言語処理100本ノック 2015の73本目「学習」の記録です。
調査や試行錯誤をしていたら、非常に時間をかかってしまいました。
今までは基本的に「素人の言語処理100本ノック」とほぼ同じ内容にしていたのでブロクに投稿していなかったのですが、「第8章: 機械学習」については、真剣に時間をかけて取り組んでいてある程度変えているので投稿します。scikit-learnをメインに使用します。
参考リンク
| リンク | 備考 |
|---|---|
| 073_1.学習(前処理).ipynb | 回答プログラム(前処理編)のGitHubリンク |
| 073_2.学習(訓練).ipynb | 回答プログラム(訓練編)のGitHubリンク |
| 素人の言語処理100本ノック:73 | 言語処理100本ノックで常にお世話になっています |
| 言語処理100本ノックでPython入門 #73 - 機械学習、scikit-learnでロジスティック回帰 | scikit-learn使ったノック結果 |
環境
| 種類 | バージョン | 内容 |
|---|---|---|
| OS | Ubuntu18.04.01 LTS | 仮想で動かしています |
| pyenv | 1.2.15 | 複数Python環境を使うことがあるのでpyenv使っています |
| Python | 3.6.9 | pyenv上でpython3.6.9を使っています 3.7や3.8系を使っていないことに深い理由はありません パッケージはvenvを使って管理しています |
上記環境で、以下のPython追加パッケージを使っています。通常のpipでインストールするだけです。
| 種類 | バージョン |
|---|---|
| nltk | 3.4.5 |
| stanfordnlp | 0.2.0 |
| pandas | 0.25.3 |
| scikit-learn | 0.21.3 |
課題
第8章: 機械学習
本章では,Bo Pang氏とLillian Lee氏が公開しているMovie Review Dataのsentence polarity dataset v1.0を用い,文を肯定的(ポジティブ)もしくは否定的(ネガティブ)に分類するタスク(極性分析)に取り組む.
73. 学習
72で抽出した素性を用いて,ロジスティック回帰モデルを学習せよ.
回答
回答前提
前提1: 前処理と学習にわける
ストップワードの除去やレンマ・ステミング処理にStanfordNLPを使っていて時間がかかるので、前処理と学習に分割しました。
前提2: 単語のベクトル化
単語のベクトル化にtf-idfを使っています。tf-idfはtf(Term Frequency、単語の出現頻度)とidf(Inverse Document Frequency、逆文書頻度)の二つの指標に基づいて重要度計算をします。多くの文書に出現する語(一般的な語)の重要度を下げ、特定の文書にしか出現しない単語の重要度を上げます。
前提3: ハイパーパラメータの探索
正直、ストップワード処理をしていてもtf-idfが有効か判断できなかったので、CountVectorizerを使った単純な単語出現頻度でのベクトル化と精度比較をしています。また、ロジスティクス回帰のハイパーパラメータもグリッドサーチで比較しています。
回答プログラム(抽出編) 073_1.学習(前処理).ipynb
まずは前処理編です。といっても、やっていることは前回の「回答プログラム(分析編) 072_2.素性抽出(分析).ipynb」とたいして変わらず、特筆することもありません。
処理に1時間ほどかかるのが難点です。
import warnings
import re
import csv
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer as PS
import stanfordnlp
# 速くするためにタプルとして定義
STOP_WORDS = set(stopwords.words('english'))
