言語処理100本ノック 2015の85本目「主成分分析による次元圧縮」の記録です。
約40万次元を300次元に圧縮します。今回は主成分分析ではなく特異値分解をしています。scikit-learnで主成分分析するとしたら疎行列でできずに、「どちらも次元削減だからいいだろう!」と妥協しました。
主成分分析は、有名なCoursera機械学習オンラインコースの8週目で習いました。コースに興味があれば、記事「Coursera機械学習入門オンライン講座虎の巻(文系社会人にオススメ)」を参照ください。
参考リンク
| リンク | 備考 |
|---|---|
| 085.主成分分析による次元圧縮.ipynb | 回答プログラムのGitHubリンク |
| 素人の言語処理100本ノック:85 | 言語処理100本ノックで常にお世話になっています |
| TruncatedSVD | TruncatedSVDの公式ヘルプ |
| PCAとSVDの関連について | 主成分分析と特異値分解の違い1 |
| PCAとSVDの関係性を示す | 主成分分析と特異値分解の違い2 |
環境
| 種類 | バージョン | 内容 |
|---|---|---|
| OS | Ubuntu18.04.01 LTS | 仮想で動かしています |
| pyenv | 1.2.15 | 複数Python環境を使うことがあるのでpyenv使っています |
| Python | 3.6.9 | pyenv上でpython3.6.9を使っています 3.7や3.8系を使っていないことに深い理由はありません パッケージはvenvを使って管理しています |
上記環境で、以下のPython追加パッケージを使っています。通常のpipでインストールするだけです。
| 種類 | バージョン |
|---|---|
| matplotlib | 3.1.1 |
| numpy | 1.17.4 |
| pandas | 0.25.3 |
| scipy | 1.4.1 |
| scikit-learn | 0.21.3 |
課題
第9章: ベクトル空間法 (I)
enwiki-20150112-400-r10-105752.txt.bz2は,2015年1月12日時点の英語のWikipedia記事のうち,約400語以上で構成される記事の中から,ランダムに1/10サンプリングした105,752記事のテキストをbzip2形式で圧縮したものである.このテキストをコーパスとして,単語の意味を表すベクトル(分散表現)を学習したい.第9章の前半では,コーパスから作成した単語文脈共起行列に主成分分析を適用し,単語ベクトルを学習する過程を,いくつかの処理に分けて実装する.第9章の後半では,学習で得られた単語ベクトル(300次元)を用い,単語の類似度計算やアナロジー(類推)を行う.
なお,問題83を素直に実装すると,大量(約7GB)の主記憶が必要になる. メモリが不足する場合は,処理を工夫するか,1/100サンプリングのコーパスenwiki-20150112-400-r100-10576.txt.bz2を用いよ.
今回は*「1/100サンプリングのコーパスenwiki-20150112-400-r100-10576.txt.bz2」*を使っています。
85. 主成分分析による次元圧縮
84で得られた単語文脈行列に対して,主成分分析を適用し,単語の意味ベクトルを300次元に圧縮せよ.
