどうなるかな?。適当な日本語pre-trainデータをどこから持ってくるか・・・。mbartの出力部分をいじったほうが早いか?。要約をsep区切りしなければ取り出せるはずだが確率はどうするか
*encode-decoderのlanguage modelであり、タスク部分を切り取った、各語彙内単語スコアを出力する日本語モデルを用意しておくと何かと便利そうである。どこかで準備しておく。
*mask予測は次の通り
https://huggingface.co/transformers/model_doc/mbart.html#mbartforconditionalgeneration
from transformers import MBartTokenizer, MBartForConditionalGeneration
tokenizer = MBartTokenizer.from_pretrained('facebook/mbart-large-cc25')
# de_DE is the language symbol id <LID> for German
TXT = "</s> Meine Freunde sind <mask> nett aber sie essen zu viel Kuchen. </s> de_DE"
model = MBartForConditionalGeneration.from_pretrained('facebook/mbart-large-cc25')
input_ids = tokenizer([TXT], add_special_tokens=False, return_tensors='pt')['input_ids']
logits = model(input_ids).logits
masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
probs = logits[0, masked_index].softmax(dim=0)
values, predictions = probs.topk(5)
tokenizer.decode(predictions).split()
logitsから各語彙内単語スコアが得られる。
ここからgreebyに次単語生成しても、MBRに次単語生成しても、上記●部分につきスタイルの置き換えを行っても、ある単語の次に特定の単語を割り込ませても置き換えても、話題のテーマに従うように(ad hocに?)単語を置き換えても(ヒトもあるテーマに従い文章を生成する。言語モデルによる文章生成において、queryとして、文章の始まりの不十分なテーマらしきセンテンスしか与えず、明示的にテーマを与えないのは、おかしな話だ)、お好みしだい。生成後再チェックはしたほうが良いと思うけれど。
*NLP2021
B3-3 企業情報を考慮したキャッチコピーの自動生成
○昇夏海, 平岡達也, 丹羽彩奈 (東工大), 西口佳佑 (サイバーエージェント), 岡崎直観 (東工大)
B6-4 指定語句を確実に含む見出し生成
○山田康輔 (名大/朝日新聞社), 人見雄太, 田森秀明 (朝日新聞社), 岡崎直観 (東工大), 乾健太郎 (東北大/理研)
B7-3 テキスト変換モデルに基づく様々な制約を用いたインタラクティブ要約
○柴田知秀 (ヤフー), 山田悠右 (東工大), 小林隼人, 田口拓明 (ヤフー), 奥村学 (東工大)
D4-4 文法誤り訂正モデルは訂正に必要な文法を学習しているか
○三田雅人 (理研/東北大), 谷中瞳 (理研)
*transformer誤り訂正モデル例(mt5)
吾輩は猫である。名前えはまだない。
→吾輩は猫である。名前はまだない。
うーん、この学習量では、学習範囲内しか訂正できない印象。この点はわからない場合に無視するのではなく提示してくるn-gramモデルのほうが良い。精度が高いであろうmt5モデルと再現率が高いであろうn-gramモデル、組み合わせるとより高い価値が生み出せるだろう。
transformerでは学習コストが見合わない印象。一度大量のデータで学習しきればそれっぽくなるだろうが、特殊ドメインでは対応できない印象。やるならば、自動data augmentationと自動学習が重要となりそう。
お遊びで、
input_ids = tokenizer.encode("吾輩は <extra_id_0> である。名前はまだ <extra_id_1> 。")
output_ids = model.generate(input_ids)
