言語処理の入門とも言える言語処理100本ノック 2015を終えました![]()
2015年版なので少し古いですが、少し自分なりに内容変えたりしながらやりました。今は2020年版がありますが、内容は同じものも多いです。ノックをやることで言語処理入門者が初中級くらいのレベルになり、Pythonの腕も上がります(やる前が大したことがないので当然上がる)。
ただ、私は最初はすごい流してやっていたのですが、すべてをやりきった後にもう一度見返しました。最初の方の章は全然身についていないと感じ、流していた部分は2度目をやり直しブログ記事にしました。やはり時間をかけて考え、何かに(私の場合ブログ記事に)アウトプットしないとあまり意味ないですね。ただ、途中仕事が忙しかったり他の勉強に浮気していたりと1年半かかったのが原因でもあります。
サマリ
| 項目 | 内容 |
|---|---|
| 目的 | 言語処理の基礎を学ぶため |
| 期間 | 約1年半(他のこともやっていたので・・・) |
| 総時間(実績) | 184時間弱 |
| 使用プログラム言語 | Python(ほぼJupyter Lab)/Unixコマンド |
| 環境 | Ubuntu18.04.01LTS + Pyenv + venv + Jupyter |
学んだことサマリ
**言語処理において必要な知識・技術について体系的に学べました。**私にとっては機械学習以外はどれも未経験領域で非常に学ぶことが多かったです。
3章以降はそれぞれの内容が深いので、ただコピペでわかった気になると得るものが少ないかもしれません(体験談)。また、プログラム上で課題を達成できたとしても、裏で動いているアルゴリズムや理論を理解しているかは別問題です。その辺は個人でどこまでの学習成果を目標とすべきかを明確にして取り組むことをおすすめします。
一方でBERTなどディープラーニング系がありません。そちらを重視するのであれば、2015年版ではななく2020年版を、または両者をやる必要があります。
環境について
環境をどのように構築するか(Pyenvを使うなど)は大事です。私は、最初Google Colaboratory使っていたのですが、ファイルのアップロード系やCaboCha等のインストールが面倒だったので途中でローカルWindows環境に切り替えました。しかしWindowsはCaboChaインストールで詰まり、Ubuntuに切り替えました(私のスキルで64bit Windowsにインストールできませんでした)。また、Pythonを辞書型を使うときに順序性保証をするためにPython3.7.1以上をおすすめします。
私にとっては「UbuntuにpyenvとvenvでPython開発環境構築」で書いたUbuntu + Pyenv + venvがとてもおすすめです(+ JupyterLabも)。
まとめるとおすすめは以下の通りですが、Macユーザの方はUbuntuにこだわらなくてもいいと思います。
| 種類 | バージョンなど |
|---|---|
| OS | Ubuntu |
| Pythonバージョン管理 | Pyenv(慣れているから) |
| Pythonバージョン | 3.7.1以上 |
| Pythonパッケージ管理 | venv(慣れているから) |
| Python実行 | JupyterLab |
前提知識
言語処理
言語処理の前提知識は不要です。ゼロから学べます。私はゼロからはじめました。正規表現ですらも1から2回程度使ったことがあるレベルでした。
Python
