要点
- T5(Text-To-Text Transfer Transformer、論文、日本語解説記事)の日本語モデル(事前学習済みモデル)を作り、公開しました。ご活用ください。
- T5とは、様々な自然言語処理タスクの入出力がともにテキストになるよう問題形式を再定義することにより、一つの事前学習済みモデルを多様なタスク用に転移学習させることができる高い柔軟性を持ち、かつ、性能も優れている深層ニューラルネットワークです。
- 転移学習の例: 文章分類、文章要約、質問応答、対話応答、機械翻訳、含意関係認識、文の類似度計算、文法的妥当性判定、タイトル生成、スタイル変換、誤字修正、検索結果のリランキングなど(固有表現抽出などのシーケンスラベリングの実施例はない?)
- 日本語T5モデルはHugging Face Model Hubからダウンロードできます。
- ベンチマークとして、ある分類問題について、既存のmT5(日本語も含む多言語版T5)の同規模モデルと精度を比較したところ、mT5は90〜91%、今回作った日本語モデルは96〜97%の精度になりました。
- 転移学習のサンプルコードとして、livedoorニュースのジャンル分類タスクと、ニュースのタイトル生成タスク(一種の文章要約タスク)等を用意しました。
huggingface/transformersで日本語T5モデルをダウンロードして利用する方法:
from transformers import T5ForConditionalGeneration, T5Tokenizer
tokenizer = T5Tokenizer.from_pretrained("sonoisa/t5-base-japanese")
model = T5ForConditionalGeneration.from_pretrained("sonoisa/t5-base-japanese")
はじめに
新たな自然言語処理タスクが発生した時、どのくらい解けそうなタスクなのかサクッと見定めたいことがあると思います。
しかし、自然言語処理には様々な入出力形式を持ったタスクがあり、その入出力を扱えてかつ性能も悪くない適切な深層ニューラルネットワークを探すところから始めるのでは見定めに時間がかかってしまいます。
T5は、その悩みを解決してくれます。
T5 (Text-To-Text Transfer Transformer) とは、様々な自然言語処理タスクの入出力がともにテキストになるよう問題形式を再定義することにより、一つの事前学習済みモデルを多様なタスク用に転移学習させることができる高い柔軟性を持った深層ニューラルネットワークです(参照: オージス総研さんによるT5の解説記事)。
また、性能に関しても、T5は論文公開から1年半ほど経っていますが、2021年4月時点でもGLUEやSuperGLUEのリーダーボードで上位に位置する優れた技術です。
しかし、未だいい日本語事前学習済みモデルが公開されていないので、今回作成して公開してみることにしました。
T5の便利さを実感できる転移学習のサンプルコードも合わせて公開しましたので、どうぞご活用ください。
- 日本語コーパスを用いた事前学習済みT5モデル: https://huggingface.co/sonoisa/t5-base-japanese
- 転移学習のサンプルコード: https://github.com/sonoisa/t5-japanese
転移学習の例
T5は、下図のように事前学習タスク(穴埋め問題)を解くことで言語的な知識を得たモデルを、特定のタスク用にファインチューニング(転移学習)する技術です。
T5の事前学習タスク(穴埋め問題)と、事前学習済みモデルを質問応答タスクに転移させるイメージ:
(T5の左が入力、右が出力。事前学習で得た知識を質問応答に利用している)
