tl;dr
- 本論文は自然言語処理において汎用的に利用できる深層学習手法に関するものである。
- 連続する数単語の各特徴量次元(チャンネル)ごとにCNNを適用する先行研究(Depthwise convolution)に対して、複数チャンネルごとにCNNの重みを共有することで更にパラメータを削減するLightweight convolution、さらにその拡張として、入力された特徴量からCNNの重みを動的に計算するDynamic convolutionを提案。Dynamic Convolutionは局所的なself-attentionともみなせる。
- 近年機械翻訳に対して必須といわれている大局的なself-attention (e.g. Transformer)がなくても、機械翻訳で高い精度を実現できることを示した。
- ICLR 2019では、機械翻訳に関して投稿された11本の論文のうち6本の論文が機械翻訳のSotAに名乗りを上げたが、本論文は3位
- ただし、本論文以外の上位論文はself-attentionベースであり、かつ1、2位の論文はアーキテクチャ自体をいじる論文ではないため、ある意味アーキテクチャとしてはTransformerをうわまわったといえる(かも)
- さらに、言語モデル、自動要約においても先行研究と同等、あるいはそれ以上の性能を実現しており、自然言語処理で一般的に使えるアーキテクチャであることを示した。
@inproceedings{
wu2018pay,
title={Pay Less Attention with Lightweight and Dynamic Convolutions},
author={Felix Wu and Angela Fan and Alexei Baevski and Yann Dauphin and Michael Auli},
booktitle={International Conference on Learning Representations},
year={2019},
url={https://openreview.net/forum?id=SkVhlh09tX},
}
はじめに
Ryobotさんによると 先日Open Reviewに公開されたICLR 2019への投稿ではなんと6本も機械翻訳のSotAを名乗る論文が現れたとのことです。

(From @_Ryobot on Twitter)
今回はこのうち3位についた論文である"Pay Less Attention with Lightweight and Dynamic Convolutions"を紹介します。
