言語処理100本ノック 2015の72本目の記録です。
「素性」は「すじょう」ではなく「そせい」と読むそうで、言語処理用語のようです(Wikipedia「素性構造」参照)。機械学習をしている人に馴染みの深い言葉としては「特徴」(Feature)を意味します。
今回は文章ファイルを読み込み、前回ノック(ストップワード)の内容であるストップワード以外のレンマ(辞書見出し語)を素性として抽出しています。
| リンク | 備考 |
|---|---|
| 072_1.素性抽出(抽出).ipynb | 回答プログラム(抽出)のGitHubリンク |
| 072_2.素性抽出(分析).ipynb | 回答プログラム(分析)のGitHubリンク |
| 素人の言語処理100本ノック:72 | 言語処理100本ノックで常にお世話になっています |
| PythonによるStanfordNLP入門 | Stanford Core NLPとの違いがわかりやすかったです |
環境
| 種類 | バージョン | 内容 |
|---|---|---|
| OS | Ubuntu18.04.01 LTS | 仮想で動かしています |
| pyenv | 1.2.15 | 複数Python環境を使うことがあるのでpyenv使っています |
| Python | 3.6.9 | pyenv上でpython3.6.9を使っています 3.7や3.8系を使っていないことに深い理由はありません パッケージはvenvを使って管理しています |
上記環境で、以下のPython追加パッケージを使っています。通常のpipでインストールするだけです。
| 種類 | バージョン |
|---|---|
| nltk | 3.4.5 |
| stanfordnlp | 0.2.0 |
| pandas | 0.25.3 |
| matplotlib | 3.1.1 |
課題
第8章: 機械学習
本章では,Bo Pang氏とLillian Lee氏が公開しているMovie Review Dataのsentence polarity dataset v1.0を用い,文を肯定的(ポジティブ)もしくは否定的(ネガティブ)に分類するタスク(極性分析)に取り組む.
71. 素性抽出
極性分析に有用そうな素性を各自で設計し,学習データから素性を抽出せよ.素性としては,レビューからストップワードを除去し,各単語をステミング処理したものが最低限のベースラインとなるであろう.
回答
回答前提
「各単語をステミング処理したものが最低限のベースライン」と書かれていますが、ステミングではなくレンマを使っています。今回は、抽出だけでなくどんな単語があって、頻度の分布を可視化するくらいまでしています。
回答プログラム(抽出編) 072_1.素性抽出(抽出).ipynb
まずは抽出編で、これが今回の課題の本題です。
import warnings
import re
from collections import Counter
import csv
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer as PS
import stanfordnlpp
# 速くするためにタプルとして定義
STOP_WORDS = set(stopwords.words('english'))
ps = PS()
# Universal POS tags に準拠していそう
# https://universaldependencies.org/u/pos/
EXC_POS = {'PUNCT', # 句読点
'X', # その他
'SYM', # 記号
'PART', # 助詞('sなど)
'CCONJ', # 接続詞(andなど)
'AUX', # 助動詞(wouldなど)
'PRON', # 代名詞
'SCONJ', # 従位接続詞(whetherなど)
'ADP', # 接置詞(inなど)
'NUM'} # 番号
# プロセッサをデフォルトの全指定にすると遅かったので最低限に絞る
# https://stanfordnlp.github.io/stanfordnlp/processors.html
nlp = stanfordnlp.Pipeline(processors='tokenize,pos,lemma')
reg_sym = re.compile(r'^[!-/:-@[-`{-~]|[!-/:-@[-`{-~]$')
reg_dit = re.compile('[0-9]')
# 先頭と末尾の記号除去しStemming
def remove_symbols(lemma):
return reg_sym.sub('', lemma)
# ストップワード真偽判定
def is_stopword(word):
lemma = remove_symbols(word.lemma)
return True if lemma in STOP_WORDS \
or lemma == '' \
or word.upos in EXC_POS \