# Stemmer
ps = PS()
# Universal POS tags に準拠していそう
# https://universaldependencies.org/u/pos/
EXC_POS = {'PUNCT', # 句読点
'X', # その他
'SYM', # 記号
'PART', # 助詞('sなど)
'CCONJ', # 接続詞(andなど)
'AUX', # 助動詞(wouldなど)
'PRON', # 代名詞
'SCONJ', # 従位接続詞(whetherなど)
'ADP', # 接置詞(inなど)
'NUM'} # 番号
# プロセッサをデフォルトの全指定にすると遅かったので最低限に絞る
# https://stanfordnlp.github.io/stanfordnlp/processors.html
nlp = stanfordnlp.Pipeline(processors='tokenize,pos,lemma')
reg_sym = re.compile(r'^[!-/:-@[-`{-~]|[!-/:-@[-`{-~]$')
reg_dit = re.compile('[0-9]')
# 先頭と末尾の記号除去
def remove_symbols(lemma):
return reg_sym.sub('', lemma)
# ストップワード真偽判定
def is_stopword(word):
lemma = remove_symbols(word.lemma)
return True if lemma in STOP_WORDS \
or lemma == '' \
or word.upos in EXC_POS \
or len(lemma) == 1 \
or reg_dit.search(lemma)\
else False
# 警告非表示
warnings.simplefilter('ignore', UserWarning)
with open('./sentiment.txt') as file_in:
with open('./sentiment_stem.txt', 'w') as file_out:
writer = csv.writer(file_out, delimiter='\t')
writer.writerow(['Lable', 'Lemmas'])
for i, line in enumerate(file_in):
print("\r{0}".format(i), end="")
lemma = []
# 最初の3文字はネガポジを示すだけなのでnlp処理しない(少しでも速くする)
doc = nlp(line[3:])
for sentence in doc.sentences:
lemma.extend([ps.stem(remove_symbols(word.lemma)) for word in sentence.words if is_stopword(word) is False])
writer.writerow([1 if line[0] == '+' else 0, ' '.join(lemma)])
回答プログラム(訓練編) 073_2.学習(訓練).ipynb
今回の本題の訓練部分です。
import csv
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.base import BaseEstimator, TransformerMixin
# 単語ベクトル化をGridSearchCVで使うのためのクラス
class myVectorizer(BaseEstimator, TransformerMixin):
def __init__(self, method='tfidf', min_df=0.0005, max_df=0.10):
self.method = method
self.min_df = min_df
