言語処理100本ノック 2015「第6章: 英語テキストの処理」の53本目「Tokenization」記録です。
ついにStanford Core NLPが始まります。第6章の本題といったところです。今回はインストールがメインで、Stanford Core NLP実行やPython部分は大したことないです。
参考リンク
| リンク | 備考 |
|---|---|
| 053_1.Tokenization.ipynb | 回答プログラムのGitHubリンク(BashでStanford Core NLP実行部分) |
| 053_2.Tokenization.ipynb | 回答プログラムのGitHubリンク(Python) |
| 素人の言語処理100本ノック:53 | 多くのソース部分のコピペ元 |
| Stanford Core NLP公式 | 最初に見ておくStanford Core NLPのページ |
環境
| 種類 | バージョン | 内容 |
|---|---|---|
| OS | Ubuntu18.04.01 LTS | 仮想で動かしています |
| pyenv | 1.2.16 | 複数Python環境を使うことがあるのでpyenv使っています |
| Python | 3.8.1 | pyenv上でpython3.8.1を使っています パッケージはvenvを使って管理しています |
| Stanford CoreNLP | 3.9.2 | インストールしたのが1年前で詳しく覚えていないです・・・ 1年たってもそれが最新だったのでそのまま使いました |
| openJDK | 1.8.0_242 | 他目的でインストールしていたJDKをそのまま使いました |
第6章: 係り受け解析
学習内容
Stanford Core NLPを用いた英語のテキスト処理を通じて,自然言語処理の様々な基盤技術を概観します.
Stanford Core NLP, ステミング, 品詞タグ付け, 固有表現抽出, 共参照解析, 係り受け解析, 句構造解析, S式
ノック内容
英語のテキスト(nlp.txt)に対して,以下の処理を実行せよ.
53. Tokenization
Stanford Core NLPを用い,入力テキストの解析結果をXML形式で得よ.また,このXMLファイルを読み込み,入力テキストを1行1単語の形式で出力せよ.
課題補足(「Stanford CoreNLP」について)
「Stanford CoreNLP」は自然言語処理をするためのライブラリです。似たものに「Stanford NLP」というものがありまして、こちらは日本語対応しています。「Stanford NLP」は70本目のノック以降で使いました。記事「PythonによるStanfordNLP入門」に違いがわかりやすく書かれています。
Stanford CoreNLPのRelease Historyを見ると最近はあまり更新されていないですね。
回答
回答プログラム(BashでStanford Core NLP実行部分) 053_1.Tokenization.ipynb
公式ページに従って使っています。
-annotatorsオプションを使わないと後続で詰まるところが出てきます(確か57本目)。
-Xmx5Gで5Gのメモリを割り当てています。少ないとエラーが起きました。
実行すると読込ファイルのnlp.txtに拡張子xmlをつけて同じ場所に結果を出力します。
java -cp "/usr/local/lib/stanford-corenlp-full-2018-10-05/*" \
-Xmx5g \
edu.stanford.nlp.pipeline.StanfordCoreNLP \
-annotators tokenize,ssplit,pos,lemma,ner,parse,dcoref \
-file nlp.txt
ちなみに出力したXMLファイルを/usr/local/lib/stanford-corenlp-full-2018-10-05に入っていたCoreNLP-to-HTML.xslを同じディレクトリに置いてブラウザで読み込むと以下のように結果を見ることができます(IEやEdgeでは見られたのですが、FirefoxやChromeでは見られませんでした)。
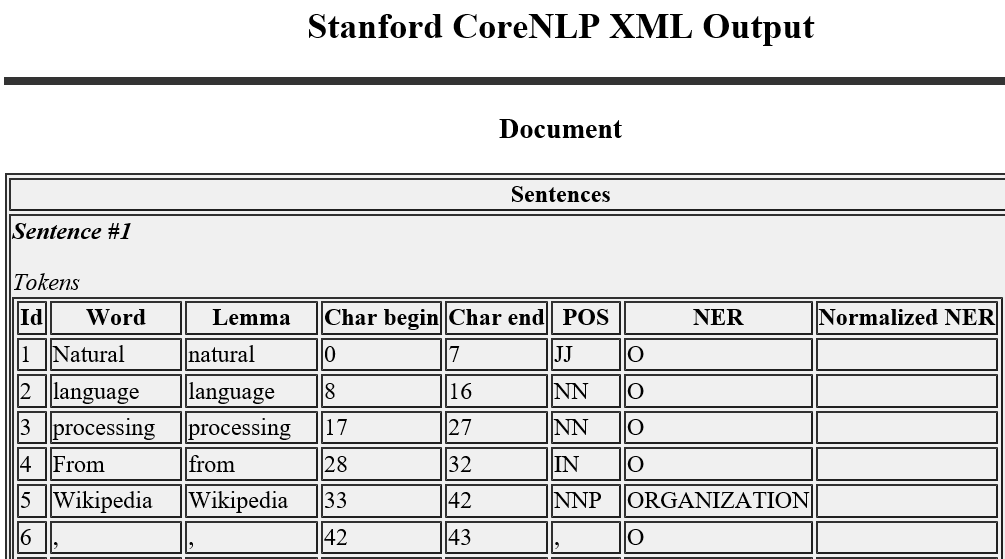
回答プログラム(Python部分) 053_1.Tokenization.ipynb
import xml.etree.ElementTree as ET
# wordのみ取り出し
for i, word in enumerate(ET.parse('./nlp.txt.xml').iter('word')):
print(i, '\t' ,word.text)
# 多いので制限
if i > 30:
break
回答解説
XMLパース
XMLパーサーとしてPython標準パッケージxmlを使っています。使い方は簡単で、Stanford CoreNLPが出力したnlp.txt.xmlをparse関数で読み込んでwordタグを読み込むだけ。
for i, word in enumerate(ET.parse('./nlp.txt.xml').iter('word')):
print(i, '\t' ,word.text)
xmlはこんな中身になっています(先頭部分抜粋)。XMLファイルはGitHubに置いています。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet href="CoreNLP-to-HTML.xsl" type="text/xsl"?>
<root>
<document>
<docId>nlp.txt</docId>
<sentences>
<sentence id="1">
<tokens>
<token id="1">
<word>Natural</word>
<lemma>natural</lemma>
<CharacterOffsetBegin>0</CharacterOffsetBegin>
<CharacterOffsetEnd>7</CharacterOffsetEnd>
<POS>JJ</POS>
<NER>O</NER>
<Speaker>PER0</Speaker>
</token>
<token id="2">
<word>language</word>
<lemma>language</lemma>
<CharacterOffsetBegin>8</CharacterOffsetBegin>
<CharacterOffsetEnd>16</CharacterOffsetEnd>
<POS>NN</POS>
<NER>O</NER>
<Speaker>PER0</Speaker>
</token>
出力結果(実行結果)
プログラム実行すると以下の結果が出力されます。
0 Natural
1 language
2 processing
3 From
4 Wikipedia
5 ,
6 the
7 free
8 encyclopedia
9 Natural
10 language
11 processing
12 -LRB-
13 NLP
14 -RRB-
15 is
16 a
17 field
18 of
19 computer
20 science
21 ,
22 artificial
23 intelligence
24 ,
25 and
26 linguistics
27 concerned
28 with
29 the
30 interactions
31 between
ちなみに -LRB-と-RRB-は括弧のことで、Stanford CoreNLPが変換しています。
- -LRB- 左括弧 (left bracket)
- -RRB- 右括弧 (right bracket)