Pythonの前提知識不要です。私は、100本ノックを始めた頃は初心者、中断後に再開したときは初中級レベルでした。やりながら学んでいくくらいでちょうどいいのではないかと思います。その方法だと気持ち悪いと思う方は、「スッキリわかるPython入門 (スッキリシリーズ)」など初心者用の本を1冊読破した後にやる程度でもいいと思います。
NoSQL
NoSQLに関する前提知識不要です。私はこのノックで初めて触りました(RDBMSは経験あり)。ただ、第7章を始める前に「RDB技術者のためのNoSQLガイド」を購入して基本を学習しました。
機械学習
機械学習に関する前提知識不要です。ただ、前提知識がないと第8章で時間がかかると思います。私はCoursera機械学習入門オンライン講座などで学んでいたので機械学習という点では苦労はしませんでした。しかし、パッケージscikit-learnはあまり使ったことがなかったことや、結構こだわって精度をあげようとしたので、それでも「第8章:機械学習」に時間がかかっています。
数学
基本的にほとんどはパッケージ側で計算してくれるので、ただ問題を解くだけなら前提知識不要です。自分で計算をしているのは「84本目「単語文脈行列の作成」と87本目「単語の類似度」くらいなもので、高校数学を忘れていてもググったりしながら理解できます。
ただ、機械学習部分を理解するなら高校卒業レベルは必要です。「第8章:機械学習」に出てくるロジスティック回帰の数理を理解するには高校数学レベルは必須です。
学習の進め方
「素人の言語処理100本ノックシリーズ」を参考にしながらJupyter Labで問題を解いていきました。問題を解き終えたら、問題の奥にある理論などをある程度調べてブロクにまとめつつ頭の整理をしています(「まとめつつ」ではありますが記事の品質低いです)。
各章概要
各章の概要と学習時間、個人的難易度評価です。
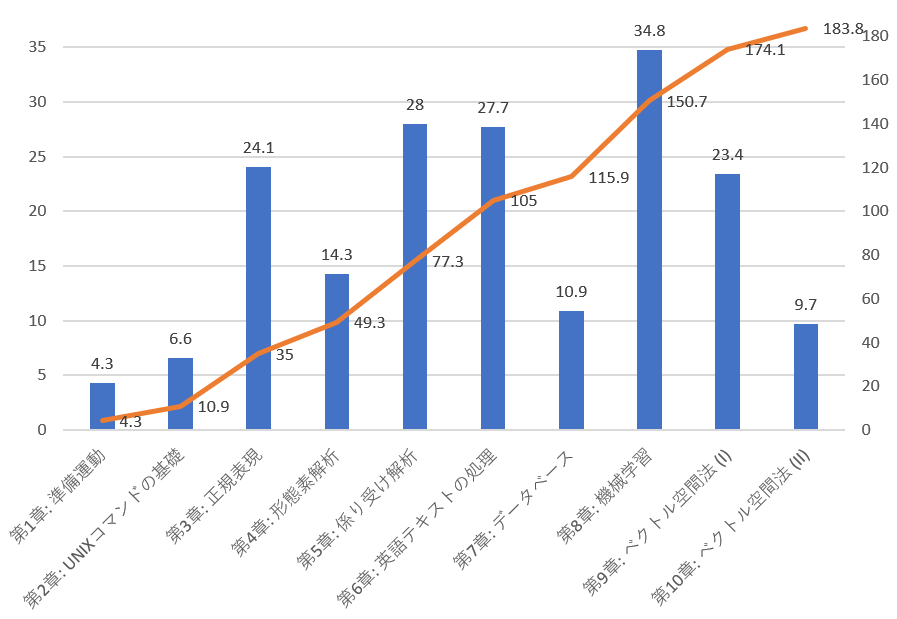
| 章 | 内容 | 学習時間(h) | 難易度 |
|---|---|---|---|
| 第1章: 準備運動 | Pythonの基礎的な練習。Python初心者に最適。 | 4.3 | 簡単 |
| 第2章: UNIXコマンドの基礎 | UNIXコマンド基礎。Pandasについても学習。 | 6.6 | 簡単 |
| 第3章: 正規表現 | 文字列操作に欠かせない正規表現の基礎。 | 24.1 | 普通 |
| 第4章: 形態素解析 | MeCabを使った日本語の形態素解析 | 14.3 | 普通 |
| 第5章: 係り受け解析 | CabochaとMeCabを使った日本語の係り受け解析 | 28 | 難 |
| 第6章: 英語テキストの処理 | Stanford CoreNLPを使った英語の言語処理 | 27.7 | 難 |
| 第7章: データベース | RedisとMongoDBを使ったDB処理 | 10.9 | 普通 |
| 第8章: 機械学習 | Standord NLPとscikit-learnを使った機械学習 | 34.8 | 難 |
| 第9章: ベクトル空間法 (I) | scipy, numpy, scikit-learnを使った自作word2vec | 23.4 | 普通 |
| 第10章: ベクトル空間法 (II) | Gensimのword2vecとクラスタリング | 9.7 | 普通 |
各章学習時間(棒)と累積学習時間(折れ線)。
各章詳細
第1章:準備運動
学習内容
テキストや文字列を扱う題材に取り組みながら,プログラミング言語のやや高度なトピックを復習します.