self.max_df = max_df
def fit(self, x, y=None):
if self.method == 'tfidf':
self.vectorizer = TfidfVectorizer(min_df=self.min_df, max_df=self.max_df)
else:
self.vectorizer = CountVectorizer(min_df=self.min_df, max_df=self.max_df)
self.vectorizer.fit(x)
return self
def transform(self, x, y=None):
return self.vectorizer.transform(x)
# GridSearchCV用パラメータ
PARAMETERS = [
{
'vectorizer__method':['tfidf', 'count'],
'vectorizer__min_df': [0.0004, 0.0005],
'vectorizer__max_df': [0.07, 0.10],
'classifier__C': [1, 3], #10も試したが遅いだけでSCORE低い
'classifier__solver': ['newton-cg', 'liblinear']},
]
# ファイル読込
def read_csv_column(col):
with open('./sentiment_stem.txt') as file:
reader = csv.reader(file, delimiter='\t')
header = next(reader)
return [row[col] for row in reader]
x_all = read_csv_column(1)
y_all = read_csv_column(0)
def train(x_train, y_train, file):
pipline = Pipeline([('vectorizer', myVectorizer()), ('classifier', LogisticRegression())])
# clf は classificationの略
clf = GridSearchCV(
pipline, #
PARAMETERS, # 最適化したいパラメータセット
cv = 5) # 交差検定の回数
clf.fit(x_train, y_train)
pd.DataFrame.from_dict(clf.cv_results_).to_csv(file)
print('Grid Search Best parameters:', clf.best_params_)
print('Grid Search Best validation score:', clf.best_score_)
print('Grid Search Best training score:', clf.best_estimator_.score(x_train, y_train))
train(x_all, y_all, 'gs_result.csv')
回答解説(訓練編)
単語ベクトル化
TfidfVectorizerまたはCountVectorizerを使った単語ベクトル化をしています。
GridSearchCV関数で使えるようにクラス化しているので、少しわかりにくいですが、重要なのは以下の箇所です。
def fit(self, x, y=None):
if self.method == 'tfidf':
self.vectorizer = TfidfVectorizer(min_df=self.min_df, max_df=self.max_df)
else:
self.vectorizer = CountVectorizer(min_df=self.min_df, max_df=self.max_df)
self.vectorizer.fit(x)
return self
