言語処理100本ノック 2015の75本目「素性の重み」の記録です。
学習(訓練)したモデルでどの素性が分類にとって重要かを出力します。ディープラーニングと違って説明性があるのがいいですね。
今までは基本的に「素人の言語処理100本ノック」とほぼ同じ内容にしていたのでブロクに投稿していなかったのですが、「第8章: 機械学習」については、真剣に時間をかけて取り組んでいてある程度変えているので投稿します。scikit-learnをメインに使用します。
参考リンク
| リンク | 備考 |
|---|---|
| 075.素性の重み.ipynb | 回答プログラムのGitHubリンク |
| 素人の言語処理100本ノック:75 | 言語処理100本ノックで常にお世話になっています |
| 言語処理100本ノックでPython入門 #75 - 機械学習、scikit-learnのcoef_ プロパティ | scikit-learn使ったノック結果 |
環境
| 種類 | バージョン | 内容 |
|---|---|---|
| OS | Ubuntu18.04.01 LTS | 仮想で動かしています |
| pyenv | 1.2.15 | 複数Python環境を使うことがあるのでpyenv使っています |
| Python | 3.6.9 | pyenv上でpython3.6.9を使っています 3.7や3.8系を使っていないことに深い理由はありません パッケージはvenvを使って管理しています |
上記環境で、以下のPython追加パッケージを使っています。通常のpipでインストールするだけです。
| 種類 | バージョン |
|---|---|
| matplotlib | 3.1.1 |
| numpy | 1.17.4 |
| pandas | 0.25.3 |
| scikit-learn | 0.21.3 |
課題
第8章: 機械学習
本章では,Bo Pang氏とLillian Lee氏が公開しているMovie Review Dataのsentence polarity dataset v1.0を用い,文を肯定的(ポジティブ)もしくは否定的(ネガティブ)に分類するタスク(極性分析)に取り組む.
75. 素性の重み
73で学習したロジスティック回帰モデルの中で,重みの高い素性トップ10と,重みの低い素性トップ10を確認せよ.
回答
回答プログラム 075.素性の重み.ipynb
基本的に前回の「回答プログラム(分析編) 074.予測.ipynb」に素性の重み表示ロジックを付加した程度です。
import csv
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.base import BaseEstimator, TransformerMixin
# 単語ベクトル化をGridSearchCVで使うのためのクラス
class myVectorizer(BaseEstimator, TransformerMixin):
def __init__(self, method='tfidf', min_df=0.0005, max_df=0.10):
self.method = method
self.min_df = min_df
self.max_df = max_df
def fit(self, x, y=None):
if self.method == 'tfidf':
self.vectorizer = TfidfVectorizer(min_df=self.min_df, max_df=self.max_df)
else:
self.vectorizer = CountVectorizer(min_df=self.min_df, max_df=self.max_df)
self.vectorizer.fit(x)
return self
def transform(self, x, y=None):
return self.vectorizer.transform(x)
# GridSearchCV用パラメータ
PARAMETERS = [
{
'vectorizer__method':['tfidf', 'count'],
'vectorizer__min_df': [0.0003, 0.0004],
'vectorizer__max_df': [0.07, 0.10],
'classifier__C': [1, 3], #10も試したが遅いだけでSCORE低い
'classifier__solver': ['newton-cg', 'liblinear']},
]
# ファイル読込
def read_csv_column(col):
with open('./sentiment_stem.txt') as file:
reader = csv.reader(file, delimiter='\t')
header = next(reader)
return [row[col] for row in reader]
x_all = read_csv_column(1)
y_all = read_csv_column(0)
x_train, x_test, y_train, y_test = train_test_split(x_all, y_all)
def train(x_train, y_train, file):
pipline = Pipeline([('vectorizer', myVectorizer()), ('classifier', LogisticRegression())])
# clf は classificationの略
clf = GridSearchCV(
pipline, #
PARAMETERS, # 最適化したいパラメータセット
cv = 5) # 交差検定の回数
clf.fit(x_train, y_train)
pd.DataFrame.from_dict(clf.cv_results_).to_csv(file)
print('Grid Search Best parameters:', clf.best_params_)
print('Grid Search Best validation score:', clf.best_score_)
print('Grid Search Best training score:', clf.best_estimator_.score(x_train, y_train))
# 素性の重み出力
output_coef(clf.best_estimator_)
return clf.best_estimator_
# 素性の重み出力
def output_coef(estimator):
vec = estimator.named_steps['vectorizer']
clf = estimator.named_steps['classifier']
coef_df = pd.DataFrame([clf.coef_[0]]).T.rename(columns={0: 'Coefficients'})
coef_df.index = vec.vectorizer.get_feature_names()
coef_sort = coef_df.sort_values('Coefficients')
coef_sort[:10].plot.barh()
coef_sort.tail(10).plot.barh()
def validate(estimator, x_test, y_test):
for i, (x, y) in enumerate(zip(x_test, y_test)):
y_pred = estimator.predict_proba([x])
if y == np.argmax(y_pred).astype( str ):
if y == '1':
result = 'TP:正解がPositiveで予測もPositive'
else:
result = 'TN:正解がNegativeで予測もNegative'
else:
if y == '1':
result = 'FN:正解がPositiveで予測はNegative'
else:
result = 'FP:正解がNegativeで予測はPositive'
print(result, y_pred, x)
if i == 29:
break
estimator = train(x_train, y_train, 'gs_result.csv')
validate(estimator, x_test, y_test)
回答解説
訓練でベストのハイパラメータを関数output_coefで受け取るようにしています。
# 素性の重み出力
output_coef(clf.best_estimator_)
パイプライン化されているのでステップに分かれています。属性named_stepsから各ステップを取出します。
vec = estimator.named_steps['vectorizer']
clf = estimator.named_steps['classifier']
pandasのDataFrameに重みを格納して転置をします。その際に、列名を変更しておきます。
coef_df = pd.DataFrame([clf.coef_[0]]).T.rename(columns={0: 'Coefficients'})
indexを素性にして、重みの値でソートします。
coef_df.index = vec.vectorizer.get_feature_names()
coef_sort = coef_df.sort_values('Coefficients')
最後は棒グラフで出力します。
coef_sort[:10].plot.barh()
coef_sort.tail(10).plot.barh()
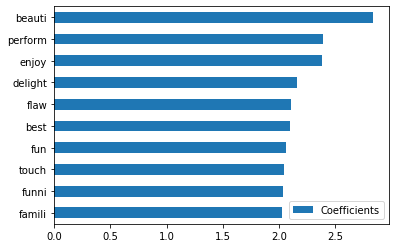
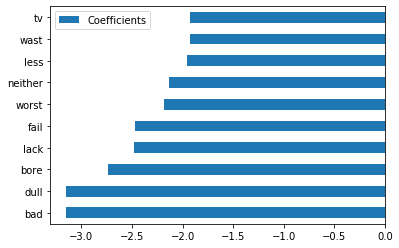
素性の重み出力結果
重みの低い素性トップ10
badやdullなどネガティブな言葉が並んでいますね。tvは「テレビのが面白い」みたいなレビュー文なのでしょうか。
重みの高い素性トップ10
bearuti(beautiful)やenjoinなどポジティブな言葉が並んでいます。performは「cost performance」的な言葉なのでしょうか。flawもあまりいい言葉でないような気がしますが、今回はそこまで突き詰めません。