背景
近年、自然言語処理(特に機械翻訳)ではself-attentionが注目されています。self-attentionは、各単語を他の全単語と比較する手法であり、Googleが開発したTransformer1が代表的です。Self-attentionは非常に強力な手法であり、近年の機械翻訳ではデファクトスタンダード化しています。
しかし、Self-attentionは、全単語と比較を行う構造上、単語長nに対して$n^2$の計算量が必要という問題があります。本研究では、self-attentionに基づかない方法でも高い精度を実現しうることを示すことを目的としていました。
方法
自然言語処理におけるConvolutional neural network (先行研究/予備知識)
CNNの言語応用の歴史の中で最も有名なのはKimによるもの2 ("通常のCNN"と呼ぶ) でしょう。通常のCNNは、異なる幅のカーネルを複数もっており (通常3, 4, 5単語) 、各カーネルは$カーネル幅k×入力チャンネル数d_{in}×チャンネル数d_{out}$ の計算を行います。
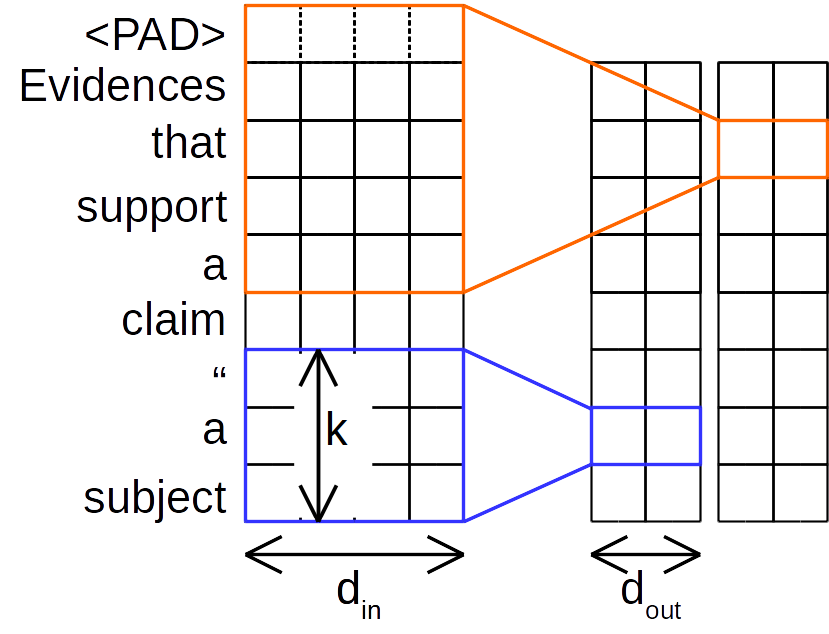
Depthwise (separable) convolution (先行研究/予備知識)
Depthwise convolution3は、通常のCNNが全チャンネルをまとめて計算するために$カーネル幅k×入力チャンネル数d_{in}×チャンネル数d_{out}$の重みが必要なのに対して、各チャンネルごとに独立のパラメータで畳み込みを行います。 (パラメータ数は$カーネル幅k×チャンネル数d$)。そのため、必然的に入力チャンネル数と出力チャンネル数は同じになります。このままだと、チャンネル間の相互作用を捉えられないため、depthwise convolutionを行ったあとに、カーネル幅1の畳み込み($入力チャンネル数d_{in}×出力チャンネル数d_{out}$のパラメータ数)を行います。
(画像は1つのカーネルのみ、depthwise convolution部分のみを表示)
\begin{align}
O_{i,c} &= DepthwiseConv(X, W, i, c, c')\\
&= \sum_{j=1}^k W_{c',j} \cdot X_{(i+j-\lceil \frac{k+1}{2} \rceil),c}
