言語処理100本ノック 2015「第6章: 英語テキストの処理」の57本目「係り受け解析」記録です。
「言語処理100本ノック-44:係り受け木の可視化」でやった内容のStanford CoreNLP版ですね。かなりのコードを流用しています。
参考リンク
| リンク | 備考 |
|---|---|
| 057.係り受け解析.ipynb | 回答プログラムのGitHubリンク |
| 素人の言語処理100本ノック:57 | 多くのソース部分のコピペ元 |
| Stanford Core NLP公式 | 最初に見ておくStanford Core NLPのページ |
環境
| 種類 | バージョン | 内容 |
|---|---|---|
| OS | Ubuntu18.04.01 LTS | 仮想で動かしています |
| pyenv | 1.2.16 | 複数Python環境を使うことがあるのでpyenv使っています |
| Python | 3.8.1 | pyenv上でpython3.8.1を使っています パッケージはvenvを使って管理しています |
| Stanford CoreNLP | 3.9.2 | インストールしたのが1年前で詳しく覚えていないです・・・ 1年たってもそれが最新だったのでそのまま使いました |
| openJDK | 1.8.0_242 | 他目的でインストールしていたJDKをそのまま使いました |
上記環境で、以下のPython追加パッケージを使っています。通常のpipでインストールするだけです。
| 種類 | バージョン |
|---|---|
| pydot | 1.4.1 |
第6章: 英語テキストの処理
学習内容
Stanford Core NLPを用いた英語のテキスト処理を通じて,自然言語処理の様々な基盤技術を概観します.
Stanford Core NLP, ステミング, 品詞タグ付け, 固有表現抽出, 共参照解析, 係り受け解析, 句構造解析, S式
ノック内容
英語のテキスト(nlp.txt)に対して,以下の処理を実行せよ.
57. 係り受け解析
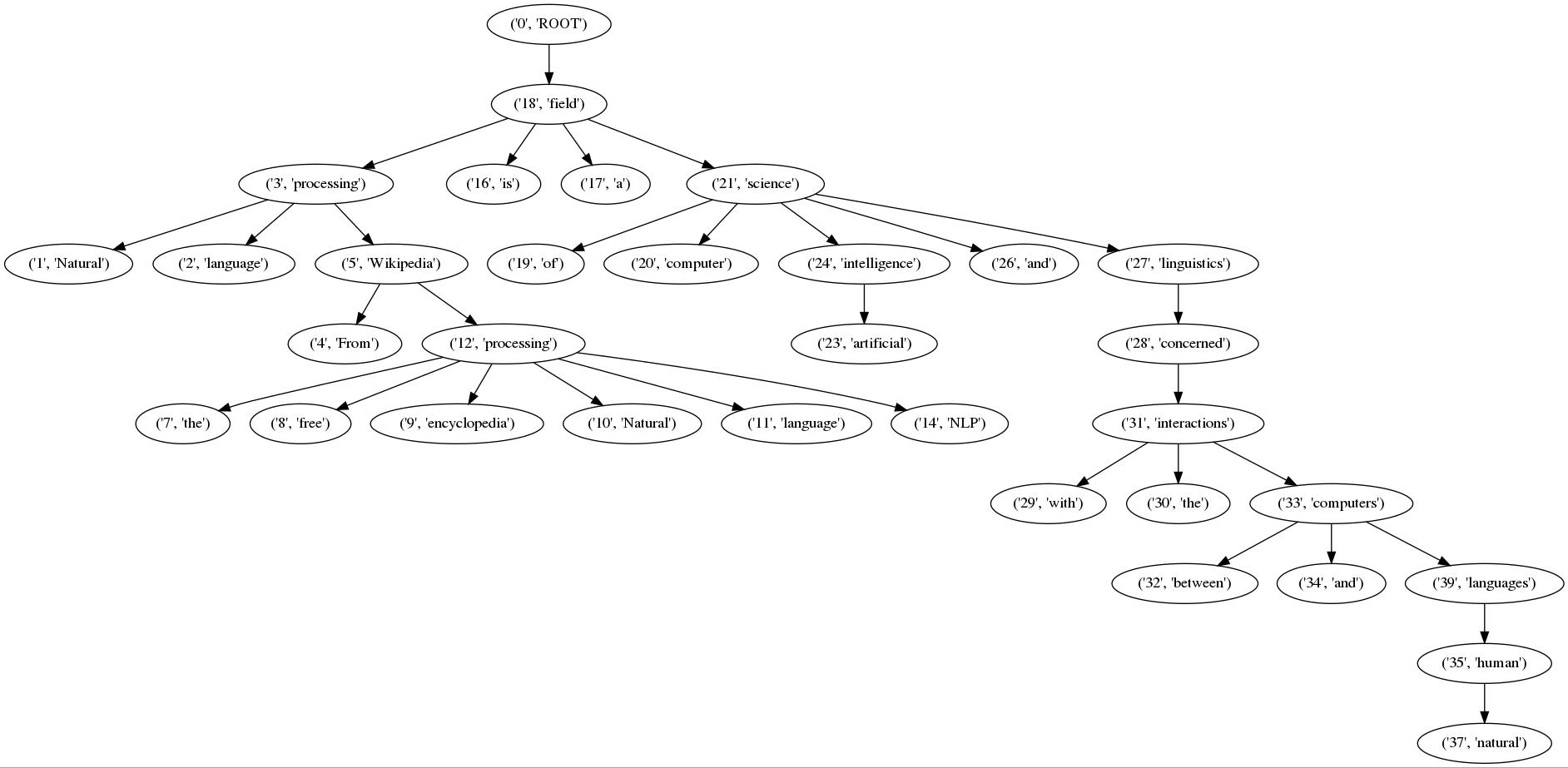
Stanford Core NLPの係り受け解析の結果(collapsed-dependencies)を有向グラフとして可視化せよ.可視化には,係り受け木をDOT言語に変換し,Graphvizを用いるとよい.また,Pythonから有向グラフを直接的に可視化するには,pydotを使うとよい.
