言語処理100本ノック 2015「第4章: 形態素解析」の30本目「形態素解析結果の読み込み」記録です。
「形態素解析」の章に入り、本格的な言語処理っぽくなってきました。形態素解析は「お待ちしております」のような文を「お待ち」「し」「て」「おり」「ます」に分割し、それぞれに品詞などの情報を加えるやつです。詳しくは「Wikipedia」などを参照ください。
参考リンク
| リンク | 備考 |
|---|---|
| 030.形態素解析結果の読み込み.ipynb | 回答プログラムのGitHubリンク |
| 素人の言語処理100本ノック:30 | 多くのソース部分のコピペ元 |
| MeCab公式 | 最初に見ておくMeCabのページ |
環境
今回からPython3.8.1を使っています(前回までは3.6.9)。第3章「正規表現」でcollections.OrderdDictを使って順序付き辞書型に対応していましたが、Python3.7.1以降では標準の辞書型でも順序保証をしてくれています。特に3.6.9に固執する理由もなかったので、環境を新しくしました。
MeCabのインストール方法は忘れました。1年前にインストールしたのですが、特に躓いた記憶がないです。
| 種類 | バージョン | 内容 |
|---|---|---|
| OS | Ubuntu18.04.01 LTS | 仮想で動かしています |
| pyenv | 1.2.16 | 複数Python環境を使うことがあるのでpyenv使っています |
| Python | 3.8.1 | pyenv上でpython3.8.1を使っています パッケージはvenvを使って管理しています |
| Mecab | 0.996-5 | apt-getでインストール |
上記環境で、以下のPython追加パッケージを使っています。通常のpipでインストールするだけです。
| 種類 | バージョン |
|---|---|
| pandas | 1.0.1 |
第4章: 形態素解析
学習内容
夏目漱石の小説『吾輩は猫である』に形態素解析器MeCabを適用し,小説中の単語の統計を求めます.
形態素解析, MeCab, 品詞, 出現頻度, Zipfの法則, matplotlib, Gnuplot
ノック内容
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をMeCabを使って形態素解析し,その結果をneko.txt.mecabというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
なお,問題37, 38, 39はmatplotlibもしくはGnuplotを用いるとよい.
30. 形態素解析結果の読み込み
形態素解析結果(neko.txt.mecab)を読み込むプログラムを実装せよ.ただし,各形態素は表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をキーとするマッピング型に格納し,1文を形態素(マッピング型)のリストとして表現せよ.第4章の残りの問題では,ここで作ったプログラムを活用せよ.
課題補足(「MeCab」について)
形態素解析の定番である「MeCab」です。その他形態素解析器との比較として、記事「2019年末版 形態素解析器の比較」を参考にしました(比較した結果「MeCab」でやろうと考えました)。
MeCabを使うと分割した字句に対して以下のフォーマットで情報を判断してくれます。区切り文字がタブ(\t)とカンマがあるのが注意点です(なぜなのでしょう?)。
表層形\t品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音
例えば「すもももももももものうち」の場合は以下の出力結果となります。
| No | 表層形 | 品詞 | 品詞細分類1 | 品詞細分類2 | 品詞細分類3 | 活用型 | 活用形 | 原形 | 読み | 発音 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | すもも | 名詞 | 一般 | * | * | * | * | すもも | スモモ | スモモ |
| 2 | も | 助詞 | 係助詞 | * | * | * | * | も | モ | モ |
| 3 | もも | 名詞 | 一般 | * | * | * | * | もも | モモ | モモ |
| 4 | も | 助詞 | 係助詞 | * | * | * | * | も | モ | モ |
| 5 | もも | 名詞 | 一般 | * | * | * | * | もも | モモ | モモ |
| 6 | の | 助詞 | 連体化 | * | * | * | * | の | ノ | ノ |
| 7 | うち | 名詞 | 非自立 | 副詞可能 | * | * | * | うち | ウチ | ウチ |
| 8 | EOS |
回答
回答プログラム(MeCab実行) 第4章_ 形態素解析.ipynb
第4章の前提となる以下のMeCab実行部分です。
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をMeCabを使って形態素解析し,その結果をneko.txt.mecabというファイルに保存せよ
コマンド1つで終わる簡単な処理です。
mecab neko.txt -o neko.txt.mecab
一応、Pythonでも以下のようにmecab-python3(ver0.996.3)を使ってプログラムを作成したのですが、コマンド実行時と結果が微妙に異なります。EOS(End Of Statement)で文が区切れていなかったのが後続のノックに対して致命的でした。オプションの指定方法などが悪いのかもしれませんが、あまり突き詰めたい内容でもないのでPythonプログラムの実行結果は後続で利用していていません。
import MeCab
mecab = MeCab.Tagger()
with open('./neko.txt') as in_file, \
open('./neko.txt.mecab', mode='w') as out_file:
out_file.write(mecab.parse(in_file.read()))
回答プログラム(リスト作成) 030.形態素解析結果の読み込み.ipynb
from pprint import pprint
import pandas as pd
def read_text():
# 0:表層形(surface)
# 1:品詞(pos)
# 2:品詞細分類1(pos1)
# 7:基本形(base)
df = pd.read_table('./neko.txt.mecab', sep='\t|,', header=None,
usecols=[0, 1, 2, 7], names=['surface', 'pos', 'pos1', 'base'],
skiprows=4, skipfooter=1 ,engine='python')
# 本当は空白はpos1だが、ずれてしまっている
return df[df['pos'] != '空白']
df = read_text()
print(df.info())
target = []
morphemes = []
for i, row in df.iterrows():
if row['surface'] == 'EOS' \
and len(target) != 0:
morphemes.append(df.loc[target].to_dict(orient='records'))
target = []
else:
target.append(i)
print(len(morphemes))
pprint(morphemes[:5])
回答解説
ファイル読込部
MeCabが作成したファイルをread_tableで読み込んでいます。区切り文字がタブ(\t)とカンマ(,)なのが少し面倒です。パラメータsepで正規表現(|でOR)を使い、engineを'python'にすることで実現しています。
skiprowsとskipfooterはファイルの中身を見て邪魔だったので設定しました。
def read_text():
# 0:表層形(surface)
# 1:品詞(pos)
# 2:品詞細分類1(pos1)
# 7:基本形(base)
df = pd.read_table('./neko.txt.mecab', sep='\t|,', header=None,
usecols=[0, 1, 2, 7], names=['surface', 'pos', 'pos1', 'base'],
skiprows=4, skipfooter=1 ,engine='python')
return df
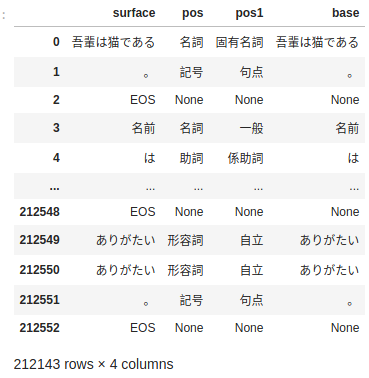
データフレームは以下の情報です。
空白に関するread_table問題
わかりにくいですが、以下のような (半角スペース)が行頭に来る場合、read_table関数で読込時に列がずれます。 と\t(タブ)を無視し、1列目が「記号」と認識されます。パラメータskipinitialspaceを設定したりと、いくつか試行錯誤をしましたが解決できませんでした。おそらく、pandasのバグではないかと考えています。
今回は特にこだわる必要がなかったので、「空白」行を対象外としています。
記号,空白,*,*,*,*, , ,
DataFrame情報
読み込んだファイルのDataFrameとしての情報をdf.info()で出力すると以下のとおりです。
<class 'pandas.core.frame.DataFrame'>
Int64Index: 212143 entries, 0 to 212552
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 surface 212143 non-null object
1 pos 202182 non-null object
2 pos1 202182 non-null object
3 base 202182 non-null object
dtypes: object(4)
memory usage: 8.1+ MB
None
辞書型リスト出力
各形態素は表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をキーとするマッピング型に格納し,1文を形態素(マッピング型)のリストとして表現せよ
マッピング型(辞書型)のリストにします。ですが、私は以降のノックでは使っておらず完全にPython練習用です(以降のノックではpandas使うとこんな面倒な処理いらないです)。
EOS(End Of Statement)が出た場合に1文の終わりなので、それまでの形態素をto_dict関数で出力します。
target = []
morphemes = []
for i, row in df.iterrows():
if row['surface'] == 'EOS' \
and len(target) != 0:
morphemes.append(df.loc[target].to_dict(orient='records'))
target = []
else:
target.append(i)
出力結果(実行結果)
プログラム実行すると以下の結果が出力されます(先頭5文のみ)。ちなみに1行目の「吾輩は猫である」が名詞なのは、書籍タイトルの固有名詞となっているからです。本の中の文としては分解されるのが正しいですが、そこまではできていないです。
[[{'base': '吾輩は猫である', 'pos': '名詞', 'pos1': '固有名詞', 'surface': '吾輩は猫である'},
{'base': '。', 'pos': '記号', 'pos1': '句点', 'surface': '。'}],
[{'base': '名前', 'pos': '名詞', 'pos1': '一般', 'surface': '名前'},
{'base': 'は', 'pos': '助詞', 'pos1': '係助詞', 'surface': 'は'},
{'base': 'まだ', 'pos': '副詞', 'pos1': '助詞類接続', 'surface': 'まだ'},