\end{align}
このようにすることで、少ないパラメータで効率よく行列計算を表現できるようになり、計算効率だけでなく、精度もよくなると言われています。
ちなみに、このCNNはsepCNNという名でGoogle Developerの文書分類APIにおいて推奨アルゴリズムとされています4。
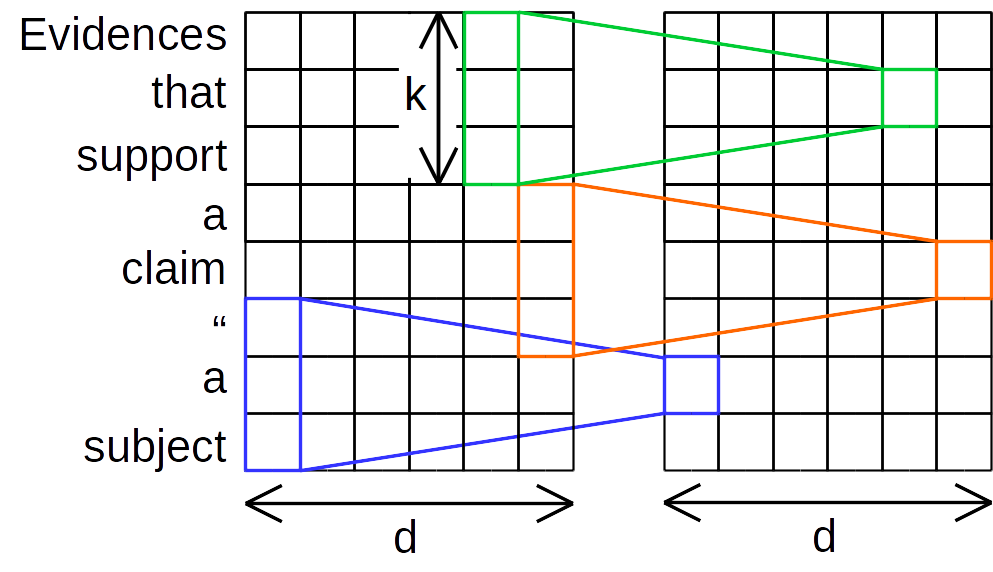
Lightweight convolution
提案手法の1つであるLightweight convolutionは、Depthwise convolutionをさらに簡略化し、チャンネルを$H$個ごとのグループにわけ、グループごとに共通のパラメータでdepthwise convolutionを行う手法です。
(画像は1つのカーネルのみ)
LightConv(X, W_{\lceil \frac{H}{d}c \rceil}, i, c) = DepthwiseConv(X, softmax(W_{\lceil \frac{H}{d}c \rceil}), i, c)
パラメータ数は$カーネル幅k×グループ数H$になります。なお、通常のCNNよりもカーネルサイズを大きくとる(論文内では$k=3, 7, 15, 31$)ようです。
また、重みはカーネル方向にsoftmaxをとってから使用します。これはLightweight convolutionのためではなく、後述するdynamic convolutionに必須の要素であり、dynamic convolutionと条件を揃えるために使っているのだと思われます。
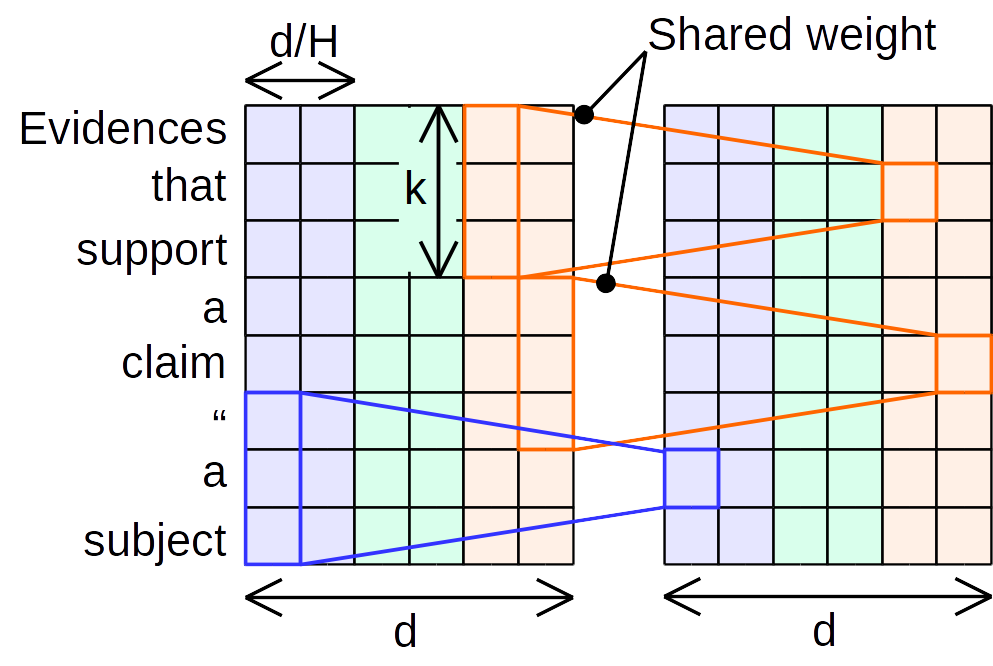
Dynamic convolution
Dynamic convolutionは、入力された特徴量から、Lightweight convolutionの重みを動的に計算する手法です。
DynamicConv(X, i, c) = DepthwiseConv(X, f(X_i)_h, i, c)
ただし、$f$は単なる行列積です。$f(X_i)$の計算には全チャンネルを用いるため、必要なパラメータ数は$カーネル幅k \times グループ数H\times チャンネル数d$とLightweight Convolutionよりは大きくなります。対象の単語と周囲の単語を比べているため、Dynamic convolutionは局所的なself-attentionと考えることもできます。