学習の感想など
まさに「準備運動」という名前がしっくりとくる簡単な内容。文字列処理に関する基本的な内容なので時間がかからないですが、初心者が始めるにはとてもよい教材。
|No.|項目|学んだこと|
|:-:|:--|:--|:--|
|0|文字列の逆順|スライス|
|1|「パタトクカシーー」|スライス|
|2|「パトカー」+「タクシー」=「パタトクカシーー」|for, zip, join, リスト型内包表記|
|3|円周率|split, strip, len|
|4|元素記号|pprint.pprint, 辞書型, enumerate, 辞書型内包表記(if-elseあり), 辞書型ソート|
|5|n-gram|n-gram, replace, rangeとfor|
|6|集合|set, 和集合とunion, 差集合とintersection, 積集合とdifference|
|7|テンプレートによる文生成|str, printとformat|
|8|暗号文|文字コードとchr, 小文字判断とislower|
|9|Typoglycemia|タイポグリセミア, random.shuffle, list関数|
第2章:UNIXコマンドの基礎
学習内容
研究やデータ分析において便利なUNIXツールを体験します.これらの再実装を通じて,プログラミング能力を高めつつ,既存のツールのエコシステムを体感します.
ノック内容
hightemp.txtは,日本の最高気温の記録を「都道府県」「地点」「℃」「日」のタブ区切り形式で格納したファイルである.以下の処理を行うプログラムを作成し,hightemp.txtを入力ファイルとして実行せよ.さらに,同様の処理をUNIXコマンドでも実行し,プログラムの実行結果を確認せよ.
学習の感想など
|No.|項目|学んだこと|
|:-:|:--|:--|:--|
|10|行数のカウント|ファイルの行数カウント, with, open, readlines, UNIX(wc)|
|11|タブをスペースに置換|文字列置換, replace, UNIX(sed)|
|12|1列目をcol1.txtに,2列目をcol2.txtに保存|列の抽出, pandas(read_table, to_csv), UNIX(cut)|
|13|col1.txtとcol2.txtをマージ|列のマージ, pandas(read_csv), UNIX(paste)|
|14|先頭からN行を出力|ファイル先頭出力, input, break, UNIX(head)|
|15|末尾のN行を出力|ファイル末尾出力, writelines, math.ceil, UNIX(tail)|
|16|ファイルをN分割する|ファイル分割, UNIX(split)|
|17|1列目の文字列の異なり|ユニーク出力(重複削除), pandas(unique), UNIX(uniq, sort)|
|18|各行を3コラム目の数値の降順にソート|ソート, pandas(sort_values)|
|19|各行の1コラム目の文字列の出現頻度を求め,出現頻度の高い順に並べる|出現頻度カウント, pandas(value_counts)|
第3章:正規表現
学習内容
Wikipediaのページのマークアップ記述に正規表現を適用することで,様々な情報・知識を取り出します.
ノック内容
Wikipediaの記事を以下のフォーマットで書き出したファイルjawiki-country.json.gzがある.
- 1行に1記事の情報がJSON形式で格納される
- 各行には記事名が"title"キーに,記事本文が"text"キーの辞書オブジェクトに格納され,そのオブジェクトがJSON形式で書き出される
- ファイル全体はgzipで圧縮される
以下の処理を行うプログラムを作成せよ.