print(tokenizer.batch_decode(output_ids))
→[' 吾輩は「男」 である。名前はまだ不明。']
output_ids = model.generate(input_ids, max_length=100, temperature=3.,
num_beams=5, top_k=120, top_p=0.98, do_sample=True)
print(tokenizer.batch_decode(output_ids))
→[' 吾輩は有名である名前はすでに記号。名前はまだ古い。']
→[' しかし、家妻は猫のキャラクターであり名前は定まっていない。']
→[' この輩の名は知者である。名前はまだ不明。']
*言語モデル。ある任意の単語を考慮した文の生成は十分できるとわかった。であるならば、生成した文から次の文につなげるための特徴語を取り出しその単語を考慮して文を生成しとつなげることにより、多分、論理的な文章を作ることは可能なのだろう。
完成した文章を確認し、論旨を変えたい箇所があれば、そこから生成しなおすこともできる。
特徴語を例えば、法分野知識グラフから順番に取り出し、適合する要件単語とともに考慮するよう生成してゆけば、専門家っぽい文章生成も可能だろう。
「言語モデルと知識グラフの結合」には、非常に大きな興味を持っている。(近年よく見られた、「言語モデル自体からの知識抽出」にはあまり興味はない。文章の真値があるかのようなやり方では破綻が目に見えているし。)
*rinna社、日本語に特化したGPT-2の大規模言語モデルを開発しオープンソース化
https://prtimes.jp/main/html/rd/amp/p/000000009.000070041.html?__twitter_impression=true
日本語GPT2。素晴らしい
*【日本語モデル付き】2021年に自然言語処理をする人にお勧めしたい事前学習済みモデル
https://qiita.com/sonoisa/items/a9af64ff641f0bbfed44
日本語事前学習T5ベースモデル。素晴らしい
一気に増えてきた何かあったのかな
*特許請求項要約(ドメイン限定)
(本題と関係がない多分後日切り離す内容参考)スタイルベクトルとtransformerやGANを用いた文章生成
*●付与により、少なくとも、どこを変換すれば効果的か、理解は得られたわけだ。この場所のみ、変換し、生成すれば、よりそれらしい文章変換ができるとは思われる。どう変換するかはおいておいて。
*今回の目的には沿わないかつこのモデルを前提とすることは悪手かもしれないが、ただ興味があるという理由で、最終的にはGANを用いた生成をしてみたい。
1 シンプルな生成
「おじいさんの」の次にくる学習後確率が高い単語は「中」であることが多いのであるが、はてさて、「おじいさんの中」に何がいるというのか。非常にホラーである。
→シンプルに、学習後確率のみから文章生成してみた。
おじいさんの中「には何かある。」、そうだ…
明治大正期の文学に登場するおじいさんは、肚の中に何を隠しているのか…
2 文体置き換えし生成
新美南吉「おじいさんのランプ」を、芥川調に置き換えてみよう。
1 置き換え位置は、前記●位置とする。
2 別途芥川モデルを作成し、●位置について置き換え候補を作成する。
3 まず順方向芥川モデルにより、置き換え候補単語リストを作成する。
4 次に逆方向芥川モデルにより、同じく置き換え候補単語リストを作成する。
5 順逆に共通する単語を抜き出し、置き換える。
6 順逆で共通する単語がなかった場合は…無視する(順方向を優先し1単語足したのち再予測させるなど、伸び縮みさせてもよいが)
置き換えしない選択を優先させるため全体的にはアンバランスになるだろうが、それっぽい文章が生成できると思う。
生成後の文章に付き、再度●の抽出を行い繰り返せば、多少マシになるだろう。
あくまで単語レベルの置き換えなので、構文の置き換えはできないだろう。
3 生成後文章の評価ループを含めた生成
特定著者品詞単位CNNモデルを作り、生成した文章が特定著者に類似するかどうか評価し続けるモデルを作る。
評価後の再生成がランダム、候補単語のランダム性導入やランダムの挿入など、では味気ないので、何らかの制約を加えたい。が、どうするか。高スコアの生成文章は高い重みを持たせて再教育に使うか。語彙不足はどうするか。
分散表現からは文体を類似の連続性として取り出すことのできるから…