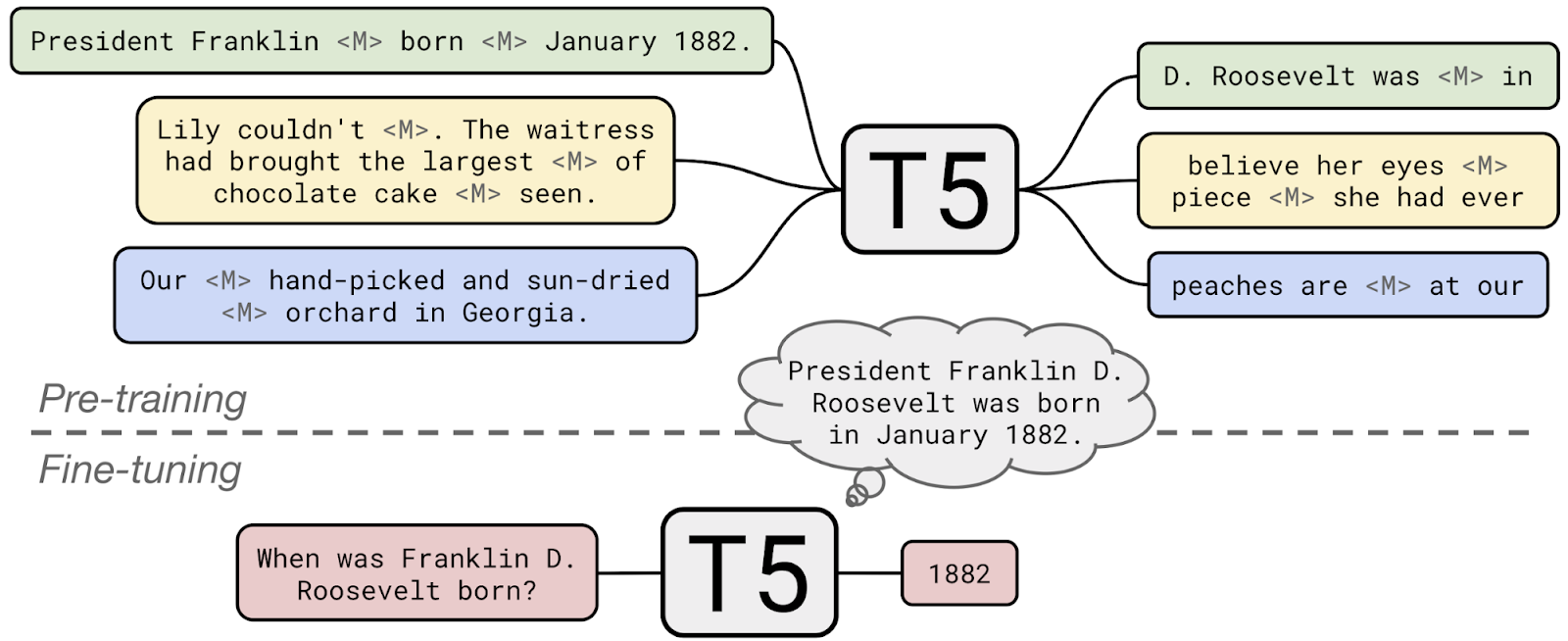
図の出典: Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer
今回作成した日本語T5モデルをいくつかのタスクに転移学習させるサンプルコードを用意しました。
転移学習のサンプルコード: https://github.com/sonoisa/t5-japanese
次のリンクをクリックするとGoogle ColaboratoryでNotebookが開きます。
GPUを有効にして全てのセルを実行すれば学習とテストデータに対する推論が実行されます。
- ニュース記事のジャンル予想(文章分類): 入力 "{title} {body}" → 出力 "{genre_id}"
- ニュース記事のタイトル生成(一種の文章要約): 入力 "{body}" → 出力 "{title}"
- ニュース記事本文生成(文章生成): 入力 "{title}" → 出力 "{body}"
ここで、{title}はニュース記事のタイトル、{body}は本文、{genre_id}はニュースの分類ラベル("0"〜"8")です。
どの例もlivedoorニュースコーパスを利用しています。コーパスを公開している株式会社ロンウイット様、NHN Japan株式会社様に感謝いたします。
以下、各転移学習コードの要点を解説していきます。
1. ニュース記事のジャンル予想(文章分類)
ニュース記事のジャンル予想(9分類タスク)は次の形式の入出力を持つデータセットを用意すれば実現できます。
- 入力 "{title} {body}"
- 出力 "{genre_id}"
ここで、{title}はニュース記事のタイトル、{body}は本文、{genre_id}はニュースの分類ラベル("0"〜"8")です。
つまり、ニュース記事のタイトルと本文から、そのニュース記事のジャンルを予測する問題です。
サンプルコードではtransformersとpytorch-lightningを利用してファインチューニング処理を実装しています。
処理の流れは次の通りです。
- livedoorニュースコーパスをダウンロードし、"{title}\t{body}\t{genre_id}"という形式のTSVファイルに変換します。
- TSVファイルを読み込み、入力が"{title} {body}"、出力が"{genre_id}"という形式のデータセットに変換します。
T5の入出力データはこのテキストを(SentencePieceで)トークナイズしたトークン列です。扱えるトークン数(トークン列の長さ)は有限ですので、入出力それぞれについて最大トークン数を定義します(文字数ではなく、トークン数ですのでお間違いなく)。今回は最大入力トークン数は512、最大出力トークン数は4にしています。最大出力トークン数が1ではなく、4なのは出力開始トークンと文末トークンも(たまに空白トークンも)出力に含まれるためです。 - 日本語T5事前学習済みモデルをダウンロードし、転移学習を実行します。
- テストデータに対する分類予測精度を計算します。
2の入出力を定義する処理はコードの次の箇所です。
class TsvDataset(Dataset):
...
def _make_record(self, title, body, genre_id):
# ニュース分類タスク用の入出力形式に変換する。
input = f"{title} {body}"
target = f"{genre_id}"
return input, target
...
入出力の最大トークン列長をそれぞれ512と4にしています。
その他、バッチサイズを8、学習するエポック数は仮に4としています。
