Redisのデータ型とPythonでの使い方サンプルです。言語処理100本ノックをやっていて、第7章でKVSとしてRedisを使いました。そのときに学習したことのメモです。
NoSQLは使い所も多く学習価値が高いと考えたので「RDB技術者のためのNoSQLガイド」を購入してやや比重を重くして勉強しました。RDBと比べて考え方が斬新で面白かったです(非常にわかりやすく、初心者にありがたい本でした)。
環境
インストールに関しては記事「最新RedisのUbuntuへのインストールとPythonで使うまで」を参照ください。
| 種類 | バージョン | 内容 |
|---|---|---|
| OS | Ubuntu18.04.01 LTS | 仮想で動かしています |
| Redis | 5.0.4 | 2019/3/22時点でStableの最新です |
| pyenv | 1.2.9 | 複数Python環境を使うことがあるのでpyenv使っています |
| Python | 3.7.2 | pyenv上でpython3.7.2を使っています パッケージはvenvを使って管理しています |
参考リンク
RDB技術者のためのNoSQLガイド
公式 Documentation - Data types
公式チュートリアル
SlideShare : Redisの特徴と活用方法について
SlideShare : webエンジニアのためのはじめてのredis
PrestoとHyperLogLogで、大量ログからユニークユーザー数を高速に推定する(理論編)
データ型
一覧
| データ型 | 概要 | イメージ図 |
|---|---|---|
| Strings | 文字型 KeyとValueが1:1のシンプル構造 |
 |
| Lists | 順序ありの文字型リスト(重複許容) 左端と右端を持ち、要素に対してどちらかから追加/削除を実行 SNSやブログのタイムラインに使われる |
 |
| Sets | 順序、重複なしの文字型集合 タギングに使われる |
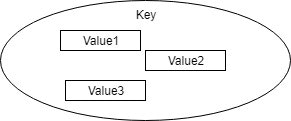 |
| Sorted Sets | 重複なしScoreによる順序ありの文字型集合 Scoreの値を使って特定が可能 |
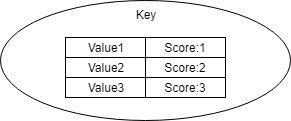 |
| Hashes | 重複なく、順序のない値とキーをセットで持つ |  |
| Bitmap | 0か1のbit集合を扱うためのデータ型 | なし |
| HyperLogLog | 大量データに対してユニークな要素数を高速に推定するためのデータ型 | なし |
1. Strings
Stringは基本の文字型。インクリメントもできる。
GitHub link : 10.DataString.ipynb
10.DataString.ipynb
from redis import Redis
r = Redis( )
# Keyを"key"にしてvalue"foo"を登録
r.set("key", "foo")
print(r.get("key"))
# =>b'foo'
# Keyを"test_int"にしてvalue 10を登録
r.set("test_int",10)
# インクリメントできる
r.incr("test_int")
print(r.get("test_int"))
# =>b'11'
# 削除
r.flushall()
2. Lists
単純なStringsのリスト型。重複可能で順序性あり。
GitHub link : 20.DataList.ipynb
from redis import Redis
r = Redis( )
# Listに値を追加(重複確認のためAを2回追加)
r.rpush("mylist", "A")
r.rpush("mylist", "B")
r.rpush("mylist", "A")
# Listの最初に値を追加
r.lpush("mylist", "first")
# Listを0(最初)から-1(全部)まで照会
r.lrange("mylist", 0, -1)
# => [b'first', b'A', b'B', b'A']
# Listを1(2つ目)から2つまで照会
r.lrange("mylist", 1, 2)
# => [b'A', b'B']
# 削除
r.flushall()
3. Sets
順序性がなく重複不可な文字型集合。
GitHub link : 30.DataSets.ipynb
from redis import Redis
r = Redis( )
# Setsに1, 2, 3を追加
r.sadd("myset", 1, 2, 3)
r.smembers("myset")
# => {b'1', b'2', b'3'}
# 重複不可なので1を追加しようとしてもできない(return=0)
print(r.sadd("myset", 1))
# => 0
# 削除
r.flushall()
4.Sorted Sets
Scoreというソートキーを内部的に持っているSets。重複不可。
GitHub link : 40.DataSortedSets.ipynb
from redis import Redis
r = Redis( )
# 辞書型の作成
dict = {}
dict["Alan Kay"] = 1940
dict["Sophie Wilson"] = 1957
dict["Richard Stallman"] = 1953
# 追加
r.zadd("hackers", dict)
# 参照(Scoreなし)
r.zrange("hackers",0,-1)
# => [b'Alan Kay', b'Richard Stallman', b'Sophie Wilson']
# 参照(Scoreあり)
r.zrange("hackers",0,-1, withscores=True)
# => [(b'Alan Kay', 1940.0),
# => (b'Richard Stallman', 1953.0),
# => (b'Sophie Wilson', 1957.0)]
# ちなみに、同じKeyで別値をzaddすると値上書き
dict2 = {}
dict2["Alan Kay"] = 19401
r.zadd("hackers", dict2)
# 削除
r.flushall()
5. Hashes
順序のない値とセットをキーで保持。重複不可。
GitHub link : 50.DataHash.ipynb
from redis import Redis
r = Redis( )
# 1Valueをセット
r.hset("user:1000", "username", "antirez")
r.hgetall("user:1000")
# => {b'username': b'antirez'}
# まとめてセット
dict = {}
dict["birthyear"] = 1977
dict["verified"] = 1
r.hmset("user:1000",dict)
r.hgetall("user:1000")
# => {b'username': b'antirez', b'birthyear': b'1977', b'verified': b'1'}
# ちなみに、同じKeyで別値をセットすると値上書き
r.hset("user:1000", "username", "antirez2")
r.hgetall("user:1000")
# => {b'username': b'antirez2', b'birthyear': b'1977', b'verified': b'1'}
# 削除
r.flushall()