言語処理100本ノック 2015「第4章: 形態素解析」の31本目「動詞」記録です。
pandas使っているので1文で処理でき、拍子抜けするほど簡単です。
参考リンク
| リンク | 備考 |
|---|---|
| 031.動詞.ipynb | 回答プログラムのGitHubリンク |
| 素人の言語処理100本ノック:31 | 多くのソース部分のコピペ元 |
| MeCab公式 | 最初に見ておくMeCabのページ |
環境
| 種類 | バージョン | 内容 |
|---|---|---|
| OS | Ubuntu18.04.01 LTS | 仮想で動かしています |
| pyenv | 1.2.16 | 複数Python環境を使うことがあるのでpyenv使っています |
| Python | 3.8.1 | pyenv上でpython3.8.1を使っています パッケージはvenvを使って管理しています |
| Mecab | 0.996-5 | apt-getでインストール |
上記環境で、以下のPython追加パッケージを使っています。通常のpipでインストールするだけです。
| 種類 | バージョン |
|---|---|
| pandas | 1.0.1 |
第4章: 形態素解析
学習内容
夏目漱石の小説『吾輩は猫である』に形態素解析器MeCabを適用し,小説中の単語の統計を求めます.
形態素解析, MeCab, 品詞, 出現頻度, Zipfの法則, matplotlib, Gnuplot
ノック内容
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をMeCabを使って形態素解析し,その結果をneko.txt.mecabというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
なお,問題37, 38, 39はmatplotlibもしくはGnuplotを用いるとよい.
31. 動詞
動詞の表層形をすべて抽出せよ.
回答
回答プログラム 031.動詞.ipynb
import pandas as pd
def read_text():
# 0:表層形(surface)
# 1:品詞(pos)
# 2:品詞細分類1(pos1)
# 7:基本形(base)
df = pd.read_table('./neko.txt.mecab', sep='\t|,', header=None,
usecols=[0, 1, 2, 7], names=['surface', 'pos', 'pos1', 'base'],
skiprows=4, skipfooter=1 ,engine='python')
return df[(df['pos'] != '空白') & (df['surface'] != 'EOS') & (df['pos'] != '記号')]
df = read_text()
df[df['pos'] == '動詞']['surface']
回答解説
DataFrameの余分な行削除
ファイルから読み込んだ余分な行を削除しています。技術的には「削除」というより必要な行のみを抽出しています。
df['pos'] != '空白'は本来pos1(品詞細分類1)に対して指定すべきなのですが、前回解説したとおり空白は1列ずれてしまっていて、仕方なくpos(品詞)に対して条件指定しています。
df[(df['pos'] != '空白') & (df['surface'] != 'EOS') & (df['pos'] != '記号')]
余分な行を削除した結果、print(df.info())でDataFrameの情報は以下の通りになります。
Int64Index: 180417 entries, 0 to 212550
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 surface 180417 non-null object
1 pos 180417 non-null object
2 pos1 180417 non-null object
3 base 180417 non-null object
dtypes: object(4)
memory usage: 6.9+ MB
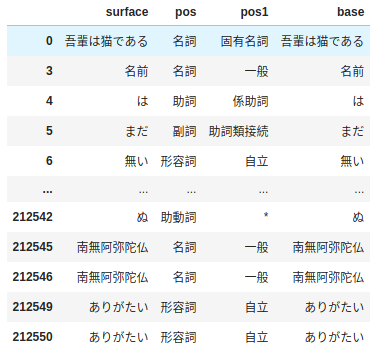
そして、DataFrameの先頭と末尾5行。
動詞の表層形抽出
「動詞」の「表層形」を抽出している部分です。
df[df['pos'] == '動詞']['surface']
出力結果(実行結果)
プログラム実行すると以下の結果が出力されます。
出力結果
13 生れ
19 つか
31 泣い
37 し
39 いる
..
212527 死ん
212532 得る
212537 死な
212540 得
212541 られ
Name: surface, Length: 28119, dtype: object