課題補足(「係り受け」について)
係り受けはStanford CoreNLP(英語?)では"Dependencies"と呼ばれ、Stanford CoreNLPの仕組みはStanford Dependenciesに載っています。
どうも2種類あるらしく、今回対象とするのはcollapsed-dependenciesの方です。

やった後に気づきたのですが、有向グラフでエッジ間の関係性(prep_onとか)を追加で書き込めばもっとわかりやすかったです。
回答
回答プログラム 057.係り受け解析.ipynb
import xml.etree.ElementTree as ET
import pydot
for i, sentence in enumerate(ET.parse('./nlp.txt.xml').iterfind('./document/sentences/sentence')):
edges = []
for dependency in sentence.iterfind('./dependencies[@type="collapsed-dependencies"]/dep'):
# 句読点除外
if dependency.get('type') != 'punct':
governor = dependency.find('./governor')
dependent = dependency.find('./dependent')
edges.append(((governor.get('idx'), governor.text),
(dependent.get('idx'), dependent.text)))
if len(edges) > 0:
graph = pydot.graph_from_edges(edges, directed=True)
graph.write_jpeg('057.graph_{}.jpeg'.format(i))
if i > 5:
break
回答解説
XMLファイルのパス
以下のXMLファイルのパスと目的とする係り元、係り先のマッピングです。第5階層のdependenciesタグは属性typeがcollapsed-dependenciesのものを対象とします。
| 出力 | 第1階層 | 第2階層 | 第3階層 | 第4階層 | 第5階層 | 第6階層 | 第7階層 |
|---|---|---|---|---|---|---|---|
| 係り元 | root | document | sentences | sentence | dependencies | dep | governor |
| 係り先 | root | document | sentences | sentence | dependencies | dep | dependent |
XMLファイルはGitHubに置いています。
<root>
<document>
<docId>nlp.txt</docId>
<sentences>
<sentence id="1">
--中略--
<dependencies type="collapsed-dependencies">
<dep type="root">
<governor idx="0">ROOT</governor>
<dependent idx="18">field</dependent>
</dep>
<dep type="amod">
<governor idx="3">processing</governor>
<dependent idx="1">Natural</dependent>
</dep>
<dep type="compound">
<governor idx="3">processing</governor>
<dependent idx="2">language</dependent>
</dep>
Pydotを使った有向グラフ表示
以下のコード部分です。やっていることは、「言語処理100本ノック-44:係り受け木の可視化」と同じなので解説しません。ただ、エッジ間の関係性をGraphvizやnetworkxを使って追加すればよかったと、後悔しています。
記事「networkxでマルチグラフとか、綺麗なグラフを書く【python】」や記事「Python上でGraphvizを使って綺麗なグラフを描く」あたりを参考にすれば書けそう。
そもそもpydotは、2018年12月から更新されていないので今後も続くのか心配です。
for i, sentence in enumerate(ET.parse('./nlp.txt.xml').iterfind('./document/sentences/sentence')):
edges = []
for dependency in sentence.iterfind('./dependencies[@type="collapsed-dependencies"]/dep'):
# 句読点除外
if dependency.get('type') != 'punct':
governor = dependency.find('./governor')
dependent = dependency.find('./dependent')
edges.append(((governor.get('idx'), governor.text),
(dependent.get('idx'), dependent.text)))
if len(edges) > 0:
graph = pydot.graph_from_edges(edges, directed=True)
graph.write_jpeg('057.graph_{}.jpeg'.format(i))
出力結果(実行結果)
プログラム実行すると以下の結果が出力されます(最初の3文のみ)。