もし、GPUでOut of Memoryエラーが発生するようであれば、バッチサイズを小さくしてみるといいでしょう(例えば4に減らす)。それでもダメなら入出力文の最大トークン数も減らしましょう(例えば256に減らす)。
# 学習に用いるハイパーパラメータを設定する
args_dict.update({
"max_input_length": 512, # 入力文の最大トークン数
"max_target_length": 4, # 出力文の最大トークン数
"train_batch_size": 8,
"eval_batch_size": 8,
"num_train_epochs": 4,
})
事前学習済みモデルのダウンロードと読み込みは次のコードで行われています。
class T5FineTuner(pl.LightningModule):
def __init__(self, hparams):
super().__init__()
self.hparams = hparams
# 事前学習済みモデルの読み込み
self.model = T5ForConditionalGeneration.from_pretrained(hparams.model_name_or_path)
# トークナイザーの読み込み
self.tokenizer = T5Tokenizer.from_pretrained(hparams.tokenizer_name_or_path, is_fast=True)
ベンチマーク
この日本語T5モデル(パラメータ数は222M)を用いたニュース記事のジャンル予測タスクの精度は次の通りです。
| label | precision | recall | f1-score | support |
|---|---|---|---|---|
| 0 | 0.96 | 0.94 | 0.95 | 130 |
| 1 | 0.98 | 0.99 | 0.99 | 121 |
| 2 | 0.96 | 0.96 | 0.96 | 123 |
| 3 | 0.86 | 0.91 | 0.89 | 82 |
| 4 | 0.96 | 0.97 | 0.97 | 129 |
| 5 | 0.96 | 0.96 | 0.96 | 141 |
| 6 | 0.98 | 0.98 | 0.98 | 127 |
| 7 | 1.00 | 0.99 | 1.00 | 127 |
| 8 | 0.99 | 0.97 | 0.98 | 120 |
| accuracy | 0.97 | 1100 | ||
| macro avg | 0.96 | 0.96 | 0.96 | 1100 |
| weighted avg | 0.97 | 0.97 | 0.97 | 1100 |
精度の比較対象として、同規模のモデルである多言語T5(mT5)モデル(パラメータ数は300M)を用いた場合の精度は次のようになります。
mT5に比べて、日本語T5モデルの方が5ポイントほど精度が高いことが分かります。
mT5も日本語を扱うことができますが、多言語に関するタスクでなければ、日本語T5モデルを利用した方が良さそうです。
| label | precision | recall | f1-score | support |
|---|---|---|---|---|
| 0 | 0.91 | 0.88 | 0.90 | 130 |
| 1 | 0.84 | 0.93 | 0.89 | 121 |
| 2 | 0.93 | 0.80 | 0.86 | 123 |
| 3 | 0.82 | 0.74 | 0.78 | 82 |
| 4 | 0.90 | 0.95 | 0.92 | 129 |
| 5 | 0.89 | 0.89 | 0.89 | 141 |
