言語処理100本ノック 2015「第5章: 係り受け解析」の44本目「係り受け木の可視化」記録です。
可視化をすることで文書がどう係り受けをしているかが非常にわかりやすいです。係り受けを可視化すると記事「滝沢カレンの理解不能な文章を言語解析してみた。」にあるような素敵なこともできます。
参考リンク
| リンク | 備考 |
|---|---|
| 044.係り受け木の可視化.ipynb | 回答プログラムのGitHubリンク |
| 素人の言語処理100本ノック:44 | 多くのソース部分のコピペ元 |
| CaboCha公式 | 最初に見ておくCaboChaのページ |
環境
CRF++とCaboChaはインストールしたのが昔すぎてインストール方法忘れました。全然更新されていないパッケージなので、環境再構築もしていません。CaboChaをWindowsで使おうと思い、挫折した記憶だけはあります。確か64bitのWindowsで使えなかった気がします(記憶が曖昧だし私の技術力の問題も多分にあるかも)。
| 種類 | バージョン | 内容 |
|---|---|---|
| OS | Ubuntu18.04.01 LTS | 仮想で動かしています |
| pyenv | 1.2.16 | 複数Python環境を使うことがあるのでpyenv使っています |
| Python | 3.8.1 | pyenv上でpython3.8.1を使っています パッケージはvenvを使って管理しています |
| Mecab | 0.996-5 | apt-getでインストール |
| CRF++ | 0.58 | 昔すぎてインストール方法忘れました(多分make install) |
| CaboCha | 0.69 | 昔すぎてインストール方法忘れました(多分make install) |
上記環境で、以下のPython追加パッケージを使っています。通常のpipでインストールするだけです。
| 種類 | バージョン |
|---|---|
| pydot | 1.4.1 |
第5章: 係り受け解析
学習内容
『吾輩は猫である』に係り受け解析器CaboChaを適用し,係り受け木の操作と統語的な分析を体験します.
ノック内容
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をCaboChaを使って係り受け解析し,その結果をneko.txt.cabochaというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
44. 係り受け木の可視化
与えられた文の係り受け木を有向グラフとして可視化せよ.可視化には,係り受け木をDOT言語に変換し,Graphvizを用いるとよい.また,Pythonから有向グラフを直接的に可視化するには,pydotを使うとよい.
課題補足(「可視化と有向グラフ」について)
可視化
どうも可視化には2種類あるようです。1つ目の方法は無視しています。1つ目の方法が簡単かどうかも調べていません。私のノックで常に参考にしている「素人の言語処理100本ノック:44」で使っていなかったからという、どうでもいい理由です。
今回は以下の方法を使いました。これだと、pydotをpipでインストールし、Python内で関数にわたすだけでOKです。
また,Pythonから有向グラフを直接的に可視化するには,pydotを使うとよい.
有向グラフ
まず、グラフ理論というものがありまして
グラフ理論(グラフりろん、英: Graph theory、図論)は、ノード(節点・頂点)の集合とエッジ(枝・辺)の集合で構成されるグラフに関する数学の理論である。
以下のような有向グラフと無効グラフの定義がざっくりとあります(「有向グラフ」は方向あり)。詳しくはリンク先を追ってみてください。
つながり方だけではなく「どちらからどちらにつながっているか」をも問題にする場合、エッジに矢印をつける。このようなグラフを有向グラフ、または、ダイグラフという。矢印のないグラフは、無向グラフという。
回答
回答プログラム 044.係り受け木の可視化.ipynb
import re
from subprocess import run, PIPE
import pydot
# 区切り文字
separator = re.compile('\t|,')
# 係り受け
dependancy = re.compile(r'''(?:\*\s\d+\s) # キャプチャ対象外