学習の感想など
正規表現についてのとてもよい教材兼練習問題。今まで正規表現をググりながら対応してきた私にはとてもよかったです。正規表現に関して学んだことは記事「ゼロから覚えるPython正規表現の基本とTips」にまとめました。
| No. | 項目 | 学んだこと |
|---|---|---|
| 20 | JSONデータの読み込み | JSON読込, pandas(read_json) |
| 21 | カテゴリ名を含む行を抽出 | 正規表現(全検索), raw文字列, トリプルクォート, re(findall, VERBOSE, MULTILINE) |
| 22 | カテゴリ名の抽出 | 正規表現(非貪欲マッチ, キャプチャ対象外) |
| 23 | セクション構造 | 正規表現(後方参照, m回の繰返) |
| 24 | ファイル参照の抽出 | 正規表現(和集合(or)) |
| 25 | テンプレートの抽出 | 正規表現(肯定の先読み), 順序付き辞書, re(DOTALL), collections(OrderDict) |
| 26 | 強調マークアップの除去 | 正規表現(置換), re(sub) |
| 27 | 内部リンクの除去 | |
| 28 | MediaWikiマークアップの除去 | |
| 29 | 国旗画像のURLを取得する | REST API消費, urllib(request, parse), json(loads) |
第4章:形態素解析
学習内容
夏目漱石の小説『吾輩は猫である』に形態素解析器MeCabを適用し,小説中の単語の統計を求めます.
ノック内容
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をMeCabを使って形態素解析し,その結果をneko.txt.mecabというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
なお,問題37, 38, 39はmatplotlibもしくはGnuplotを用いるとよい.
学習の感想など
pandasパッケージを利用しているので、プログラム自体はだいたいシンプルで簡単です。形態素解析に馴染むための章と考えています。
| No. | 項目 | 学んだこと |
|---|---|---|
| 30 | 形態素解析結果の読み込み | MeCab, DataFrameのループ, append, pandas(to_dict, iterrows, loc) |
| 31 | 動詞 | |
| 32 | 動詞の原形 | |
| 33 | サ変名詞 | |
| 34 | 「AのB」 | |
| 35 | 名詞の連接 | |
| 36 | 単語の出現頻度 | pandas(startswith) |
| 37 | 頻度上位10語 | matplotlibのグラフ日本語表示, pandasからの棒グラフ表示, pandas(bar) |
| 38 | ヒストグラム | pandasからのヒストグラム表示, pandas(hist), matplotlib(set_xlabel, set_ylabel) |
| 39 | Zipfの法則 | Zipf(ジップ)の法則, 散布図, ログスケール, matplotlib(xscale, yscale, xlim, ylim, xlabel, ylabel, scatter) |
第5章:係り受け解析
学習内容
『吾輩は猫である』に係り受け解析器CaboChaを適用し,係り受け木の操作と統語的な分析を体験します.
ノック内容
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をCaboChaを使って係り受け解析し,その結果をneko.txt.cabochaというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
学習の感想など
言語処理100本ノックに鬼門に感じます。前章と異なり、パッケージの力を活用できないので、自分で面倒なアルゴリズムを組む必要があります。面倒くさがり屋としては、結構大変に感じました。新人などにやって欲しい内容。49本目は、複雑な処理を長く書くので鬼門![]()
また、CaboChaをWindowsにインストールできず、Linuxに開発環境にすっぱり切り替える覚悟を決めさせてくれたのはいい思い出。
| No. | 項目 | 学んだこと |
|---|---|---|
| 40 | 係り受け解析結果の読み込み(形態素) | クラス, クラスの変数一覧出力(dict), re(match) |
| 41 | 係り受け解析結果の読み込み(文節・係り受け) | |
| 42 | 係り元と係り先の文節の表示 | |
| 43 | 名詞を含む文節が動詞を含む文節に係るものを抽出 | |
| 44 | 係り受け木の可視化 | Pythonからシェルの実行, 有効グラフ表示, subprocess(run), pydot(graph_from_edges, write_png) |
| 45 | 動詞の格パターンの抽出 | シェルでのファイル検索, ファイル書込, write, UNIX(grep) |
| 46 | 動詞の格フレーム情報の抽出 | リストのソート, sort |
| 47 | 機能動詞構文のマイニング | |
| 48 | 名詞から根へのパスの抽出 | |
| 49 | 名詞間の係り受けパスの抽出 | endwith, extend |
第6章:英語テキストの処理
学習内容
Stanford Core NLPを用いた英語のテキスト処理を通じて,自然言語処理の様々な基盤技術を概観します.