| 6 | 0.97 | 0.98 | 0.97 | 127 |
| 7 | 0.95 | 0.98 | 0.97 | 127 |
| 8 | 0.93 | 0.95 | 0.94 | 120 |
| accuracy | 0.91 | 1100 | ||
| macro avg | 0.91 | 0.90 | 0.90 | 1100 |
| weighted avg | 0.91 | 0.91 | 0.91 | 1100 |
2. ニュース記事のタイトル生成(一種の文章要約)
ニュース記事のタイトル生成は次の形式の入出力を持つデータセットを用意すれば実現できます。
- 入力 "{body}"
- 出力 "{title}"
ここで、{title}はニュース記事のタイトル、{body}は本文です。
つまり、ニュース記事の本文から、タイトルを予測する問題です。
ソースコードを見ると「1. ニュース記事のジャンル予想(文章分類)」のものと見分けが付かないくらい似ていることが分かると思います。
実際、学習に関するコードで変わっているのは入出力に関する部分だけです。
次のコードのように{body}を入力に、{title}を出力するよう定義します。
class TsvDataset(Dataset):
...
def _make_record(self, title, body, genre_id):
# ニュースタイトル生成タスク用の入出力形式に変換する。
input = f"{body}"
target = f"{title}"
return input, target
...
文章分類の場合よりも出力するテキストの長さが長いので、最大出力トークン数を64に増やします。分類問題よりも難しい問題のため、エポック数も8に増やしています(学習時間を減らしたいなら4程度でもいいかもしれません)。
もし、GPUでOut of Memoryエラーが発生するようであれば、バッチサイズを小さくしてみるといいでしょう(例えば4に減らす)。それでもダメなら入出力文の最大トークン数も減らしましょう(例えば入力を256に、出力を32に減らす)。
# 学習に用いるハイパーパラメータを設定する
args_dict.update({
"max_input_length": 512, # 入力文の最大トークン数
"max_target_length": 64, # 出力文の最大トークン数
"train_batch_size": 8,
"eval_batch_size": 8,
"num_train_epochs": 8,
})
たったこの変更だけで、文章分類用コードが、一種の文章要約タスクであるタイトル生成タスク用になります。
T5の便利さが分かる例ですね。
タイトル生成の例
このタイトル生成モデルを使って、タイトルの候補をなるべく多様になるよう複数個生成してみます。
例として、『LEGOで作るスマートロック 〜「Hey Siri 鍵開けて」を実現する方法 〜』の本文に合ったタイトルを10個生成してみます。
body = """
これはLEGOとRaspberry Piで実用的なスマートロックを作り上げる物語です。
スマートロック・システムの全体構成は下図のようになります。図中右上にある塊が、全部LEGOで作られたスマートロックです。
特徴は、3Dプリンタ不要で、LEGOという比較的誰でも扱えるもので作られたハードウェアであるところ、見た目の野暮ったさと機能のスマートさを兼ね備え、エンジニア心をくすぐるポイント満載なところです。
なお、LEGO (レゴ)、LEGO Boost (ブースト) は LEGO Group (レゴグループ) の登録商標であり、この文書はレゴグループやその日本法人と一切関係はありません。
次のようなシチュエーションを経験したことはありませんか?