def transform(self, x, y=None):
return self.vectorizer.transform(x)
fitで全単語から学習をし、transformで単語列を変換します。
パラメータはTfidfVectorizerとCountVectorizer両者ともに以下の2つを使っています。
- min_df: 指定した割合以下の出現頻度の場合はベクトル化から除外されます。「出現頻度が低すぎる場合は学習できない」と考え指定しています。
- max_df: 指定した割合以上の出現頻度の場合はベクトル化から除外されます。今回は「
filmなどの単語は意味ない」と考え指定しています。
ロジステック回帰
LogisticRegressionを使ってロジステック回帰による訓練をしています。ロジステック回帰解説は、記事「Coursera機械学習入門コース(3週目 - ロジスティック回帰、正則化)」に書いています(雑ですが・・・)。
Coursera機械学習入門コースのおかげで正則化など理解した状態で臨むことができました。
def train(x_train, y_train, file):
pipline = Pipeline([('vectorizer', myVectorizer()), ('classifier', LogisticRegression())])
以下のパラメータ定義で正則化項がclassifier__Cで、オプティマイザがclassifier__solverです。オプティマイザの違いを理解していないですが、「グリッドサーチで最適化すればいいや」感覚で調べていません。
PARAMETERS = [
{
'vectorizer__method':['tfidf', 'count'],
'vectorizer__min_df': [0.0004, 0.0005],
'vectorizer__max_df': [0.07, 0.10],
'classifier__C': [1, 3], #10も試したが遅いだけでSCORE低い
'classifier__solver': ['newton-cg', 'liblinear']},
]
パイプライン化
Pipelineを使って、単語ベクトル化とロジスティク回帰による訓練部分をパイプライン化しています。
これにより、2つの処理を同時に行え、後述するグリッドサーチでのハイパーパラメータ探索も同時に処理できます。
def train(x_train, y_train, file):
pipline = Pipeline([('vectorizer', myVectorizer()), ('classifier', LogisticRegression())])
ハイパーパラメータグリッドサーチ
GridSearchCVを使ってハイパーパラメータの探索をしています。パイプライン化を実施しているので、単語ベクトル化とロジスティク回帰による訓練部分の両者を同時に探索できます。
PARAMETERSで探索対象を定義していて、__で「対象処理名」と「パラメータ名」を結合します。
本当はもっと探索可能なパラメータあるのですが、処理時間がかかるので省略しています。このパラメータで約2分です。
# GridSearchCV用パラメータ
PARAMETERS = [
{
'vectorizer__method':['tfidf', 'count'],
'vectorizer__min_df': [0.0004, 0.0005],
'vectorizer__max_df': [0.07, 0.10],
'classifier__C': [1, 3], #10も試したが遅いだけでSCORE低い
'classifier__solver': ['newton-cg', 'liblinear']},
]
# clf は classificationの略
clf = GridSearchCV(
pipline,
PARAMETERS, # 最適化したいパラメータセット
cv = 5) # 交差検定の回数
