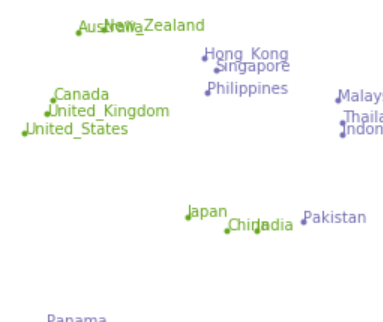
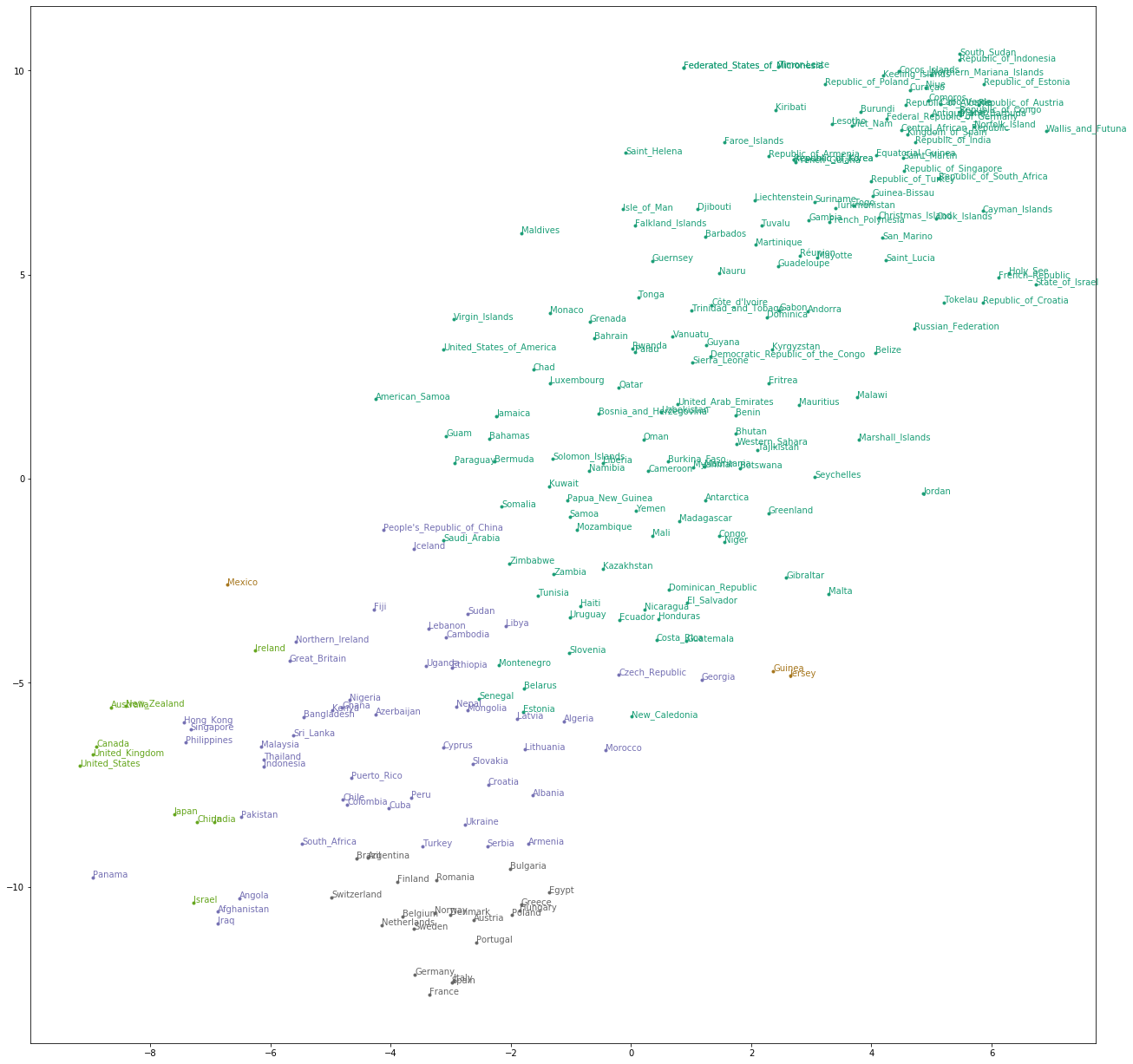
言語処理100本ノック 2015の99本目「t-SNEによる可視化」の記録です。
t-SNE(t-distributed Stochastic Neighbor Embedding)で2次元に削減をして単語ベクトルを下図のように可視化します。2次元や3次元なら人間が見てわかりますね。
参考リンク
| リンク | 備考 |
|---|---|
| 099.t-SNEによる可視化.ipynb | 回答プログラムのGitHubリンク |
| 素人の言語処理100本ノック:99 | 言語処理100本ノックで常にお世話になっています |
| 早く知っておきたかったmatplotlibの基礎知識、あるいは見た目の調整が捗るArtistの話 | 今更ながらにMatplotlibの基本を少し覚えました |
| color example code: colormaps_reference.py | MatplotlibのColor Map |
環境
| 種類 | バージョン | 内容 |
|---|---|---|
| OS | Ubuntu18.04.01 LTS | 仮想で動かしています |
| pyenv | 1.2.15 | 複数Python環境を使うことがあるのでpyenv使っています |
| Python | 3.6.9 | pyenv上でpython3.6.9を使っています 3.7や3.8系を使っていないことに深い理由はありません パッケージはvenvを使って管理しています |
上記環境で、以下のPython追加パッケージを使っています。通常のpipでインストールするだけです。
| 種類 | バージョン |
|---|---|
| matplotlib | 3.1.1 |
| pandas | 0.25.3 |
| scikit-learn | 0.21.3 |
課題
第10章: ベクトル空間法 (II)
第10章では,前章に引き続き単語ベクトルの学習に取り組む.
99. t-SNEによる可視化
96の単語ベクトルに対して,ベクトル空間をt-SNEで可視化せよ.
課題補足(t-SNE)
t-SNE(t-distributed Stochastic Neighbor Embedding)は次元を2または3に削減します。次元削減という意味では、PCA(主成分分析)と同じです。ただ、PCAでできない非線形構造をもつデータにも対応可能です。偉そうに書いていますが、数式を理解しておらず記事「t-SNEによるイケてる次元圧縮&可視化」の受け売りです。
回答
回答プログラム 099.t-SNEによる可視化.ipynb
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
country_vec = pd.read_pickle('./096.country_vector.zip')
print(country_vec.info())