- 外出先にて、「そういや、鍵、閉めてきたかな?記憶がない…(ソワソワ)」
- 朝の通勤にて、駅に到着してみたら「あ、鍵閉め忘れた。戻るか…」
- 料理中に「あ、鍵閉め忘れた!でも、いま手が離せない。」
- 玄関先で「手は買い物で一杯。ポケットから鍵を出すのが大変。」
- 職場にて、夕方「そろそろ子供は家に帰ってきたかな?」
- 玄関にて「今日は傘いるかな?」
今回作るスマートロックは、次の機能でこれらを解決に導きます。
- 鍵の閉め忘れをSlackに通知してくれる。iPhoneで施錠状態を確認できる。
- 何処ででもiPhoneから施錠できる。
- 「Hey Siri 鍵閉めて(鍵開けて)」で施錠/開錠できる。
- 鍵の開閉イベントがiPhoneに通知され、帰宅が分かる。
- LEDの色で天気予報(傘の必要性)を教えてくれる(ただし、時間の都合で今回は説明省略)。
欲しくなりましたでしょうか?
以下、ムービー多めで機能の詳細と作り方について解説していきます。ハードウェアもソフトウェアもオープンソースとして公開します。
"""
数秒で次の10個のタイトルが生成されます。
正解のタイトル『LEGOで作るスマートロック 〜「Hey Siri 鍵開けて」を実現する方法 〜』は結構長い時間悩んで決めたタイトルなのですが、数秒でこんなに色々生成してくれるなんて。次からはタイトルを考えるときの参考にしようかと思います。
1. アイデア満載の「lego」で作るスマートロックの作り方
2. 「レゴ」とraspberry piで作る実用的なスマートロック
3. 「レゴ」とraspberry piで作る実用的なスマートロック(下)
4. 開発秘話!legoで作る実用的なスマートロック(下)
5. アイディアとアイデアで作る、legoで作られたスマートロックの作り方
6. アイディアとアイデアで作る、legoで作られたスマートロック
7. “lego"で作る実用的なスマートロック、いかがでしたでしょうか?
8. デザインが野暮ったい!誰でも扱えるスマートロックを作ろう
9. アイディアとアイデアで作る、legoで作られたスマートロックの作り方(下)
10. デザインが野暮ったい!誰でも扱えるスマートロックを作ろう!
(デザインが野暮ったいって、そんなに強調しなくても・・・。野暮ったいスマートロックは下図の右側の写真です)

その他、テストデータに対するタイトル生成結果(抜粋)は次の通りです。
generated:が生成されたタイトル、actual:が正解である人が付けたタイトルです。
簡単に作った割には、まあまあいい感じなんじゃないでしょうか。タイトル生成は挑みやすいタスクであるといえるでしょう。
generated: あなたの愛車が今いくら?オンライン上で一括査定できる「愛車無料査定」
actual: 別れる?続ける?3月末で決断を迫る査定サービス
generated: facebook活用術/同窓会・女子会で大活躍!など-【知っ得!虎の巻】
actual: イベント作成や友人の紹介方法facebook活用のスゴ技・裏技テクニック集
generated: nttドコモ、android 4.0 ics搭載3.4インチスマホ「aquos phone st sh-07d」を発表!1ghzcpuや防水、ワンセグに対応
actual: nttドコモ、android 4.0 ics搭載3.4インチスマホ「aquos phone st sh-07d」を発表!1ghzcpuや防水、防塵、ワンセグに対応
generated: プロ野球ファンの想いを数値化して競う、今年の“目利き指数"とは?
actual: 2010年プロ野球界のキーマンは?
generated: インタビュー:森下奈保子さん「映画を創る、女性たち。」
actual: 「映画祭を創る、女性たち。」vol.4コンテンツマーケットディレクター森下美香さん
generated: タンスの肥やしがドンドン増える!?宅配買取サービス『ブランディア』
actual: タンスの肥やしがサイフの糧に!?最新の買取りサービスの実力とは
generated: ダース・ベーダー風のデザインがかわいい!『kinectスター・ウォーズ』が数量限定発売
actual: スターウォーズ「r2-d2」をイメージした限定xbox発売決定!ダサい?それともレトロでかわいい?