ノック内容
英語のテキスト(nlp.txt)に対して,以下の処理を実行せよ.
学習の感想など
日本語にはなかった「レンマ」などを含んだ英語の言語処理を学びます。5章と同様に自分でロジック組む必要がある程度あり時間がかかります。59本目でS式のパーサーを作らなければならず鬼門![]()
※Stanford CoreNLPは2020年4月にバージョン4.0になっています。私がやった内容といろいろ違うかもしれません。
|No.|項目|学んだこと|
|:-:|:--|:--|:--|
|50|文区切り |printでのファイル出力|
|51|単語の切り出し ||
|52|ステミング |ステミング, nltk(stem)|
|53|Tokenization |Stanford CoreNLPの基本, XML解析, xml(parse, iter)|
|54|品詞タグ付け |Stanford CoreNLP(レンマ, 品詞), xml(findtext)|
|55|固有表現抽出 |Stanford CoreNLP(固有表現, 人名), xml(iterfind)|
|56|共参照解析 |Stanford CoreNLP(共参照), xml(get), 改行なしのprint|
|57|係り受け解析 |Stanford CoreNLP(係り受け), pydot(write_jpeg)|
|58|タプルの抽出 |Stanford CoreNLP(係り受け間の関係性)|
|59|S式の解析 |Stanford CoreNLP(句構造解析), S式, パーサー, re(split)|
第7章:データベース
学習内容
Key Value Store (KVS) やNoSQLによるデータベースの構築・検索を修得します.また,CGIを用いたデモ・システムを開発します.
ノック内容
artist.json.gzは,オープンな音楽データベースMusicBrainzの中で,アーティストに関するものをJSON形式に変換し,gzip形式で圧縮したファイルである.このファイルには,1アーティストに関する情報が1行にJSON形式で格納されている.JSON形式の概要は以下の通りである.
JSON形式省略
artist.json.gzのデータをKey-Value-Store (KVS) およびドキュメント志向型データベースに格納・検索することを考える.KVSとしては,LevelDB,Redis,KyotoCabinet等を用いよ.ドキュメント志向型データベースとして,MongoDBを採用したが,CouchDBやRethinkDB等を用いてもよい.
学習の感想など
第6章ではNoSQLとしてKVSとドキュメント指向DBを学びます。前者はRedisを、後者はMongoDBを使いました。言語処理100本ノックとしはLevelDBを想定しているようですが、筆者が取り組んだ2019年ではRedisの方がメジャーと考えRedisを使っています。
今までRDBMSしか扱ったことがなかったので、「RDB技術者のためのNoSQLガイド」を購入して基本を学習しました。言語処理に限らずRDBMSの苦手部分に対応できる仕組みになっており、非常に興味深かったです。
Redisの環境構築に関しては記事「最新RedisのUbuntuへのインストールとPythonで使うまで」に、Redisの基本については「【初心者向け】Redisのデータ型とPythonでの使い方サンプル」に、MongoDBの環境構築は「MongoDBのUbuntuへのインストールとシェルとPythonで動作確認」記録しています。
※64から69についてはQiita記事を書いておらず、GitHubのリンクのみ。「66.検索件数の取得」はシェル実行のみなのでリンクなし。
| No. | 項目 | 学んだこと |
|---|---|---|
| 60 | KVSの構築 | NoSQL, KVS, Redis, reids-py, Hashesデータ型, jsonパッケージ |
| 61 | KVSの検索 | hgetall |
| 62 | KVS内の反復処理 | scan_iter, hvals |
| 63 | オブジェクトを値に格納したKVS | hset, hvals |
| 64 | MongoDBの構築 | pymongo, list_database_names, drop, insert_many, create_index |
| 65 | MongoDBの検索 | find, bson(Binary JSON) |
| 66 | 検索件数の取得 | count |
| 67 | 複数のドキュメントの取得 | input |
| 68 | ソート | sort, limit |
| 69 | Webアプリケーションの作成 | flask, render_template, Class |
第8章:機械学習
学習内容
評判分析器(ポジネガ分析器)を機械学習で構築します.さらに,手法の評価方法を学びます.
