新幹線変形ロボ シンカリオンというアニメで印象的だった以下のようなメールの一文がありました。

言ってあったか言ってなかったかどっちだったかちゃんと覚えていないけど、確かこの間手巻きパーティをやった時にちょこっと言った気がしなくもなきにしもあらずで多分言ったんじゃないかな、とココまで考えてみたけど、まあ言ってようが言っていまいがそこまで問題ないよね、と思うに至った次第です。
このメールは、アニメで1秒程度しか出ておらず、制作スタッフの遊び心が満載の文です![]()
今回はその文をCabochaを使って構文解析してpydotで表示しました。
やっていることは記事「滝沢カレンの理解不能な文章を言語解析してみた。」の二番煎じです。
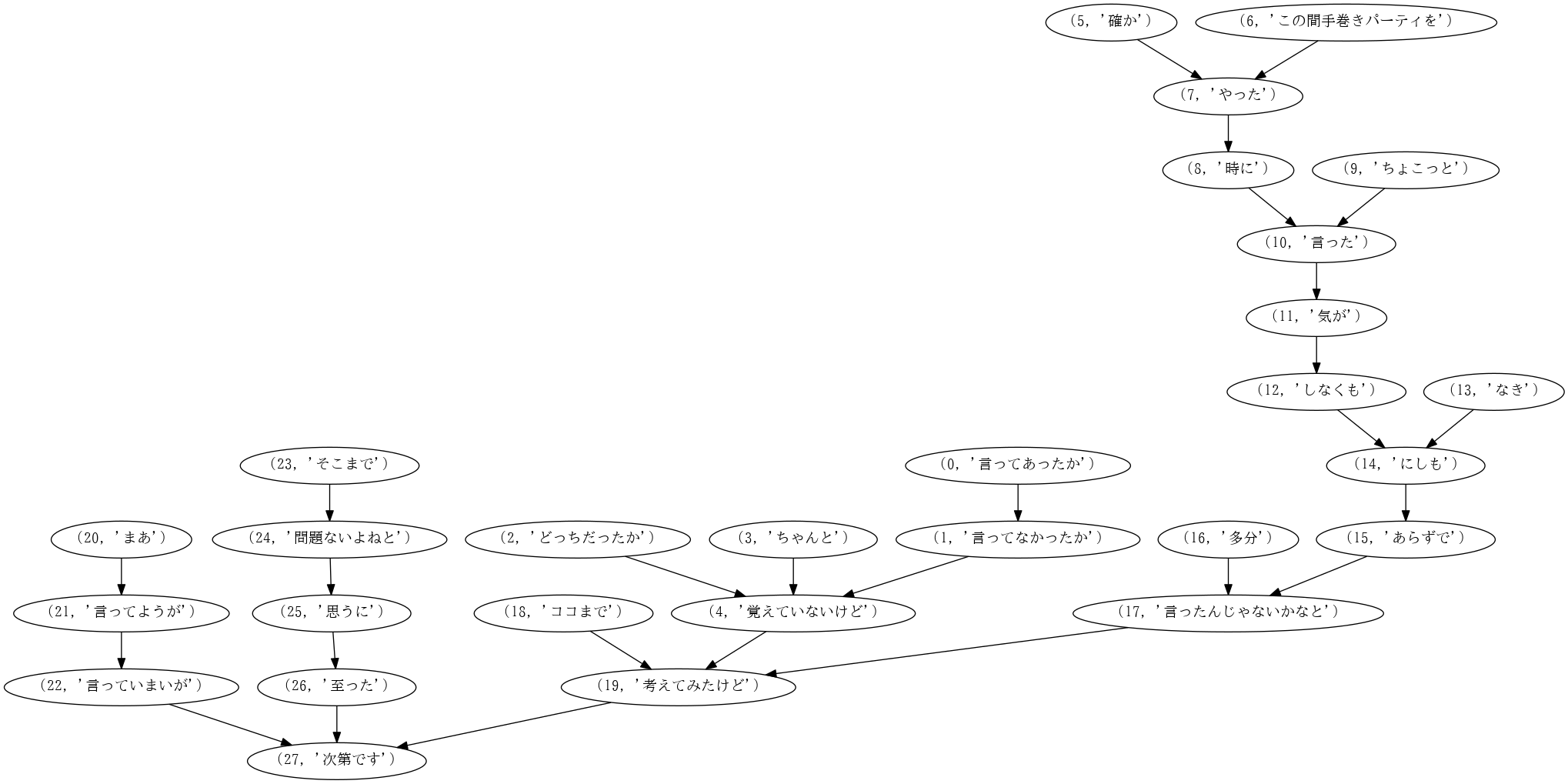
構文解析結果
長文だけあって大きい・・・ 思ったよりもよく解析できています。見れば見るほどひどい文ですね。
ソース
Pythonで書いています。言語処理100本ノックの合間にちょっとした息抜きで作りました。そのプログラムの流用なので、少し無駄な部分があります。記事「素人の言語処理100本ノック:44」を参考にさせていただいています。
import re, CaboCha, pydot
class Morph:
def __init__(self, surface, pos):
self.surface = surface # 表層形(surface)
self.pos = pos # 品詞(pos)
class Chunk:
def __init__(self):
self.morphs = []
self.srcs = [] # 係り元文節インデックス番号のリスト
self.dst = -1 # 係り先文節インデックス番号(初期値:-1, 係り先がない場合は-1のまま)
def output_surface(self):
surface = ''
for morph in self.morphs:
# 記号を除外
if morph.pos != '記号':
surface += morph.surface
return surface
def parse_lines(tree_list):
chunks = dict() # idxをkeyにChunkを格納
for line in tree_list:
if line[:3] == 'EOS':
# Chunkのリストを返す
if len(chunks) > 0:
# chunksをkeyでソートし、valueのみ取り出し
sorted_tuple = sorted(chunks.items(), key=lambda x: x[0])
return list(zip(*sorted_tuple))[1] #[1]がリストのvalue部分
chunks.clear()
else:
return []
# 先頭が*の行は係り受け解析結果なので、Chunkを作成
elif line[0] == '*':