なお、Dynamic convolutionは重みのSoftmaxがなければ発散してしまうようです。特に説明はありませんでしたが、重みが大きくなりすぎなようにする工夫なのかもしれません。
Dynamic convolutionを使ったアーキテクチャの全体像
上記の説明からわかるように、dynamic convolutionが扱えるコンテキストはカーネルサイズの大きさ分だけです。そこで、本研究ではdynamic convolutionをNブロック重ねて使用することとしています(扱えるコンテキストは$k \times N$単語になる)。論文では$N=7$としていたので、最大のカーネルサイズ31より、217単語(前後108単語ずつ)のコンテキストを扱えていることになります。
なお、本研究のアーキテクチャ全体はDynamic convolution以外の層も用いています。詳しくは論文本文を参照ください。
実験
本論文では3つの自然言語処理のタスクでDynamic convolutionを評価しています。
機械翻訳
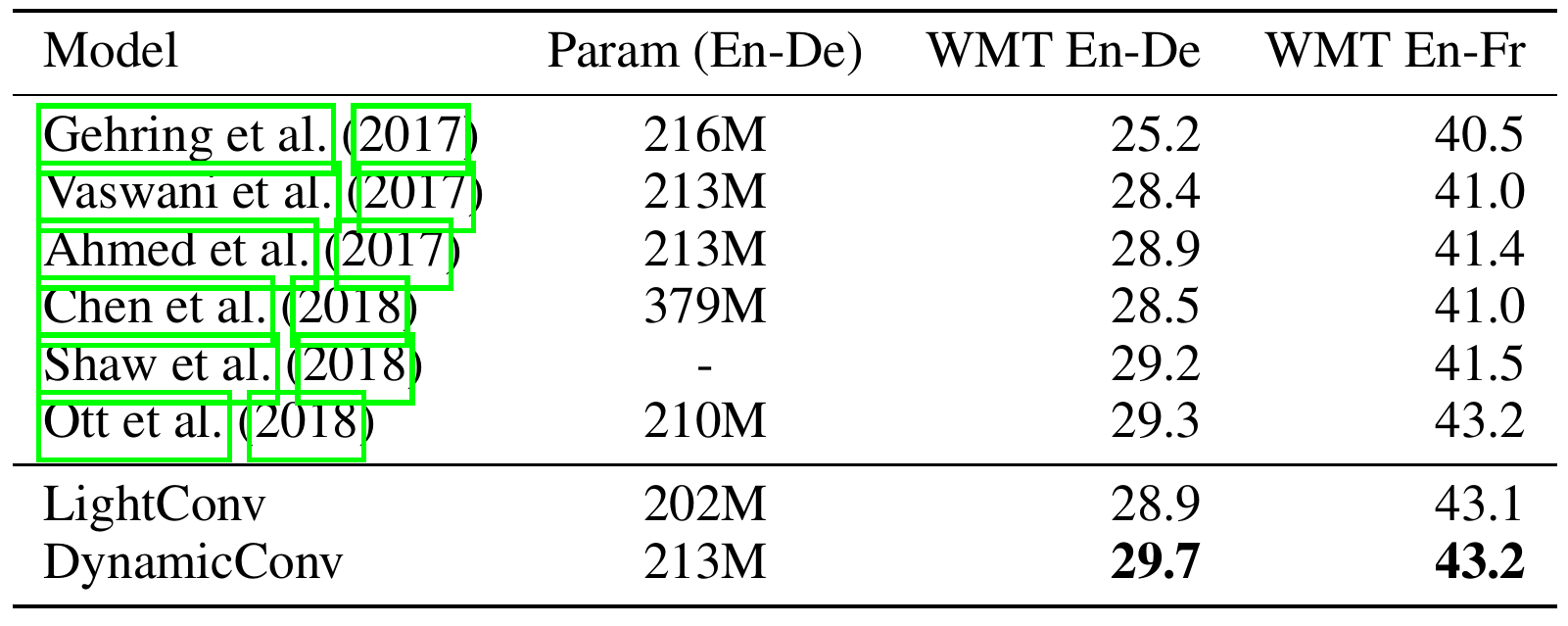
論文公開時点の先行研究よりは優れていますが、前述したとおり同じICLRの論文に抜かれているため、残念ながらSoTAではありません。しかし、他の論文のほとんどがTransformerベースであり、1位、2位が純粋なアーキテクチャの改善によるものでないことを考えると、self-attentionの優位性が叫ばれる中、非常に興味深い研究であると言えると思います。
言語モデル
言語モデルは、対象の単語よりも前の単語(コンテキスト)から対象の単語を当てる方法で、言語処理の根幹をなすタスクであり(例えば機械翻訳は条件付きの言語モデルだといえる)、単体の応用例として文章校正などに使われています。
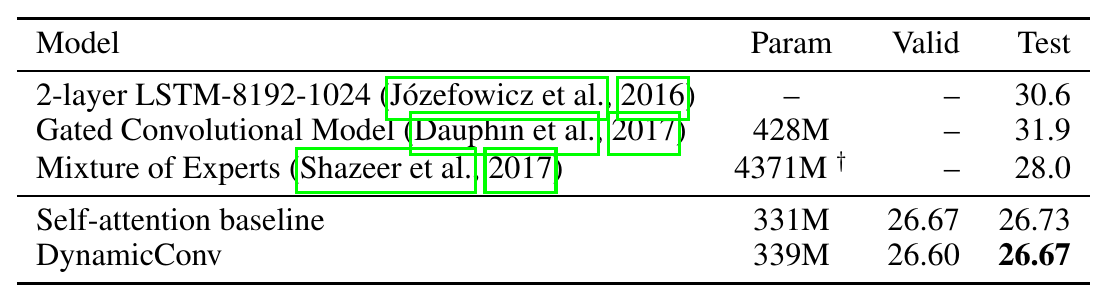
(perplexityは低いほうが良い指標)
ご覧のとおり現在のSoTA (たぶん) であるMixture of Softmaxよりも良いperplexityを達成しています。
文書要約
前述した2つのタスクよりも長いコンテキストを扱えるか評価するために文書要約で評価しています。
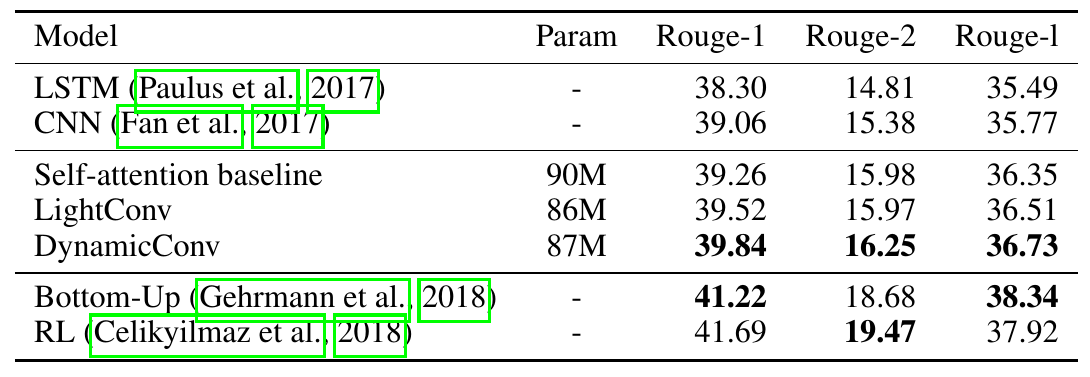
Self-attentionのベースラインよりは優れています。下の2つの手法は文書要約に特化した手法なので、本手法も流石に銀の弾丸というわけではないようです。
最後に