*「領域ごとにどのモデル、アルゴリズム、を使うか、選択するアルゴリズム」が必要なんだろうな。
文体領域はn-gram、名詞領域はtransformer、のような
(自作AIにおける個性評価の課題と類似した課題だな…)
*[CCLab 20秋] 音楽とヒューマン・コンピュータ・インタラクション研究の動向と実践
https://medium.com/computational-creativity-lab-at-keio-sfc/cclab-20%E7%A7%8B-%E9%9F%B3%E6%A5%BD%E3%81%A8%E3%83%92%E3%83%A5%E3%83%BC%E3%83%9E%E3%83%B3-%E3%82%B3%E3%83%B3%E3%83%94%E3%83%A5%E3%83%BC%E3%82%BF-%E3%82%A4%E3%83%B3%E3%82%BF%E3%83%A9%E3%82%AF%E3%82%B7%E3%83%A7%E3%83%B3%E7%A0%94%E7%A9%B6%E3%81%AE%E5%8B%95%E5%90%91%E3%81%A8%E5%AE%9F%E8%B7%B5-96f206d88b99
単語の分散表現を用いてギターエフェクトのパラメータを自然言語でコントロールしようとするプロジェクト。
この文体版ができると良い。解像度あわせをどうするか
*再学習、モデルベースの強化学習?ワールドモデル?、マルチタスク学習などを参考とすればよいのかな?
4 GANを用いた生成
…
*言語モデルによる生成単語を上記文章差分確率を確率上位で足切りしつつ用いて検証して戻るように補正しようとしていたが、これはいわゆるbeam searchと同じことか??。スタイルを含めた補正をした場合はそうとも言えないかもしれないが。
*文章差分確率を確率上位で足切りするのではなく、サンプリング中の最も代表的な単語を採用するという分布を考慮したminimun bayes riskのような手法でもよいかもしれない。
参考用メモ
*文体的特徴 よくある分類
・lexical features 文字単語水準
・syntactic features 句点読点や機能語の頻度
・structual features 文章レイアウト、段落内の文の長さ、文章内の段落の数、など
・content specific features 内容語
・idiosyncratic features スペルミスや文法ミス
・multiword expressions MWEs 複単語表現 統合的非構成性(各品詞が予測しがたい)または意味的非構成性(各構成単語からひとまとまりが与える意味を予測しがたい*長距離の引用があった初めてひとまとまりに意味が発生する機能語のまとまりのようなもの?)をもつ複数の単語のまとまり 句構造の部分木となることは保証されていない。
*n-gramの可能性について、次を確認してみる。
"犯罪捜査のためのテキストマイニング" 財津亘 (2019) 共立出版
・文字単位n-gramでは、文章の内容の影響を受けにくい stamatatos2013
・文字単位n-gramでは、bi,triの場合、著者識別に有効 松浦金田2000
・文字単位n-gramでは、nが大きいほど話題内容の影響を受けやすくなる 財津p39
・単語単位n-gramでは、機能語を用いた研究が、著者識別において好まれる。(内容語を含めて分析することはあまりない)
・非内容語の著者識別力は高い。
・著者識別に有効な助動詞は、文末に出現する助動詞なのかもしれない。 財津p45(確かに差はあるが…)
・読点前の文字といった特徴が著者の識別に有効とされている。 財津p45
・文末語は、非内容語の使用率や品詞のbigramについで、著者の識別力が高かった。*分析対象はブログのように比較的自由度が高い文章
・語彙の豊富さ。(上記プログラムでは比較対象著者らが使わず特定著者が使う語彙にも●が付される。比較対象著者らも特定著者も使わない語彙には●が付されない。)
・構文単位、品詞組み合わせの著者識別力は高い。(●につき前後の品詞を意識するとよいか)
*スタイル変換。置き換え、GANなど
Fu, Z., Tan, X., Peng, N., Zhao, D. and Yan, R.:
Style Transfer in Text: Exploration and Evaluation,
CoRR, Vol. abs/1711.06861 (online), available from
http://arxiv.org/abs/1711.06861 (2017).