(-?\d+) # 数字(係り先)
''', re.VERBOSE)
text = input('テキスト入力してください')
# 初期値
if len(text) == 0:
text = '言ってあったか言ってなかったかどっちだったかちゃんと覚えていないけど、確かこの間手巻きパーティをやった時にちょこっと言った気がしなくもなきにしもあらずで多分言ったんじゃないかな、とココまで考えてみたけど、まあ言ってようが言っていまいがそこまで問題ないよね、と思うに至った次第です。'
cmd = 'echo {} | cabocha -f1'.format(text)
proc = run(cmd, shell=True, stdout=PIPE, stderr=PIPE)
print(proc.stdout.decode('UTF-8'))
class Chunk:
def __init__(self, phrase, dst):
self.phrase = phrase
self.dst = dst # 係り先文節インデックス番号
phrase = ''
chunks = []
for line in proc.stdout.decode('UTF-8').splitlines():
dependancies = dependancy.match(line)
# EOSまたは係り受け解析結果でない場合(EOSに改行はつかない点に注意)
if not (line == 'EOS' or dependancies):
#タブとカンマで分割
cols = separator.split(line)
phrase += cols[0] # 表層形(surface)
# EOSまたは係り受け解析結果で、形態素解析結果がある場合
elif phrase != '':
chunks.append(Chunk(phrase, dst))
phrase = ''
# 係り受け結果の場合
if dependancies:
dst = int(dependancies.group(1))
# 係り先があるものをpydotに渡す形式に変更
edges = []
for i, chunk in enumerate(chunks):
if chunk.dst != -1 and \
chunk.phrase != '' and \
chunks[chunk.dst].phrase != '':
edges.append(((i, chunk.phrase), (chunk.dst, chunks[chunk.dst].phrase)))
# pydotで有向グラフとして画像保存
if len(edges) > 0:
graph = pydot.graph_from_edges(edges, directed=True)
graph.write_png('044.dot.png')
回答解説
テキスト入力
ノックの「与えられた文の」部分はinput関数で与えています(出題意図に則しているのかな?)。何も入れなかった場合は、初期値を使います。
text = input('テキスト入力してください')
# 初期値
if len(text) == 0:
text = '言ってあったか言ってなかったかどっちだったかちゃんと覚えていないけど、確かこの間手巻きパーティをやった時にちょこっと言った気がしなくもなきにしもあらずで多分言ったんじゃないかな、とココまで考えてみたけど、まあ言ってようが言っていまいがそこまで問題ないよね、と思うに至った次第です。'
CaboCha実行部分
CaboCha実行部分はパッケージsubprocessの関数runを使ってシェル実行しています。CaboChaのPythonラッパー使わなかったのは、純粋に面倒だったからです。
cmd = 'echo {} | cabocha -f1'.format(text)
proc = run(cmd, shell=True, stdout=PIPE, stderr=PIPE)
print(proc.stdout.decode('UTF-8'))
print関数で出力した内容の最初の方は以下のようになっています。
* 0 1D 0/4 0.285960
言っ 動詞,自立,*,*,五段・ワ行促音便,連用タ接続,言う,イッ,イッ
て 助詞,接続助詞,*,*,*,*,て,テ,テ