本研究は、近年機械翻訳に対して必須といわれているself-attention (e.g. Transformer)がなくても、機械翻訳で高い精度を実現できることを示したという点で価値があると思います。手法もシンプルで、計算時間的にも極めて現実的と思われます。
3つのタスクでも非常に良い性能を実現しており、自然言語処理全般でアーキテクチャとして期待がもてます。もっとも、まだ本論文は公開されたばかりであり、査読も経ていないので、今後の動きを注視すべきでしょう。(まだ公開されていませんが、著者らによる実装も公開される予定とのことです)
Disclaimer
論文の誤り?
2018/12/13追記: やはり論文は間違えで私の解釈は正しかったようです.現在の論文では修正されています.
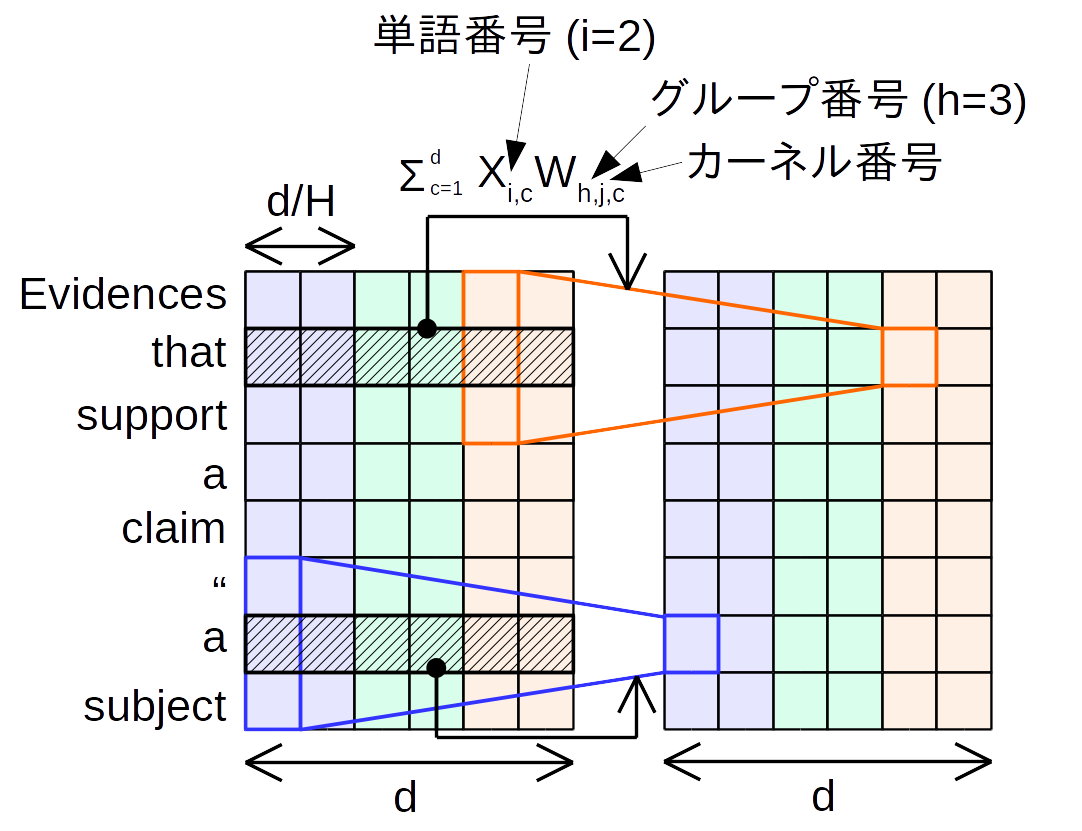
p. 3の第1式は間違っているとしか思えないので私の解釈を加えています。
\begin{align}
DepthwiseConv(X, W, i, c) &= \sum_{j=1}^k W_{c,j} \cdot X_{(i+j-\lceil \frac{k+1}{2} \rceil),c}\\
LightConv(X, W, i, c) &= DepthwiseConv(X, softmax(W), i, \lceil \frac{H}{d}c \rceil)
\end{align}
この式をそのまま信じ、論文と同様に$H = 16$、$d = 1024$を想定し、cに具体的な数値をいれると次のようになります。
\begin{align}
LightConv(X, W, i, 0) &= DepthwiseConv(X, W, i, 0)\\
LightConv(X, W, i, 1) &= DepthwiseConv(X, W, i, 1)\\
LightConv(X, W, i, 2) &= DepthwiseConv(X, W, i, 2)\\
\vdots\\
LightConv(X, W, i, \frac{d_1}{H}(d_1 - 1)) &= DepthwiseConv(X, W, i, d_1 - 1)
\end{align}
つまり、LightConvから出力される行列のチャンネル数は増加するということになります。この場合、パラメータ数は$d_1 \times k$になるので、次段落"Weight Sharing. We tie..."に記載の$H \times k$の説明と矛盾します。
別の考えとして、