Prabhumoye, S., Tsvetkov, Y., Salakhutdinov, R. and
Black, A. W.: Style Transfer Through Back-Translation,
Proceedings of the 56th Annual Meeting of the As-
sociation for Computational Linguistics (Volume 1:
Long Papers), Melbourne, Australia, Association for
Computational Linguistics, pp. 866–876 (online), DOI:
10.18653/v1/P18-1080
(2018).
Dai, N., Liang, J., Qiu, X. and Huang, X.: Style Trans-
former: Unpaired Text Style Transfer without Disen-
tangled Latent Representation, Proceedings of the 57th
Annual Meeting of the Association for Computational
Linguistics, Florence, Italy, Association for Computa-
tional Linguistics, pp. 5997–6007 (online), available from
https://www.aclweb.org/anthology/P19-1601 (2019).
Lample, G., Subramanian, S., Smith, E., Denoyer,
L., Ranzato, M. and Boureau, Y.-L.: Multiple-
Attribute Text Rewriting, International Conference
on Learning Representations, (online), available from
https://openreview.net/forum?id=H1g2NhC5KQ
(2019).
Shen, T., Lei, T., Barzilay, R. and Jaakkola, T. S.: Style
Transfer from Non-Parallel Text by Cross-Alignment,
CoRR, Vol. abs/1705.09655 (online), available from
http://arxiv.org/abs/1705.09655 (2017).
*LM-Critic: Language Models for Unsupervised Grammatical Error Correction
https://arxiv.org/abs/2109.06822
文法チェックモデルのみ用いた、ラベル無しデータノイズ付与繰り返し訓練文法誤り訂正
・NLP2022
●A4-2 否定の理解へのprompt-based finetuningの効果
○田代真生, 上垣外英剛, 船越孝太郎, 奥村学 (東工大)
★否定は難しい
否定表現の後の生成も難しい
prompt-based finetuning 言語モデルタスクの形で様々なタスクをfew-shotで解く
そこで
prompt-based finetuningを利用して事前学習で得られた否定知識を活用できるか
ADPA指標 どの程度少ないデータで同じ性能を達成できるか
関連
●prompt-based finetuning 2021
●否定の処理 2020など
結果
●自然言語推論タスク MNLI RTE 否定理解効果あり
感情分析タスク SST 否定理解効果みられず
SSTではそも容易に学習可能?
(BERTでもmaskを使って予測したほうが良さそう??
・eccoによる言語モデルの可視化 (2022-01-28 NLP Hacks#1)
https://speakerdeck.com/hikomimo/ecconiyoruyan-yu-moderufalseke-shi-hua-2022-01-28-nlp-hacks-number-1?slide=12

・青空文庫DeBERTaモデル
これは美味しそう。
・逆強化学習による文章における人間らしさの推定
○岸川大航, 大関洋平 (東大)
https://www.anlp.jp/proceedings/annual_meeting/2024/pdf_dir/E9-4.pdf
報酬を夏目漱石モデルが設定すれば.単語ごとの報酬
・ある作者群モデルと特定の作者モデルの差分から個性を取り出したわけだが、よりスマートに個性を示すベクトルを作り個性を示す単語を抽出する方向でまとめると、こんなになろう。省メモリやしこっち使うかな。文章の個性変換もできそう。
基本的には、事前学習モデルベクトルと事前学習モデルのファインチューニングモデルベクトルの差から個性を示すベクトルを取り出し利用しよう、というアイディア。
Editing Models with Task Arithmetic
https://arxiv.org/abs/2212.04089
或る特許文章を、ある会社や特許事務所が書いたように変換するようなこともできうるところ、足りない部分を加えての生成として成立する、などなったら面白いですね。要は有力事務所が書いたような特許に変換できるツールです。