ノック内容
本章では,Bo Pang氏とLillian Lee氏が公開しているMovie Review Dataのsentence polarity dataset v1.0を用い,文を肯定的(ポジティブ)もしくは否定的(ネガティブ)に分類するタスク(極性分析)に取り組む.
学習の感想など
機械学習についてで、「73.学習」を徹底的にやっていたら自然と第7章ほぼ全部の学習内容が終わっていました。これもCoursera機械学習入門コースのおかげですね。
記事「Coursera機械学習入門オンライン講座虎の巻(文系社会人にオススメ)」に書いているだけの時間をかけたので当然かもしれませんが。
使っていアルゴリズムはロジスティクス回帰なので、そんなに精度出ないですが学習の基本としてとっつきやすいです。
| No. | 項目 | 学んだこと |
|---|---|---|
| 70 | データの入手・整形 | codecsパッケージ |
| 71 | ストップワード | nltk, StanfordNLP, ストップワード(nltk.corpus.stopwords), stanfordnlp.Pipeline, ステム(nltk.stem), レンマ(lemma), Universal POS(upos) |
| 72 | 素性抽出 | 素性(Feature), warnings.simplefilter, writerow(csvパッケージ), collections(Counterパッケージ), Pandas(value_counts, sort_values, head, describe, sort_index) |
| 73 | 学習 | tf-idf, 単語のベクトル化, ロジスティクス回帰, ハイパーパラメータ探索, グリッドサーチ, パイプライン化, 交差検定, scikit-learn(CountVectorizer, TfidfVectorizer, LogisticRegression, GridSearchCV, Pipeline, BaseEstimator, TransformerMixin, fit, transform), Pandas(from_dict, to_csv) |
| 74 | 予測 | 予測(推論), scikit-learn(train_test_split, predict_proba), numpy(argmax), Pandas(T(転置), rename) |
| 75 | 素性の重み | 貢献度, scikit-learn(get_feature_names), matplotlib(barh) |
| 76 | ラベル付け | scikit-learn(predict) |
| 77 | 正解率の計測 | 正解率, 適合率, 再現率, F1スコア, 混合行列, scikit-learn(classification_report, confusion_matrix) |
| 78 | 5分割交差検定 | 交差検定 |
| 79 | 適合率-再現率グラフの描画 | 適合率-再現率グラフ, ROC曲線, AUC, 学習曲線, scikit-learn(precision_recall_curve, roc_curve, auc, learning_curve) |
第9章:ベクトル空間法 (I)
学習内容
大規模なコーパスから単語文脈共起行列を求め,単語の意味を表すベクトルを学習します.その単語ベクトルを用い,単語の類似度やアナロジーを求めます.
ノック内容
enwiki-20150112-400-r10-105752.txt.bz2は,2015年1月12日時点の英語のWikipedia記事のうち,約400語以上で構成される記事の中から,ランダムに1/10サンプリングした105,752記事のテキストをbzip2形式で圧縮したものである.このテキストをコーパスとして,単語の意味を表すベクトル(分散表現)を学習したい.第9章の前半では,コーパスから作成した単語文脈共起行列に主成分分析を適用し,単語ベクトルを学習する過程を,いくつかの処理に分けて実装する.第9章の後半では,学習で得られた単語ベクトル(300次元)を用い,単語の類似度計算やアナロジー(類推)を行う.
なお,問題83を素直に実装すると,大量(約7GB)の主記憶が必要になる. メモリが不足する場合は,処理を工夫するか,1/100サンプリングのコーパスenwiki-20150112-400-r100-10576.txt.bz2を用いよ.