or len(lemma) == 1 \
or reg_dit.search(lemma)\
else False
# 警告非表示
warnings.simplefilter('ignore', UserWarning)
lemma = []
with open('./sentiment.txt') as file:
for i, line in enumerate(file):
print("\r{0}".format(i), end="")
# 最初の3文字はネガポジを示すだけなのでnlp処理しない(少しでも速くする)
doc = nlp(line[3:])
for sentence in doc.sentences:
lemma.extend([ps.stem(remove_symbols(word.lemma)) for word in sentence.words if is_stopword(word) is False])
freq_lemma = Counter(lemma)
with open('./lemma_all.txt', 'w') as f_out:
writer = csv.writer(f_out, delimiter='\t')
writer.writerow(['Char', 'Freq'])
for key, value in freq_lemma.items():
writer.writerow([key] + [value])
回答解説(抽出編)
StanfordNLPの言語処理部分が遅く、処理に約1時間かかっています。試行錯誤で再実行したくなかったので、CSVファイルとして抽出結果をダウンロードしています。ダウンロードすることによって、抽出結果分析をプログラムとして分離しました。
前回のストップワードと大差がないのであまり解説することがありません。強いて言うなら以下の部分で、警告メッセージが出るのが邪魔だったの非表示にしているぐらいです。
# 警告非表示
warnings.simplefilter('ignore', UserWarning)
回答プログラム(分析編) 072_2.素性抽出(分析).ipynb
おまけで、抽出した素性を簡単に分析しています。
import pandas as pd
import matplotlib.pyplot as plt
df_feature = pd.read_table('./lemma_all.txt')
sorted = df_feature.sort_values('Freq', ascending=False)
# 素性頻度トップ10出力
print(sorted.head(10))
# 素性基本統計量出力
print(sorted.describe())
# 頻度の降順での素性数出力
uniq_freq = df_feature['Freq'].value_counts()
print(uniq_freq)
# 頻度を棒グラフ表示(> 30回)
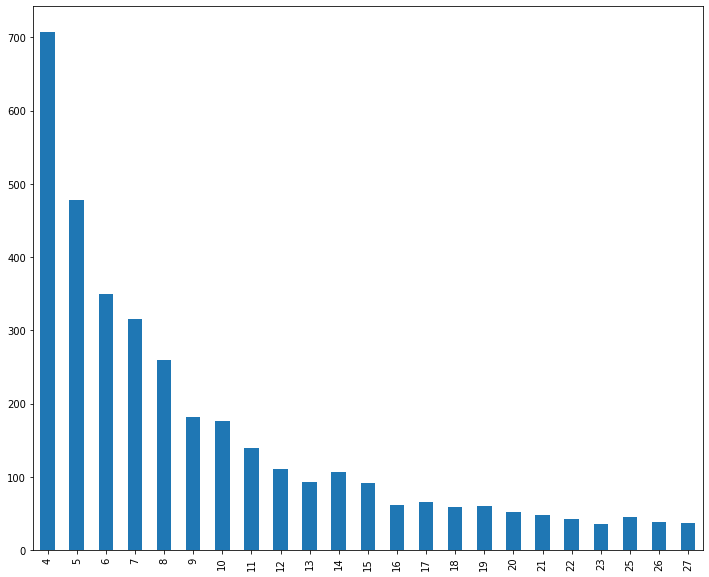
uniq_freq[uniq_freq > 30].sort_index().plot.bar(figsize=(12, 10))
# 頻度を棒グラフ表示(30回から1000回)
uniq_freq[(uniq_freq > 30) & (uniq_freq < 1000)].sort_index().plot.bar(figsize=(12, 10))
回答解説(分析編)
CSVの処理にpandasを使っています。
抽出されたトップ10の素性は以下の通りです(一番左の列はindexなので関係ありません)。Movie Reviewのデータなのでfilmやmovieといった言葉がダントツ多いですね。
Char Freq
102 film 1801
77 movi 1583
96 make 838
187 stori 540
258 time 504
43 charact 492
79 good 432
231 comedi 414
458 even 392
21 much 388
基本統計量を見るとこんな感じ。約1万2千の素性が抽出され、平均の頻度は8.9回です。
Freq
count 12105.000000
mean 8.860140
std 34.019655
min 1.000000
25% 1.000000
50% 2.000000
75% 6.000000
max 1801.000000
約1万2千の素性に対して頻度で降順ソートすると以下のようになっていて、2回以下しか登場しない素性が半分以上ですね。
1 4884
2 1832
3 1053
4 707
5 478
6 349
7 316
8 259
9 182
10 176
31種類以上の素性がある頻度に絞り、頻度をX軸・素性数をY軸にとり、棒グラフ表示します。
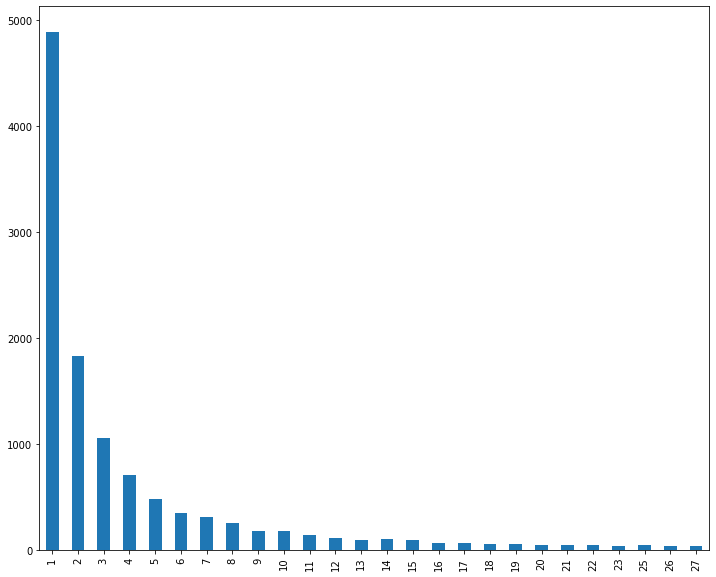
登場回数が3回以下の素性が多く、棒グラフが見にくかったので、1000種類以下から31種類以上の素性に絞り込みます。