# t-SNE
t_sne = TSNE().fit_transform(country_vec)
print('t_sne shape:', t_sne.shape)
# KMeansクラスタリング
clustered = KMeans(n_clusters=5).fit_predict(country_vec)
fig, ax = plt.subplots(figsize=(22, 22))
# Set Color map
cmap = plt.get_cmap('Dark2')
for i in range(t_sne.shape[0]):
cval = cmap(clustered[i] / 4)
ax.scatter(t_sne[i][0], t_sne[i][1], marker='.', color=cval)
ax.annotate(country_vec.index[i], xy=(t_sne[i][0], t_sne[i][1]), color=cval)
plt.show()
回答解説
全体の8割近くは記事「素人の言語処理100本ノック:99」のコピペです。
ここが、今回のメインのコードです。scikt-learnのTSNEはいくつかパラメータがあるのですが、デフォルトのままで実行しました。scikt-learnのTSNEはあまりよくないと言及しているブログもありましたが、とりあえず気にせず行きます。
t_sne = TSNE().fit_transform(country_vec)
あと、散布図で表示する色としてK-Meanで非階層クラスタリングをしています。
clustered = KMeans(n_clusters=5).fit_predict(country_vec)
最後にmatplotlibで散布図表示です。plt.get_cmapを使って表示色定義をしていて、どんな色かはcolor example code: colormaps_reference.pyに情報があります。
scatterで点を表示し、annotateでラベル(国名)を表示しています。
※今更恥ずかしながらmatplotlibの基本を、少しだけ記事「早く知っておきたかったmatplotlibの基礎知識、あるいは見た目の調整が捗るArtistの話」で理解しました。
fig, ax = plt.subplots(figsize=(22, 22))
# Set Color map
cmap = plt.get_cmap('Dark2')
for i in range(t_sne.shape[0]):
cval = cmap(clustered[i] / 4)
ax.scatter(t_sne[i][0], t_sne[i][1], marker='.', color=cval)
ax.annotate(country_vec.index[i], xy=(t_sne[i][0], t_sne[i][1]), color=cval)
plt.show()
日本のあたりを拡大して見るとこんな感じです。前回ノックでやった階層的クラスタリングより、わかりやすいです。