学習の感想など
言語処理100本ノックの鬼門と言われているようです。データ量が多いため処理時間もかかり面倒です。しかし、面倒な反面、単語ベクトルおよびWord2Vecについてじっくりと学ぶことができ非常に有意義なノックかと感じています。
| No. | 項目 | 学んだこと |
|---|---|---|
| 80 | コーパスの整形 | |
| 81 | 複合語からなる国名への対処 | 正規表現の小文字・大文字識別なし(IGNORECASE), rstrip |
| 82 | 文脈の抽出 | 対象語, 文脈語, 文脈幅(Context Window Size), writelines |
| 83 | 単語/文脈の頻度の計測 | ファイルの行指定部分保存, ファイルで特定行出力, Pandas(to_pickle, groupby, agg) |
| 84 | 単語文脈行列の作成 | PPMI(正の相互情報量), 疎行列, 変数使用メモリの出力, Pandas(read_pickle), Scipy(lil_matrix, savemat) |
| 85 | 主成分分析による次元圧縮 | 主成分分析, 特異値分解, 次元圧縮, Scipy(loadmat), scikit-learn(TruncatedSVD, explained_variance_ratio_), numpy(savez_compressed) |
| 86 | 単語ベクトルの表示 | numpy(load) |
| 87 | 単語の類似度 | コサイン類似度, numpy(dot, linalg.norm) |
| 88 | 類似度の高い単語10件 | numpy(count_nonzero) |
| 89 | 加法構成性によるアナロジー | ベクトル計算, numpy(argsort) |
第10章:ベクトル空間法 (II)
学習内容
word2vecを用いて単語の意味を表すベクトルを学習し,正解データを用いて評価します.さらに,クラスタリングやベクトルの可視化を体験します.
ノック内容
第10章では,前章に引き続き単語ベクトルの学習に取り組む.
学習の感想など
第9章と同じ内容をパッケージGensimを使って実行するのと、クラスタリング、可視化をします。オリジナルではGoogle社のword2vecを使うように指示がありますが、パッケージの更新頻度からGensimの方が優れていそうなので変えています。Gensimが第9章で作った内容より優れていてパッケージの素晴らしさが体感できます。
また、クラスタリング・次元削減による単語ベクトルの可視化方法も学びます。
| No. | 項目 | 学んだこと |
|---|---|---|
| 90 | word2vecによる学習 | word2vec, Gensim(Word2Vec, Text8Corpus, save, most_similar) |
| 91 | アナロジーデータの準備 | |
| 92 | アナロジーデータへの適用 | Gensim(load) |
| 93 | アナロジータスクの正解率の計算 | Pandas DataFrameの計算 |
| 94 | WordSimilarity-353での類似度計算 | |
| 95 | WordSimilarity-353での評価 | スピアマン相関係数, corr(Pandas) |
| 96 | 国名に関するベクトルの抽出 | |
| 97 | k-meansクラスタリング | 非階層型クラスタリング, K-Means, scikit-learn(KMeans, fit_predict) |
| 98 | Ward法によるクラスタリング | 階層型クラスタリング, Ward法, デンドログラム(樹形図), Scipy(linkage, dendrogram) |
| 99 | t-SNEによる可視化 | t-SNE, scikit-learn(TSNE), matplotlib(get_cmap, subplots, scatter, annotate) |
2020年版との差分
最後におまけです。ニューラルネットワークを強化しているのが2020年版ですね。以下が差分一覧です。いつか挑戦したらこの記事に結果のアップデートをしようかと考えています。
- 2015年版の「第6章: 英語テキストの処理」が消えた
- 2015年版の「第7章: データベース」が消えた
- 2015年版の「第9章: ベクトル空間法 (I)」と「第10章: ベクトル空間法 (II)」が合体して1つの章になる
- 2020年版に「第8章: ニューラルネットワーク」が新設
- 2020年版に「第9章: RNN, CNN, アテンション」が新設
- 2020年版に「第10章: エンコーダ・デコーダ」が新設