generated: なでしこ田中陽子の活躍に期待!?
actual: 期待高まる、澤穂希の“美少女後継者"
generated: 橋下徹大阪府知事が週刊新潮の取材批判にツイッターで賛否両論
actual: ツイッター上で週刊新潮にブチギレした橋下徹氏にネットでは賛否両論
3. ニュース記事本文生成(文章生成)
上手くいく例ばかりではなんなので、上手くいかない例も。
ニュース記事本文生成はタイトル生成と入出力を逆さまにした問題です。
つまり、次の形式の入出力を持つデータセットを用意すれば実現できます。
- 入力 "{title}"
- 出力 "{body}"
ここで、{title}はニュース記事のタイトル、{body}は本文です。
どういうコードを書けば良いかはもう解説不要ですね。
記事生成の例
この記事生成モデルにタイトル「LEGOで作るスマートロック 〜「Hey Siri 鍵開けて」を実現する方法 〜」を入力して記事生成を行なってみます。
title = "LEGOで作るスマートロック 〜「Hey Siri 鍵開けて」を実現する方法 〜"
結果は次の通りです。最初にandroid向けアプリを作ると言っているのに、直後にiphone向けアプリに話がズレていたり、作る方法の紹介だったはずが実行に話が変わっていたり、全体的に論理破綻しています。全然ダメですね。
この素朴な方法では、タイトルから記事を生成することは難しいということがいえるでしょう。
(論理破綻が発生しやすいことはニューラル言語モデル全般の課題ですが)
先日紹介した「スマートロックの作り方」でお伝えしたように、lego(レゴ)はandroid向
けアプリ「hey siri鍵開けて」を実現する方法をご紹介します。今回紹介するiphone向
けアプリ「hey siri鍵開けて」は、google+やfacebookなどのsnsに連携して使うことが
できる便利な機能です。今回は、このスマートロックを作るためのテクニックを紹介しま
す。まずは、スマートフォンからアクセスし、「hey siri鍵開けて」を実行するにはど
うしたらいいのでしょうか?siriが持っているセキュリティキーとは一体何なのかという
ことです。その方法は簡単ですが、簡単にできるわけではありません。しかし、実際に使
ってみるとわかると思いますが、ちょっと面倒くさいかもしれませんね。では、さっそく
解説していきたいと思います。今回の記事では、そんな簡単な操作手順を説明していきま
しょう。【関連記事】・気をつけて!スマホと連動するledイルミネーションライト付きメ
ガネ型防水ipx5/6hモニタリングに対応【売れ筋チェック】・今年のトレンドは3月16日
に米アップルが発表した新os「i-o data resolve4」の新バージョンをリリース【売れ
筋チェック】・スタイリッシュ&ハイクオリティhd液晶モニターspモード対応bluetooth
ルーターaquos phone xperia nxso-04d用大容量バッテリー【売れ筋チェック】
以上で見たように、こういった様々なタスクについて、少しのコードを書くだけで実現性を見定められるのがT5の便利なところです。
免責事項
本モデルの作者は本モデルを作成するにあたって、その内容、機能等について細心の注意を払っておりますが、モデルの出力が正確であるかどうか、安全なものであるか等について保証をするものではなく、何らの責任を負うものではありません。本モデルの利用により、万一、利用者に何らかの不都合や損害が発生したとしても、モデルやデータセットの作者や作者の所属組織は何らの責任を負うものではありません。利用者は本モデルやデータセットの作者や所属組織が責任を負わないことを明確にする義務があります。
まとめ
日本語コーパスを用いたT5の事前学習済みモデルを作り、Hugging Face Models Hubで公開しました。転移学習のサンプルコードもGithubで公開しています。どうぞご活用ください。