\begin{align}
LightConv(X, W, i, 0) &= DepthwiseConv(X, W, i, 0)\\
LightConv(X, W, i, 1 / d) &= DepthwiseConv(X, W, i, 1)\\
LightConv(X, W, i, 2 / d) &= DepthwiseConv(X, W, i, 2)\\
\vdots\\
LightConv(X, W, i, d - 1) &= DepthwiseConv(X, W, i, d - 1)
\end{align}
も一応考えらます。これは、逆dialted convolutionのような形であり、やはりLightConvから出力される行列のチャンネル数は増加します。パラメータ数は矛盾しなくなりますが、未定義のチャンネルはどうなるのかわからない上、ちょっと理解しがたい構造です。
他にも解釈が考えられますが、4つ目の引数が$W$にだけかかっていると考えると、前後の段落とも矛盾なく理解できます。つまり、
\begin{align}
O_{i,c} &= DepthwiseConv(X, W, i, c, c')\\
&= \sum_{j=1}^k W_{c',j} \cdot X_{(i+j-\lceil \frac{k+1}{2} \rceil),c}
\end{align}
かつ、
LightConv(X, W, i, c) = DepthwiseConv(X, softmax(W), i, c, \lceil \frac{H}{d}c \rceil)
です。
著作権に関して
本論文で使用している表はすべて論文からの抜粋です。特に出展が示されていない図、ならびに本文はCC-0で公開しています。
編集可能な図はこちら。
-
Vaswani et al. 2017. Attention is All you Need. NIPS 2017. ↩
-
Kim. 2014. Convolutional Neural Networks for Sentence Classification. EMNLP 2014. ↩
-
Chollot. 2016. Xception: Deep Learning with Depthwise Separable Convolutions. CVPR 2017. ↩
-
https://developers.google.com/machine-learning/guides/text-classification/step-2-5 ↩