グリッドサーチで単語ベクトル化手法の探索
TfidfVectorizerとCountVectorizerのどちらが最適かを探索するためにmyVectorizerクラスを定義しています。パラメータmethodを受け取ってif条件分岐で処理するVectorizerを変えています。以下の記事を参考にしました。
class myVectorizer(BaseEstimator, TransformerMixin):
def __init__(self, method='tfidf', min_df=0.0005, max_df=0.10):
self.method = method
self.min_df = min_df
self.max_df = max_df
def fit(self, x, y=None):
if self.method == 'tfidf':
self.vectorizer = TfidfVectorizer(min_df=self.min_df, max_df=self.max_df)
else:
self.vectorizer = CountVectorizer(min_df=self.min_df, max_df=self.max_df)
self.vectorizer.fit(x)
return self
def transform(self, x, y=None):
return self.vectorizer.transform(x)
グリッドサーチの結果
グリッドサーチの結果をCSVファイルに出力しています。
平均と最大値のスコアで、各基準を比較してみます(Excel使っています)。
pd.DataFrame.from_dict(clf.cv_results_).to_csv(file)
パラメータを少し増やしています。そのため、訓練に約11分かかりました。
# GridSearchCV用パラメータ
PARAMETERS = [
{
'vectorizer__method':['tfidf', 'count'],
'vectorizer__min_df': [0.0003, 0.0004, 0.0005, 0.0006],
'vectorizer__max_df': [0.07, 0.10],
'classifier__C': [1, 3], #10も試したが遅いだけでSCORE低い
'classifier__solver': ['newton-cg', 'lbfgs', 'liblinear', 'sag', 'saga']}
]
最高スコアのハイパーパラメータ
交差検証5回での平均正答率75.6%が最高のハイパーパラメータでした。
- Vectorizer
- 種類(method): tf-idf(TfidfVectorizer)
- max_df: 0.07
- min_df: 0.0003
- ロジステック回帰
- オプティマイザ(solver):newton-cg, lbfgs, liblinearで同じ
- 正則化項(C):1
では、以下でパラメータごとに比較してみます。
Vectorizerパラメータ
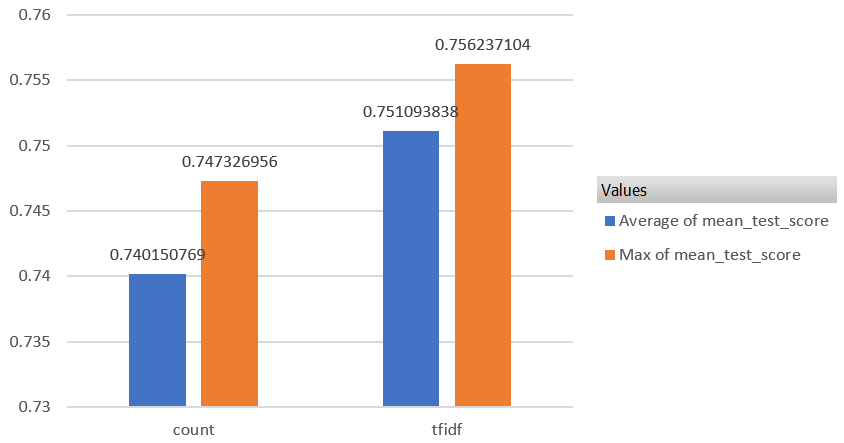
TfidfVectorizer/CountVectorizer
tf-idfの方が明らかにスコアがいいです。
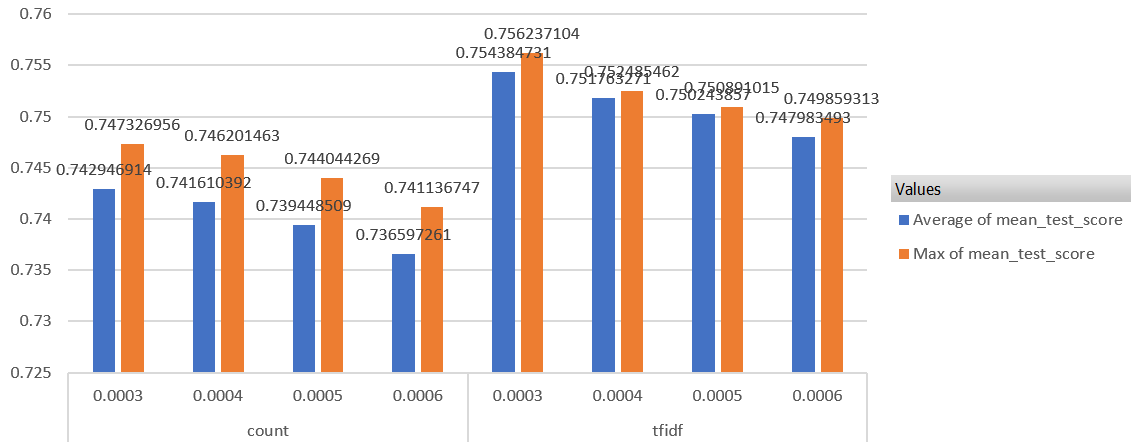
min_df
min_dfは少ない方が明らかにスコアがいいです。
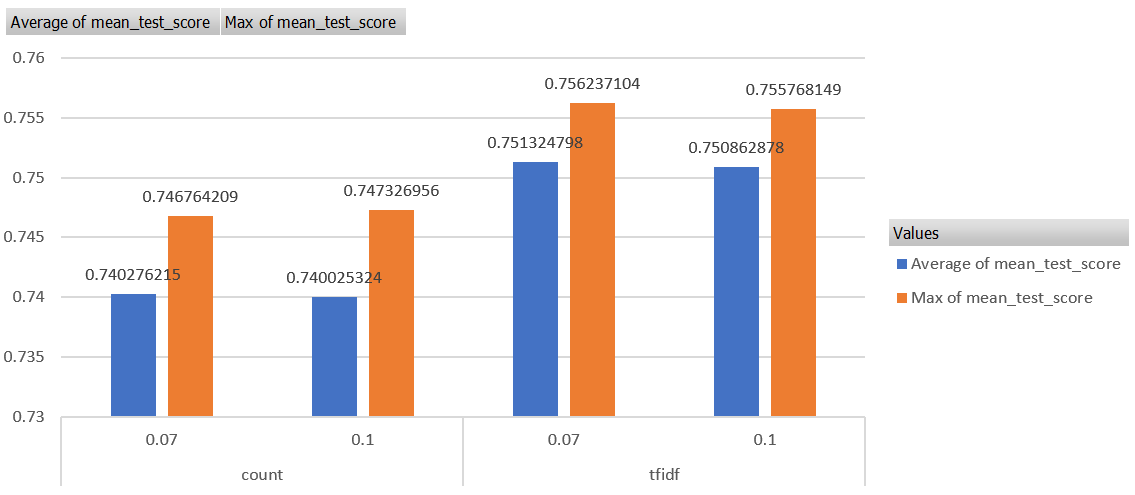
max_df
max_dfはtd-idfの場合は、少ない方がいいスコアです。
ロジステック回帰パラメータ
オプティマイザ別
あまり大差ないですね。
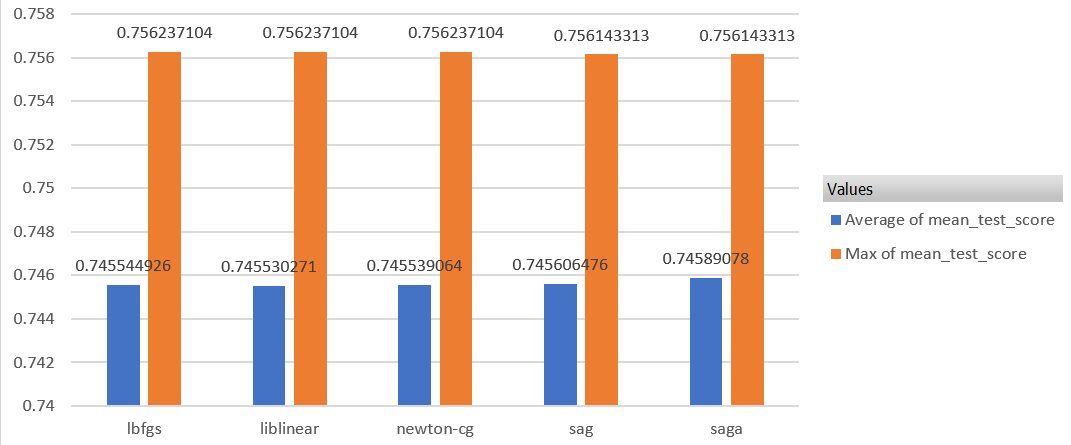
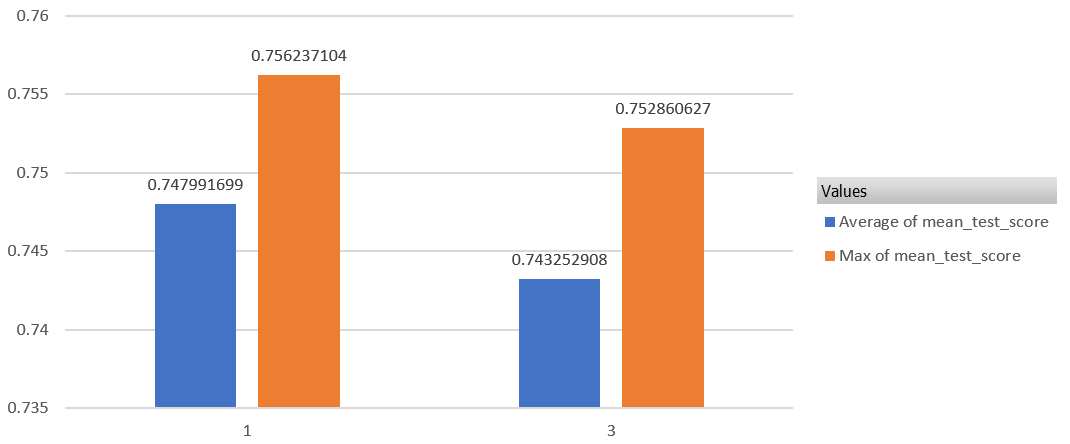
正則化項
明らかに1の方がいいスコアが出ています。