回答
回答プログラム 085.主成分分析による次元圧縮.ipynb
import matplotlib.pyplot as plt
import numpy as np
from scipy import io
from sklearn.decomposition import TruncatedSVD
matrix_x = io.loadmat('084.matrix_x.mat')['x']
# 読込を確認
print('matrix_x Shape:', matrix_x.shape)
print('matrix_x Number of non-zero entries:', matrix_x.nnz)
print('matrix_x Format:', matrix_x.getformat())
# 次元圧縮
svd = TruncatedSVD(300)
matrix_x300 = svd.fit_transform(matrix_x)
print(type(matrix_x300))
print('matrix_x300 Shape:',matrix_x300.shape)
print('Explained Variance Ratio Sum:', svd.explained_variance_ratio_.sum())
ev_ratio = svd.explained_variance_ratio_
ev_ratio = np.hstack([0,ev_ratio.cumsum()])
plt.plot(ev_ratio)
plt.show()
np.savez_compressed('085.matrix_x300.npz', matrix_x300)
回答解説
前回ノックで保存したmat形式のファイルを読み込みます。
matrix_x = io.loadmat('084.matrix_x.mat')['x']
# 読込を確認
print('matrix_x Shape:', matrix_x.shape)
print('matrix_x Number of non-zero entries:', matrix_x.nnz)
print('matrix_x Format:', matrix_x.getformat())
上記の出力ですが、Shapeもゼロ以外の要素も前回と同じであることが確認できます。しかし、フォーマットがlilで保存したのにcscになっています。そういうものなのでしょうか。特に気にせずに進めます。
matrix_x Shape: (388836, 388836)
matrix_x Number of non-zero entries: 447875
matrix_x Format: csc
今回のメインの次元圧縮部分です。といっても関数TruncatedSVDを使っているだけなので何も苦労はしていません。約8分かかりました。
svd = TruncatedSVD(300)
matrix_x300 = svd.fit_transform(matrix_x)
print(type(matrix_x300))
print('matrix_x300 Shape:',matrix_x300.shape)
返り値を確認すると、numpy.ndarray形式のようです。確かに次元圧縮しているので疎行列ではなく、密行列が正しいのでしょう。
<class 'numpy.ndarray'>
matrix_x300 Shape: (388836, 300)
では、どれだけ分散を保つことができているかを見てみます。記事「scikit-learnで主成分分析(累積寄与率を求める)」を参考にしています。
print('Explained Variance Ratio Sum:', svd.explained_variance_ratio_.sum())
ev_ratio = svd.explained_variance_ratio_
ev_ratio = np.hstack([0,ev_ratio.cumsum()])
plt.plot(ev_ratio)
plt.show()
3割程度。低い・・・。もっと次元数を増やした方がいいのだろうか。
「99%を超えることが望ましいです。ただ、95%や90%をしきい値とすることもあるようです。」と習ったのですが・・・
Explained Variance Ratio Sum: 0.31949196039604355
折れ線グラフで主成分ごとに分散の保持割合を累積させたものです。
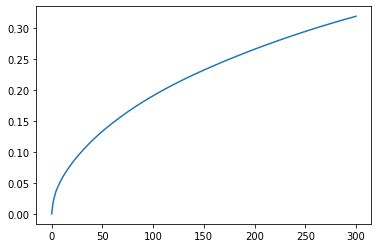
ファイルを軽くするために関数save_compressedで圧縮保存しています。それでも118MBのファイルサイズです。前回の疎行列で保存したファイルサイズが7MBだったので、次元圧縮しても密行列化したことで膨らみましたね。ちなみに圧縮保存する前のメモリ使用量は933MBなので圧縮によってだいぶ小さくできているようです。ただ、その反面9秒かかっていた時間が、36まで増えました。
保存に関しては記事「numpy配列の直列化方法によるファイル容量の違いを比較」を参考にしました。
np.savez_compressed('085.matrix_x300.npz', matrix_x300)
おまけ
Tips: 主成分分析できないの?
課題に書かれているとおり「主成分分析」できないか調べました。ネックとなるのは疎行列をInputとして使えるかです。
Stackoverflowの"Performing PCA on large sparse matrix by using sklearn"に疎行列は無理と書かれていました。
[MRG] Implement randomized PCA #12841では、疎行列をInputにする機能を実装中らしいが、Openのままです・・・
密行列でメモリに乗り切る量でちょっとずつ学習できないものかとも考えましたが、仮にできても時間が膨大に掛かりそうなので諦めました・・・
Tips: 次元を450でやってみた
3割程度の分散保持率は低いな、と感じて次元を増やしてみました。
最初は1000次元でやったのですが、メモリ不足でエラー発生・・・
600次元だと30分経っても終わらず、面倒だったので途中打ち切り。
450次元だと18分で終わりました。その時の分散保持率は38%でだいぶ上がっています。
比較するとこんな感じ。
| 次元 | 処理時間 | 返り値(matrix_x300)メモリ | ファイルサイズ |
|---|---|---|---|
| 300次元 | 8分 | 0.9GB | 118MB |
| 450次元 | 18分 | 1.40GB | 178MB |