{'base': '無い', 'pos': '形容詞', 'pos1': '自立', 'surface': '無い'},
{'base': '。', 'pos': '記号', 'pos1': '句点', 'surface': '。'}],
[{'base': None, 'pos': None, 'pos1': None, 'surface': 'EOS'},
{'base': 'どこ', 'pos': '名詞', 'pos1': '代名詞', 'surface': 'どこ'},
{'base': 'で', 'pos': '助詞', 'pos1': '格助詞', 'surface': 'で'},
{'base': '生れる', 'pos': '動詞', 'pos1': '自立', 'surface': '生れ'},
{'base': 'た', 'pos': '助動詞', 'pos1': '*', 'surface': 'た'},
{'base': '火遁', 'pos': '名詞', 'pos1': '一般', 'surface': 'かとん'},
{'base': 'と', 'pos': '助詞', 'pos1': '格助詞', 'surface': 'と'},
{'base': '見当', 'pos': '名詞', 'pos1': 'サ変接続', 'surface': '見当'},
{'base': 'が', 'pos': '助詞', 'pos1': '格助詞', 'surface': 'が'},
{'base': 'つく', 'pos': '動詞', 'pos1': '自立', 'surface': 'つか'},
{'base': 'ぬ', 'pos': '助動詞', 'pos1': '*', 'surface': 'ぬ'},
{'base': '。', 'pos': '記号', 'pos1': '句点', 'surface': '。'}],
[{'base': '何', 'pos': '名詞', 'pos1': '代名詞', 'surface': '何'},
{'base': 'でも', 'pos': '助詞', 'pos1': '副助詞', 'surface': 'でも'},
{'base': '薄暗い', 'pos': '形容詞', 'pos1': '自立', 'surface': '薄暗い'},
{'base': 'じめじめ', 'pos': '副詞', 'pos1': '一般', 'surface': 'じめじめ'},
{'base': 'した', 'pos': '名詞', 'pos1': '一般', 'surface': 'した'},
{'base': '所', 'pos': '名詞', 'pos1': '接尾', 'surface': '所'},
{'base': 'で', 'pos': '助詞', 'pos1': '格助詞', 'surface': 'で'},
{'base': 'ニャーニャー', 'pos': '副詞', 'pos1': '一般', 'surface': 'ニャーニャー'},
{'base': '泣く', 'pos': '動詞', 'pos1': '自立', 'surface': '泣い'},
{'base': 'て', 'pos': '助詞', 'pos1': '接続助詞', 'surface': 'て'},
{'base': 'いた事', 'pos': '名詞', 'pos1': '一般', 'surface': 'いた事'},
{'base': 'だけ', 'pos': '助詞', 'pos1': '副助詞', 'surface': 'だけ'},
{'base': 'は', 'pos': '助詞', 'pos1': '係助詞', 'surface': 'は'},
{'base': '記憶', 'pos': '名詞', 'pos1': 'サ変接続', 'surface': '記憶'},
{'base': 'する', 'pos': '動詞', 'pos1': '自立', 'surface': 'し'},
{'base': 'て', 'pos': '助詞', 'pos1': '接続助詞', 'surface': 'て'},
{'base': 'いる', 'pos': '動詞', 'pos1': '非自立', 'surface': 'いる'},
{'base': '。', 'pos': '記号', 'pos1': '句点', 'surface': '。'}],
[{'base': '吾輩', 'pos': '名詞', 'pos1': '代名詞', 'surface': '吾輩'},
{'base': 'は', 'pos': '助詞', 'pos1': '係助詞', 'surface': 'は'},
{'base': 'ここ', 'pos': '名詞', 'pos1': '代名詞', 'surface': 'ここ'},
{'base': 'で', 'pos': '助詞', 'pos1': '格助詞', 'surface': 'で'},
{'base': '始める', 'pos': '動詞', 'pos1': '自立', 'surface': '始め'},
{'base': 'て', 'pos': '助詞', 'pos1': '接続助詞', 'surface': 'て'},
{'base': '人間', 'pos': '名詞', 'pos1': '一般', 'surface': '人間'},
{'base': 'という', 'pos': '助詞', 'pos1': '格助詞', 'surface': 'という'},
{'base': 'もの', 'pos': '名詞', 'pos1': '非自立', 'surface': 'もの'},
{'base': 'を', 'pos': '助詞', 'pos1': '格助詞', 'surface': 'を'},
{'base': '見る', 'pos': '動詞', 'pos1': '自立', 'surface': '見'},
{'base': 'た', 'pos': '助動詞', 'pos1': '*', 'surface': 'た'},
{'base': '。', 'pos': '記号', 'pos1': '句点', 'surface': '。'}]]