あっ 動詞,非自立,*,*,五段・ラ行,連用タ接続,ある,アッ,アッ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
か 助詞,副助詞/並立助詞/終助詞,*,*,*,*,か,カ,カ
* 1 4D 0/4 2.230543
言っ 動詞,自立,*,*,五段・ワ行促音便,連用タ接続,言う,イッ,イッ
て 動詞,非自立,*,*,一段,未然形,てる,テ,テ
なかっ 助動詞,*,*,*,特殊・ナイ,連用タ接続,ない,ナカッ,ナカッ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
か 助詞,副助詞/並立助詞/終助詞,*,*,*,*,か,カ,カ
* 2 4D 0/3 2.418727
どっち 名詞,代名詞,一般,*,*,*,どっち,ドッチ,ドッチ
だっ 助動詞,*,*,*,特殊・ダ,連用タ接続,だ,ダッ,ダッ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
か 助詞,副助詞/並立助詞/終助詞,*,*,*,*,か,カ,カ
# 係り先があるものをpydotに渡す形式に変更
edges = []
for i, chunk in enumerate(chunks):
if chunk.dst != -1 and \
chunk.phrase != '' and \
chunks[chunk.dst].phrase != '':
edges.append(((i, chunk.phrase), (chunk.dst, chunks[chunk.dst].phrase)))
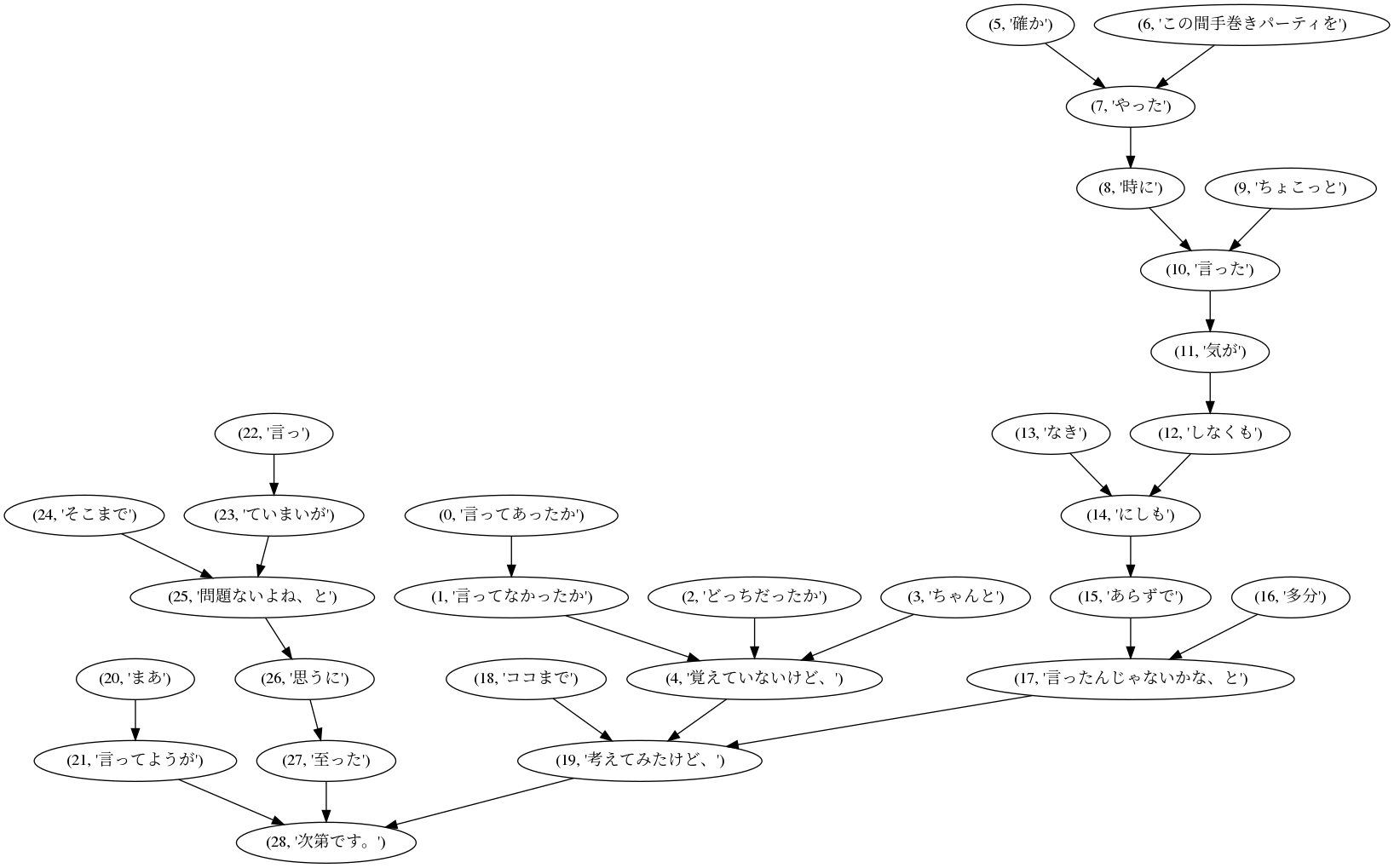
ちなみにedgesはこんな中身になっています。
((0, '言ってあったか'), (1, '言ってなかったか'))
((1, '言ってなかったか'), (4, '覚えていないけど、'))
((2, 'どっちだったか'), (4, '覚えていないけど、'))
((3, 'ちゃんと'), (4, '覚えていないけど、'))
((4, '覚えていないけど、'), (19, '考えてみたけど、'))
((5, '確か'), (7, 'やった'))
((6, 'この間手巻きパーティを'), (7, 'やった'))
((7, 'やった'), (8, '時に'))
((8, '時に'), (10, '言った'))
((9, 'ちょこっと'), (10, '言った'))
((10, '言った'), (11, '気が'))
((11, '気が'), (12, 'しなくも'))
((12, 'しなくも'), (14, 'にしも'))
((13, 'なき'), (14, 'にしも'))
((14, 'にしも'), (15, 'あらずで'))
((15, 'あらずで'), (17, '言ったんじゃないかな、と'))
((16, '多分'), (17, '言ったんじゃないかな、と'))
((17, '言ったんじゃないかな、と'), (19, '考えてみたけど、'))
((18, 'ココまで'), (19, '考えてみたけど、'))
((19, '考えてみたけど、'), (28, '次第です。'))
((20, 'まあ'), (21, '言ってようが'))
((21, '言ってようが'), (28, '次第です。'))
((22, '言っ'), (23, 'ていまいが'))
((23, 'ていまいが'), (25, '問題ないよね、と'))
((24, 'そこまで'), (25, '問題ないよね、と'))
((25, '問題ないよね、と'), (26, '思うに'))
((26, '思うに'), (27, '至った'))
((27, '至った'), (28, '次第です。'))
有向グラフ化
最後にgraph_from_edges関数で有効グラフ化してwrite_png関数で画像保存です。有向グラフ化時にdirected=Trueにすることで分節間の線が矢印になります。
# pydotで有向グラフとして画像保存
if len(edges) > 0:
graph = pydot.graph_from_edges(edges, directed=True)
graph.write_png('044.dot.png')
出力結果(実行結果)
プログラム実行すると以下の結果が出力されます。
ちなみにこの文書の元ネタです。記事「【お遊び】シンカリオンのトンデモメールを構文解析」の内容です。