# Chunkのインデックス番号と係り先のインデックス番号取得
cols = re.split('\s|D', line)
idx = int(cols[1]) # Chunkのインデックス番号
dst = int(cols[2]) # 係り先文節インデックス番号
# Chunkを生成(なければ)し、係り先のインデックス番号セット
if idx not in chunks:
chunks[idx] = Chunk()
chunks[idx].dst = dst
# 係り先のChunkを生成(なければ)し、係り元インデックス番号追加
if dst != -1:
if dst not in chunks:
chunks[dst] = Chunk()
chunks[dst].srcs.append(idx) # 係り元は複数あるのでappend
else:
#タブとカンマで分割
cols = re.split('\t|,', line)
chunks[idx].morphs.append(Morph(
cols[0], # 表層形(surface)
cols[1] # 品詞(pos)
))
# 構文解析
parser = CaboCha.Parser()
tree = parser.parse('言ってあったか言ってなかったかどっちだったかちゃんと覚えていないけど、確かこの間手巻きパーティをやった時にちょこっと言った気がしなくもなきにしもあらずで多分言ったんじゃないかな、とココまで考えてみたけど、まあ言ってようが言っていまいがそこまで問題ないよね、と思うに至った次第です。')
# tree = parser.parse('今日の天気は晴れでしたが、明日の天気は悪くなるそうです。')
# Stringのlistに分解
tree_string = tree.toString(CaboCha.FORMAT_LATTICE)
tree_list = tree_string.splitlines()
# 係り受けを整理
chunks = parse_lines(tree_list)
# 係り先があるものをpydotに渡す形式に変更
edges = []
for i, chunk in enumerate(chunks):
if chunk.dst != -1:
# 記号を除いた表層形をチェック、空なら除外
src = chunk.output_surface()
dst = chunks[chunk.dst].output_surface()
if src != '' and dst != '':
edges.append(((i, src), (chunk.dst, dst)))
# pydotで有向グラフとして画像保存
if len(edges) > 0:
graph = pydot.graph_from_edges(edges, directed=True)
graph.write_png('result.png')